Chez X5, nous traitons beaucoup de données dans un système ERP. On pense que personne d'autre ne nous traite dans SAP ERP et SAP BW en Russie. Mais il y a un autre point - le nombre d'opérations et la charge sur ce système augmentent rapidement. Pendant 3 ans, nous nous sommes «battus» pour les performances de notre poids lourd ERP, nous avons obtenu beaucoup de cônes, et avec quelles méthodes ils ont été traités, nous disons sous la coupe.

ERP X5
Désormais, X5 exploite plus de 13 000 magasins. La plupart des processus commerciaux de chacun d'entre eux passent par un seul système ERP. Chaque magasin peut avoir de 3 000 à 30 000 produits, ce qui crée des problèmes de charge sur le système, car des processus de recalcul régulier des prix le traversent conformément aux promotions et aux exigences législatives et au calcul de reconstitution des stocks. Tout cela est critique, et s'il n'est pas calculé à temps quelles marchandises en quelle quantité devraient être livrées au magasin demain ou quel prix devrait être sur les marchandises, les acheteurs ne trouveront pas ce qu'ils recherchaient sur les étagères ou ne pourront pas acheter les marchandises au prix de la promotion en cours stocks. En général, en plus de comptabiliser les transactions financières, le système ERP est responsable de beaucoup dans la vie quotidienne de chaque magasin.
Un peu des caractéristiques de performance d'un système ERP. Son architecture est classique, à trois niveaux avec des éléments orientés services: en plus, nous avons plus de 5000 clients épais et des téraoctets de flux d'informations provenant des magasins et des centres de distribution, dans la couche application - SAP ABAP avec plus de 10000 processus et, enfin, Oracle Database avec plus de 100 To de données. Chaque processus ABAP est une machine virtuelle conditionnelle qui exécute la logique métier ABAP avec son propre dialecte DBSL et SQL, la mise en cache, la gestion de la mémoire, l'ORM, etc. Chaque jour, nous obtenons plus de 15 To de modifications dans le journal de la base de données. Le niveau de charge est de 500 000 requêtes par seconde.
Cette architecture est un environnement hétérogène. Chacun des composants est multiplateforme, nous pouvons le déplacer sur différentes plates-formes, choisir les optimales, etc.
Le fait que le système ERP soit sous charge 24 heures sur 24, 365 jours par an, ajoute du carburant à l'incendie. Disponibilité - 99,9% du temps tout au long de l'année. La charge est divisée en profils jour et nuit et entretien ménager en temps libre.
Mais ce n'est pas tout. Le système a un cycle de libération serré et serré. Il réalise plus de 2 000 changements de lots par an. Cela peut être un nouveau bouton, et de sérieux changements dans la logique des applications métier.

En conséquence, il s'agit d'un système volumineux et très chargé, mais en même temps stable, prévisible et prêt pour la croissance qui peut héberger des dizaines de milliers de magasins. Mais cela n'a pas toujours été le cas.
2014. Point de bifurcation
Pour plonger dans le matériel pratique, vous devez remonter à 2014. Ensuite, il y a eu les tâches les plus difficiles pour optimiser le système. Il y avait environ 5 000 magasins.
À cette époque, le système était dans un état tel que la plupart des processus critiques n'étaient pas évolutifs et ne répondaient pas adéquatement à la charge croissante (c'est-à-dire l'apparition de nouveaux magasins et marchandises). De plus, deux ans plus tôt, un Hi-End cher a été acheté, et pendant un certain temps, une mise à niveau ne faisait pas partie de nos plans. De plus, les processus de l'ERP étaient déjà sur le point de violer le SLA. Le vendeur a conclu que la charge sur le système n'est pas évolutive. Personne ne savait si elle pouvait supporter au moins + 10% de l'augmentation de charge. Et il était prévu d'ouvrir deux fois plus de magasins en trois ans.
Il était impossible d'alimenter simplement le système ERP avec du fer neuf, et cela n'aiderait pas. Par conséquent, tout d'abord, nous avons décidé d'inclure une technique d'optimisation logicielle dans le cycle de publication et de suivre la règle: une croissance de charge linéaire proportionnelle à la croissance des inducteurs de charge est la clé de la prévisibilité et de l'évolutivité.
Quelle était la technique d'optimisation? Il s'agit d'un processus cyclique, divisé en plusieurs étapes:
- surveillance (identifier les goulots d'étranglement dans le système et identifier les principaux consommateurs de ressources)
- analyse (profilage des processus consommateurs, identification des structures avec le plus grand effet non linéaire sur la charge)
- développement (réduction de l'influence des structures sur la charge, réalisation de la charge linéaire)
- tests dans un environnement d'évaluation de la qualité ou mise en œuvre dans un environnement productif
Ensuite, le cycle a été répété.
Dans le processus, nous avons réalisé que les outils de surveillance actuels ne nous permettent pas d'identifier rapidement les meilleurs consommateurs, d'identifier les goulots d'étranglement et les processus gourmands en ressources. Par conséquent, pour accélérer, nous avons essayé les outils de recherche élastique et Grafana. Pour ce faire, ils ont développé indépendamment des collecteurs qui, à partir d'outils de surveillance standard dans Oracle / SAP / AIX / Linux, ont transféré les métriques vers la recherche élastique et ont permis une surveillance en temps réel de l'intégrité du système. En outre, ils ont enrichi la surveillance avec leurs mesures personnalisées, par exemple, le temps de réponse et le débit de composants SAP spécifiques ou la présentation de profils de charge pour les processus métier.
Optimisation du code et des processus
Tout d'abord, pour un effet moindre des goulots d'étranglement sur la vitesse, ils ont assuré une alimentation plus fluide de la charge du système.
La plupart des processus commerciaux de notre système ERP, par exemple, comme la tarification régulière ou la planification du réapprovisionnement des stocks, sont un traitement séquentiel étape par étape d'une grande quantité de données (pour toutes les marchandises et tous les magasins). Pour mettre en œuvre le traitement dans le cadre de tâches aussi difficiles, nous avons à un moment donné développé notre propre gestionnaire de traitement parallèle par lots (ci-après appelé le planificateur de charge). Dans ce cas, sous la forme d'un package, une étape de traitement effectuée séparément pour un magasin séparé est présentée.
Initialement, la logique de l'ordonnanceur était telle que d'abord les packages de la première étape de traitement étaient exécutés pour tous les magasins, puis les packages de la deuxième étape, etc. Autrement dit, le système exécutait simultanément des processus qui créaient le même type de charge et provoquaient la dégradation de certaines ressources (entrées / sorties vers la base de données ou le processeur sur les serveurs d'applications, etc.).
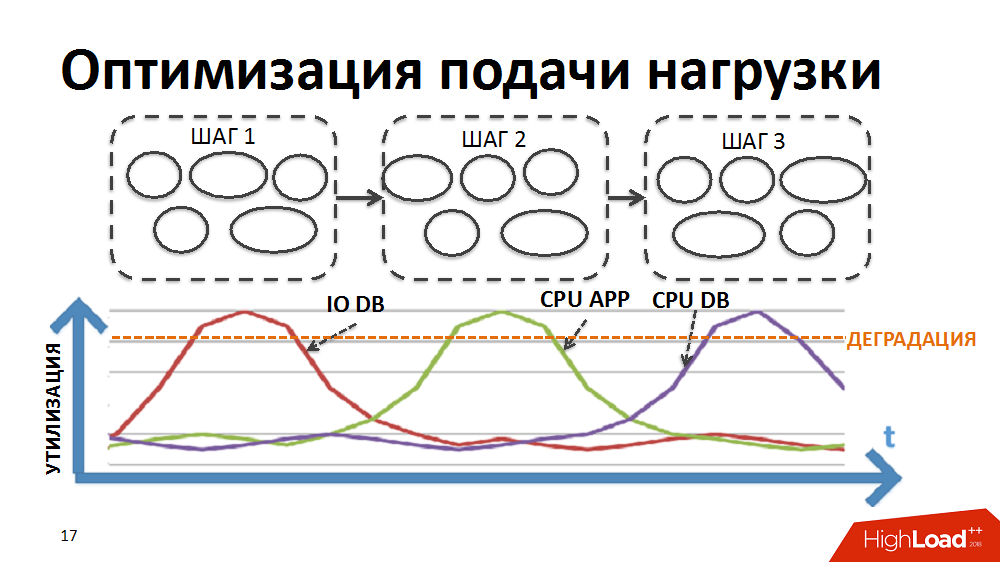
Nous avons réécrit la logique du planificateur afin que la chaîne de packages soit formée séparément pour chaque magasin et que la priorité de lancement de nouveaux packages soit établie non pas par étapes, mais par magasins.
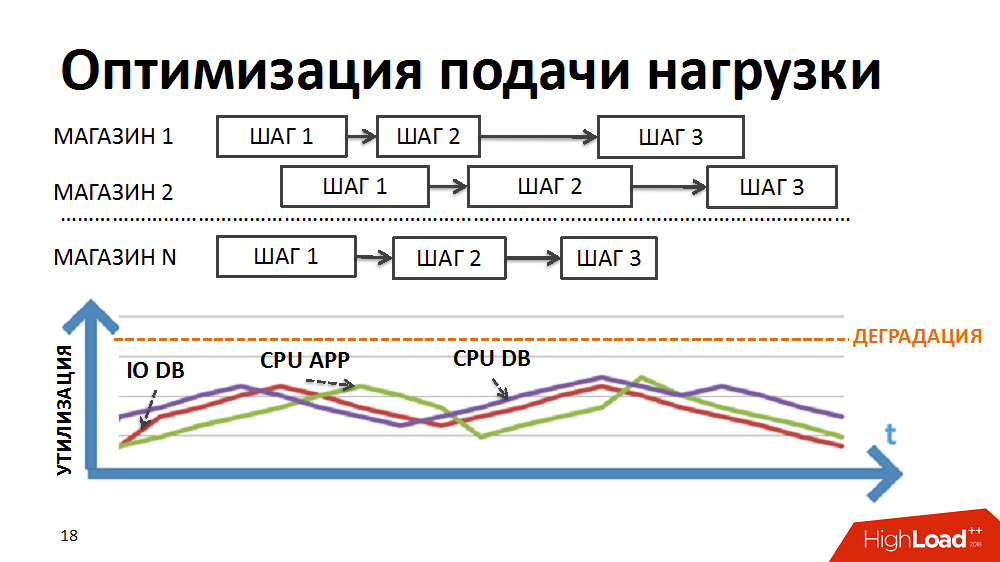
En raison de la durée différente des packages pour les différents magasins et du grand nombre contrôlé de processus exécutés simultanément dans le cadre des tâches de l'ordonnanceur de charge, nous avons réalisé l'exécution simultanée de processus hétérogènes, un chargement plus fluide de la charge et l'élimination de certains goulots d'étranglement.
Ensuite, ils ont commencé à optimiser les conceptions individuelles. Chaque paquet individuel a été examiné, profilé et assemblé des conceptions non optimales et des approches appliquées pour les optimiser. Par la suite, ces approches ont été incluses dans la réglementation du développeur afin d'empêcher une croissance indésirable de la charge pendant le développement du système. Certains d'entre eux:
- charge excessive sur le CPU des serveurs d'applications (Souvent générée par des algorithmes non linéaires dans le code du programme, par exemple, la bonne vieille recherche linéaire en boucles ou des algorithmes de recherche non linéaires pour les intersections d'ensembles d'éléments désordonnés, etc. ... Elle a été traitée en remplaçant par des algorithmes linéaires: remplacer la recherche linéaire en boucles par des binaires; pour rechercher des intersections d'ensembles, nous utilisons des algorithmes linéaires, des éléments de précommande, etc.)
- des appels identiques à la base de données avec les mêmes conditions dans le même processus conduisent souvent à une utilisation excessive du processeur de la base de données (elle est traitée en mettant en cache les résultats du premier échantillon dans la mémoire du programme ou au niveau du serveur d'applications et en utilisant des données mises en cache pour les échantillons suivants)
- demandes de jointure fréquentes (il est préférable de les exécuter, bien sûr, au niveau de la base de données, mais parfois nous nous sommes permis de les diviser en échantillons simples, dont le résultat est mis en cache, et de transférer la logique de collage à l'application. Ce sont des cas où il vaut mieux chauffer le serveur d'applications, et non la base de données. )
- demandes de jointure importantes entraînant un grand nombre d'E / S
À propos de ce dernier plus en détail. Dans ce cas, le modèle de données a été traduit sous une forme moins normale. Un exemple classique est une sélection de documents comptables pour une date spécifique pour un magasin individuel. De nombreux employés le demandent. La table principale (table d'en-tête) stocke les dates des documents, dans la table des positions - le magasin et les marchandises. Les requêtes les plus courantes sont une sélection de tous les documents d'un magasin particulier pour une date spécifique. Avec cette demande, le filtre par date sur la table des en-têtes donne 500 000 enregistrements, le filtre par magasin - le même montant. Dans le même temps, après avoir collé sur un magasin séparé pour la bonne date, nous avons un terme de 3 mille. Peu importe la table à partir de laquelle nous commençons à filtrer et à coller les données, nous obtenons toujours beaucoup d'E / S indésirables.
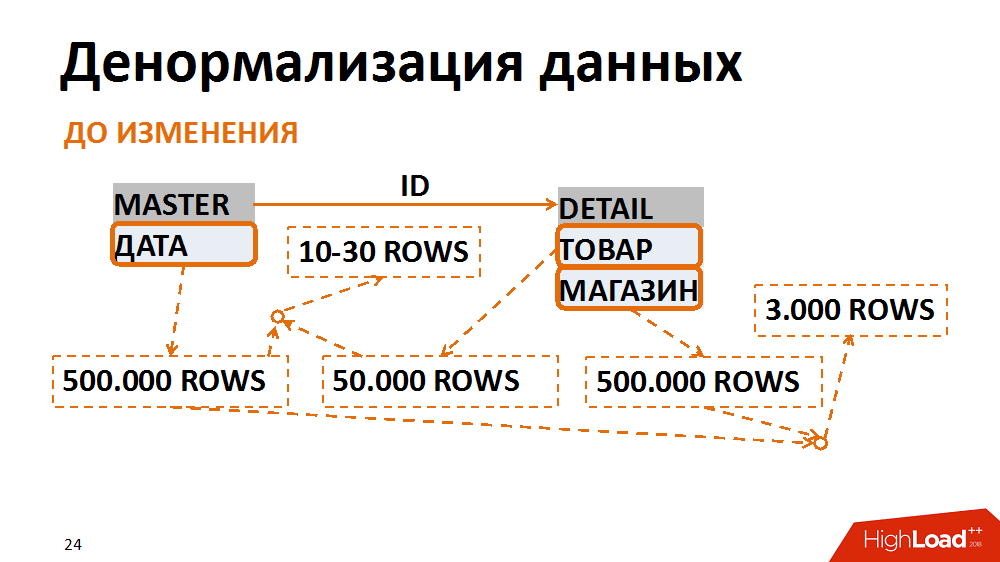
Cela peut être évité en présentant les données sous une forme moins normale. Dans un cas, le champ de date a été dupliqué dans la table de position, il a été rempli lors de la création de documents, les index ont été collectés pour une recherche rapide et ils étaient déjà filtrés selon la table de position. Ainsi, après avoir sacrifié des frais généraux insignifiants pour stocker un nouveau champ et des index, nous avons réduit à plusieurs reprises le nombre d'opérations d'entrée / sortie générées par des requêtes problématiques.

2015. Le problème d'un service
Depuis un an et demi, nous avons fait un excellent travail d'optimisation du système, il est devenu plus prévisible. Néanmoins, les plans visant à doubler le nombre de magasins sont restés pertinents, de sorte que les défis auxquels nous étions confrontés étaient toujours d'actualité.
En montant, nous avons rencontré divers goulets d'étranglement. Par exemple, fin 2015, ils ont réalisé qu'ils s'étaient reposés sur les performances d'un core-service de la plateforme. Il s'agit d'un service de verrouillage logique SAP ABAP. À cause de cela, le système ne résisterait clairement pas à la croissance de la charge. Des pertes de grosses sommes d'argent se profilaient à l'horizon.
Pour clarifier, la tâche du service est d'apporter la transactionnalité logique au niveau du serveur d'applications. Dans ABAP, une seule transaction peut passer par plusieurs étapes sur différents workflows. Pour que la transaction soit complète, il existe un service de verrouillage et des mécanismes associés. Les opérations de verrouillage et de déverrouillage s'y produisent rapidement, mais elles sont atomiques, elles ne peuvent pas être séparées. Il y avait un problème avec les E / S synchrones.
Le service s'est accéléré un peu après que les développeurs SAP aient publié un correctif spécial, nous avons basculé le service sur un autre matériel et travaillé sur les paramètres du système, mais ce n'était toujours pas suffisant. Le plafond du service des passeports était d'environ 7 000 opérations par seconde, et pendant longtemps nous en avions déjà besoin de 10 000.
Après le test de charge synthétique, il a été constaté que la dégradation n'est pas linéaire et nous sommes néanmoins à la limite de performance de service au-dessus de laquelle se manifeste la dégradation inacceptable de l'ensemble du système ERP. Des appels répétés aux développeurs n'ont donné qu'un verdict décevant - le service fonctionne correctement, nous en demandons simplement trop dans l'architecture actuelle de la solution. Même si nous nous engageions immédiatement à refaire toute l'architecture de la solution, il nous faudrait plusieurs mois pour maintenir l'opérabilité du système actuel.
L'une des premières options pour essayer de prolonger la durée de vie d'un service de verrouillage consiste à accélérer les E / S et l'écriture dans le système de fichiers. Quoi? Expériences avec une alternative à AIX. Transféré le service à Linux sur la Power-machine la plus puissante, et gagné beaucoup de temps de réponse. Le service avec le système de fichiers activé s'est comporté de la même manière que sur Aix avec les personnes handicapées. Ensuite, nous avons transféré ce code sur l'une des lames x86_64 et obtenu une courbe de performance en pente encore plus fantastique que précédemment. Ça avait l'air drôle.
On peut supposer que les développeurs sur AIX et Linux ont fait quelque chose de différent lors du dernier test, mais l'architecture du processeur a également eu un effet ici.
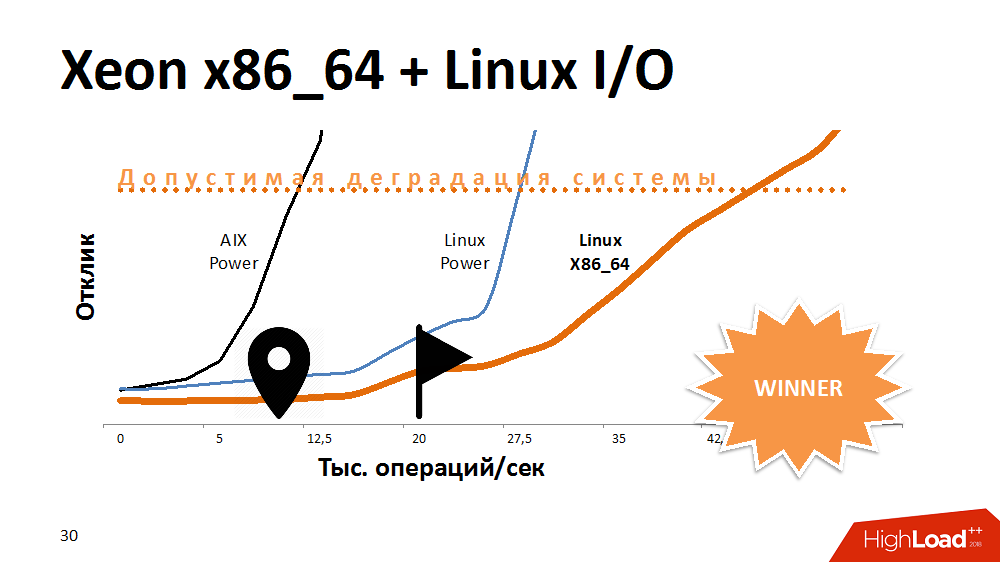
Quelle a été la conclusion? Certaines plates-formes conviennent parfaitement aux bases de données multithread, offrant à la fois des performances et une tolérance aux pannes, mais un processeur sur une architecture différente peut mieux faire face à des tâches spécifiques. Si au début de la construction d'une solution pour abandonner la multiplateforme, vous pouvez perdre de l'espace pour des manœuvres à l'avenir.
Néanmoins, nous avons compris ce problème et le service a commencé à fonctionner 3 à 4 fois plus rapidement, ce qui est suffisant pour une très longue croissance.
2016. DB CPU Bottleneck
Littéralement six mois plus tard, des problèmes exotiques ont commencé à se faire sentir avec le processeur de la base de données. Il semble clair qu'avec une augmentation de la charge, la consommation de ressources processeur augmente. Mais SysTime a commencé à en prendre la majeure partie, et il y avait clairement un problème dans le noyau. Ils ont commencé à comprendre, à faire des tests de charge synthétique et ont réalisé que notre débit était de 300000 opérations par seconde, c'est-à-dire milliards de requêtes par heure, puis dégradation.
En conséquence, nous sommes arrivés à la conclusion que la demande parfaite est celle qui n'existe pas. Nous avons élargi notre technique d'optimisation avec de nouvelles approches et mené un audit du système ERP: nous avons commencé à rechercher des requêtes, par exemple, avec une faible efficacité (100000 sélections - à la suite de 100 lignes ou 0 en général) - à refaire. Si les demandes "vides" ne peuvent pas être supprimées, alors laissez-les aller au "cache négatif", le cas échéant. Si de nombreuses demandes pour les mêmes données de produit sont traitées en parallèle, laissez-les tourmenter le serveur d'applications et non la base de données, nous le mettons en cache. Nous «agrandissons» également un grand nombre de requêtes uniques fréquentes sur une clé dans le cadre d'un processus, en la remplaçant par des sélections plus rares sur une partie d'une clé. Ou, par exemple, pour répartir la charge dans la chaîne de traitement, différentes étapes peuvent être effectuées sur différents serveurs d'applications. C'est bien, mais à différentes étapes, ils peuvent demander la même chose à la base. Ensuite, laissez la première étape après avoir démarré sur le cache d'application une partie des demandes, et il reste là pour terminer le reste de la chaîne.

Avec l'aide de telles astuces, nous avons gagné un peu partout, mais au final nous avons sérieusement déchargé la base. Le système a pris vie. Pendant ce temps, nous sommes descendus à Aix.
D'autres expériences ont révélé un plafond de performances - les 300 000 appels DataBase par seconde déjà mentionnés. La racine du problème était la performance de l'interface réseau, qui avait un plafond - environ 300 000 paquets par seconde dans une direction. À mesure que le plafond se rapprochait, le temps des appels système augmentait. Comme il s'est avéré plus tard, il s'agissait également d'un héritage de la pile réseau du noyau AIX.
En général, nous n'avons jamais eu de problèmes de latence, le cœur du réseau était productif, tous les cordons étaient assemblés en un grand canal indestructible sur une seule interface. Nous avons fait un contournement: nous avons divisé l'ensemble du réseau entre les serveurs d'applications et la base de données en groupes sur différentes interfaces. En conséquence, chaque groupe de serveurs d'applications a communiqué avec la base de données via sa propre interface distincte. Les performances maximales de chaque interface ont été légèrement réduites, mais au total, nous avons overclocké le réseau à 1 million de paquets par seconde dans une direction.
Et le principe "La meilleure requête est celle qui n'existe pas" a été ajouté au Talmud pour les développeurs, afin que cela soit pris en compte lors de l'écriture du code.
2017. Live to upgrade
Eh bien, la dernière étape de la récupération de notre système, passée en 2017. Il ne restait plus qu'à vivre un peu jusqu'à la mise à niveau et il fallait tenir le SLA pour rien. Le code a été optimisé, mais nous avons vu que plus la charge sur le processeur de la base de données était élevée, plus les processus fonctionnaient lentement, bien que la marge d'utilisation soit de 10 à 20%. Initialement, on estimait que 100% est deux fois plus que 50%. Et quand il y a une réserve de 10-20%, c'est 10-20%. En fait, à une charge supérieure à 67-80%, la durée des tâches a augmenté de façon non linéaire, c'est-à-dire La loi d'Amdahl a fonctionné. Le système avait une limite de parallélisation et lorsqu'il a été dépassé, avec la participation d'un nombre croissant de processeurs dans le travail, les performances de chaque processeur individuel ont diminué.
À cette époque, nous utilisions 125 processeurs physiques, ou 500 processeurs logiques, compte tenu du multithreading au niveau AIX. Que suggéreriez-vous? Surclassement? Même avant la fin de sa coordination, il a fallu attendre plusieurs mois et ne pas abandonner le SLA.
À un moment donné, ils ont réalisé que les mesures traditionnelles d'utilisation des processeurs ne sont pas indicatives pour nous - elles ne montrent pas le début réel de la dégradation. Pour une évaluation réaliste de la santé du système, nous avons commencé à utiliser la métrique intégrée - le résultat d'un test synthétique comme métrique pour les performances du processeur de base de données. Une fois par minute, ils ont fait un test synthétique, mesuré sa durée et affiché cette métrique sur nos moniteurs. Et ils ont réagi si la métrique dépassait le point critique déclaré. Nous avons un peu tenu la charge de nos planificateurs de charge afin qu'elle reste dans la zone «couple maximal» de la base de données.
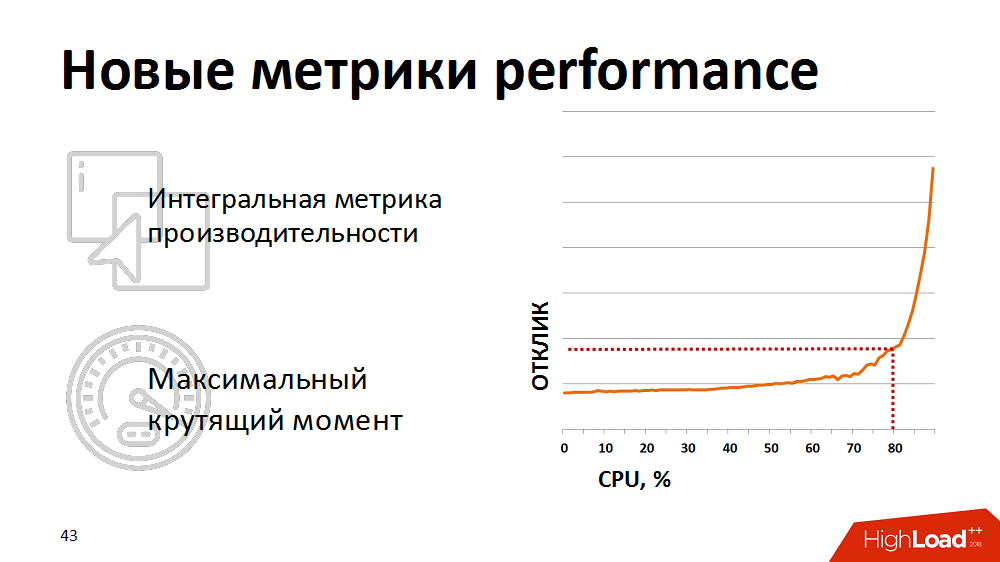
Cependant, le contrôle manuel était inefficace et nous étions fatigués de nous réveiller la nuit. Ensuite, nous avons réécrit le planificateur de charge afin qu'il reçoive des commentaires sur les mesures de performances actuelles. Si les mesures dépassaient le seuil jaune (voir l'image), la planification des packages de faible priorité était gelée et seuls les processus critiques de l'entreprise étaient prioritaires. Ainsi, nous avons pu contrôler automatiquement l'intensité de la charge et les ressources ont été utilisées efficacement. Et la chose la plus intéressante est que, en maintenant le système à 80% de la charge, dans cette même zone de couple maximal, nous avons finalement obtenu une réduction du temps total pour l'exécution des processus métier, car chaque fil a commencé à fonctionner beaucoup plus rapidement.
Quelques conseils pour ceux qui travaillent avec un ERP très chargé
- Il est très important de surveiller les performances des systèmes au début d'un projet, en particulier avec leurs propres métriques.
- Assurer une augmentation linéaire de la charge proportionnelle à l'augmentation du nombre de conducteurs de charge (dans notre cas, il s'agissait de marchandises et de magasins).
- Éliminez les constructions non linéaires dans le code, utilisez la mise en cache pour éliminer les requêtes de base de données identiques.
- Si vous devez transférer la charge de l'UC de la base de données vers l'UC du serveur d'applications, vous pouvez recourir à la division des demandes de jointure en échantillons simples.
- Pour toutes les optimisations, n'oubliez pas qu'une demande rapide est bonne et qu'une demande rapide et fréquente est parfois mauvaise.
- .
- , ; “ ” .
Highload , .
, , SAP #ITX5, #ITX5
SAP.