 Publié par Ekaterina Semashko, développeur iOS junior fort, DataArt
Publié par Ekaterina Semashko, développeur iOS junior fort, DataArtUn peu sur le projet: une application mobile pour la plateforme iOS, écrite en Swift. Le but de l'application est la possibilité de partager des cartes de réduction entre les employés de l'entreprise et leurs amis.
L'un des objectifs du projet était d'apprendre et de pratiquer les technologies et les bibliothèques populaires. Le domaine a été choisi pour le stockage des données locales, Alamofire a été utilisé pour travailler avec le serveur, Google Sign-In a été utilisé pour l'authentification, PINRemoteImage a été utilisé pour le téléchargement d'images.
Les principales fonctions de l'application:
- ajouter une carte, la modifier et la supprimer;
- visualiser les cartes des autres;
- rechercher des cartes par nom de magasin / nom d'utilisateur;
- Ajoutez des cartes à vos favoris pour un accès rapide.
La possibilité d'utiliser l'application sans se connecter au réseau a été supposée dès le début, mais uniquement en mode lecture. C'est-à-dire nous pouvions afficher des informations sur les cartes, mais nous ne pouvions pas les modifier sans Internet. Pour cela, l'application avait toujours une copie de toutes les cartes et marques de la base de données du serveur, ainsi qu'une liste de favoris pour l'utilisateur actuel. La recherche a également été mise en œuvre localement.
Plus tard, nous avons décidé de nous développer hors ligne en ajoutant un mode d'enregistrement. Les informations sur les modifications apportées par l'utilisateur ont été stockées et synchronisées lorsqu'une connexion Internet est apparue. La mise en œuvre d'un tel mode hors ligne en lecture-écriture sera discutée.
Que faut-il pour un mode hors ligne complet dans une application mobile? Nous devons supprimer la dépendance de l'utilisateur à la qualité de la connexion Internet, en particulier:
- Supprimez la dépendance des réponses à l'utilisateur de ses actions dans l'interface utilisateur du serveur. Tout d'abord, la requête va interagir avec le stockage local, puis elle sera envoyée au serveur.
- Marquez et stockez les modifications locales.
- Implémentez un mécanisme de synchronisation - lorsqu'une connexion Internet apparaît, vous devez envoyer les modifications au serveur.
- Montrez à l'utilisateur quelles modifications sont synchronisées, lesquelles ne le sont pas.
Approche hors ligne
Tout d'abord, j'ai dû changer le mécanisme existant pour interagir avec le serveur et la base de données. L'objectif était d'empêcher l'utilisateur de dépendre de la présence ou de l'absence d'Internet. Tout d'abord, il doit interagir avec l'entrepôt de données local et les demandes de serveur doivent être en arrière-plan.
Dans la version précédente, il y avait une forte connexion entre la couche de stockage de données et la couche réseau. Le mécanisme de travail avec les données était le suivant: d'abord une demande a été faite au serveur via la classe NetworkManager, nous avons attendu le résultat, après que les données ont été enregistrées dans la base de données via la classe Repository. Ensuite, le résultat a été donné à l'interface utilisateur, comme le montre le diagramme.
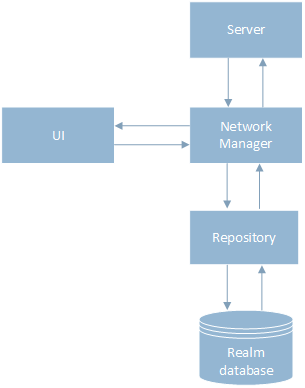
Pour implémenter l'approche hors ligne en premier, j'ai séparé la couche de stockage de données et la couche réseau, introduisant une nouvelle classe Flow qui contrôlait l'ordre dans lequel NetworkManager et le référentiel étaient appelés. Maintenant, les données sont d'abord enregistrées dans la base de données via la classe Repository, puis le résultat est envoyé à l'interface utilisateur et l'utilisateur continue de travailler avec l'application. En arrière-plan, une demande est faite au serveur, après la réponse, les informations dans la base de données et l'interface utilisateur sont mises à jour.
Travailler avec des identificateurs d'objet
Avec la nouvelle architecture, plusieurs nouvelles tâches sont apparues, dont une avec des objets id. Auparavant, nous les recevions du serveur lors de la création de l'objet. Mais maintenant, l'objet a été créé localement, en conséquence, il était nécessaire de générer un identifiant et, après la synchronisation, de les mettre à jour avec ceux en cours. Je suis tombé sur la première limitation de Realm: après avoir créé un objet, vous ne pouvez pas changer sa clé primaire.
La première option consistait à abandonner la clé primaire de l'objet, à faire de id un champ régulier. Mais en même temps, les avantages de l'utilisation de la clé primaire ont été perdus: l'indexation du domaine, qui accélère la récupération de l'objet, la possibilité de mettre à jour l'objet avec le drapeau de création (créer un objet s'il n'existe pas) et le respect de l'unicité de l'objet.
Je voulais enregistrer la clé primaire, mais cela ne pouvait pas être l'ID de l'objet depuis le serveur. En conséquence, la solution de travail était d'avoir deux identifiants, l'un d'eux serveur, un champ facultatif et le second local, qui serait la clé primaire.
Par conséquent, un identifiant local est généré sur le client lors de la création locale de l'objet, et dans le cas où l'objet provenait du serveur, il est égal à l'identifiant du serveur. Étant donné que dans la source unique d'application de vérité, il existe une base de données, lors de la réception de données du serveur, l'objet est mis à jour avec l'identifiant local actuel et ne fonctionne qu'avec lui. Lors de l'envoi de données au serveur, l'identifiant du serveur est transmis.
Stockage des modifications non synchronisées
Les modifications apportées aux objets qui n'ont pas encore été envoyés au serveur doivent être stockées localement. Cela peut être implémenté des manières suivantes:
- Ajout de champs à des objets existants
- stocker des objets non synchronisés dans des tables séparées;
- le stockage des modifications de champs individuels dans un certain format.
Je n'utilise pas d'objets Realm directement dans mes classes, mais je fais leur mappage par moi-même pour éviter les problèmes de multithreading. L'interface des mises à jour automatiques se fait à l'aide d'échantillons de résultats de mise à jour automatique, où je m'abonne aux demandes de mise à jour. Seule la première approche fonctionnait avec mon architecture actuelle, donc le choix s'est porté sur l'ajout de champs aux objets existants.
L'objet cartographique a subi le plus de modifications:
- synchronisé - y a-t-il des données sur le serveur;
- supprimé - vrai, si la carte est supprimée uniquement localement, la synchronisation est requise.
Identifiants discutés dans la partie précédente:
- localId - la clé primaire de l'entité dans l'application, soit égale à l'ID du serveur, soit générée localement;
- serverId - id du serveur.
Il convient également de mentionner le stockage d'images. En substance, le champ Attachment diskURL a été ajouté au champ serverURL de l'image sur le serveur, qui stocke l'adresse de l'image locale non synchronisée. Lors de la synchronisation de l'image, l'image locale a été supprimée afin de ne pas obstruer la mémoire de l'appareil.
Synchronisation du serveur
Pour synchroniser avec le serveur, le travail avec l'accessibilité a été ajouté, de sorte que lorsque Internet apparaît, le mécanisme de synchronisation démarre.
Tout d'abord, il vérifie s'il y a des modifications à apporter à la base de données. Ensuite, une demande est envoyée au serveur pour une diffusion de données réelle, par conséquent, les modifications qui n'ont pas besoin d'être envoyées au client sont éliminées (par exemple, la modification d'un objet qui a déjà été supprimé sur le serveur). Les modifications restantes mettent en file d'attente les demandes au serveur.
Pour envoyer des modifications, il était possible d'implémenter des mises à jour groupées, d'envoyer les modifications dans un tableau ou de faire une demande importante pour synchroniser toutes les données. Mais à ce moment-là, le développeur principal était déjà occupé dans un autre projet et ne nous a aidés que pendant notre temps libre, nous créons donc une demande pour chaque type de changement.
J'ai implémenté la file d'attente via OperationQueue et enveloppé chaque demande dans une opération asynchrone. Certaines opérations dépendent les unes des autres, par exemple, nous ne pouvons pas charger l'image de la carte avant de créer la carte, j'ai donc ajouté la dépendance de l'opération d'image à l'opération de carte. En outre, l'opération de téléchargement d'images sur le serveur a reçu une priorité inférieure à tout le monde, et je les ai ajoutées à la file d'attente également en raison de leur lourdeur.
Lors de la planification du mode hors ligne, la grande question était de résoudre les conflits avec le serveur lors de la synchronisation. Mais lorsque nous sommes arrivés à ce point lors de la mise en œuvre, nous avons réalisé que le cas où un utilisateur modifie les mêmes données sur différents appareils est très rare. Il nous suffit donc de mettre en œuvre le dernier mécanisme de victoires de l'auteur. Lors de la synchronisation, la priorité est toujours donnée aux modifications non envoyées sur le client, elles ne sont pas effacées.
La gestion des erreurs en est encore à ses balbutiements, si la synchronisation échoue, l'objet sera ajouté à la file d'attente des modifications la prochaine fois qu'Internet apparaîtra. Et puis, s'il est toujours hors de synchronisation après la fusion, l'utilisateur décidera de le laisser ou de le supprimer.
Solution de contournement supplémentaire lors de l'utilisation de Realm
Lorsque vous travaillez avec Realm face à plusieurs autres problèmes. Peut-être que cette expérience sera également utile à quelqu'un.
Lors du tri par chaîne, l'ordre suit l'ordre des caractères en UTF-8, il n'y a pas de prise en charge de la recherche sensible à la casse. Nous sommes confrontés à une situation où les noms en minuscules viennent après les noms en majuscules, par exemple: Magnet, Pyaterochka, Ribbon. Si la liste est très grande, tous les noms en minuscules seront en bas, ce qui est très désagréable.
Pour conserver l'ordre de tri, quel que soit le cas, nous avons dû introduire un nouveau champ lowercasedName, le mettre à jour lors de la mise à jour du nom et le trier par lui.
De plus, un nouveau champ a été ajouté pour le tri par la présence d'une carte dans les favoris, car cela nécessite essentiellement une sous-requête pour les relations de l'objet.
Lors de la recherche dans Realm, il existe la méthode CONTAINS [c]% @ pour les recherches non sensibles à la casse. Mais, hélas, cela ne fonctionne qu'avec l'alphabet latin. Pour les marques russes, nous avons également dû créer des champs séparés et les rechercher. Mais plus tard, il s'est avéré être entre nos mains d'exclure les caractères spéciaux lors de la recherche.
Comme vous pouvez le voir, pour les applications mobiles, il est tout à fait possible d'implémenter un mode hors ligne avec enregistrement des modifications et synchronisation avec peu de sang, et parfois même avec des modifications minimes sur le backend.
Malgré certaines difficultés, vous pouvez utiliser Realm pour l'implémenter, tout en bénéficiant de tous les avantages sous la forme de mises à jour en direct, d'une architecture sans copie et d'une API pratique.
Il n'y a donc aucune raison de refuser à tout moment à vos utilisateurs l'accès aux données, quelle que soit la qualité de la connexion.