
Tout a commencé ringard - depuis un an, mon entreprise paie des frais mensuels pour un service qui savait comment trouver une région avec des plaques d'immatriculation sur la photo. Cette fonction est utilisée pour esquisser automatiquement les numéros de certains clients.
Et un beau jour, le ministère des Affaires intérieures de l'Ukraine a ouvert l'accès au
registre des véhicules . Maintenant, en utilisant la plaque d'immatriculation, il est devenu possible de vérifier certaines informations sur la voiture (marque, modèle, année de fabrication, couleur, etc.)! La routine ennuyeuse de la programmation linéaire s'est estompée avant une nouvelle tâche - lire les nombres à travers la base de photos et valider ces données avec celles que l'utilisateur a spécifiées. Vous savez vous-même comment ça se passe «les yeux illuminés» - l'appel a été accepté, toutes les autres tâches sont devenues ennuyeuses et monotones pendant un certain temps ... Nous nous sommes mis au travail et avons obtenu de bons résultats, que nous avons en fait décidé de partager avec la communauté.
Pour référence: sur le site AUTO.RIA.com, environ 100 000 photos sont ajoutées par jour.
Les datasaentistes le savent depuis longtemps et sont capables de résoudre de tels problèmes, donc
dimabendera et
moi avons écrit cet article spécifiquement pour les programmeurs. Si vous n'avez pas peur de l'expression «réseaux convolutionnels» et savez écrire «Hello World» en python - vous êtes les bienvenus sous cat…
Qui d'autre reconnaît
Il y a un an, j'ai étudié ce marché et il s'est avéré que peu de services et de logiciels peuvent fonctionner avec les numéros de pays exUSSR. Voici une liste des entreprises avec lesquelles nous avons travaillé:
- Il existe une version open source et commerciale. La version opensource montrait un taux de reconnaissance très faible, en plus, elle nécessitait des dépendances spécifiques pour son assemblage et son fonctionnement (nous ne l'avons pas particulièrement apprécié). La version commerciale, ou plutôt, le service commercial fonctionne bien. Capable de travailler avec des numéros russes et ukrainiens. Les prix sont modérés - 49 $ / 50 000 reconnaissances par mois. Démo en ligne d'OpenALPR
- Nous utilisons ce service depuis environ un an. La qualité est bonne. Il trouve très bien la zone avec le numéro. Le service ne sait pas comment travailler avec des numéros ukrainiens et européens. Il convient de noter le bon travail avec des images de faible qualité (dans la neige, photo basse résolution, ...). Le prix du service est également acceptable, mais ils hésitent à accepter de petits volumes.
Il existe de nombreux systèmes commerciaux avec des logiciels fermés, mais nous n'avons pas trouvé une bonne implémentation open source. En fait, cela est très étrange, car les outils open source qui sous-tendent la solution à ce problème existent depuis longtemps.
Quels outils sont nécessaires pour reconnaître les nombres
Trouver des objets dans une image ou dans un flux vidéo est une tâche du domaine de la vision par ordinateur, qui est résolue par différentes approches, mais le plus souvent à l'aide de réseaux de neurones dits convolutionnels. Nous devons trouver non seulement la zone de la photo où se trouve l'objet souhaité, mais également séparer tous ses points des autres objets ou de l'arrière-plan. Ce type de tâche est appelée «Segmentation d'instance». L'illustration ci-dessous illustre différents types de tâches de vision par ordinateur.
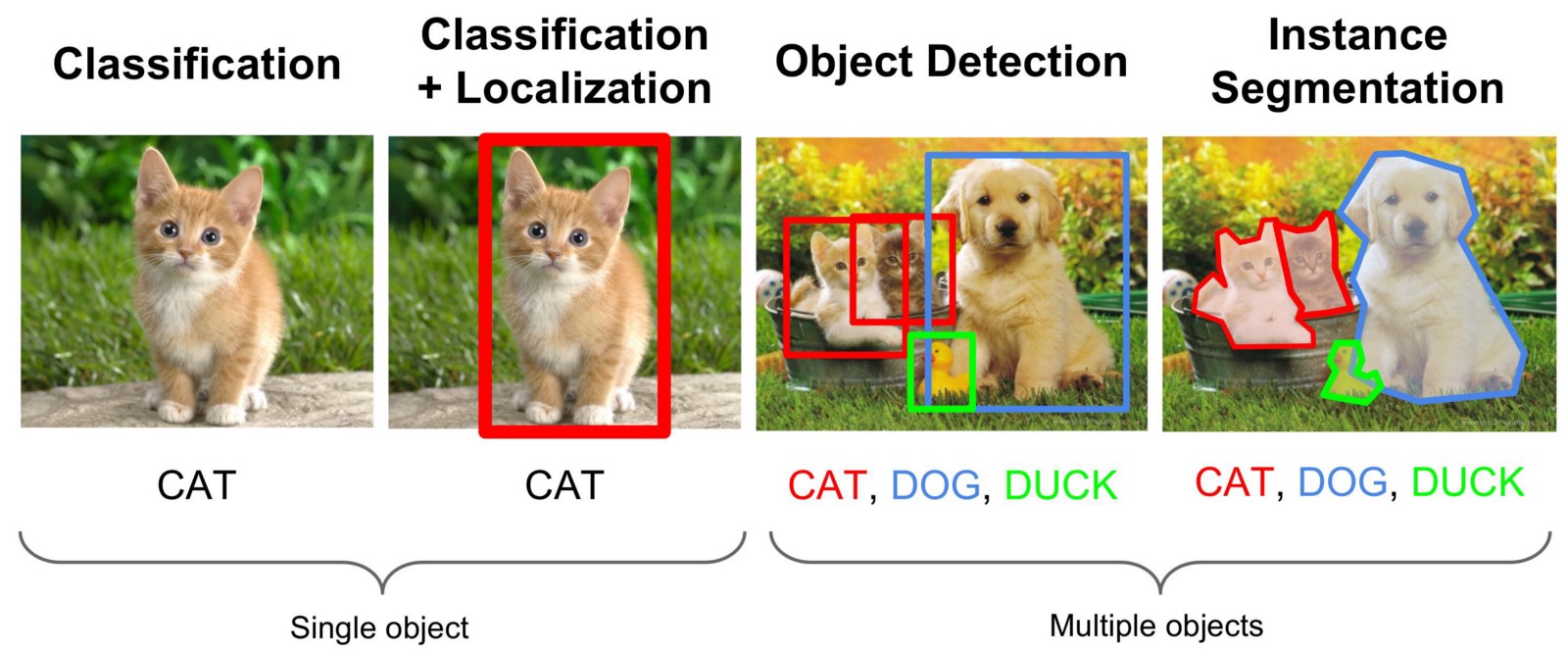
Je n'écrirai pas beaucoup de théorie sur le fonctionnement du réseau de convolution, ces informations sont suffisantes sur le réseau et les rapports sur YouTube.
A partir d'architectures modernes de tableaux convolutifs pour des tâches de segmentation, ils utilisent souvent:
U-Net ou
Mask R-CNN . Nous avons choisi le masque R-CNN.
Le deuxième outil dont nous avons besoin est une bibliothèque de reconnaissance de texte qui pourrait fonctionner avec différentes langues et qui peut être facilement personnalisée selon les spécificités des textes que nous reconnaîtrons. Ici, le choix n'est pas si grand, le plus avancé est
tesseract de Google.
Il existe également un certain nombre d'outils moins «globaux» avec lesquels nous aurons besoin de normaliser la zone avec la plaque d'immatriculation (apportez-la de manière à ce que la reconnaissance de texte soit possible). Généralement, opencv est utilisé pour de telles conversions.
En outre, il sera possible d'essayer de déterminer le pays et le type auquel appartient le numéro de plaque d'immatriculation, de sorte que dans le post-traitement, nous appliquons un modèle de raffinement spécifique à ce pays et à ce type de numéro. Par exemple, la plaque d'immatriculation ukrainienne, à partir de 2015, décorée en bleu et jaune, se compose du modèle «deux lettres quatre chiffres deux lettres».

De plus, en ayant des statistiques sur la fréquence des «réunions» dans les plaques d'immatriculation d'une combinaison particulière de lettres ou de chiffres, vous pouvez améliorer la qualité du post-traitement dans des situations «controversées». "
Filet Nomeroff
D'après le titre de l'article, il est clair que nous avons tous mis en œuvre et nommé le projet
Nomeroff Net . Maintenant, une partie du code de ce projet travaille déjà en production sur
AUTO.RIA.com . Bien sûr, c'est encore loin des analogues commerciaux; tout ne fonctionne bien que pour les chiffres ukrainiens. De plus, une vitesse acceptable n'est atteinte qu'avec le support du tensorflow du module GPU! Sans GPU, vous pouvez également essayer, mais pas sur le Raspberry Pi :).
Tous les matériaux pour notre projet: jeux de données balisés et modèles formés , nous avons publié publiquement avec la permission de RIA.com sous une licence Creative Commons CC BY 4.0
De quoi avons-nous besoin
Dmitry et moi fonctionnons tous sur Fedora 28, je suis sûr que tout peut être installé sur n'importe quelle autre distribution Linux. Je ne voudrais pas transformer ce post en instructions pour installer et configurer tensorflow, si vous voulez essayer et que quelque chose ne fonctionne pas - demandez dans les commentaires, je répondrai et vous le dirai.
Afin d'accélérer l'installation, nous prévoyons de créer un fichier docker - attendez-vous dans les prochaines mises à jour du projet.
Nomeroff Net "Bonjour tout le monde"
Essayons de reconnaître quelque chose. Nous clonons un
référentiel avec le code de
github . Nous téléchargeons dans le dossier des modèles,
des modèles formés pour la recherche et la classification des nombres, nous ajusterons légèrement les variables avec l'emplacement des dossiers pour nous-mêmes.
UPD: Ce code est obsolète, il ne fonctionnera que
dans la branche 0.1.0 ,
voir les derniers exemples ici :
Tout peut être reconnu:
import os import sys import json import matplotlib.image as mpimg
Démo en ligne
Ils ont esquissé une
démo simple pour ceux qui ne veulent pas installer et exécuter tout cela :). Soyez indulgent et patient avec la vitesse du script.
Si vous avez besoin d'exemples de nombres ukrainiens (pour vérifier le fonctionnement des algorithmes de correction), prenez un exemple
dans ce dossier.Et ensuite
Je comprends que le sujet est très niche et ne suscitera probablement pas un grand intérêt parmi un large éventail de programmeurs, en outre, le code et les modèles sont encore assez «bruts» en termes de qualité de reconnaissance, de vitesse, de consommation de mémoire, etc. Mais il y a toujours de l'espoir qu'il y aura des passionnés qui seront intéressés à former des modèles pour leurs besoins, leur pays, qui vous aideront et vous diront où il y a des problèmes et avec nous, ne feront pas pire que les homologues commerciaux.
Problèmes connus
- Le projet n'a pas de documentation, seulement des exemples de code de base.
- En tant que module de reconnaissance, le tesseract OCR universel est sélectionné et il peut lire beaucoup, mais il fait beaucoup d'erreurs. Dans le cas de la reconnaissance des nombres ukrainiens, un système de correction spécialisé y est écrit, ce qui compense jusqu'à présent certaines des erreurs, mais il y a une intuition que beaucoup plus peut être fait ici.
- Les nombres «carrés» (plaques d'immatriculation avec une proportion de 1: 2) sont assez rares et nous venons juste de commencer à les traiter, il y aura donc plus d'erreurs avec eux.
- Parfois, au lieu d'une plaque d'immatriculation, notre modèle trouve des panneaux de signalisation avec le nom du village, un tableau de bord à l'intérieur de la cabine et d'autres objets.
- Avec une mauvaise qualité du nombre ou une faible résolution, une région de 4 points n'est pas complètement déterminée
Annonce
Si cela peut être intéressant pour quelqu'un, dans la deuxième partie, nous allons parler de comment et comment baliser votre jeu de données et comment former vos modèles qui peuvent mieux fonctionner pour votre contenu (votre pays, la taille de votre photo). Nous parlerons également de la façon de créer votre propre classificateur, qui, par exemple, vous aidera à déterminer si le nombre est esquissé sur la photo.
Quelques exemples dans le cahier Jupyter:
Liens utiles