Vous a-t-on déjà demandé de calculer la quantité de quelque chose en fonction des données de la base de données du mois dernier, en regroupant le résultat par certaines valeurs et en le décomposant par jour / heure?
Si oui - alors vous imaginez déjà que vous devez écrire quelque chose comme ça, pire encore
SELECT hour(datetime), somename, count(*), sum(somemetric) from table where datetime > :monthAgo group by 1, 2 order by 1 desc, 2
De temps en temps, une grande variété de telles demandes commencent à apparaître, et si vous endurez et aidez une fois, hélas, des appels viendront à l'avenir.
Mais de telles demandes sont mauvaises en ce qu'elles consomment bien les ressources système lors de l'exécution, et il peut y avoir tellement de données que même une réplique pour de telles demandes sera dommage (et son heure).
Mais que se passe-t-il si je dis que dans PostgreSQL, vous pouvez créer une vue qui, à la volée, ne prendra en compte que les nouvelles données entrantes dans une requête directement similaire, comme ci-dessus?
Donc - il peut faire l'extension PipelineDB
Démonstration de leur site comment cela fonctionne PipelineDB était auparavant un projet distinct, mais est maintenant disponible en tant qu'extension pour PG 10.1 et supérieur.
Et bien que les opportunités fournies existent depuis longtemps dans d'autres produits spécifiquement conçus pour collecter des métriques en temps réel, PipelineDB a un avantage significatif: un seuil d'entrée plus bas pour les développeurs qui connaissent déjà SQL).
Pour certains, ce n'est peut-être pas essentiel. Personnellement, je ne suis pas trop paresseux pour essayer tout ce qui semble approprié pour résoudre un problème particulier, mais je ne vais pas tout de suite utiliser une nouvelle solution pour tous les cas. Par conséquent, dans cet article, je ne demande pas de tout laisser tomber et d'installer PipelineDB tout de suite, ce n'est qu'un aperçu des principales fonctionnalités, comme la chose me parut curieuse.
Et donc, en général, ils ont une bonne documentation, mais je veux partager mon expérience sur la façon d'essayer cette entreprise dans la pratique et d'apporter les résultats à Grafana.
Afin de ne pas salir la machine locale, je déploie tout dans le docker.
Images utilisées:
postgres:latest ,
grafana/grafanaInstaller PipelineDB sur Postgres
Sur une machine avec postgres, exécutez séquentiellement:
apt updateapt install curlcurl -s http://download.pipelinedb.com/apt.sh | bashapt install pipelinedb-postgresql-11cd /var/lib/postgresql/data- Ouvrez le fichier
postgresql.conf dans n'importe quel éditeur - Recherchez la clé
shared_preload_libraries , décommentez et définissez la valeur pipelinedb - Clé
max_worker_processes définie sur 128 (quais de recommandation) - Redémarrez le serveur
Création d'un flux et d'une vue dans PipelineDB
Après le redémarrage pg - regardez les journaux pour qu'il y ait une telle chose - La base de données dans laquelle nous travaillerons:
CREATE DATABASE testpipe; - Création d'une extension:
CREATE EXTENSION pipelinedb; - Maintenant, la chose la plus intéressante est de créer un flux. C'est en cela que vous devez ajouter des données pour un traitement ultérieur:
CREATE FOREIGN TABLE flow_stream ( dtmsk timestamp without time zone, action text, duration smallint ) SERVER pipelinedb;
En fait, c'est très similaire à la création d'une table ordinaire, vous ne pouvez pas simplement obtenir des données de ce flux avec une simple select - vous avez besoin d'une vue - en fait comment le créer:
CREATE VIEW viewflow WITH (ttl = '3 month', ttl_column = 'm') AS select minute(dtmsk) m, action, count(*), avg(duration)::smallint, min(duration), max(duration) from flow_stream group by 1, 2;
Elles sont appelées vues continues et se matérialisent par défaut, c'est-à-dire avec préservation de l'état.
La WITH transmet des paramètres supplémentaires.
Dans mon cas, ttl = '3 month' signifie que vous devez stocker les données uniquement pour les 3 derniers mois et prendre la date / heure de la colonne M Le processus de reaper arrière-plan reaper données obsolètes et les supprime.
Pour ceux qui ne sont pas au courant, la fonction minute renvoie une date / heure sans secondes. Ainsi, tous les événements qui se sont produits en une minute auront le même temps en raison de l'agrégation. - Une telle vue est presque une table, car l'index par date pour l'échantillonnage sera utile si beaucoup de données sont stockées
create index on viewflow (m desc, action);
Utilisation de PipelineDB
N'oubliez pas: insérez des données dans le flux et lisez à partir de la vue en vous y abonnant
insert into flow_stream VALUES (now(), 'act1', 21); insert into flow_stream VALUES (now(), 'act2', 33); select * from viewflow order by m desc, action limit 4; select now()
J'exécute la demande manuellement Je regarde d'abord comment les données changent à la 46e minute
Dès que la 47e arrive, la précédente cesse de se mettre à jour et la minute en cours commence à ticter.
Si vous faites attention au plan de requête, vous pouvez voir le tableau d'origine avec les données
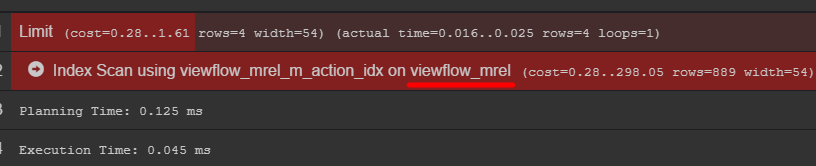
Je vous conseille d'y aller et de découvrir comment vos données sont réellement stockées
Générateur d'événements C # using Npgsql; using System; using System.Threading; namespace PipelineDbLogGenerator { class Program { private static Random _rnd = new Random(); private static string[] _actions = new string[] { "foo", "bar", "yep", "goal", "ano" }; static void Main(string[] args) { var connString = "Host=localhost;port=5432;Username=postgres;Database=testpipe"; using (var conn = new NpgsqlConnection(connString)) { conn.Open(); while (true) { var dt = DateTime.UtcNow; using (var cmd = new NpgsqlCommand()) { var act = GetAction(); cmd.Connection = conn; cmd.CommandText = "INSERT INTO flow_stream VALUES (@dtmsk, @action, @duration)"; cmd.Parameters.AddWithValue("dtmsk", dt); cmd.Parameters.AddWithValue("action", act); cmd.Parameters.AddWithValue("duration", GetDuration(act)); var res = cmd.ExecuteNonQuery(); Console.WriteLine($"{res} {dt}"); } Thread.Sleep(_rnd.Next(50, 230)); } } } private static int GetDuration(string act) { var c = 0; for (int i = 0; i < act.Length; i++) { c += act[i]; } return _rnd.Next(c); } private static string GetAction() { return _actions[_rnd.Next(_actions.Length)]; } } }
Conclusion à Grafana
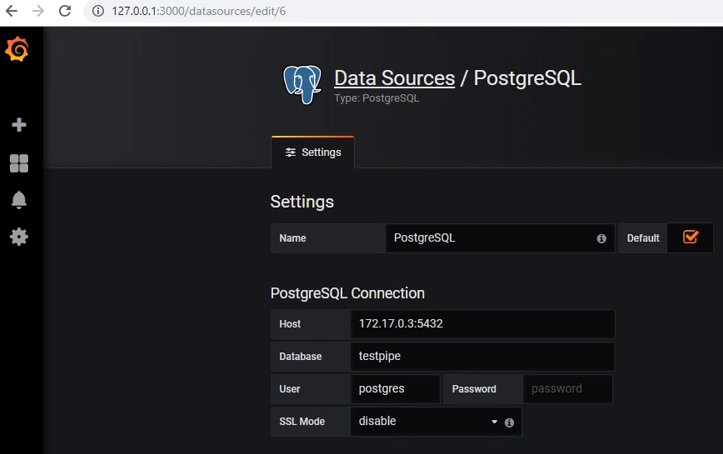
Pour obtenir des données de postgres, vous devez ajouter la source de données appropriée:
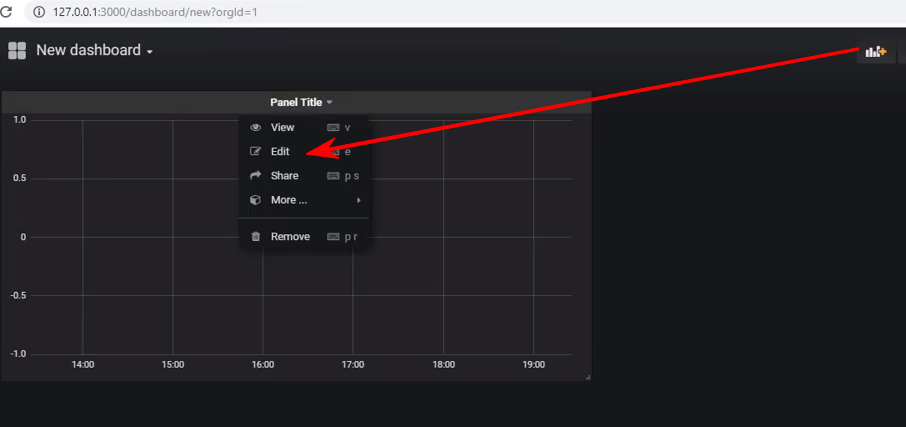
Créez un nouveau tableau de bord et ajoutez-y un panneau de type Graphique, et après cela, vous devez entrer dans l'édition du panneau:
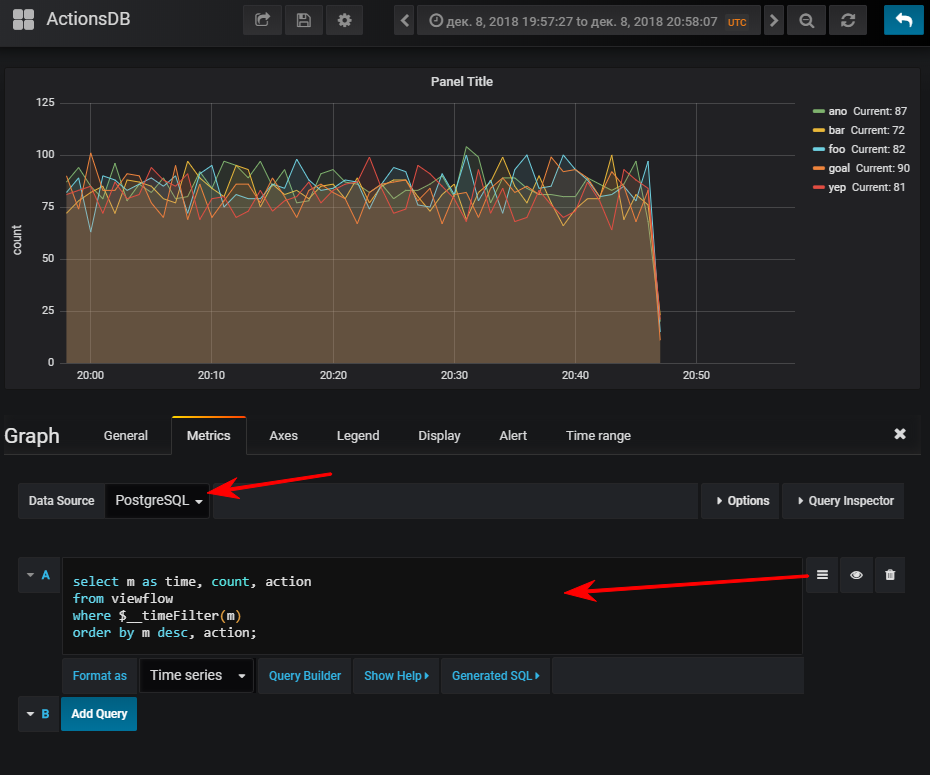
Ensuite - sélectionnez une source de données, passez en mode d'écriture sql-query et entrez ceci:
select m as time,
Et puis vous obtenez un horaire normal, bien sûr, si vous avez démarré le générateur d'événements
Pour info: avoir un indice peut être très important. Bien que son utilisation dépende du volume de la table résultante. Si vous prévoyez de stocker un petit nombre de lignes dans un court laps de temps, il peut très facilement s'avérer que le scan séquentiel sera moins cher et l'index n'en ajoutera que plus. charger lors de la mise à jour des valeurs
Plusieurs vues peuvent être abonnées à un flux.
Supposons que je veuille voir combien de méthodes api sont effectuées par les centiles
CREATE VIEW viewflow_per WITH (ttl = '3 d', ttl_column = 'm') AS select minute(dtmsk) m, action, percentile_cont(0.50) WITHIN GROUP (ORDER BY duration)::smallint p50, percentile_cont(0.95) WITHIN GROUP (ORDER BY duration)::smallint p95, percentile_cont(0.99) WITHIN GROUP (ORDER BY duration)::smallint p99 from flow_stream group by 1, 2; create index on viewflow_per (m desc);
Je fais le même tour avec grafana et j'obtiens: Total
En général, la chose fonctionne, elle s'est bien comportée, sans se plaindre. Bien que sous le docker, le téléchargement de leur base de données de démonstration dans l'archive (2,3 Go) s'est avéré être un peu long.
Je veux noter - je n'ai pas effectué de tests de résistance.
Documentation officiellePeut être intéressant