
Poursuivant nos articles avec des instructions pratiques sur la façon de faciliter la vie dans le travail quotidien avec Kubernetes, nous parlons de deux histoires du monde de l'exploitation: l'allocation de nœuds individuels pour des tâches spécifiques et la configuration de php-fpm (ou d'un autre serveur d'applications) pour des charges lourdes. Comme précédemment, les solutions décrites ici ne prétendent pas être idéales, mais sont proposées comme point de départ pour vos cas spécifiques et comme base de réflexion. Les questions et améliorations dans les commentaires sont les bienvenues!
1. L'allocation de nœuds individuels pour des tâches spécifiques
Nous élevons un cluster Kubernetes sur des serveurs virtuels, des clouds ou des serveurs bare metal. Si vous installez tous les logiciels système et applications client sur les mêmes nœuds, il est probable que des problèmes surviennent:
- l'application client commencera soudainement à «fuir» de la mémoire, bien que ses limites soient très élevées;
- les demandes ponctuelles complexes de loghouse, de Prométhée ou d'Ingress * mènent au MOO, par conséquent, l'application cliente souffre;
- une fuite de mémoire due à un bogue dans le logiciel système tue l'application cliente, bien que les composants ne soient pas logiquement connectés entre eux.
* Entre autres choses, il était pertinent pour les anciennes versions d'Ingress, quand en raison du grand nombre de connexions Websocket et des rechargements constants de nginx, des «processus nginx bloqués» sont apparus, qui se chiffraient à des milliers et consommaient une énorme quantité de ressources.Le vrai cas est l'installation de Prometheus avec un grand nombre de métriques, dans lesquelles lors de l'affichage du tableau de bord "lourd", où un grand nombre de conteneurs d'applications sont présentés, à partir de chacun desquels des graphiques sont dessinés, la consommation de mémoire est rapidement passée à ~ 15 Go. En conséquence, le tueur OOM pourrait «venir» sur le système hôte et commencer à tuer d'autres services, ce qui à son tour a conduit à «un comportement incompréhensible des applications dans le cluster». Et en raison de la charge élevée du processeur sur l'application cliente, il est facile d'obtenir un temps de traitement de requête Ingst instable ...
La solution s'est rapidement imposée: il a fallu allouer des machines individuelles pour différentes tâches. Nous avons identifié 3 principaux types de groupes de travail:
- Fronts , où nous ne mettons que des entrées, pour être sûr qu'aucun autre service ne peut affecter le temps de traitement des demandes;
- Noeuds système sur lesquels nous déployons des VPN , loghouse , Prometheus , Dashboard, CoreDNS, etc.;
- Noeuds pour les applications - en fait, où les applications clientes se déploient. Ils peuvent également être alloués pour des environnements ou des fonctionnalités: dev, prod, perf, ...
Solution
Comment mettons-nous cela en œuvre? Très simple: deux mécanismes natifs de Kubernetes. Le premier est
nodeSelector pour sélectionner le nœud souhaité où l'application doit aller, qui est basé sur les étiquettes
installées sur chaque nœud.
Disons que nous avons un nœud
kube-system-1 . Nous y ajoutons une étiquette supplémentaire:
$ kubectl label node kube-system-1 node-role/monitoring=
... et dans
Deployment , qui devrait être déployé sur ce nœud, nous écrivons:
nodeSelector: node-role/monitoring: ""
Le deuxième mécanisme est les
souillures et les tolérances . Avec son aide, nous indiquons explicitement que sur ces machines, seuls les conteneurs pouvant être tolérés à cette souillure peuvent être lancés.
Par exemple, il existe une machine
kube-frontend-1 sur laquelle nous roulerons uniquement Ingress. Ajoutez de la souillure à ce nœud:
$ kubectl taint node kube-frontend-1 node-role/frontend="":NoExecute
... et au
Deployment nous créons la tolérance:
tolerations: - effect: NoExecute key: node-role/frontend
Dans le cas de kops, des groupes d'instances individuels peuvent être créés pour les mêmes besoins:
$ kops create ig --name cluster_name IG_NAME
... et vous obtenez quelque chose comme cette configuration de groupe d'instances dans kops:
apiVersion: kops/v1alpha2 kind: InstanceGroup metadata: creationTimestamp: 2017-12-07T09:24:49Z labels: dedicated: monitoring kops.k8s.io/cluster: k-dev.k8s name: monitoring spec: image: kope.io/k8s-1.8-debian-jessie-amd64-hvm-ebs-2018-01-14 machineType: m4.4xlarge maxSize: 2 minSize: 2 nodeLabels: dedicated: monitoring role: Node subnets: - eu-central-1c taints: - dedicated=monitoring:NoSchedule
Ainsi, les nœuds de ce groupe d'instances ajouteront automatiquement une étiquette et une coloration supplémentaires.
2. Configuration de php-fpm pour les charges lourdes
Il existe une grande variété de serveurs qui sont utilisés pour exécuter des applications Web: php-fpm, gunicorn et similaires. Leur utilisation dans Kubernetes signifie qu'il y a plusieurs choses auxquelles vous devez toujours penser:
- Il est nécessaire de comprendre approximativement combien de travailleurs nous sommes disposés à allouer en php-fpm dans chaque conteneur. Par exemple, nous pouvons allouer 10 employés pour traiter les demandes entrantes, allouer moins de ressources pour le pod et évoluer en utilisant le nombre de pods - c'est une bonne pratique. Un autre exemple est d'allouer 500 travailleurs pour chaque pod et d'avoir 2-3 de tels pods en production ... mais c'est une assez mauvaise idée.
- Des tests de vivacité / de préparation sont nécessaires pour vérifier le bon fonctionnement de chaque module et dans le cas où le module est «bloqué» en raison de problèmes de réseau ou en raison de l'accès à la base de données (il peut y avoir l'une de vos options et la raison). Dans de telles situations, vous devez recréer le module problématique.
- Il est important d'enregistrer explicitement la demande et de limiter les ressources pour chaque conteneur afin que l'application ne "coule" pas et ne commence pas à endommager tous les services sur ce serveur.
Des solutions
Malheureusement,
il n'y a pas de solution miracle qui vous aide à comprendre immédiatement de combien de ressources (CPU, RAM) une application peut avoir besoin. Une option possible est de surveiller la consommation des ressources et de sélectionner à chaque fois les valeurs optimales. Afin d'éviter les kill'ov OOM injustifiés et la limitation du processeur, qui affectent considérablement le service, vous pouvez proposer:
- ajoutez les tests de vivacité / préparation corrects afin que nous puissions dire avec certitude que ce conteneur fonctionne correctement. Il s'agit très probablement d'une page de service qui vérifie la disponibilité de tous les éléments d'infrastructure (nécessaires pour que l'application fonctionne dans le pod) et renvoie un code de réponse 200 OK;
- sélectionner correctement le nombre de travailleurs qui traiteront les demandes et les répartir correctement.
Par exemple, nous avons 10 pods qui se composent de deux conteneurs: nginx (pour envoyer des requêtes statiques et proxy au backend) et php-fpm (en fait le backend, qui traite les pages dynamiques). Le pool Php-fpm est configuré pour un nombre statique de travailleurs (10). Ainsi, dans une unité de temps, nous pouvons traiter 100 requêtes actives vers les backends. Laissez chaque requête être traitée par PHP en 1 seconde.
Que se passe-t-il si 1 demande supplémentaire arrive dans un module spécifique, dans lequel 10 demandes sont actuellement activement traitées? PHP ne pourra pas le traiter et Ingress l'enverra pour réessayer vers le pod suivant s'il s'agit d'une requête GET. S'il y avait une demande POST, il retournera une erreur.
Et si nous prenons en compte que lors du traitement des 10 demandes, nous recevrons un chèque de kubelet (sonde de vivacité), il échouera et Kubernetes commencera à penser que quelque chose ne va pas avec ce conteneur, et le tuera. Dans ce cas, toutes les demandes qui ont été traitées actuellement se termineront par une erreur (!) Et au moment du redémarrage du conteneur, il sera déséquilibré, ce qui entraînera une augmentation des demandes pour tous les autres backends.
Clairement
Supposons que nous ayons 2 pods qui ont chacun 10 travailleurs php-fpm configurés. Voici un graphique qui affiche des informations pendant le «temps d'arrêt», c'est-à-dire lorsque le seul qui demande php-fpm est l'exportateur php-fpm (nous avons chacun un travailleur actif):
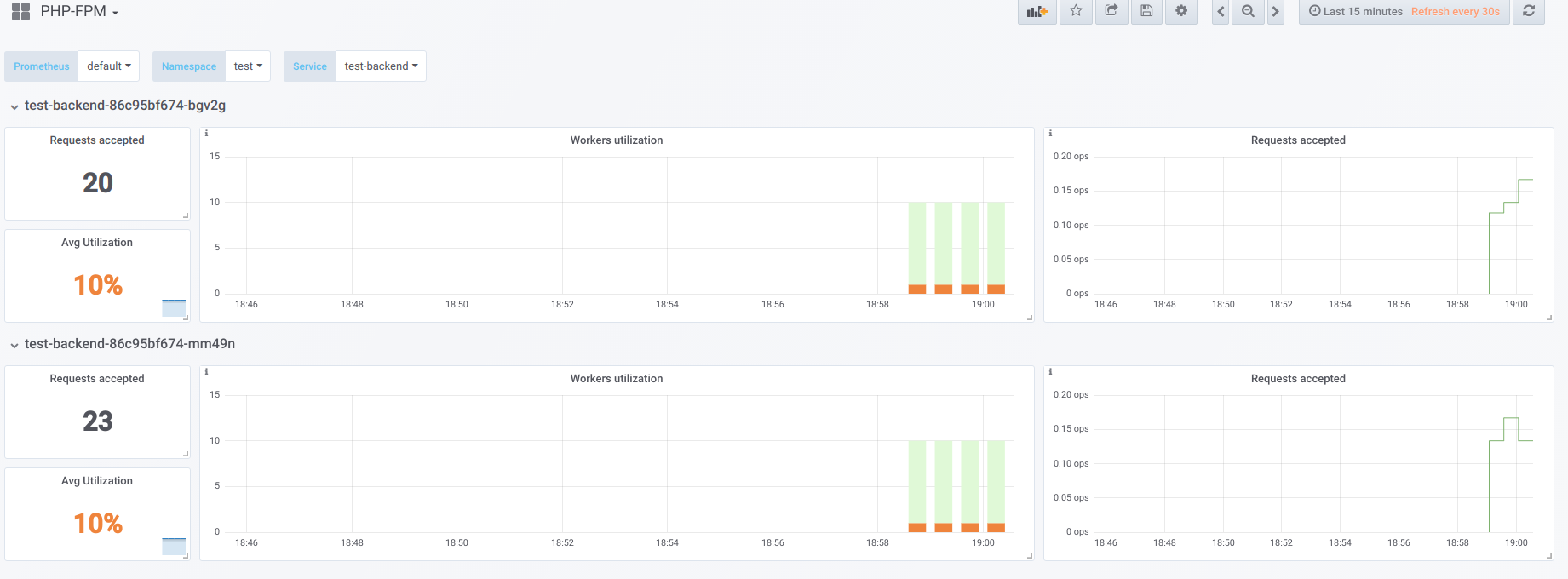
Maintenant, démarrez le démarrage avec la concurrence 19:
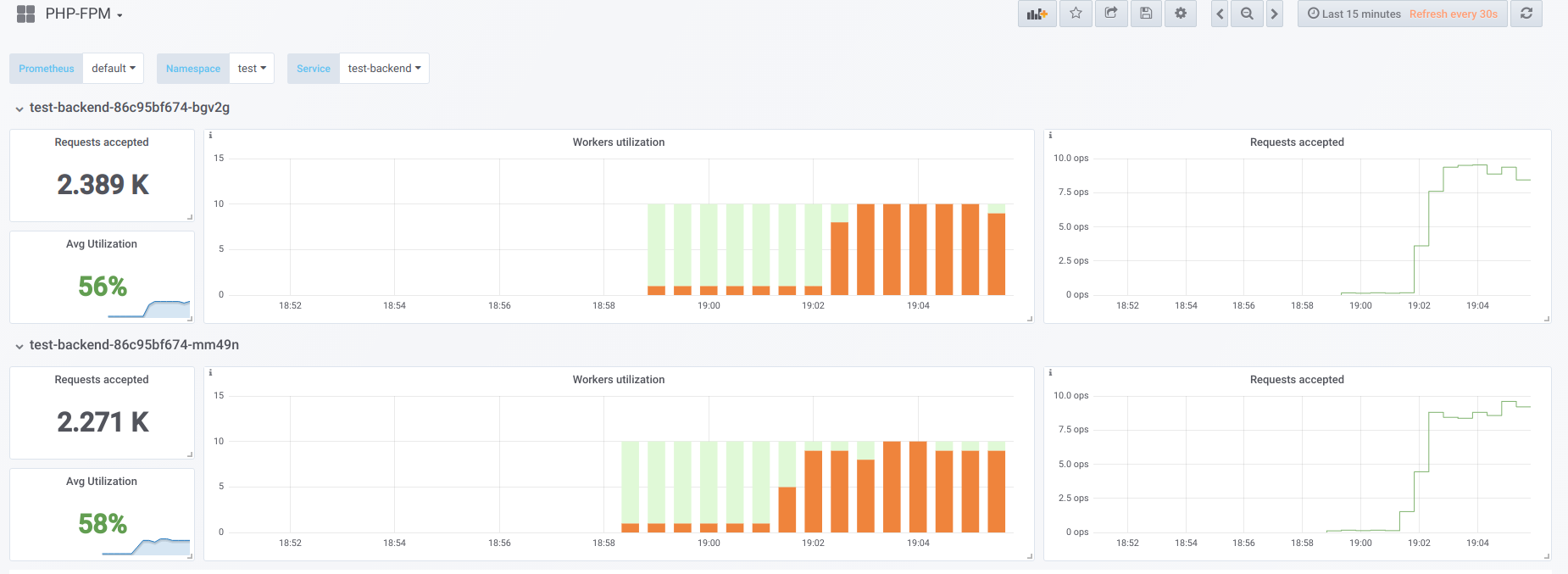
Essayons maintenant de rendre la concurrence supérieure à ce que nous pouvons gérer (20) ... disons 23. Ensuite, tous les employés de php-fpm sont occupés à traiter les demandes des clients:

Les vorkers ne suffisent plus pour traiter un échantillon de vivacité, nous voyons donc cette image dans le tableau de bord Kubernetes (ou
describe pod ):

Maintenant, lorsque l'un des pods redémarre, un
effet d'avalanche se produit : les demandes commencent à tomber sur le deuxième pod, qui n'est pas non plus en mesure de les traiter, ce qui nous fait recevoir un grand nombre d'erreurs de la part des clients. Une fois que les piscines de tous les conteneurs sont pleines, l'augmentation du service est problématique - cela n'est possible que par une forte augmentation du nombre de pods ou de travailleurs.
Première option
Dans un conteneur avec PHP, vous pouvez configurer 2 pools fpm: l'un pour le traitement des demandes des clients, l'autre pour vérifier la «capacité de survie» du conteneur. Ensuite, sur le conteneur nginx, vous devrez effectuer une configuration similaire:
upstream backend { server 127.0.0.1:9000 max_fails=0; } upstream backend-status { server 127.0.0.1:9001 max_fails=0; }
Il ne reste plus qu'à envoyer l'échantillon de vivacité pour traitement à l'amont appelé
backend-status .
Maintenant que la sonde de vivacité est traitée séparément, des erreurs se produiront toujours pour certains clients, mais au moins aucun problème n'est associé au redémarrage du pod et à la déconnexion d'autres clients. Ainsi, nous réduirons considérablement le nombre d'erreurs, même si nos backends ne peuvent pas faire face à la charge actuelle.
Cette option est certainement meilleure que rien, mais elle est également mauvaise car quelque chose peut arriver au pool principal, que nous n'apprendrons pas à utiliser le test de vivacité.
Deuxième option
Vous pouvez également utiliser le module nginx peu populaire appelé
nginx-limit-upstream . Ensuite, en PHP, nous spécifierons 11 travailleurs, et dans le conteneur avec nginx, nous ferons une configuration similaire:
limit_upstream_zone limit 32m; upstream backend { server 127.0.0.1:9000 max_fails=0; limit_upstream_conn limit=10 zone=limit backlog=10 timeout=5s; } upstream backend-status { server 127.0.0.1:9000 max_fails=0; }
Au niveau du frontend, nginx limitera le nombre de requêtes qui seront envoyées au backend (10). Un point intéressant est qu'un backlog spécial est créé: si le client reçoit la 11ème requête pour nginx, et nginx voit que le pool php-fpm est occupé, alors cette requête est placée dans le backlog pendant 5 secondes. Si, pendant ce temps, php-fpm ne s'est pas libéré, alors seulement Ingress entrera en action, qui réessayera la demande vers un autre pod. Cela lisse l'image, car nous aurons toujours 1 travailleur PHP gratuit pour traiter un échantillon de vivacité - nous pouvons éviter l'effet d'avalanche.
Autres pensées
Pour des options plus polyvalentes et plus belles pour résoudre ce problème, il vaut la peine de chercher dans la direction d'
Envoy et de ses analogues.
En général, afin que Prometheus ait un emploi clair des travailleurs, ce qui à son tour aidera à trouver rapidement le problème (et à le notifier), je recommande fortement d'obtenir des
exportateurs prêts à l'emploi pour convertir les données du logiciel au format Prometheus.
PS
Autres du cycle de trucs et astuces de K8:
Lisez aussi dans notre blog: