
Chaque jour, un million et demi de personnes recherchent Ozon pour une variété de produits, et pour chacun d'eux, le service doit sélectionner des produits similaires (si l'aspirateur en a encore besoin d'un plus puissant) ou des produits connexes (si des piles sont nécessaires pour le dinosaure chantant). Lorsqu'il existe trop de types de produits, le modèle Word2Vec aide à résoudre le problème. Nous comprenons comment cela fonctionne et comment créer des représentations vectorielles pour des objets arbitraires.
La motivation
Pour construire et former le modèle, nous utilisons la technique d'intégration, standard pour l'apprentissage automatique, lorsque chaque objet se transforme en vecteur de longueur fixe, et que les vecteurs proches correspondent aux objets proches. Presque tous les modèles connus nécessitent que les données d'entrée soient d'une longueur fixe, et un ensemble de vecteurs est un moyen facile de les amener sous cette forme.
Word2vec est l'une des premières méthodes d'intégration. Nous avons adapté cette méthode à notre tâche, nous utilisons les produits comme mots et les sessions utilisateurs comme phrases. Si tout est clair pour vous, n'hésitez pas à parcourir les résultats.
Je parlerai ensuite de l'architecture du modèle et de son fonctionnement. Étant donné que nous traitons des marchandises, nous devons apprendre à en construire de telles descriptions qui, d'une part, contiennent suffisamment d'informations et, d'autre part, sont compréhensibles pour l'algorithme d'apprentissage automatique.
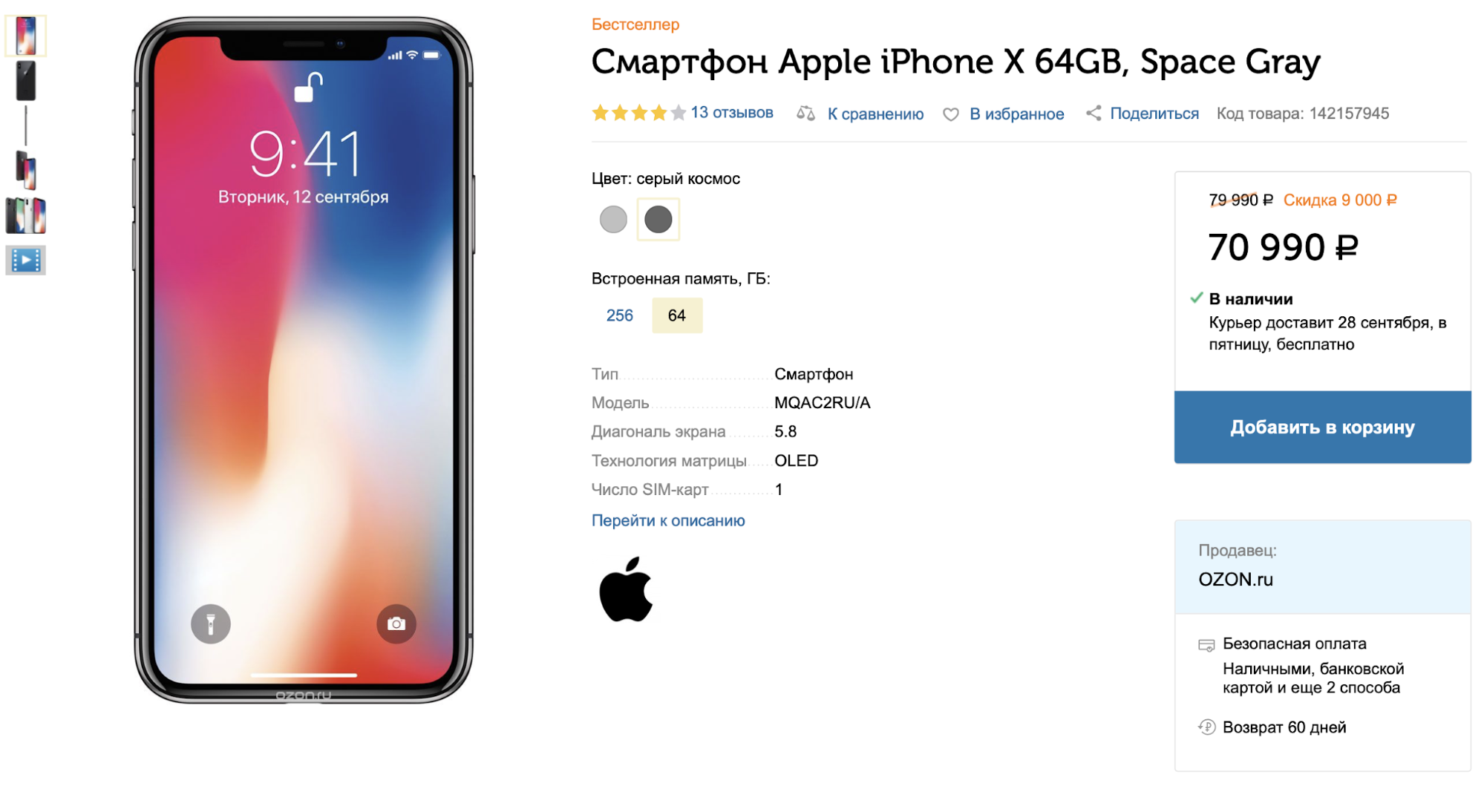
Sur le site, chaque produit a une carte. Il se compose d'un titre, d'une description textuelle, de spécifications et de photographies. Nous disposons également de données sur l'interaction des utilisateurs avec le produit: les vues, l'ajout au panier ou les favoris sont stockés dans les journaux.
Il existe deux façons fondamentalement différentes de construire une description vectorielle d'un produit:
- utiliser le contenu - réseaux de neurones convolutifs pour extraire des caractéristiques de photos, de réseaux récurrents ou d'un sac de mots pour analyser une description de texte;
- utilisation des données sur les interactions des utilisateurs avec le produit: quels produits et à quelle fréquence ils regardent / ajoutent au panier avec les données.
Nous nous concentrerons sur la deuxième méthode.
Données pour le modèle Prod2Vec
Voyons d'abord quelles données nous utilisons. Nous avons à notre disposition tous les clics des utilisateurs sur le site, ils peuvent être divisés en sessions utilisateurs - séquences de clics avec des intervalles ne dépassant pas 30 minutes entre les clics adjacents. Pour former le modèle, nous utilisons des données d'environ 100 millions de sessions utilisateur, dans chacune desquelles nous ne sommes intéressés que par la visualisation et l'ajout de produits au panier.
Un exemple d'une vraie session utilisateur:

Chaque produit de la session correspond à son contexte - tous les produits que l'utilisateur a ajoutés au panier dans cette session, ainsi que les produits qui sont visualisés avec cela. Le modèle prod2vec est basé sur l'hypothèse que les produits similaires ont le plus souvent des contextes similaires.
Par exemple:

Ainsi, si l'hypothèse est vraie, alors, par exemple, les cas pour le même modèle de téléphone auront des contextes similaires (le même téléphone). Nous testerons cette hypothèse en construisant des vecteurs produits.
Modèle Prod2Vec
Lorsque nous avons introduit les concepts d'un produit et son contexte, nous décrivons le modèle lui-même. Il s'agit d'un réseau neuronal avec deux couches entièrement connectées. Le nombre d'entrées de la première couche est égal au nombre de produits pour lesquels nous voulons construire des vecteurs. Chaque produit à l'entrée sera encodé par un vecteur de zéros avec une seule unité - la place de ce produit dans le dictionnaire.
Le nombre de neurones en sortie de la première couche est égal à la dimension des vecteurs que nous voulons obtenir, par exemple 64. En sortie de la dernière couche, là encore, il y a un nombre de neurones égal au nombre de marchandises.

Nous formerons le modèle pour prédire le contexte, connaissant le produit. Cette architecture est appelée Skip-gram (son alternative est CBOW, où nous prédisons le produit en fonction de son contexte). Pendant la formation, les marchandises sont livrées à l'entrée, les marchandises devraient être sorties de leur contexte (un vecteur de zéros avec une unité à l'endroit correspondant).
Il s'agit essentiellement d'une classification multiclasse et la perte d'entropie croisée peut être utilisée pour entraîner le modèle. Pour une paire mot-mot du contexte, il s'écrit comme suit:
L=−pc+ log sumVi=1exp(pi)
où pc - prédiction du réseau du produit à partir du contexte, V - le nombre total de marchandises pi - prédiction réseau pour le produit i .
Après avoir entraîné le modèle, nous pouvons jeter la deuxième couche - elle ne sera pas nécessaire pour obtenir des vecteurs. La matrice des poids de la première couche (taille du nombre de marchandises x 64) est un dictionnaire de vecteurs de marchandises. Chaque produit correspond à une ligne d'une matrice de longueur 64 - c'est le vecteur correspondant au produit, qui peut être utilisé dans d'autres algorithmes.
Mais cette procédure ne fonctionne pas pour un grand nombre de produits. Et nous en avons, rappelons-le, un million et demi.
Pourquoi Prod2Vec ne fonctionne pas
- La fonction de perte contient de nombreuses opérations de prise de l'exposant - il s'agit d'un calcul long et instable.
- En conséquence, les gradients sont pris en compte pour tous les poids du réseau - et il peut y en avoir des dizaines de millions.
Pour résoudre ces problèmes, la méthode d'échantillonnage négatif est appropriée, en utilisant laquelle nous enseignons au réseau non seulement à prédire le contexte du produit, mais aussi à ne pas prédire les produits qui ne sont pas exactement dans le contexte. Pour ce faire, nous devons générer des exemples négatifs - pour chaque produit, sélectionnez ceux qui n'ont pas besoin d'être prédits pour lui. Et ici, la disponibilité d'une énorme quantité de marchandises nous aide. Lors du choix d'une paire aléatoire pour un produit, nous avons une très faible probabilité que ce soit un produit du contexte.
Par conséquent, pour chaque produit dans le contexte, nous générons au hasard 5 à 10 produits qui ne sont pas inclus dans le contexte. De plus, les marchandises ne sont pas échantillonnées selon une distribution uniforme, mais proportionnellement à la fréquence de leur occurrence.
La fonction de perte est maintenant similaire à celle utilisée dans la classification binaire. Pour une paire mot-mot, du contexte, cela ressemble à ceci:
L=− log sigma(uTwOvwI)− sumwn log sigma(−uTwnvwI)
Dans ces notations uwO désigne une colonne de la matrice de poids de la deuxième couche correspondant au produit du contexte, uwn - la même chose pour un produit sélectionné au hasard, vwI - la ligne de la matrice de poids de la première couche correspondant au produit principal (c'est exactement le vecteur que nous construisons pour lui). Fonction sigma(x)= frac11+exp(−x) .
La différence avec la version précédente est que nous n'avons pas besoin de mettre à jour tous les poids du réseau à chaque itération, nous avons seulement besoin de mettre à jour ceux qui correspondent à un petit nombre de produits (le premier produit est celui pour lequel nous prédisons, le reste est soit un produit de son contexte, soit sélectionné au hasard ) Dans le même temps, nous nous sommes débarrassés d'un grand nombre de captures exponentielles à chaque itération.
Une autre technique, qui à son tour améliore la qualité du modèle résultant, est le sous-échantillonnage. Dans ce cas, nous prenons intentionnellement des biens moins fréquemment trouvés pour la formation afin d'obtenir le meilleur résultat pour les biens rares.
Résultats
Produits associés
Nous avons donc appris à obtenir des vecteurs pour les marchandises, nous devons maintenant vérifier l'adéquation et l'applicabilité de notre modèle.
L'image suivante montre le produit et ses voisins les plus proches dans la mesure du cosinus de proximité.
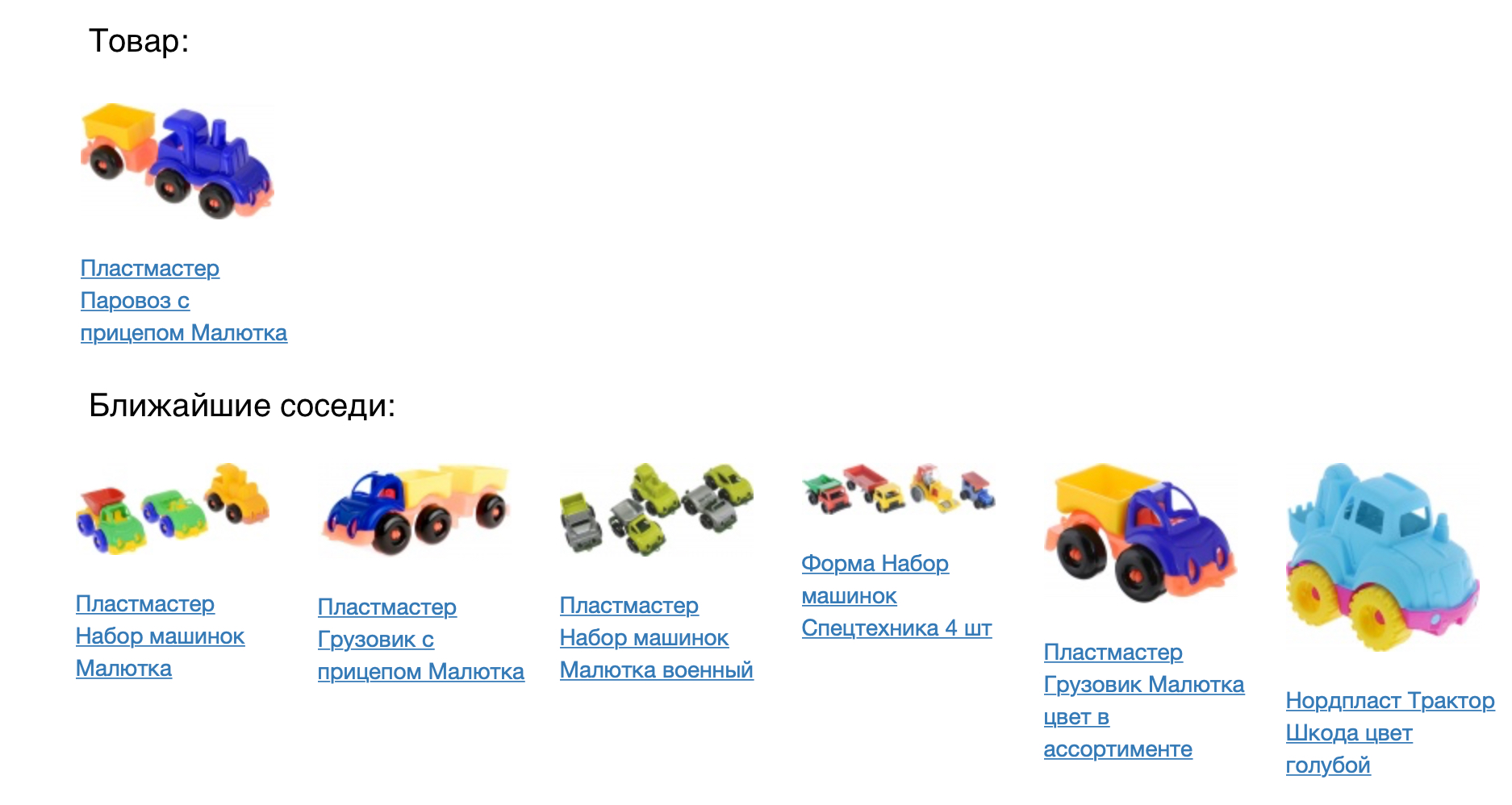
Le résultat semble bon, mais vous devez vérifier numériquement la qualité de notre modèle. Pour ce faire, nous l'avons appliqué à la tâche de recommandations de produits. Pour chaque produit, nous avons recommandé de venir dans un espace vectoriel construit. Nous avons comparé le modèle prod2vec avec un modèle beaucoup plus simple, basé sur des statistiques de vues conjointes et en ajoutant des articles au panier. Pour chaque produit de la session, une liste de 7 recommandations a été prise. La combinaison de tous les produits recommandés au cours de la session a été comparée à ce qu'une personne a réellement ajouté au panier. En utilisant prod2vec, dans plus de 40% des sessions, nous avons recommandé au moins un produit, qui a ensuite été ajouté au panier. A titre de comparaison, un algorithme plus simple montre une qualité de 34%.
La description vectorielle qui en résulte nous permet non seulement de rechercher les plus proches (ce qui peut être fait par un modèle plus simple, mais avec une qualité moindre). Nous pouvons considérer quels effets secondaires intéressants peuvent être montrés en utilisant notre modèle.
Arithmétique vectorielle
Pour illustrer que les vecteurs portent la vraie signification des biens, nous pouvons essayer d'utiliser l'arithmétique vectorielle pour eux. Comme dans l'exemple de manuel sur word2vec (roi - homme + femme = reine), par exemple, nous pouvons nous demander quel produit est approximativement à la même distance de l'imprimante que le sac à poussière de l'aspirateur. Le bon sens veut qu'il s'agisse d'une sorte de consommable, à savoir une cartouche. Notre modèle est capable d'attraper de tels modèles:

Visualisation de l'espace produit
Pour mieux comprendre les résultats, nous pouvons visualiser l'espace vectoriel des marchandises dans l'avion, en réduisant la dimension à deux (dans cet exemple, nous avons utilisé t-SNE).

On voit clairement que les produits connexes forment des grappes. Par exemple, des grappes avec des textiles pour la chambre, des vêtements masculins et féminins, des chaussures sont clairement visibles. Encore une fois, nous notons que ce modèle est construit uniquement sur la base de l'historique des interactions des utilisateurs avec les biens; nous n'avons pas utilisé la similitude des images ou des descriptions de texte lors de la formation.
À partir de l'illustration de l'espace, vous pouvez également voir comment, à l'aide du modèle, vous pouvez sélectionner des accessoires pour les marchandises. Pour ce faire, vous devez prendre des marchandises du cluster le plus proche, par exemple, recommander des articles de sport pour les T-shirts et des casquettes pour les pulls chauds.
Plans
Nous introduisons maintenant le modèle prod2vec en production pour calculer les recommandations de produits. De plus, les vecteurs obtenus peuvent être utilisés comme fonctionnalités pour d'autres algorithmes d'apprentissage automatique dans lesquels notre équipe est engagée (prévision de la demande de produits, classement dans la recherche et les catalogues, recommandations personnelles).
À l'avenir, nous prévoyons de mettre en œuvre les intégrations reçues sur le site en temps réel. Pour toutes les marchandises vues, les prochaines seront dans la session, qui se refléteront instantanément dans la livraison personnalisée. Nous prévoyons également d'intégrer l'analyse d'images et l'analyse de similarité selon la description du vecteur dans notre modèle, ce qui améliorera considérablement la qualité des vecteurs résultants.
Si vous savez comment le faire au mieux (ou le refaire) - venez visiter (et encore mieux travailler).
Références:
- Mikolov, Tomas et al. "Représentations distribuées des mots et des phrases et leur compositionnalité." Progrès dans les systèmes de traitement de l'information neuronale. 2013.
- Grbovic, Mihajlo et al. "E-commerce dans votre boîte de réception: recommandations de produits à grande échelle." Actes de la 21e conférence internationale ACM SIGKDD sur la découverte des connaissances et l'exploration de données. ACM, 2015.
- Grbovic, Mihajlo et Haibin Cheng. "Personnalisation en temps réel à l'aide des intégrations pour le classement de recherche sur Airbnb." Actes de la 24e conférence internationale ACM SIGKDD sur la découverte des connaissances et l'exploration de données. ACM, 2018.