Chez Rostelecom, nous utilisons Hadoop pour stocker et traiter les données téléchargées à partir de plusieurs sources à l'aide d'applications Java. Nous sommes maintenant passés à une nouvelle version de hadoop avec l'authentification Kerberos. Lors du déménagement, j'ai rencontré un certain nombre de problèmes, notamment l'utilisation de l'API YARN. Le travail de Hadoop avec Kerberos Authentication mérite un article séparé, mais dans cet article, nous parlerons du débogage de Hadoop MapReduce.

Lors de l'exécution de tâches dans le cluster, le démarrage du débogueur est compliqué par le fait que nous ne savons pas quel nœud traitera telle ou telle partie des données d'entrée, et nous ne pouvons pas configurer notre débogueur à l'avance.
Vous pouvez utiliser le
System.out.println("message") éprouvé par le temps
System.out.println("message") . Mais comment analyser la sortie de
System.out.println("message") dispersée sur ces nœuds?
Nous pouvons envoyer des messages au flux d'erreur standard. Tout écrit en stdout ou stderr,
envoyé dans le fichier journal approprié, qui se trouve sur la page Web d'informations sur les tâches étendues ou dans les fichiers journaux.
Nous pouvons également inclure des outils de débogage dans notre code, mettre à jour les messages d'état des tâches et utiliser des compteurs personnalisés pour nous aider à comprendre l'ampleur de la catastrophe.
L'application Hadoop MapReduce peut être déboguée dans les trois modes dans lesquels Hadoop peut fonctionner:
- autonome
- mode pseudo-distribué
- entièrement distribué
Plus en détail, nous nous concentrerons sur les deux premiers.
Mode pseudo-distribué
Le mode pseudo-distribué est utilisé pour simuler un véritable cluster. Et il peut être utilisé pour tester dans un environnement aussi proche que productif que possible. Dans ce mode, tous les démons Hadoop fonctionneront sur un seul nœud!
Si vous avez un serveur de développement ou un autre bac à sable (par exemple, une machine virtuelle avec un environnement de développement personnalisé, comme Hortonworks Sanbox avec HDP), vous pouvez déboguer le programme de contrôle à l'aide d'outils de débogage à distance.
Pour démarrer le débogage, vous devez définir la valeur de la variable d'environnement:
YARN_OPTS . Voici un exemple. Pour plus de commodité, vous pouvez créer le fichier startWordCount.sh et y ajouter les paramètres nécessaires pour lancer l'application.
Maintenant, en exécutant le script
`./startWordCount.sh` , nous verrons un message
Listening for transport dt_socket at address: 6000
Il reste à configurer l'IDE pour le débogage à distance. J'utilise intellij IDEA. Allez dans le menu Exécuter -> Modifier les configurations ... Ajouter une nouvelle configuration à
Remote .
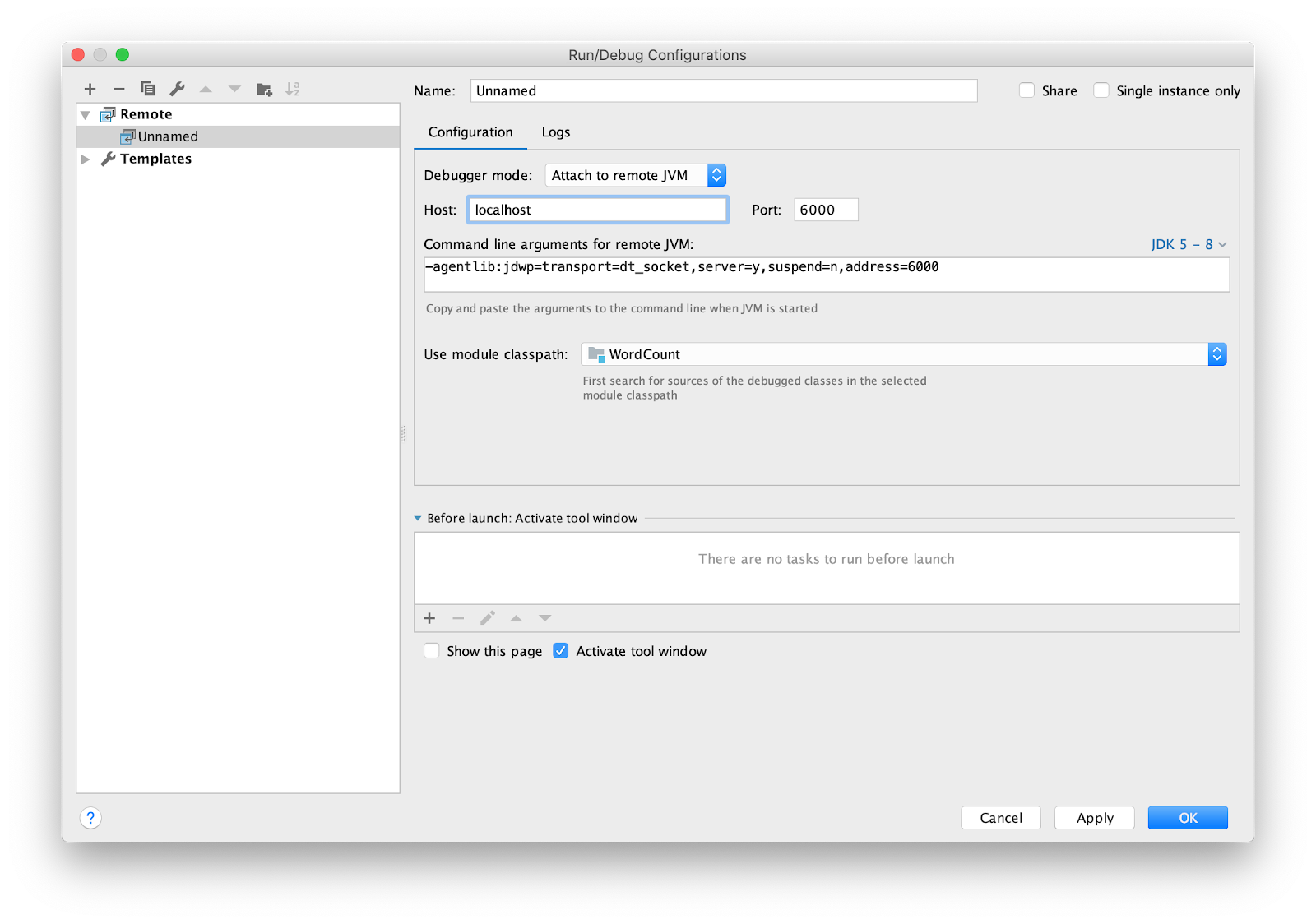
Définissez le point d'arrêt sur principal et exécutez.
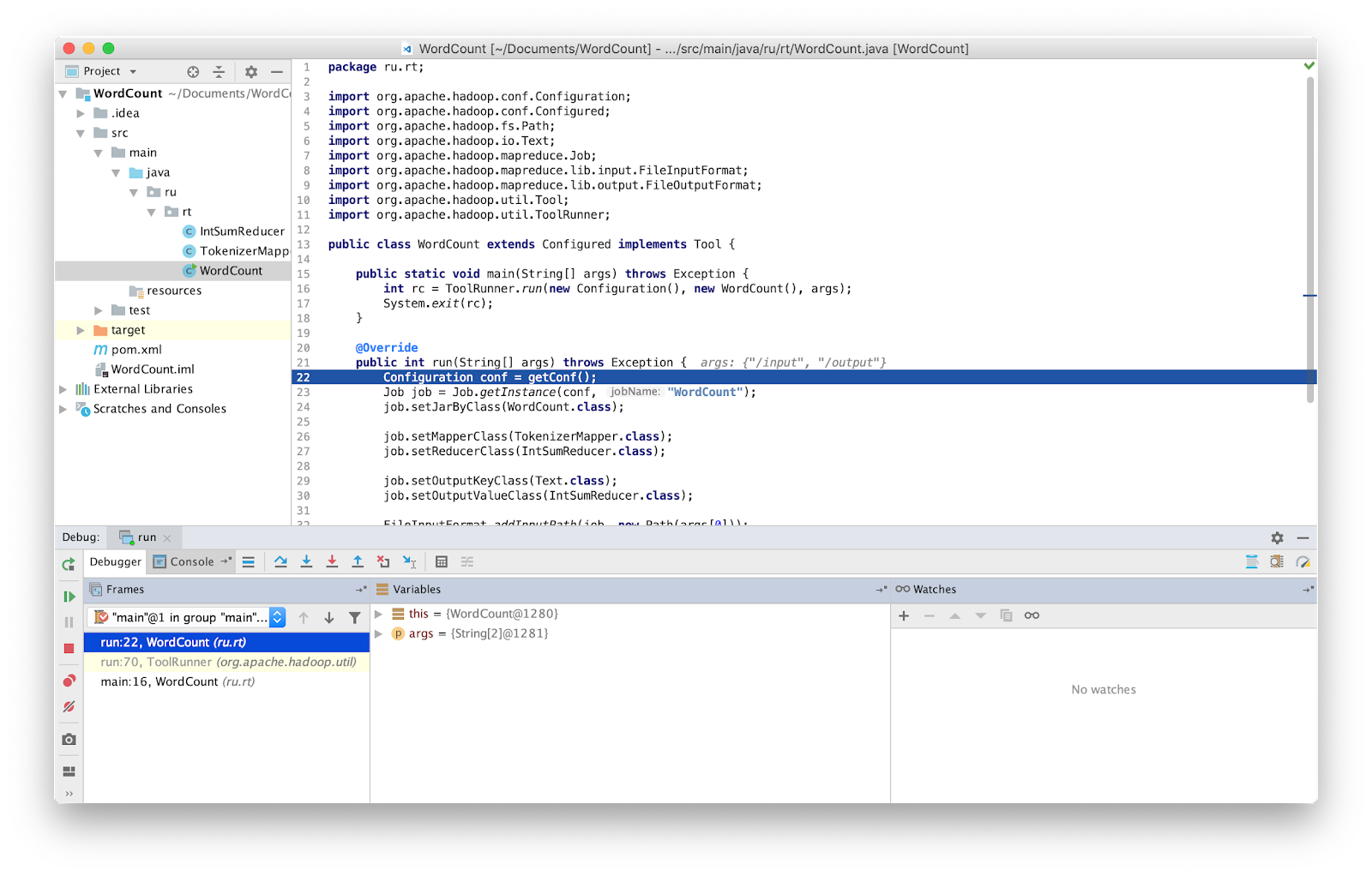
Voilà, maintenant nous pouvons déboguer le programme comme d'habitude.
ATTENTION Vous devez vous assurer que vous travaillez avec la dernière version du code source. Sinon, vous pouvez avoir des différences dans les lignes où le débogueur s'arrête.
Dans les versions antérieures de Hadoop, une classe spéciale était fournie qui vous permettait de redémarrer une tâche ayant échoué - isolationRunner. Les données à l'origine de l'échec ont été enregistrées sur le disque à l'adresse indiquée dans la variable d'environnement Hadoop mapred.local.dir. Malheureusement, dans les versions récentes de Hadoop, cette classe n'est plus fournie.
Autonome (démarrage local)
Autonome est le mode standard dans lequel Hadoop fonctionne. Il convient au débogage où HDFS n'est pas utilisé. Avec un tel débogage, vous pouvez utiliser l'entrée et la sortie via le système de fichiers local. Le mode autonome est généralement le mode Hadoop le plus rapide car il utilise le système de fichiers local pour toutes les données d'entrée et de sortie.
Comme mentionné précédemment, vous pouvez injecter des outils de débogage dans votre code, tels que des compteurs. Les compteurs sont définis par l'
énumération Java. Le nom d'énumération définit le nom du groupe et les champs d'énumération déterminent les noms des compteurs. Un compteur peut être utile pour évaluer un problème,
et peut être utilisé en complément de la sortie de débogage.
Déclaration et utilisation du compteur:
package ru.rt.example; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class Map extends Mapper<LongWritable, Text, Text, IntWritable> { private Text word = new Text(); enum Word { TOTAL_WORD_COUNT, } @Override public void map(LongWritable key, Text value, Context context) { String[] stringArr = value.toString().split("\\s+"); for (String str : stringArr) { word.set(str); context.getCounter(Word.TOTAL_WORD_COUNT).increment(1); } } } }
Pour incrémenter le compteur, utilisez la méthode
increment(1) .
... context.getCounter(Word.TOTAL_WORD_COUNT).increment(1); ...
Une fois MapReduce terminé, la tâche affiche les compteurs à la fin.
Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 ru.rt.example.Map$Word TOTAL_WORD_COUNT=655
Des données erronées peuvent être sorties vers stderr ou stdout, ou pour écrire des sorties vers hdfs en utilisant la classe
MultipleOutputs pour une analyse plus approfondie. Les données reçues peuvent être transmises à l'entrée de l'application en mode autonome ou lors de l'écriture de tests unitaires.
Hadoop possède la bibliothèque MRUnit, qui est utilisée en conjonction avec les frameworks de test (par exemple JUnit). Lors de l'écriture de tests unitaires, nous vérifions que la fonction produit le résultat attendu en sortie. Nous utilisons la classe MapDriver du package MRUnit, dans les propriétés desquelles nous définissons la classe testée. Pour ce faire, utilisez la méthode
withMapper() , les valeurs d'entrée
withInputValue() et le résultat attendu
withOutput() ou
withMultiOutput() si plusieurs sorties sont utilisées.
Voici notre test.
package ru.rt.example; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mrunit.mapreduce.MapDriver; import org.apache.hadoop.mrunit.types.Pair; import org.junit.Before; import org.junit.Test; import java.io.IOException; public class TestWordCount { private MapDriver<Object, Text, Text, IntWritable> mapDriver; @Before public void setUp() { Map mapper = new Map(); mapDriver.setMapper(mapper) } @Test public void mapperTest() throws IOException { mapDriver.withInput(new LongWritable(0), new Text("msg1")); mapDriver.withOutput(new Pair<Text, IntWritable>(new Text("msg1"), new IntWritable(1))); mapDriver.runTest(); } }
Mode entièrement distribué
Comme son nom l'indique, il s'agit d'un mode dans lequel toute la puissance de Hadoop est utilisée. Le programme MapReduce lancé peut fonctionner sur 1000 serveurs. Il est toujours difficile de déboguer le programme MapReduce, car vous avez des mappeurs exécutés sur différentes machines avec différentes données d'entrée.
Conclusion
Il s'est avéré que tester MapReduce n'est pas aussi simple qu'il y paraît à première vue.
Pour gagner du temps à rechercher des erreurs dans MapReduce, j'ai utilisé toutes les méthodes énumérées ci-dessus et je conseille à tout le monde de les appliquer également. Cela est particulièrement utile dans le cas de grandes installations, telles que celles qui fonctionnent dans Rostelecom.