Si vous développez de grandes bases de données et que vous rencontrez soudainement un plafond de performances, il est temps de vous étendre. Avec l'extension scale-out, c'est clair: vous ajoutez des serveurs et vous ne connaissez pas le problème. Avec l'extension, ce n'est pas tellement amusant. Selon l'architecture standard sans colle, nous prenons deux processeurs, puis nous en ajoutons deux de plus ... nous arrivons donc à huit et c'est tout. Intel ne le prévoyait plus; économisez sur un nouveau serveur

Mais il existe une alternative: l'architecture collée. Dans ce document, les unités de calcul à double processeur sont interconnectées via des contrôleurs de nœuds. Avec leur aide, le seuil supérieur par serveur atteint 16 processeurs ou plus. Dans cet article, nous parlerons davantage de l'architecture collée en général et de la façon dont elle est implémentée dans nos serveurs.
Avant de passer à l'architecture collée, par souci d'honnêteté, nous nous attardons sur les avantages et les inconvénients du sans colle.
Les solutions faites selon une architecture sans colle sont typiques. Les processeurs communiquent entre eux sans périphérique supplémentaire, mais via le bus QPI \ UPI standard. Le résultat est un peu moins cher qu'avec du collé. Mais tous les huit processeurs doivent dépenser beaucoup d'argent - pour installer un nouveau serveur.
 Architecture typique sans colle
Architecture typique sans colleEt avec l'architecture collée, comme nous l'avons déjà dit, le plafond passe à 16 processeurs ou plus par serveur.
Fonctionnement de l'architecture collée Bull BCS2
Les points forts de l'architecture Bull BCS2 sont fournis par deux composants: le contrôleur de nœud eXternal résilient et la mise en cache du processeur. Les équipes compatibles avec les processeurs Intel Xeon E7-4800 / 8800 v4 sont prises en charge.
 Architecture collée Bull BCS2. Toutes les connexions du serveur sont visibles ici. Chaque nœud BCS possède 7 liaisons XQPI.
Architecture collée Bull BCS2. Toutes les connexions du serveur sont visibles ici. Chaque nœud BCS possède 7 liaisons XQPI.Grâce à la mise en cache, la quantité d'interaction entre les processeurs est réduite - les processeurs de chaque module ont accès à un cache commun. Ainsi, la charge sur la RAM est réduite. Noda, à son tour, fonctionne comme un commutateur de trafic et résout le problème des «cols étroits» - il redirige le trafic le long du chemin le moins utilisé.
En conséquence, l'architecture Bull BCS2 ne consomme que 5 à 10% de la bande passante du bus Intel QPI, la norme pour une architecture sans colle. Quant aux retards d'accès à la mémoire locale, ils sont comparables aux systèmes sans colle à 4 sockets et sont 44% inférieurs aux systèmes sans colle à 8 sockets. Selon les spécifications, la vitesse totale de transfert de données du nœud BCS est de 230 Go / s - 25,6 Go / s est obtenu pour chacun des 7 ports. La bande passante maximale est de 300 Go / s.

Dans chaque serveur Bullion S, il y a un tel interrupteur sur la carte mère. Une liaison XQPI (16 sockets) en termes de vitesse équivaut à dix ports 10 GigE.
 Gamme Bullion S
Gamme Bullion SDans les configurations sur 4 et 8 processeurs, la différence entre architecture collée et sans colle est négligeable. Cependant, la situation change lors du passage à 16 processeurs. Nous nous souvenons que sans colle, vous avez déjà besoin de deux serveurs pour cela. Et dans le serveur Bullion S avec une architecture collée, tout se déroule comme ceci:
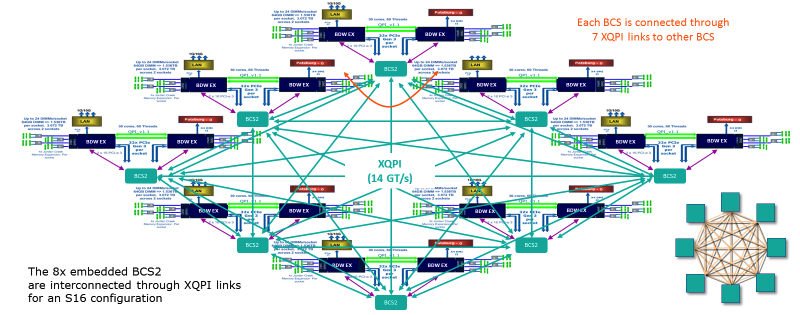 Les modules biprocesseurs sont interconnectés via un réseau XQPI avec un débit de 14 GT / s (milliards de transactions par seconde)
Les modules biprocesseurs sont interconnectés via un réseau XQPI avec un débit de 14 GT / s (milliards de transactions par seconde)Les emplacements peuvent accueillir n'importe quel processeur de la famille E7, à l'exception du E7-8893, qui ne peut être utilisé que dans des configurations à deux processeurs. Comparé à l'accès à la mémoire locale, le retard du système NUMA atteint environ x1,5 à l'intérieur du module et environ x4 entre les modules. Le contrôleur hôte gère la partition matérielle et vous permet de créer jusqu'à 8 partitions distinctes exécutées sur le système d'exploitation des serveurs Bullion S.
Par conséquent, nous pouvons héberger jusqu'à 384 cœurs de processeur sur un seul serveur. Quant à la RAM, ici le plafond est de 384 modules DDR4 de 64 Go. Au total, nous obtenons 24 téraoctets.
La configuration décrite est pertinente pour nos chevaux de bataille - les serveurs Bullion S. En plus de cela, nous avons la ligne BullSequana S, qui peut inclure jusqu'à 32 processeurs physiques basés sur la plate-forme Intel Purley et les architectures Skylake et Cascadelake (T1 2019).
Exemples d'intégration
Bullion S est conçu pour les tâches exigeantes - SAP HANA, Oracle, MS SQL, Datalake (avec certification Cloudera pour BullSequana S), la virtualisation / VDI pour VMware et les solutions hyperconvergées basées sur VMware vSAN. En partie sur les serveurs Bullion S, Siemens a créé la plus grande plateforme SAP HANA au monde. Également basé sur Bullion S, PWC a construit une énorme solution pour Hadoop et l'analyse. Au total, environ 300 entreprises dans le monde utilisent les solutions Bull.
Afin que vous puissiez comprendre les capacités de nos serveurs, nous présenterons un plan de migration d'une base de données Oracle de Power vers x86 dans les succursales d'un opérateur de télécommunications russe:

Conclusion
Grâce à la mise en cache des processeurs, l'architecture collée permet aux processeurs de communiquer directement avec les autres processeurs du nœud. Et liens rapides - ne ralentissez pas lorsque vous interagissez avec d'autres clusters. Aujourd'hui, jusqu'à 16 processeurs (384 cœurs) et jusqu'à 24 To de RAM s'intègrent dans un serveur Bullion S. L'étape de mise à l'échelle consiste en deux processeurs - cela facilite la répartition de la charge financière lors de la création d'une infrastructure informatique.
Dans les documents futurs, nous prévoyons d'analyser nos serveurs plus en détail. Nous serons heureux de répondre à vos questions dans les commentaires.