La structure interne des dictionnaires en Python ne se limite pas uniquement au bucket et au hachage privé. Il s'agit d'un monde étonnant de clés partagées, de mise en cache de hachage, de DKIX_DUMMY et de comparaisons rapides, qui peuvent être effectuées encore plus rapidement (au prix d'un bogue avec une probabilité approximative de 2 ^ -64).
Si vous ne connaissez pas le nombre d'éléments dans le dictionnaire que vous venez de créer, combien de mémoire est dépensée pour chaque élément, pourquoi maintenant (CPython 3.6 et versions ultérieures) le dictionnaire est implémenté dans deux tableaux et comment il se rapporte au maintien de l'ordre d'insertion, ou vous n'avez tout simplement pas regardé la présentation de Raymond Hettinger "Modern Python moderne" Dictionnaires Une confluence d'une douzaine de grandes idées. " Alors bienvenue.
Cependant, les personnes qui connaissent la conférence peuvent également trouver des détails et des informations fraîches, et pour les nouveaux arrivants qui ne sont pas familiers avec le seau et le hachage fermé, l'article sera également intéressant.
Les dictionnaires en CPython sont partout, les classes, les variables globales, les paramètres kwargs sont basés sur eux, l'
interpréteur crée des milliers de dictionnaires , même si vous-même n'avez pas ajouté de crochets à votre script. Mais pour résoudre de nombreux problèmes appliqués, des dictionnaires sont également utilisés, il n'est pas surprenant que leur implémentation continue de s'améliorer et de plus en plus se développer en différentes astuces.
Implémentation de base des dictionnaires (via Hashmap)
Si vous connaissez le travail de Hashmap standard et le hachage privé, vous pouvez passer au chapitre suivant.
L'idée sous-jacente aux dictionnaires est simple: si nous avons un tableau dans lequel des objets de la même taille sont stockés, alors nous avons facilement accès à l'objet souhaité, connaissant l'index.
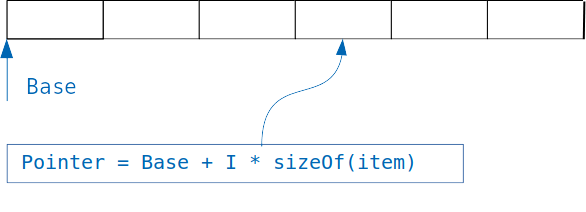
Nous ajoutons simplement un index multiplié par la taille de l'objet au décalage du tableau, et nous obtenons l'adresse de l'objet souhaité.
Mais que se passe-t-il si nous voulons organiser une recherche non pas par un index entier, mais par une variable d'un autre type, par exemple, pour trouver des utilisateurs à leur adresse mail?
Dans le cas d'un tableau simple, nous devrons parcourir les mails de tous les utilisateurs du tableau et les comparer avec la recherche, cette approche est appelée recherche linéaire et, évidemment, elle est beaucoup plus lente que l'accès à l'objet par index.
La recherche linéaire peut être considérablement accélérée si nous limitons la taille de la zone dans laquelle vous souhaitez effectuer la recherche. Ceci est généralement réalisé en prenant le reste du
hachage . Le champ recherché est la clé.
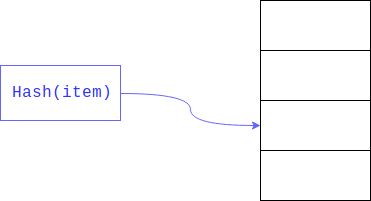
Par conséquent, une recherche linéaire n'est pas effectuée sur l'ensemble du grand tableau, mais le long de sa partie.
Mais que faire s'il y a déjà un élément? Cela pourrait très bien se produire, car personne ne garantissait que les résidus de la division du hachage seraient uniques (comme le hachage lui-même). Dans ce cas, l'objet sera placé à l'index suivant, s'il est occupé, il se déplacera d'un autre index et ainsi de suite jusqu'à ce qu'il en trouve un libre. Lors de la récupération d'un élément, toutes les clés avec le même hachage seront affichées.
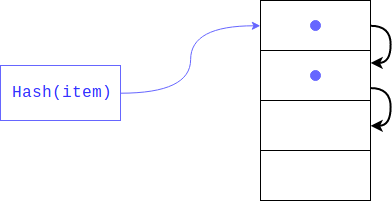
Ce type de hachage est appelé privé. S'il y a peu de cellules libres dans le dictionnaire, alors une telle recherche menace de dégénérer en une recherche linéaire, donc nous perdrons tous les gains pour lesquels le dictionnaire a été créé, afin d'éviter cela, l'interprète conserve le tableau rempli en 1/2 - 2/3. S'il n'y a pas suffisamment de cellules libres, un nouveau tableau est créé deux fois plus grand que le précédent et les éléments de l'ancien sont transférés vers le nouveau à la fois.
Que faire si l'élément a été supprimé? Dans ce cas, une cellule vide est formée dans le tableau et l'algorithme de recherche par clé ne peut pas distinguer, cette cellule est vide car un élément avec un tel hachage n'était pas dans le dictionnaire, ou parce qu'il a été supprimé. Pour éviter la perte de données lors de la suppression, la cellule est marquée d'un indicateur spécial (DKIX_DUMMY). Si cet indicateur est rencontré lors d'une recherche d'élément, la recherche se poursuit, la cellule est considérée comme occupée, si elle est insérée, la cellule sera écrasée.
Fonctionnalités d'implémentation en Python
Chaque élément du dictionnaire doit contenir un lien vers l'objet cible et la clé. La clé doit être stockée pour le traitement de collision, l'objet - pour des raisons évidentes. Étant donné que la clé et l'objet peuvent être de n'importe quel type et taille, nous ne pouvons pas les stocker directement dans la structure, ils se trouvent dans la mémoire dynamique et les liens vers ceux-ci sont stockés dans la structure de l'élément de liste. Autrement dit, la taille d'un élément doit être égale à la taille minimale de deux pointeurs (16 octets sur les systèmes 64 bits). Cependant, l'interpréteur stocke également le hachage, ceci afin de ne pas le recalculer à chaque augmentation de la taille du dictionnaire. Au lieu de calculer le hachage de chaque clé d'une nouvelle manière et de prendre le reste de la division par le nombre de compartiments, l'interprète lit simplement la valeur déjà enregistrée. Mais que se passe-t-il si l'objet clé est modifié? Dans ce cas, le hachage doit être recalculé et la valeur stockée sera incorrecte? Une telle situation est impossible, car les types mutables ne peuvent pas être des clés de dictionnaire.
La structure de l'élément dictionnaire est définie comme suit:
typedef struct { Py_hash_t me_hash;
La taille minimale du dictionnaire est déclarée par la constante PyDict_MINSIZE, qui est de 8. Les développeurs ont décidé qu'il s'agissait de la taille optimale afin d'éviter un gaspillage de mémoire inutile pour stocker des valeurs vides et du temps pour l'expansion dynamique de la matrice. Ainsi, lors de la création d'un dictionnaire (jusqu'à la version 3.6), il fallait un minimum de 8 éléments dans le dictionnaire * 24 octets dans la structure = 192 octets (cela ne prend pas en compte le reste des champs: le coût de la variable dictionnaire elle-même, le compteur du nombre d'éléments, etc.)
Les dictionnaires sont également utilisés pour implémenter des champs de classe personnalisés. Python vous permet de modifier dynamiquement le nombre d'attributs, cette dynamique ne nécessite pas de coûts supplémentaires, car l'ajout / la suppression d'un attribut est essentiellement équivalent à l'opération correspondante sur le dictionnaire. Cependant, une minorité de programmes utilisent cette fonctionnalité; la plupart sont limités aux champs déclarés dans __init__. Mais chaque objet doit stocker son propre dictionnaire, avec ses clés et ses hachages, malgré le fait qu'ils coïncident avec d'autres objets. Une amélioration logique ici est le stockage des clés partagées en un seul endroit, ce qui est exactement ce qui a été mis en œuvre dans le
PEP 412 - Key-Sharing Dictionary . La possibilité de modifier dynamiquement le dictionnaire n'a pas disparu: si l'ordre ou le nombre de clés est modifié, le dictionnaire est converti des clés de division en clé normale.
Pour éviter les collisions, le «chargement» maximum du dictionnaire est 2/3 de la taille actuelle du tableau.
#define USABLE_FRACTION(n) (((n) << 1)/3)
Ainsi, la première extension se produira lorsque le 6ème élément sera ajouté.
La matrice s'avère être assez déchargée, pendant le fonctionnement du programme, de la moitié au tiers des cellules restent vides, ce qui conduit à une consommation de mémoire accrue. Afin de contourner cette limitation et, si possible, de ne stocker que les données nécessaires, un nouveau
niveau d'abstraction du tableau a été ajouté.
Au lieu de stocker un tableau clairsemé, par exemple:
d = {'timmy': 'red', 'barry': 'green', 'guido': 'blue'}
À partir de la version 3.6, les dictionnaires sont organisés comme suit:
indices = [None, 1, None, None, None, 0, None, 2] entries = [[-9092791511155847987, 'timmy', 'red'], [-8522787127447073495, 'barry', 'green'], [-6480567542315338377, 'guido', 'blue']]
C'est-à-dire seuls les enregistrements réellement nécessaires sont stockés, ils sont retirés de la table de hachage dans un tableau séparé et seuls les index des enregistrements correspondants sont stockés dans la table de hachage. Si initialement le tableau prenait 192 octets, il n'en est plus que de 80 (3 * 24 octets pour chaque enregistrement + 8 octets pour les index). Compression atteinte à 58%. [2]
La taille d'un élément dans les index change également de manière dynamique, initialement elle est égale à un octet, c'est-à-dire que l'ensemble du tableau peut être placé dans un registre, lorsque l'index commence à tenir sur 8 bits, puis les éléments s'étendent à 16, puis à 32 bits. Il existe des constantes spéciales DKIX_EMPTY et DKIX_DUMMY pour les éléments vides et supprimés, respectivement, l'extension de l'index à 16 octets se produit lorsqu'il y a plus de 127 éléments dans le dictionnaire.
De nouveaux objets sont ajoutés aux entrées, c'est-à-dire que lors de l'expansion du dictionnaire, il n'est pas nécessaire de les déplacer, il vous suffit d'augmenter la taille des index et de le remplir avec des index.
Lors de l'itération sur un dictionnaire, le tableau d'indices n'est pas nécessaire, les éléments sont renvoyés séquentiellement à partir des entrées, car des éléments sont ajoutés à chaque fois à la fin des entrées, le dictionnaire enregistre automatiquement l'ordre d'apparition des éléments. Ainsi, en plus de réduire la mémoire nécessaire pour stocker le dictionnaire, nous avons reçu une expansion dynamique plus rapide et une préservation de l'ordre des clés. La réduction de la mémoire est bonne en soi, mais en même temps, elle peut augmenter les performances, car elle permet à plus d'enregistrements d'entrer dans le cache du processeur.
Les développeurs de CPython ont tellement aimé cette implémentation que les dictionnaires sont désormais requis pour maintenir l'ordre d'insertion par spécification. Si plus tôt l'ordre des dictionnaires était déterminé, c'est-à-dire il était strictement déterminé par le hachage et était inchangé du début à la fin, puis un peu d'aléatoire y était ajouté pour que les clés soient différentes à chaque fois, maintenant les clés du dictionnaire doivent maintenir l'ordre. On ne sait pas dans quelle mesure cela était nécessaire et que faire si une implémentation encore plus efficace du dictionnaire mais ne préservait pas l'ordre d'insertion.
Cependant, il y avait des demandes pour implémenter un mécanisme pour conserver la déclaration d'attributs dans les
classes et dans les
kwargs , et cette implémentation vous permet de fermer ces problèmes sans mécanismes spéciaux.
Voici à quoi cela ressemble dans le
code CPython :
struct _dictkeysobject { Py_ssize_t dk_refcnt; Py_ssize_t dk_size; dict_lookup_func dk_lookup; Py_ssize_t dk_usable; Py_ssize_t dk_nentries; char dk_indices[]; };
Mais l'itération est plus compliquée que vous ne le pensez au départ, il existe des mécanismes de vérification supplémentaires que le dictionnaire n'a pas été modifié pendant l'itération, l'un d'eux est une
version 64 bits
du dictionnaire qui stocke chaque dictionnaire.
Enfin, nous considérons le mécanisme de résolution des collisions. Le fait est qu'en python, les valeurs de hachage sont facilement prévisibles:
>>>[hash(i) for i in range(4)] [0, 1, 2, 3]
Et puisque lors de la création d'un dictionnaire à partir de ces hachages, le reste de la division est pris, puis, en fait, ils déterminent dans quel compartiment l'enregistrement ira, uniquement les derniers bits de la clé (s'il est entier). Vous pouvez imaginer une situation où nous avons beaucoup d'objets «veulent» entrer dans des seaux voisins, auquel cas vous devrez regarder beaucoup d'objets qui ne sont pas à leur place lors de la recherche. Pour réduire le nombre de collisions et augmenter le nombre de bits qui déterminent dans quel compartiment l'enregistrement ira, le mécanisme suivant a été implémenté:
perturb est une variable entière initialisée par un hachage. Il est à noter que dans le cas d'un grand nombre de collisions, il est remis à zéro et l'indice suivant est calculé par la formule:
j = (5 * j + 1) % n
Lors de l'extraction d'un élément du dictionnaire, la même recherche est effectuée: l'index de l'emplacement dans lequel l'élément doit se trouver est calculé, si l'emplacement est vide, l'exception "valeur non trouvée" est levée. S'il y a une valeur dans cet emplacement, vous devez vérifier que sa clé correspond à celle que vous recherchez, cela peut ne pas être possible en cas de collision. Cependant, la clé peut être presque n'importe quel objet, y compris celui pour lequel l'opération de comparaison prend un temps considérable. Pour éviter une opération de comparaison longue, plusieurs astuces sont utilisées en Python:
tout d'abord, les pointeurs sont comparés, si le pointeur clé de l'objet souhaité est égal au pointeur de l'objet recherché, c'est-à-dire qu'ils pointent vers la même zone de mémoire, puis la comparaison renvoie immédiatement true. Mais ce n'est pas tout. Comme vous le savez, les objets égaux doivent avoir des hachages égaux, ce qui signifie que les objets avec des hachages différents ne sont pas égaux. Après avoir vérifié les pointeurs, les hachages sont vérifiés; s'ils ne sont pas égaux, false sera retourné. Et seulement si les hachages sont égaux, une comparaison honnête sera appelée.
Quelle est la probabilité d'un tel résultat? Environ 2 ^ -64, bien sûr, en raison de la prévisibilité facile de la valeur de hachage, vous pouvez facilement prendre un tel exemple, mais en réalité, cette vérification ne revient pas souvent à combien? Raymond Hettinger a assemblé l'interpréteur en modifiant la dernière opération de comparaison avec un simple retour vrai. C'est-à-dire l'interprète considère les objets égaux si leurs hachages sont égaux. Il a ensuite défini des tests automatisés de nombreux projets populaires sur cet interprète, qui se sont terminés avec succès. Il peut sembler étrange de considérer des objets avec des hachages égaux égaux, de ne pas vérifier en outre leur contenu et de se fier entièrement au hachage uniquement, mais vous le faites régulièrement lorsque vous utilisez les protocoles git ou torrent. Ils considèrent les fichiers (blocs de fichiers) égaux si leurs hachages sont égaux, ce qui peut bien conduire à des erreurs, mais leurs créateurs (et nous tous) espérons qu'il convient de noter, il n'est pas déraisonnable, que la probabilité de collision est extrêmement faible.
Maintenant, vous devriez enfin comprendre la structure du dictionnaire, qui ressemble à ceci:
typedef struct { PyObject_HEAD Py_ssize_t ma_used; uint64_t ma_version_tag; PyDictKeysObject *ma_keys; PyObject **ma_values; } PyDictObject;
Changements futurs
Dans le chapitre précédent, nous avons examiné ce qui a déjà été implémenté et peut être utilisé par tout le monde dans leur travail, mais les améliorations ne sont bien sûr pas limitées à: les plans de la version 3.8 incluent la
prise en charge des dictionnaires inversés . En effet, rien n'empêche au lieu d'itérer depuis le début d'un tableau d'éléments et d'augmenter les indices, en commençant par la fin et les indices décroissants.
Matériel supplémentaire
Pour une immersion plus approfondie dans le sujet, il est recommandé de vous familiariser avec les matériaux suivants:
- Enregistrement du rapport au début de l'article
- Proposition pour une nouvelle implémentation de dictionnaires
- Dictionnaire du code source dans CPython