Nous voulons partager l'histoire qui s'est produite lors de l'un de nos projets pour la nouvelle année. L'essence du projet est qu'il automatise le travail des médecins dans les institutions médicales. Pendant la visite du patient, le médecin écrit des informations sur l'enregistreur, puis l'audio est transcrit. Après le processus de transcription - c.-à-d. transformer l'enregistrement audio en texte - un document médical est formé selon les normes pertinentes et renvoyé à la clinique, d'où l'enregistrement audio est venu, où le médecin d'envoi le reçoit, le vérifie et l'approuve. Après avoir passé les contrôles obligatoires, le document est envoyé aux patients finaux.
Toutes les institutions médicales utilisant le produit peuvent être conditionnellement divisées en deux grands groupes:
- Hébergement dans le centre de données de notre client, qui est entièrement responsable de la fonctionnalité de l'application, à la fois pour le logiciel et le matériel. Par exemple, si l'espace disque est épuisé ou si les performances du serveur ne sont pas suffisantes sur le processeur;
- Auto-hébergés: ils placent tous les équipements directement chez eux et sont eux-mêmes responsables de ses performances. Notre client leur fournit l'application et son support.
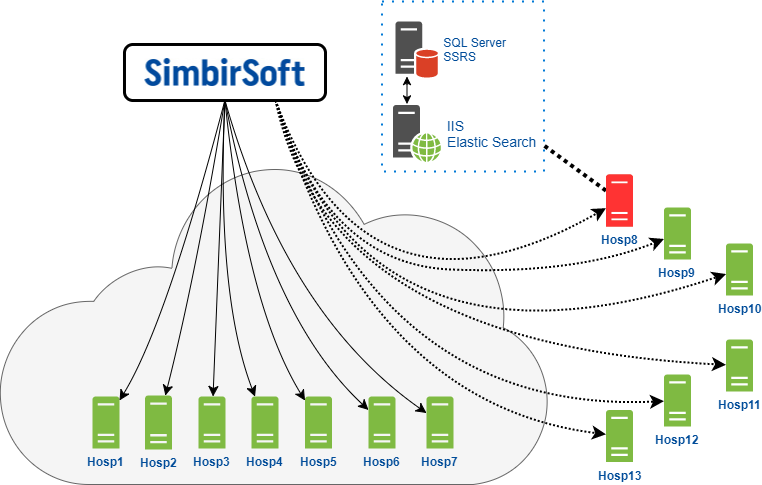
C'est ainsi que notre équipe interagit avec les serveurs finaux hébergés directement dans le cloud de notre client.

Nous avons accès à ces serveurs pour effectuer tous les travaux et la maintenance planifiés qui sont nécessaires.
Le deuxième groupe - les clients auto-hébergés - pour eux, le cloud client agit comme une passerelle par laquelle nous nous connectons à ces serveurs. Dans ce cas, nous avons des droits limités, souvent nous ne pouvons effectuer aucune opération en raison des paramètres de sécurité. Nous nous connectons aux serveurs via RDP, le protocole Remote Desktop sur Windows OS. Naturellement, tout cela fonctionne via un VPN.
Il convient de garder à l'esprit que chaque serveur représenté dans le diagramme est en réalité une combinaison d'un serveur d'applications et d'un serveur de base de données. Sur le serveur de base de données, respectivement, le SGBD MS SQL Server et le service de génération de rapports SSRS sont installés. De plus, la version de MSSQL Server est différente dans toutes les cliniques: 2008, 2012, 2014. En plus des versions elles-mêmes, différents Service Packs et correctifs sont installés partout. En général, un zoo complet.
Sur le serveur d'applications, nous avons installé le serveur Web IIS et ElasticSearch. ElasticSearch est un moteur de recherche qui implémente également la recherche en texte intégral.
L'essence principale de notre produit est le «travail». Le travail est une entité abstraite qui relie toutes les informations liées à la réception d'un patient particulier. Ces informations comprennent:
- données sur le médecin;
- données patient;
- données sur la visite;
- fichier audio (discours du médecin);
- documents (plusieurs versions);
- historique de traitement du travail;
- informations sur la succursale, etc.
Ce diagramme montre un schéma de base de données simplifié à partir duquel vous pouvez voir les relations entre les tables principales. Ce n'est que la partie de base, en fait, la base de données contient plus de 200 tables.

Un peu sur la clinique où l'incident s'est produit:
- 1500-2000 travaux par jour;
- 1000+ utilisateurs actifs (médecins + secrétaires);
- Auto-hébergé.
DB:
- Taille: 800+ Go (750K + œuvres, 2M + documents);
- SGBD: MS SQL Server 2008 R2;
- Modèle de récupération: simple.
Ici, je veux faire une petite explication. Il existe 3 modèles de récupération dans SQL Server: simple, enregistré en bloc et complet. Je ne parlerai pas du troisième maintenant, je vais vous expliquer le premier et le deuxième. La principale différence est que dans le modèle simple, nous ne stockons pas l'historique des transactions dans le journal - dès que la transaction a été validée, l'enregistrement du journal des transactions sera supprimé. Lorsque vous utilisez le mode de récupération complète, l'historique complet des modifications de données est stocké dans un journal des transactions. Qu'est-ce que cela nous donne? En cas de situation imprévue, lorsque nous devons restaurer la base de données à partir de sauvegardes, nous pouvons revenir non seulement à une sauvegarde spécifique, mais également à tout moment, jusqu'à une certaine transaction, c'est-à-dire que nous avons dans les sauvegardes, non seulement un certain état de la base de données au moment de la sauvegarde, mais aussi toute une histoire de modifications des données.
Je pense que cela ne vaut pas la peine d'expliquer que le mode simple n'est utilisé qu'en développement, sur des serveurs de test et que son utilisation en production est inacceptable. Pas du tout.
Mais la clinique, apparemment, avait ses propres réflexions à ce sujet;)
Commencer
Quelques jours plus tard, le Nouvel An, tout le monde se prépare pour les vacances, achète des cadeaux, décore les sapins de Noël, passe les fêtes d'entreprise et attend un long week-end.
22 décembre (vendredi) 1 jour
14:31 Le client a déclaré qu'il n'avait pas reçu le prochain rapport quotidien. Le rapport arrive par la poste deux fois par jour selon un calendrier; il est nécessaire de contrôler l'envoi de données à un système d'intégration externe, ce qui n'est pas trop critique.
Il peut y avoir plusieurs raisons:
- Problèmes avec SMTP, les lettres n'ont tout simplement pas été livrées (ils ont changé le mot de passe, par exemple, et ils n'en ont parlé à personne);
- Problèmes côté serveur des rapports;
- Quelque chose est arrivé à la base de données.
16:03 La clinique change parfois le mot de passe en SMTP, sans en avertir personne, donc, après avoir terminé les tâches en cours, nous vérifions calmement le rapport manuellement en le lançant via l'interface Web - nous obtenons une erreur qui indique des problèmes dans la base de données.
Un exemple de l'erreur que nous avons reçue lors du démarrage du rapport.
SQL Server detected a logical consistency-based I/O error: incorrect checksum (expected: 0x9876641f; actual: 0xa3255fbf). It occurred during a read of page (1:876) in database ID 7 at offset 0x000000006d8000 in file 'D:\Program Files\Microsoft SQL Server\MSSQL10_50.MSSQLSERVER\MSSQL\DATA\ServerLive.mdf'.
Cela indique que la base de données contient des pages corrompues. Nous avions un léger sentiment d'anxiété.
20:53 Afin d'évaluer l'étendue des dommages, nous
exécutons une vérification de la base de données à l'aide de la
commande spéciale
DBCC CHECKDB . Selon la taille des dégâts, la commande de test peut prendre un certain temps, nous exécutons donc la commande la nuit. Ici, nous avons de la chance que cela se soit produit vendredi après-midi, c'est-à-dire que nous avions au moins tous les jours de congé pour résoudre ce problème.
À ce moment, la situation était la suivante:
23 décembre (samedi) 2e jour
10:02 Le matin, nous constatons que la vérification de la base de données avec CHECKDB est disquette - cela était dû à un manque d'espace disque libre, car au cours du processus de vérification, la base de données temporaire tempdb est activement utilisée et, à un moment donné, l'espace disque libre s'est simplement épuisé.
Par conséquent, nous décidons au lieu de vérifier la base de données entière de lancer immédiatement une analyse de table. Pour ce faire, utilisez la
commande DBCC CHECKTABLE .
10:46 Nous décidons de commencer avec la table JobHistory, qui est probablement corrompue, car c'est elle qui a été utilisée pour générer le rapport. Ce tableau, comme son nom l'indique, préserve l'histoire de toutes les œuvres, c'est-à-dire les transitions du travail entre les étapes.
Exécutez
DBCC CHECKTABLE ('dbo.JobHistory') .
La vérification de cette table révèle des tables endommagées dans la base de données, ce qui était attendu en principe.
12:00 À l'heure actuelle, si la base de données utilisait le modèle de récupération complète, nous pourrions restaurer les pages endommagées à partir de la sauvegarde, et ce serait fini, mais notre base de données était en mode simple. Par conséquent, la seule option pour réparer les dommages reste le lancement de la même commande avec le paramètre spécial
REPAIR_ALLOW_DATA_LOSS . Cela peut entraîner une perte de données.
Nous commençons. La vérification se termine à nouveau avec une erreur - nous obtenons une erreur indiquant que la restauration de cette table est impossible jusqu'à ce que les tables associées soient restaurées. La table d'historique fait référence à la table de travail (Jobs) par la clé étrangère, par conséquent, nous concluons qu'il y a également des dommages dans la table de travail principale (Jobs).
13:30 La prochaine étape consiste à vérifier le tableau des emplois, en même temps - nous espérons que les dommages se trouvent dans l'index, et non dans les données. Dans ce cas, il nous suffira de reconstruire simplement l'index pour la récupération des données.
17:33 Après un certain temps, nous constatons que notre serveur n'est pas disponible via RDP. Il a probablement été éteint, le contrôle n'a pas été effectué, les travaux ont été suspendus. Nous informons la clinique que le serveur n'est pas disponible, veuillez le soulever.
Une légère anxiété prend des formes très spécifiques.
24 décembre (dimanche) 3e jour
14:31 Plus près du dîner, le serveur est relevé, nous réexécutons la vérification de la table Jobs.
DBCC CHECKTABLE ('dbo.Jobs')16:05 La vérification n'est pas terminée, le serveur n'est pas disponible. Encore une fois.
Après un certain temps, le serveur n'est plus disponible, avant que nous ayons réussi à terminer la vérification de la table. À ce stade, le service informatique de la clinique effectue une série de vérifications de serveur. Nous attendons la fin des travaux.
En raison des vacances, la communication entre nous et le client a été lente - nous nous attendions à des réponses aux questions pendant plusieurs heures.
25 décembre (lundi - Noël) 4e jour
16:00 Le lendemain, le serveur a été relevé, le client a Noël et nous recommençons à vérifier la table, mais cette fois nous excluons les index de l'analyse et nous laissons uniquement la vérification des données. Et après un certain temps, le serveur n'est plus disponible.
Que se passe-t-il?
En ce moment, les pensées commencent à s'infiltrer, ce n'est pas seulement une coïncidence, et on soupçonne qu'il pourrait être endommagé au niveau du fer (un disque dur est tombé). Nous supposons qu'il y a des secteurs défectueux sur le disque et lorsque l'analyse tente de lire les données de ces secteurs, le système se bloque. Nous informons notre client de notre hypothèse.
Le client exécute une vérification du disque sur la machine hôte.
17:19 Le service informatique de la clinique a signalé que le fichier de la machine virtuelle était endommagé - c'est mauvais! (
Nous ne pouvons pas encore travailler et nous attendons un signal quand ils règlent le problème et nous pouvons continuer notre travail.
26 décembre (mardi) Jour 5
14:05 Le service de la clinique informatique lance un autre processus de récupération de disque. On nous a dit que nous pouvons exécuter CHECKTABLE en parallèle pour vérifier la table. Nous recommençons le test - la machine virtuelle plante à nouveau, nous informons le client que le fichier de la machine virtuelle est toujours corrompu.
De nos jours, toutes les communications avec le client sont très lentes avec un décalage énorme dû aux vacances.
27 décembre (mercredi) Jour 6
14:00 Nous commençons la vérification du disque à l'aide de Windows -
checkdisk à l'intérieur de la machine virtuelle - aucun problème n'a été détecté.
La base de données est en mode simple, donc les chances de corriger la base de données actuelle avec les outils SGBD ont tendance à zéro, car nous ne pouvons pas récupérer les pages individuelles endommagées.
Nous commençons à envisager l'option de restauration et de restauration de la base de données à partir d'une sauvegarde.
Nous vérifions les sauvegardes de la base de données et constatons que les sauvegardes n'ont pas été effectuées à l'aide du SGBD, la dernière sauvegarde a eu lieu en 2014, c'est-à-dire Il n'y a aucune sauvegarde de la base de données. La raison pour laquelle ils ne l'ont pas fait est un problème distinct, il est de la responsabilité de la clinique d'assurer l'efficacité et la sécurité de la base de données.
Il y a une forte probabilité que cela ne fonctionne pas pour restaurer la base de données actuelle, nous commençons à envisager d'autres options de restauration.
Arrêtons-nous plus en détail sur la situation des sauvegardes à la clinique.
La situation avec les sauvegardes:
- Il n'y a pas de sauvegarde de base de données (!!!)
- Il n'y a pas d'instantanés de la machine virtuelle (!?)
- Mais il y a des sauvegardes sur disque (complètes + inc)
La base de données se trouve sur le disque D, respectivement, ils ont effectué des sauvegardes complètes hebdomadaires et des sauvegardes incrémentielles quotidiennes.
- tous les vendredis à 20h00 sauvegarde complète
- sauvegarde incrémentielle quotidienne
- il y a une sauvegarde complète du 15 et 22
- il y a des sauvegardes quotidiennes jusqu'au 21
C'est-à-dire en principe, nous pouvons revenir à l'état avant que le problème ne survienne.
Nous attendons une mise à jour de la clinique pour démarrer la restauration de la base de données à partir de la sauvegarde.
Dans le même temps, la clinique a envoyé une demande au fournisseur de fer (HP) marquée «urgent».
28 décembre (jeudi) Jour 7
13:13 Le service informatique de la clinique commence à configurer une nouvelle machine virtuelle, Il n'est pas possible de réparer les dommages dans le fichier de l'ancienne machine virtuelle.
19:09 Une nouvelle
machine virtuelle
est disponible avec SQL Server installé.
L'étape suivante consiste à restaurer la base de données à partir de la sauvegarde sur disque. Pour commencer, nous décidons de revenir au 22e jour, si le problème persiste, puis de revenir au 21e, 20e et ainsi de suite, jusqu'à ce que nous arrivions à un état de fonctionnement.
C'était le 28e jour dans la cour, nous étions à la fête d'entreprise, et ici, ils nous disent que la clinique a des problèmes avec la restauration des sauvegardes, car les SAUVEGARDES sont VIDE!
Voici les nouvelles!
Lors de la restauration d'une sauvegarde du lecteur D à partir du 21, il s'avère qu'il est vide, comme tout le monde. Des sauvegardes directes de broyeur sont obtenues - elles semblent être là, mais en même temps elles ne le sont pas. On ne sait pas du tout comment cela s'est produit, mais, pour autant que nous ayons pu le comprendre, le problème réside dans un espace disque insuffisant pour le stockage des sauvegardes sur disque. Ils ont alloué 500 Go de sauvegardes pour le stockage, mais au moment de l'incident, la base de données pesait déjà 800 Go, donc, en principe, la sauvegarde ne pouvait pas réussir. C'est-à-dire les sauvegardes ont été effectuées régulièrement selon le calendrier, mais en raison du manque d'espace, elles se sont soldées par une erreur et, par conséquent, étaient vides, et le service informatique de la clinique n'a même pas eu l'idée de vérifier que tout allait bien. Ne fais pas ça.
29 décembre (vendredi) Jour 8
13:11 Discussion sur d'autres actions. Options possibles:
- Tentative de copier des fichiers de base de données (fichiers .ldf + .two) - les chances de succès sont très faibles;
- Essayer de sauvegarder la base de données est encore très peu de chances;
- Configurer la réplication - peut fonctionner.
Un lecteur de 1 To a été alloué sur le nouveau serveur, ce qui n'est évidemment pas suffisant si nous essayons de sauvegarder et de restaurer à partir de celui-ci, car dans le pire des cas, sans compression, les sauvegardes prendront autant d'espace que la base de données d'origine, c'est-à-dire 800 Go.
Veuillez ajouter des emplacements sur le nouveau serveur et procéder à la copie des fichiers de base de données.
Une base de données a été créée sur le nouveau serveur et le schéma de base de données a été restauré - cela permettra au moins de traiter de nouveaux travaux. La clinique pourra au moins accepter de nouveaux patients en utilisant un tel système.
14:36 Par conséquent, nous passons à l’option numéro un, bien que nous ne nous attendions pas à beaucoup de succès.
Arrêtez SQL Server, commencez à copier le fichier de données (mdf) et le journal (ldf).
16:13 Après la moitié du fichier journal, il a été copié avec succès (48 Go) et 50 Go du fichier de données ont déjà été copiés (il reste 795 sur 846 Go). À cette vitesse, il faudra environ 12 heures pour terminer la copie.
16:30 L' ancien serveur de base de données s'est éteint lors de la copie du fichier, ce qui est tout à fait normal.
17:09 Par conséquent, nous passons à l'option suivante - configurer la réplication, alors que nous pouvons spécifier quelles données seront répliquées, c'est-à-dire que nous pouvons d'abord exclure les tables délibérément endommagées et copier d'abord les données intactes, puis transférer les tables problématiques en plusieurs parties. Mais cette option, malheureusement, ne fonctionne pas non plus, car nous ne pouvons même pas créer une publication avec certaines tables en raison de la corruption de la base de données.
Nous envisageons également des options de transfert de données.
20:01 Par conséquent, nous commençons simplement à transférer les données de l'ancien vers le nouveau serveur en les important et en les exportant par ordre de priorité.
21:35 D'abord, les données les plus critiques, puis d'archivage et moins critiques (~ 300 Go). Lors de la première vague d'exportation, il restait moins de 300 Go de données. Le tableau Documents (300 Go) est également exclu. Nous commençons le processus de copie la nuit.
30 décembre (samedi) Jour 9
15:00 Nous continuons de transférer des données. La table Jobs n'est pas disponible du tout. La plupart des tableaux ont été copiés à cette époque.
Mais sans
Jobs, tout cela est inutile, car il est le lien principal entre toutes les données et leur donne un sens et une valeur d'un point de vue commercial. Sans cela, nous avons juste un ensemble de données disparates que nous ne pouvons tout simplement pas utiliser.
En outre, à ce stade, la récupération du schéma de base de données est terminée.
Les conséquences de l'incident:À ce stade, nous avons une énorme perte de données en direct.
C'est-à-dire formellement, nous avons certaines données dans la base de données, mais, en fait, il n'y a aucun moyen de les utiliser ou de les connecter, nous pouvons donc parler de la perte complète de données.
Données perdues sur plus de 750 000 admissions de patients.
C'est vraiment triste!
- C'est un coup dur porté à la réputation de notre client, qui peut s'avérer être un gros problème pour lui dans les affaires lors de la conclusion de nouveaux contrats et de la recherche de nouveaux clients.
- Perdre autant de données pour la clinique peut entraîner de graves problèmes et des amendes, car Il s'agit de données confidentielles contenant une confidentialité médicale et, au sens littéral, dépendent de la vie des gens.
Nous avons commencé à penser à ce que nous pouvons faire dans cette situation. Ils ont commencé à trier le système par os pour trouver des indices.
15:16 En analysant tous les aspects du système, nous comprenons que nous pouvons essayer d'extraire les données manquantes de l'index ElasticSearch. Le fait est qu'en raison de la configuration incorrecte des index ElasticSearch, il stocke non seulement les champs par lesquels la recherche en texte intégral est effectuée, mais en général tout, c'est-à-dire qu'il existe en fait une copie complète des données et que nous pouvons théoriquement en extraire des données sur les œuvres et les remettre dans notre base de données. On espère que les données pourront toujours récupérer.
Un bug auquel vous pouvez mettre un monument!
 18:00
18:00 Un utilitaire a été rapidement écrit pour extraire les données, et après quelques heures nous nous assurons que l'approche fonctionne et que les données peuvent être restaurées.
20:00 La restauration du travail à partir d'ElasticSearch à l'aide d'un utilitaire écrit a commencé. L'approche a fonctionné, nous pouvons restaurer les données sur le travail. En parallèle, nous commençons à extraire les dernières versions du document pour chaque œuvre.
31 décembre (dimanche - nouvel an) Jour 10
14:09 Pendant la nuit, 188 811 œuvres ont été restaurées.
20:13 Voyant notre succès, la clinique décide de reporter le transfert du serveur vers le service HP afin de nous donner le temps d'extraire le maximum de données de l'ancien serveur.
Avec de telles nouvelles, nous avons célébré le Nouvel An))
01 janvier (lundi) 11e jour
11:23 Préparation du démarrage du système après l'incident:
- reconfiguré IIS sur le serveur d'applications;
- reconfiguré tous les services nécessaires pour travailler avec le nouveau serveur de base de données;
- déclencheurs, procédures stockées, fonctions restaurées.
14:28 Puis ils ont commencé à copier le tableau des documents, qui a été ignoré en raison de la grande taille lors du transfert initial.
- L'ancien serveur DB s'arrête à nouveau. Évidemment, la table Documents est également corrompue, c'est avec elle que toutes les informations patient sont stockées. Heureusement, il n'est pas complètement endommagé, nous pouvons lui faire des demandes, et lorsqu'une demande nous renvoie un enregistrement endommagé, à ce moment le serveur se bloque et s'arrête. Nous pouvons extraire certaines des données.
En conséquence, nous signalons le client, ils lèvent le serveur, et en parallèle nous continuons à préparer la nouvelle base de données pour le lancement du système.
18:01 Récupération de toutes les contraintes d'intégrité après le transfert de la partie principale des données.
22:02 Fin de la restauration des restrictions. Nous avons simplement transféré les données brutes au maximum. La présence de contraintes d'intégrité compliquerait grandement notre tâche.
02 janvier (mardi) Jour 12
05:52 L' ancien serveur DB s'est à nouveau éteint lors de la copie du document. Il est rapidement relevé pour que nous puissions continuer à travailler.
09:00 Il a été possible de récupérer par lots environ 200 000 documents (environ 20%)
Nous avons commencé à utiliser différentes méthodes de récupération: tri par différentes colonnes pour obtenir des données de la fin ou du début de la table, jusqu'à ce que nous tombions sur une partie endommagée de la table.
13:42 A commencé à copier les œuvres d'archives dans le tableau - heureusement, il n'est pas endommagé.
17:08 Restauration de tous les documents d'archives (491 380 pièces).
Le système est prêt à être lancé: les utilisateurs peuvent créer et traiter de nouveaux travaux.
Malheureusement, en raison de dommages partiels à la table de documents, vous ne pouvez pas simplement transférer toutes les données de celle-ci, comme avec d'autres tables, car la table est partiellement endommagée. Par conséquent, lorsque vous essayez de récupérer toutes les données, la demande se bloque lorsque vous essayez de lire des pages corrompues. Par conséquent, nous extrayons les données au point en utilisant différentes sortes et tailles d'échantillon:
- Tri par différents champs (ID, DateTime);
- Tri croissant, décroissant;
- Travailler avec de petits groupes de lignes (1000, 100);
- Récupération des travaux par ID.
03 janvier (mercredi) Jour 13
08:58 Poursuite du processus de restauration des documents. Les documents ont été restaurés uniquement pour des travaux actifs et incomplets. À ce stade, 1000 œuvres (actives) sans documents.
11:38 Migration de tous les travaux SQL
13:17 5 fonctionne sans documents, 231 pas de travail, mais il y a un fichier audio, vous devez resynchroniser.
04 janvier (jeudi) Jour 14
La récupération manuelle et la vérification du travail restant ont commencé.
Le système fonctionne, surveille et corrige les erreurs en ligne.
05 janvier (vendredi) Jour 15
La migration des rapports vers SSRS est prévue.
Le transfert vers un nouveau serveur n'est pas possible, car la clinique a installé une ancienne version de SQL Server et il ne fonctionnera pas pour transférer la base de données de l'ancien serveur.
Options:
- Mettre à niveau SQL Server de 2008 à 2008 R2;
- Configurez tout à partir de zéro.
Il a été décidé d'attendre la mise à jour de SQL Server.
09:21 La restauration en arrière-plan des documents pour les travaux terminés a commencé - le processus est long et prendra plusieurs jours.
13:28 Changement de priorité de restauration des documents par les services.
18:18 La clinique a donné accès à SMTP, configuration du courrier
Résultat:
- Presque toutes les données ont été restaurées (seulement 5 emplois ont été perdus);
- Des recommandations sur la maintenance des bases de données ont été émises pour éviter de telles situations;
- Les sauvegardes de base de données sont configurées à l'aide de SQL Server;
- Surveillance supplémentaire des sauvegardes de notre part, alertes en cas de panne.