
17 milliards d'événements, 60 millions de sessions utilisateurs et un grand nombre de dates virtuelles ont lieu quotidiennement à Badoo. Chaque événement est soigneusement stocké dans des bases de données relationnelles pour une analyse ultérieure en SQL et au-delà.
Bases de données transactionnelles distribuées modernes avec des dizaines de téraoctets de données - un véritable miracle d'ingénierie. Mais SQL, comme l'incarnation de l'algèbre relationnelle dans la plupart des implémentations standard, ne nous permet pas encore de formuler des requêtes en termes de tuples ordonnés.
Dans le dernier article d'une série sur les machines virtuelles , je parlerai d'une approche alternative pour trouver des sessions intéressantes - le moteur d'expression régulière ( Pig Match ), qui est défini pour les séquences d'événements.
La machine virtuelle, le bytecode et le compilateur sont inclus gratuitement!
Première partie, introduction
Deuxième partie, optimisation
Troisième partie, appliquée (actuelle)
À propos des événements et des sessions
Supposons que nous ayons déjà un entrepôt de données qui vous permet de visualiser rapidement et séquentiellement les événements de chacune des sessions utilisateur.
Nous voulons rechercher des sessions par des requêtes comme "compter toutes les sessions où il y a une sous-séquence d'événements spécifiée", "trouver les parties d'une session décrites par un modèle donné", "retourner la partie de la session qui s'est produite après un modèle donné" ou "compter le nombre de sessions qui ont atteint certaines parties modèle. " Cela peut être utile pour une variété de types d'analyses: recherche de sessions suspectes, analyse en entonnoir, etc.
Les sous-séquences souhaitées doivent en quelque sorte être décrites. Dans sa forme la plus simple, cette tâche est similaire à la recherche d'une sous-chaîne dans un texte; nous voulons avoir un outil plus puissant - les expressions régulières. Les implémentations modernes de moteurs d'expression régulière utilisent le plus souvent (vous l'avez deviné!) Des machines virtuelles.
La création de petites machines virtuelles pour faire correspondre des sessions avec des expressions régulières sera discutée ci-dessous. Mais d'abord, nous allons clarifier les définitions.
Un événement se compose d'un type d'événement, d'une heure, d'un contexte et d'un ensemble d'attributs spécifiques à chaque type.
Le type et le contexte de chaque événement sont des entiers issus de listes prédéfinies. Si tout est clair avec les types d'événements, alors le contexte est, par exemple, le numéro de l'écran sur lequel l'événement donné s'est produit.
Un attribut d' événement est un entier arbitraire dont la signification est déterminée par le type d'événement. Un événement peut ne pas avoir d'attributs ou il peut y en avoir plusieurs.
Une session est une séquence d'événements triée par le temps.
Mais passons enfin aux affaires. Le buzz, comme on dit, s'est calmé et je suis monté sur scène.
Comparer sur un morceau de papier
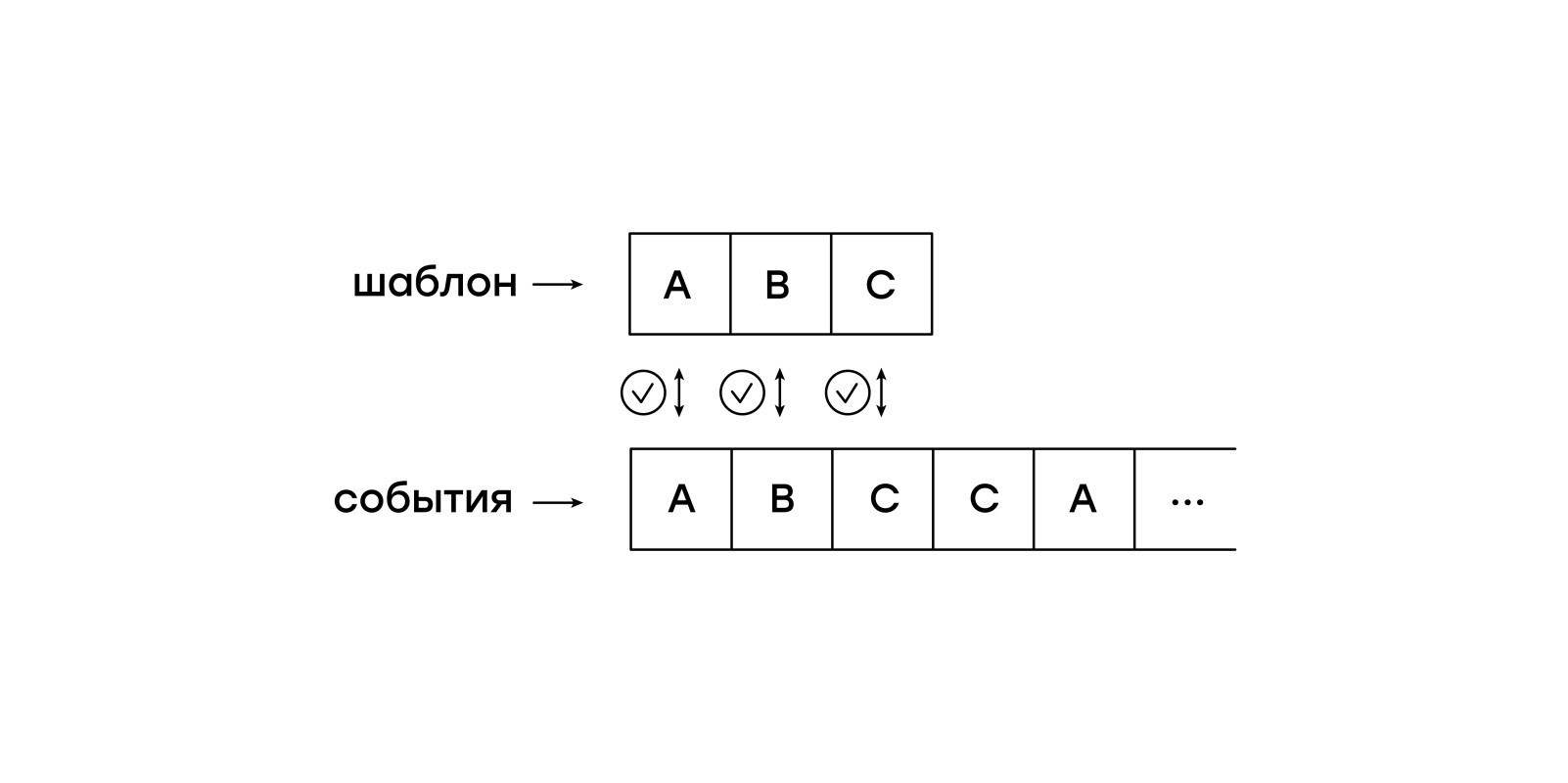
Une caractéristique de cette machine virtuelle est la passivité vis-à-vis des événements d'entrée. Nous ne voulons pas garder la session entière en mémoire et permettre à la machine virtuelle de passer indépendamment d'un événement à l'autre. Au lieu de cela, nous alimenterons les événements de la session dans la machine virtuelle un par un.
Définissons les fonctions d'interface:
matcher *matcher_create(uint8_t *bytecode); match_result matcher_accept(matcher *m, uint32_t event); void matcher_destroy(matcher *matcher);
Si tout est clair avec les fonctions matcher_create et matcher_destroy, alors matcher_accept mérite d'être commenté. La fonction matcher_accept reçoit une instance de la machine virtuelle et de l'événement suivant (32 bits, où 16 bits pour le type d'événement et 16 bits pour le contexte), et renvoie un code expliquant ce que le code utilisateur doit faire ensuite:
typedef enum match_result {
Opcodes de la machine virtuelle:
typedef enum matcher_opcode {
La boucle principale d'une machine virtuelle:
match_result matcher_accept(matcher *m, uint32_t next_event) { #define NEXT_OP() \ (*m->ip++) #define NEXT_ARG() \ ((void)(m->ip += 2), (m->ip[-2] << 8) + m->ip[-1]) for (;;) { uint8_t instruction = NEXT_OP(); switch (instruction) { case OP_ABORT:{ return MATCH_ERROR; } case OP_NAME:{ uint16_t name = NEXT_ARG(); if (event_name(next_event) != name) return MATCH_FAIL; break; } case OP_SCREEN:{ uint16_t screen = NEXT_ARG(); if (event_screen(next_event) != screen) return MATCH_FAIL; break; } case OP_NEXT:{ return MATCH_NEXT; } case OP_MATCH:{ return MATCH_OK; } default:{ return MATCH_ERROR; } } } #undef NEXT_OP #undef NEXT_ARG }
Dans cette version simple, notre machine virtuelle correspond séquentiellement au modèle décrit par bytecode avec les événements entrants. En tant que tel, ce n'est tout simplement pas une comparaison très concise des préfixes de deux lignes: le modèle souhaité et la ligne d'entrée.
Les préfixes sont des préfixes, mais nous voulons trouver les modèles souhaités non seulement au début, mais aussi à un endroit arbitraire de la session. La solution naïve consiste à redémarrer la correspondance à partir de chaque événement de session. Mais cela implique une visualisation multiple de chacun des événements et de manger des bébés algorithmiques.
L'exemple du premier article de la série, en effet, simule le redémarrage d'une correspondance à l'aide de la restauration (retour arrière en anglais). Le code dans l'exemple semble, bien sûr, plus mince que celui donné ici, mais le problème n'a pas disparu: chacun des événements devra être vérifié plusieurs fois.
Vous ne pouvez pas vivre comme ça.
Moi encore moi et encore moi

Décrivons encore une fois le problème: nous devons faire correspondre le modèle avec les événements entrants, en commençant par chacun des événements en commençant une nouvelle comparaison. Alors pourquoi ne faisons-nous pas cela? Laissez la machine virtuelle marcher sur les événements entrants dans plusieurs threads!
Pour ce faire, nous devons obtenir une nouvelle entité - un flux. Chaque thread stocke un seul pointeur - vers l'instruction en cours:
typedef struct matcher_thread { uint8_t *ip; } matcher_thread;
Naturellement, maintenant dans la machine virtuelle elle-même, nous ne stockerons pas le pointeur explicite. Il sera remplacé par deux listes de fils (en savoir plus à leur sujet ci-dessous):
typedef struct matcher { uint8_t *bytecode; matcher_thread current_threads[MAX_THREAD_NUM]; uint8_t current_thread_num; matcher_thread next_threads[MAX_THREAD_NUM]; uint8_t next_thread_num; } matcher;
Et voici la boucle principale mise à jour:
match_result matcher_accept(matcher *m, uint32_t next_event) { #define NEXT_OP(thread) \ (*(thread).ip++) #define NEXT_ARG(thread) \ ((void)((thread).ip += 2), ((thread).ip[-2] << 8) + (thread).ip[-1]) /* - */ add_current_thread(m, initial_thread(m)); // for (size_t thread_i = 0; thread_i < m->current_thread_num; thread_i++ ) { matcher_thread current_thread = m->current_threads[thread_i]; bool thread_done = false; while (!thread_done) { uint8_t instruction = NEXT_OP(current_thread); switch (instruction) { case OP_ABORT:{ return MATCH_ERROR; } case OP_NAME:{ uint16_t name = NEXT_ARG(current_thread); // , , // next_threads, if (event_name(next_event) != name) thread_done = true; break; } case OP_SCREEN:{ uint16_t screen = NEXT_ARG(current_thread); if (event_screen(next_event) != screen) thread_done = true; break; } case OP_NEXT:{ // , .. // next_threads add_next_thread(m, current_thread); thread_done = true; break; } case OP_MATCH:{ return MATCH_OK; } default:{ return MATCH_ERROR; } } } } /* , */ swap_current_and_next(m); return MATCH_NEXT; #undef NEXT_OP #undef NEXT_ARG }
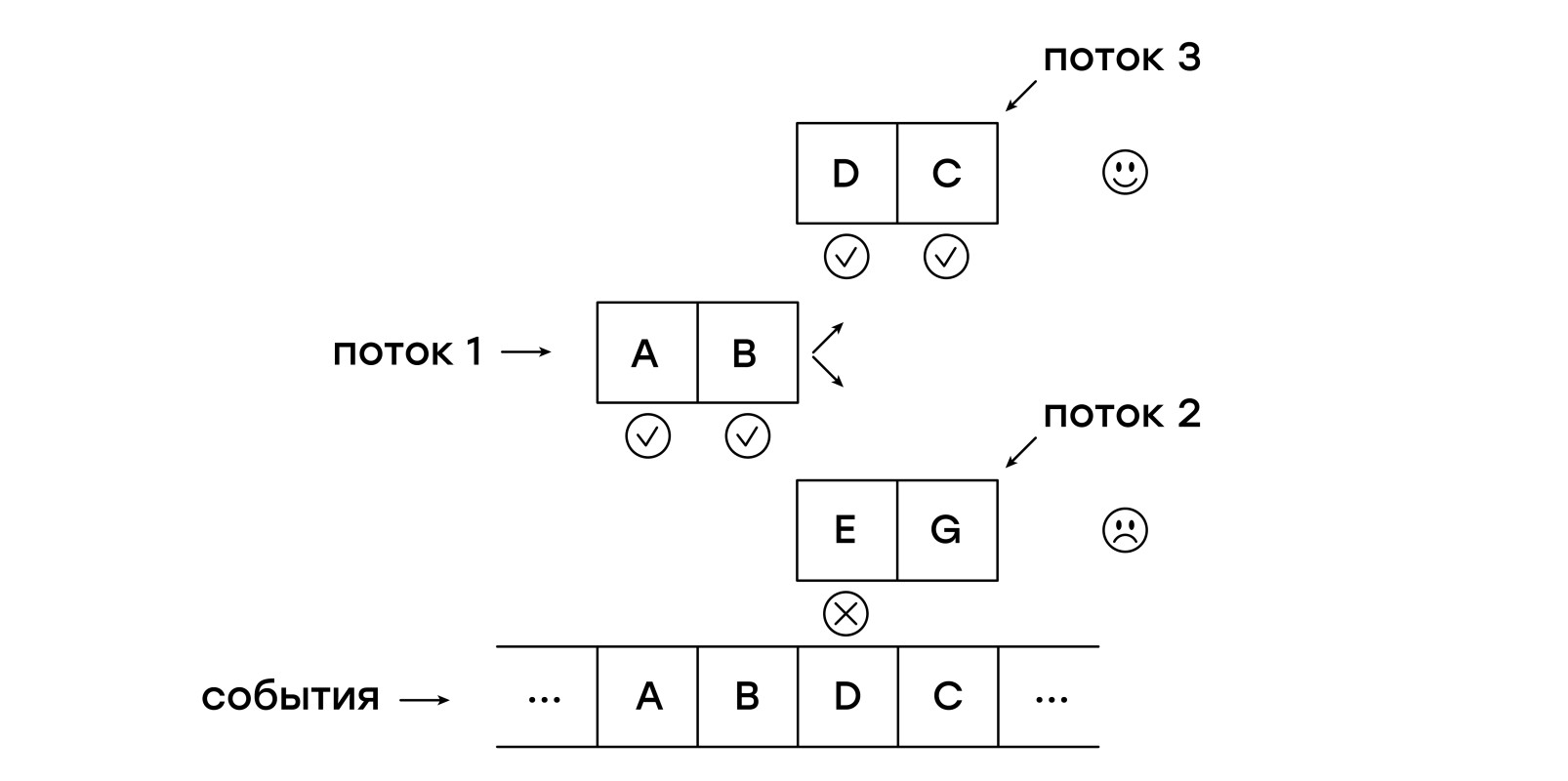
À chaque événement reçu, nous ajoutons d'abord un nouveau thread à la liste current_threads, vérifiant le modèle depuis le tout début, après quoi nous commençons à parcourir la liste current_threads, en suivant chaque pointeur en suivant les instructions.
Si une instruction NEXT est rencontrée, le thread est placé dans la liste next_threads, c'est-à-dire qu'il attend que l'événement suivant soit reçu.
Si le modèle de thread ne correspond pas à l'événement reçu, un tel thread n'est tout simplement pas ajouté à la liste next_threads.
L'instruction MATCH quitte immédiatement la fonction, signalant un code retour que le modèle correspond à la session.
Une fois l'analyse de la liste des threads terminée, les listes actuelle et suivante sont permutées.
En fait, c'est tout. Nous pouvons dire que nous faisons littéralement ce que nous voulions: en même temps, nous vérifions plusieurs modèles, lançant un nouveau processus de correspondance pour chacun des événements de session.
Identités et branches multiples dans les modèles
La recherche d'un modèle qui décrit une séquence linéaire d'événements est, bien sûr, utile, mais nous voulons obtenir des expressions régulières complètes. Et les flux que nous avons créés à l'étape précédente sont également utiles ici.
Supposons que nous voulions trouver une séquence de deux ou trois événements qui nous intéressent, quelque chose comme une expression régulière sur les lignes: "a? Bc". Dans cette séquence, le symbole "a" est facultatif. Comment l'exprimer en bytecode? C'est facile!
Nous pouvons commencer deux threads, un pour chaque cas: avec le symbole "a" et sans lui. Pour ce faire, nous introduisons une instruction supplémentaire (de type SPLIT addr1, addr2), qui démarre deux threads à partir des adresses spécifiées. En plus de SPLIT, JUMP nous est également utile, qui continue simplement l'exécution avec l'instruction spécifiée dans l'argument direct:
typedef enum matcher_opcode { OP_ABORT, OP_NAME, OP_SCREEN, OP_NEXT,
La boucle elle-même et le reste des instructions ne changent pas - nous introduisons simplement deux nouveaux gestionnaires:
Notez que les instructions ajoutent des threads à la liste actuelle, c'est-à-dire qu'elles continuent de fonctionner dans le contexte de l'événement en cours. Le thread dans lequel la branche s'est produite n'entre pas dans la liste des threads suivants.
La chose la plus surprenante dans cette machine virtuelle d'expression régulière est que nos threads et cette paire d'instructions sont suffisants pour exprimer presque toutes les constructions généralement acceptées lors de la correspondance de chaînes.
Expressions régulières sur les événements
Maintenant que nous avons une machine virtuelle et des outils appropriés, nous pouvons réellement gérer la syntaxe de nos expressions régulières.
L'enregistrement manuel des opcodes pour des programmes plus sérieux se fatigue rapidement. La dernière fois, je n'ai pas fait de parseur à part entière, mais l'utilisateur true-grue a montré les capacités de sa bibliothèque raddsl en utilisant le mini-langage PigletC comme exemple . J'ai été tellement impressionné par la brièveté du code qu'avec l'aide de raddsl j'ai écrit un petit compilateur d'expressions régulières de chaînes en cent ou deux cents en Python. Le compilateur et les instructions pour son utilisation sont sur GitHub. Le résultat du compilateur en langage assembleur est compris par un utilitaire qui lit deux fichiers (un programme pour une machine virtuelle et une liste des événements de session pour vérification).
Pour commencer, nous nous limitons au type et au contexte de l'événement. Le type d'événement est désigné par un seul numéro; si vous devez spécifier un contexte, spécifiez-le via deux points. L'exemple le plus simple:
> python regexp/regexp.py "13" # , 13 NEXT NAME 13 MATCH
Maintenant un exemple avec contexte:
python regexp/regexp.py "13:12" # 13, 12 NEXT NAME 13 SCREEN 12 MATCH
Les événements successifs doivent être séparés d'une manière ou d'une autre (par exemple, par des espaces):
> python regexp/regexp.py "13 11 10:9" 08:40:52 NEXT NAME 13 NEXT NAME 11 NEXT NAME 10 SCREEN 9 MATCH
Modèle plus intéressant:
> python regexp/regexp.py "12|13" SPLIT L0 L1 L0: NEXT NAME 12 JUMP L2 L1: NEXT NAME 13 L2: MATCH
Faites attention aux lignes se terminant par deux points. Ce sont des balises. L'instruction SPLIT crée deux threads qui continuent leur exécution à partir des étiquettes L0 et L1, et JUMP à la fin de la première branche d'exécution passe simplement à la fin de la branche.
Vous pouvez choisir entre des chaînes d'expressions plus véritablement en regroupant les sous-séquences entre parenthèses:
> python regexp/regexp.py "(1 2 3)|4" SPLIT L0 L1 L0: NEXT NAME 1 NEXT NAME 2 NEXT NAME 3 JUMP L2 L1: NEXT NAME 4 L2: MATCH
Un événement arbitraire est indiqué par un point:
> python regexp/regexp.py ". 1" NEXT NEXT NAME 1 MATCH
Si nous voulons montrer que la sous-séquence est facultative, nous mettons un point d'interrogation après:
> python regexp/regexp.py "1 2 3? 4" NEXT NAME 1 NEXT NAME 2 SPLIT L0 L1 L0: NEXT NAME 3 L1: NEXT NAME 4 MATCH
Bien sûr, plusieurs répétitions régulières (plus ou astérisque) sont également courantes dans les expressions régulières:
> python regexp/regexp.py "1+ 2" L0: NEXT NAME 1 SPLIT L0 L1 L1: NEXT NAME 2 MATCH
Ici, nous exécutons simplement l'instruction SPLIT plusieurs fois, en démarrant de nouveaux threads à chaque cycle.
De même avec un astérisque:
> python regexp/regexp.py "1* 2" L0: SPLIT L1 L2 L1: NEXT NAME 1 JUMP L0 L2: NEXT NAME 2 MATCH

Perspective
D'autres extensions de la machine virtuelle décrite peuvent être utiles.
Par exemple, il peut facilement être développé en vérifiant les attributs d'événement. Pour un système réel, je suppose d'utiliser une syntaxe comme «1: 2 {3: 4, 5:> 3}», ce qui signifie: événement 1 dans le contexte 2 avec l'attribut 3 ayant la valeur 4 et la valeur d'attribut 5 supérieure à 3. Attributs ici vous pouvez simplement le passer dans un tableau à la fonction matcher_accept.
Si vous passez également l'intervalle de temps entre les événements à matcher_accept, vous pouvez ajouter une syntaxe au langage de modèle qui vous permet de sauter le temps entre les événements: "1 mindelta (120) 2", ce qui signifie: événement 1, puis l'intervalle est d'au moins 120 secondes, événement 2 Combiné à la préservation d'une sous-séquence, cela vous permet de collecter des informations sur le comportement de l'utilisateur entre deux sous-séquences d'événements.
D'autres éléments utiles qui sont relativement faciles à ajouter sont: la préservation des sous-séquences d'expressions régulières, la séparation des astérisques avides et ordinaires et des opérateurs plus, etc. En termes de théorie des automates, notre machine virtuelle est un automate fini non déterministe, pour la mise en œuvre duquel il n'est pas difficile de faire de telles choses.
Conclusion
Notre système est développé pour des interfaces utilisateur rapides, donc le moteur de stockage de session est auto-écrit et optimisé spécifiquement pour le passage à travers toutes les sessions. Tous les milliards d'événements divisés en sessions sont vérifiés par rapport aux modèles en quelques secondes sur un seul serveur.
Si la vitesse n'est pas si critique pour vous, alors un système similaire peut être conçu comme une extension pour un système de stockage de données plus standard comme une base de données relationnelle traditionnelle ou un système de fichiers distribué.
Soit dit en passant, dans les dernières versions du standard SQL, une fonctionnalité similaire à celle décrite dans l'article est déjà apparue et des bases de données individuelles ( Oracle et Vertica ) l'ont déjà implémentée. Yandex ClickHouse, à son tour, implémente son propre langage de type SQL, mais il a également des fonctions similaires .
En me distrayant des événements et des expressions régulières, je tiens à répéter que l'applicabilité des machines virtuelles est beaucoup plus large qu'il n'y paraît à première vue. Cette technique est appropriée et largement utilisée dans tous les cas où il est nécessaire de distinguer clairement entre les primitives que le moteur système comprend et le sous-système "avant", c'est-à-dire, par exemple, certains DSL ou langage de programmation.
Ceci conclut une série d'articles sur les diverses utilisations des interprètes de bytecode et des machines virtuelles. J'espère que les lecteurs de Habr ont aimé la série et, bien sûr, je serai heureux de répondre à toutes les questions sur le sujet.
Les interprètes de bytecode pour les langages de programmation sont un sujet spécifique, et il y a relativement peu de littérature à leur sujet. Personnellement, j’ai aimé le livre de Ian Craig, Virtual Machines, bien qu’il ne décrive pas tant l’implémentation des interprètes que des machines abstraites - des modèles mathématiques qui sous-tendent divers langages de programmation.
Dans un sens plus large, un autre livre est consacré aux machines virtuelles - «Machines virtuelles: plates-formes flexibles pour systèmes et processus» («Machines virtuelles: plates-formes polyvalentes pour systèmes et processus»). Il s'agit d'une introduction aux différentes applications de la virtualisation, couvrant la virtualisation des langages, des processus et des architectures informatiques en général.
Les aspects pratiques du développement de moteurs d'expression régulière sont rarement discutés dans la littérature de compilation populaire. The Pig Match et l'exemple du premier article sont basés sur les idées d'une étonnante série d'articles de Russ Cox, l'un des développeurs du moteur Google RE2.
La théorie des expressions régulières est présentée dans tous les manuels universitaires sur les compilateurs. Il est habituel de se référer au fameux "Dragon Book" , mais je recommanderais de commencer par le lien ci-dessus.
En travaillant sur cet article, j'ai d'abord utilisé un système intéressant pour le développement rapide de compilateurs pour Python raddsl , qui appartient à la plume de l'utilisateur true-grue (merci, Peter!). Si vous êtes confronté à la tâche de prototyper un langage ou de développer rapidement une sorte de DSL, vous devriez y prêter attention.