Un quintette est un moyen d'enregistrer des données atomiques indiquant leur rôle dans nos vies. Les quintettes peuvent décrire toutes les données, tandis que chacun d'eux contient des informations exhaustives sur vous-même et sur les relations avec d'autres quintettes. Il représente les termes du domaine, quelle que soit la plateforme utilisée. Sa tâche est de simplifier le stockage des données et d'améliorer la visibilité de leur présentation.

Je parlerai d'une nouvelle approche de stockage et de traitement des informations et partagerai mes réflexions sur la création d'une plateforme de développement dans ce nouveau paradigme.
Le quintette a des propriétés: type, valeur, parent, ordre entre frères. Avec l'identifiant, seuls 5 composants sont obtenus. Il s'agit de la forme universelle la plus simple d'enregistrement des informations, une nouvelle norme qui pourrait potentiellement convenir à tout le monde. Les quintettes sont stockés dans un système de fichiers d'une structure unique, dans un champ d'information indexé monotone continu.
Pour enregistrer des informations, il existe un nombre infini de normes, d'approches et de règles, dont la connaissance est nécessaire pour travailler avec ces enregistrements. Les normes sont décrites séparément et ne se rapportent pas directement aux données. Dans le cas des quintettes, en prenant l'un d'entre eux, vous pouvez obtenir des informations pertinentes sur sa nature, ses propriétés et ses règles de travail avec son domaine. Sa norme est uniforme et inchangée pour tous les domaines. Le quintette est caché à l'utilisateur - les métadonnées et les données sont à sa disposition sous la forme familière à beaucoup.
Un quintette n'est pas seulement une information, mais aussi une commande exécutable. Mais surtout, ce sont les données que vous souhaitez stocker, enregistrer et récupérer. Comme dans notre cas ils sont directement adressés, connectés et indexés, nous les stockerons dans une sorte de base de données. Pour tester le prototype d'un système de stockage de données de quintet, par exemple, nous avons utilisé une base de données relationnelle régulière.
Structure du quintette
L'idée principale de cet article est de remplacer les types de machines par des termes humains et de remplacer les variables par des objets. Pas par les objets qui ont besoin d'un constructeur, d'un destructeur, d'interfaces et d'un garbage collector, mais par des unités d'informations en cristal pur sur lesquelles un client opère. Autrement dit, si le client dit "Application", alors pour sauvegarder l'
essentiel de ces informations sur les médias ne nécessiterait pas l'expertise d'un programmeur.
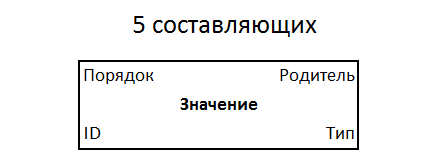
Il est utile de concentrer l'attention de l'utilisateur uniquement sur la valeur de l'objet, et son type, parent, ordre (entre égaux en subordination) et identificateur doivent être évidents d'après le contexte ou simplement cachés. Cela signifie que l'
utilisateur ne sait rien du tout sur les quintettes , il définit simplement sa tâche, s'assure qu'elle est correctement acceptée, puis démarre son exécution.
Concepts de base
Il existe un ensemble de types de données que tout le monde peut comprendre: chaîne, nombre, fichier, texte, date, etc. Un ensemble aussi simple est tout à fait suffisant pour formuler le problème et pour le «programmer» et les types nécessaires à sa mise en œuvre. Les types de base représentés par des quintets peuvent ressembler à ceci:

Dans ce cas, certains des composants du quintette ne sont pas utilisés et il est utilisé comme type de base. Cela facilite la navigation au cœur du système lors de la navigation dans les métadonnées.
Contexte
En raison de l'écart analytique entre l'utilisateur et le programmeur, une déformation importante des concepts se produit au stade de la définition du problème. L'euphémisme, l'incompréhensibilité et l'initiative non sollicitée transforment souvent une pensée simple et compréhensible du client en un mélange logiquement impossible, à en juger du point de vue de l'utilisateur.

Le transfert de connaissances doit se produire sans perte ni distorsion. De plus, à l'avenir, lors de l'organisation du stockage de ces connaissances, il est nécessaire de se débarrasser des restrictions imposées par le système de gestion des données sélectionné.
Comment stocker des données
En règle générale, il existe de nombreuses bases de données sur le serveur; chacune d'entre elles contient une description de la structure de l'entité avec un ensemble spécifique d'attributs - des données interconnectées. Ils sont stockés dans un ordre spécifique, idéalement optimal pour l'échantillonnage.
Le système de stockage d'informations proposé est un compromis entre diverses méthodes bien connues: colonne, chaîne et NoSQL. Il est conçu pour résoudre les tâches généralement effectuées par l'une de ces méthodes.
Par exemple, la théorie des bases de colonnes est magnifique: nous lisons uniquement la colonne souhaitée et pas toutes les lignes d'enregistrements dans leur ensemble. Cependant, dans la pratique, il est peu probable que des données soient placées sur les médias de sorte qu'elles soient applicables à des dizaines de sections différentes de l'analyse. Notez que les attributs et les mesures analytiques peuvent être ajoutés et supprimés, parfois plus rapidement que nous ne pouvons reconstruire cette économie de colonne. Sans oublier le fait que les données de la base de données peuvent être ajustées, ce qui violera également la beauté du plan d'échantillonnage en raison de la fragmentation inévitable.
Métadonnées
Nous avons introduit un concept - un terme - pour décrire tous les objets avec lesquels nous opérons: entité, propriété, requête, fichier, etc. Nous définirons tous les termes que nous utilisons dans notre domaine. Et avec leur aide, nous décrirons toutes les entités qui ont des détails, y compris sous la forme de relations entre les entités. Par exemple, accessoires - un lien vers une entrée du répertoire d'état. Le terme est écrit dans un quintet de données.
Un ensemble de descriptions de termes sont des métadonnées qui définissent la structure des tables et des champs dans une base de données régulière. Par exemple, il existe la structure de données suivante: une application à partir d'une date qui a du contenu (texte d'application) et un statut, auquel les participants au processus de production ajoutent des commentaires indiquant la date. Dans le constructeur de base de données traditionnel, cela ressemblera à ceci:

Puisque nous avons décidé de cacher à l'utilisateur tous les détails non essentiels, tels que les ID de liaison, par exemple, le schéma sera quelque peu simplifié: les mentions des ID sont supprimées et les noms des entités et leurs valeurs clés sont combinés.
L'utilisateur «dessine» la tâche: une requête à partir de la date d'aujourd'hui qui a un état (valeur de référence) et à laquelle vous pouvez ajouter des commentaires indiquant la date:

Maintenant, nous voyons 6 champs de données différents au lieu de 9, et l'ensemble du schéma nous propose de lire et de comprendre 7 mots au lieu de 13. Bien que ce soit loin d'être le principal, bien sûr.
Voici les quintets générés par le noyau de contrôle pour décrire cette structure:

Des explications à la place des valeurs de quintette surlignées en gris sont fournies pour plus de clarté. Ces champs ne sont pas remplis car toutes les informations nécessaires sont uniquement déterminées par les composants restants.
Découvrez comment les quintettes sont liés Données utilisateur
Pensez à stocker un tel ensemble de données pour la tâche ci-dessus:

Les données elles-mêmes sont stockées dans des quintets selon la structure indiquant l'appartenance à certains termes sous la forme d'un tel ensemble:
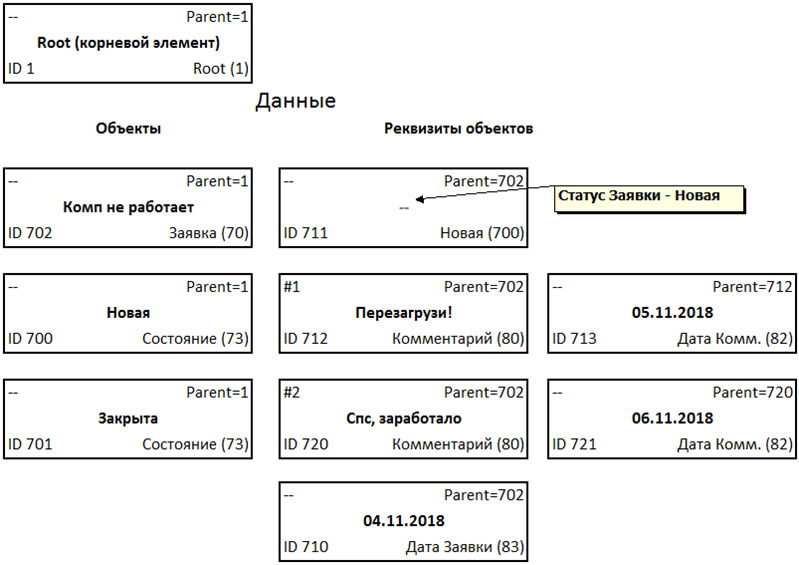
Nous voyons une structure hiérarchique familière qui est stockée à l'aide de la méthode aka Adjacency List.
Performances
L'exemple ci-dessus est très simple, mais que se passera-t-il lorsque la structure sera des milliers de fois plus complexe et que les données seront en gigaoctets?
Nous aurons besoin de:
- La structure hiérarchique considérée ci-dessus est de 1 pc.
- Arbre B pour la recherche par ID, parent et type - 3 pièces.
Ainsi, tous les enregistrements de notre base de données seront indexés, y compris les données et les métadonnées. Une telle indexation est nécessaire pour préserver les propriétés d'une base de données relationnelle - l'outil le plus simple et le plus populaire. L'index parent est en fait composite (ID parent + type). Un index par type est également composite (type + valeur) pour une recherche rapide des objets d'un type donné.
Les métadonnées nous permettent de nous débarrasser de la récursivité: par exemple, pour trouver tous les détails d'un objet donné, nous utilisons l'index par ID parent. Si vous devez rechercher des objets d'un certain type, un index par ID de type est utilisé. Un type est un analogue d'un nom de table et d'un champ dans un SGBD relationnel.

Dans tous les cas, nous n'analysons pas l'ensemble des données, et même avec un grand nombre de valeurs de tout type, la valeur souhaitée peut être trouvée en un petit nombre d'étapes.
La base de la plateforme de développement
En soi, une telle base de données n'est pas autosuffisante pour la programmation d'applications et n'est pas complète, comme on dit, selon Turing. Mais nous ne parlons pas ici uniquement de la base de données, mais essayons de couvrir tous les aspects: les objets sont, entre autres, des algorithmes de contrôle arbitraires qui peuvent être lancés, et ils fonctionneront.
En conséquence, au lieu de structures de bases de données complexes et de codes source d'algorithmes de contrôle stockés séparément, nous obtenons un champ d'information uniforme, limité par le volume du support et marqué par des métadonnées. Les données elles-mêmes sont présentées à l'utilisateur d'une manière qu'il comprend - la structure du domaine et les entrées correspondantes. L'utilisateur modifie arbitrairement la structure et les données, y compris en effectuant des opérations en masse avec eux.
Nous n'avons rien inventé de nouveau: toutes les données sont déjà stockées dans le système de fichiers et leur recherche s'effectue à l'aide d'arbres B, dans le système de fichiers, dans les bases de données. Nous venons de réorganiser la présentation des données pour les rendre plus faciles et plus visuelles à travailler avec.
Pour travailler avec cette représentation de données, vous aurez besoin d'un noyau très compact - notre moteur de base de données est d'un ordre de grandeur plus petit que le BIOS de l'ordinateur, et, par conséquent, il peut être fait sinon en matériel, puis au moins aussi vite et aussi léché que possible. Pour des raisons de sécurité, il est également en lecture seule.
En ajoutant une nouvelle classe à l'assemblage de mon .Net bien-aimé, nous pouvons observer la perte de 200-300 Mo de RAM uniquement pour la description de cette classe. Ces mégaoctets ne rentreront pas dans le cache du bon niveau, ce qui entraînera le système dans un désordre avec les conséquences qui en découlent. Une situation similaire avec Java. Décrire la même classe avec des quintets prendra des dizaines ou des centaines d'octets, car la classe n'utilise que des astuces primitives pour travailler avec des données qui sont déjà familières au noyau.
Comment gérer différents formats: SGBDR, NoSQL, bases de colonnesL'approche décrite couvre deux domaines principaux: RDBMS et NoSQL. Lors de la résolution de problèmes qui tirent parti des bases de données en colonnes, nous devons indiquer au noyau que certains objets doivent être stockés, en tenant compte de l'optimisation de l'échantillonnage de masse des valeurs d'un certain type de données (notre terme). Ainsi, le noyau pourra placer les données sur le disque de la manière la plus rentable.
Ainsi, pour la base de la colonne, nous pouvons économiser de manière significative l'espace occupé par les quintettes: utilisez uniquement un ou deux de ses composants pour stocker des données utiles au lieu de cinq, et utilisez également l'index uniquement pour indiquer le début des chaînes de données. Dans de nombreux cas, seul l'indice sera utilisé pour les échantillons de notre base de colonnes analogiques, sans avoir besoin d'accéder aux données de la table elle-même.
Il convient de noter que l'idée n'a pas pour objectif de collecter tous les développements avancés de ces trois types de bases de données. Au contraire, le moteur du nouveau système sera réduit autant que possible, n'incarnant que le minimum de fonctions nécessaires - tout ce qui couvre les requêtes DDL et DML dans le concept décrit ici.
Paradigme de programmation
L'utilisation de l'approche décrite ne se limite pas aux quintettes, mais promeut un paradigme différent de celui auquel les programmeurs sont habitués. Au lieu d'un langage impératif, déclaratif ou objet, le langage de requête est proposé comme plus familier aux humains et nous permettant de définir la tâche directement sur l'ordinateur, en contournant les programmeurs et la couche impénétrable des environnements de développement existants.
Bien entendu, un traducteur d'une langue utilisateur gratuite vers une langue d'exigences claires sera toujours nécessaire dans la plupart des cas.Ce sujet sera décrit plus en détail dans des articles séparés avec des exemples et des développements existants.
Donc, en bref, cela fonctionne comme suit:
- Nous avons décrit une fois avec des quintets les types de données primitifs: chaîne, nombre, fichier, texte et autres, et avons également formé le noyau à travailler avec eux. La formation se réduit à la présentation correcte des données et à la mise en œuvre d'opérations simples avec elles.
- Nous décrivons maintenant en quintets les termes utilisateur (types de données) - sous la forme de métadonnées. La description revient à spécifier un type de données primitif pour chaque type d'utilisateur et à déterminer la subordination.
- Saisissez les quintettes de données selon la structure spécifiée par les métadonnées. Chaque quintet de données contient un lien vers son type et son parent, ce qui vous permet de le trouver rapidement dans l'entrepôt de données.
- Les tâches principales se résument à récupérer des données et à effectuer des opérations simples avec elles pour implémenter des algorithmes arbitrairement complexes décrits par l'utilisateur.
- L'utilisateur gère les données et les algorithmes à l'aide d'une interface visuelle qui présente visuellement le premier et le second.
L'intégralité de l'ensemble du système est assurée par la réalisation des exigences de base: le noyau peut effectuer des opérations séquentielles, effectuer des branchements conditionnels, traiter des ensembles de données et arrêter le travail lorsqu'un certain résultat est atteint.
Pour une personne, l'avantage est la simplicité de perception, par exemple, au lieu de déclarer un cycle impliquant des variables
for (i=0; i<length(A); i++) if A[i] meets a condition do something with A[i]
une construction plus humaine est utilisée, comme
with every A, that match a condition, do something
Nous rêvons de faire abstraction des subtilités de bas niveau de la mise en œuvre d'un système d'information: boucles, constructeurs, fonctions, manifestes, bibliothèques - tout cela prend trop de place dans le cerveau d'un programmeur, laissant peu de place au travail créatif et au développement.
Mise à l'échelle
Une application moderne est inconcevable sans moyen de mise à l'échelle: une capacité illimitée à étendre la capacité de charge d'un système d'information est requise. Dans l'approche décrite, compte tenu de l'extrême simplicité de l'organisation des données, la mise à l'échelle s'avère ne pas être organisée plus compliquée que dans les architectures existantes.
Dans l'exemple ci-dessus avec des applications, vous pouvez les séparer, par exemple, par leur ID, ce qui rend la génération d'ID avec des octets élevés fixes pour différents serveurs. Autrement dit, lorsque vous utilisez 32 bits pour le stockage d'ID, les deux ou trois bits les plus importants, selon les besoins, indiqueront le serveur sur lequel ces applications sont stockées. Ainsi, chaque serveur aura son propre pool d'ID.
Le cœur d'un serveur unique peut fonctionner indépendamment des autres serveurs, sans rien savoir d'eux. Lors de la création d'une application, une priorité élevée sera accordée au serveur avec le nombre minimum d'ID utilisés, garantissant une répartition uniforme de la charge.
Étant donné un ensemble limité de variations possibles des demandes et des réponses avec une seule organisation de données, vous aurez besoin d'un répartiteur assez compact qui distribue les demandes sur les serveurs et agrège leurs résultats.