Avez-vous remarqué comment un créneau de marché, devenu populaire, attire de peur les spécialistes du marketing de la sécurité de l'information? Ils vous convainquent qu'en cas de cyberattaque, l'entreprise ne pourra faire face à aucune des tâches pour répondre à l'incident. Et ici, bien sûr, un aimable assistant apparaît - un fournisseur de services qui est prêt pour un certain montant à sauver le client de tout tracas et de la nécessité de prendre des décisions. Nous expliquons pourquoi une telle approche peut être dangereuse non seulement pour le portefeuille, mais aussi pour le niveau de sécurité de l'entreprise, quels avantages pratiques la participation d'un prestataire de services peut-elle apporter et quelles décisions doivent toujours rester dans le domaine de responsabilité du client.

Tout d'abord, nous traiterons de la terminologie. En matière de gestion des incidents, on entend souvent deux abréviations, SOC et CSIRT, dont l'importance est importante à comprendre pour éviter les manipulations marketing.
SOC (Security Operations Center) - une unité dédiée aux tâches opérationnelles de sécurité de l'information. Le plus souvent, lorsque l'on parle des fonctions du SOC, les gens signifient surveiller et identifier les incidents. Cependant, la responsabilité du SOC comprend généralement toutes les tâches liées aux processus de sécurité de l'information, y compris la réponse et l'élimination des conséquences des incidents, les activités méthodologiques pour améliorer l'infrastructure informatique et augmenter le niveau de sécurité de l'entreprise. Dans le même temps, le SOC est souvent une unité de personnel indépendante, comprenant des spécialistes de différents profils.
CSIRT (équipe de réponse aux incidents de cybersécurité) - un groupe / une équipe ou une unité formée temporairement chargée de répondre aux incidents émergents. Le CSIRT a généralement une dorsale permanente, composée de professionnels de la sécurité de l'information, d'administrateurs de SZI et d'un groupe de juricomptables. Cependant, la composition finale de l'équipe dans chaque cas est déterminée par le vecteur de menace et peut être complétée par le service informatique, les propriétaires de systèmes d'entreprise et même la direction de l'entreprise avec un service de relations publiques (pour niveler le fond négatif dans les médias).
Malgré le fait que dans ses activités, le CSIRT est le plus souvent guidé par la norme NIST, qui comprend un cycle complet de gestion des incidents, actuellement, dans l'espace marketing, l'accent est plus souvent mis sur les activités de réponse, refusant cette fonction au SOC et contrastant ces deux termes.
Le concept de SOC est-il plus large par rapport au CSIRT? À mon avis, oui. Dans ses activités, le SOC ne se limite pas aux incidents, il peut s'appuyer sur des données de cyber-intelligence, des prévisions et des analyses du niveau de sécurité de l'organisation et inclure des tâches de sécurité plus larges.
Mais revenons à la norme NIST, comme l'une des approches les plus populaires qui décrivent la procédure et les phases de la gestion des incidents. La procédure générale de la norme NIST SP 800-61 est la suivante:
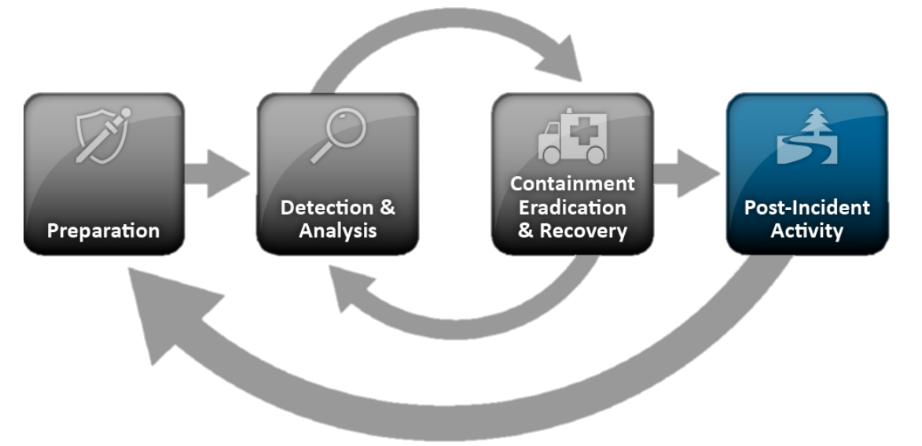
- Préparation:
- Création de l'infrastructure technique nécessaire pour gérer les incidents
- Créer des règles de détection des incidents
- Identification et analyse des incidents:
- Suivi et identification
- Analyse d'incident
- Priorisation
- Alerte
- Localisation, neutralisation et récupération:
- Localisation des incidents
- Collecte, stockage et documentation des signes d'incident
- Atténuation des catastrophes
- Récupération après incident
- Activité méthodique:
- Résumé de l'incident
- Base de connaissances Fill + Threat Intelligence
- Mesures organisationnelles et techniques
Malgré le fait que la norme NIST soit dédiée à la réponse aux incidents, une partie importante de la réponse est occupée par la section "Détection et analyse des incidents", qui décrit en fait les tâches classiques de surveillance et de traitement des incidents. Pourquoi leur accorde-t-on une telle attention? Pour répondre à la question, examinons de plus près chacun de ces blocs.
La préparation
La tâche d'identification des incidents commence par la création et «l'atterrissage» d'un modèle de menace et d'un modèle d'intrus sur les règles d'identification des incidents. Vous pouvez détecter les incidents en analysant les événements de sécurité des informations (journaux) à partir de divers outils de protection des informations, des composants de l'infrastructure informatique, des systèmes d'application, des éléments des systèmes technologiques (ACS) et d'autres ressources d'informations. Bien sûr, vous pouvez le faire manuellement, avec des scripts, des rapports, mais pour une détection efficace en temps réel des incidents de sécurité de l'information, des solutions spécialisées sont toujours nécessaires.
Les systèmes SIEM viennent à la rescousse ici, mais leur fonctionnement n'est pas moins une quête que l'analyse des logs "bruts", et à chaque étape, de la connexion des sources à la création des règles d'incidents. Les difficultés sont liées au fait que les événements provenant de différentes sources doivent avoir une apparence uniforme, et les paramètres clés des événements doivent correspondre aux mêmes champs d'événements dans SIEM, quelle que soit la classe / le fabricant du système ou du matériel.
Les règles de détection des incidents, les listes d'indicateurs de compromis, les tendances des cybermenaces forment le soi-disant «contenu» du SIEM. Il doit effectuer les tâches de collecte de profils d'activité du réseau et des utilisateurs, de collecte de statistiques sur les événements de différents types et d'identification des incidents de sécurité des informations typiques. La logique de déclenchement des règles de détection des incidents doit tenir compte de l'infrastructure et des processus commerciaux particuliers d'une entreprise particulière.
Comme il n'y a pas d'infrastructure standard de l'entreprise et des processus commerciaux qui s'y déroulent, il ne peut donc pas y avoir de contenu unifié du système SIEM. Par conséquent, tous les changements dans l'infrastructure informatique de l'entreprise doivent être reflétés en temps opportun à la fois dans les paramètres et le réglage des équipements de sécurité, et dans SIEM. Si le système n'a été configuré qu'une seule fois, au début de la prestation de services, ou est mis à jour une fois par an, cela réduit les chances de détecter les incidents militaires et de filtrer avec succès les faux positifs plusieurs fois.
Ainsi, la configuration des fonctions de sécurité, la connexion des sources au système SIEM et l'adaptation du contenu SIEM sont des tâches primordiales dans la réponse aux incidents, une base sans laquelle il est impossible de continuer. Après tout, si l'incident n'a pas été enregistré en temps opportun et n'est pas passé par les phases d'identification et d'analyse, nous ne parlons plus de réponse, nous ne pouvons que travailler avec ses conséquences.
Détection et analyse des incidents
Le service de surveillance doit travailler avec les incidents en mode temps réel 24h / 24 et 7j / 7. Cette règle, comme les bases de la sécurité, est écrite dans le sang: environ la moitié des cyberattaques critiques commencent la nuit, très souvent vendredi (ce fut le cas, par exemple, avec le virus rançongiciel WannaCry). Si vous ne prenez pas de mesures de protection dans la première heure, il peut déjà être ringard trop tard. Dans ce cas, transférez simplement tous les incidents enregistrés à l'étape suivante décrite dans la norme NIST, c'est-à-dire au stade de la localisation, c'est peu pratique, et voici pourquoi:
- Obtenir des informations supplémentaires sur ce qui se passe ou filtrer un faux positif est plus facile et plus correct au stade de l'analyse, plutôt que de localiser l'incident. Cela vous permet de minimiser le nombre d'incidents référés aux prochaines étapes du processus de réponse aux incidents, où des spécialistes de haut niveau doivent être impliqués dans leur prise en compte - gestionnaires de la gestion des incidents, équipes d'intervention, systèmes informatiques et administrateurs SIS. Il est plus logique de construire le processus de manière à ne pas faire remonter chaque bagatelle, y compris les faux positifs, au niveau CISO.
- La réponse et la «suppression» d'un incident comportent toujours des risques commerciaux. La réponse à un incident peut inclure des efforts pour bloquer les accès suspects, isoler l'hôte et atteindre le niveau de leadership. Dans le cas d'un faux positif, chacune de ces étapes affectera directement la disponibilité des éléments d'infrastructure et forcera l'équipe de gestion des incidents à «éteindre» leur propre escalade pendant une longue période avec des rapports et des mémos de plusieurs pages.
Habituellement, la première ligne d'ingénieurs travaille dans le service de surveillance 24/7, qui sont directement impliqués dans le traitement des incidents potentiels enregistrés par le système SIEM. Le nombre de ces incidents peut atteindre plusieurs milliers par jour (encore une fois - d'autant plus au stade de la localisation?), Mais heureusement, la plupart d'entre eux s'inscrivent dans des schémas bien connus. Par conséquent, pour augmenter la vitesse de leur traitement, vous pouvez utiliser des scripts et des instructions qui décrivent pas à pas les actions nécessaires.
Il s'agit d'une pratique éprouvée qui permet de réduire la charge sur la ligne 2 et la ligne 3 des analystes - ils ne seront transférés que les incidents qui ne correspondent à aucun des scripts existants. Sinon, soit l'escalade des incidents sur les deuxième et troisième lignes de surveillance atteindra 80%, soit sur la première ligne, il faudra mettre des spécialistes coûteux avec une grande expertise et une longue période de formation.
Ainsi, en plus des employés de première ligne, des analystes et des architectes sont nécessaires pour créer des scripts et des instructions, former des spécialistes de première ligne, créer du contenu dans SIEM, connecter les sources, maintenir l'opérabilité et intégrer SIEM aux systèmes de classe IRP, CMDB et plus encore.
Une tâche de surveillance importante est la recherche, le traitement et la mise en œuvre de diverses bases de réputation, rapports APT, newsletters et abonnements dans le système SIEM, qui se transforment finalement en indicateurs de compromis (IoC). Ce sont eux qui permettent d'identifier les attaques secrètes des attaquants sur l'infrastructure, les malwares non détectés par les éditeurs d'antivirus, et bien plus encore. Cependant, comme pour connecter des sources d'événements au système SIEM, l'ajout de toutes ces informations sur les menaces nécessite d'abord de résoudre un certain nombre de tâches:
- Automatisation de l'ajout d'indicateurs
- Évaluation de leur applicabilité et de leur pertinence
- Priorisation et prise en compte de l'obsolescence des informations
- Et le plus important - une compréhension des moyens de protection que vous pouvez obtenir des informations pour vérifier ces indicateurs. Si tout est assez simple avec ceux du réseau - vérifier les pare-feu et les proxy, alors avec les hôtes c'est plus difficile - avec quoi comparer les hachages, comment sur tous les hôtes pour vérifier les processus en cours, les branches de registre et les fichiers écrits sur le disque dur?
Ci-dessus, je n'ai abordé qu'une partie des aspects du processus de surveillance et d'analyse des incidents auxquels toute entreprise élaborant un processus de réponse aux incidents devra faire face. À mon avis, c'est la tâche la plus importante de tout le processus, mais passons à l'unité de travail avec des incidents de sécurité de l'information déjà enregistrés et analysés.
Localisation, neutralisation et récupération
Ce bloc, selon certains experts en sécurité de l'information, est le facteur déterminant dans la différence entre l'équipe de surveillance et l'équipe de réponse aux incidents. Examinons de plus près ce que le NIST y met.
Localisation des incidents
Selon le NIST, la tâche principale du processus de localisation des incidents est de développer une stratégie, c'est-à-dire de déterminer des mesures pour empêcher la propagation de l'incident au sein de l'infrastructure de l'entreprise. Le complexe de ces mesures peut comprendre diverses actions - isoler les hôtes impliqués dans l'incident au niveau du réseau, changer de mode de fonctionnement des outils de protection des informations et même arrêter les processus commerciaux de l'entreprise pour minimiser les dommages causés par l'incident. En fait, la stratégie est un playbook, composé d'une matrice d'actions en fonction du type d'incident.
La mise en œuvre de ces actions peut concerner le domaine de responsabilité du changement de support technique informatique, les propriétaires et administrateurs de systèmes (y compris les systèmes commerciaux), une entreprise sous-traitante tierce et le service de sécurité de l'information. Les actions peuvent être effectuées manuellement, par des composants EDR, et même des scripts auto-écrits utilisés par la commande.
Étant donné que les décisions prises à ce stade peuvent affecter directement les processus commerciaux de l'entreprise, la décision d'appliquer une stratégie spécifique dans la grande majorité des cas reste la tâche d'un responsable de la sécurité de l'information interne (impliquant souvent des propriétaires de systèmes commerciaux), et
cette tâche ne peut pas être externalisée. entreprise . Le rôle du prestataire de services de sécurité de l'information dans la localisation de l'incident se réduit à l'application opérationnelle de la stratégie choisie par le client.
Collecte, stockage et documentation des signes d'incident
Une fois que des mesures opérationnelles ont été prises pour localiser l'incident, une enquête approfondie doit être menée, rassemblant toutes les informations pour évaluer son ampleur. Cette tâche est divisée en deux sous-tâches:
- Transfert de données supplémentaires à l'équipe de surveillance, connexion de sources supplémentaires d'événements de sécurité des informations impliqués dans l'incident au système de collecte et d'analyse des événements.
- Connecter l'équipe de criminalistique pour analyser les images du disque dur, analyser les vidages de mémoire, les échantillons de logiciels malveillants et les outils utilisés par les cybercriminels dans cet incident.
Une personne devrait également être nommée pour coordonner les activités de toutes les unités dans le cadre de l'enquête sur l'incident. Ce spécialiste devrait avoir l'autorité et les contacts de tout le personnel impliqué dans l'enquête. Un employé contractuel peut-il jouer ce rôle? Plus probablement non que oui. Il est plus logique de confier ce rôle à un spécialiste ou au responsable du service de sécurité informatique du client.
Atténuation des catastrophes
Ayant reçu une image complète de l'incident de différents services, le coordinateur élabore des mesures pour éliminer les conséquences de l'incident. Cette procédure peut comprendre:
- Suppression des indicateurs de compromis identifiés et des traces de présence de malwares / intrus.
- "Recharger" les hôtes infectés et changer les mots de passe des utilisateurs.
- Installer les dernières mises à jour et développer des mesures compensatoires pour éliminer les vulnérabilités critiques utilisées dans l'attaque.
- Modification des profils de sécurité des SIG.
- Contrôle de l'intégralité des actions effectuées par les unités concernées et absence de re-compromis des systèmes par les intrus.
Lors de l'élaboration des mesures, nous recommandons que le coordinateur consulte les unités spécialisées responsables de systèmes spécifiques, les administrateurs du système de sécurité de l'information, le groupe de criminalistique et le service de surveillance des incidents SI. Mais, encore une fois, la décision finale sur l'application de certaines mesures est prise par le coordinateur du groupe d'analyse des incidents.
Récupération après incident
Dans cette section, le NIST parle en fait des tâches du service informatique et du service d'exploitation des systèmes d'entreprise. Tout le travail est réduit à la restauration et à la vérification des performances des systèmes informatiques et des processus métier de l'entreprise. Il n'est pas logique de s'attarder sur ce point, car la plupart des entreprises sont confrontées à la solution de ces problèmes, sinon à la suite d'incidents de sécurité de l'information, puis au moins après des défaillances qui se produisent périodiquement même dans les installations de systèmes les plus stables et les plus tolérantes aux pannes.
Activité méthodique
La quatrième section de la méthodologie de réponse aux incidents est consacrée au travail sur les bogues et à l'amélioration des technologies de sécurité de l'entreprise.
Pour la préparation d'un rapport d'incident, le remplissage de la base de connaissances et de TI, en règle générale, l'équipe de criminalistique est responsable en collaboration avec le service de surveillance. Si aucune stratégie de localisation n'a été développée à l'époque pour cet incident, son écriture est incluse dans ce bloc.
Eh bien, il est évident qu'un point très important dans le travail sur les bogues est de développer une stratégie pour prévenir des incidents similaires à l'avenir:
- Modification de l'architecture de l'infrastructure informatique et des SIG existants.
- L'introduction de nouveaux outils de sécurité de l'information.
- Introduction du processus de gestion des correctifs et de suivi des incidents de sécurité de l'information (en cas d'absence).
- Correction des processus d'affaires de l'entreprise.
- Dotation en personnel supplémentaire au département de la sécurité de l'information.
- Changement d'autorité des employés de la sécurité de l'information.
Rôle de fournisseur de services
Ainsi, la participation éventuelle du prestataire de services à différentes étapes de la réponse aux incidents peut être représentée sous la forme d'une matrice:
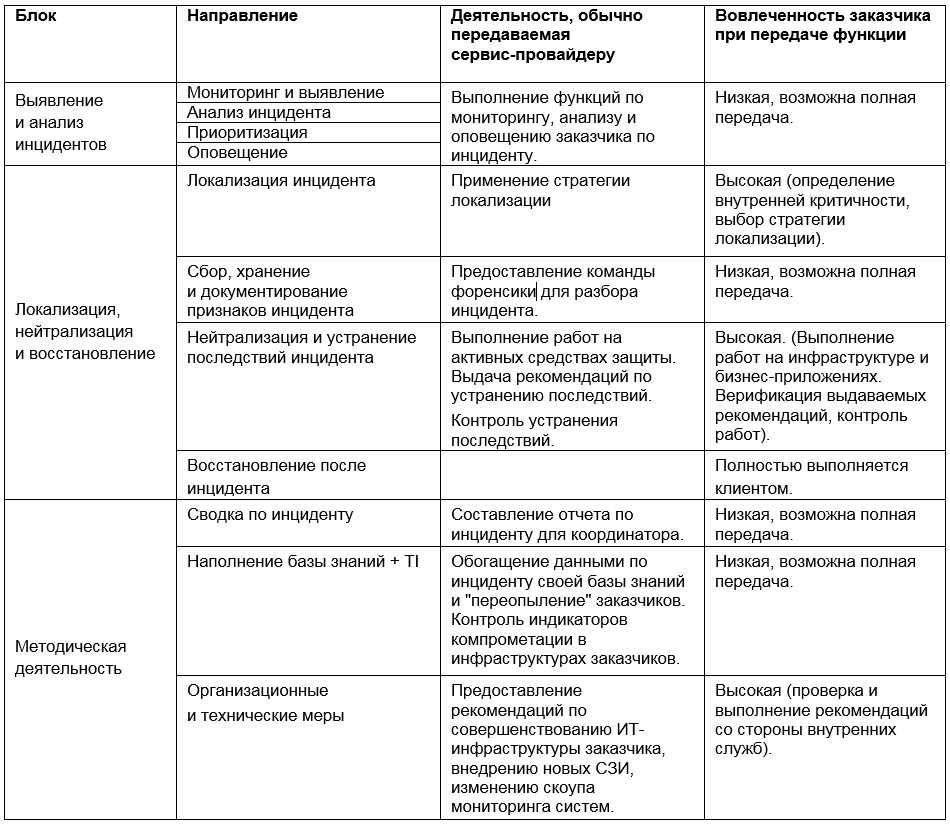
Le choix des outils et des approches de gestion des incidents est l'une des tâches les plus difficiles de la sécurité de l'information. La tentation de faire confiance aux promesses d'un prestataire de services et de lui confier toutes les fonctions peut être grande, mais nous conseillons une évaluation saine de la situation et un équilibre entre l'utilisation des ressources internes et externes - dans l'intérêt à la fois de l'efficacité économique et de l'efficacité des processus.