Défi
L'une des grandes tâches de l'application de stockage et d'analyse des achats est de rechercher des produits identiques ou très proches dans la base de données, qui contient des noms de produits variés et obscurs obtenus à partir des reçus. Il existe deux types de demande d'entrée:
- Un nom spécifique avec des abréviations, qui ne peut être compris que par les caissiers d'un supermarché local ou les acheteurs avides.
- Une requête en langage naturel entrée par l'utilisateur dans la chaîne de recherche.
En règle générale, les demandes du premier type proviennent des produits du chèque lui-même, lorsque l'utilisateur a besoin de trouver des produits moins chers. Notre tâche consiste à sélectionner l'analogue de produit le plus similaire à partir de la vérification dans d'autres magasins à proximité. Il est important de choisir la marque de produit la plus appropriée et, si possible, le volume.
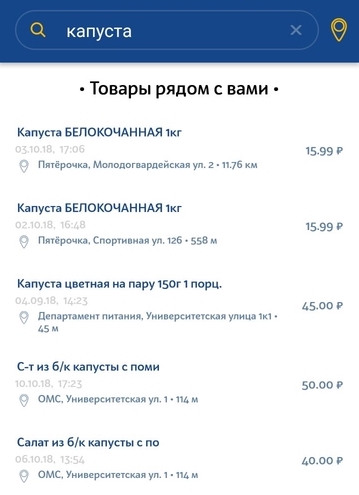
Le deuxième type de demande est une simple demande de l'utilisateur de rechercher un produit spécifique dans le magasin le plus proche. La demande peut être une description très générale et non unique du produit. Il peut y avoir de légers écarts par rapport à la demande. Par exemple, si un utilisateur recherche du lait à 3,2% et dans notre base de données seulement 2,5% de lait, nous voulons toujours afficher au moins ce résultat.
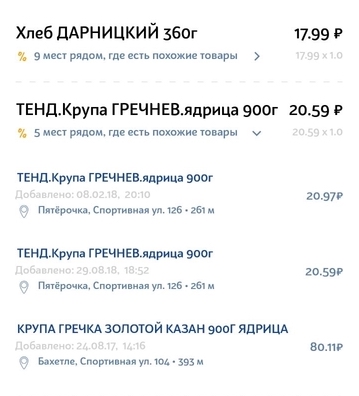
Ensemble de données sur les fonctionnalités - problèmes à résoudre
Les informations contenues dans le reçu du produit sont loin d'être idéales. Il a beaucoup d'abréviations pas toujours claires, d'erreurs grammaticales, de fautes de frappe, de traductions diverses, de lettres latines au milieu de l'alphabet cyrillique et de jeux de caractères qui n'ont de sens que pour l'organisation interne dans un magasin particulier.
Par exemple, une purée de pomme-banane avec du fromage cottage peut facilement être inscrite sur le chèque comme ceci:

À propos de la technologie
Elasticsearch est une technologie assez populaire et abordable pour implémenter la recherche. Il s'agit d'un moteur de recherche d'API JSON REST utilisant Lucene et écrit en Java. Les principaux avantages d'Elastic sont la vitesse, l'évolutivité et la tolérance aux pannes. Des moteurs similaires sont utilisés pour des recherches complexes dans la base de données de documents. Par exemple, une recherche prenant en compte la morphologie de la langue ou une recherche par géo-coordonnées.
Orientations pour l'expérimentation et l'amélioration
Pour comprendre comment vous pouvez améliorer votre recherche, vous devez analyser le système de recherche dans ses composants personnalisés. Pour notre cas, la structure du système ressemble à ceci.
- La chaîne d'entrée pour la recherche passe par l'analyseur qui, d'une certaine manière, divise la chaîne en jetons - unités de recherche qui recherchent parmi les données qui sont également stockées en tant que jetons.
- Ensuite, il y a une recherche directe de ces jetons pour chaque document dans la base de données existante. Après avoir trouvé le jeton dans un certain document (qui est également présenté dans la base de données comme un ensemble de jetons), sa pertinence est calculée selon le modèle de similarité sélectionné (nous l'appellerons le modèle de pertinence). Il peut s'agir d'un simple TF / IDF (terme fréquence - fréquence de document inverse), ou il peut s'agir d'autres modèles plus complexes ou spécifiques.
- À l'étape suivante, le nombre de points marqués par chaque jeton individuel est agrégé d'une certaine manière. Les paramètres d'agrégation sont définis par la sémantique des requêtes. Un exemple de telles agrégations peut être des poids supplémentaires pour certains jetons (valeur ajoutée), des conditions pour la présence obligatoire d'un jeton, etc. Le résultat de cette étape est Score - l'évaluation finale de la pertinence d'un document particulier de la base de données par rapport à la demande initiale.

Trois composants configurables séparément peuvent être distingués du dispositif de recherche, dans chacun desquels vous pouvez mettre en évidence vos propres voies et méthodes d'amélioration.
- Analyseurs
- Modèle de similitude
- Améliorations au moment de la requête
Ensuite, nous examinerons chaque composant individuellement et analyserons les paramètres spécifiques qui ont contribué à améliorer la recherche dans le cas des noms de produits.
Améliorations au moment de la requête
Pour comprendre ce que nous pouvons améliorer dans la demande, nous donnons un exemple de la demande initiale.
{ "query": { "multi_match": { "query": " 105", "type": "most_fields", "fields": ["name"], "minimum_should_match": "70%" } }, “size”: 100, “min_score”: 15 }
Nous utilisons le type de requête most_fields, car nous prévoyons la nécessité d'une combinaison de plusieurs analyseurs pour le champ «nom du produit». Ce type de requête vous permet de combiner les résultats de recherche pour différents attributs de l'objet contenant le même texte, analysés de différentes manières. Une alternative à cette approche consiste à utiliser les requêtes best_fields ou cross_fields, mais elles ne conviennent pas à notre cas, car la recherche est calculée parmi les différents attributs de l'objet (ex: nom et description). Nous sommes confrontés à la tâche de prendre en compte divers aspects d'un attribut - le nom du produit.
Ce qui peut être configuré:
- Combinaison pondérée de différents analyseurs.
Initialement, tous les éléments de recherche ont le même poids - et donc, la même importance. Cela peut être modifié en ajoutant le paramètre «boost», qui prend des valeurs numériques. Si le paramètre est supérieur à 1, l'élément de recherche aura un impact plus important sur les résultats, respectivement, inférieur à 1 - inférieur. - Séparation des analyseurs en «devrait» et «doit».
À savoir, certains analyseurs doivent coïncider, et certains sont facultatifs, c'est-à-dire insuffisants. Dans notre cas, l'analyseur de nombres peut être un exemple des avantages d'une telle séparation. Si seul le numéro correspond au nom du produit dans la demande et au nom du produit dans la base de données, alors ce n'est pas une condition suffisante pour leur équivalence. Nous ne voulons pas voir de tels produits en conséquence. Dans le même temps, si la demande est «crème 10%», nous voulons que toutes les crèmes avec 10% de matières grasses aient un gros avantage sur les crèmes avec 20% de matières grasses. - Le paramètre minimum_should_match. Combien de jetons doivent nécessairement correspondre dans la demande et le document de la base de données? Ce paramètre fonctionne avec le type de notre demande (most_fields) et vérifie le nombre minimum de jetons correspondants pour chacun des champs (dans notre cas, pour chaque analyseur).
- Paramètre Min_score. Documents de sélection des seuils avec des points insuffisants. Le hic, c'est qu'il n'y a pas de vitesse maximale connue. Le score obtenu dépend d'une demande spécifique et d'une base de données spécifique de documents. Parfois, il peut être de 150 et parfois de 2, mais ces deux valeurs signifient que l'objet de la base de données est pertinent pour la demande. Nous ne pouvons pas comparer les scores des résultats de différentes requêtes.
- Constante
Après un contrôle suffisant des valeurs finales de la vitesse pour différentes requêtes, vous pouvez identifier une frontière approximative, après quoi pour la plupart des requêtes, les résultats deviennent inappropriés. C'est la décision la plus simple, mais aussi la plus stupide, ce qui conduit à une recherche de mauvaise qualité. - Essayez d'analyser les scores obtenus pour une demande spécifique après avoir effectué une recherche avec un minimum ou zéro min_score.
L'idée est qu'après un certain moment, vous pouvez observer un saut brusque dans le sens d'une vitesse décroissante. Il ne reste plus qu'à déterminer ce saut afin de s'arrêter dans le temps. Une telle approche fonctionnerait bien sur des requêtes similaires:
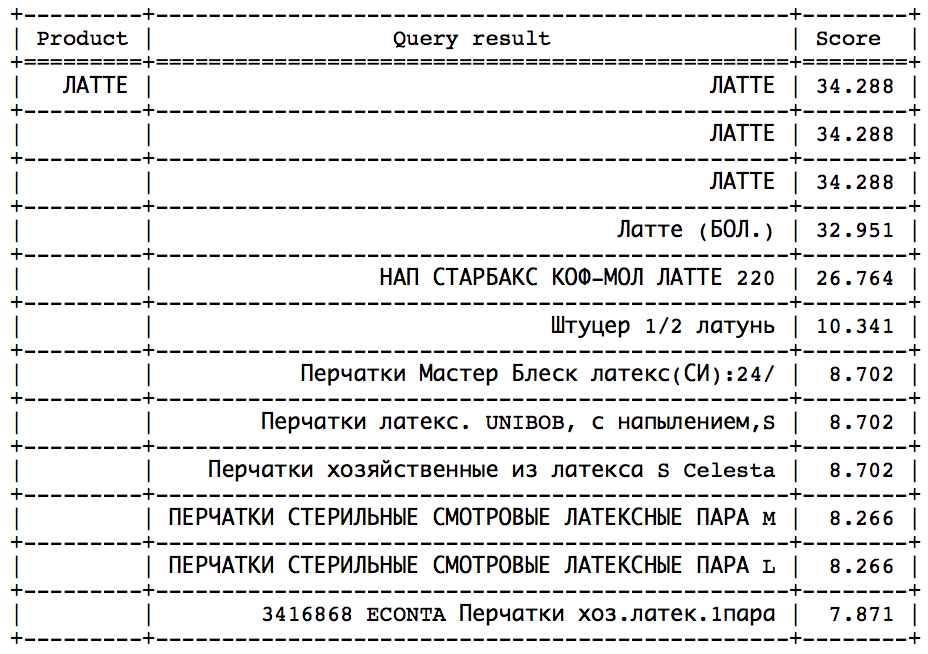
Le saut peut être trouvé par des méthodes statistiques. Mais, malheureusement, pas dans toutes les demandes, ce saut est présent et est facilement identifiable. - Calculez la vitesse idéale et définissez min_score comme une certaine fraction de l'idéal, ce qui peut être fait de deux manières:
- D'après la description détaillée des calculs fournis par Elastic lui-même lors de la définition du paramètre expliquer: true. C'est une tâche difficile, nécessitant une compréhension approfondie de l'architecture des requêtes et des algorithmes de calcul utilisés par Elastic.
- Par un petit truc. Nous recevons une demande, ajoutons un nouveau produit à notre base de données du même nom, effectuons une recherche et obtenons la vitesse maximale. Puisqu'il y aura une correspondance de 100% dans le nom, la valeur résultante sera idéale. C'est cette approche que nous utilisons dans notre système, car les inquiétudes concernant le coût élevé de cette opération dans le temps n'ont pas été confirmées.
- Modifiez l'algorithme de notation, qui est responsable de la valeur de pertinence finale. Cela peut prendre en compte la distance par rapport au magasin (donner plus de points aux produits les plus proches), les prix des produits (donner plus de points aux produits avec le prix le plus probable), etc.
Analyseurs
L'analyseur analyse la chaîne d'entrée en trois étapes et émet des jetons à la sortie - unités de recherche:

Tout d'abord, les modifications se produisent au niveau des caractères de la chaîne. Il peut s'agir de remplacer, de supprimer ou d'ajouter des caractères à une chaîne. Ensuite, un tokenizer entre en jeu, qui est conçu pour diviser la chaîne en jetons. Le tokenizer standard divise la chaîne en jetons en fonction des signes de ponctuation. Dans la dernière étape, les jetons reçus sont filtrés et traités.
Considérez quelles variations des étapes sont devenues utiles dans notre cas.
Filtres char
- Selon les spécificités de la langue russe, il serait utile de traiter des caractères tels que th et e et de les remplacer respectivement par et et e.
- Effectuer la translittération - le transfert de caractères d'une écriture par des caractères d'une autre écriture. Dans notre cas, il s'agit du traitement des noms écrits en latin ou mélangés aux deux alphabets. La translittération peut être implémentée en utilisant le plug-in ( ICU Analysis Plugin ) comme filtre à jetons (c'est-à-dire qu'il ne traite pas la chaîne d'origine, mais les jetons finaux). Nous avons décidé d'écrire notre translittération, car nous n'étions pas très satisfaits de l'algorithme dans le plugin. L'idée est de remplacer d'abord les occurrences du jeu de quatre caractères (par exemple, «SHCH => u»), puis les occurrences de trois caractères, etc. L'ordre dans lequel les filtres de symboles sont utilisés est important car le résultat dépendra de l'ordre.
- Remplacer le latin c, entouré de cyrillique, par le russe p. La nécessité de cela a été identifiée après analyse des noms dans la base de données - de très nombreux noms en cyrillique comprenaient le latin c, ce qui signifie cyrillique c. Quand comme si le nom est complètement en latin, alors latin C signifie cyrillique k ou c. Par conséquent, avant la translittération, il est nécessaire de remplacer le caractère c.
- Suppression de trop grands nombres des noms. Parfois, dans les noms de produits, il y a un numéro d'identification interne (par exemple 3387522 K.Ts. Maslo podsoln.raf. 0.9l), qui n'a aucune signification dans le cas général.
- Remplacement des virgules par des points. Pourquoi est-ce nécessaire? Pour que les chiffres, par exemple, la teneur en matières grasses du lait 3.2 et 3.2, soient équivalents
Tokenizer
- Tokenizer standard - sépare les lignes en fonction de l'espace et des signes de ponctuation (par exemple, "twix extra 2" -> "twix", "extra", "2")
- Tokenizer EdgeNGram - divise chaque mot en jetons d'une longueur donnée (généralement une plage de nombres), en commençant par le premier caractère (par exemple, pour N = [3, 6]: "twix extra 2" -> "twee", "tweak", "Twix", "ex", "ext", "ext", "extra")
- Tokenizer pour les nombres - sélectionne uniquement les nombres dans une chaîne en recherchant une expression régulière (par exemple, "twix extra 2 4.5" -> "2", "4.5")
Filtre à jeton
- Filtre en minuscules
- Filtre de stamming - exécute un algorithme de stamming pour chaque jeton. La racine consiste à déterminer la forme initiale d'un mot (par exemple, «riz» -> «riz»)
- Analyse phonétique. Il est nécessaire afin de minimiser l'influence des fautes de frappe et des différentes façons d'écrire le même mot sur les résultats de la recherche. Le tableau présente les différents algorithmes disponibles pour l'analyse phonétique et le résultat de leur travail dans des cas problématiques. Dans le premier cas (Shampooing / champagne / champignon / champignon), le succès est déterminé par la génération de codages différents, dans le reste - les mêmes.

Modèle de similitude
Le modèle de pertinence est nécessaire afin de déterminer dans quelle mesure la coïncidence d'un jeton affecte la pertinence de l'objet de la base de données par rapport à la demande. Supposons que le jeton de la demande et le produit de la base de données correspondent - ce n'est certainement pas mauvais, mais cela ne dit pas grand-chose sur la conformité du produit à la demande. Ainsi, la coïncidence de différents jetons porte des valeurs différentes. Pour en tenir compte, un modèle de pertinence est nécessaire. Elastic propose de nombreux modèles différents. Si vous les comprenez vraiment, vous pouvez choisir un modèle très spécifique et adapté à un cas particulier. Le choix peut être basé sur le nombre de mots fréquemment utilisés (comme le même jeton pour), une évaluation de l'importance des longs jetons (plus long signifie mieux? Pire? Peu importe?), Quels résultats voulons-nous voir à la fin, etc. Des exemples de modèles proposés dans Elastic peuvent être TF-IDF (le modèle le plus simple et le plus compréhensible), Okapi BM25 (TF-IDF amélioré, le modèle par défaut), la divergence par rapport au hasard, la divergence par rapport à l'indépendance, etc. Chaque modèle dispose également d'options personnalisables. Après plusieurs expériences avec le modèle, le modèle par défaut Okapi BM25 a montré le meilleur résultat, mais avec des paramètres différents de ceux prédéfinis.
Utiliser des catégories
Au cours de la recherche, des informations supplémentaires très importantes sur le produit - sa catégorie - sont devenues disponibles. Vous pouvez en savoir plus sur la façon dont nous avons implémenté la catégorisation dans l'article. Si je comprends bien, je mange beaucoup de bonbons, ou le classement des marchandises par chèque dans l'application . Jusque-là, nous avons basé notre recherche uniquement sur une comparaison des noms de produits, il est maintenant possible de comparer la catégorie de demande et les produits dans la base de données.
Les options possibles pour utiliser ces informations sont une correspondance obligatoire dans le champ catégorie (formatée comme un filtre de résultats), un avantage supplémentaire sous la forme de points pour les marchandises de la même catégorie (comme dans le cas des nombres) et le tri des résultats par catégorie (première correspondance, puis toutes les autres). Pour notre cas, la dernière option a fonctionné le mieux. En effet, notre algorithme de catégorisation est trop bon pour utiliser la deuxième méthode, et pas assez bon pour utiliser la première. Nous avons suffisamment confiance en l'algorithme et souhaitons que l'appariement des catégories soit un gros avantage. Dans le cas de l'ajout de points supplémentaires à la vitesse (deuxième méthode), les produits de même catégorie remonteront dans la liste, mais perdront tout de même pour certains produits dont le nom correspond mieux. Cependant, la première méthode ne nous convient pas non plus, car des erreurs de catégorisation sont encore possibles. Parfois, la demande peut contenir des informations insuffisantes pour déterminer correctement la catégorie, ou il y a trop peu de produits dans cette catégorie dans le rayon immédiat de l'utilisateur. Dans ce cas, nous voulons toujours afficher les résultats avec une catégorie différente, mais toujours pertinente par nom de produit.
La seconde méthode est également bonne car elle ne "gâche" pas la vitesse des produits à la suite de la recherche, et permet de continuer à utiliser la vitesse minimale calculée sans obstacles.
L'implémentation spécifique du tri est visible dans la requête finale.
Modèle final
La sélection du modèle de recherche final a inclus la génération de divers moteurs de recherche, leur évaluation et leur comparaison. Le plus souvent, la comparaison était basée sur l'un des paramètres. Supposons que dans un cas spécifique, nous devions calculer la meilleure taille pour le tokenizer edgeNgram (c'est-à-dire choisir la plage de N la plus efficace). Pour ce faire, nous avons généré les mêmes moteurs de recherche avec une seule différence dans la taille de cette plage. Après cela, il a été possible de déterminer la meilleure valeur pour ce paramètre.
Les modèles ont été évalués à l'aide de la mesure nDCG (gain cumulatif actualisé normalisé), une mesure permettant d'évaluer la qualité du classement. Des requêtes prédéfinies ont été envoyées à chaque modèle de recherche, après quoi la métrique nDCG a été calculée sur la base des résultats de recherche reçus.
Analyseurs qui sont entrés dans le modèle final:



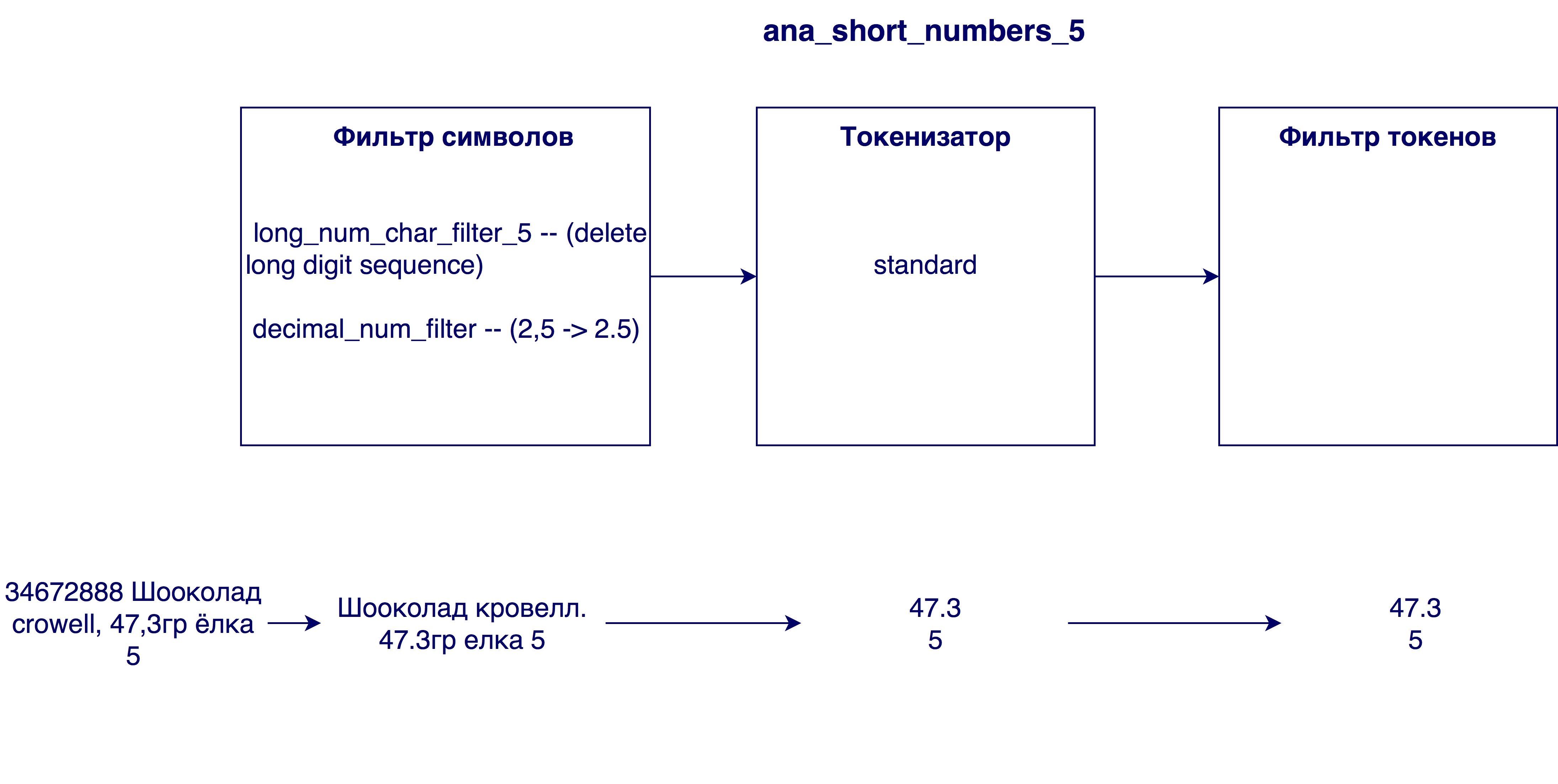
Le modèle par défaut (Okapi - BM25) avec le paramètre b = 0,5 a été choisi comme modèle de pertinence. La valeur par défaut est 0,75. Ce paramètre indique dans quelle mesure la longueur du nom de produit normalise la variable tf (terme fréquence). Un nombre plus petit dans notre cas fonctionne mieux, car un nom long n'affecte pas très souvent la signification d'un seul mot. C'est-à-dire que le mot «chocolat» dans le nom «chocolat aux noisettes broyées dans un paquet de 25 pièces» ne perd pas sa valeur du fait que le nom est assez long.
La requête finale ressemble à ceci:
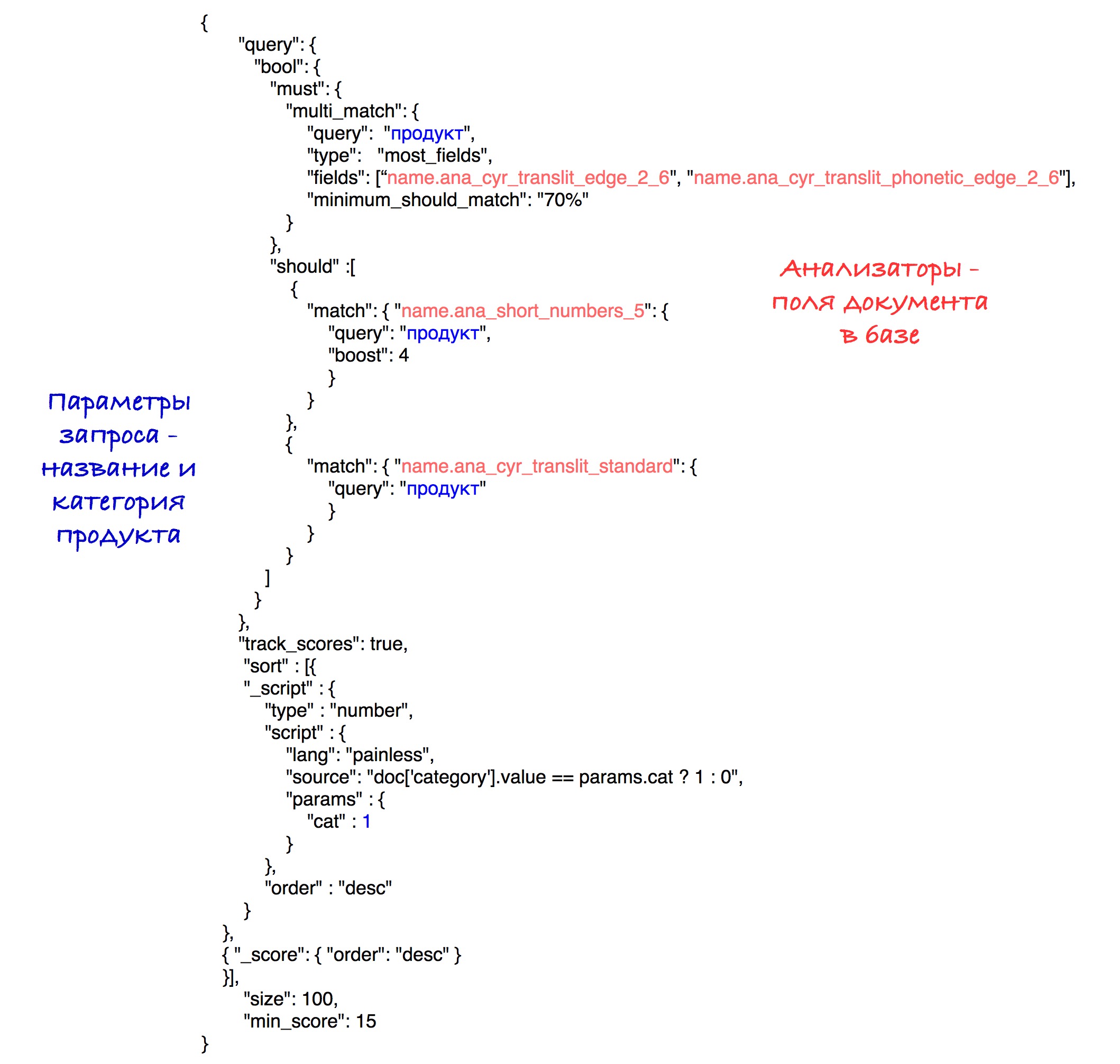
Expérimentalement, la meilleure combinaison d'analyseurs et de poids a été révélée.
Suite au tri, les produits de même catégorie vont au début des résultats, puis à tous les autres. Le tri par nombre de points (vitesse) est stocké dans chaque sous-ensemble.
Par souci de simplicité, le seuil de vitesse est fixé à 15 dans cette demande, bien que dans notre système, nous utilisons le paramètre calculé qui a été décrit précédemment.
Dans le futur
Il y a des réflexions sur l'amélioration de la recherche en résolvant l'un des problèmes les plus embarrassants de notre algorithme, qui est l'existence d'un million et d'une manière différente de raccourcir un mot de 5 lettres. Il peut être résolu par le traitement initial des noms afin de révéler les abréviations. Une façon de résoudre ce problème est d'essayer de comparer le nom abrégé de notre base de données avec l'un des noms de la base de données avec les noms complets «corrects». Cette décision rencontre ses propres obstacles, mais elle semble un changement prometteur.