Bonjour encore!
En décembre, nous commencerons la formation du prochain
groupe Data Scientist , il y aura donc de plus en plus de leçons ouvertes et d'autres activités. Par exemple, l'autre jour, un webinaire s'est tenu sous le nom long de «Feature Engineering sur l'exemple du jeu de données Titanic classique». Il a été mené par
Alexander Sizov , un développeur expérimenté, Ph.D., un expert en Machine / Deep learning, et un participant à divers projets commerciaux internationaux liés à l'intelligence artificielle et l'analyse des données.
Une leçon ouverte a duré environ une heure et demie. Au cours du webinaire, l'enseignant a parlé de la sélection des fonctionnalités, de la transformation des données source (codage, mise à l'échelle), de la définition des paramètres, de la formation du modèle et bien plus encore. Pendant la leçon, on a montré aux participants un cahier Jupyter. Pour le travail, nous avons utilisé des données ouvertes de la
plate- forme
Kaggle (un ensemble de données classique sur le Titanic, dont beaucoup commencent à se familiariser avec la science des données). Ci-dessous, nous proposons une vidéo et une transcription de l'événement passé, et
ici vous pouvez récupérer la présentation et les codes dans un ordinateur portable Jupiter.
Sélection des fonctionnalités
Le thème a été choisi, bien que classique, mais toujours un peu sombre. En particulier, il était nécessaire de résoudre le problème de classification binaire et de prédire à partir des données disponibles si le passager survivra ou non. Les données elles-mêmes ont été divisées en deux échantillons de formation et de test. La variable clé est Survie (survécu / non survécu; 0 = non, 1 = oui).
Entrer les données d'entraînement:
- classe de billets
- l'âge et le sexe du passager;
- état matrimonial (s'il y a des parents à bord);
- prix du billet;
- numéro de cabine;
- port d'embarquement.
Comme vous pouvez le voir, les types de variables sont différents: numérique, texte. À partir de ce kaléidoscope, il était nécessaire de former un ensemble de données pour la prochaine formation de modèle.
Nous résumons:
- train.csv - ensemble de formation - ensemble de données de formation. La réponse est connue en eux - survie - un signe binaire 0 (n'a pas survécu) / 1 (a survécu);
- test.csv - test set - test data set. La réponse est inconnue. Il s'agit d'un exemple à envoyer à la plateforme kaggle pour calculer la métrique de qualité du modèle;
- gender_submission.csv est un exemple du format des données à envoyer à kaggle.
Algorithme de travail
- Le travail s'est déroulé par étapes:
- Analyse des données de train.csv.
- Gestion des valeurs manquantes.
- Mise à l'échelle.
- Codage des caractéristiques catégorielles.
- Construire un modèle et sélectionner des paramètres, choisir le meilleur modèle sur les données converties de train.csv.
- Fixation et modèle de la méthode de transformation.
- Application des mêmes conversions à test.csv à l'aide d'un pipeline.
- Application du modèle sur test.csv.
- Enregistrement du fichier de résultats de l'application dans le même format que dans gender_submission.csv.
- Envoi des résultats à la plateforme kaggle.
La partie pratique du webinaireLa première chose à faire était de lire l'ensemble de données et d'afficher nos données à l'écran:
Pour l'analyse des données, une bibliothèque de profilage peu connue mais plutôt utile a été utilisée:
pandas_profiling.ProfileReport(df_train)En savoir plus sur le profilageCette bibliothèque fait tout ce qui peut être fait a priori sans connaître les détails des données. Par exemple, affichez des statistiques sur les données (combien de variables et de quel type elles sont, combien de lignes, valeurs manquantes, etc.). De plus, des statistiques distinctes pour chaque variable sont fournies avec un minimum et un maximum, un graphique de distribution et d'autres paramètres.
Comme vous le savez, pour faire un bon modèle, vous devez vous plonger dans le processus que nous essayons de simuler et comprendre quels sont les attributs clés. De plus, loin de toujours dans nos données, il y a tout ce qui est nécessaire, et, plus précisément, presque jamais en elles, il n'y a tout ce qui est nécessaire, déterminant et déterminant complètement notre processus. En règle générale, nous devons toujours combiner quelque chose, peut-être ajouter des entités supplémentaires qui ne sont pas représentées dans l'ensemble de données (par exemple, les prévisions météorologiques). C'est pour comprendre le processus que nous avons besoin d'une analyse des données, ce qui peut être fait en utilisant la bibliothèque de profilage.
Valeurs manquantesL'étape suivante consiste à résoudre le problème des valeurs manquantes, car dans la plupart des cas, les données ne sont pas complètement remplies.
Les solutions suivantes sont disponibles pour ce problème:
- supprimer des lignes avec des valeurs manquantes (gardez à l'esprit que vous pouvez perdre certaines valeurs importantes);
- supprimer un signe (pertinent s'il y a trop peu de données dessus);
- remplacer les valeurs manquantes par autre chose (médiane, moyenne ...).
Un exemple de conversion simple utilisant la méthode fillna, qui affecte les valeurs de la variable médiane uniquement aux cellules qui ne sont pas remplies:

De plus, l'enseignant a montré des exemples d'utilisation d'Imputer et de pipeline.
Mise à l'échelle des fonctionnalitésLe fonctionnement du modèle et la décision finale dépendent de l'échelle des caractéristiques. Le fait est que ce n'est pas un fait qu'une entité à plus grande échelle est plus importante qu'une entité à plus petite échelle. C'est pourquoi le modèle doit soumettre des fonctionnalités dont l'échelle est identique, c'est-à-dire ayant le même poids pour le modèle.
Il existe différentes techniques de mise à l'échelle, cependant, le format de la leçon ouverte ne permet d'en considérer que deux plus en détail:
 Combinaisons de fonctionnalités
Combinaisons de fonctionnalitésLes combinaisons de fonctionnalités existantes à l'aide d'opérations arithmétiques (somme, multiplication, division) vous permettent d'obtenir toute fonctionnalité qui rend le modèle plus efficace. Ce n'est pas toujours réussi, et nous ne savons pas quelle combinaison donnera l'effet souhaité, mais la pratique montre qu'il est logique d'essayer. Il est pratique d'appliquer des transformations d'entités à l'aide du pipeline.
CodageNous avons donc des données de différents types: numérique et texte. Actuellement, la plupart des modèles sur le marché ne peuvent pas fonctionner avec des données texte. Par conséquent, tous les signes catégoriels (textuels) doivent être convertis en une représentation numérique, pour laquelle un codage est utilisé.
Encodage d'étiquette . Il s'agit d'un mécanisme implémenté dans le cadre de nombreuses bibliothèques pouvant être appelé et appliqué:

Le codage d'étiquette attribue un identifiant unique à chaque valeur unique. Moins - nous introduisons l'ordre dans une certaine variable qui n'a pas été ordonnée, ce qui n'est pas bon.
OneHotEncoder. Les valeurs uniques de la variable de texte sont développées sous la forme de colonnes qui sont ajoutées aux données source, où chaque colonne est une variable binaire sous la forme de 0 et 1. Cette approche est exempte de défauts de codage d'étiquette, mais a son inconvénient: s'il existe de nombreuses valeurs uniques, nous ajoutons trop de colonnes et dans certains cas, la méthode n'est tout simplement pas applicable (l'ensemble de données se développe trop).
Formation modèleAprès avoir effectué les étapes ci-dessus, un pipeline final est compilé avec un ensemble de toutes les opérations nécessaires. Il suffit maintenant de prendre l'ensemble de données source et d'appliquer le pipeline résultant à ces données à l'aide de l'opération fit_transform:
x_train = vec.fit_transform(df_train)Par conséquent, nous obtenons l'ensemble de données x_train, qui est prêt à être utilisé dans le modèle. La seule chose à faire est de séparer la valeur de notre variable cible pour que nous puissions conduire la formation.
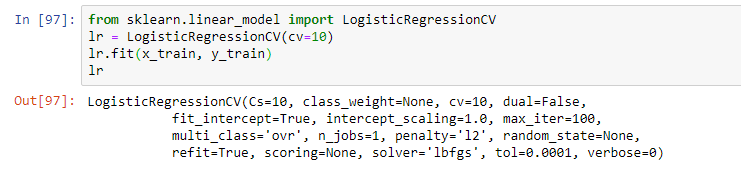
Sélectionnez ensuite le modèle. Dans le cadre du webinaire, l'enseignant a proposé une régression logistique simple. Le modèle a été formé en utilisant l'opération d'ajustement, résultant en un modèle sous forme de régression logistique avec certains paramètres:
Cependant, en pratique, plusieurs modèles sont généralement utilisés et semblent être les plus efficaces. Et la solution finale est souvent une combinaison de ces modèles en utilisant des techniques d'empilement et d'autres approches de modèles d'ensemble (en utilisant plusieurs modèles au sein du même modèle hybride).
Après la formation, le modèle peut être appliqué sur des données de test, évaluant sa qualité dans le cadre d'une métrique. Dans notre cas, la qualité dans l'exactitude_score était de 0,8:

Cela signifie que sur les données obtenues, la variable est correctement prédite dans 80% des cas. Après avoir reçu les résultats de la formation, nous pouvons soit améliorer le modèle (si la précision n'est pas satisfaisante), soit procéder directement aux prévisions.
C'était le sujet principal de la leçon, mais l'enseignant a parlé plus en détail des caractéristiques du modèle dans différentes tâches et a répondu aux questions du public. Donc, si vous ne voulez rien manquer, regardez le webinaire complet si vous êtes intéressé par ce sujet.
Comme toujours, nous attendons vos commentaires et questions que vous pouvez laisser ici ou les poser à
Alexandre en allant le voir lors d'une
journée portes ouvertes.