Faire un ticket dans le système de gestion de projet et de suivi des tâches, chacun de nous est heureux de voir les termes approximatifs de la décision sur notre appel.
Lors de la réception d'un flux de billets entrants, une personne / une équipe doit les aligner en priorité et en temps, ce qui prendra pour résoudre chaque appel.
Tout cela vous permet de planifier plus efficacement votre temps pour les deux parties.
Sous la coupe, je vais parler de la façon dont j'ai analysé et formé des modèles ML qui prédisent le temps nécessaire pour résoudre les tickets émis à notre équipe.
Je travaille moi-même pour le poste SRE dans une équipe appelée LAB. Nous recevons des appels des développeurs et de QA concernant le déploiement de nouveaux environnements de test, leurs mises à jour vers les dernières versions, les solutions aux divers problèmes qui se posent, et bien plus encore. Ces tâches sont assez hétérogènes et, logiquement, prennent un temps différent à accomplir. Il y a notre équipe depuis plusieurs années et pendant ce temps une bonne base de demandes a réussi à s'accumuler. J'ai décidé d'analyser cette base et à partir de là, à l'aide du machine learning, d'élaborer un modèle qui traitera de la prédiction de l'heure probable de clôture d'un appel (ticket).
Dans notre travail, nous utilisons JIRA, cependant, le modèle que je présente dans cet article n'a aucun rapport avec un produit spécifique - les informations nécessaires ne sont pas un problème à obtenir à partir d'une base de données.
Passons donc des mots aux actes.
Analyse préliminaire des données
Nous chargeons tout ce dont nous avons besoin et affichons les versions des packages utilisés.
Code sourceimport warnings warnings.simplefilter('ignore') %matplotlib inline import matplotlib.pyplot as plt import pandas as pd import numpy as np import datetime from nltk.corpus import stopwords from sklearn.model_selection import train_test_split from sklearn.metrics import mean_absolute_error, mean_squared_error from sklearn.neighbors import KNeighborsRegressor from sklearn.linear_model import LinearRegression from datetime import time, date for package in [pd, np, matplotlib, sklearn, nltk]: print(package.__name__, 'version:', package.__version__)
pandas version: 0.23.4 numpy version: 1.15.0 matplotlib version: 2.2.2 sklearn version: 0.19.2 nltk version: 3.3
Téléchargez les données du fichier csv. Il contient des informations sur les tickets fermés au cours des 1,5 dernières années. Avant d'écrire les données dans un fichier, elles étaient légèrement prétraitées. Par exemple, les virgules et les points ont été supprimés des champs de texte avec descriptions. Cependant, il ne s'agit que d'un traitement préliminaire et à l'avenir, le texte sera encore clarifié.
Voyons ce qu'il y a dans notre ensemble de données. Au total, 10783 billets y sont entrés.
Explication du champ| Créé | Date et heure de création du ticket |
| Résolu | Date et heure de fermeture des billets |
| Resolution_time | Le nombre de minutes écoulées entre la création et la fermeture d'un ticket. Il est considéré comme l'heure du calendrier, car l'entreprise a des bureaux dans différents pays, travaillant dans différents fuseaux horaires et il n'y a pas d'heure fixe pour l'ensemble du département. |
| Engineer_N | Noms «codés» des ingénieurs (afin de ne pas divulguer par inadvertance d'informations personnelles ou confidentielles à l'avenir, il y aura pas mal de données «codées» dans l'article, qui sont essentiellement simplement renommées). Ces champs contiennent le nombre de tickets en mode «en cours» au moment de la réception de chacun des tickets dans le jeu de dates présenté. Je vais m'attarder sur ces domaines séparément vers la fin de l'article, car ils méritent une attention particulière. |
| Cessionnaire | L'employé qui a participé à la résolution du problème. |
| Issue_type | Type de billet. |
| L'environnement | Le nom de l'environnement de travail de test pour lequel le ticket a été créé (cela peut signifier soit un environnement spécifique, soit l'emplacement dans son ensemble, par exemple, un centre de données). |
| Priorité | Priorité du ticket. |
| Type de travail | Le type de travail attendu pour ce ticket (ajout ou suppression de serveurs, mise à jour de l'environnement, travail de surveillance, etc.) |
| La description | La description |
| Résumé | Titre du billet. |
| Observateurs | Le nombre de personnes qui "regardent" le ticket, c'est-à-dire ils reçoivent des notifications par e-mail pour chaque activité du ticket. |
| Votes | Le nombre de personnes qui ont "voté" pour le billet, montrant ainsi son importance et leur intérêt pour celui-ci. |
| Journaliste | La personne qui a émis le billet. |
| Engineer_N_vacation | Si l'ingénieur était en vacances au moment de l'émission du billet. |
df.info()
<class 'pandas.core.frame.DataFrame'> Index: 10783 entries, ENV-36273 to ENV-49164 Data columns (total 37 columns): Created 10783 non-null object Resolved 10783 non-null object Resolution_time 10783 non-null int64 engineer_1 10783 non-null int64 engineer_2 10783 non-null int64 engineer_3 10783 non-null int64 engineer_4 10783 non-null int64 engineer_5 10783 non-null int64 engineer_6 10783 non-null int64 engineer_7 10783 non-null int64 engineer_8 10783 non-null int64 engineer_9 10783 non-null int64 engineer_10 10783 non-null int64 engineer_11 10783 non-null int64 engineer_12 10783 non-null int64 Assignee 10783 non-null object Issue_type 10783 non-null object Environment 10771 non-null object Priority 10783 non-null object Worktype 7273 non-null object Description 10263 non-null object Summary 10783 non-null object Watchers 10783 non-null int64 Votes 10783 non-null int64 Reporter 10783 non-null object engineer_1_vacation 10783 non-null int64 engineer_2_vacation 10783 non-null int64 engineer_3_vacation 10783 non-null int64 engineer_4_vacation 10783 non-null int64 engineer_5_vacation 10783 non-null int64 engineer_6_vacation 10783 non-null int64 engineer_7_vacation 10783 non-null int64 engineer_8_vacation 10783 non-null int64 engineer_9_vacation 10783 non-null int64 engineer_10_vacation 10783 non-null int64 engineer_11_vacation 10783 non-null int64 engineer_12_vacation 10783 non-null int64 dtypes: float64(12), int64(15), object(10) memory usage: 3.1+ MB
Au total, nous avons 10 champs «objet» (c'est-à-dire contenant une valeur texte) et 27 champs numériques.
Tout d'abord, recherchez immédiatement les émissions dans nos données. Comme vous pouvez le voir, il existe de tels tickets dans lesquels le temps de décision est estimé en millions de minutes. Il ne s'agit manifestement pas d'informations pertinentes, ces données n'interféreront qu'avec la construction du modèle. Ils sont arrivés ici, car la collecte de données à partir de JIRA a été effectuée par une requête dans le champ Résolu, et non créée. En conséquence, ces billets qui ont été fermés au cours des 1,5 dernières années sont arrivés ici, mais ils auraient pu être ouverts beaucoup plus tôt. Il est temps de s'en débarrasser. Nous supprimerons les billets créés avant le 1er juin 2017. Il nous reste 9493 billets.
En ce qui concerne les raisons - je pense que dans chaque projet, vous pouvez facilement trouver des demandes qui traînent depuis un certain temps en raison de diverses circonstances et qui sont le plus souvent fermées non pas en résolvant le problème lui-même, mais en "expirant le délai de prescription".
Code source df[['Created', 'Resolved', 'Resolution_time']].sort_values('Resolution_time', ascending=False).head()

Code source df = df[df['Created'] >= '2017-06-01 00:00:00'] print(df.shape)
(9493, 33)
Commençons donc par examiner ce que nous pouvons trouver intéressant dans nos données. Pour commencer, découvrons les environnements les plus simples - les plus populaires parmi nos tickets, les "reporters" les plus actifs, etc.
Code source df.describe(include=['object'])

Code source df['Environment'].value_counts().head(10)
Environment_104 442 ALL 368 Location02 367 Environment_99 342 Location03 342 Environment_31 322 Environment_14 254 Environment_1 232 Environment_87 227 Location01 202 Name: Environment, dtype: int64
Code source df['Reporter'].value_counts().head()
Reporter_16 388 Reporter_97 199 Reporter_04 147 Reporter_110 145 Reporter_133 138 Name: Reporter, dtype: int64
Code source df['Worktype'].value_counts()
Support 2482 Infrastructure 1655 Update environment 1138 Monitoring 388 QA 300 Numbers 110 Create environment 95 Tools 62 Delete environment 24 Name: Worktype, dtype: int64
Code source df['Priority'].value_counts().plot(kind='bar', figsize=(12,7), rot=0, fontsize=14, title=' ');
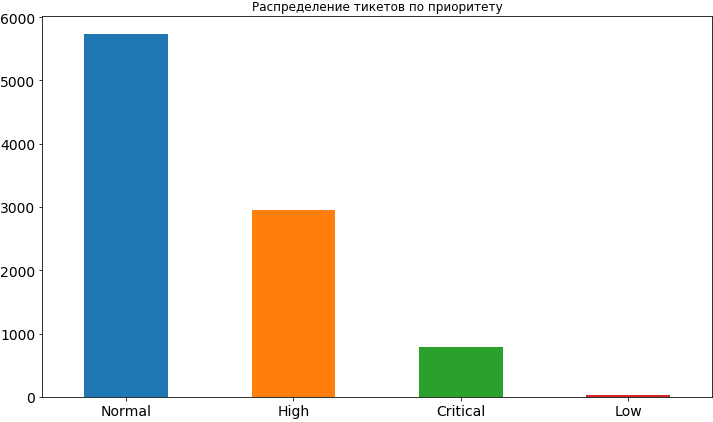
Eh bien, quelque chose que nous avons déjà appris. Le plus souvent, la priorité des tickets est normale, environ 2 fois moins souvent élevée et encore moins critique. Très rarement, il y a une faible priorité, apparemment les gens ont peur de l'exposer, croyant que dans ce cas, il restera assez longtemps dans la file d'attente et le temps pour sa décision peut être retardé. Plus tard, lorsque nous allons déjà construire le modèle et analyser ses résultats, nous verrons que de telles craintes peuvent ne pas être infondées, car une faible priorité affecte vraiment le délai de la tâche et, bien sûr, pas dans le sens de l'accélération.
À partir des colonnes des environnements les plus populaires et des journalistes les plus actifs, nous voyons que Reporter_16 passe par une large marge et Environment_104 vient en premier dans les environnements. Même si vous n'avez pas encore deviné, je vais vous dire un petit secret - ce journaliste est de l'équipe travaillant sur cet environnement particulier.
Voyons de quel type d'environnement proviennent les tickets les plus critiques.
Code source df[df['Priority'] == 'Critical']['Environment'].value_counts().index[0]
'Environment_91'
Nous allons maintenant imprimer des informations sur le nombre de tickets de priorités différentes provenant du même environnement «critique».
Code source df[df['Environment'] == df[df['Priority'] == 'Critical']['Environment'].value_counts().index[0]]['Priority'].value_counts()
High 62 Critical 57 Normal 46 Name: Priority, dtype: int64
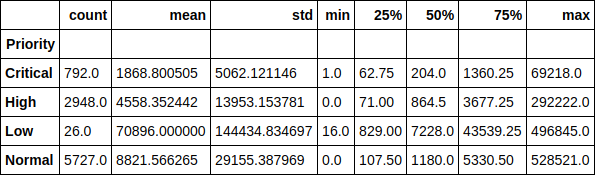
Regardons le temps d'exécution du ticket dans le contexte des priorités. Par exemple, il est amusant de remarquer que la durée moyenne d’exécution d’un ticket de faible priorité est supérieure à 70 000 minutes (près de 1,5 mois). La dépendance du temps d'exécution du ticket à sa priorité est également facilement identifiable.
Code source df.groupby(['Priority'])['Resolution_time'].describe()
Ou ici sous forme de graphique, la valeur médiane. Comme vous pouvez le voir, l'image n'a pas beaucoup changé, par conséquent, les émissions n'affectent pas grandement la distribution.
Code source df.groupby(['Priority'])['Resolution_time'].median().sort_values().plot(kind='bar', figsize=(12,7), rot=0, fontsize=14);

Examinons maintenant le temps moyen de solution de ticket pour chacun des ingénieurs, en fonction du nombre de tickets que l'ingénieur avait à ce moment-là. En fait, ces graphiques, à ma grande surprise, ne montrent aucune image. Pour certains, le temps d'exécution augmente à mesure que les tickets actuels du travail augmentent, tandis que pour certains, cette relation est l'inverse. Pour certains, la dépendance n'est pas du tout traçable.
Cependant, pour l'avenir, je dirai que la présence de cette fonctionnalité dans l'ensemble de données a augmenté la précision du modèle de plus de 2 fois et qu'il y a certainement un effet sur le temps d'exécution. Nous ne le voyons tout simplement pas. Et le modèle voit.
Code source engineers = [i.replace('_vacation', '') for i in df.columns if 'vacation' in i] cols = 2 rows = int(len(engineers) / cols) fig, axes = plt.subplots(nrows=rows, ncols=cols, figsize=(16,24)) for i in range(rows): for j in range(cols): df.groupby(engineers[i * cols + j])['Resolution_time'].mean().plot(kind='bar', rot=0, ax=axes[i, j]).set_xlabel('Engineer_' + str(i * cols + j + 1)) del cols, rows, fig, axes
Image longue comme résultat Faisons une petite matrice d'interaction par paire des fonctionnalités suivantes: temps de solution du ticket, nombre de votes et nombre d'observateurs. Avec un bonus diagonal, nous avons la distribution de chaque attribut.
De l'intéressant, on peut voir la dépendance de la réduction du temps de solution de ticket sur le nombre croissant d'observateurs. On voit également que les gens ne sont pas très actifs dans l'utilisation des votes.
Code source pd.scatter_matrix(df[['Resolution_time', 'Watchers', 'Votes']], figsize=(15, 15), diagonal='hist');
Ainsi, nous avons effectué une petite analyse préliminaire des données, vu les dépendances existantes entre l'attribut cible, qui est le temps qu'il faut pour résoudre le ticket, et des signes tels que le nombre de votes pour le ticket, le nombre "d'observateurs" derrière lui et sa priorité. Nous continuons.
Construire un modèle. Panneaux de construction
Il est temps de passer à la construction du modèle lui-même. Mais d'abord, nous devons mettre nos fonctionnalités sous une forme compréhensible pour le modèle. C'est-à-dire décomposer les signes catégoriques en vecteurs clairsemés et éliminer l'excès. Par exemple, nous n'avons pas besoin des champs avec l'heure à laquelle le ticket a été créé et fermé dans le modèle, ainsi que le champ Destinataire, car nous utiliserons éventuellement ce modèle pour prédire le temps d'exécution d'un ticket qui n'a encore été attribué à personne ("assassiné").
Le signe cible, comme je viens de le mentionner, est le moment de résoudre le problème pour nous, nous le prenons donc comme un vecteur distinct et le supprimons également de l'ensemble de données générales. De plus, certains des champs étaient vides car les journalistes ne remplissent pas toujours le champ de description lors de l'émission d'un ticket. Dans ce cas, les pandas définissent leurs valeurs sur NaN, nous les remplaçons simplement par une chaîne vide.
Code source y = df['Resolution_time'] df.drop(['Created', 'Resolved', 'Resolution_time', 'Assignee'], axis=1, inplace=True) df['Description'].fillna('', inplace=True) df['Summary'].fillna('', inplace=True)
Nous décomposons les signes catégoriels en vecteurs clairsemés ( codage à chaud ). Jusqu'à ce que nous touchions les champs avec la description et la table des matières du ticket. Nous les utiliserons un peu différemment. Certains noms de reporter contiennent un [X]. JIRA marque donc les employés inactifs qui ne travaillent plus dans l'entreprise. J'ai décidé de les laisser parmi les panneaux, bien qu'il soit possible d'effacer les données d'eux, car à l'avenir, lors de l'utilisation du modèle, nous ne verrons pas de tickets de ces employés.
Code source def create_df(dic, feature_list): out = pd.DataFrame(dic) out = pd.concat([out, pd.get_dummies(out[feature_list])], axis = 1) out.drop(feature_list, axis = 1, inplace = True) return out X = create_df(df, df.columns[df.dtypes == 'object'].drop(['Description', 'Summary'])) X.columns = X.columns.str.replace(' \[X\]', '')
Et maintenant, nous allons traiter le champ de description dans le ticket. Nous travaillerons avec lui de l'une des manières peut-être les plus simples - nous rassemblerons tous les mots utilisés dans nos billets, compterons les plus populaires parmi eux, éliminerons les mots "supplémentaires" - ceux qui ne peuvent évidemment pas affecter le résultat, comme, par exemple, le mot "please" (s'il vous plaît - toutes les communications dans JIRA se font strictement en anglais), qui est la plus populaire. Oui, ce sont nos gens polis.
Nous supprimons également les « mots vides», selon la bibliothèque nltk, et effaçons plus complètement le texte des caractères inutiles. Permettez-moi de vous rappeler que c'est la chose la plus simple qui puisse être faite avec le texte. Nous ne « tamponnons » pas les mots, vous pouvez également compter les N-grammes de mots les plus populaires, mais nous nous limiterons à cela.
Code source all_words = np.concatenate(df['Description'].apply(lambda s: s.split()).values) stop_words = stopwords.words('english') stop_words.extend(['please', 'hi', '-', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', '(', ')', '=', '{', '}']) stop_words.extend(['h3', '+', '-', '@', '!', '#', '$', '%', '^', '&', '*', '(for', 'output)']) stop_symbols = ['=>', '|', '[', ']', '#', '*', '\\', '/', '->', '>', '<', '&'] words_series = pd.Series(list(all_words)) del all_words words_series = words_series[~words_series.isin(stop_words)] for symbol in stop_symbols: words_series = words_series[~words_series.str.contains(symbol, regex=False, na=False)]
Après tout cela, nous avons obtenu l'objet pandas.Series contenant tous les mots utilisés. Regardons les plus populaires d'entre eux et prenons les 50 premiers de la liste pour les utiliser comme signes. Pour chacun des tickets, nous verrons si ce mot est utilisé dans la description, et si oui, mettez 1 dans la colonne correspondante, sinon 0.
Code source usefull_words = list(words_series.value_counts().head(50).index) print(usefull_words[0:10])
['error', 'account', 'info', 'call', '{code}', 'behavior', 'array', 'update', 'env', 'actual']
Maintenant, dans notre ensemble de données générales, nous allons créer des colonnes séparées pour les mots que nous avons sélectionnés. Sur ce point, vous pouvez vous débarrasser du champ de description lui-même.
Code source for word in usefull_words: X['Description_' + word] = X['Description'].str.contains(word).astype('int64') X.drop('Description', axis=1, inplace=True)
Nous ferons de même pour le champ du titre du ticket.
Code source all_words = np.concatenate(df['Summary'].apply(lambda s: s.split()).values) words_series = pd.Series(list(all_words)) del all_words words_series = words_series[~words_series.isin(stop_words)] for symbol in stop_symbols: words_series = words_series[~words_series.str.contains(symbol, regex=False, na=False)] usefull_words = list(words_series.value_counts().head(50).index) for word in usefull_words: X['Summary_' + word] = X['Summary'].str.contains(word).astype('int64') X.drop('Summary', axis=1, inplace=True)
Voyons ce que nous avons fini dans la matrice d'entités X et le vecteur de réponse y.
((9493, 1114), (9493,))
Nous allons maintenant diviser ces données en un échantillon de formation (formation) et un échantillon de test dans un rapport de pourcentage de 75/25. Au total, nous avons 7119 exemples sur lesquels nous allons nous entraîner, et 2374 sur lesquels nous évaluerons nos modèles. Et la dimension de notre matrice d'attributs est passée à 1114 en raison de la mise en place de signes catégoriques.
Code source X_train, X_holdout, y_train, y_holdout = train_test_split(X, y, test_size=0.25, random_state=17) print(X_train.shape, X_holdout.shape)
((7119, 1114), (2374, 1114))
Nous formons le modèle.
Régression linéaire
Commençons par le modèle le plus léger et (attendu) le moins précis - la régression linéaire. Nous évaluerons à la fois la précision des données d'entraînement et l'échantillon retardé (holdout) - données que le modèle n'a pas vues.
Dans le cas d'une régression linéaire, le modèle plus ou moins acceptable se montre sur les données d'apprentissage, mais la précision sur l'échantillon retardé est monstrueusement faible. Bien pire que de prévoir la moyenne habituelle pour tous les billets.
Ici, vous devez prendre une courte pause et dire comment le modèle évalue la qualité en utilisant sa méthode de score.
L'évaluation se fait par le coefficient de détermination :
O Where Le résultat est-il prédit par le modèle a - la valeur moyenne pour l'ensemble de l'échantillon.
Nous ne nous attarderons pas trop sur le coefficient maintenant. Nous constatons seulement qu'il ne reflète pas pleinement l'exactitude du modèle qui nous intéresse. Par conséquent, en même temps, nous utiliserons l'erreur moyenne absolue (MAE) pour l'évaluer et nous y fier.
Code source lr = LinearRegression() lr.fit(X_train, y_train) print('R^2 train:', lr.score(X_train, y_train)) print('R^2 test:', lr.score(X_holdout, y_holdout)) print('MAE train', mean_absolute_error(lr.predict(X_train), y_train)) print('MAE test', mean_absolute_error(lr.predict(X_holdout), y_holdout))
R^2 train: 0.3884389470220214 R^2 test: -6.652435243123196e+17 MAE train: 8503.67256637168 MAE test: 1710257520060.8154
Augmentation du gradient
Eh bien, où sans elle, sans boost de gradient? Essayons de former le modèle et voyons ce qui se passe. Nous utiliserons pour cela le fameux XGBoost. Commençons par les paramètres hyperparamétriques standard.
Code source import xgboost xgb = xgboost.XGBRegressor() xgb.fit(X_train, y_train) print('R^2 train:', xgb.score(X_train, y_train)) print('R^2 test:', xgb.score(X_holdout, y_holdout)) print('MAE train', mean_absolute_error(xgb.predict(X_train), y_train)) print('MAE test', mean_absolute_error(xgb.predict(X_holdout), y_holdout))
R^2 train: 0.5138516547636054 R^2 test: 0.12965507684512545 MAE train: 7108.165167471887 MAE test: 8343.433260957032
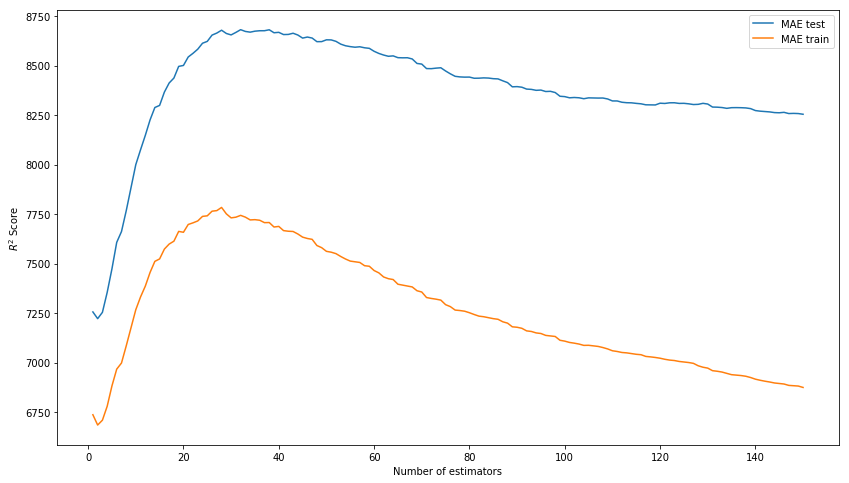
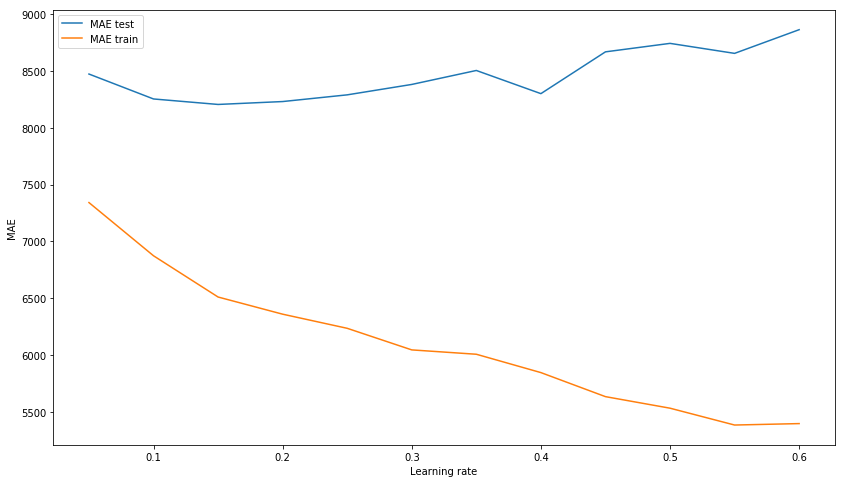
Le résultat hors de la boîte n'est plus mauvais. Essayons de modéliser le modèle en sélectionnant des hyperparamètres: n_estimators, learning_rate et max_depth. En conséquence, nous nous attardons sur les valeurs de 150, 0,1 et 3, respectivement, comme montrant le meilleur résultat sur l'échantillon de test en l'absence de surentraînement du modèle sur les données d'entraînement.
Nous sélectionnons n_estimateurs* Au lieu de R ^ 2, le score de l'image doit être MAE.
xgb_model_abs_testing = list() xgb_model_abs_training = list() rng = np.arange(1,151) for i in rng: xgb = xgboost.XGBRegressor(n_estimators=i) xgb.fit(X_train, y_train) xgb.score(X_holdout, y_holdout) xgb_model_abs_testing.append(mean_absolute_error(xgb.predict(X_holdout), y_holdout)) xgb_model_abs_training.append(mean_absolute_error(xgb.predict(X_train), y_train)) plt.figure(figsize=(14, 8)) plt.plot(rng, xgb_model_abs_testing, label='MAE test'); plt.plot(rng, xgb_model_abs_training, label='MAE train'); plt.xlabel('Number of estimators') plt.ylabel('$R^2 Score$') plt.legend(loc='best') plt.show();
Nous sélectionnons learning_rate xgb_model_abs_testing = list() xgb_model_abs_training = list() rng = np.arange(0.05, 0.65, 0.05) for i in rng: xgb = xgboost.XGBRegressor(n_estimators=150, random_state=17, learning_rate=i) xgb.fit(X_train, y_train) xgb.score(X_holdout, y_holdout) xgb_model_abs_testing.append(mean_absolute_error(xgb.predict(X_holdout), y_holdout)) xgb_model_abs_training.append(mean_absolute_error(xgb.predict(X_train), y_train)) plt.figure(figsize=(14, 8)) plt.plot(rng, xgb_model_abs_testing, label='MAE test'); plt.plot(rng, xgb_model_abs_training, label='MAE train'); plt.xlabel('Learning rate') plt.ylabel('MAE') plt.legend(loc='best') plt.show();
Nous sélectionnons max_depth xgb_model_abs_testing = list() xgb_model_abs_training = list() rng = np.arange(1, 11) for i in rng: xgb = xgboost.XGBRegressor(n_estimators=150, random_state=17, learning_rate=0.1, max_depth=i) xgb.fit(X_train, y_train) xgb.score(X_holdout, y_holdout) xgb_model_abs_testing.append(mean_absolute_error(xgb.predict(X_holdout), y_holdout)) xgb_model_abs_training.append(mean_absolute_error(xgb.predict(X_train), y_train)) plt.figure(figsize=(14, 8)) plt.plot(rng, xgb_model_abs_testing, label='MAE test'); plt.plot(rng, xgb_model_abs_training, label='MAE train'); plt.xlabel('Maximum depth') plt.ylabel('MAE') plt.legend(loc='best') plt.show();

Nous allons maintenant former le modèle avec des hyperparamètres sélectionnés.
Code source xgb = xgboost.XGBRegressor(n_estimators=150, random_state=17, learning_rate=0.1, max_depth=3) xgb.fit(X_train, y_train) print('R^2 train:', xgb.score(X_train, y_train)) print('R^2 test:', xgb.score(X_holdout, y_holdout)) print('MAE train', mean_absolute_error(xgb.predict(X_train), y_train)) print('MAE test', mean_absolute_error(xgb.predict(X_holdout), y_holdout))
R^2 train: 0.6745967150462303 R^2 test: 0.15415143189670344 MAE train: 6328.384400466232 MAE test: 8217.07897417256
Le résultat final avec les paramètres sélectionnés et la visualisation présente une importance - l'importance des signes selon le modèle. En premier lieu, il y a le nombre d'observateurs de billets, mais ensuite 4 ingénieurs partent immédiatement. Par conséquent, la durée d'emploi d'un ticket peut être assez fortement affectée par l'emploi d'un ingénieur. Et il est logique que le temps libre de certains d'entre eux soit plus important. Du moins parce que l'équipe a à la fois des ingénieurs seniors et des intermédiaires (nous n'avons pas de juniors dans l'équipe). Au fait, toujours en secret, l'ingénieur en premier lieu (barre orange) est vraiment l'un des plus expérimentés de toute l'équipe. De plus, ces 4 ingénieurs ont tous un préfixe senior à leur poste. Il s'avère que le modèle l'a une nouvelle fois confirmé.
Code source features_df = pd.DataFrame(data=xgb.feature_importances_.reshape(1, -1), columns=X.columns).sort_values(axis=1, by=[0], ascending=False) features_df.loc[0][0:10].plot(kind='bar', figsize=(16, 8), rot=75, fontsize=14);
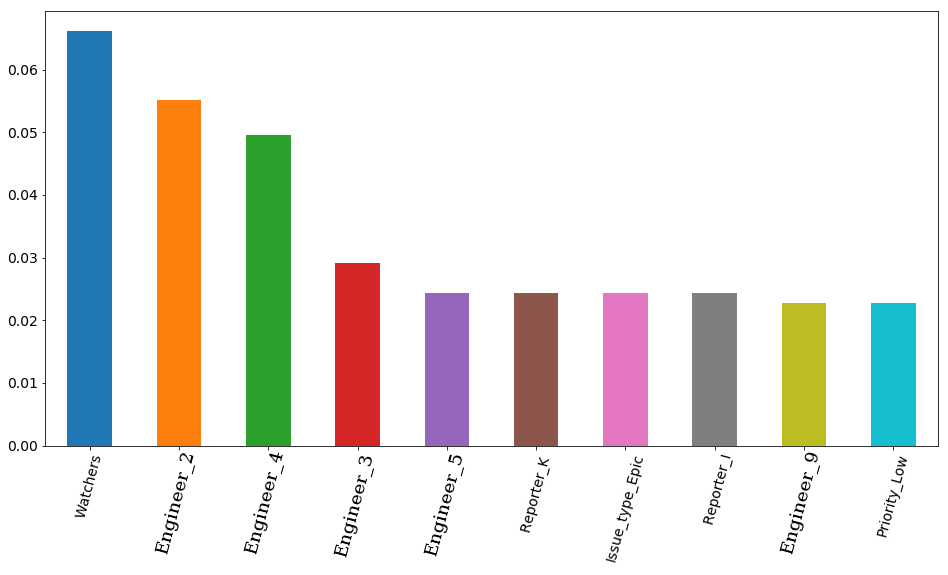
Réseau de neurones
Mais nous ne nous arrêterons pas à un seul boost de gradient et essayerons de former le réseau neuronal, ou plutôt le perceptron multicouche, un réseau neuronal à distribution directe entièrement connecté. Cette fois, nous ne commencerons pas avec les paramètres standard des hyperparamètres, car dans la bibliothèque sklearn, que nous utiliserons, par défaut, il n'y a qu'une seule couche cachée avec 100 neurones et pendant la formation, le modèle donne un avertissement sur le désaccord pour les 200 itérations standard. Nous utilisons immédiatement 3 couches cachées avec 300, 200 et 100 neurones, respectivement.
Par conséquent, nous constatons que le modèle n'est pas surentraîné sur l'échantillon d'apprentissage, ce qui ne l'empêche toutefois pas de montrer un résultat décent sur l'échantillon d'essai. Ce résultat est un peu inférieur au résultat de l'augmentation du gradient.
Code source from sklearn.neural_network import MLPRegressor nn = MLPRegressor(random_state=17, hidden_layer_sizes=(300, 200 ,100), alpha=0.03, learning_rate='adaptive', learning_rate_init=0.0005, max_iter=200, momentum=0.9, nesterovs_momentum=True) nn.fit(X_train, y_train) print('R^2 train:', nn.score(X_train, y_train)) print('R^2 test:', nn.score(X_holdout, y_holdout)) print('MAE train', mean_absolute_error(nn.predict(X_train), y_train)) print('MAE test', mean_absolute_error(nn.predict(X_holdout), y_holdout))
R^2 train: 0.9771443840549647 R^2 test: -0.15166596239118246 MAE train: 1627.3212161350423 MAE test: 8816.204561947616
Voyons ce que nous pouvons réaliser en essayant de choisir la meilleure architecture de notre réseau. , , 200 , , . .
plt.figure(figsize=(14, 8)) for i in [(500,), (750,), (1000,), (500,500)]: nn = MLPRegressor(random_state=17, hidden_layer_sizes=i, alpha=0.03, learning_rate='adaptive', learning_rate_init=0.0005, max_iter=200, momentum=0.9, nesterovs_momentum=True) nn.fit(X_train, y_train) plt.plot(nn.loss_curve_, label=str(i)); plt.xlabel('Iterations') plt.ylabel('MSE') plt.legend(loc='best') plt.show()

. 3 10 .
plt.figure(figsize=(14, 8)) for i in [(500,300,100), (80, 60, 60, 60, 40, 40, 40, 40, 20, 10), (80, 60, 60, 40, 40, 40, 20, 10), (150, 100, 80, 60, 40, 40, 20, 10), (200, 100, 100, 100, 80, 80, 80, 40, 20), (80, 40, 20, 20, 10, 5), (300, 250, 200, 100, 80, 80, 80, 40, 20)]: nn = MLPRegressor(random_state=17, hidden_layer_sizes=i, alpha=0.03, learning_rate='adaptive', learning_rate_init=0.001, max_iter=200, momentum=0.9, nesterovs_momentum=True) nn.fit(X_train, y_train) plt.plot(nn.loss_curve_, label=str(i)); plt.xlabel('Iterations') plt.ylabel('MSE') plt.legend(loc='best') plt.show()
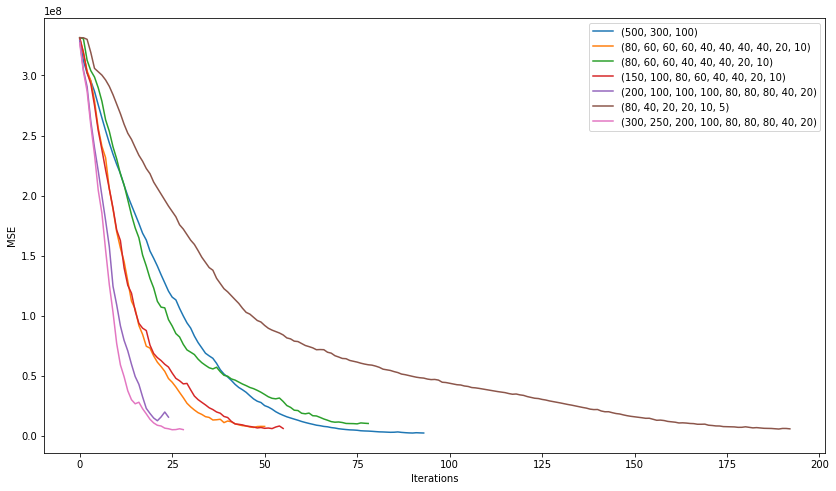
"" (200, 100, 100, 100, 80, 80, 80, 40, 20) :
2506
7351
, , . learning rate .
nn = MLPRegressor(random_state=17, hidden_layer_sizes=(200, 100, 100, 100, 80, 80, 80, 40, 20), alpha=0.1, learning_rate='adaptive', learning_rate_init=0.007, max_iter=200, momentum=0.9, nesterovs_momentum=True) nn.fit(X_train, y_train) print('R^2 train:', nn.score(X_train, y_train)) print('R^2 test:', nn.score(X_holdout, y_holdout)) print('MAE train', mean_absolute_error(nn.predict(X_train), y_train)) print('MAE test', mean_absolute_error(nn.predict(X_holdout), y_holdout))
R^2 train: 0.836204705204337 R^2 test: 0.15858607391959356 MAE train: 4075.8553476632796 MAE test: 7530.502826043687
, . , . , , .
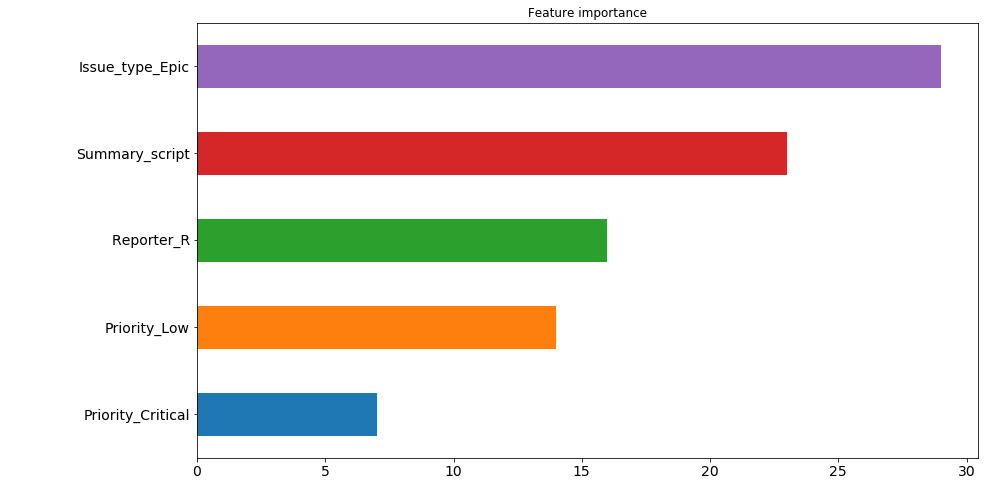
. : ( , 200 ). , "" . , 30 200 , issue type: Epic . , .. , , , , . 4 5 . , . , .
— 9 , . , , , .
pd.Series([X_train.columns[abs(nn.coefs_[0][:,i]).argmax()] for i in range(nn.hidden_layer_sizes[0])]).value_counts().head(5).sort_values().plot(kind='barh', title='Feature importance', fontsize=14, figsize=(14,8));
. ? 7530 8217. (7530 + 8217) / 2 = 7873, , , ? , . , . , 7526.
, kaggle . , , .
nn_predict = nn.predict(X_holdout) xgb_predict = xgb.predict(X_holdout) print('NN MSE:', mean_squared_error(nn_predict, y_holdout)) print('XGB MSE:', mean_squared_error(xgb_predict, y_holdout)) print('Ensemble:', mean_squared_error((nn_predict + xgb_predict) / 2, y_holdout)) print('NN MAE:', mean_absolute_error(nn_predict, y_holdout)) print('XGB MSE:', mean_absolute_error(xgb_predict, y_holdout)) print('Ensemble:', mean_absolute_error((nn_predict + xgb_predict) / 2, y_holdout))
NN MSE: 628107316.262393 XGB MSE: 631417733.4224195 Ensemble: 593516226.8298339 NN MAE: 7530.502826043687 XGB MSE: 8217.07897417256 Ensemble: 7526.763569558157
? 7500 . C'est-à-dire 5 . . . , .
( ):
((nn_predict + xgb_predict) / 2 - y_holdout).apply(np.abs).sort_values(ascending=False).head(10).values
[469132.30504392, 454064.03521379, 252946.87342439, 251786.22682697, 224012.59016987, 15671.21520735, 13201.12440327, 203548.46460229, 172427.32150665, 171088.75543224]
. , .
df.loc[((nn_predict + xgb_predict) / 2 - y_holdout).apply(np.abs).sort_values(ascending=False).head(10).index][['Issue_type', 'Priority', 'Worktype', 'Summary', 'Watchers']]
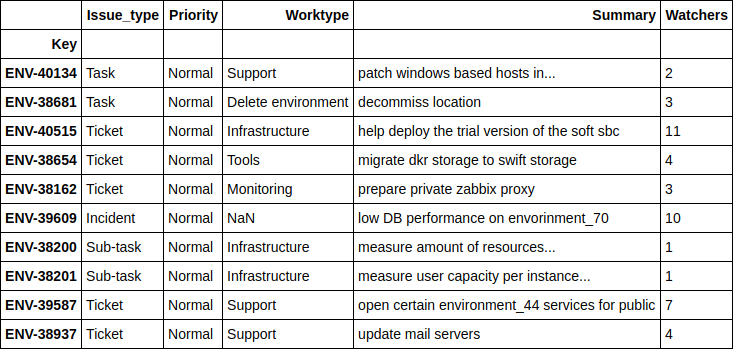
, - , . 4 .
, .
print(((nn_predict + xgb_predict) / 2 - y_holdout).apply(np.abs).sort_values().head(10).values) df.loc[((nn_predict + xgb_predict) / 2 - y_holdout).apply(np.abs).sort_values().head(10).index][['Issue_type', 'Priority', 'Worktype', 'Summary', 'Watchers']]
[ 1.24606014, 2.6723969, 4.51969139, 10.04159236, 11.14335444, 14.4951508, 16.51012874, 17.78445744, 21.56106258, 24.78219295]
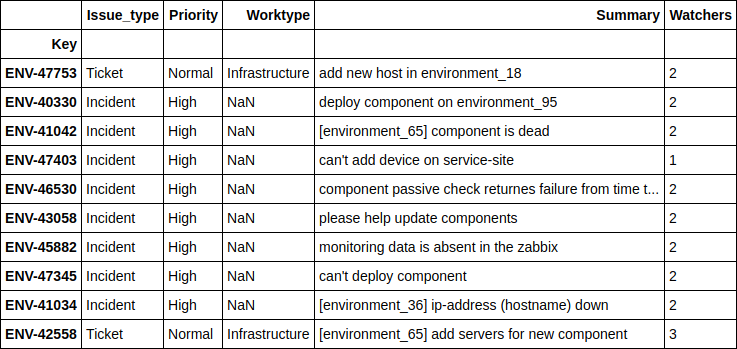
, , - , - . , , , .
Engineer
, 'Engineer', , , ? .
, 2 . , , , , . , , , "" , ( ) , , , . , " ", .
, . , , 12 , ( JQL JIRA):
assignee was engineer_N during (ticket_creation_date) and status was "In Progress"
10783 * 12 = 129396 , … . , , , .. 5 .
, , , , 2 . .
. SLO , .
, , ( : - , - , - ) , .