Cet article poursuit la discussion sur les améliorations de performances qui pourraient se réaliser sans les différents mais. La partie précédente sur StringBuilder est ici .
Nous examinons ici quelques «améliorations» rejetées en raison d'un manque de compréhension des subtilités de la spécification du langage, des cas d'angle non évidents et d'autres raisons. C'est parti!
Quand rien n'annonce des ennuis
Je pense que chacun de nous a travaillé avec les méthodes Collections.emptySet() / Collections.emptyList() . Ce sont des méthodes très utiles qui vous permettent de renvoyer une collection immuable vide sans créer de nouvel objet. En regardant à l'intérieur de la classe EmptyList nous allons voir ceci:
private static class EmptyList<E> { public Iterator<E> iterator() { return emptyIterator(); } public Object[] toArray() { return new Object[0]; } }
Vous voyez un fort potentiel d'amélioration? La méthode EmptyList.iterator() renvoie un itérateur vide de la présence, pourquoi ne pas faire la même feinte avec vos oreilles pour le tableau retourné par la méthode toArray() ?
En d'autres termes, la méthode doit toujours renvoyer un nouveau tableau.
Vous direz: "Il est immuable! Qu'est-ce qui peut mal tourner!?"
Seuls des experts expérimentés peuvent répondre à cette question:
- Qui est responsable?
- Experts responsables Paul Sandoz et Tagir Valeev
La réponse des expertshttp://mail.openjdk.java.net/pipermail/core-libs-dev/2017-September/049171.html
Notez également que cela modifie le comportement visible. E. g. quelqu'un peut se synchroniser sur l'objet tableau renvoyé par l'appel toArray, donc cette modification peut provoquer un partage de verrou indésirable.
Une fois, j'ai suggéré une amélioration similaire: renvoyer EMPTY_LIST de Arrays.asList () lorsque le tableau fourni a une longueur nulle. Il a été refusé pour la même raison [1].
http://mail.openjdk.java.net/pipermail/core-libs-dev/2015-September/035197.html
Au fait, il est probablement raisonnable pour Arrays.asList de vérifier la longueur du tableau comme:
public static <T> List<T> asList(T... a) { if(a.length == 0) return Collections.emptyList(); return new ArrayList<>(a); }
Cela semble raisonnable, non? Pourquoi créer une nouvelle liste pour un tableau vide si vous pouvez en prendre un tout prêt gratuitement?
Il y a une raison de ne pas le faire. Pour le moment, Arrays.asList ne spécifie aucune contrainte sur l'identité de la liste renvoyée. L'ajout de la micro-optimisation changera cela. C'est un cas de bord et un cas d'utilisation douteux aussi, mais étant donné que je laisserais les choses telles quelles.
Cette déclaration va probablement vous dérouter:
E. g. quelqu'un peut se synchroniser sur l'objet tableau renvoyé par l'appel toArray, donc cette modification peut provoquer un partage de verrou indésirable.
Vous direz: "Qui dans leur bon sens sera synchronisé sur la baie (!) Renvoyé (!!!) de la collection!?"
Cela ne semble pas très crédible, mais le langage offre une telle opportunité, ce qui signifie qu'il est possible qu'un certain utilisateur le fasse (ou l'ait déjà fait). Ensuite, le changement proposé modifiera au mieux le comportement du code, et au pire, il entraînera une panne de synchronisation (allez plus tard, rattrapez-le). Le risque est tellement injustifié et le gain escompté est si insignifiant qu'il vaut mieux tout laisser tel quel.
En général, la possibilité de synchroniser sur n'importe quel objet, kmk, était l'erreur des développeurs de langage. Premièrement, l'en-tête de chaque objet contient une structure responsable de la synchronisation, et deuxièmement, nous nous trouvons dans la situation décrite ci-dessus lorsqu'un objet apparemment immuable ne peut pas être retourné plusieurs fois, car il peut être synchronisé sur lui.
La morale de cette fable est la suivante: la spécification et la compatibilité descendante sont des vaches sacrées de Java. N'essayez même pas de les empiéter: le gardien tire sans prévenir.
Essayer, essayer ...
Il existe plusieurs classes basées sur des tableaux dans le JDK à la fois, et toutes implémentent les méthodes List.indexOf() et List.lastIndexOf() :
- java.util.ArrayList
- java.util.Arrays $ ArrayList
- java.util.Vector
- java.util.concurrent.CopyOnWriteArrayList
Le code de ces méthodes dans ces classes est répété presque un à un. De nombreuses applications et frameworks proposent également leurs solutions pour le même problème:
En conséquence, nous avons du code erroné qui doit être compilé (parfois parfois plusieurs fois), qui a lieu dans ReserverCodeCache, qui doit être testé, et qui se promène simplement de classe en classe avec presque aucun changement.
Les développeurs, à leur tour, aiment beaucoup écrire quelque chose comme
int i = Arrays.asList(array).indexOf(obj);
Je voudrais introduire des méthodes utilitaires généralisées dans le JDK et les utiliser partout, comme suggéré . Le patch est aussi simple que deux sous:
1) les implémentations de List.indexOf() et List.lastIndexOf() déplacent vers java.util.Arrays
2) à la place, Arrays.indexOf() et Arrays.lastIndexOf() sont appelés, respectivement
Il semblerait que ce qui pourrait mal tourner? Le gain de cette approche est [apparemment] évident. Mais l'article concerne les échecs, alors pensez à ce qui pourrait mal tourner.
- Qui est responsable?
- Experts responsables Martin Buchholz et Paul Sandoz
À mon humble avis, un peu tendu, mais néanmoinsMartin Buchholz:
Sergey, je suis en quelque sorte en train de maintenir toutes ces classes de collection, et j'ai parfois voulu également avoir des méthodes indexOf dans Array.java. Mais:
Les tableaux sont généralement déconseillés. Toutes les nouvelles méthodes statiques sur les tableaux (ou, là où je le souhaite, sur l'objet tableau lui-même! Nécessite un changement de langage java!) Rencontreront une résistance.
Nous en sommes venus à regretter de prendre en charge les valeurs null dans les collections, donc les classes de collection plus récentes comme ArrayDeque ne les prennent pas en charge.
Une autre variante que les utilisateurs pourraient souhaiter est le type de comparaison d'égalité à utiliser.
Nous en sommes venus à regretter d'avoir ArrayList avec un index de départ basé sur zéro - il aurait été préférable d'avoir le comportement de tableau circulaire d'ArrayDeque dès le premier jour.
Le code de recherche des tranches de tableau est très petit, vous n'économisez donc pas beaucoup. Il est facile de faire une erreur au coup par coup, mais cela est également vrai pour une API de tableaux.
Paul Sandoz:
Je n'irais pas jusqu'à dire que les tableaux sont découragés, je le tournerais positivement comme "à utiliser avec soin" car ils sont épineux, par exemple toujours modifiables. Ils pourraient certainement être améliorés. Je serais très heureux de voir des tableaux implémenter un tableau commun 'interface ish, nous pourrions être en mesure de faire des progrès après les types de valeur sédiment.
Tout nouvel ajout à Arrays se heurterait à une certaine résistance, du moins pour moi :-) Il n'ajoute jamais qu'une ou deux méthodes, beaucoup d'autres veulent également venir pour le trajet (toutes les primitives plus les variantes de gamme). Donc, toute nouvelle fonctionnalité doit être suffisamment bénéfique et dans ce cas, je ne pense pas que les avantages soient suffisamment forts (comme une éventuelle pression de cache du code de réduction).
Paul.
Correspondance: http://mail.openjdk.java.net/pipermail/core-libs-dev/2018-March/051968.html
La morale de cette fable est la suivante: votre ingénieux patch peut être abattu pour examen simplement parce qu'il n'y verra aucune valeur particulière. Eh bien, oui, il y a du code en double, mais cela ne dérange personne, alors laissez-le vivre.
Des améliorations pour ArrayList? Je les ai
Cyclomoteur le patch n'est pas le mien, je vais le poster pour que vous y réfléchissiez. La proposition elle-même a été exprimée ici et elle semble très attrayante. Voyez par vous-même:
A l'oeil nu, la proposition est très, très logique. Vous pouvez mesurer les performances à l'aide d'un simple benchmark :
@State(Scope.Benchmark) public class ArrayListBenchmark { @State(Scope.Benchmark) public static class Data { @Param({"10", "100", "1000", "10000"}) public int size; ArrayList<Integer> arrayRandom = new ArrayList<Integer>(size); @Setup(Level.Invocation) public void initArrayList() { Random rand = new Random(); rand.setSeed(System.currentTimeMillis());
Résumé:
Benchmark (size) Mode Cnt Score Error Units construct_new_array_list 10 thrpt 25 388.212 ± 23.110 ops/s construct_new_array_list 100 thrpt 25 90.208 ± 7.995 ops/s construct_new_array_list 1000 thrpt 25 23.289 ± 1.687 ops/s construct_new_array_list 10000 thrpt 25 7.659 ± 0.560 ops/s construct_new_array_list 10 thrpt 25 562.678 ± 37.370 ops/s construct_new_array_list 100 thrpt 25 119.791 ± 13.232 ops/s construct_new_array_list 1000 thrpt 25 33.811 ± 3.812 ops/s construct_new_array_list 10000 thrpt 25 10.889 ± 0.564 ops/s
Pas mal du tout pour un changement aussi simple. L'essentiel est qu'il ne semble pas y avoir de prise. Créez honnêtement un tableau, copiez honnêtement les données et n'oubliez pas la taille. Maintenant, ils doivent définitivement accepter le patch!
Mais c'était làMartin Buchholz:
Il ne fait aucun doute que nous pouvons optimiser le cas d'ArrayList -> ArrayList, mais qu'en est-il de toutes les autres implémentations de Collection? ArrayDeque et CopyOnWriteArrayList me viennent à l'esprit.
ArrayList est une classe populaire à utiliser pour faire des copies de collections. Où vous arrêtez-vous?
Une sous-classe pathologique d'ArrayList pourrait décider de ne pas stocker d'éléments dans le tableau de support, avec une rupture qui s'ensuit.
La solution bénie au problème de copie de liste est probablement List.copyOf https://docs.oracle.com/en/java/javase/11/docs/api/java.base/java/util/List.html#copyOf(java .util.Collection ) qui pourrait faire l'optimisation que vous espérez .
Alan Bateman
ArrayList n'est pas final, il est donc possible que quelqu'un l'ait étendu pour utiliser autre chose que elementData. Il pourrait être plus sûr d'utiliser l'identité de classe plutôt que instanceof.
Rien ne m'interdit de me dissocier d' ArrayList et de stocker des données dans une liste chaînée. Ensuite, c instanceof ArrayList retournera la vérité, nous arriverons dans la zone de copie et tomberons en toute sécurité.
La morale de cette fable est la suivante: un éventuel changement de comportement peut être la cause de l'échec. En d'autres termes, il faut garder à l'esprit la probabilité d'un changement, même le plus absurde, s'il est permis par le langage. Et oui, cela aurait pu fonctionner si ArrayList avait déclaré la final depuis le début.
Spécifications à nouveau
Lors du débogage de mon application, je suis accidentellement tombé dans les tripes de Spring et j'ai trouvé le code suivant:
Heureusement, en entrant dans java.lang.reflect.Constructor.getParameterTypes() j'ai fait défiler le code un peu plus bas et en ai trouvé un magnifique:
@Override public Class<?>[] getParameterTypes() { return parameterTypes.clone(); } public int getParameterCount() { return parameterTypes.length; }
Tu vois, oui? Si nous devons trouver le nombre d'arguments constructeur / méthode, il suffit d'appeler java.lang.reflect.Method.getParameterCount() et de ne pas copier le tableau. Vérifiez si le jeu en vaut la chandelle dans le cas le plus simple, dans lequel la méthode n'a pas de paramètres:
@State(Scope.Thread) @BenchmarkMode(Mode.AverageTime) @OutputTimeUnit(TimeUnit.NANOSECONDS) public class MethodToStringBenchmark { private Method method; @Setup public void setup() throws Exception { method = getClass().getMethod("toString"); } @Benchmark public int getParameterCount() { return method.getParameterCount(); } @Benchmark public int getParameterTypes() { return method.getParameterTypes().length; } }
Sur ma machine et avec JDK 11, cela se présente comme suit:
Benchmark Mode Cnt Score Error Units getParameterCount avgt 25 2,528 ± 0,085 ns/op getParameterCount:·gc.alloc.rate avgt 25 ≈ 10⁻⁴ MB/sec getParameterCount:·gc.alloc.rate.norm avgt 25 ≈ 10⁻⁷ B/op getParameterCount:·gc.count avgt 25 ≈ 0 counts getParameterTypes avgt 25 7,299 ± 0,410 ns/op getParameterTypes:·gc.alloc.rate avgt 25 1999,454 ± 89,929 MB/sec getParameterTypes:·gc.alloc.rate.norm avgt 25 16,000 ± 0,001 B/op getParameterTypes:·gc.churn.G1_Eden_Space avgt 25 2003,360 ± 91,537 MB/sec getParameterTypes:·gc.churn.G1_Eden_Space.norm avgt 25 16,030 ± 0,045 B/op getParameterTypes:·gc.churn.G1_Old_Gen avgt 25 0,004 ± 0,001 MB/sec getParameterTypes:·gc.churn.G1_Old_Gen.norm avgt 25 ≈ 10⁻⁵ B/op getParameterTypes:·gc.count avgt 25 2380,000 counts getParameterTypes:·gc.time avgt 25 1325,000 ms
Que pouvons-nous y faire? Nous pouvons rechercher l'utilisation de l'antipattern Method.getParameterTypes().length dans le JDK (au moins dans java.base ) et le remplacer là où cela a du sens:
java.lang.invoke.MethodHandleProxies
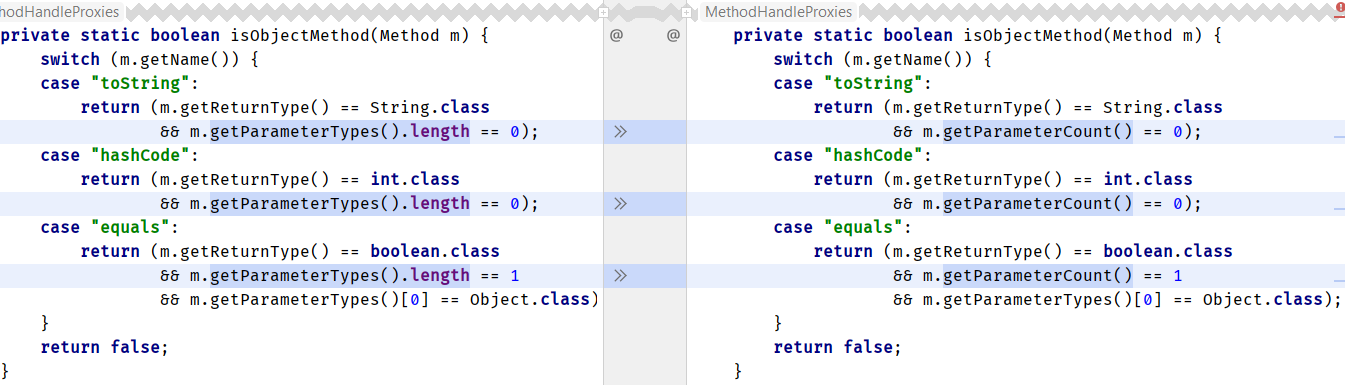
java.util.concurrent.ForkJoinTask
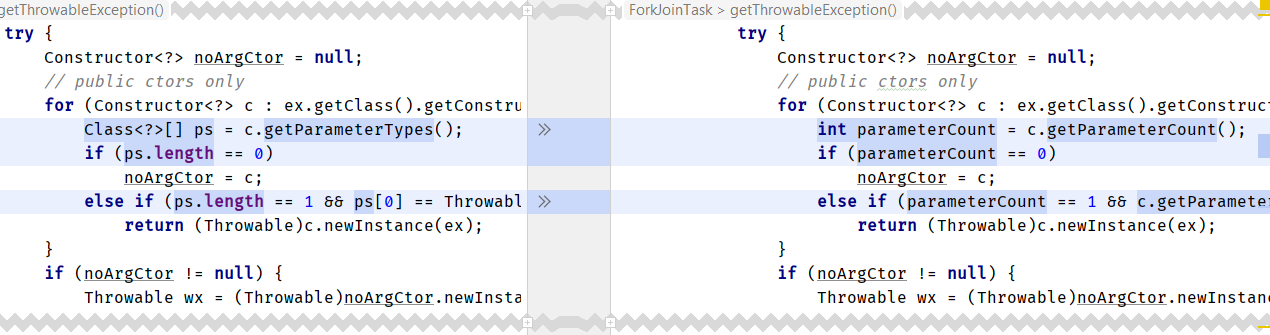
java.lang.reflect.Executable

sun.reflect.annotation.AnnotationType

Le patch a été envoyé avec une lettre de motivation .
Du coup, il s'est avéré que, depuis plusieurs années , la tâche était similaire, et même des changements y étaient préparés. Les commentaires ont noté une augmentation des performances assez décente pour de tels changements simples. Cependant, eux et mon patch sont nettoyés jusqu'à présent et restent immobiles. Pourquoi? Probablement parce que les développeurs sont trop occupés par des choses plus nécessaires et qu'ils n'y mettent bêtement pas la main.
La morale de cette fable est la suivante: vos changements ingénieux peuvent geler simplement par manque de travailleurs.
Mais ce n'est pas la fin! Au cours de la discussion sur la rationalité du remplacement décrit dans d'autres projets, des camarades plus expérimentés ont avancé une contre-proposition: peut-être que vous ne devriez pas faire le remplacement de Method.getParameterTypes().length -> Method.getParameterCount() avec vos mains, mais confier cela au compilateur? Est-ce possible et sera-t-il "légal"?
Essayons de vérifier en utilisant le test:
@Test void arrayClone() { final Object[] objects = new Object[3]; objects[0] = "azaza"; objects[1] = 365; objects[2] = 9876L; final Object[] clone = objects.clone(); assertEquals(objects.length, clone.length); assertSame(objects[0], clone[0]); assertSame(objects[1], clone[1]); assertSame(objects[2], clone[2]); }
qui passe, et qui montre que si le tableau cloné ne quitte pas la portée, alors il peut être supprimé, car l'accès à n'importe quel élément depuis ses cellules ou le champ de length peut être obtenu à partir de l'original.
Le JDK peut-il faire cela? Nous vérifions:
@State(Scope.Thread) @BenchmarkMode(Mode.AverageTime) @OutputTimeUnit(TimeUnit.NANOSECONDS) public class ArrayAllocationEliminationBenchmark { private int length = 10; @Benchmark public int baseline() { return new int[length].length; } @Benchmark public int baselineClone() { return new int[length].clone().length; } }
Sortie pour JDK 13:
Benchmark Mode Cnt Score Error Units baseline avgt 50 6,135 ± 0,140 ns/op baseline:·gc.alloc.rate.norm avgt 50 56,000 ± 0,001 B/op clone avgt 50 18,359 ± 0,619 ns/op clone:·gc.alloc.rate.norm avgt 50 112,000 ± 0,001 B/op
Il s'avère que openjdk ne sait pas lancer de new int[length] , contrairement au Graal , hehe:
Benchmark Mode Cnt Score Error Units baseline avgt 25 2,470 ± 0,156 ns/op baseline:·gc.alloc.rate.norm avgt 25 0,005 ± 0,008 B/op lone avgt 25 13,086 ± 1,059 ns/op lone:·gc.alloc.rate.norm avgt 25 112,113 ± 0,115 B/op
Il s'avère que vous pouvez modifier un peu le compilateur d'optimisation openjdk afin qu'il puisse faire ce que le Graal peut faire. Étant donné que non seulement tout le monde peut entrer dans une annonce positive dans le code VM et déposer quelque chose de significatif, je me suis limité à une lettre dans laquelle j'exprimais mes observations.
Il s'est avéré, et il y a plusieurs subtilités. Vladimir Ivanov indique que:
Étant donné qu'il n'y a aucun moyen de développer / réduire les tableaux Java,
La transformation "cloned_array.length => original_array.length" est correcte
indépendamment du fait que la variante clonée s'échappe ou non.
De plus, la transformation est déjà là:
http://hg.openjdk.java.net/jdk/jdk/file/tip/src/hotspot/share/opto/memnode.cpp#l2388
Je n'ai pas examiné les références que vous avez mentionnées, mais il semble que
L'accès cloned_array.length n'est pas la raison pour laquelle le tableau cloné est toujours
là.
Concernant vos autres idées, rediriger les accès de l'instance clonée vers
l'original est problématique (dans le cas général) car le compilateur doit prouver
il n'y a eu aucun changement dans les deux versions et les accès indexés rendent même
plus dur. Et les points de sécurité causent également des problèmes (pour la rematérialisation).
Mais je conviens qu'il serait intéressant de couvrir (au moins) des cas simples de
copie défensive.
Autrement dit, frapper un clone semble être possible et pas particulièrement difficile. Mais avec la conversion
int len = new int[arrayLength].length;
->
int len = arrayLength;
des difficultés surviennent:
Nous n'éliminons pas les allocations de tableaux qui n'ont pas une longueur connue
car ils peuvent provoquer une exception NegativeArraySize. Dans ce cas, nous
devrait être en mesure de prouver que la longueur est positive.
Quoi qu'il en soit - j'ai un patch presque terminé qui remplace le tableau inutilisé
allocations avec un gardien approprié.
En d'autres termes, vous ne pouvez pas simplement prendre et supprimer la création d'un tableau, car selon la spécification, l' exécution doit lever une NegativeArraySizeException et nous ne pouvons rien y faire:
@Test void arrayWithNwgativeSize() { int length = 0; try { int newLen = -3; length = new Object[newLen].length;
Pourquoi le Graal a-t-il pu? Je pense que la raison en est que la valeur du champ de length dans le benchmark ci-dessus était constante et toujours égale à 10, ce qui a permis au profileur de conclure que la vérification d'une valeur négative n'est pas nécessaire, ce qui signifie qu'elle peut être supprimée avec la création du tableau lui-même. Correct dans les commentaires si j'ai fait une erreur.
C'est tout pour aujourd'hui :) Ajoutez vos exemples dans les commentaires, nous comprendrons.