Créons un prototype d'agent d'apprentissage par renforcement (RL) qui maîtrisera la compétence de trading.
Étant donné que la mise en œuvre du prototype fonctionne en langage R, j'encourage les utilisateurs et les programmeurs R à se rapprocher des idées présentées dans cet article.
Ceci est une traduction de mon article en anglais:
Can Reinforcement Learning Trade Stock? Implémentation dans R.Je tiens à avertir les chasseurs de code que dans cette note, il n'y a qu'un code pour un réseau de neurones adapté pour R.Si je ne me suis pas distingué en bon russe, signalez les erreurs (le texte a été préparé avec l'aide d'un traducteur automatique).
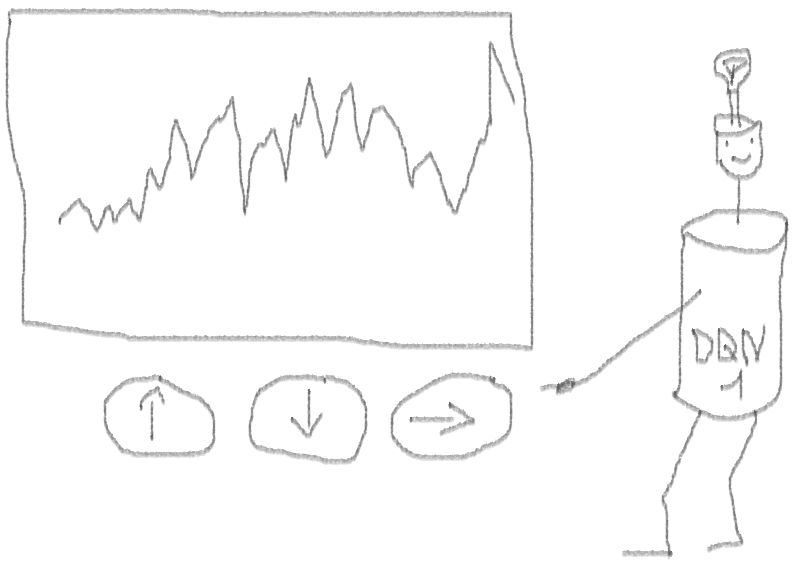
Introduction au problème
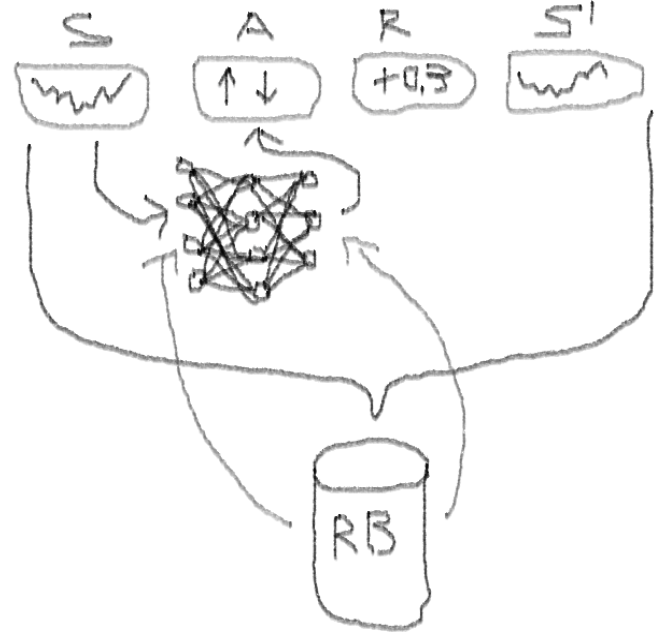
Je vous conseille de commencer à plonger dans le sujet avec cet article:
DeepMindIl vous présente l'idée d'utiliser le Deep Q-Network (DQN) pour approximer une fonction de valeur qui est critique dans les processus décisionnels de Markov.
Je recommande également d'approfondir les mathématiques en utilisant la préimpression de ce livre de Richard S. Sutton et Andrew J. Barto:
Reinforcement LearningCi-dessous, je présenterai une version étendue du DQN original, qui comprend plus d'idées qui aident l'algorithme à converger rapidement et efficacement, à savoir:
Deep Double Dueling Noisy NN avec sélection prioritaire dans le tampon de lecture d'expérience.
Qu'est-ce qui rend cette approche meilleure que le DQN classique?
- Double: il y a deux réseaux, dont l'un est formé, et l'autre évalue les valeurs suivantes de Q
- Duel: il y a des neurones qui valorisent et bénéficient clairement
- Bruyant: il existe des matrices de bruit appliquées aux poids des couches intermédiaires, où la moyenne et les écarts-types sont des poids entraînés
- Priorité d'échantillonnage: les lots d'observations du tampon de lecture contiennent des exemples, en raison desquels la formation préalable des fonctions a conduit à de gros résidus qui peuvent être stockés dans la matrice auxiliaire.
Eh bien, qu'en est-il du commerce effectué par l'agent DQN? C'est un sujet intéressant en tant que tel.
Il y a des raisons pour lesquelles cela est intéressant:
- Liberté absolue de choix des représentations de statut, d'actions, de récompenses et d'architecture de NN. Vous pouvez enrichir l'espace d'entrée avec tout ce que vous jugez digne d'essayer, des nouvelles aux autres actions et indices.
- La correspondance de la logique de négociation avec la logique d'apprentissage du renforcement est la suivante: l'agent effectue des actions discrètes (ou continues), est rarement récompensé (après la clôture de la transaction ou l'expiration de la période), l'environnement est partiellement observable et peut contenir des informations sur les prochaines étapes, le commerce est un jeu épisodique.
- Vous pouvez comparer les résultats DQN avec plusieurs références, telles que les indices et les systèmes de trading techniques.
- L'agent peut apprendre continuellement de nouvelles informations et ainsi s'adapter aux règles changeantes du jeu.
Afin de ne pas étirer la matière, regardez le code de ce NN, que je veux partager, car c'est une des parties mystérieuses de l'ensemble du projet.
Code R pour un réseau neuronal de valeur utilisant Keras pour construire notre agent RL
J'ai utilisé cette source pour adapter le code Python pour la partie bruit du réseau:
github repoCe réseau de neurones ressemble à ceci:
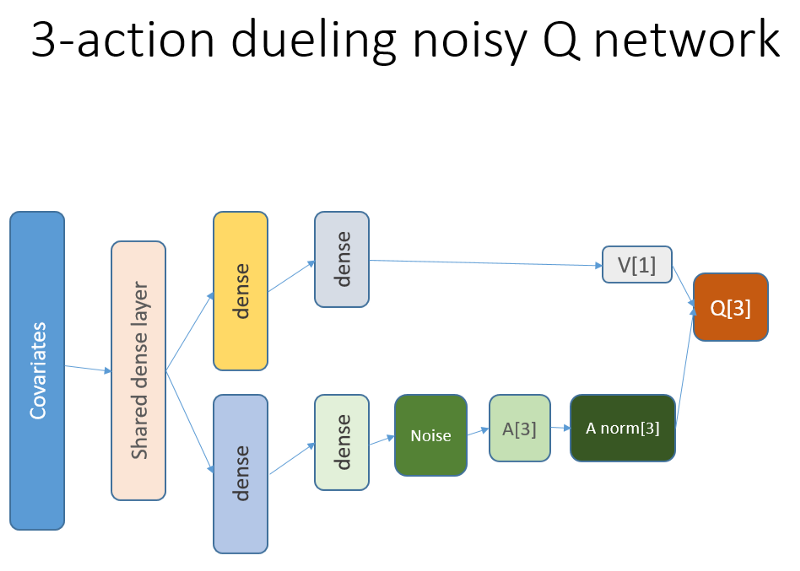
Rappelons que dans l'architecture duel, nous utilisons l'égalité (équation 1):
Q = A '+ V, où
A '= A - moy (A);
Q = valeur de l'état-action;
V = valeur d'état;
A = avantage.
D'autres variables du code parlent d'elles-mêmes. De plus, cette architecture n'est valable que pour une tâche spécifique, alors ne la prenez pas pour acquise.
Le reste du code sera probablement assez générique pour la publication, et il sera intéressant pour le programmeur de l'écrire vous-même.
Et maintenant - les expériences. Le test du travail de l'agent a été effectué dans un bac à sable, loin des réalités du trading sur un marché en direct, avec un vrai courtier.
Phase I
Nous exécutons notre agent sur un ensemble de données synthétique. Notre coût de transaction est de 0,5:
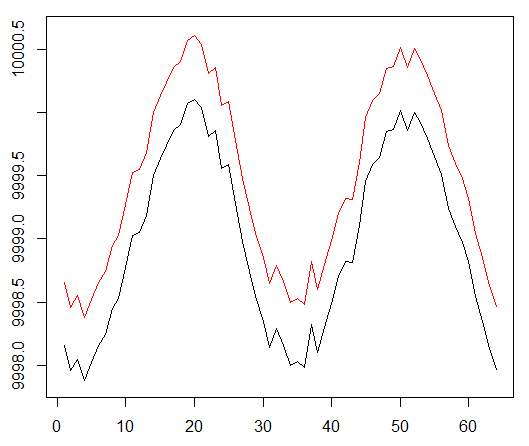
Le résultat est excellent. La récompense épisodique moyenne maximale dans cette expérience
devrait être de 1,5.
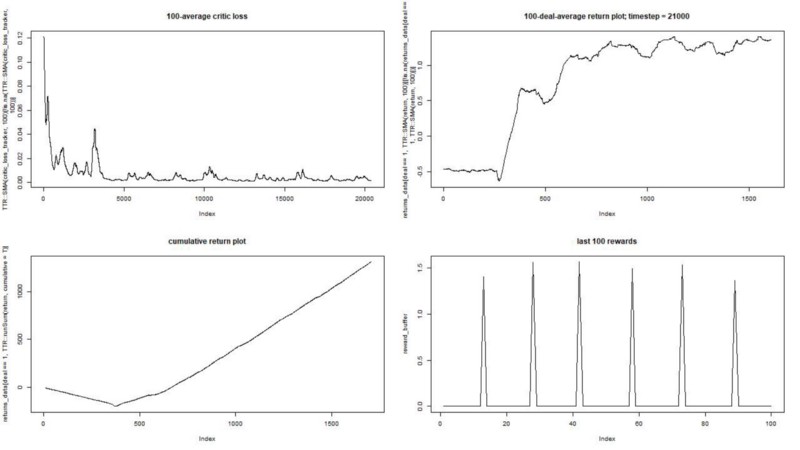
On voit: perte de critique (le soi-disant réseau de valeur dans l'approche acteur-critique), récompense moyenne pour un épisode, récompense accumulée, échantillon de récompenses récentes.
Phase II
Nous enseignons à notre agent un symbole boursier choisi arbitrairement qui démontre un comportement intéressant: un début plat, une croissance rapide au milieu et une fin morne. Dans notre kit de formation environ 4300 jours. Le coût de transaction est fixé à 0,1 dollar américain (délibérément bas); La récompense est le profit / la perte en USD après la conclusion d'un accord d'achat / vente de 1,0 action.
Source:
finance.yahoo.com/quote/algn?ltr=1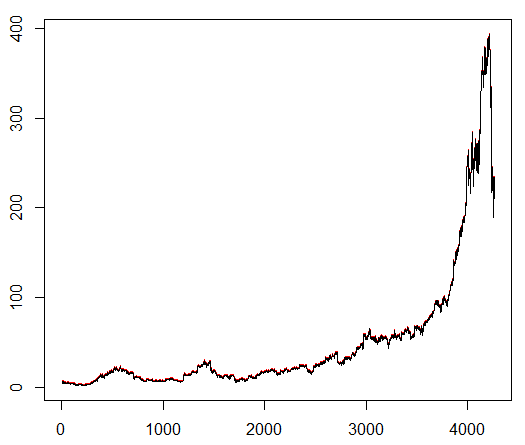 NASDAQ: ALGN
NASDAQ: ALGNAprès avoir défini certains paramètres (en laissant l'architecture NN identique), nous sommes arrivés au résultat suivant:

Cela s'est avéré pas mal, car l'agent a finalement appris à faire du profit en appuyant sur trois boutons de sa console.
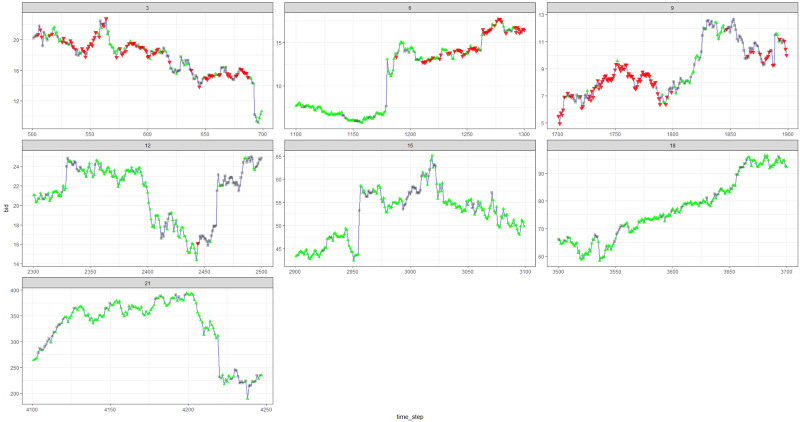 marqueur rouge = vendre, marqueur vert = acheter, marqueur gris = ne rien faire.
marqueur rouge = vendre, marqueur vert = acheter, marqueur gris = ne rien faire.Veuillez noter qu'à son apogée, la récompense moyenne par épisode a dépassé la valeur de transaction réaliste qui peut être rencontrée dans le trading réel.
Dommage que les actions chutent comme des folles à cause des mauvaises nouvelles ...
Observations finales
Négocier avec RL est non seulement difficile, mais également utile. Lorsque votre robot le fait mieux que vous, il est temps de consacrer votre temps personnel à l'éducation et à la santé.
J'espère que ce fut un voyage intéressant pour vous. Si vous avez aimé cette histoire, agitez la main. S'il y a beaucoup d'intérêt, je peux continuer et vous montrer comment fonctionnent les méthodes de gradient de politique en utilisant le langage R et l'API Keras.
Je remercie également mes amis qui s'intéressent aux réseaux de neurones pour leurs conseils.
Si vous avez encore des questions, je suis toujours là.