Je vais parler de la pêche à la traîne en mathématiques. Ce ne sont pas des trucs de hackers à la mode, c'est plutôt une expression artistique, une drôle de technologie intelligente pour que les gens vous considèrent comme un crétin. Je vais maintenant vérifier si mon rapport est prêt à être affiché à l'écran. Tout semble bien se passer, je peux donc me présenter.

Je m'appelle Frank Tu, épelé frank ^ 2 et @franksquared sur Twitter, car Twitter a également une sorte de spammeur nommé "frank 2". J'ai essayé de leur appliquer l'ingénierie sociale pour qu'ils suppriment son compte, car techniquement c'est du spam et j'ai le droit de m'en débarrasser comme mon clone. Mais apparemment, si vous les traitez honnêtement, ils ne font pas la même chose, car malgré ma demande de supprimer le compte de spammeur, ils n'y ont rien fait, alors j'ai envoyé ce putain de Twitter en enfer.
Beaucoup de gens me reconnaissent par ma casquette. Je travaille dans les groupes régionaux DefCon DC949 et DC310. Je travaille également avec Rapid7, mais je ne peux pas en parler ici sans utiliser un langage grossier, et mon manager ne veut pas que je jure. J'ai donc préparé cette présentation pour DefCon et je vais respecter le délai de 15 minutes, bien que ce soit un sujet assez compliqué. Il s'agit essentiellement d'une présentation standard qui se concentre sur la rétro-ingénierie et les choses amusantes connexes.
Lors de la discussion de ce sujet sur Twitter, deux camps se sont formés. Un gars a dit: "Je ne sais pas de quoi parle ce putain de franc ^ 2, mais c'est génial!" Le deuxième gars de Reddit a vu mes diapositives et était bouleversé par les liens vers des choses qui n'étaient pas liées au sujet, était en colère qu'un sujet aussi sérieux n'ait pas été entièrement couvert, donc je souhaitais que ma présentation ait "plus de contenu et moins de déchets".

Par conséquent, je veux me concentrer sur cette citation. Rien de personnel, mec de Reddit - je dis cela non seulement au cas où il serait présent dans cette pièce, mais aussi parce que c'était une critique juste. Parce qu'une conversation qui ne contient pas suffisamment de contenu utile est une conversation vide.
Le sujet de ma conversation est une routine standard pour les pirates, mais il me semble qu'en fait, les intervenants n'essaient généralement pas de présenter leurs informations de manière divertissante, même lorsque cela est possible, préférant des conclusions sèches et émasculées. "Voici l'IP, voici l'ESP, voici comment vous pouvez effectuer un exploit, voici mon" zéro jour ", maintenant applaudissez!" - et tout le monde tape des mains.
Merci pour les applaudissements, je l'apprécie! Il me semble qu'il y a beaucoup de points intéressants dans mon matériel, donc il mérite d'être énoncé d'une manière quelque peu divertissante, ce que j'essaierai de faire.
Vous verrez une attitude exceptionnellement superficielle envers l'informatique et l'humour complètement enfantin, alors j'espère que vous apprécierez ce que je vais montrer ici. Je suis désolé si vous êtes venu ici à la recherche d'une conversation sérieuse.
Sur la diapositive, vous voyez une analyse scientifique de mon dernier rapport comparant la part d'une approche strictement scientifique et la part d'un «médicament» qui assure la sécurité informatique.

Vous voyez qu'il y a beaucoup plus de «drogues», mais ne vous inquiétez pas, maintenant la part de la science a légèrement augmenté.

Il y a quelque temps, mon ami Merlin, assis ici au premier plan, a écrit un bot étonnant basé sur le script IRC Python, qui n'occupe qu'une seule ligne.
C'est un exercice vraiment génial pour apprendre la programmation fonctionnelle, ce qui est très amusant à jouer. Vous pouvez simplement ajouter une fonction après l'autre et obtenir des combinaisons de toutes sortes de fonctions différentes, et tout cela est dessiné sur l'écran comme une vague arc-en-ciel, en général, c'est l'une des choses les plus stupides que vous puissiez faire.
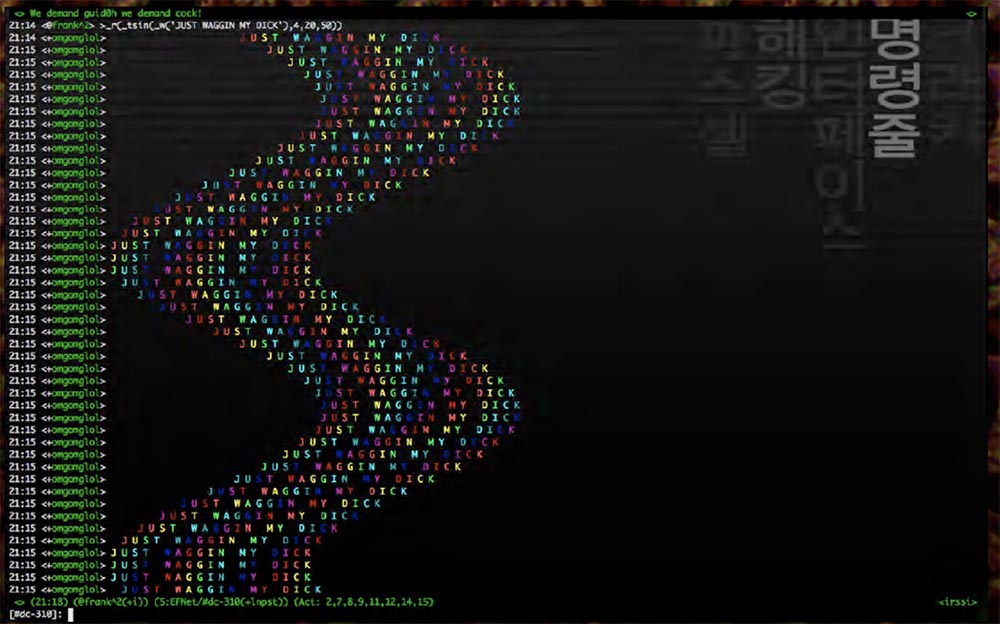
Je pensais que si vous appliquez ce principe aux fichiers binaires? Je ne sais pas d'où vient cette idée, mais elle s'est avérée géniale! Cependant, je veux clarifier certains concepts de base.
Il est possible que votre professeur de mathématiques ait présenté ces fonctions beaucoup plus compliquées qu'elles ne le sont réellement.

Ainsi, la formule f (x) a un sens très simple, elle fonctionne comme des fonctions ordinaires. Vous avez X, vous avez une entrée, puis vous obtenez X 7 fois, ce qui est égal à votre valeur. En Python, vous pouvez créer une fonction (lambda x: x * 7). Si vous voulez travailler avec Java - je suis désolé, j'espère que vous ne voudrez jamais faire ça - alors vous pouvez faire quelque chose comme:
public static int multiplyBySevenAndReturn(Integer x) { return x * 7; }
Vous savez, les fonctions mathématiques peuvent même être beaucoup plus compliquées, mais c'est tout ce que nous devons savoir à leur sujet pour le moment.
Si vous regardez l'assemblage de code, vous remarquerez que les instructions JMP et CALL ne sont pas liées à des valeurs spécifiques; elles fonctionnent avec un décalage. Si vous utilisez un débogueur, vous pouvez voir que le JMP00401000 ressemble plus à une instruction de transfert vers octets qu'à une instruction spécifique pour passer à 5 ou 10 octets. La même chose s'applique à la fonction CALL, sauf qu'elle pousse tout un tas de choses sur votre pile. L'exception est le cas lorsque vous «collez» l'adresse au registre, c'est-à-dire que vous accédez à une adresse spécifique. Tout se passe ici d'une manière complètement différente. Après avoir raccordé l'adresse au registre et effectué quelque chose comme APPELER EAX, la fonction accède à la valeur spécifique dans EAX. Il en va de même pour CALL [EAX] ou JMP [EAX] - il déréférence simplement EAX et va à cette adresse. Lorsque vous utilisez un débogueur, vous ne pourrez peut-être pas déterminer à quelle adresse spécifique CALL accède. Cela peut être un problème, vous devez donc en être conscient.
Regardons la fonction de saut court JMP SHORT. Il s'agit d'une instruction spéciale dans l'architecture x86 qui vous permet d'utiliser un décalage de 1 octet au lieu d'un décalage de 4 octets, ce qui réduit l'espace mémoire utilisé. Cela importera plus tard pour toutes les manipulations qui se produiront avec des instructions individuelles. Il est important de garder à l'esprit que JMP SHORT a une plage de 256 octets. Cependant, il n'y a rien de tel qu'un CALL SHORT.

Considérons maintenant la sorcellerie de l'informatique. Au milieu de la création de ces diapositives, j'ai réalisé qu'en fait, vous pouvez définir un assemblage comme un espace nul, c'est-à-dire qu'il n'y a techniquement aucun espace entre chaque instruction. Si vous regardez les instructions individuelles, vous verrez que chacune est exécutée l'une après l'autre. Techniquement, cela peut être interprété comme un saut inconditionnel à l'instruction suivante. Cela nous donne un espace entre chaque instruction d'assemblage, tandis que chaque instruction est associée de manière correspondante à un saut inconditionnel.
Si vous regardez cet exemple d'assemblage, au fait, ce sont des choses très simples que je recommande de décoder avec ASCII, il ne s'agit donc que d'un ensemble d'instructions régulières.
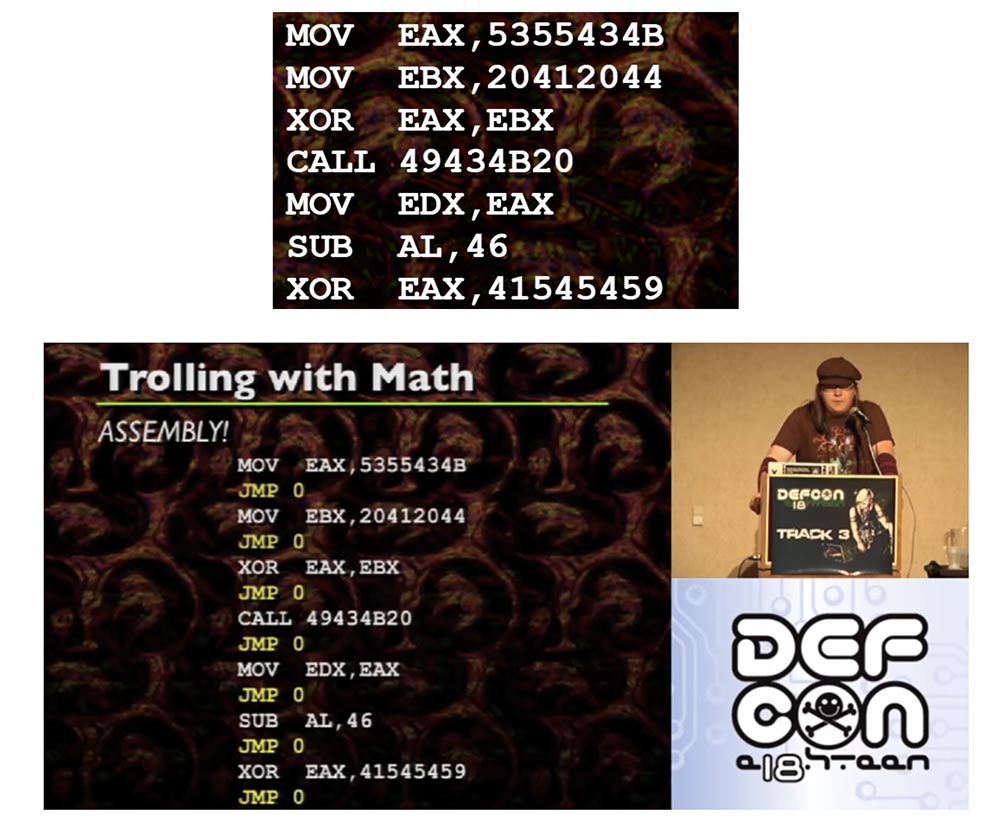
Les 0 JMP situés entre chaque instruction sont des sauts inconditionnels que vous ne voyez généralement pas. Ils se suivent après chaque instruction. Par conséquent, il est possible de placer chaque instruction d'assemblage individuelle dans un emplacement de mémoire arbitraire si et seulement si chaque instruction d'unité est accompagnée d'un saut inconditionnel à l'instruction suivante. Parce que si vous transférez l'assembly et que vous devez utiliser le même code qu'auparavant, vous devez attacher un saut inconditionnel à chaque instruction.
Regardons plus loin. Un tableau unidimensionnel peut techniquement être interprété comme un tableau bidimensionnel, il nécessite juste un peu de mathématiques, de lignes ou quelque chose comme ça, je ne le dirai pas avec certitude, mais ce n'est pas trop difficile. Cela nous donne l'occasion d'interpréter l'emplacement en mémoire sous la forme d'un réseau (x, y). En combinaison avec l'interprétation de l'espace vide entre les instructions comme des sauts inconditionnels qui peuvent être liés les uns aux autres, nous pouvons littéralement dessiner des instructions. C'est génial!
Pour mettre cela en pratique, vous devez effectuer les étapes suivantes:
- démonter chaque instruction pour découvrir quel est le code;
- Allouez une place en mémoire beaucoup plus grande que la taille du jeu d'instructions. Je réserve généralement 10 fois plus de mémoire que la taille du code;
- pour chaque instruction, déterminer f (x);
- mettre chaque instruction à l'emplacement correspondant (x, y) en mémoire;
- attacher un saut inconditionnel à l'instruction;
- marquez la mémoire comme exécutable et exécutez le code.
Malheureusement, de nombreuses questions se posent ici. C'est comme avec la gravité, qui ne fonctionne qu'en théorie, mais en pratique, nous voyons une chose complètement différente. Parce qu'en réalité, x86 envoie en enfer vos instructions JMP, les instructions CALL, déforme votre code auto-référentiel, code auto-modifiant qui utilise l'itération.

Commençons par les instructions JMP. Étant donné que les instructions JMP sont biaisées, lorsqu'elles sont placées dans un endroit arbitraire, elles ne pointent plus vers où vous pensez qu'elles devraient pointer. SHORT JMP se retrouve dans une position similaire. Placés accidentellement par votre fonction (x, y), ils n'indiqueront pas sur quoi vous comptez. Mais contrairement aux JMP longs, les JMP courts sont plus faciles à corriger, surtout si vous avez affaire à un tableau unidimensionnel. SHORT JMP est facile à convertir en JMP standard, mais vous devez ensuite déterminer ce qu'est devenu le nouveau décalage.
Travailler avec des JMP basés sur des registres est toujours un casse-tête, et comme ils nécessitent des décalages serrés et peuvent être calculés au moment de l'exécution, il n'y a pas de moyen facile de savoir où ils vont. Pour détecter automatiquement chaque registre, vous devez utiliser un tas de connaissances issues de la théorie de la compilation. Au moment de l'exécution, il peut y avoir des pointeurs de fonction, des pointeurs de classe, etc. Certes, si vous ne voulez pas faire de travail supplémentaire pour faire tout cela, vous ne pouvez pas le faire. Les fonctions f (x) fonctionnent en code réel pas aussi élégamment que sur papier. Si vous voulez le faire correctement, vous devrez faire beaucoup de travail.
Pour définir des pointeurs de classe et des choses comme ça, vous devez conjurer avec C et C ++. Avant de sauvegarder, lors du démontage, convertissez votre SHORT JMP en JMP normal, car il faut faire face aux biais, c'est assez simple.
Essayer de calculer les déplacements réels est un énorme casse-tête. Toutes les instructions que vous trouvez ont des décalages qui se déplacent lorsque le code se déplace et doivent être recalculées. Cela signifie que vous devez suivre les instructions et indiquer où elles se déplacent en tant qu'objectifs. C’est difficile pour moi de vous expliquer sur les diapositives, mais un exemple de comment y parvenir est sur le CD avec le matériel de cette conférence.
Après avoir placé toutes les instructions, remplacez les anciens décalages par les nouveaux décalages. Si vous n'avez pas endommagé le déplacement, alors tout ira bien. Maintenant que vous vous êtes préparé, il existe une réelle opportunité de mettre en œuvre l'idée au plus haut niveau. Pour ce faire, vous avez besoin de:
- démonter les instructions;
- préparer un tampon mémoire;
- initialiser les constantes disponibles f (x);
- itérer sur f (x) et certains pointeurs de données, selon lesquels votre code sera écrit lors du suivi des putains d'instructions;
- Attribuer des instructions aux index créés correspondants;
- corriger tous les sauts conditionnels;
- marquer la nouvelle partition mémoire comme exécutable;
- exécuter du code.
Si vous remettez les choses à leur place, alors nous obtenons des choses étranges - tout est foiré, les instructions sautent dans des lieux de mémoire obscurs, et tout cela semble tout simplement enchanteur.

Est-ce que tout cela a une signification pratique ou est-ce juste une représentation de cirque? La valeur appliquée de ces transformations est la suivante. Isoler les instructions d'assemblage et quelques étapes pour calculer f (x) nous permet de placer ces instructions d'assemblage n'importe où dans le tampon sans aucune intervention de l'utilisateur. Pour confondre les chemins d'exécution de code, tout ce que vous avez à faire est d'écrire mathématiquement la fonction et les pointeurs dans un assembleur, en les choisissant au hasard.
Cela simplifie considérablement les techniques de codage polymorphe. Au lieu d'écrire du code à chaque fois qui manipule votre code d'une certaine manière, vous pouvez écrire une série de fonctions qui déterminent aléatoirement la position de votre code, puis sélectionnez ces fonctions comme aléatoires, etc.
Anti-reverse n'est pas aussi cool et frais que la technique anti-débogage.
L'anti-version ne dépend pas du plaisir que vous obtenez à rendre impossible l'utilisation de l'IDA, ni de la façon dont vous gâcherez l'ordinateur du Reverser avec des images GNAA Last Measure, bien que ce soit sacrément amusant. Anti-inversion signifie simplement être un connard, car si vous, comme le dernier connard, obtenez un Reverser, un mec qui rompt la protection de différents systèmes, il se mettra simplement en colère, enverra ce programme malveillant en enfer et partira.
Pendant ce temps, vous pourrez vendre tous vos bots aux réseaux d'entreprises russes, car avec votre logiciel vous «baissez» tous ceux impliqués dans la rétro-ingénierie. Tout le monde sait comment trouver des techniques anti-débogage sur Google, mais ils n'y trouveront pas de solutions aux problèmes résultant de choses créatives. Les anti-revolvers les plus créatifs feront que les inverseurs casseront leurs doigts du clavier et laisseront des trous de la taille d'un poing dans les murs. Les inverseurs vont bouillir de colère, ils ne comprendront pas ce que vous avez fait, parce que votre code a tout gâché.
C'est une sorte de jeu nerveux, une chose psychologique, si vous êtes créatif dans ce domaine et créez un anti-retour vraiment magnifique, vous pouvez en être fier. Mais vous savez qu'en fait, vous essayez simplement de les éloigner de votre code.
Alors qu'est-ce que je vais faire? Je vais prendre les fonctions d'obscurcissement et les confondre. Ensuite, je vais utiliser la deuxième version de l'obfuscation des fonctions enchevêtrées et appliquer à nouveau l'obfuscation. Alors, tirons le code. Ceci est un exemple de pêche à la traîne mathématique, que j'ai pris comme exemple.
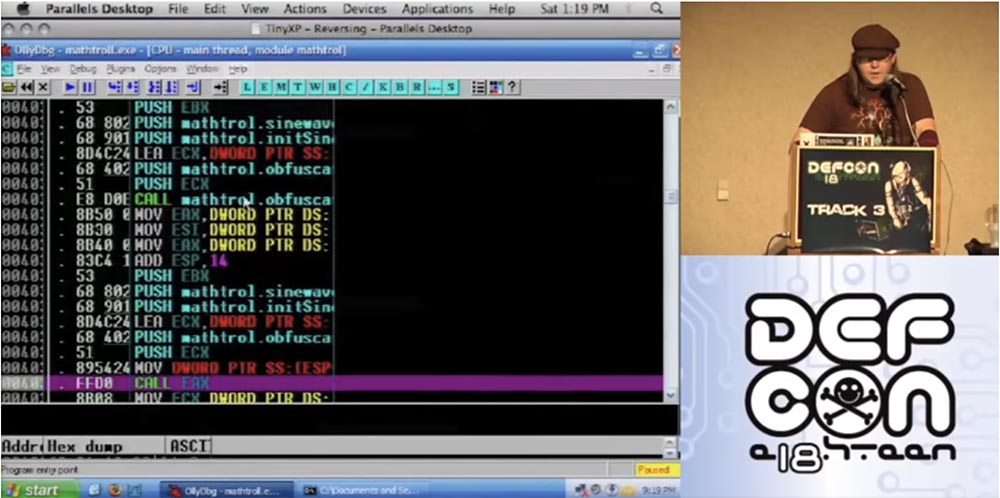
Ainsi, j'entre la commande "confuse by formula" dans la fenêtre qui s'ouvre.
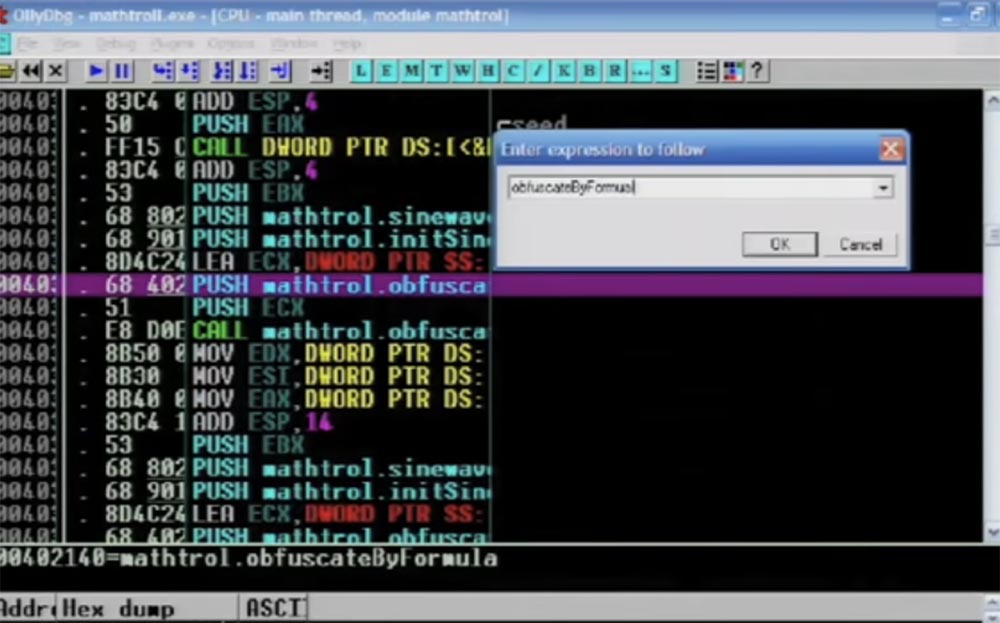
Ensuite, vous voyez des instructions d'assemblage qui font leur travail. Notez que j'utilise C ++ ici, bien qu'à la moindre occasion j'essaye d'éviter cela.
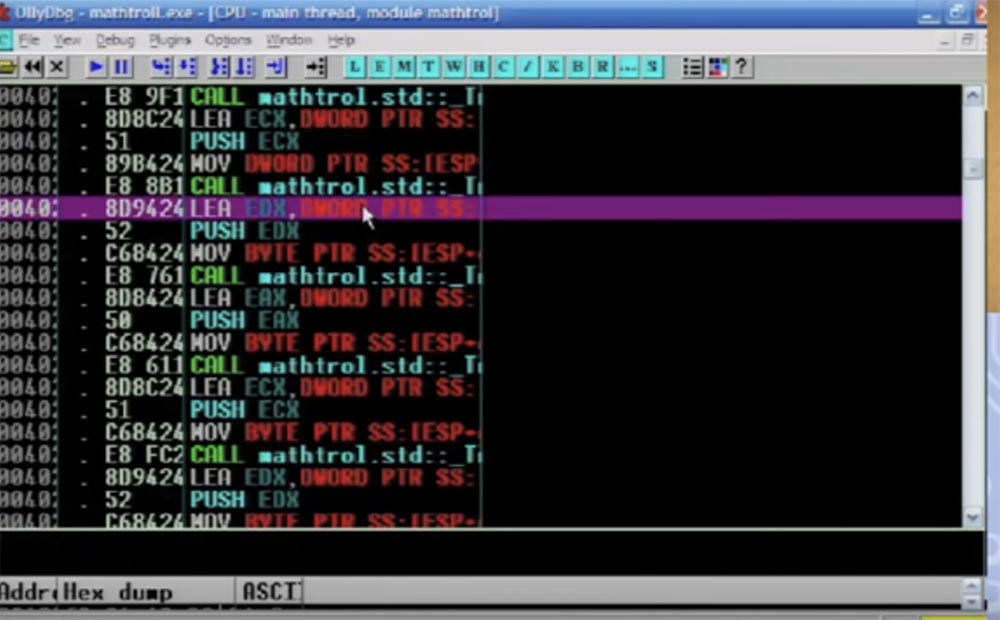
Ici, la fonction active CALL EAX est mise en évidence, puis l'instruction de saut à appliquer suit, vous voyez un tas de toutes sortes de choses différentes dans le tampon, et tout cela se fait avec chaque instruction individuelle.
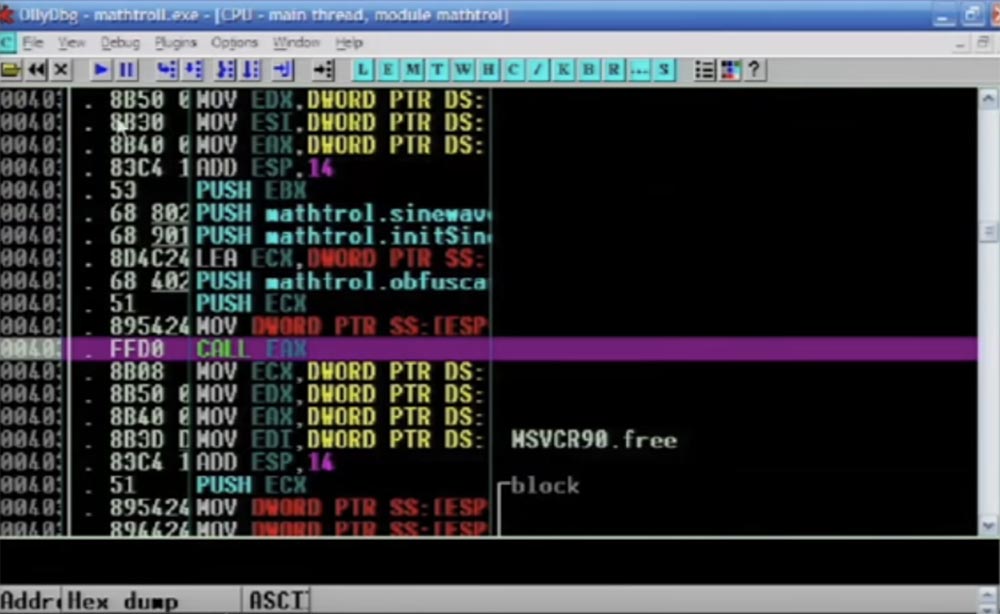

Maintenant, je rembobine le programme jusqu'à la fin, et vous verrez le résultat. Donc, le code a toujours fière allure, un tas d'instructions JMP sont compilées ici, cela semble déroutant et en fait, il est déroutant.
La diapositive suivante montre une représentation graphique de l'apparence de la pile.

Chaque fois que cela se produit, je génère une formule d'onde sinusoïdale aléatoire de forme arbitraire, vous voyez ici un tas de formes différentes, et c'est cool. Je pense que le code commence quelque part en haut à gauche, mais je ne me souviens pas exactement. Il tord donc tout, vous pouvez non seulement faire des sinusoïdes, mais aussi tordre les spirales.
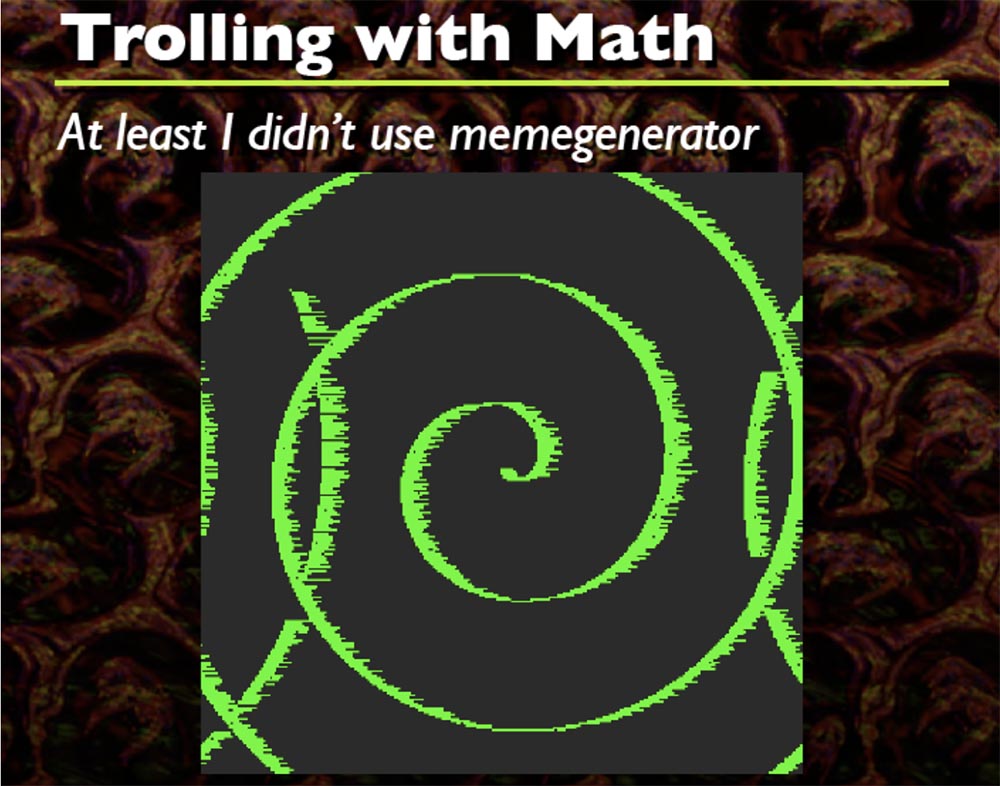
Seules deux formules fonctionnent ici, que j'ai incluses dans le code source. Sur cette base, vous pouvez faire autant de choses créatives que vous le souhaitez, essentiellement c'est juste DIFF du tampon de début au tampon de fin.
Le problème est que cet exemple de code utilise des sauts inconditionnels, ce qui est en fait mauvais, car le code doit être exactement le même qu'avant, c'est-à-dire que les sauts inconditionnels ne suivent qu'une seule direction. Par conséquent, vous devez aller du point d'entrée à la fin de la même manière, vous débarrasser des instructions de saut et vous avez terminé - vous avez votre code! Que faire? Il est nécessaire de transformer les sauts inconditionnels en sauts conditionnels. Les sauts conditionnels se font dans deux directions, c'est beaucoup mieux, on peut dire que c'est 50% mieux.
Ici, nous avons un dilemme intéressant: si nous avons besoin de sauts conditionnels, alors nous devons toujours utiliser des sauts inconditionnels ... Alors on fait quoi? Les prédicats opaques nous sauveront! Pour ceux qui ne le savent pas, un prédicat opaque est essentiellement une instruction booléenne qui est toujours exécutée pour une version particulière indépendamment de quoi que ce soit.
Examinons donc l'extension de l'espace zéro que j'ai mentionnée plus tôt. Si vous avez un ensemble d'instructions et qu'elles ont des sauts inconditionnels, des transitions entre chaque instruction, il s'ensuit qu'une série d'instructions d'assemblage qui n'affectent pas directement les instructions dont nous avons besoin peut précéder ou suivre une seule instruction.
Par exemple, si vous avez écrit des instructions très spécifiques qui ne modifient pas l'assembly principal de ce que vous essayez de confondre, c'est-à-dire que vous essayez de ne pas vous impliquer dans les registres tant que vous conservez l'état de chaque instruction d'assembly. Et c'est encore plus étonnant.
Vous pouvez considérer chaque instruction d'assemblage, qui peut être confondue, comme le préambule, les données d'assemblage et le post-scriptum. Le préambule est celui qui précède l'instruction d'assemblage, et le post-scriptum est celui qui la suit. Le préambule est généralement utilisé ou peut être utilisé pour deux choses:
- correction des conséquences du prédicat opaque du préambule précédent;
- fragments de code anti-débogage.
Mais le préambule est essentiellement limité car vous ne pouvez pas en faire trop.
Postscript est une chose plus drôle. Il peut être utilisé pour:
- prédicats opaques et sauts complexes vers les sections de code suivantes;
- anti-débogage et obscurcissement de l'exécution globale du code;
- chiffrement et déchiffrement de divers fragments de code dans le programme lui-même.
En ce moment, je travaille sur la possibilité de chiffrer et de déchiffrer chaque instruction individuelle de sorte que lorsque chaque instruction est exécutée, elle déchiffre la section suivante, la section suivante, la suivante, etc. La diapositive suivante en montre un exemple.

Les lignes du préambule et l'appel du débogueur sont surlignés en vert. Tout ce que cet appel fait est de vérifier si nous avons un débogueur, après quoi nous allons dans une section arbitraire du code.
Ci-dessous, nous avons un prédicat opaque très simple. Si vous maintenez la valeur Eax dans le post-script à l'instruction supérieure, puis suivez l'opérateur XOR, donc votre JZ pense: "OK, je peux évidemment aller à gauche ou à droite, je pense que c'est mieux j'irai à droite, car il y a 0". Ensuite, POP EAX est exécuté, votre EAX revient en arrière, après quoi l'instruction suivante est traitée, etc.
Cela, évidemment, crée des problèmes beaucoup plus importants que notre stratégie de base, tels que les effets résiduels et la complication de la génération de différents ensembles d'instructions. Par conséquent, il sera très difficile de déterminer comment une instruction affecte une autre instruction. Vous pouvez me lancer des pantoufles, car je n'ai pas encore terminé ce programme incroyable, mais vous pouvez suivre les progrès du développement sur mon blog.

Je note que nos formules f (x) ne doivent pas être calculées de manière itérative, par exemple f (1), f (2), ... f (n). Rien ne les empêche d'être calculés au hasard. Si vous êtes intelligent, vous pouvez déterminer le nombre d'instructions dont vous avez besoin, puis attribuer, par exemple, f (27), f (54), f (9), et ce sera l'endroit où votre instruction sera placée au hasard. Lorsque vous effectuez cette opération, selon la façon dont vous avez écrit votre code, vous pouvez l'arrêter à l'avance et le code liera toujours vos instructions de manière aléatoire.
Si votre code est généré sur la base d'une formule prévisible, il s'ensuit que le point d'entrée est également prévisible, vous pouvez donc prendre un niveau de plus avant de terminer la réception du code et confondre considérablement le point d'entrée à un degré ou un autre. Par exemple, prenez 300 instructions d'assemblage provenant d'un seul point d'entrée.
Parlons maintenant des lacunes.

Cette méthode nécessite une compilation minutieuse du code, principalement en utilisant GCC ou, Dieu nous en préserve, en utilisant C ++. C ++ est en fait un langage assez cool pour plusieurs raisons, mais vous savez que tous les compilateurs sont nuls. Donc, l'essentiel dans cette affaire est une compilation artisanale compétente, car si votre tentative de confondre votre propre assemblage entraînera l'approbation du gang qui a inventé le ver Conficker, alors vous avez foiré.
Vous aurez besoin d'une grande quantité de mémoire. Rappelez-vous l'image avec des ondes sinusoïdales. Le rouge est le code, et le bleu est la mémoire nécessaire pour qu'il fonctionne, et il devrait être suffisant pour que tout fonctionne comme il se doit.
Vous aurez probablement affaire à un gigantesque ensemble de données après avoir terminé le code. Et il augmentera considérablement si vous souhaitez confondre plusieurs fonctions.
Les pointeurs de fonction se comportent de manière imprévisible - parfois correctement, parfois non. Cela dépend de ce que vous faites et il y aura certainement un problème parce que vous ne pouvez pas prédire où et quand le pointeur de fonction se déclenche dans votre assembly.
Plus vous générez de l'obscurcissement et manipulez l'assemblage dans le préambule et le post-scriptum, plus il est difficile de corriger et de déboguer. Donc, écrire un tel code revient à trouver un équilibre entre «d'accord, je vais insérer soigneusement un ou deux JMP ici» et «comment diable puis-je tout comprendre en peu de temps»? Il vous suffit donc d'insérer des instructions, puis de comprendre pendant plusieurs mois ce que vous avez fait.
J'espère que vous avez appris quelque chose d'utile aujourd'hui. À mon avis, je me suis vraiment enivré et donc je ne comprends pas vraiment ce qui s'est passé maintenant. La diapositive suivante montre mes contacts Twitter, mon blog et mon site Web, alors visitez-moi ou écrivez.

C'est tout, merci d'être venu!
Merci de rester avec nous. Aimez-vous nos articles? Vous voulez voir des matériaux plus intéressants? Soutenez-nous en passant une commande ou en le recommandant à vos amis, une
réduction de 30% pour les utilisateurs Habr sur un analogue unique de serveurs d'entrée de gamme que nous avons inventés pour vous: Toute la vérité sur VPS (KVM) E5-2650 v4 (6 cœurs) 10 Go DDR4 240 Go SSD 1 Gbps à partir de 20 $ ou comment diviser le serveur? (les options sont disponibles avec RAID1 et RAID10, jusqu'à 24 cœurs et jusqu'à 40 Go de DDR4).
VPS (KVM) E5-2650 v4 (6 cœurs) 10 Go DDR4 240 Go SSD 1 Gbit / s jusqu'en janvier gratuitement en payant pour une période de six mois, vous pouvez commander
ici .
Dell R730xd 2 fois moins cher? Nous avons seulement
2 x Intel Dodeca-Core Xeon E5-2650v4 128 Go DDR4 6x480 Go SSD 1 Gbps 100 TV à partir de 249 $ aux Pays-Bas et aux États-Unis! Pour en savoir plus sur la
création d'un bâtiment d'infrastructure. classe utilisant des serveurs Dell R730xd E5-2650 v4 coûtant 9 000 euros pour un sou?