HTTP est une belle chose: un protocole qui existe depuis plus de 20 ans sans grand changement.
 Il s'agit de la deuxième partie de la série sur la sécurité Web: la première partie était le fonctionnement des navigateurs .
Il s'agit de la deuxième partie de la série sur la sécurité Web: la première partie était le fonctionnement des navigateurs .Comme nous l'avons vu dans l'article précédent, les navigateurs interagissent avec les applications Web en utilisant le protocole HTTP, et c'est la raison principale pour laquelle nous nous penchons sur ce sujet. Si les utilisateurs saisissent les informations de leur carte de crédit sur le site Web et qu'un attaquant peut intercepter les données avant d'atteindre le serveur, nous aurons probablement des problèmes.
Comprendre comment HTTP fonctionne, comment sécuriser les communications entre les clients et les serveurs, et quelles fonctionnalités liées à la sécurité le protocole offre est la première étape vers l'amélioration de notre sécurité.
Cependant, lorsque nous discutons de HTTP, nous devons toujours faire la distinction entre la sémantique et l'implémentation technique, car ce sont deux aspects complètement différents de HTTP.
La principale différence entre eux s'explique par une analogie très simple: il y a 20 ans, les gens prenaient soin de leurs proches de la même manière qu'aujourd'hui, même si la façon dont ils interagissaient a considérablement changé. Nos parents sont susceptibles de prendre leur voiture et de se rendre chez leur sœur pour rattraper leur retard et passer du temps avec leur famille.
Au lieu de cela, ces jours-ci, ils envoient le plus souvent des messages à WhatsApp, passent des appels téléphoniques ou utilisent un groupe sur Facebook, ce qui était auparavant impossible. Cela ne signifie pas que les gens communiquent ou se soucient plus ou moins, mais simplement que leur interaction a changé.
HTTP n'est pas différent: la sémantique du protocole n'a pas beaucoup changé, tandis que l'implémentation technique de l'interaction des clients et des serveurs a été optimisée au fil des ans. Si vous regardez la requête HTTP de 1996, elle sera très similaire à celles que nous avons vues dans l'article précédent, bien que la façon dont ces paquets traversent le réseau soit très différente.
Revue
Comme nous l'avons vu, HTTP suit un modèle de demande / réponse lorsqu'un client connecté à un serveur envoie une demande et que le serveur y répond.
Un message HTTP (demande ou réponse) se compose de plusieurs parties:
- "Première ligne" (première ligne)
- en-têtes (en-têtes de demande)
- corps (corps de la demande)
Dans la requête, la première ligne indique la méthode utilisée par le client, le chemin d'accès à la ressource qu'il souhaite, ainsi que la version du protocole qu'il va utiliser:
GET /players/lebron-james HTTP/1.1Dans ce cas, le client essaie d'obtenir la ressource (
GET ) dans
/Players/Lebron-James via la version
1.1 protocole - rien de compliqué à comprendre.
Après la première ligne, HTTP nous permet d'ajouter des métadonnées au message via des en-têtes qui prennent la forme d'une valeur-clé, séparés par deux points:
GET /players/lebron-james HTTP/1.1
Host: nba.com
Accept: */*
Coolness: 9000Par exemple, dans cette demande, le client a ajouté 3 en-têtes supplémentaires à la demande:
Host ,
Accept et
Coolness .
Attendez,
Coolness ?!?!
Les en-têtes ne doivent pas utiliser de noms spécifiques et réservés, mais il est généralement recommandé de s'appuyer sur ceux qui sont standardisés dans la spécification HTTP: plus vous vous écartez des normes, moins vous serez compris par un autre participant à l'échange.
Cache-Control est, par exemple, un en-tête utilisé pour déterminer si (et comment) une réponse peut être mise en cache: la plupart des mandataires et des mandataires inverses la comprennent en suivant la spécification HTTP à la lettre. Si vous deviez renommer l'en
Cache-Control tête
Cache-Control en
Awesome-Cache-Control , les mandataires n'auraient aucune idée de la façon de mettre en cache la réponse, car ils ne sont pas conçus pour répondre aux spécifications que vous venez d'inventer.
Cependant, il est parfois judicieux d'inclure un en-tête «personnalisé» dans le message, car vous pouvez ajouter des métadonnées qui ne font pas vraiment partie de la spécification HTTP: le serveur peut décider d'inclure des informations techniques dans sa réponse afin que le client puisse simultanément répondre aux demandes et recevoir des informations importantes état du serveur qui renvoie une réponse:
...
X-Cpu-Usage: 40%
X-Memory-Available: 1%
...Lorsque vous utilisez des en-têtes personnalisés, il est toujours préférable de mettre un préfixe avec une clé devant eux afin qu'ils n'entrent pas en conflit avec d'autres en-têtes qui pourraient devenir standard à l'avenir: historiquement, cela a bien fonctionné jusqu'à ce que tout le monde commence à utiliser les préfixes
X «non standard», qui à leur tour sont devenus la norme. Les en
X-Forwarded-For têtes
X-Forwarded-For et
X-Forwarded-Proto sont des exemples d'en-têtes personnalisés qui sont
largement utilisés et compris par les équilibreurs de charge et les proxys , même s'ils ne font
pas partie de la norme HTTP .
Si vous devez ajouter votre propre en-tête personnalisé, il est généralement préférable d'utiliser un préfixe propriétaire tel que
Acme-Custom-Header ou
A-Custom-Header .
Après les en-têtes, la demande peut contenir un corps séparé des en-têtes par une ligne vide:
POST /players/lebron-james/comments HTTP/1.1
Host: nba.com
Accept: */*
Coolness: 9000
Best Player Ever
Notre demande est terminée: première ligne (informations de localisation et de protocole), en-têtes et corps. Veuillez noter que le corps est complètement facultatif et, dans la plupart des cas, il est utilisé uniquement lorsque nous voulons envoyer des données au serveur, donc la méthode
POST est utilisée dans l'exemple ci-dessus.
La réponse n'est pas très différente:
HTTP/1.1 200 OK
Content-Type: application/json
Cache-Control: private, max-age=3600
{"name": "Lebron James", "birthplace": "Akron, Ohio", ...}Les premières informations envoyées dans la réponse sont la version du protocole qu'il utilise, ainsi que l'état de cette réponse. Voici les en-têtes et, si nécessaire, un saut de ligne suivi du corps.
Comme déjà mentionné, le protocole a subi de nombreuses révisions et au fil du temps de nouvelles fonctions ont été ajoutées (nouveaux en-têtes, codes d'état, etc.), mais la structure principale n'a pas beaucoup changé (première ligne, en-têtes et corps). Ce qui a vraiment changé, c'est la façon dont les clients et les serveurs échangent ces messages - examinons cela de plus près.
HTTP contre HTTPS contre H2
Il y a eu 2 changements sémantiques importants dans
HTTP / 1.0 :
HTTP / 1.0 et
HTTP / 1.1."Où sont HTTPS et
HTTP2 ?", Demandez-vous.
HTTPS et HTTP2 (abrégé en H2) sont des changements plus techniques car ils ont introduit de nouvelles façons de transmettre des messages sur Internet, sans affecter de manière significative la sémantique du protocole.
HTTPS est une extension
HTTP «sécurisée» et comprend l'établissement d'une clé secrète partagée entre le client et le serveur, garantissant que nous communiquons avec la bonne personne et chiffrons les messages qui échangent une clé secrète partagée (plus de détails plus loin). Alors que HTTPS visait à améliorer la sécurité du protocole HTTP, H2 visait à fournir une vitesse élevée.
H2 utilise des messages binaires plutôt que textuels, prend en charge le multiplexage, utilise l'algorithme HPACK pour compresser les en-têtes ... ... En bref, H2 améliore les performances par rapport à HTTP / 1.1.
Les propriétaires de sites Web hésitaient à passer au HTTPS, car cela comprenait des solutions de contournement supplémentaires entre le client et le serveur (comme déjà mentionné, il est nécessaire d'établir une clé secrète partagée entre les deux parties), ralentissant ainsi l'utilisateur: avec H2, qui est crypté par défaut, il n'y a plus d'excuses car des fonctionnalités telles que le multiplexage et la poussée du serveur le
rendent meilleur que le HTTP / 1.1 standard .
Https
HTTPS (HTTP Secure) permet aux clients et aux serveurs de communiquer en toute sécurité via TLS (Transport Layer Security), le successeur de SSL (Secure Socket Layer).
Le problème sur lequel se concentre TLS est assez simple et peut être illustré par une simple métaphore: votre âme sœur vous appelle au milieu de la journée lorsque vous êtes en réunion et vous demande de lui dire le mot de passe de votre compte bancaire en ligne, car il doit compléter les opérations bancaires transfert pour assurer le paiement en temps opportun des études de votre fils. Il est très important que vous le signaliez dès maintenant, sinon vous courrez le risque que votre enfant soit expulsé de l'école le lendemain matin.
Vous êtes maintenant confronté à deux problèmes:
- authentifier que vous parlez vraiment à votre âme soeur, car il pourrait s'agir de quelqu'un qui prétend être son
- cryptage : transmettre votre mot de passe pour que vos collègues ne puissent pas le comprendre et l'écrire
Que ferez-vous? C'est exactement le problème que HTTPS essaie de résoudre.
Pour vérifier à qui vous parlez, HTTPS utilise des certificats de clé publique (certificats de clé publique), qui ne sont rien de plus que des certificats qui indiquent l'identité d'un serveur particulier: lorsque vous vous connectez via HTTPS à une adresse IP, le serveur derrière cette adresse vous présente Son certificat est pour vous de prouver votre identité. Pour revenir à notre analogie, vous pouvez simplement demander à votre âme soeur de dire votre numéro de sécurité sociale. Dès que vous vérifiez que le numéro est correct, vous obtenez un niveau de confiance supplémentaire.
Cela n'empêche toutefois pas les «agresseurs» de découvrir le numéro de sécurité sociale de la victime, de voler le smartphone de votre âme sœur et de vous appeler. Comment vérifions-nous l'identité de l'appelant?
Au lieu de demander directement à votre âme sœur d'écrire votre numéro de sécurité sociale, vous appelez plutôt votre mère (qui habite à côté) et lui demandez d'aller à votre appartement et de vous assurer que votre autre moitié indique le numéro de sécurité sociale. Cela ajoute un niveau de confiance supplémentaire, car vous ne considérez pas votre mère comme une menace et comptez sur elle pour vérifier l'identité de l'appelant.
En termes de HTTPS, votre maman s'appelle CA, abréviation de Certificate Authority: le travail d'une CA est de vérifier l'identité d'un serveur particulier et d'émettre un certificat avec sa propre signature numérique: cela signifie que lorsque je me connecte à un domaine spécifique, je ne recevrai pas de certificat généré par le propriétaire du domaine (soi-disant
auto -
signé certificat ) et CA.
La tâche de l'autorité de certification est de vérifier l'authenticité du domaine et d'émettre le certificat en conséquence: lorsque vous "commandez" un certificat (généralement appelé certificat SSL, bien que TLS soit actuellement utilisé à la place - les noms collent vraiment!), L'autorité de certification peut vous appeler ou Demandez à modifier le paramètre DNS pour vous assurer que vous contrôlez ce domaine. Une fois le processus de vérification terminé, il émet un certificat, qui peut ensuite être installé sur les serveurs Web.
Ensuite, les clients, tels que les navigateurs, se connecteront à vos serveurs et recevront ce certificat afin qu'ils puissent vérifier son authenticité: les navigateurs ont une sorte de «relation» avec l'autorité de certification, dans le sens où ils gardent une trace de la liste des domaines approuvés dans l'autorité de certification pour s'assurer Le certificat est vraiment digne de confiance. Si le certificat n'est pas signé par une autorité de confiance, le navigateur affichera un grand avertissement d'information pour les utilisateurs:
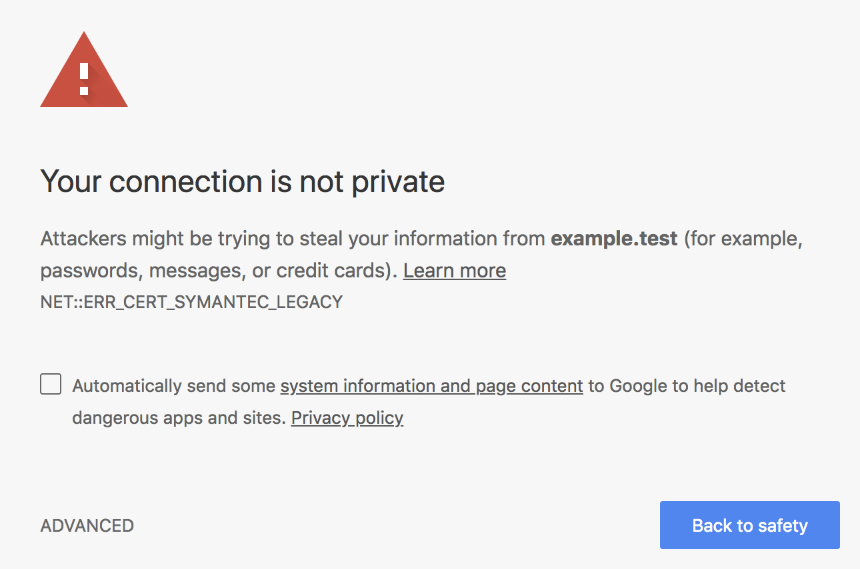
Nous sommes à mi-chemin pour assurer la communication entre vous et votre autre moitié: maintenant que nous avons réussi l'authentification (vérification de l'identité de l'appelant), nous devons nous assurer que nous pouvons communiquer en toute sécurité sans l'intervention d'autres personnes dans le processus. Comme je l'ai mentionné, vous êtes en plein milieu de la réunion et vous devez noter votre mot de passe pour les opérations bancaires en ligne. Vous devez trouver un moyen de crypter votre communication afin que seuls vous et votre âme sœur puissiez comprendre votre conversation.
Vous pouvez le faire en définissant une clé secrète commune entre vous deux et crypter les messages avec cette clé: par exemple, vous pouvez utiliser
l' option de
chiffrement César en fonction de la date de votre mariage.

Cela fonctionnera bien si les deux parties ont établi des relations, comme vous et votre âme sœur, car elles peuvent créer une clé basée sur la mémoire partagée que personne ne connaît. Les navigateurs et les serveurs ne peuvent cependant pas utiliser le même mécanisme, car ils ne se connaissent pas à l'avance.
Au lieu de cela, des variantes du
protocole d'échange de clés Diffie-Hellman sont utilisées, ce qui garantit que les parties sans connaissance préalable établissent une clé secrète partagée et que personne d'autre ne peut la «voler». Cela comprend l'
utilisation des mathématiques .
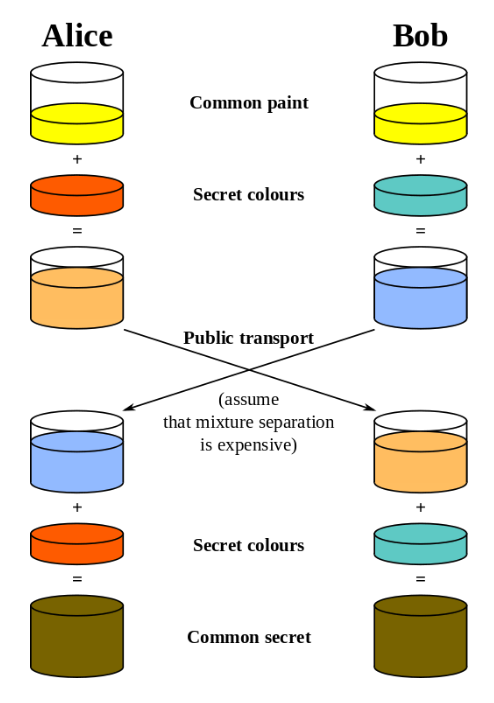
Une fois la clé secrète installée, le client et le serveur peuvent communiquer sans craindre que quelqu'un intercepte leurs messages. Même si les attaquants le font, ils n'auront pas de clé secrète partagée nécessaire pour déchiffrer les messages.
Pour plus d'informations sur HTTPS et Diffie-Hellman, je recommanderais de lire "
Comment HTTPS protège les connexions " par Hartley Brody et "
Comment fonctionne vraiment HTTPS?" »Robert Heaton. En outre,
Nine Algorithms That Changed the Future a un chapitre incroyable expliquant le cryptage des clés publiques, et je le recommande vivement aux passionnés d'informatique intéressés par les algorithmes originaux.
Https partout
Vous décidez toujours si vous devez prendre en charge HTTPS sur votre site? J'ai une mauvaise nouvelle pour vous: les navigateurs ont commencé à protéger les utilisateurs des sites Web qui ne prennent pas en charge HTTPS afin de «forcer» les développeurs Web à fournir des capacités de navigation entièrement cryptées.
Suivant la devise «
HTTPS partout », les navigateurs ont commencé à s'opposer aux connexions non chiffrées - Google a été le premier fournisseur de navigateur à donner une date limite aux développeurs Web en annonçant qu'à partir de Chrome 68 (juillet 2018), il marquerait les sites Web HTTP comme «non sécurisés» :
Encore plus troublant pour les sites Web qui ne profitent pas du HTTPS est le fait que dès qu'un utilisateur tape quelque chose sur une page Web, le libellé «Insecure» devient rouge - cette étape devrait encourager les utilisateurs à réfléchir à deux fois avant d'échanger des données. avec des sites Web qui ne prennent pas en charge HTTPS.
Comparez cela à ce à quoi ressemble un site HTTPS avec un certificat valide:
Théoriquement, un site Web ne doit pas être sécurisé, mais dans la pratique, il effraie les utilisateurs - et à juste titre. À l'époque où H2 n'était pas une réalité, il serait logique de s'en tenir au trafic HTTP simple et non chiffré. Il n'y a pratiquement aucune raison à cela pour le moment. Rejoignez le mouvement HTTPS Everywhere et contribuez à faire d'Internet
un endroit plus sûr pour surfer .
GET vs POST
Comme nous l'avons vu précédemment, une requête HTTP commence par une sorte de «première ligne»:
Tout d'abord, le client indique au serveur les méthodes qu'il utilise pour exécuter la demande: les méthodes HTTP de base incluent
GET, POST, PUT DELETE, mais la liste peut être poursuivie avec des méthodes moins courantes (mais toujours standard) telles que
TRACE, OPTIONS ou
HEADThéoriquement, aucune méthode n'est plus sûre que les autres; en pratique, tout n'est pas si simple.
Les demandes GET ne contiennent généralement pas de corps, donc les paramètres sont inclus dans l'URL (par exemple,
www.example.com/articles?article_id=1 ), tandis que les demandes POST sont généralement utilisées pour envoyer ("publier") des données qui sont incluses dans le corps. Une autre différence est les effets secondaires de ces méthodes:
GET est une méthode idempotente, ce qui signifie que peu importe le nombre de demandes que vous envoyez, vous ne modifiez pas l'état du serveur Web. Au lieu de cela,
POST pas idempotent: pour chaque demande que vous envoyez, vous pouvez changer l'état du serveur (pensez, par exemple, à effectuer un nouveau paiement - maintenant vous comprenez probablement pourquoi les sites vous demandent de ne pas actualiser la page lors de la réalisation d'une transaction).
Pour illustrer la différence importante entre ces méthodes, nous devons jeter un œil aux journaux du serveur Web que vous connaissez peut-être déjà:
192.168.99.1 - [192.168.99.1] - - [29/Jul/2018:00:39:47 +0000] "GET /?token=1234 HTTP/1.1" 200 525 "-" "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36" 404 0.002 [example-local] 172.17.0.8:9090 525 0.002 200
192.168.99.1 - [192.168.99.1] - - [29/Jul/2018:00:40:47 +0000] "GET / HTTP/1.1" 200 525 "-" "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36" 393 0.004 [example-local] 172.17.0.8:9090 525 0.004 200
192.168.99.1 - [192.168.99.1] - - [29/Jul/2018:00:41:34 +0000] "PUT /users HTTP/1.1" 201 23 "http://example.local/" "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36" 4878 0.016 [example-local] 172.17.0.8:9090 23 0.016 201Comme vous pouvez le voir, les serveurs Web enregistrent le chemin de la demande: cela signifie que si vous incluez des données sensibles dans votre URL, elles seront ignorées par le serveur Web et stockées quelque part dans vos journaux - vos données sensibles seront quelque part dans texte brut, que nous devons éviter complètement.
Imaginez qu'un attaquant puisse accéder à l'un de vos anciens fichiers journaux , qui peuvent contenir des informations de carte de crédit, des jetons d'accès pour vos services privés, etc., ce sera un désastre complet.
Les serveurs Web n'enregistrent pas les en-têtes et les corps HTTP, car les données stockées seront trop volumineuses - c'est pourquoi l'envoi d'informations via le corps de la demande plutôt que l'URL est généralement plus sûr. De là, nous pouvons en déduire que
POST (et les méthodes similaires non idempotentes) sont plus sûres que
GET , même si cela dépend davantage de la façon dont les données sont envoyées à l'aide d'une certaine méthode, et non du fait qu'une méthode particulière est essentiellement plus sûre que d'autres: si vous incluiez des informations confidentielles dans le corps de la demande
GET , vous n'auriez pas plus de problèmes que d'utiliser
POST , même si une telle approche était considérée comme inhabituelle.
Nous croyons aux en-têtes HTTP
Dans cet article, nous avons examiné HTTP, son évolution et la façon dont son extension sécurisée combine authentification et cryptage pour permettre aux clients et serveurs de communiquer via un canal sécurisé: ce n'est pas tout ce que HTTP a à offrir en termes de sécurité.
La traduction a été prise en charge par EDISON Software , une société de sécurité professionnelle, et développe également des systèmes de vérification médicale électronique .