Récemment, le développement Web a été divisé. Maintenant, nous ne sommes pas tous des programmeurs full-stack - nous sommes front-end et back-end. Et la chose la plus difficile à ce sujet, comme ailleurs, est le problème de l'interaction et de l'intégration.
Le frontend avec le backend interagit via l'API. Et le résultat du développement dans son ensemble dépend de quelle API il s'agit, de la qualité ou de la mauvaise entente entre le backend et le frontend. Si nous commençons tous à discuter ensemble de la façon de procéder à la mise à niveau et à passer toute la journée à la retravailler, nous ne pourrons peut-être pas passer aux tâches commerciales.
Afin de ne pas déraper et reproduire des holivars sur les noms des variables, vous avez besoin d'une bonne spécification. Parlons de ce que cela devrait être de rendre la vie plus facile pour tout le monde. Dans le même temps, nous deviendrons des experts dans les abris à vélos.

Commençons de loin - avec le problème que nous résolvons.
Il était une fois, en 1959,
Cyril Parkinson (à ne pas confondre avec la maladie, il est écrivain et figure économique) a proposé plusieurs lois intéressantes. Par exemple, ces dépenses augmentent avec le revenu, etc. L'un d'eux est appelé la loi de la trivialité:
Le temps passé à discuter de l'élément est inversement proportionnel au montant considéré.
Parkinson était un économiste, alors il a expliqué ses lois en termes économiques, quelque chose comme ça. Si vous venez au conseil d'administration et dites que vous avez besoin de 10 millions de dollars pour construire une centrale nucléaire, cette question sera probablement beaucoup moins discutée que l'allocation de 100 livres pour un abri à vélos pour les employés. Parce que tout le monde sait comment construire un abri à vélos, tout le monde a sa propre opinion, tout le monde se sent important et veut participer, et la centrale nucléaire est quelque chose d'abstrait et de lointain, 10 millions n'ont également jamais été vus - il y a moins de questions.
En 1999, la loi de la trivialité de Parkinson est apparue dans la programmation, qui a ensuite été activement développée. En programmation, cette loi se retrouve principalement dans la littérature anglophone et sonne comme une métaphore. Cela s'appelait l'
effet Bikeshed (l'effet d'un abri à vélos), mais l'essence est la même - nous sommes prêts pour un abri à vélos et voulons discuter beaucoup plus longtemps que la construction d'une centrale électrique.
Ce terme a été inventé par le développeur danois Poul-Henning Kamp, qui a été impliqué dans la création de FreeBSD. Au cours du processus de conception, l'équipe a passé très longtemps à discuter du fonctionnement de la fonction sommeil. Voici une citation tirée d'une
lettre de Poul-Henning Kamp (le développement a ensuite été effectué par courrier électronique):
C'était une proposition de faire dormir (1) DTRT Si on me donnait un argument non entier qui éteignait ce feu de camp particulier, je ne vais pas en dire plus à ce sujet que cela, car c'est un élément beaucoup plus petit qu'on ne le ferait attendez-vous de la longueur du fil, et il a déjà reçu beaucoup plus d'attention que certains des * problèmes * que nous avons ici.
Dans cette lettre, il dit qu'il y a beaucoup de problèmes non résolus beaucoup plus importants: "Ne nous occupons pas du garage à vélos, nous allons faire quelque chose et aller de l'avant!"
Poul-Henning Kamp a donc introduit en 1999 le terme effet bikeshed dans la littérature anglophone, qui peut être reformulé comme suit:
La quantité de bruit créée par le changement de code est inversement proportionnelle à la complexité du changement.
Plus l'ajout ou le changement est simple, plus nous avons besoin d'avis à ce sujet. Je pense que beaucoup l'ont rencontré. Si nous résolvons une question simple, par exemple, comment nommer les variables, cela n'a pas d'importance pour une machine - cette question provoquera un grand nombre d'holivars. Mais les problèmes graves, vraiment importants pour les entreprises ne sont pas discutés et passent en arrière-plan.
Selon vous, qu'est-ce qui est le plus important: comment communiquons-nous entre le backend et le frontend, ou les tâches métier que nous faisons? Tout le monde pense différemment, mais tout client, une personne qui s'attend à ce que vous lui apportiez de l'argent, dira: "Fais-moi déjà nos tâches commerciales!" Il ne se soucie absolument pas de la façon dont vous transférez les données entre le backend et le frontend. Peut-être qu'il ne sait même pas ce qu'est un backend et un frontend.
Pour résumer l'introduction, je voudrais dire: l'
API est un abri à vélos.Lien de présentationÀ propos de l'orateur: Alexey Avdeev (
Avdeev ) travaille dans la société Neuron.Digital, qui s'occupe des neurones et en fait une interface cool pour eux. Alex fait également attention à OpenSource et conseille tout le monde. Il est engagé dans le développement depuis longtemps - depuis 2002, il a découvert l'ancien Internet, quand les ordinateurs étaient grands, Internet était petit, et le manque de JS ne dérangeait personne et tout le monde faisait des sites Web sur les tables.
Comment gérer les hangars à vélos?
Après que le respecté Cyril Parkinson ait déduit la loi de la trivialité, il a été beaucoup discuté. Il s'avère que l'effet d'un abri à vélo ici peut être facilement évité:
- N'écoutez pas les conseils. Je pense que l'idée est moyenne - si vous n'écoutez pas les conseils, vous pouvez faire une telle chose, surtout en programmation, et surtout si vous êtes un développeur novice.
- Faites comme vous voulez. "Je suis artiste, je le vois!" - pas d'effet bikeshed, tout ce dont vous avez besoin est fait, mais des choses très étranges apparaissent sur la sortie. Cela se trouve souvent chez les pigistes. Vous avez sûrement rencontré des tâches que vous deviez accomplir pour d'autres développeurs et dont la mise en œuvre vous a dérouté.
- Est-il important de se demander? Sinon, vous ne pouvez tout simplement pas en discuter, mais c'est une question de conscience personnelle.
- Utilisez des critères objectifs. Je parlerai de ce point dans le rapport. Pour éviter l'effet d'un abri à vélo, vous pouvez utiliser des critères qui disent objectivement ce qui est le mieux. Ils existent.
- Ne parlez pas de ce que vous ne voulez pas écouter des conseils. Dans notre entreprise, les développeurs backend débutants sont des introvertis, il arrive donc qu'ils fassent quelque chose dont ils ne parlent pas aux autres. En conséquence, nous rencontrons des surprises. Cette méthode fonctionne, mais en programmation ce n'est pas la meilleure option.
- Si vous ne vous souciez pas du problème, vous pouvez simplement le laisser partir ou choisir l'une des options proposées qui ont surgi dans le processus de holivarov.
Outil anti-bikeshedding
Je veux parler d'
outils objectifs pour résoudre le problème d'un abri à vélos. Pour vous montrer ce qu'est un outil anti-bikeshedding, je vais vous raconter une petite histoire.
Imaginez que nous ayons un développeur backend novice. Il est récemment venu dans l'entreprise et a été chargé de concevoir un petit service, par exemple un blog, pour lequel vous devez écrire un protocole REST.
 Roy Fielding, auteur de REST
Roy Fielding, auteur de RESTSur la photo, Roy Fielding, qui a soutenu en 2000 sa thèse "Styles architecturaux et conception d'architectures logicielles réseau" et a ainsi introduit le terme REST. De plus, il a inventé HTTP et, en fait, est l'un des fondateurs d'Internet.
REST est un ensemble de principes architecturaux qui expliquent comment concevoir des protocoles REST, des API REST, des services RESTful. Ce sont des principes architecturaux assez abstraits et complexes. Je suis sûr qu'aucun de vous n'a jamais vu une API entièrement conforme à tous les principes RESTful.
Exigences de l'architecture REST
Je vais donner quelques exigences pour les protocoles
REST , auxquels je ferai ensuite référence et sur lesquels je m'appuierai. Il y en a beaucoup, vous pouvez en lire plus sur Wikipédia.
1.
Le modèle client-serveur.Le principe le plus important de REST, c'est notre interaction avec le backend. Selon REST, le backend est un serveur, le frontal est un client, et nous communiquons dans un format client-serveur. Les appareils mobiles sont également un client. Les développeurs de montres, de réfrigérateurs, d'autres services - développent également la partie client. L'API RESTful est le serveur auquel le client accède.
2.
Manque de condition.Il ne doit pas y avoir d'état sur le serveur, c'est-à-dire que tout ce qui est nécessaire pour une réponse vient dans la demande. Lorsqu'une session est stockée sur le serveur, et selon cette session différentes réponses arrivent, c'est une violation du principe REST.
3.
Uniformité de l'interface.C'est l'un des principes sous-jacents clés sur lesquels l'API REST doit être construite. Il comprend les éléments suivants:
- L'identification des ressources est la façon dont nous devons créer une URL. Sur REST, nous nous tournons vers le serveur pour une sorte de ressource.
- Manipulation des ressources par présentation. Le serveur nous renvoie une vue différente de celle qui se trouve dans la base de données. Peu importe que vous stockiez les informations dans MySQL ou PostgreSQL - nous avons une vue.
- Messages "auto-descriptifs" - c'est-à-dire que le message contient un identifiant, des liens d'où vous pouvez récupérer ce message - tout ce qui est nécessaire pour travailler à nouveau avec cette ressource.
- Hypermedia est un lien vers les actions suivantes avec une ressource. Il me semble que pas une seule API REST ne le fait, mais elle est décrite par Roy Fielding.
Il y a 3 autres principes que je ne cite pas car ils ne sont pas importants pour mon histoire.
Blog RESTful
Retour au développeur backend débutant, à qui on a demandé de rendre un service pour le blog sur RESTful. Voici un exemple de prototype.
Il s'agit d'un site sur lequel il y a des articles, vous pouvez les commenter, l'article et les commentaires ont un auteur - une histoire standard. Notre développeur débutant backend fera une API RESTful pour ce blog.
Nous travaillons avec toutes les données du blog sur la base de
CRUD .
Il devrait être possible de créer, lire, mettre à jour et supprimer n'importe quelle ressource. Essayons de demander à notre développeur principal de créer un AP RESTful basé sur le principe de CRUD. Autrement dit, écrivez des méthodes pour créer des articles, obtenir une liste d'articles ou un seul article, mettre à jour et supprimer.
Voyons comment il pourrait le faire.
 Tout va mal avec tous les principes de REST
Tout va mal avec tous les principes de REST . La chose la plus intéressante est que cela fonctionne. J'ai en fait des API qui ressemblaient à quelque chose comme ça. Pour le client, c'est un abri à vélos, pour les développeurs, c'est l'occasion de se détendre et de discuter, et pour un développeur novice, c'est juste un nouveau monde énorme et courageux sur lequel il trébuche à chaque fois, tombe, se fracasse la tête. Il doit le refaire encore et encore.

Il s'agit d'une option REST. Sur la base des principes d'identification des ressources, nous travaillons avec des ressources - avec des articles et utilisons les méthodes HTTP proposées par Roy Fielding. Il ne pouvait s'empêcher d'utiliser son travail précédent dans son prochain travail.
Pour mettre à jour les articles, beaucoup utilisent la méthode PUT; sa sémantique est légèrement différente. La méthode PATCH met à jour les champs qui ont été transmis et le PUT remplace simplement un article par un autre. Par sémantique, PATCH est une fusion et PUT est un remplacement.
Notre développeur novice backend est tombé, ils l'ont ramassé et ont dit: "Tout est en ordre, faites-le comme ça", et il l'a refait honnêtement. Mais il trouvera alors un long chemin à travers les épines.
Pourquoi est-ce si juste?- parce que Roy Fielding l'a dit;
- parce que c'est REST;
- car ce sont les principes architecturaux sur lesquels se fonde actuellement notre profession.
Cependant, il s'agit d'un "abri à vélos", et la méthode précédente fonctionnera. Les ordinateurs communiquaient avant REST, et tout fonctionnait. Mais maintenant, une norme est apparue dans l'industrie.
Supprimer l'article
Prenons l'exemple de la suppression d'un article. Supposons qu'il existe une méthode de ressource normale DELETE / articles, qui supprime l'article par id. HTTP contient des en-têtes. L'en-tête Accept accepte le type de données que le client souhaite recevoir en réponse. Notre junior a écrit un serveur qui retourne 200 OK, Content-Type: application / json, et passe un corps vide:
01. DELETE /articles/ 1 /1.1
02. Accept: application/json01. HTTP/1.1 200 OK
02. Content-Type: application/json
03. null
Une
erreur très
courante a été commise ici - un corps vide . Tout semble logique - l'article a été supprimé, 200 OK, l'en-tête application / json est présent, mais le client va très probablement tomber. Il générera une erreur car un corps vide n'est pas valide. Si vous avez déjà essayé d'analyser une chaîne vide, vous êtes confronté au fait que tout analyseur json trébuche et se bloque à ce sujet.
Comment résoudre cette situation? La meilleure option est probablement de passer json. Si nous avons déclaré: «Acceptez, donnez-nous json», le serveur dit: «Content-Type, je vous donne json», donnez json. Un objet vide, un tableau vide - mettez quelque chose là-bas - ce sera la solution, et cela fonctionnera.
Il y a encore une solution. En plus de 200 OK, il existe un code de réponse 204 - pas de contenu. Avec lui, vous ne pouvez pas transmettre le corps. Tout le monde ne le sait pas.
J'ai donc conduit aux types de médias.
Types de mime
Les types de médias sont comme une extension de fichier, uniquement sur le Web. Lorsque nous transmettons des données, nous devons informer ou demander quel type nous voulons recevoir en réponse.
- Par défaut, c'est text / plain - just text.
- Si rien n'est spécifié, le navigateur signifiera probablement un flux d'application / octet - juste un flux de bits.
Vous pouvez spécifier juste un type spécifique:
- application / pdf;
- image / png;
- application / json;
- application / xml;
- application / vnd.ms-excel.
Les en-têtes Content-Type et Accept sont et sont importants.
L'API et le client doivent transmettre les en-têtes Content-Type et Accept.
Si votre API est basée sur JSON, passez toujours Accept: application / json et Content-Type application / json.
Exemples de types de fichiers.

Les types de supports sont similaires à ces types de fichiers, uniquement sur Internet.
Codes de réponse
Le prochain exemple des aventures de notre développeur junior est les codes de réponse.

Le taux de réponse le plus drôle est de 200 OK. Tout le monde l'aime - cela signifie que tout s'est bien passé. J'ai même eu un cas - j'ai reçu des
erreurs 200 OK . Quelque chose est effectivement tombé sur le serveur, en réponse à la réponse vient une page HTML sur laquelle une erreur HTML a été compilée. J'ai demandé une application json avec le code 200 OK, et j'ai pensé comment travailler avec elle? Vous allez par réponse, cherchez le mot "erreur", vous pensez que c'est une erreur.
Cela fonctionne, cependant, dans HTTP, il existe de nombreux autres codes que vous pouvez utiliser, et REST vous recommande de les utiliser sur REST. Par exemple, la création d'une entité (article) peut être répondue:
- 201 Créé est un code réussi. L'article est créé, en réponse, vous devez renvoyer l'article créé.
- 202 Accepté signifie que la demande a été acceptée, mais son résultat sera plus tard. Ce sont des opérations de longue durée. Sur Accepté, aucun corps ne peut être retourné. Autrement dit, si vous ne donnez pas le Content-Type dans la réponse, le corps peut également ne pas l'être. Ou texte / plan de type contenu - c'est tout, pas de questions. Une chaîne vide est un texte / plan valide.
- 204 Pas de contenu - le corps peut être complètement absent.
- 403 Interdit - Vous n'êtes pas autorisé à créer cet article.
- 404 Introuvable - vous avez grimpé quelque part de travers, il n'y a pas de tel moyen, par exemple.
- 409 Le conflit est un cas extrême que peu de gens utilisent. Il est parfois nécessaire si vous générez un identifiant sur le client, et non sur le backend, et à ce moment-là, quelqu'un a déjà réussi à créer cet article. Le conflit est la bonne réponse dans ce cas.
Création d'entité
L'exemple suivant: nous créons une entité, disons Content-Type: application / json, et passons cette application / json. Cela fait du client - notre interface. Créons cet article:
01. POST /articles /1.1
02. Content-Type: application/json
03. { "id": 1, "title": " JSON API"}Le code peut venir en réponse:
- 422 Entité non traitable - Une entité non traitée. Tout semble être super - la sémantique, il y a du code;
- 403 Interdit
- 500 Erreur de serveur interne.
Mais il est absolument incompréhensible de savoir ce qui s'est exactement passé: quel type d'entité n'est pas traité, pourquoi ne devrais-je pas y aller et qu'est-il finalement arrivé au serveur?
Erreurs de retour
Soyez sûr (et les juniors ne le savent pas) en réponse, renvoyez des erreurs. C'est sémantique et correct. Soit dit en passant, Fielding n'a pas écrit à ce sujet, c'est-à-dire qu'il a été inventé plus tard et construit au-dessus de REST.
Le backend peut retourner un tableau avec des erreurs en réponse, il peut y en avoir plusieurs.
01. HTTP/1.1 422 Unprocessable Entity
02. Content-Type: application/json
03.
04. { "errors": [{
05. "status": "422",
06. "title": "Title already exist",
07. }]}Chaque erreur peut avoir son propre statut et titre. C'est très bien, mais cela va déjà au niveau de la convention sur REST. Cela pourrait être notre outil anti-bikeshedding pour arrêter de discuter et créer immédiatement une bonne API.
Ajouter une pagination
L'exemple suivant: les concepteurs viennent voir notre développeur backend débutant et disent: «Nous avons beaucoup d'articles, nous avons besoin de pagination. Nous avons dessiné celui-ci. "

Examinons-le plus en détail. Tout d'abord, 336 pages sont frappantes. Quand j'ai vu ça, j'ai pensé à comment obtenir ce chiffre. Où obtenir 336, car lorsque je demande une liste d'articles, j'obtiens une liste d'articles. Par exemple, il y en a 10 000, c'est-à-dire que je dois télécharger tous les articles, les diviser par le nombre de pages et trouver ce nombre. Pendant très longtemps, je chargerai ces articles, j'ai besoin d'un moyen d'obtenir rapidement le nombre d'entrées. Mais si notre API renvoie une liste, alors où mettre ce nombre d'enregistrements en général, car un tableau d'articles vient en réponse. Il s'avère que puisque le nombre d'enregistrements n'est placé nulle part, il doit être ajouté à chaque article pour que chaque article dise: "Et nous sommes tous si nombreux!"
Cependant, il existe une convention au-dessus de l'API REST qui résout ce problème.
Demande de liste
Pour rendre l'API extensible, vous pouvez immédiatement utiliser les paramètres GET pour la pagination: la taille de la page en cours et son numéro, de sorte que exactement la partie de la page que nous avons demandée nous soit retournée. C'est pratique. En réponse, vous ne pouvez pas donner immédiatement un tableau, mais ajouter une imbrication supplémentaire. Par exemple, la clé de données contiendra un tableau, les données que nous avons demandées et la méta-clé, qui n'existait pas auparavant, contiendra le total.
01. GET /articles? page[size]=30&page[number]=2
02. Content-Type: application/json
01. HTTP/1.1 200 OK
02. {
03. "data": [{ "id": 1, "title": "JSONAPI"}, ...],
04. "meta": { "count": 10080 }
05. }
De cette façon, l'API peut renvoyer des informations supplémentaires. En plus de compter, il peut y avoir d'autres informations - elles sont extensibles. Maintenant, si le junior ne l'a pas fait tout de suite, et seulement après qu'on lui ait demandé de faire la pyjinisation, alors il a
fait le changement en arrière incompatible , a cassé l'API, et tous les clients ont dû le refaire - généralement ça fait très mal.
La pajinisation est différente. Je propose plusieurs astuces de vie que vous pouvez utiliser.
[décalage] ... [limite]
01. GET /articles? page[offset]=30&page[limit]=30
02. Content-Type: application/json
01. HTTP/1.1 200 OK
02. {
03. "data": [{ "id": 1, "title": "JSONAPI"}, ...],
04. "meta": { "count": 10080 }
05. }
Ceux qui travaillent avec des bases de données peuvent déjà avoir un sous-cortex [offset] ... [limit]. L'utiliser à la place de la page [taille] ... la page [numéro] sera plus facile. Il s'agit d'une approche légèrement différente.
Positionnement du curseur
01. GET /articles? page[published_at]=1538332156
02. Content-Type: application/json01. HTTP/1.1 200 OK
02. {
03. "data": [{ "id": 1, "title": "JSONAPI"}, ...],
04. "meta": { "count": 10080 }
05. }L'emplacement du curseur utilise un pointeur sur l'entité avec laquelle commencer le chargement des enregistrements. Par exemple, cela est très pratique lorsque vous utilisez la pagination ou le chargement dans des listes qui changent fréquemment. Disons que de nouveaux articles sont constamment écrits sur notre blog. La troisième page n'est plus la même troisième page qui sera dans une minute, mais si nous allons à la quatrième page, nous obtiendrons des enregistrements de la troisième page, car toute la liste se déplacera.
Ce problème est résolu par la pagination du curseur. Nous disons: "Chargez les articles qui viennent après l'article publié à ce moment-là" - il ne peut déjà y avoir aucun changement de manière purement technologique, et c'est cool.
Problème N +1
Le prochain problème que notre développeur junior rencontrera certainement est le problème N + 1 (les backenders comprendront). Supposons que vous souhaitiez répertorier une liste de 10 articles. Nous téléchargeons une liste d'articles, chaque article a un auteur et pour chacun, vous devez télécharger un auteur. Nous expédions:
- 1 demande de liste d'articles;
- 10 demandes pour les auteurs de chaque article.
Total: 11 requêtes pour afficher une petite liste.
Ajouter des liens
Sur le backend, ce problème est résolu dans tous les ORM - il vous suffit de vous rappeler d'ajouter cette connexion. Ces connexions peuvent également être utilisées sur l'extrémité avant. Cela se fait comme suit:
01. GET /articles? include =author
02. Content-Type: application/json
Vous pouvez utiliser un paramètre GET spécial, appelez-le include (comme sur le backend), en disant quels liens nous devons charger avec les articles. Supposons que nous téléchargions des articles et que nous voulions immédiatement mettre l'auteur en rapport avec les articles. La réponse ressemble à ceci:
01. /1.1 200
02. { "data": [{
03. { attributes: { "id": 1, "title": "JSON API" },
04. { relationships: {
05. "author": { "id": 1, "name": "Avdeev" } }
06. }, ...
07. }]}Les propres attributs d'article ont été transférés aux données et les relations clés ont été ajoutées. Nous mettons toutes les connexions dans cette clé. Ainsi, avec une seule demande, nous avons reçu toutes les données qui avaient précédemment reçu 11 demandes. C'est un hack de vie cool qui résout bien le problème avec N + 1 sur l'extrémité avant.
Le problème de la duplication des données
Supposons que vous souhaitiez afficher 10 articles indiquant l'auteur, tous les articles ont un auteur, mais l'objet avec l'auteur est très grand (par exemple, un nom de famille très long, qui prend un mégaoctet). Un auteur est inclus 10 fois dans la réponse, et 10 inclusions du même auteur dans la réponse prendront 10 Mo.
Étant donné que tous les objets sont identiques, le problème qu'un auteur est inclus 10 fois (10 Mo) est résolu à l'aide de la normalisation, qui est utilisée dans les bases de données. À l'avant, vous pouvez également utiliser la normalisation pour travailler avec l'API - c'est très cool.
01. /1.1 200
02. { "data": [{
03. "id": "1″, "type": "article",
04. "attributes": { "title": "JSON API" },
05. "relationships": { ... }
06. "author": { "id": 1, "type": "people" } }
07. }, ... ]
08. }Nous marquons toutes les entités avec un certain type (c'est un type de représentation, un type de ressource). Roy Fielding a introduit le concept d'une ressource, c'est-à-dire qu'ils ont demandé des articles - ont reçu un «article». Dans les relations, nous mettons un lien vers le type de personnes, c'est-à-dire que nous avons toujours les ressources humaines ailleurs. Et la ressource elle-même que nous prenons dans une clé distincte incluse, qui se trouve au même niveau que les données.
01. /1.1 200
02. {
03. "data": [ ... ],
04. "included": [{
05. "id": 1, "type": "people",
06. "attributes": { "name": "Avdeev" }
07. }]
08. }Ainsi, toutes les entités liées dans une seule instance tombent dans la clé spéciale incluse. Nous ne stockons que des liens, et les entités elles-mêmes sont stockées dans inclus.
La taille de la demande a diminué. Il s'agit d'un hack de vie dont le back-end de début ne sait pas. Il saura plus tard quand il aura besoin de casser l'API.
Tous les champs de ressources ne sont pas nécessaires
Le hack de vie suivant peut être appliqué lorsque tous les champs de ressources ne sont pas nécessaires. Cela se fait à l'aide d'un paramètre GET spécial, qui répertorie les attributs à renvoyer, séparés par des virgules. Par exemple, l'article est volumineux, et il peut y avoir des mégaoctets dans le champ de contenu, et nous devons afficher uniquement la liste des en-têtes - nous n'avons pas besoin du contenu dans la réponse.
GET /articles ?fields[article]=title /1.101. /1.1 200 OK
02. { "data": [{
03. "id": "1″, "type": "article",
04. "attributes": { "title": " JSON API" },
05. }, ... ]
06. }Si vous avez besoin, par exemple, également de la date de publication, vous pouvez écrire une «date de publication» séparée par des virgules. En réponse, deux champs viendront en attributs. Il s'agit d'une convention qui peut être utilisée comme un outil anti-bikeshedding.
Recherche par articles
Nous avons souvent besoin de recherches et de filtres. Il existe des conventions pour cela - filtres spéciaux paramètres GET:
●
GET /articles ?filters[search]=api HTTP/1.1 - recherche;
●
GET /articles ?fiIters[from_date]=1538332156 HTTP/1.1 - télécharger des articles à partir d'une date spécifique;
●
GET /articles ?filters[is_published]=true HTTP/1.1 - téléchargez les articles qui viennent d'être publiés;
●
GET /articles ?fiIters[author]=1 HTTP/1.1 - téléchargez les articles avec le premier auteur.
Tri des articles
●
GET /articles ?sort=title /1.1 - par titre;
●
GET /articles ?sort=published_at HTTP/1.1 - par date de publication;
●
GET /articles ?sort=-published_at HTTP/1.1 - par date de publication dans le sens opposé;
●
GET /articles ?sort=author,-publisbed_at HTTP/1.1 - d'abord par auteur, puis par date de publication dans le sens inverse, si les articles sont du même auteur.
Besoin de changer les URL
Solution: l'hypermédia, que j'ai déjà mentionné, peut se faire comme suit. Si nous voulons que l'objet (ressource) soit auto-descriptif, le client pourrait comprendre par hypermédia ce qui peut être fait avec lui, et le serveur pourrait se développer indépendamment du client, alors vous pouvez ajouter des liens à la liste d'articles, à l'article lui-même en utilisant des clés de liens spéciales :
01. GET /articles /1.1
02. {
03. "data": [{
04. ...
05. "links": { "self": "http://localhost/articles/1" },
06. "relationships": { ... }
07. }],
08. "links": { "self": " http://localhost/articles " }
09. }
Ou lié, si nous voulons dire au client comment télécharger un commentaire sur cet article:
01. ...
02. "relationships": {
03. "comments": {
04. "links": {
05. "self": "http://localhost/articles/l/relationships/comments ",
06. "related": " http://localhost/articles/l/comments "
07. }
08. }
09. }Le client voit qu'il y a un lien, le suit, charge un commentaire. S'il n'y a pas de lien, alors il n'y a pas de commentaires. C'est pratique, mais si peu le font. Fielding est venu avec les principes de REST, mais tous ne sont pas entrés dans notre industrie. Nous en utilisons principalement deux ou trois.
En 2013, tous les hacks de la vie dont je vous ai parlé, Steve Klabnik a combiné dans la spécification de l'API JSON et s'est enregistré en tant que
nouveau type de média au-dessus de JSON . Notre développeur backend junior, évoluant progressivement, est donc arrivé à l'API JSON.
API JSON
Tout est décrit en détail sur le site
http://jsonapi.org/implementations/ : il existe même une liste de 170 implémentations différentes de spécifications pour 32 langages de programmation - et celles-ci ne sont ajoutées qu'au catalogue. Des bibliothèques, des analyseurs, des sérialiseurs, etc. ont déjà été écrits.
Puisque cette spécification est open source, tout le monde y investit. J'ai, entre autres, écrit quelque chose moi-même. Je suis sûr qu'il y en a beaucoup. Vous pouvez vous joindre à ce projet vous-même.
Avantages de l'API JSON
La spécification de l'API JSON résout un certain nombre de problèmes - un
accord commun pour tout le monde . Puisqu'il existe un accord général, nous
ne discutons pas au sein de l'équipe - le garage à vélos est documenté. Nous avons un accord sur les matériaux pour fabriquer un abri à vélo et comment le peindre.
Maintenant, lorsque le développeur fait quelque chose de mal et que je le vois, je ne lance pas la discussion, mais je dis: "Pas par l'API JSON!" et montrer en place dans la spécification. Ils me détestent dans l'entreprise, mais s'y habituent progressivement, et tout le monde a commencé à aimer l'API JSON. Nous faisons de nouveaux services par défaut selon cette spécification. Nous avons une clé de date, nous sommes prêts à ajouter des méta, à inclure des clés. Il existe des filtres de paramètres GET réservés pour les filtres. Nous ne discutons pas de ce qu'il faut appeler un filtre - nous utilisons cette spécification. Il décrit comment créer une URL.
Puisque nous ne discutons pas, mais que nous effectuons des tâches commerciales, la
productivité du développement est plus élevée . Nous avons les spécifications décrites, le développeur a lu le backend, fait l'API, nous l'avons vissé - le client est content.
Les problèmes populaires ont déjà été résolus , par exemple, avec la pagination. Il y a beaucoup d'indices dans la spécification.
Comme il s'agit de JSON (merci à Douglas Crockford pour ce format), il est plus concis que XML, il est assez
facile à lire et à comprendre .
Le fait qu'il s'agisse d'
Open Source peut être à la fois un plus et un moins, mais j'adore l'Open Source.
API JSON
L'objet a grandi (date, attributs, inclus, etc.) - le
frontend a besoin d'analyser les réponses: être capable d'itérer sur des tableaux, de contourner l'objet et de savoir comment réduire les travaux. Tous les développeurs novices ne connaissent pas ces choses complexes. Il existe des bibliothèques de sérialiseurs / désérialiseurs, vous pouvez les utiliser. En général, cela fonctionne uniquement avec des données, mais les objets sont volumineux.
Et le
backend a mal:
- Contrôle de l'emboîtement - inclure peut être grimpé très loin;
- La complexité des requêtes de base de données - elles sont parfois construites automatiquement et s'avèrent très difficiles;
- Sécurité - vous pouvez grimper dans la jungle, surtout si vous connectez une sorte de bibliothèque;
- La spécification est difficile à lire. Elle est en anglais, et cela en a effrayé certains, mais peu à peu tout le monde s'y est habitué;
- Toutes les bibliothèques n'implémentent pas bien la spécification - c'est un problème Open Source.
API JSON pièges
Un peu de hardcore.
Le nombre de relations dans le problème n'est pas limité. Si nous incluons, demandons des articles, y ajoutons des commentaires, alors en réponse, nous recevrons tous les commentaires de cet article. Il y a 10 000 commentaires - obtenez tous les 10 000 commentaires:
GET /articles/1?include=comments /1.101. ...
02. "relationships": {
03. "comments": {
04. "data": [0 ... ∞]
05. }
06. }Ainsi, en réalité, 5 Mo sont venus à notre demande en réponse: «Il est écrit dans le cahier des charges - il est nécessaire de reformuler correctement la demande:
GET /comments? filters[article]=1& page[size]=30 HTTP/1.101. {
02. "data": [0 ... 29]
03. }Nous demandons des commentaires avec un filtre par article, disons: "30 pièces, s'il vous plaît" et obtenez 30 commentaires. C'est l'ambiguïté.
Les mêmes choses peuvent être formulées de manière ambiguë :
●
GET /articles/1 ?include=comments HTTP/1.1 - demander un article avec des commentaires;
●
GET /articles/1/comments HTTP/1.1 - demander des commentaires sur l'article;
●
GET /comments ?filters[article]=1 HTTP/1.1 - demander des commentaires avec un filtre par article.
C'est la même chose - les mêmes données, qui sont obtenues de différentes manières, il y a une certaine ambiguïté. Cet écueil n'est pas immédiatement visible.
Les relations polymorphes un à plusieurs se glissent très rapidement dans REST.
01. GET /comments?include=commentable /1.1
02.
03. ...
04. "relationships": {
05. "commentable" : {
06. "data": { "type": "article", "id": "1″ }
07. }
08. }Il existe une connexion polymorphe commentable sur le backend - elle rampe dans REST. Cela devrait donc arriver, mais cela peut être déguisé. Vous ne pouvez pas le masquer dans l'API JSON - il sortira.
Relations plusieurs-à-plusieurs complexes avec des options avancées . De plus, toutes les tables de connexion sortent:
01. GET /users?include =users_comments /1.1
02.
03. ...
04. "relationships": {
05. "users_comments": {
06. "data": [{ "type": "users_comments", "id": "1″ }, ...]
07. },
08. }Swagger
Swagger est un outil d'écriture de documentation en ligne.
Disons que notre développeur principal a été invité à écrire la documentation de son API, et il l'a écrite. C'est facile si l'API est simple. S'il s'agit d'une API JSON, Swagger ne peut pas être écrit si facilement.
Exemple: animalerie Swagger. Chaque méthode peut être ouverte, voir réponse et exemples.
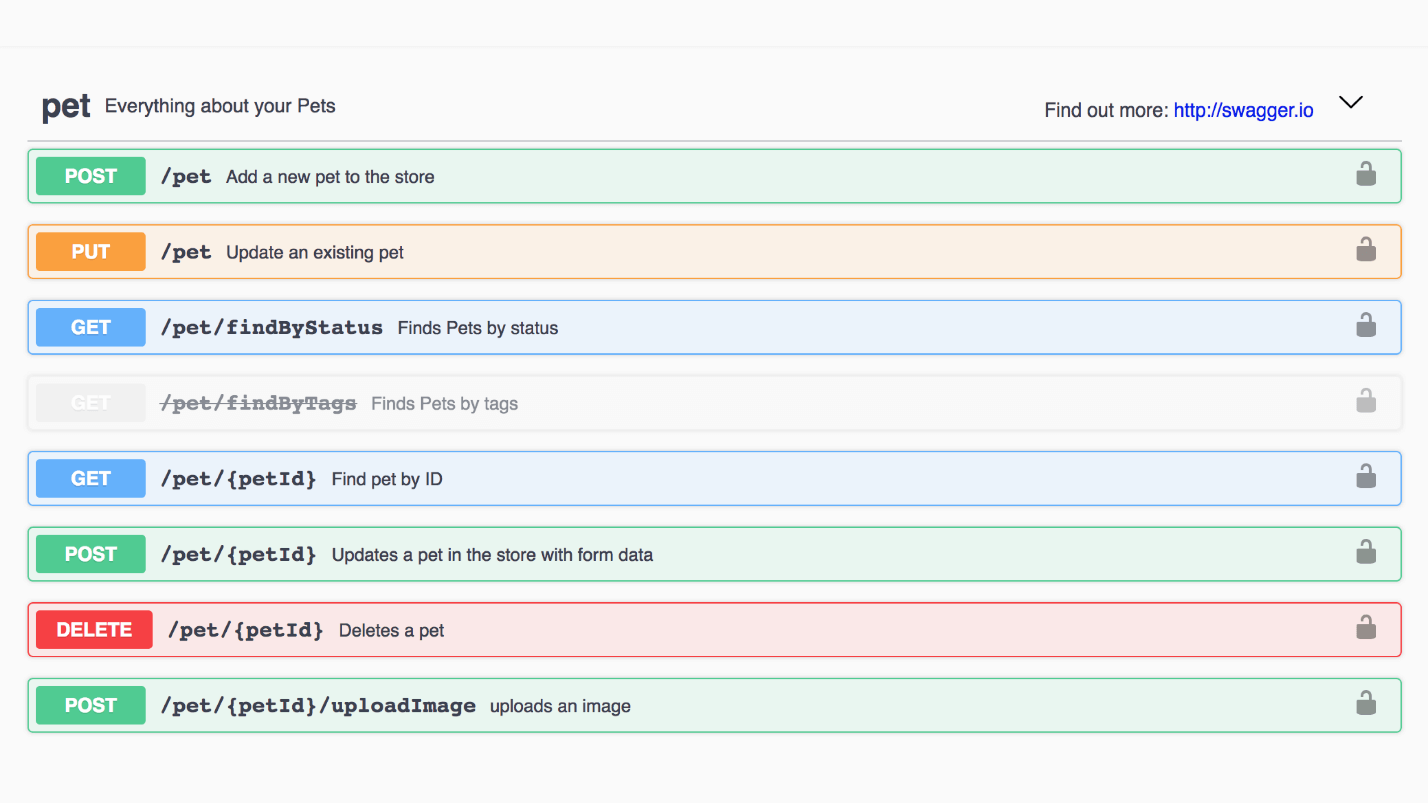
Ceci est un exemple de modèle Pet. Voici une interface sympa, tout est facile à lire.
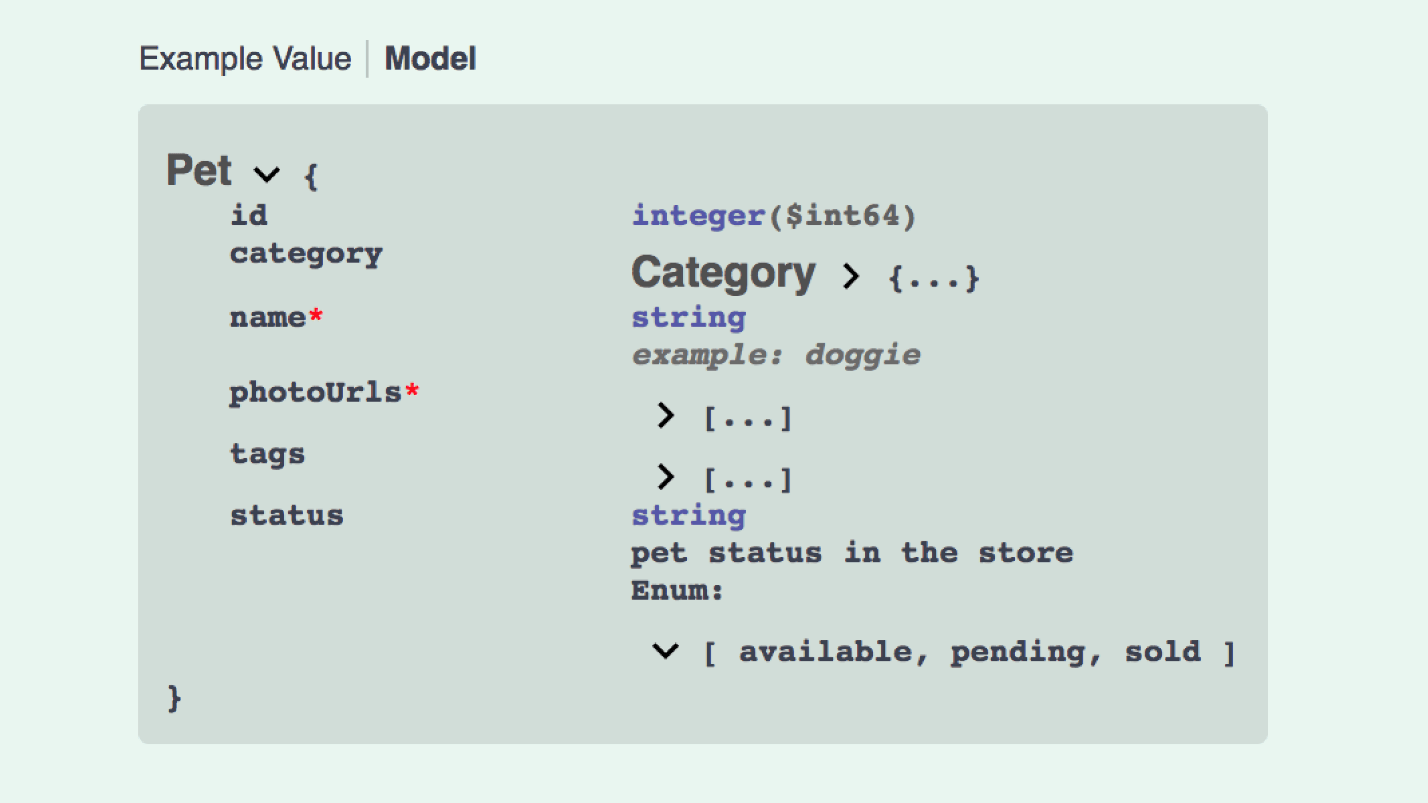
Et voici à quoi ressemble la création du modèle d'API JSON:

Ce n'est pas si génial. Nous avons besoin de données, dans des données quelque chose avec des relations, contient 5 types de modèles, etc. Vous pouvez écrire Swagger, l'API ouverte est une chose puissante, mais compliquée.
Alternative
Il existe une spécification OData, qui est apparue un peu plus tard - en 2015. C'est «La meilleure façon de se reposer», comme le garantit le site officiel. Cela ressemble à ceci:
01. GET http://services.odata.org/v4/TripRW/People HTTP/1.1 - demande GET;
02. OData-Version: 4.0 - en-tête spécial avec version;
03. OData-MaxVersion: 4.0 - Deuxième en-tête de version spéciale
La réponse ressemble à ceci:
01. HTTP/1.1 200 OK
02. Content-Type: application/json; odata.metadata=minimal
03. OData-Version: 4.0
04. {
05. '@odata.context': 'http://services.odata.org/V4/
06. '@odata.nextLink' : 'http://services.odata.org/V4/
07. 'value': [{
08. '@odata.etag': 1W/108D1D5BD423E51581′,
09. 'UserName': 'russellwhyte',
10. ...
Voici l'application étendue / json et l'objet.
Nous n'avons pas utilisé OData, tout d'abord, car c'est la même chose que l'API JSON, mais ce n'est pas concis. Il y a des objets énormes et il me semble que tout est bien pire à lire. OData est également sorti en Open Source, mais c'est plus compliqué.
Et GraphQL?
Naturellement, lorsque nous recherchions un nouveau format d'API, nous avons rencontré ce battage médiatique.
●
Seuil d'entrée élevé.Du point de vue du frontend, tout semble cool, mais vous ne pouvez pas demander au nouveau développeur d'écrire GraphQL, car vous devez d'abord l'étudier. C'est comme SQL - vous ne pouvez pas écrire immédiatement SQL, vous devez au moins lire ce que c'est, parcourir les tutoriels, c'est-à-dire que le seuil d'entrée augmente.
●
L'effet du big bang.S'il n'y avait pas d'API dans le projet, et que nous avons commencé à utiliser GraphQL, après un mois nous avons réalisé que cela ne nous convenait pas, il serait trop tard. Dois écrire des béquilles. Vous pouvez évoluer avec l'API JSON ou OData - le RESTful le plus simple, s'améliorant progressivement, se transforme en une API JSON.
● L'
enfer sur le backend.GraphQL appelle l'enfer sur le backend - un à un, tout comme l'API JSON entièrement implémentée, car GraphQL obtient un contrôle total sur les requêtes, et ceci est une bibliothèque, et vous devrez résoudre un tas de questions:
- contrôle de la nidification;
- récursivité
- limitation de fréquence;
- contrôle d'accès.
Au lieu de conclusions
Je recommande d'arrêter de discuter sur le garage à vélos, de prendre l'outil anti-bikeshedding comme spécification et de simplement créer une API avec une bonne spécification.
Pour trouver votre norme pour résoudre le problème d'un abri à vélos, vous pouvez consulter ces liens:
●
http://jsonapi.org●
http://www.odata.org●
https://graphgl.org●
http://xmlrpc.scripting.com●
https://www.jsonrpc.org: alexey-avdeev.com github .
, Frontend Conf , 27 28 ++ . , .
? ? ? , ? !
, , , , .