Dans cet article, vous apprendrez tout sur la bibliothèque babylonienne, et surtout - comment la recréer, et en fait n'importe quelle bibliothèque.
Commençons par les citations de la
bibliothèque babylonienne de
Luis Borges .
Devis«L'univers - certains l'appellent la Bibliothèque - se compose d'un nombre énorme, peut-être infini, de galeries hexagonales, avec de larges chambres de ventilation entourées de rails bas. De chaque hexagone, deux étages supérieurs et deux étages inférieurs sont visibles - à l'infini. »
«Une bibliothèque est une balle dont le centre exact se trouve dans l'un des hexagones et dont la surface est inaccessible. Sur chaque mur de chaque hexagone, il y a cinq étagères, sur chaque étagère, trente-deux livres du même format, chaque livre a quatre cent dix pages, chaque page a quarante lignes, chaque ligne contient environ quatre-vingt lettres noires. Il y a des lettres sur la colonne vertébrale du livre, mais elles ne définissent pas ni ne préfigurent ce que les pages diront. Cette différence, je le sais, semblait autrefois mystérieuse. »
Si vous entrez dans un hexagone aléatoire, montez sur n'importe quel mur, regardez n'importe quelle étagère et prenez le livre que vous aimez le plus, alors vous êtes le plus susceptible d'être contrarié. Après tout, vous vous attendiez à découvrir le sens de la vie là-bas, mais vous avez vu un étrange ensemble de personnages. Mais ne vous fâchez pas si vite! La plupart des livres n'ont pas de sens, car ils sont une recherche combinatoire de toutes les variantes possibles de vingt-cinq caractères (
c'est cet alphabet que Borges a utilisé dans sa bibliothèque, mais le lecteur découvrira alors qu'il peut y avoir n'importe quel nombre de caractères dans la bibliothèque ). La loi principale de la bibliothèque est qu'il n'y a pas deux livres absolument identiques, donc leur nombre est fini, et la bibliothèque finira également un jour. Borges pensait que la bibliothèque était périodique:
Devis«Peut-être que la peur et la vieillesse me trompent, mais je pense que la race humaine - la seule - est proche de l'extinction, et la Bibliothèque survivra: illuminée, inhabitée, sans fin, absolument immobile, remplie de volumes précieux, inutile, incorruptible, mystérieuse. Je viens d'écrire sans fin. Je n'ai pas mis ce mot par amour pour la rhétorique; Je pense qu'il est logique de supposer que le monde est sans fin. Ceux qui le jugent limité admettent que quelque part dans les couloirs, les escaliers et les hexagones peuvent se terminer pour une raison inconnue - une telle hypothèse est absurde. Ceux qui l'imaginent sans frontières oublient que le nombre de livres possibles est limité. J'ose proposer une telle solution à ce problème séculaire: la bibliothèque est illimitée et périodique. Si l'éternel vagabond entreprenait un voyage dans n'importe quelle direction, il serait en mesure de vérifier après des siècles que les mêmes livres se répètent dans le même gâchis (qui, une fois répété, devient ordre - Ordre). Cet espoir gracieux illumine ma solitude. »
Comparé au non-sens, il y a très peu de livres dont le contenu peut au moins être compris par une personne, mais cela ne change pas le fait que la bibliothèque contient tous les textes qui ont été et seront jamais inventés par une personne. Et d'ailleurs, depuis l'enfance, vous avez l'habitude de considérer certaines séquences de symboles significatives, tandis que d'autres ne le font pas. En fait, dans le contexte de la bibliothèque, il n'y a aucune différence entre eux. Mais ce qui a du sens a un pourcentage beaucoup plus faible, et nous l'appelons langage. C'est un moyen de communication entre les gens. Toute langue ne contient que quelques dizaines de milliers de mots, dont nous connaissons 70% de la force, il s'avère donc que nous ne pouvons pas interpréter la plupart de la recherche combinatoire des livres. Et quelqu'un souffre d'
apophénie et même dans des jeux de caractères aléatoires, il voit une signification cachée. Mais c'est une bonne idée pour la
stéganographie ! Eh bien, je continue à discuter de ce sujet dans les commentaires.
Avant de procéder à l'implémentation de cette bibliothèque, je vais vous surprendre par un fait intéressant: si vous souhaitez recréer la bibliothèque babylonienne de Louis Borges, vous n'y arriverez pas, car ses volumes dépassent le volume de l'Univers visible 10 ^ 611338 (!) Times. Et à propos de ce qui se passera dans des bibliothèques encore plus grandes, j'ai même peur de penser.
Implémentation de la bibliothèque
Description du module
Notre petite introduction est terminée. Mais ce n'est pas sans signification: maintenant vous comprenez à quoi ressemble la bibliothèque babylonienne, et la lecture ne sera que plus intéressante. Mais je vais m'éloigner de l'idée originale, je voulais créer une bibliothèque «universelle», qui sera discutée plus loin. J'écrirai en JavaScript sous Node.js. Que devrait faire la bibliothèque?
- Trouvez rapidement le texte souhaité et affichez son emplacement dans la bibliothèque
- Définir un titre de livre
- Trouvez rapidement un livre avec le bon titre
De plus, il doit être universel, c'est-à-dire n'importe lequel des paramètres de la bibliothèque peut être modifié si je le souhaite. Eh bien, je pense que je vais d'abord montrer tout le code du module, nous allons l'analyser en détail, voir comment cela fonctionne, et je dirai quelques mots.
Dépôt GithubLe fichier principal est index.js, toute la logique de la bibliothèque y est décrite, je vais vous expliquer le contenu de ce fichier.
let sha512 = require(`js-sha512`);
Nous connectons le module implémentant l'
algorithme de hachage
sha512 . Cela peut vous sembler étrange, mais cela nous sera toujours utile.
Quelle est la sortie de notre module? Il renvoie une fonction, un appel auquel retournera un objet de bibliothèque avec toutes les méthodes nécessaires. Nous pourrions le renvoyer tout de suite, mais gérer la bibliothèque ne serait pas si pratique lorsque nous transmettons des paramètres à la fonction et obtenons la bibliothèque «nécessaire». Cela nous permettra de créer une bibliothèque «universelle». Puisque j'essaie d'écrire dans le style ES6, ma fonction de flèche accepte un objet comme paramètres, qui seront ensuite déstructurés dans les variables nécessaires:
module.exports = ({ lengthOfPage = 4819, lengthOfTitle = 31, digs = '0123456789abcdefghijklmnopqrstuvwxyz', alphabet = ', .', wall = 5, shelf = 7, volume = 31, page = 421, } = {}) => {
Passons maintenant en revue les paramètres. En tant que paramètres numériques standard, j'ai décidé de choisir des nombres premiers, car il me semblait que ce serait plus intéressant.
- lengthOfPage - nombre, nombre de caractères sur une page. La valeur par défaut est 4819. Si nous factorisons ce nombre, nous obtenons 61 et 79. 61 lignes de 79 caractères, ou vice versa, mais je préfère la première option.
- lengthOfTitle - nombre, nombre de caractères dans le titre du titre du livre.
- digs - une chaîne, les chiffres possibles d'un nombre avec une base égale à la longueur de cette chaîne. À quoi sert ce numéro? Il contiendra le numéro (identifiant) de l'hexagone vers lequel nous voulons aller. Par défaut, il s'agit du latin minuscule et des chiffres de 0 à 9. La plupart du texte est codé ici, donc ce sera un grand nombre - plusieurs milliers de bits (selon le nombre de caractères sur la page), mais il sera traité caractère par caractère.
- alphabet - la chaîne, les caractères que nous voulons voir dans la bibliothèque. Il en sera rempli. Pour que tout fonctionne correctement, le nombre de caractères de l'alphabet doit être égal au nombre de caractères de la chaîne avec des chiffres possibles du nombre identifiant l'hexagone.
- mur - nombre, nombre maximal de murs, par défaut 5
- tablette - numéro, numéro de tablette maximum, par défaut 7
- volume - nombre, nombre maximum de livres, par défaut 31
- page - numéro, numéro de page maximum, par défaut 421
Comme vous pouvez le voir, cela ressemble un peu à la vraie bibliothèque babylonienne de Luis Borges. Mais j'ai dit plus d'une fois que nous créerons des bibliothèques «universelles» qui peuvent être la façon dont nous voulons les voir (par conséquent, le nombre hexadécimal peut être interprété différemment, par exemple, juste l'identifiant d'un endroit où est stocké celui souhaité) informations). La bibliothèque babylonienne n'est que l'une d'entre elles. Mais tous ont beaucoup en commun - un algorithme est responsable de leurs performances, ce qui sera maintenant discuté.
Algorithmes de recherche et d'affichage des pages
Lorsque nous allons à une adresse, nous voyons le contenu de la page. Si nous allons à nouveau à la même adresse, le contenu devrait être exactement le même. Cette propriété des bibliothèques fournit un algorithme pour générer des nombres pseudo-aléatoires - la
méthode congruente linéaire . Lorsque nous devons sélectionner un caractère pour générer l'adresse ou, inversement, le contenu de la page, cela nous aidera et le nombre de pages, d'étagères, etc. sera utilisé comme grain. La configuration de mon PRNG: m = 2 ^ 32 (4294967296), a = 22695477, c = 1. Je voudrais également ajouter que dans notre implémentation seul le principe de génération de nombres reste de la méthode congruente linéaire, le reste est changé. Nous continuons sur la liste des programmes:
Code module.exports = ({ lengthOfPage = 4819, lengthOfTitle = 31, digs = '0123456789abcdefghijklmnopqrstuvwxyz', alphabet = ', .', wall = 5, shelf = 7, volume = 31, page = 421, } = {}) => { let seed = 13;
Comme vous pouvez le voir, le grain PRNG change après chaque réception du numéro, et les résultats dépendent directement du soi-disant point de référence - le grain, après quoi les chiffres nous intéresseront. (nous générons l'adresse ou obtenons le contenu de la page)
La fonction
getHash nous aidera à générer un point de référence. Nous obtenons simplement un hachage de certaines données, prenons 7 caractères, traduisons en un système de nombres décimaux et vous avez terminé!
La fonction
mod se comporte de la même manière que l'opérateur%. Mais si le dividende est <0 (de telles situations sont possibles), la fonction
mod retournera un nombre positif en raison de la structure spéciale, nous en avons besoin pour sélectionner correctement les caractères de la chaîne
alphabétique lors de la réception du contenu de la page à l'adresse.
Et le dernier morceau de code de dessert est l'objet de bibliothèque retourné:
Code return { wall, shelf, volume, page, lengthOfPage, lengthOfTitle, search(searchStr) { let wall = `${(Math.random() * this.wall + 1 ^ 0)}`, shelf = `${(Math.random() * this.shelf + 1 ^ 0)}`, volume = pad(`${(Math.random()* this.volume + 1 ^ 0)}`, 2), page = pad(`${(Math.random()* this.page + 1 ^ 0)}`, 3), locHash = getHash(`${wall}${shelf}${volume}${page}`), hex = ``, depth = Math.random() * (this.lengthOfPage - searchStr.length) ^ 0; for (let i = 0; i < depth; i++){ searchStr = alphabet[Math.random() * alphabet.length ^ 0] + searchStr; } seed = locHash; for (let i = 0; i < searchStr.length; i++){ let index = alphabetIndexes[searchStr[i]] || -1, rand = rnd(0, alphabet.length), newIndex = mod(index + parseInt(rand), digs.length), newChar = digs[newIndex]; hex += newChar; } return `${hex}-${wall}-${shelf}-${+volume}-${+page}`; }, searchExactly(text) { const pos = Math.random() * (this.lengthOfPage - text.length) ^ 0; return this.search(`${` `.repeat(pos)}${text}${` `.repeat(this.lengthOfPage - (pos + text.length))}`); }, searchTitle(searchStr) { let wall = `${(Math.random() * this.wall + 1 ^ 0)}`, shelf = `${(Math.random() * this.shelf + 1 ^ 0)}`, volume = pad(`${(Math.random()* this.volume + 1 ^ 0)}`, 2), locHash = getHash(`${wall}${shelf}${volume}`), hex = ``; searchStr = searchStr.substr(0, this.lengthOfTitle); searchStr = searchStr.length == this.lengthOfTitle ? searchStr : `${searchStr}${` `.repeat(this.lengthOfTitle - searchStr.length)}`; seed = locHash; for (let i = 0; i < searchStr.length; i++){ let index = alphabetIndexes[searchStr[i]], rand = rnd(0, alphabet.length), newIndex = mod(index + parseInt(rand), digs.length), newChar = digs[newIndex]; hex += newChar; } return `${hex}-${wall}-${shelf}-${+volume}`; }, getPage(address) { let addressArray = address.split(`-`), hex = addressArray[0], locHash = getHash(`${addressArray[1]}${addressArray[2]}${pad(addressArray[3], 2)}${pad(addressArray[4], 3)}`), result = ``; seed = locHash; for (let i = 0; i < hex.length; i++) { let index = digsIndexes[hex[i]], rand = rnd(0, digs.length), newIndex = mod(index - parseInt(rand), alphabet.length), newChar = alphabet[newIndex]; result += newChar; } seed = getHash(result); while (result.length < this.lengthOfPage) { result += alphabet[parseInt(rnd(0, alphabet.length))]; } return result.substr(result.length - this.lengthOfPage); }, getTitle(address) { let addressArray = address.split(`-`), hex = addressArray[0], locHash = getHash(`${addressArray[1]}${addressArray[2]}${pad(addressArray[3], 2)}`), result = ``; seed = locHash; for (let i = 0; i < hex.length; i++) { let index = digsIndexes[hex[i]], rand = rnd(0, digs.length), newIndex = mod(index - parseInt(rand), alphabet.length), newChar = alphabet[newIndex]; result += newChar; } seed = getHash(result); while (result.length < this.lengthOfTitle) { result += alphabet[parseInt(rnd(0, alphabet.length))]; } return result.substr(result.length - this.lengthOfTitle); } };
Au début, nous lui écrivons les propriétés de la bibliothèque que j'ai décrite précédemment. Vous pouvez les changer même après l'appel de la fonction principale (qui, en principe, peut être appelée constructeur, mais mon code est faiblement similaire à l'implémentation de classe de la bibliothèque, donc je me limiterai au mot «principal»). Ce comportement n'est peut-être pas tout à fait adéquat, mais flexible. Passez maintenant en revue chaque méthode.
Méthode de recherche
search(searchStr) { let wall = `${(Math.random() * this.wall + 1 ^ 0)}`, shelf = `${(Math.random() * this.shelf + 1 ^ 0)}`, volume = pad(`${(Math.random() * this.volume + 1 ^ 0)}`, 2), page = pad(`${(Math.random() * this.page + 1 ^ 0)}`, 3), locHash = getHash(`${wall}${shelf}${volume}${page}`), hex = ``, depth = Math.random() * (this.lengthOfPage - searchStr.length) ^ 0; for (let i = 0; i < depth; i++){ searchStr = alphabet[Math.random() * alphabet.length ^ 0] + searchStr; } seed = locHash; for (let i = 0; i < searchStr.length; i++){ let index = alphabetIndexes[searchStr[i]] || -1, rand = rnd(0, alphabet.length), newIndex = mod(index + parseInt(rand), digs.length), newChar = digs[newIndex]; hex += newChar; } return `${hex}-${wall}-${shelf}-${+volume}-${+page}`; }
Renvoie l'adresse de la chaîne
searchStr dans la bibliothèque. Pour ce faire, sélectionnez au hasard
mur, étagère, volume, page .
volume et
page également rembourrés avec des zéros à la longueur souhaitée. Ensuite, concaténez-les dans une chaîne pour passer à la fonction
getHash . Le
locHash résultant est le point de départ, c'est-à-dire le grain.
Pour une plus grande imprévisibilité, nous
complétons la profondeur de searchStr avec des caractères pseudo-aléatoires de l'alphabet, définissons la graine de
départ sur
locHash . À ce stade, peu importe la façon dont nous complétons la ligne, vous pouvez donc utiliser le PRNG JavaScript intégré, ce n'est pas critique. Vous pouvez l'abandonner complètement pour que les résultats qui nous intéressent soient toujours en haut de la page.
Il ne reste plus qu'à générer l'identifiant hexagonal. Pour chaque caractère de la chaîne
searchStr ,
nous exécutons l'algorithme:
- Obtenez le numéro du caractère d' index dans l'alphabet à partir de l'objet alphabetIndexes . Si ce n'est pas le cas, retournez -1, mais si cela se produit, vous faites certainement quelque chose de mal.
- Générez un nombre aléatoire pseudo-aléatoire en utilisant notre PRNG, dans la plage de 0 à la longueur de l'alphabet.
- Calculez le nouvel indice, qui est calculé comme la somme du nombre de l' indice de symbole et du nombre pseudo-aléatoire rand , divisé modulo la longueur des fouilles .
- Ainsi, nous avons obtenu le chiffre de l'identifiant hexagonal - newChar (en le prenant à partir des fouilles ).
- Ajouter newChar à l'identifiant hexadécimal hex
À la fin de la génération
hexadécimale , nous renvoyons l'adresse complète de l'endroit où se trouve la ligne souhaitée. Les composants d'adresse sont séparés par un tiret.
Méthode SearchExactly
searchExactly(text) { const pos = Math.random() * (this.lengthOfPage - text.length) ^ 0; return this.search(`${` `.repeat(pos)}${text}${` `.repeat(this.lengthOfPage - (pos + text.length))}`); }
Cette méthode fait la même chose que la méthode de
recherche , mais remplit tous les espaces libres (rend la chaîne de
recherche searchStr avec une longueur de caractères
lengthOfPage ). Lorsque vous consultez une telle page, il apparaît qu'il n'y a rien d'autre que votre texte.
Méthode SearchTitle
searchTitle(searchStr) { let wall = `${(Math.random() * this.wall + 1 ^ 0)}`, shelf = `${(Math.random() * this.shelf + 1 ^ 0)}`, volume = pad(`${(Math.random()* this.volume + 1 ^ 0)}`, 2), locHash = getHash(`${wall}${shelf}${volume}`), hex = ``; searchStr = searchStr.substr(0, this.lengthOfTitle); searchStr = searchStr.length == this.lengthOfTitle ? searchStr : `${searchStr}${` `.repeat(this.lengthOfTitle - searchStr.length)}`; seed = locHash; for (let i = 0; i < searchStr.length; i++){ let index = alphabetIndexes[searchStr[i]], rand = rnd(0, alphabet.length), newIndex = mod(index + parseInt(rand), digs.length), newChar = digs[newIndex]; hex += newChar; } return `${hex}-${wall}-${shelf}-${+volume}`; }
La méthode
searchTitle renvoie l'adresse d'un livre appelé
searchStr . À l'intérieur, c'est très similaire à la
recherche . La différence est que lors du calcul de
locHash, nous n'utilisons pas la page pour lier son nom au livre. Cela ne devrait pas dépendre de la page.
searchStr est tronqué à
lengthOfTitle et
complété avec des espaces si nécessaire. De même, l'identifiant hexagonal est généré et l'adresse reçue est retournée. Veuillez noter qu'il n'y a pas de page, comme c'était le cas lors de la recherche de l'adresse exacte d'un texte arbitraire. Donc, si vous voulez savoir ce qui se trouve dans le livre avec le nom que vous avez inventé, décidez de la page que vous souhaitez consulter.
Méthode GetPage
getPage(address) { let addressArray = address.split(`-`), hex = addressArray[0], locHash = getHash(`${addressArray[1]}${addressArray[2]}${pad(addressArray[3], 2)}${pad(addressArray[4], 3)}`), result = ``; seed = locHash; for (let i = 0; i < hex.length; i++) { let index = digsIndexes[hex[i]], rand = rnd(0, digs.length), newIndex = mod(index - parseInt(rand), alphabet.length), newChar = alphabet[newIndex]; result += newChar; } seed = getHash(result); while (result.length < this.lengthOfPage) { result += alphabet[parseInt(rnd(0, alphabet.length))]; } return result.substr(result.length - this.lengthOfPage); }
Le contraire de la méthode de
recherche . Sa tâche consiste à renvoyer le contenu de la page à l'adresse indiquée. Pour ce faire, nous convertissons l'adresse en un tableau à l'aide du séparateur "-". Nous avons maintenant un tableau de composants d'adresse: identifiant hexagonal, mur, étagère, livre, page. Nous calculons
locHash de la même manière que nous l'avons fait dans la méthode de
recherche . Nous obtenons le même numéro que lors de la génération de l'adresse. Cela signifie que le PRNG produira les mêmes nombres, c'est ce comportement qui assure la réversibilité de nos transformations sur le texte source. Pour le calculer, nous effectuons l'algorithme sur chaque caractère (de facto, c'est un chiffre) de l'identifiant hexagonal:
- Nous calculons l' index dans les digits de chaîne. Prenez-le de digsIndexes .
- En utilisant le PRNG, nous générons un nombre aléatoire pseudo-aléatoire dans la plage 0 à la base du système numérique d'un grand nombre, égal à la longueur de la chaîne contenant les chiffres de ce beau nombre. Tout est évident.
- Nous calculons la position du symbole du texte source newIndex comme la différence entre index et rand , divisé modulo la longueur de l'alphabet. Il est possible que la différence soit négative, alors la division habituelle modulo donnera un indice négatif, ce qui ne nous convient pas, nous utilisons donc une version modifiée de la division modulo. (vous pouvez essayer l'option de prendre la valeur absolue de la formule ci-dessus, cela résout également le problème des nombres négatifs, mais en pratique cela n'a pas encore été testé)
- Le caractère du texte de la page est newChar , nous obtenons l'index de l'alphabet.
- Ajoutez un caractère de texte au résultat.
Le résultat obtenu à ce stade ne remplira pas toujours la page entière, nous allons donc calculer le nouveau grain à partir du résultat actuel et remplir l'espace libre avec des caractères de l'alphabet. Le PRNG nous aide à choisir un symbole.
Ceci termine le calcul du contenu de la page, nous le renvoyons, sans oublier de recadrer à la longueur maximale. L'identifiant hexagonal était peut-être indécemment grand dans l'adresse d'entrée.
Méthode GetTitle
getTitle(address) { let addressArray = address.split(`-`), hex = addressArray[0], locHash = getHash(`${addressArray[1]}${addressArray[2]}${pad(addressArray[3], 2)}`), result = ``; seed = locHash; for (let i = 0; i < hex.length; i++) { let index = digsIndexes[hex[i]], rand = rnd(0, digs.length), newIndex = mod(index - parseInt(rand), alphabet.length), newChar = alphabet[newIndex]; result += newChar; } seed = getHash(result); while (result.length < this.lengthOfTitle) { result += alphabet[parseInt(rnd(0, alphabet.length))]; } return result.substr(result.length - this.lengthOfTitle); }
Eh bien, l'histoire est la même. Imaginez que vous lisez la description de la méthode précédente, uniquement lors du calcul des grains PRNG, ne prenez pas en compte le numéro de page, et ajoutez et recadrez le résultat à la longueur maximale du titre du livre -
lengthOfTitle .
Test du module de création de bibliothèques
Après avoir examiné le principe de fonctionnement de toute bibliothèque de type babylonien - il est temps de tout essayer dans la pratique. J'utiliserai la configuration au plus près de celle créée par Louis Borges. Nous rechercherons une simple phrase "habr.com":
const libraryofbabel = require(`libraryofbabel`)({ lengthOfPage: 3200, alphabet: `abcdefghijklmnopqrstuvwxyz, .`,
Run, le résultat:

Pour le moment, cela ne nous donne rien. Mais découvrons ce qui se cache derrière cette adresse! Le code sera comme ceci:
const libraryofbabel = require(`libraryofbabel`)({ lengthOfPage: 3200, alphabet: `abcdefghijklmnopqrstuvwxyz, .`,
Résultat:
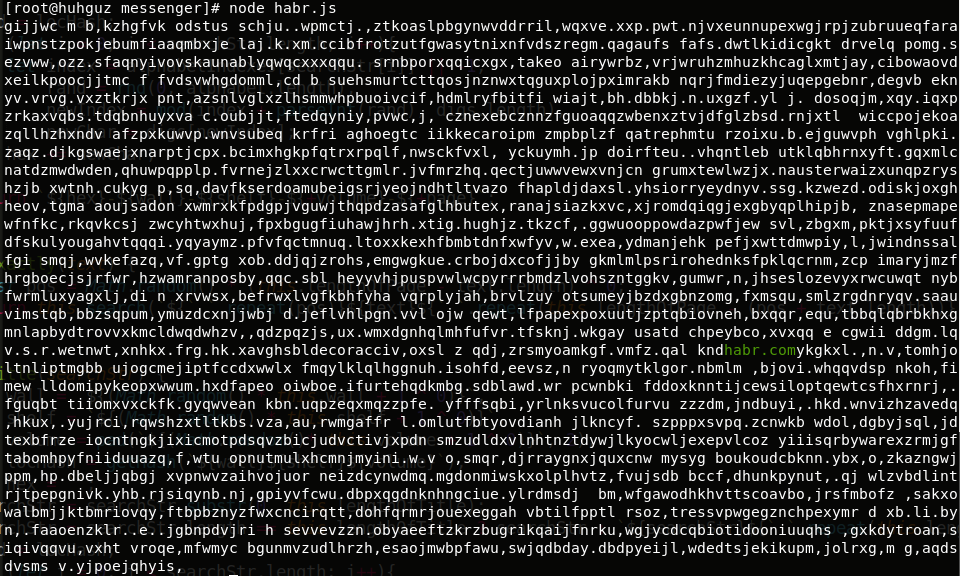
Nous avons trouvé ce que nous recherchions dans un nombre infini de pages dénuées de sens (je parie)!
Mais c'est loin d'être le seul endroit où se trouve cette phrase. Au prochain démarrage du programme, une autre adresse sera générée. Si vous le souhaitez, vous pouvez en enregistrer un et l'utiliser. L'essentiel est que le contenu des pages ne change jamais. Regardons le titre du livre dans lequel se trouve notre phrase. Le code sera le suivant:
const libraryofbabel = require(`libraryofbabel`)({ lengthOfPage: 3200, alphabet: `abcdefghijklmnopqrstuvwxyz, .`,
Le titre du livre ressemble à ceci:
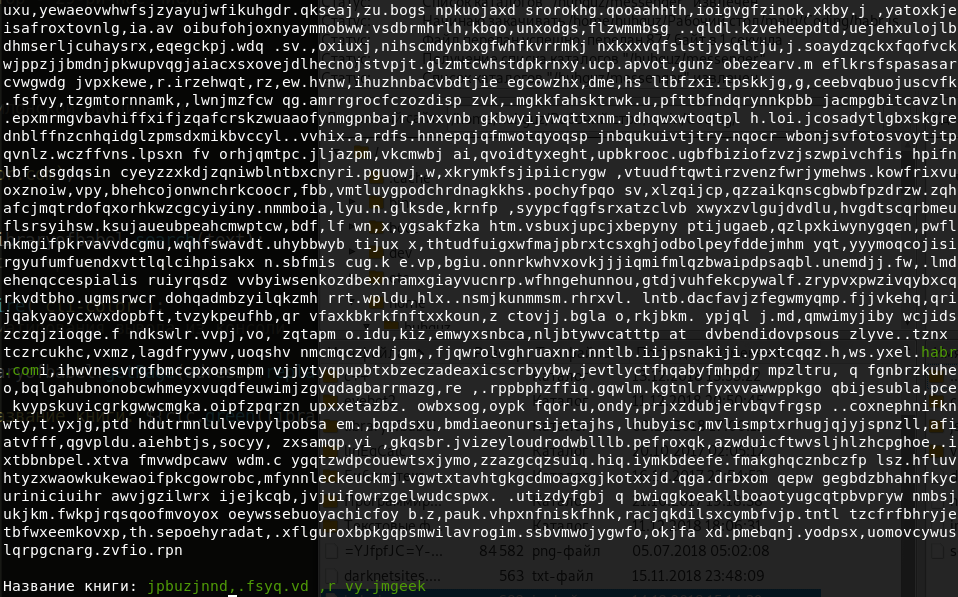
Honnêtement, ça n'a pas l'air très attrayant. Trouvons alors un livre avec notre phrase dans le titre:
const libraryofbabel = require(`libraryofbabel`)({ lengthOfPage: 3200, alphabet: `abcdefghijklmnopqrstuvwxyz, .`,
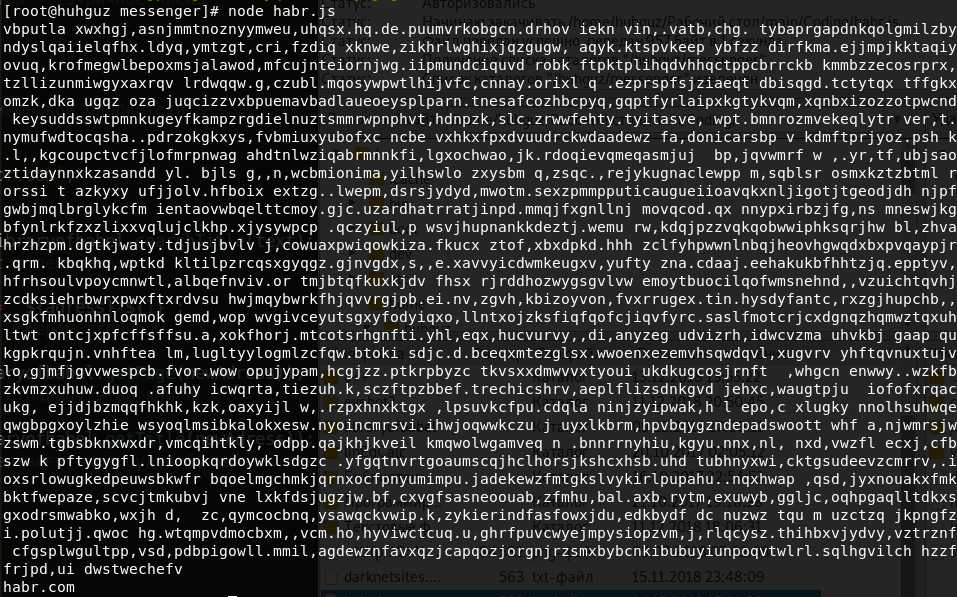
Vous comprenez maintenant comment utiliser cette bibliothèque. Permettez-moi de démontrer la possibilité de créer une bibliothèque complètement différente. Maintenant, il sera rempli de uns et de zéros, chaque page aura 100 caractères, l'adresse sera un nombre hexadécimal. N'oubliez pas d'observer la condition d'égalité des longueurs de l'alphabet et de la chaîne de chiffres de notre grand nombre. Nous rechercherons, par exemple, "10101100101010111001000000". Nous regardons:
const libraryofbabel = require(`libraryofbabel`)({ lengthOfPage: 100, alphabet: `1010101010101010`,

Jetons un coup d'œil à la recherche d'une correspondance complète. Pour ce faire,
revenons à l'ancien exemple et dans le code, remplacez
libraryofbabel.search par
libraryofbabel.searchExactly :
const libraryofbabel = require(`libraryofbabel`)({ lengthOfPage: 3200, alphabet: `abcdefghijklmnopqrstuvwxyz, .`,
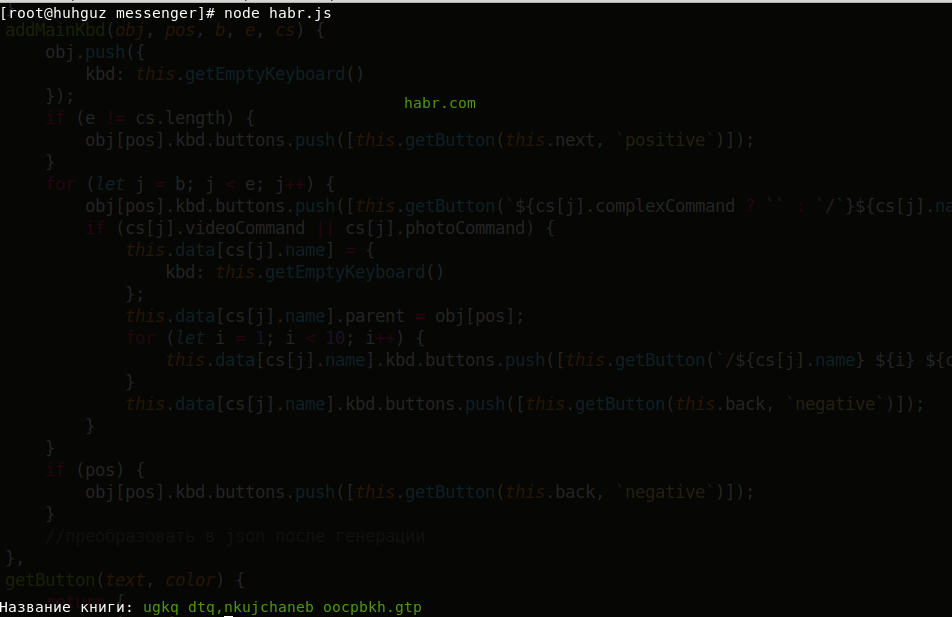
Conclusion
Après avoir lu la description de l'algorithme de fonctionnement de la bibliothèque, vous avez probablement déjà deviné que c'était une sorte de tromperie.
Lorsque vous recherchez quelque chose de significatif dans la bibliothèque, il est simplement encodé sous une forme différente et affiché sous une forme différente. Mais il est si bien servi que vous commencez à croire en ces rangées infinies d'hexagones. En fait, ce n'est rien de plus qu'une abstraction mathématique. Mais le fait que dans cette bibliothèque vous puissiez trouver absolument n'importe quoi, n'importe quoi, est vrai. La vérité est que si vous générez des séquences aléatoires de caractères, tôt ou tard, vous pouvez obtenir absolument n'importe quel texte. Pour une meilleure compréhension de ce sujet, vous pouvez étudier le théorème des singes sans fin .Vous pouvez trouver d'autres options pour implémenter des bibliothèques: utilisez n'importe quel algorithme de chiffrement, où le texte chiffré sera l'adresse dans votre bibliothèque complète. Décryptage - obtenir le contenu de la page. Ou peut-être essayerbase64 , m?Une utilisation possible de la bibliothèque est de stocker des mots de passe dans certains de ses emplacements. Créez la configuration dont vous avez besoin, découvrez où se trouvent vos mots de passe dans la bibliothèque (oui, ils existent déjà. Et vous pensiez que c'était vous qui les aviez inventés?), Enregistrez l'adresse. Et maintenant, lorsque vous avez besoin de trouver une sorte de mot de passe, il vous suffit de le trouver dans la bibliothèque. Mais cette approche est dangereuse, car un attaquant peut découvrir la configuration de la bibliothèque et simplement utiliser votre adresse. Mais s'il ne connaît pas la signification de ce qu'il a trouvé, il est peu probable que vos données lui parviennent. Et est-ce vraiment une telle méthode de stockage de mot de passe? Non, il a donc sa place.Cette idée peut être utilisée pour créer une variété de "bibliothèques". Vous pouvez parcourir non seulement les caractères, mais aussi les mots entiers ou même les sons! Imaginez un endroit où vous pouvez écouter absolument n'importe quel son disponible pour la perception humaine, ou pour trouver une sorte de chanson. À l'avenir, je vais certainement essayer de mettre en œuvre cela.La version web en russe est disponible ici , elle est déployée sur mon serveur virtuel. Je ne connais pas toutes les recherches agréables du sens de la vie dans la bibliothèque babylonienne, ni ce que vous voulez créer. Salut! :)