Il semble que nous soyons si profondément immergés dans la jungle du développement à haute charge que nous ne pensons tout simplement pas aux problèmes de base. Prenez, par exemple, le sharding. Que comprendre s'il est possible d'écrire conditionnellement shards = n dans les paramètres de la base de données et que tout sera fait par lui-même. C'est vrai, il l'est, mais si, plutôt, quand quelque chose tourne mal, les ressources commencent vraiment à être rares, j'aimerais comprendre quelle est la raison et comment y remédier.
En bref, si vous apportiez votre implémentation alternative de hachage dans Cassandra, alors il n'y a pratiquement aucune révélation pour vous. Mais si la charge de vos services arrive déjà et que la connaissance du système ne suit pas, vous êtes le bienvenu. Le grand et terrible
Andrei Aksyonov (
shodan ) à sa manière habituelle dira que le
partage est mauvais, pas le partage est également mauvais , et comment il est organisé à l'intérieur. Et tout à fait par accident, l'une des parties de l'histoire du sharding ne concerne pas vraiment le sharding du tout, mais le diable sait quoi - comment mapper des objets sur des fragments.

La photo des phoques (même s'ils se sont avérés accidentellement être des chiots) semble déjà répondre à la question de savoir pourquoi c'est tout, mais commençons dans l'ordre.
Qu'est-ce que le sharding?
Si vous google persistante, il se trouve qu'il existe une frontière assez floue entre le soi-disant partitionnement et le soi-disant sharding. Tout le monde appelle tout ce qu'il veut que ce qu'il veut. Certaines personnes distinguent le partitionnement horizontal et le partitionnement. D'autres disent que le sharding est un certain type de partitionnement horizontal.
Je n'ai trouvé aucune norme terminologique qui serait approuvée par les pères fondateurs et certifiée ISO. Une croyance intérieure personnelle est quelque chose comme ceci: Le
partitionnement, en moyenne, «coupe la base en morceaux» de manière arbitraire.
- Cloisonnement vertical Par exemple, il y a un tableau géant avec quelques milliards d'entrées dans 60 colonnes. Au lieu de tenir une telle table gigantesque, nous gardons 60 tables non moins gigantesques avec 2 milliards d'enregistrements chacune - et ce n'est pas une base de données à temps partiel, mais un partitionnement vertical (comme un exemple de terminologie).
- Partitionnement horizontal - nous coupons ligne par ligne, peut-être à l'intérieur du serveur.
Le moment gênant ici est la différence subtile entre le partitionnement horizontal et le sharding. Vous pouvez me couper en morceaux, mais je ne vous dirai pas avec certitude de quoi il s'agit. On a le sentiment que le partage et le partitionnement horizontal sont à peu près la même chose.
Le sharding est en général lorsqu'une grande table en termes de bases de données ou d'une collection de documents, d'objets, si vous n'avez pas de base de données, mais un magasin de documents, est coupée spécifiquement pour les objets. Autrement dit, des pièces de 2 milliards d'objets sont sélectionnées, quelle que soit leur taille. Les objets eux-mêmes à l'intérieur de chaque objet ne sont pas coupés en morceaux, nous ne nous décomposons pas en colonnes distinctes, à savoir, nous disposons des faisceaux à différents endroits.
Lien vers la présentation pour l'exhaustivité.De subtiles différences terminologiques ont déjà persisté. Par exemple, relativement parlant, les développeurs de Postgres peuvent dire que le partitionnement horizontal se produit lorsque toutes les tables dans lesquelles la table principale est divisée se trouvent dans le même schéma, et lorsque sur des machines différentes, il est partitionné.
Dans un sens général, sans être lié à la terminologie d'une base de données spécifique et d'un système de gestion de données spécifique, on a le sentiment que le sharding ne fait que trancher ligne par ligne et ainsi de suite - et c'est tout:
Partitionnement (~ =, \ in ...) Le partitionnement horizontal == est typique.
J'insiste, généralement. En ce sens que nous faisons tout cela non seulement pour couper 2 milliards de documents en 20 tableaux, chacun étant plus facile à gérer, mais pour le distribuer dans de nombreux cœurs, de nombreux disques ou de nombreux serveurs physiques ou virtuels différents .
Il est entendu que nous procédons de telle sorte que chaque fragment - chaque shatka de données - soit répliqué plusieurs fois. Mais en fait, non.
INSERT INTO docs00 SELECT * FROM documents WHERE (id%16)=0 ... INSERT INTO docs15 SELECT * FROM documents WHERE (id%16)=15
En fait, si vous effectuez un tel découpage de données, et à partir d'une table SQL géante sur MySQL, vous générerez 16 petites tables sur votre vaillant ordinateur portable, sans aller au-delà d'un seul ordinateur portable, pas d'un seul schéma, pas d'une seule base de données, etc. etc. - tout, vous avez déjà du sharding.
En se souvenant de l'illustration avec des chiots, cela conduit à ce qui suit:
- La bande passante augmente.
- La latence ne change pas, c'est-à-dire que chacun, pour ainsi dire, travailleur ou consommateur dans ce cas, obtient le sien. On ne sait pas ce que les chiots obtiennent sur la photo, mais les demandes sont servies à peu près en même temps, comme si le chiot était seul.
- Ou à la fois cela, et un autre, et toujours une haute disponibilité (réplication).
Pourquoi la bande passante? Parfois, nous pouvons avoir de tels volumes de données qui ne correspondent pas - on ne sait pas où, mais ils ne correspondent pas - par 1 {core | conduire | serveur | ...}. Il n'y a tout simplement pas assez de ressources et c'est tout. Pour travailler avec ce grand ensemble de données, vous devez le couper.
Pourquoi la latence? Sur un cœur, l'analyse d'une table de 2 milliards de lignes est 20 fois plus lente que l'analyse de 20 tables sur 20 noyaux, en parallèle. Les données sont traitées trop lentement sur une seule ressource.
Pourquoi une haute disponibilité? Ou nous coupons les données afin de faire l'une et l'autre en même temps, et en même temps plusieurs copies de chaque fragment - la réplication fournit une haute disponibilité.
Un exemple simple de "comment le faire avec vos mains"
Le partitionnement conditionnel peut être découpé en utilisant la table de test test.documents pour 32 documents, et en générant à partir de cette table 16 tables de test pour environ 2 documents test.docs00, 01, 02, ..., 15 chacun.
INSERT INTO docs00 SELECT * FROM documents WHERE (id%16)=0 ... INSERT INTO docs15 SELECT * FROM documents WHERE (id%16)=15
Pourquoi? Parce que a priori nous ne savons pas comment est distribué id, si de 1 à 32 inclus, alors il y aura exactement 2 documents chacun, sinon non.
Nous faisons cela pour quoi. Après avoir fait 16 tableaux, nous pouvons «attraper» 16 de ce dont nous avons besoin. Indépendamment de ce sur quoi nous nous appuyions, nous pouvons paralléliser ces ressources. Par exemple, s'il n'y a pas assez d'espace disque, il sera judicieux de décomposer ces tables en disques distincts.
Tout cela, malheureusement, n'est pas gratuit. Je soupçonne que dans le cas du standard SQL canonique (je n'ai pas relu le standard SQL depuis longtemps, il n'a peut-être pas été mis à jour depuis longtemps), il n'y a pas de syntaxe standardisée officielle pour dire à un serveur SQL: «Cher serveur SQL, faites-moi 32 fragments et les mettre sur 4 disques. " Mais dans les implémentations individuelles, il existe souvent une syntaxe spécifique afin de faire la même chose en principe. PostgreSQL a des mécanismes de partitionnement, MySQL MariaDB l'a, Oracle a probablement fait tout cela il y a longtemps.
Néanmoins, si nous le faisons à la main, sans support de base de données et dans le cadre de la norme, nous
payons conditionnellement la complexité de l'accès aux données . Là où il y avait un simple SELECT * FROM documents WHERE id = 123, maintenant 16 x SELECT * FROM docsXX. Et bien, si on essayait d'obtenir le record par clé. Significativement plus intéressant si nous essayions d'obtenir une première gamme de disques. Maintenant (si, je le souligne, comme si c'était un imbécile, et que je reste dans la norme), les résultats de ces 16 SELECT * FROM devront être combinés dans l'application.
Quel changement de performance attendre?- Intuitivement linéaire.
- Théoriquement - sublinéaire, parce que la loi d'Amdahl .
- En pratique - peut-être presque linéairement, peut-être pas.
En fait, la bonne réponse est inconnue. En appliquant intelligemment la technique de sharding, vous pouvez obtenir une détérioration super-linéaire significative des performances de votre application, et même le DBA fonctionnera avec un poker chaud.
Voyons comment cela peut être réalisé. Il est clair que simplement définir le paramètre sur les fragments PostgreSQL = 16, puis il s'est décollé - ce n'est pas intéressant. Réfléchissons à la façon dont nous pourrions réaliser que
nous ralentirions à 32 fois après le partage , ce qui est intéressant du point de vue de la façon de ne pas le faire.
Nos tentatives d'accélération ou de ralentissement reposeront toujours contre les classiques - la bonne vieille loi d'Amdahl, qui dit qu'il n'y a pas de parallélisation parfaite de toute demande, il y a toujours une partie cohérente.
Loi d'Amdahl
Il y a toujours une partie sérialisée.
Il y a toujours une partie de l'exécution de la requête qui est parallélisée, et il y a toujours une partie qui n'est pas parallèle. Même s'il vous semble qu'une requête parfaitement parallèle, collectant au moins une ligne du résultat que vous allez envoyer au client, à partir des lignes reçues de chaque fragment, il y en a toujours, et elle est toujours cohérente.
Il y a toujours une sorte de partie séquentielle. Il peut être minuscule, absolument invisible dans le contexte général, il peut être gigantesque et, par conséquent, affecter fortement la parallélisation, mais il est toujours là.
De plus, son influence est en
train de changer et peut augmenter considérablement, par exemple, si nous réduisons notre table - augmentons les taux - de 64 enregistrements à 16 tables de 4 enregistrements, cette partie changera. Bien sûr, à en juger par ces quantités gigantesques de données, nous travaillons sur un téléphone mobile et un processeur à 86 MHz, nous n'avons pas assez de fichiers qui peuvent être ouverts en même temps. Apparemment, avec une telle entrée, nous ouvrons un fichier à la fois.
- C'était Total = Serial + Parallel . Par exemple, où parallèle est tout le travail à l'intérieur de la base de données et série envoie le résultat au client.
- Il est devenu Total2 = Serial + Parallel / N + Xserial. Par exemple, lorsque le général ORDER BY, Xserial> 0.
Avec cet exemple simple, j'essaie de montrer que certains Xserial apparaissent. En plus du fait qu'il y a toujours une partie sérialisée, et du fait que nous essayons de travailler avec des données en parallèle, une partie supplémentaire apparaît pour assurer ce découpage des données. En gros, nous pouvons avoir besoin de:
- trouver ces 16 tables dans le dictionnaire de base de données interne;
- ouvrir des fichiers;
- allouer de la mémoire;
- déplacer la mémoire;
- tacher les résultats;
- synchroniser entre les cœurs;
Tous les effets désynchronisés apparaissent toujours. Ils peuvent être insignifiants et occuper un milliardième du temps total, mais ils sont toujours non nuls et existent toujours. Avec leur aide, nous pouvons considérablement perdre en productivité après le sharding.
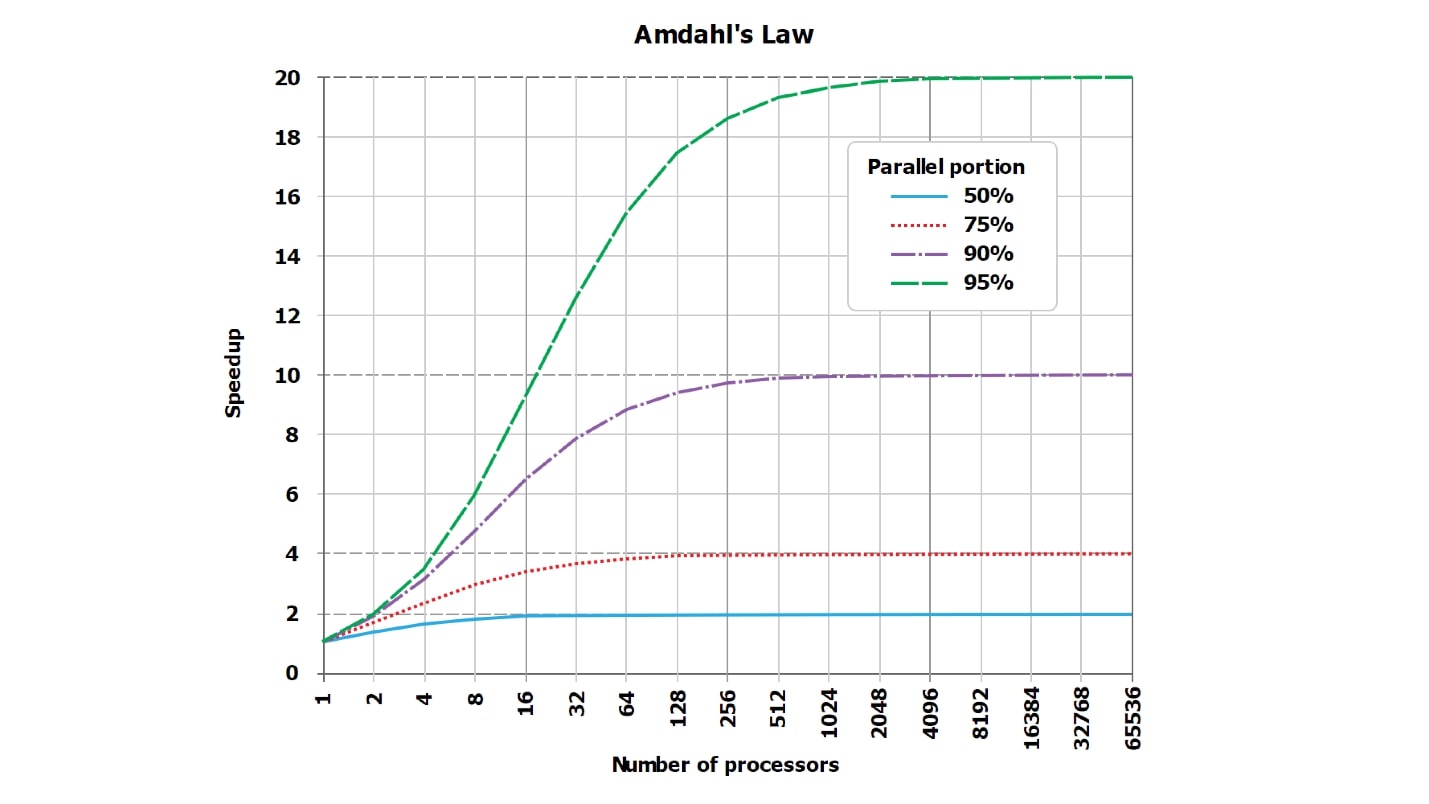
Ceci est une image standard de la loi d'Amdahl. Ce n'est pas très lisible, mais il est important que les lignes, qui devraient idéalement être droites et croître linéairement, butent sur l'asymptote. Mais comme le graphique sur Internet est illisible, j'ai fait, à mon avis, des tableaux plus visuels avec des chiffres.
Supposons que nous ayons une partie sérialisée du traitement de la demande, ce qui ne prend que 5%:
série = 0,05 = 1/20.Intuitivement, il semblerait qu'avec la partie sérialisée, qui ne prend que 1/20 du traitement de la demande, si nous parallélisons le traitement de la demande à 20 cœurs, elle deviendra environ 20, dans le pire des cas, 18 fois plus rapide.
En fait, les
mathématiques sont une chose sans cœur :
wall = 0.05 + 0.95/num_cores, speedup = 1 / (0.05 + 0.95/num_cores)Il s'avère que si vous calculez soigneusement, avec une partie sérialisée de 5%, l'accélération sera 10 fois (10,3), et c'est 51% par rapport à l'idéal théorique.
| 8 noyaux | = 5,9 | = 74% |
| 10 cœurs | = 6,9 | = 69% |
| 20 noyaux | = 10,3 | = 51% |
| 40 noyaux | = 13,6 | = 34% |
| 128 cœurs | = 17,4 | = 14% |
En utilisant 20 cœurs (20 disques, si vous le souhaitez) pour la tâche sur laquelle on a travaillé auparavant, nous n'obtiendrons jamais théoriquement une accélération plus de 20 fois, mais pratiquement beaucoup moins. De plus, avec une augmentation du nombre de parallèles, l'inefficacité augmente rapidement.
Lorsqu'il ne reste que 1% du travail sérialisé et 99% en parallèle, les valeurs d'accélération sont quelque peu améliorées:
| 8 noyaux | = 7,5 | = 93% |
| 16 cœurs | = 13,9 | = 87% |
| 32 coeurs | = 24,4 | = 76% |
| 64 coeurs | = 39,3 | = 61% |
Pour une requête complètement thermonucléaire, qui dure naturellement des heures, et les travaux préparatoires et l'assemblage du résultat prennent très peu de temps (série = 0,001), on verra déjà une bonne efficacité:
| 8 noyaux | = 7,94 | = 99% |
| 16 cœurs | = 15,76 | = 99% |
| 32 coeurs | = 31,04 | = 97% |
| 64 coeurs | = 60,20 | = 94% |
Veuillez noter que
nous ne verrons jamais 100% . Dans des cas particulièrement bons, vous pouvez voir, par exemple, 99,999%, mais pas exactement 100%.
Comment mélanger et casser en N fois?
Vous pouvez mélanger et casser exactement N fois:
- Envoyez les demandes docs00 ... docs15 de manière séquentielle , pas en parallèle.
- Dans les requêtes simples, ne sélectionnez pas par clé , O something quelque chose = 234.
Dans ce cas, la partie sérialisée (série) occupe non pas 1% et non 5%, mais environ 20% dans les bases de données modernes. Vous pouvez obtenir 50% de la partie sérialisée si vous accédez à la base de données à l'aide d'un protocole binaire extrêmement efficace ou si vous la liez en tant que bibliothèque dynamique à un script Python.
Le reste du temps de traitement d'une simple demande sera occupé par des opérations non parallélisées d'analyse de la demande, de préparation du plan, etc. Autrement dit, il ralentit de ne pas lire le dossier.
Si nous divisons les données en 16 tables et les exécutons séquentiellement, comme c'est le cas dans le langage de programmation PHP, par exemple, (il ne sait pas très bien comment exécuter les processus asynchrones), nous obtenons le ralentissement de 16 fois. Et peut-être même davantage, car des allers-retours sur le réseau seront également ajoutés.
Du coup lors du sharding, le choix d'un langage de programmation est important.
Nous nous souvenons du choix d'un langage de programmation, car si vous envoyez des requêtes à la base de données (ou au serveur de recherche) séquentiellement, d'où vient l'accélération? Au contraire, un ralentissement apparaîtra.
Vélo de la vie
Si vous choisissez C ++,
écrivez dans les threads POSIX , pas Boost I / O. J'ai vu une excellente bibliothèque de développeurs expérimentés d'Oracle et MySQL lui-même, qui ont écrit la communication avec le serveur MySQL sur Boost. Apparemment, ils ont été forcés d'écrire en C pur au travail, mais ils ont ensuite réussi à faire demi-tour, à prendre Boost avec des E / S asynchrones, etc. Un problème - cette E / S asynchrone, qui théoriquement aurait dû conduire 10 demandes en parallèle, pour une raison quelconque, avait un point de synchronisation invisible à l'intérieur. Lors du démarrage de 10 requêtes en parallèle, elles ont été exécutées exactement 20 fois plus lentement qu'une, car 10 fois pour les requêtes elles-mêmes et une fois pour le point de synchronisation.
Conclusion: écrivez dans des langages qui implémentent l'exécution parallèle et attendent bien les différentes requêtes. Pour être honnête, je ne sais pas exactement quoi conseiller à part Go. Non seulement parce que j'aime vraiment Go, mais parce que je ne sais rien de mieux.
N'écrivez pas dans des langues inappropriées dans lesquelles vous ne pouvez pas exécuter 20 requêtes parallèles dans la base de données. Ou à chaque occasion, ne faites pas tout avec vos mains - comprenez comment cela fonctionne, mais ne le faites pas manuellement.
Vélo d'essai A / B
Parfois, vous pouvez ralentir parce que vous êtes habitué au fait que tout fonctionne et que vous n’avez pas remarqué que la partie sérialisée, premièrement, est, deuxièmement, une grosse.
- Immédiatement ~ 60 fragments d'index de recherche, catégories
- Ce sont des fragments corrects et corrects, sous un domaine.
- Il y avait jusqu'à 1 000 documents et 50 000 documents.
Il s'agit d'un vélo de production, lorsque les requêtes de recherche ont été légèrement modifiées et ils ont commencé à sélectionner beaucoup plus de documents parmi 60 fragments de l'index de recherche. Tout a fonctionné rapidement et sur le principe: "ça marche - ne le touchez pas", ils l'ont tous oublié, ce qui est en fait à l'intérieur de 60 éclats. Nous avons augmenté la limite d'échantillonnage pour chaque fragment de mille à 50 000 documents. Soudain, il a commencé à ralentir et le parallélisme a cessé. Les demandes elles-mêmes, qui ont été exécutées en fonction des tessons, ont plutôt bien volé et l'étape a été ralentie lorsque 50 000 documents ont été collectés auprès de 60 tessons. Ces 3 millions de documents finaux sur un core ont fusionné, triés, le top 3 millions a été sélectionné et remis au client. La même partie en série a ralenti, la même loi impitoyable d'Amdal a fonctionné.
Alors peut-être que tu ne devrais pas faire du sharding avec tes mains, mais juste humainement
dites à la base de données: "Faites-le!"
Avertissement: je ne sais pas vraiment comment faire quelque chose de bien. Je suis du mauvais étage !!!
J'ai fait la promotion d'une religion appelée «fondamentalisme algorithmique» tout au long de ma vie consciente. Il est brièvement formulé très simplement:
Vous ne voulez vraiment rien faire avec vos mains, mais il est extrêmement utile de savoir comment cela est organisé à l'intérieur. De sorte qu'au moment où quelque chose ne va pas dans la base de données, vous comprenez au moins ce qui s'est mal passé là-bas, comment il est organisé à l'intérieur et à peu près comment il peut être réparé.
Examinons les options:
- "Mains . " Plus tôt, nous avons fragmenté manuellement les données en 16 tables virtuelles et réécrit toutes les requêtes avec nos mains - c'est extrêmement inconfortable à faire. S'il est possible de ne pas mélanger les mains - ne mélangez pas les mains! Mais parfois, ce n'est pas possible, par exemple, vous avez MySQL 3.23, puis vous devez.
- "Automatique". Il arrive que vous puissiez mélanger automatiquement ou presque automatiquement, lorsque la base de données peut distribuer les données elle-même, il vous suffit d'écrire à peu près quelque part un paramètre spécifique. Il y a beaucoup de bases et elles ont beaucoup de réglages différents. Je suis sûr que dans chaque base de données dans laquelle il est possible d'écrire shards = 16 (quelle que soit la syntaxe), de nombreux autres paramètres sont collés à ce cas par le moteur.
- "Semi-automatique" - un mode complètement cosmique, à mon avis, et brutal. Autrement dit, la base elle-même ne semble pas pouvoir le faire, mais il existe des correctifs supplémentaires externes.
Il est difficile de dire quelque chose sur la machine, sauf pour l'envoyer à la documentation sur la base de données appropriée (MongoDB, Elastic, Cassandra, ... en général, le soi-disant NoSQL). Si vous êtes chanceux, alors vous tirez simplement sur l'interrupteur «faites-moi 16 éclats» et tout fonctionnera. À ce moment, quand cela ne fonctionne pas, le reste de l'article peut être nécessaire.
À propos du dispositif semi-automatique
Dans certains endroits, les technologies de l'information sophistiquées inspirent l'horreur chthonique. Par exemple, MySQL prêt à l'emploi n'avait aucune implémentation de partitionnement vers certaines versions, bien sûr, néanmoins, la taille des bases utilisées au combat atteignait des valeurs indécentes.
La souffrance de l'humanité face aux administrateurs de base de données individuels est tourmentée depuis des années et écrit plusieurs mauvaises solutions de partitionnement conçues sans raison. Après cela, une solution de sharding plus ou moins décente est écrite appelée ProxySQL (MariaDB / Spider, PG / pg_shard / Citus, ...). Ceci est un exemple bien connu de ce même manteau.
ProxySQL dans son ensemble, bien sûr, est une solution complète de classe entreprise pour l'open source, pour le routage et plus encore. Mais l'une des tâches à résoudre est le partitionnement d'une base de données, qui en elle-même ne sait pas comment fragmenter humainement. Vous voyez, il n'y a pas de commutateur «shards = 16», soit vous devez réécrire chaque demande dans l'application, et il y en a beaucoup, soit mettre une couche intermédiaire entre l'application et la base de données qui ressemble à: «Hmm ... SELECT * FROM documents? Oui, il doit être déchiré en 16 petits SELECT * FROM server1.document1, SELECT * FROM server2.document2 - à ce serveur avec ce nom d'utilisateur / mot de passe, à ceci avec un autre. Si on ne répond pas, alors ... "etc.
Cela peut être fait exactement par des correctifs intermédiaires. Ils sont légèrement inférieurs à ceux de toutes les bases de données. Pour PostgreSQL, si je comprends bien, il existe des solutions intégrées en même temps (PostgresForeign Data Wrappers, à mon avis, est intégré à PostgreSQL lui-même), il existe des correctifs externes.
La configuration de chaque correctif spécifique est un sujet géant distinct qui ne rentrera pas dans un seul rapport, nous ne discuterons donc que des concepts de base.
Mieux vaut parler un peu de la théorie du buzz.
Une automatisation parfaite absolue?
Toute la théorie du buzz dans le cas du sharding dans cette lettre F (), le principe de base est
toujours le même brut:
shard_id = F(object).Le sharding, c'est généralement quoi? Nous avons 2 milliards d'enregistrements (ou 64). Nous voulons les diviser en plusieurs morceaux. Une question inattendue se pose - comment? Selon quel principe dois-je répartir mes 2 milliards d'enregistrements (ou 64) sur 16 serveurs à ma disposition?
Le mathématicien latent en nous devrait suggérer qu'à la fin il y a toujours une certaine fonction magique qui, pour chaque document (objet, ligne, etc.), déterminera dans quelle pièce le mettre.
Si nous approfondissons les mathématiques, cette fonction dépend toujours non seulement de l'objet lui-même (la ligne elle-même), mais également de paramètres externes tels que le nombre total de fragments. La fonction, qui pour chaque objet doit indiquer où la placer, ne peut pas renvoyer une valeur de plus qu'il n'y a de serveurs sur le système. Et les fonctions sont un peu différentes:
- shard_func = F1 (objet);
- shard_id = F2 (shard_func, ...);
- shard_id = F2 ( F1 (objet), current_num_shards, ...).
Mais plus loin nous ne creuserons pas dans ces jungles de fonctions individuelles, nous parlons juste de ce que sont les fonctions magiques F ().
Que sont F ()?
Ils peuvent proposer de nombreux mécanismes de mise en œuvre différents et très différents. Exemple de résumé:
- F = rand ()% nums_shards
- F = somehash ( object.id )% num_shards
- F = object.date% num_shards
- F = object.user_id% num_shards
- ...
- F = shard_table [somehash () | ... object.date | ...]
Un fait intéressant - vous pouvez naturellement disperser toutes les données au hasard - nous jetons l'enregistrement suivant sur un serveur arbitraire, sur un noyau arbitraire, dans une table arbitraire. Il n'y aura pas beaucoup de bonheur, mais cela fonctionnera.
Il existe des méthodes légèrement plus intelligentes d'escroquerie pour des fonctions de hachage reproductibles ou même cohérentes, ou d'escroquerie pour certains attributs. Passons en revue chaque méthode.
F = rand ()
La dispersion n'est pas une méthode très correcte. Un problème: nous avons dispersé nos 2 milliards d'enregistrements pour mille serveurs au hasard, et nous ne savons pas où se trouve l'enregistrement. Nous devons extraire user_1, mais nous ne savons pas où il se trouve. Nous allons sur un millier de serveurs et trions tout - d'une manière ou d'une autre, c'est inefficace.
F = somehash ()
Répartissons les utilisateurs de manière adulte: lisez la fonction de hachage reproduite de user_id, prenez le reste de la division par le nombre de serveurs et contactez immédiatement le serveur souhaité.
Pourquoi on fait ça? Et puis, nous avons une charge élevée et nous n'introduisons rien dans un seul serveur. Si elle s'entremêlait, la vie serait si simple.Eh bien, la situation s'est déjà améliorée, pour obtenir un enregistrement, nous allons sur un serveur bien connu. Mais si nous avons une plage de clés, dans toute cette plage, nous devons trier toutes les valeurs de clé et, dans la limite, aller soit à autant de fragments que nous avons de clés dans la plage, soit à chaque serveur en général. Bien sûr, la situation s'est améliorée, mais pas pour toutes les demandes. Certaines demandes ont été affectées.
Partage naturel (F = object.date% num_shards)
Parfois, c'est souvent 95% du trafic et 95% de la charge sont des demandes qui ont une sorte de partage naturel. , 95% - 1 , 3 , 7 , 5% . 95% , , , .
, , , - .
— , . , , , , . 5 % .
, :
- , 95% .
- 95% , , . , . , .
, — , - .
, , , , . « - ».
«». , .
1. :
, , .
, / , , , PM ( , PM ), . .
, . , , 100 . .
, , , , - .
2. «» : , join
, ?
- «» … WHERE randcol BETWEEN aaa AND bbb?
- «» … users_32shards JOIN posts_1024 shards?
: , !
, , , . . (, , document store ), , .
—
- . . , . , , , . - , , , , — .
, .
3. / :
: , .
, .
, , , . , , , 10 , - 30, 100 . . — , - — , - .
, : 16 -, 32. , 17, 23 — . , , - ?
: , , .
, «», « ».
#1.
- NewF(object), .
- NewF()=OldF() .
- .
- Ouch.
, 2 , , . : 17 , 6 , 2 , 17 23 . 10 , , . .
#2.
— — 17 23, 16 32 ! , .
- NewF(object), .
- 2^N, 2^(N+1) .
- NewF()=OldF() 0,5.
- 50% .
- , .
, , . , , .
, . , 16 16, — .
, — .
#3. Consistent hashing
, consistent hashing
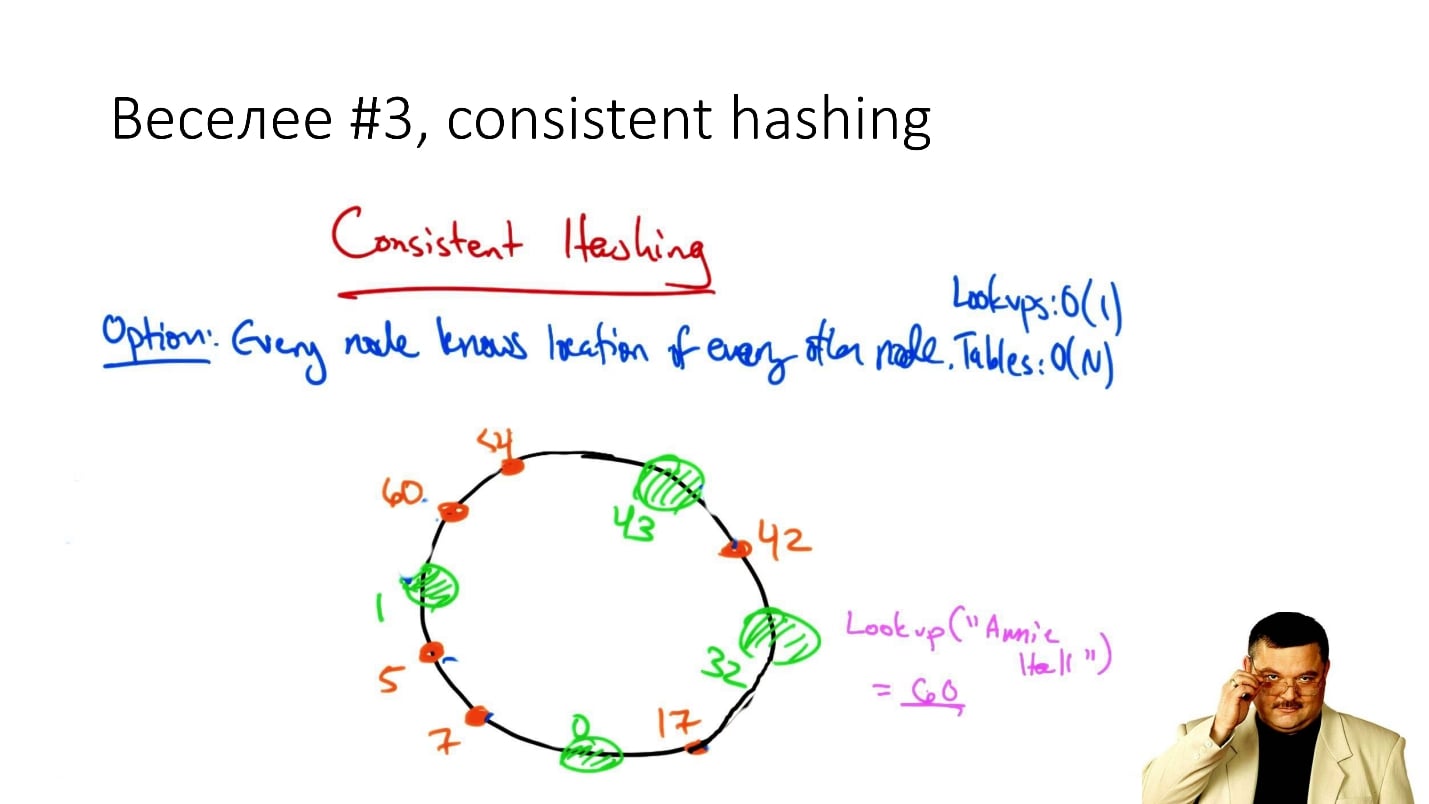
«consistent hashing», , .
: () , . , , , ( , ), .
, . , , , : , .
. , . , .., . , - , , .
, , , Cassandra . , , , , , .
, — / , , .
, : ? ? — , !
#4. Rendezvous/HRW
( , ):
shard_id = arg max hash(object_id, shard_id).Rendezvous hashing, , , Highest Random Weight. :
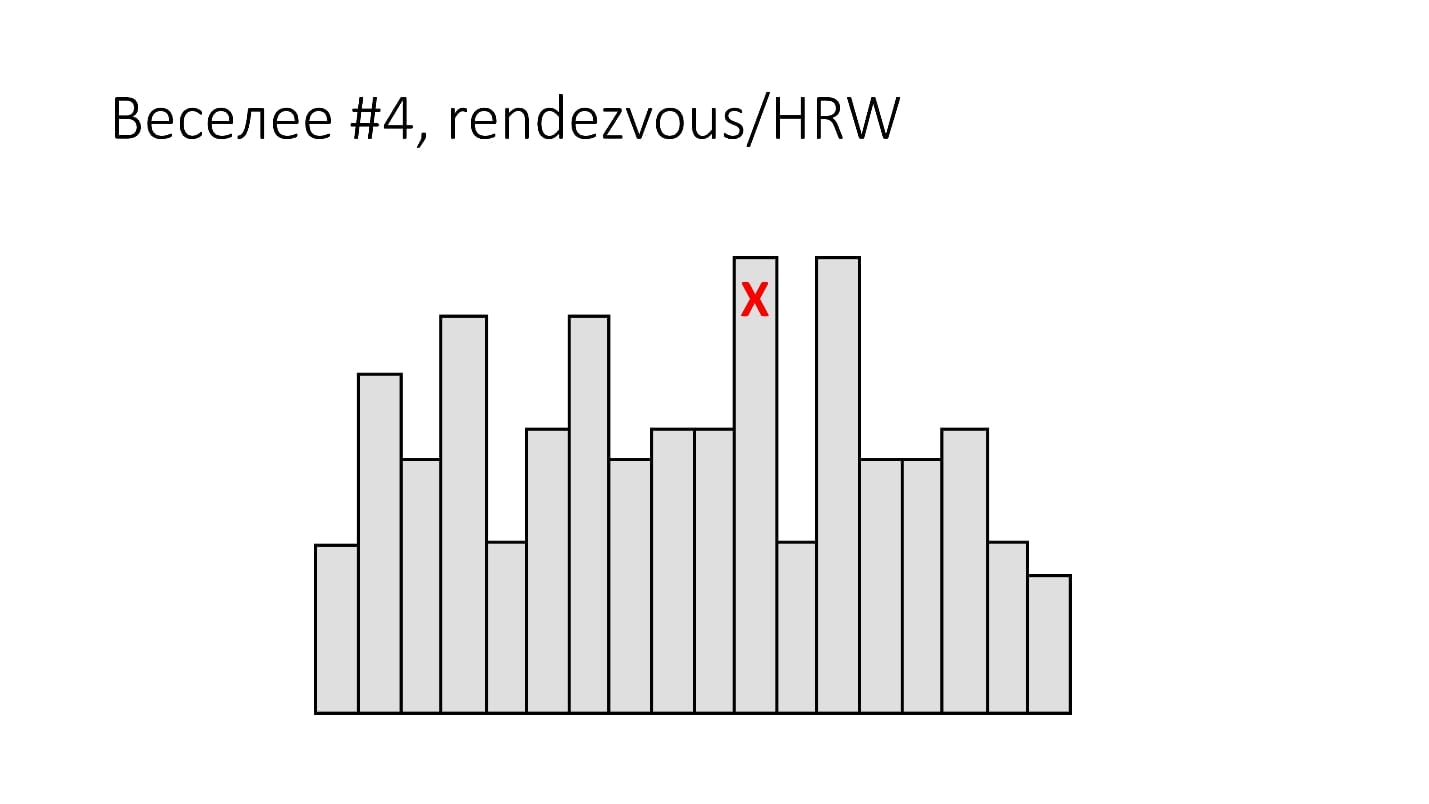
, , 16 . (), - , 16 , . -, .
HRW-hashing, Rendezvous hashing. , -, , .
, . , - - . .
, .
#5.
, Google - :
- Jump Hash — Google '2014.
- Multi Probe —Google '2015.
- Maglev — Google '2016.
, . , , , -, . .
#6.
— . ? , 2 , object_id 2 , .
, ? ?
. , - , , . , , , , .
:
- 1 .
- / / / : min/max_id => shard_id.
- 8 4 (4 !) — 20 .
- - , 20 — .
- 20 — .
2 - 16 — 100 - . : , , — 1 . , , .
, , , - , .
Conclusions
: « , !». , 20 .
, , . ,
— . 100$ , . -, . — .
, , «» (, DFS, ...) . , , highload - . , , - . —
, .
F() , , , .. , , 2
.
, , .
HighLoad++ , , —Sphinx—highload , .
Highload User Group. , .
, ,
HighLoad++ . , , . , , .
highload-, .
, , , . , , , .
24 - «», « ». , . ,
.
, , 8 9 - HighLoad++ early bird .