Institut de technologie du Massachusetts. Cours magistral # 6.858. "Sécurité des systèmes informatiques." Nikolai Zeldovich, James Mickens. 2014 année
Computer Systems Security est un cours sur le développement et la mise en œuvre de systèmes informatiques sécurisés. Les conférences couvrent les modèles de menace, les attaques qui compromettent la sécurité et les techniques de sécurité basées sur des travaux scientifiques récents. Les sujets incluent la sécurité du système d'exploitation (OS), les fonctionnalités, la gestion du flux d'informations, la sécurité des langues, les protocoles réseau, la sécurité matérielle et la sécurité des applications Web.
Cours 1: «Introduction: modèles de menace»
Partie 1 /
Partie 2 /
Partie 3Conférence 2: «Contrôle des attaques de pirates»
Partie 1 /
Partie 2 /
Partie 3Conférence 3: «Débordements de tampon: exploits et protection»
Partie 1 /
Partie 2 /
Partie 3Conférence 4: «Séparation des privilèges»
Partie 1 /
Partie 2 /
Partie 3Conférence 5: «D'où viennent les systèmes de sécurité?»
Partie 1 /
Partie 2Conférence 6: «Opportunités»
Partie 1 /
Partie 2 /
Partie 3Conférence 7: «Native Client Sandbox»
Partie 1 /
Partie 2 /
Partie 3Conférence 8: «Modèle de sécurité réseau»
Partie 1 /
Partie 2 /
Partie 3Conférence 9: «Sécurité des applications Web»,
partie 1 /
partie 2 /
partie 3Conférence 10: «Exécution symbolique»
Partie 1 /
Partie 2 /
Partie 3Conférence 11: «Ur / Web Programming Language»
Partie 1 /
Partie 2 /
Partie 3Conférence 12: Sécurité du réseau,
partie 1 /
partie 2 /
partie 3Conférence 13: «Protocoles réseau»,
partie 1 /
partie 2 /
partie 3Conférence 14: «SSL et HTTPS»
Partie 1 /
Partie 2 /
Partie 3Conférence 15: «Logiciel médical»
Partie 1 /
Partie 2 /
Partie 3Conférence 16: «Side Channel Attacks»
Partie 1 /
Partie 2 /
Partie 3Conférence 17: «Authentification des utilisateurs»,
partie 1 /
partie 2 /
partie 3Conférence 18: «Navigation privée sur Internet»
Partie 1 /
Partie 2 /
Partie 3Conférence 19: «Réseaux anonymes»
Partie 1 /
Partie 2 /
Partie 3Conférence 20: «Sécurité des téléphones portables»
Partie 1 /
Partie 2 /
Partie 3Conférence 21: «Suivi des données»
Partie 1 /
Partie 2 /
Partie 3 Étudiant: Donc, le support architectural est la solution idéale?
Professeur: oui, il existe aussi des méthodes pour cela. Cependant, c'est un peu compliqué parce que, comme vous pouvez le voir, nous avons mis en évidence l'état de souillure à côté de la variable elle-même. Par conséquent, si vous pensez au support fourni par l'équipement lui-même, il peut être très difficile de modifier la disposition du matériel, car tout est cuit en silicium ici. Mais s'il est possible à un niveau élevé dans la machine virtuelle Dalvic, on peut imaginer qu'il sera possible de placer les variables et leur infection côte à côte au niveau matériel. Donc, si vous changez la disposition en silicium, vous pouvez probablement faire le travail.
 Étudiant:
Étudiant: que fait TaintDroid avec les informations qui s'appuient sur les autorisations de branche git, les autorisations de branche?
Professeur: nous y reviendrons dans une seconde, alors gardez cette pensée jusqu'à ce que nous y arrivions.
Étudiant: Je me demande si des dépassements de tampon peuvent se produire ici, parce que ces choses - les variables et leurs infections - se cumulent?
Professeur: C'est une bonne question. On pourrait espérer que dans un langage comme Java il n'y a pas de débordement de tampon. Mais dans le cas du langage C, quelque chose de catastrophique peut se produire, car si vous avez en quelque sorte fait un débordement de tampon, puis réécrit les balises taint pour les variables, leurs valeurs nulles sont définies dans les piles et les données circulent librement dans le réseau.
Étudiant: Je pense que tout cela peut être prédit?
Professeur: absolument vrai. Le problème des débordements de tampon peut être résolu à l'aide des "canaries" - indicateurs de pile, car si vous avez ces données sur la pile, vous ne voulez pas les faire écraser ou vous ne voulez pas que les valeurs déjà écrasées soient fissurées d'une manière ou d'une autre. Vous avez donc tout à fait raison - vous pouvez simplement empêcher les débordements de tampon.
En bref, le suivi des taches peut être fourni à ce bas niveau x86 / ARM, bien qu'il puisse être un peu cher et un peu difficile à mettre en œuvre de la bonne manière. Vous pouvez vous demander pourquoi nous résolvons tout d'abord le problème du suivi des infections au lieu de surveiller la façon dont le programme essaie d'envoyer quelque chose sur le réseau, simplement en scannant des données qui nous semblent confidentielles. Cela semble assez facile, car nous n'avons alors pas besoin de surveiller dynamiquement tout ce que fait le programme.

Le problème est que cela ne fonctionnera qu'au niveau heuristique. En fait, si un attaquant sait que vous faites exactement cela, il peut facilement vous casser. Si vous restez assis là et essayez de chercher des numéros de sécurité sociale, un attaquant pourrait simplement utiliser le codage base 64 ou faire quelque chose de stupide, comme la compression. Le contournement de ce type de filtre est assez banal, donc en pratique, cela est complètement insuffisant pour assurer la sécurité.
Revenons maintenant à votre question sur la façon dont nous pouvons suivre les flux circulant dans les succursales. Cela nous mènera à un sujet appelé Flux implicites ou Flux implicites. Un flux implicite se produit généralement lorsque vous avez une valeur infectée qui affectera la façon dont vous affectez une autre variable, même si cette variable de flux implicite n'affecte pas de variables directement. Je vais donner un exemple concret.
Supposons que vous ayez une instruction if qui regarde votre IMEI et dit: "si elle est supérieure à 42, alors j'attribuerai x = 0, sinon j'attribuerai x = 1."
Fait intéressant, nous examinons d'abord les données IMEI confidentielles et les comparons avec un certain nombre, mais ensuite, en attribuant x, nous n'affectons rien qui serait obtenu directement à partir de ces données confidentielles.
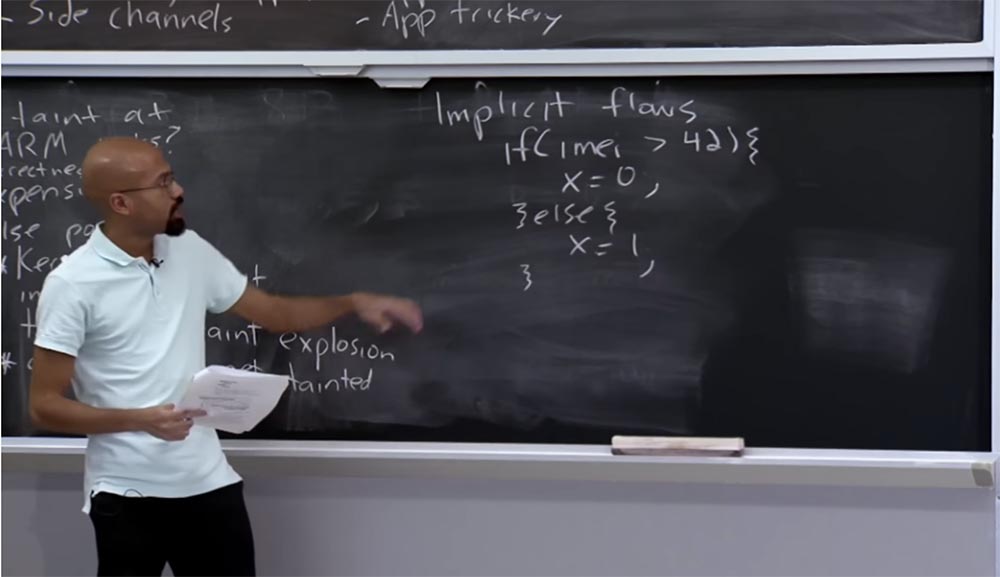
Ceci est un exemple de l'un des threads implicites. La valeur de x dépend vraiment de la comparaison ci-dessus, mais l'adversaire, s'il est intelligent, peut construire son code de telle manière qu'aucune connexion directe ne puisse y être tracée.
Veuillez noter que même ici, au lieu d'affecter simplement x = 0, x = 1, vous pouvez simplement mettre la commande pour envoyer quelque chose sur le réseau, c'est-à-dire que vous pouvez dire sur le réseau que x = 0 ou x = 1, ou quelque chose comme ça. Ceci est un exemple de l'un de ces threads implicites qu'un système comme TaintDroid ne peut pas contrôler. Ainsi, cela s'appelle un flux implicite, par opposition à un flux explicite, par exemple, un opérateur d'affectation. Les développeurs sont donc conscients de ce problème.
Si j'ai bien compris, ils m'ont demandé ce qui se passerait si nous avons une sorte de fonction machine qui fait quelque chose de similaire à l'exemple ci-dessus, et donc le système TaintDroid n'a pas besoin de le savoir, car TaintDroid ne sera pas en mesure d'examiner ce code machine et de voir les choses ce genre. Soit dit en passant, les développeurs affirment qu'ils contrôleront cela en utilisant des méthodes orientées machine qui sont déterminées par la machine virtuelle elle-même et qu'ils examineront la façon dont cette méthode est mise en œuvre. Par exemple, nous prenons ces deux nombres, puis retournons leur valeur moyenne. Dans ce cas, le système TaintDroid se fiera à la fonction de la machine, nous devons donc déterminer quelle doit être la politique d'infection infectieuse appropriée.
Cependant, vous avez raison de dire que si quelque chose comme cela était caché dans le code machine et pour une raison quelconque n'a pas été soumis à une révision ouverte, les politiques manuelles inventées par les auteurs de TaintDroid peuvent ne pas intercepter ce flux implicite. En fait, cela peut permettre aux informations de fuir. De plus, il peut même y avoir un flux direct, que les auteurs de TaintDroid n'ont pas remarqué, et nous pouvons avoir une fuite encore plus directe.
 Étudiant:
Étudiant: c'est-à-dire qu'en pratique cela semble très dangereux, non? Parce que vous pouvez littéralement effacer toutes les valeurs infectées en regardant simplement les 3 dernières lignes.
Professeur: Nous avons eu plusieurs classes qui ont examiné comment les flux implicites font de telles choses. Il existe plusieurs façons de résoudre ce problème. Une façon d'empêcher que cela ne se produise est d'attribuer une balise taint au PC, l'infectant essentiellement avec le test Branch. L'idée est que d'un point de vue humain, nous pouvons considérer ce code et dire que ce flux implicite existe ici, car pour y arriver, nous avons dû creuser dans des données confidentielles.
Alors qu'est-ce que cela signifie au niveau de la mise en œuvre? Cela signifie que pour arriver ici, le PC doit avoir quelque chose qui a été infecté par des données confidentielles. Autrement dit, nous pouvons dire que nous avons reçu ces données parce que le PC a été installé ici - x = 0 - ou ici - x = 1.
En général, on peut imaginer que le système effectuera une analyse et découvrira que les flux implicites PC ne sont pas infectés à cet endroit, puis il détecte l'infection à partir de l'IMEI, et à ce stade où x = 0, le PC est déjà infecté. En fin de compte, ce qui se passe, c'est que si x est une variable qui est initialement affichée sans tache, alors nous disons: "OK, à ce stade x = 0, nous obtenons l'infection du PC, qui a été effectivement infecté ci-dessus, dans IMEI". Il y a quelques subtilités ici, mais en général, vous pouvez suivre la façon dont le PC est installé, puis essayer de propager l'infection aux opérateurs cibles.
Est-ce clair? Si vous voulez en savoir plus, alors nous pouvons parler de ce sujet car j'ai fait beaucoup de recherches de ce genre. Cependant, le système que je viens de décrire peut encore être trop conservateur. Imaginez qu'au lieu de x = 1, ici, comme ci-dessus, nous avons également x = 0. Dans ce cas, cela n'a aucun sens d'infecter x avec quelque chose en rapport avec IMEI, donc aucune information ne peut fuir de ces branches.
Mais si vous utilisez un schéma d'infection PC informatisé, vous pouvez surestimer le nombre de variables x corrompues. Il y a quelques subtilités que vous pouvez faire pour essayer de contourner certains de ces problèmes, mais ce sera un peu difficile.
Élève: lorsque vous quittez l'instruction if, vous quittez également Branch et vous vous débarrassez de l'infection?
Professeur: en règle générale, oui, dès que l'ensemble des variables se termine, le PC sera nettoyé de l'infection. L'infection n'est établie qu'à l'intérieur de ces branches de x à x. La raison en est que lorsque vous descendez ici, vous le faites, quel que soit l'IMEI.
Nous avons parlé de l'utilité du suivi des infections à ce niveau très bas, bien que très coûteux, car il vous permet vraiment de voir quelle est la durée de vie de vos données. Il y a quelques conférences, nous avons parlé du fait que, souvent, les données clés vivent en mémoire beaucoup plus longtemps que vous ne le pensez.
Vous pouvez imaginer que bien que le suivi des infections x86 ou ARM soit assez coûteux, vous pouvez l'utiliser pour auditer votre système. Par exemple, vous pouvez infecter une clé secrète qu'un utilisateur a entrée et voir où et comment elle se déplace dans le système. Il s'agit d'une analyse hors ligne, elle n'affecte pas les utilisateurs, il est donc normal qu'elle soit lente. Une telle analyse aidera à découvrir, par exemple, que ces données tombent dans la mémoire tampon du clavier, ceci vers un serveur externe, ceci ailleurs. Ainsi, même s'il s'agit d'un processus lent, il peut toujours être très utile.
Comme je l'ai dit, une caractéristique utile de TaintDroid est qu'il limite «l'univers» des sources d'infection et des absorbeurs d'informations infectées. Mais en tant que développeur, vous voulez probablement avoir un contrôle plus précis sur les marques d'infection avec lesquelles votre programme interagit. Par conséquent, en tant que programmeur, vous souhaiterez effectuer les opérations suivantes.
Ainsi, vous déclarez un entier de ce type et l'appelez X, puis lui liez une étiquette. La signification de cette étiquette est qu'Alice est propriétaire des informations qu'elle permet à Bob de visualiser, ou que ces informations sont marquées pour être consultées par Bob. TaintDroid ne vous permet pas de le faire, car il contrôle essentiellement cet univers d'étiquettes, mais en tant que programmeur, vous voudrez peut-être le faire.
Supposons que votre programme dispose de canaux d'entrée et de sortie et qu'ils soient également étiquetés. Ce sont les étiquettes que vous avez choisies en tant que programmeur, contrairement au système lui-même, en essayant de dire que de telles choses sont prédéterminées à l'avance. Dites pour les canaux d'entrée que vous définissez des valeurs de lecture qui obtiennent l'étiquette de canal.
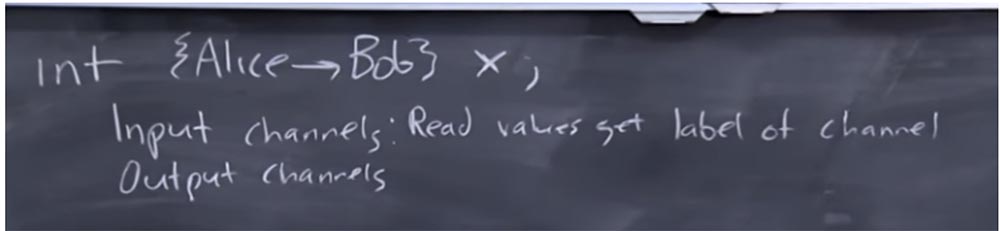
Ceci est très similaire à la façon dont TaintDroid fonctionne - si les valeurs du capteur GPS sont lues, elles sont marquées avec la balise taint du canal GPS, mais maintenant, en tant que programmeur, vous sélectionnez vous-même ces étiquettes. Dans ce cas, l'étiquette du canal de sortie doit correspondre à la valeur d'étiquette que nous avons enregistrée.

D'autres politiques peuvent être introduites ici, mais l'idée principale est qu'il existe des gestionnaires de programme qui laissent le développeur choisir le type d'étiquettes et quelle pourrait être leur sémantique. Cela nécessitera beaucoup de travail de la part du programmeur, dont le résultat sera la capacité d'effectuer une vérification statique. Par statique, je veux dire une vérification qui est effectuée au moment de la compilation et qui peut "détecter" de nombreux types d'erreurs de flux d'informations.
Donc, si vous étiquetez soigneusement tous les canaux du réseau et les canaux d'écran avec des étiquettes avec les autorisations appropriées, puis placez soigneusement vos données, qui sont données à titre d'exemple sur la carte, alors pendant la compilation, le compilateur pourra vous dire: «Hé, si vous exécutez ce programme, vous risquez alors de subir une fuite d'informations car une partie des données passera par un canal non fiable. »
À un niveau élevé, une vérification statique peut détecter bon nombre de ces erreurs, car de tels commentaires int {Alice Bob} x sont un peu comme des types. Tout comme les compilateurs peuvent détecter les erreurs liées aux types dans un langage de type, ils peuvent tout aussi bien fonctionner avec du code écrit dans le langage ci-dessus, en disant que si vous exécutez ce programme, cela peut être un problème. Par conséquent, vous devez corriger le fonctionnement des étiquettes, vous devrez peut-être déclassifier quelque chose, etc.
Ainsi, selon la langue, ces étiquettes peuvent être associées à des personnes, à des ports d'E / S, etc. TaintDroid vous donne la possibilité de vous familiariser avec les principes de fonctionnement des flux d'informations et des fuites d'informations, cependant, il existe des systèmes plus complexes avec une sémantique plus prononcée pour gérer ces processus.
Gardez à l'esprit que lorsque nous parlons de vérification statique, il est préférable pour nous de détecter autant d'échecs et d'erreurs que possible à l'aide de la vérification statistique, plutôt que de la vérification dynamique. Il y a une raison très délicate à cela. Supposons que nous reportions tous les contrôles statiques pendant la durée d'un programme, ce que nous pouvons certainement faire.
Le problème est que l'échec ou le succès de ces vérifications est un canal implicite. Ainsi, un attaquant peut fournir des informations au programme, puis vérifier si cela a provoqué un plantage du programme. Si un échec se produit, le pirate peut dire: "Oui, nous avons effectué une vérification dynamique du flux d'informations, il y a donc ici un secret concernant les valeurs qui affectent le processus de calcul." Par conséquent, vous souhaiterez essayer de rendre ces vérifications aussi statiques que possible.
Si vous voulez plus d'informations sur ces choses, vous devriez consulter Jif. Il s'agit d'un système très puissant qui a créé des étiquettes de méthodes de calcul d'étiquettes. Vous pouvez commencer par cela et continuer dans cette direction. Mon collègue, le professeur Zeldovich, a fait beaucoup de bien dans ce domaine, vous pouvez donc lui parler de ce sujet.
Fait intéressant, TaintDroid est très limité dans sa capacité à afficher et à décrire les balises. Il existe des systèmes qui vous permettent de faire des choses plus puissantes.
Enfin, je voudrais parler de ce que nous pouvons faire si nous voulons suivre les flux d'informations à l'aide de programmes traditionnels ou à l'aide de programmes écrits en C ou C ++ qui ne prennent pas en charge toutes ces choses dans le processus d'exécution de code. Il existe un système TightLip très raisonnable, et certains des auteurs du même article envisagent comment suivre les fuites d'informations dans un système dans lequel nous ne voulons rien changer dans l'application elle-même.
L'idée de base est que le concept de processus doppelganger, ou "homologues de processus", est utilisé ici. TightLip utilise un processus double par défaut. La première chose qu'elle fait est d'analyser périodiquement le système de fichiers de l'utilisateur, à la recherche de types de fichiers confidentiels. Il peut s'agir de fichiers e-mail, de documents texte, etc. Pour chacun de ces fichiers, le système crée sa version «nettoyée». C'est-à-dire que dans le fichier des messages électroniques, il remplace les informations «à» ou «à partir de» par une chaîne de même longueur contenant des données factices, par exemple des espaces. Cela fonctionne comme un processus d'arrière-plan.
La deuxième chose que TightLip fait au démarrage d'un processus consiste à déterminer si le processus tente d'accéder à un fichier confidentiel. Si un tel accès a lieu, TightLip crée un double de ce processus. Ce double ressemble exactement au processus d'origine, qui essaie d'affecter les données sensibles, mais la différence fondamentale est que le double, je vais le désigner DG, lit les données effacées.

Imaginez que vous tentiez d'accéder à votre fichier e-mail. Le système génère ce nouveau processus, doppelganger, exactement le même que l'original, mais maintenant il lit les données nettoyées au lieu des données sensibles réelles. Essentiellement, TightLip exécute ces deux processus en parallèle et les observe pour voir ce qu'ils font. , , , . , , - , , – , , , -, .

, , TightLip , . , . , , , , . , TaintDroid, , : «, , , , - ».
, , , - . TaintDroid, , - , . — , — . , , , , , .
: , - Word, , - .
: , . , . . Word. - , - , . .
: , , ? - .
: , . , , , - , . , . «» , , , .
, , , , , , , .

– , TightLip TCB, , -, . , . . , , . TightLip.
, . taint .
: , ? , ?
: ! - DG , , . , , , -, , .
, .
.
Merci de rester avec nous. Aimez-vous nos articles? Vous voulez voir des matériaux plus intéressants? Soutenez-nous en passant une commande ou en le recommandant à vos amis, une
réduction de 30% pour les utilisateurs Habr sur un analogue unique de serveurs d'entrée de gamme que nous avons inventés pour vous: Toute la vérité sur VPS (KVM) E5-2650 v4 (6 cœurs) 10 Go DDR4 240 Go SSD 1 Gbps à partir de 20 $ ou comment diviser le serveur? (les options sont disponibles avec RAID1 et RAID10, jusqu'à 24 cœurs et jusqu'à 40 Go de DDR4).
VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps ,
.
Dell R730xd 2 fois moins cher? Nous avons seulement
2 x Intel Dodeca-Core Xeon E5-2650v4 128 Go DDR4 6x480 Go SSD 1 Gbps 100 TV à partir de 249 $ aux Pays-Bas et aux États-Unis! Pour en savoir plus sur la
création d'un bâtiment d'infrastructure. classe utilisant des serveurs Dell R730xd E5-2650 v4 coûtant 9 000 euros pour un sou?