Remarque perev. : Cet article poursuit la série de documents sur le dispositif de base des réseaux dans Kubernetes, qui est décrit sous une forme accessible et avec des illustrations illustratives (cependant, il n'y avait pratiquement aucune illustration dans cette partie du béton pour le moment). En traduisant les deux parties précédentes de cette série, nous les avons combinées en une seule publication , qui parlait du modèle de réseau K8s (interaction au sein des nœuds et entre les nœuds) et des réseaux de superposition. Sa lecture préliminaire est souhaitable (recommandée par l'auteur lui-même). La suite est consacrée aux services Kubernetes et au traitement du trafic sortant et entrant.
NB : Pour la commodité de l'auteur, le texte de l'auteur est complété par des liens (principalement vers la documentation officielle des K8).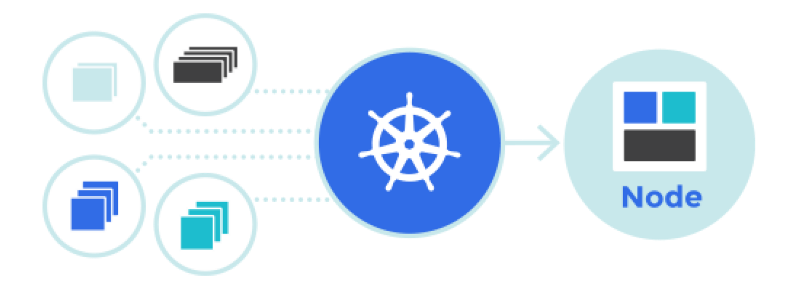
Dynamique des clusters
En raison de la nature dynamique et en constante évolution de Kubernetes et des systèmes distribués en général, les pods (et, par conséquent, leurs adresses IP) sont également en constante évolution. Les raisons de cela varient des mises à jour entrantes pour atteindre l'état et les événements souhaités conduisant à la mise à l'échelle, aux plantages imprévus du pod ou du nœud. Par conséquent, les adresses IP du pod ne peuvent pas être utilisées directement pour la communication.
Le
service dans Kubernetes entre en jeu - une IP virtuelle avec un groupe d'adresses IP de pod qui sont utilisées comme points de terminaison et identifiées par des
sélecteurs d'étiquettes . Un tel service fonctionne comme un équilibreur de charge virtuel, dont l'adresse IP reste constante, et en même temps, les adresses IP du pod qu'il présente peuvent changer en permanence.
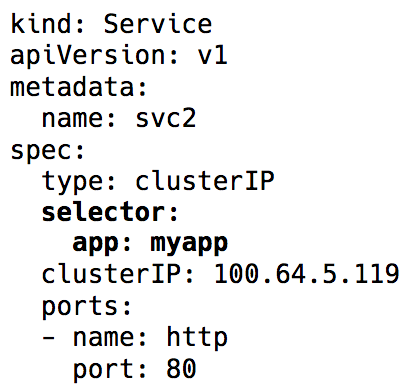 Sélecteur d'étiquette dans l'objet Service dans Kubernetes
Sélecteur d'étiquette dans l'objet Service dans KubernetesDerrière l'implémentation complète de cette IP virtuelle se trouvent des règles iptables (les dernières versions de Kubernetes ont également
la possibilité d' utiliser IPVS, mais c'est un sujet pour une autre discussion), qui sont contrôlées par un composant Kubernetes appelé
kube-proxy . Cependant, un tel nom est trompeur dans les réalités d'aujourd'hui. Kube-proxy était vraiment utilisé comme proxy dans les jours précédant la sortie de Kubernetes v1.0, mais cela a conduit à une grande consommation de ressources et de freins en raison des opérations de copie constantes entre l'espace du noyau et l'espace utilisateur. Maintenant, c'est juste un contrôleur - comme beaucoup d'autres contrôleurs dans Kubernetes. Il surveille le serveur API pour les modifications des points de terminaison et met à jour les règles iptables en conséquence.
Selon ces règles iptables, si le paquet est destiné à l'adresse IP du service, une traduction d'adresse réseau de destination (DNAT) est effectuée pour lui: cela signifie que son adresse IP passera de l'IP du service à l'un des points de terminaison, c'est-à-dire l'une des adresses IP du pod, que iptables sélectionne au hasard. Cela garantit que la charge est uniformément répartie entre les pods.
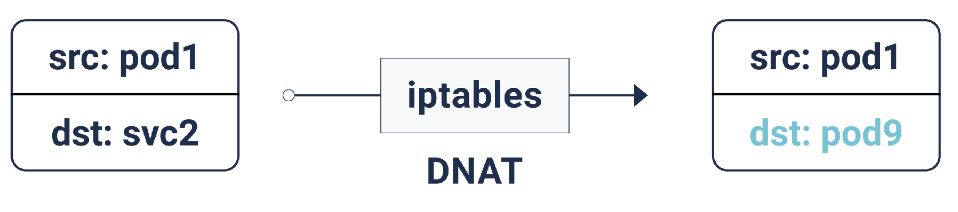 DNAT dans iptables
DNAT dans iptablesDans le cas d'un tel DNAT, les informations nécessaires sont stockées dans
conntrack - la table de comptabilité des connexions sous Linux (il stocke les traductions à cinq paires faites par iptables:
protocol ,
srcIP ,
srcPort ,
dstIP ,
dstPort ). Tout est organisé de telle manière que lorsqu'une réponse est renvoyée, une opération DNAT inverse (non-DNAT) peut se produire, c'est-à-dire Remplacement de la source IP du Pod IP au Service IP. Grâce à ce client, il n'est absolument pas nécessaire de savoir comment travailler avec les packages en arrière-plan.
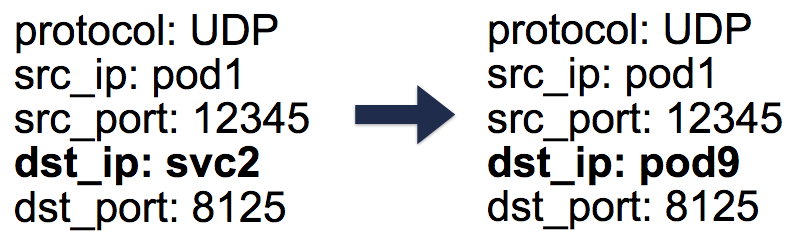 Entrées à cinq paires (5 tuples) dans la table conntrack
Entrées à cinq paires (5 tuples) dans la table conntrackAinsi, en utilisant les services Kubernetes, nous pouvons travailler avec les mêmes ports sans aucun conflit (car la réaffectation des ports aux points de terminaison est possible). Cela rend la découverte de services très facile. Il suffit d'utiliser le DNS interne et de coder en dur l'hôte des services. Vous pouvez même utiliser les variables préconfigurées de Kubernetes avec l'hôte et le port de service.
Astuce : En choisissant le deuxième chemin, vous économisez beaucoup d'appels DNS inutiles!
Trafic sortant
Les services Kubernetes décrits ci-dessus fonctionnent au sein d'un cluster. Dans la pratique, les applications ont généralement besoin d'accéder à certains API / sites externes.
En général, les hôtes peuvent avoir des adresses IP privées et publiques. Pour accéder à Internet, un NAT individuel est fourni pour ces adresses IP privées et publiques - ceci est particulièrement vrai pour les environnements cloud.
Pour une interaction normale de l'hôte avec l'adresse IP externe, l'IP source passe de l'IP hôte privé à l'IP publique pour les paquets sortants et pour les paquets entrants - dans la direction opposée. Cependant, dans les cas où la connexion à l'IP externe est initiée par le pod, l'adresse IP source est l'IP du pod, que le mécanisme NAT du fournisseur de cloud ne connaît pas. Par conséquent, il supprimera simplement les paquets avec des adresses IP source différentes des adresses IP hôtes.
Et ici, vous l'aurez deviné, nous aurons encore plus besoin d'iptables! Cette fois, les règles, qui sont également ajoutées par kube-proxy, sont exécutées par SNAT (Source Network Address Translation), alias
IP MASQUERADE (masquerading). Au lieu de l'adresse IP source, le noyau est invité à utiliser l'interface IP à partir de laquelle le paquet arrive. Une entrée apparaît dans conntrack pour poursuivre l'opération inverse (non-SNAT) sur la réponse.
Trafic entrant
Jusqu'à présent, tout allait bien. Les pods peuvent communiquer entre eux et avec Internet. Cependant, il nous manque toujours l'essentiel - servir le trafic des utilisateurs. Il existe actuellement deux façons de le mettre en œuvre:
1. NodePort / Cloud Load Balancer (niveau L4: IP et port)
La définition de
NodePort comme type de service affectera le service
NodePort dans une plage de 30 000 à
NodePort 000. Ce
nodePort ouvert sur chaque nœud, même si aucun pod n'est en cours d'exécution sur le nœud. Le trafic entrant sur ce
NodePort envoyé à l'un des pods (qui peuvent même apparaître sur un autre nœud!), Toujours en utilisant iptables.
Le type de service
LoadBalancer dans les environnements cloud crée un équilibreur de charge cloud (par exemple, ELB) en face de tous les nœuds, fonctionnant plus loin avec le même
NodePort .
2. Entrée (niveau L7: HTTP / TCP)
De nombreuses autres implémentations effectuent également le mappage hôte / chemin HTTP avec les backends correspondants - par exemple, nginx, traefik, HAProxy, etc. Avec eux, le LoadBalancer et le NodePort redeviennent le point d'entrée pour le trafic, mais il y a l'avantage ici que nous n'avons besoin que d'une seule entrée pour servir le trafic entrant de tous les services au lieu de nombreux NodePort / LoadBalancers.
Stratégies réseau
Les stratégies réseau peuvent être considérées comme des groupes de sécurité / ACL pour les pods.
NetworkPolicy règles
NetworkPolicy autorisent / refusent le trafic entre les pods. Leur implémentation exacte dépend de la couche réseau / CNI, mais la plupart d'entre eux utilisent simplement iptables.
...
C’est tout. Dans les
tranches précédentes, nous avons appris les bases de la mise en réseau dans Kubernetes et le fonctionnement des superpositions. Nous savons maintenant comment l'abstraction du service aide dans un cluster dynamique et rend la découverte des services très simple. Nous avons également examiné comment le trafic sortant / entrant circule et quelles stratégies réseau peuvent être utiles pour sécuriser un cluster.
PS du traducteur
Lisez aussi dans notre blog: