
Nous nous efforçons de nous assurer qu'après avoir commandé un taxi à l'utilisateur, une voiture propre et en bon état de marche de la marque, de la couleur et du numéro qui apparaît dans l'application viendra à l'utilisateur. Et pour cela, nous utilisons le contrôle qualité à distance (DCC).
Aujourd'hui, je vais expliquer aux lecteurs de Habr comment utiliser l'apprentissage automatique pour réduire le coût du contrôle qualité dans un service en croissance rapide avec des centaines de milliers de machines et ne pas mettre en ligne une machine qui ne respecte pas les règles du service.
Comment DCC a-t-il été organisé avant l'apprentissage automatique
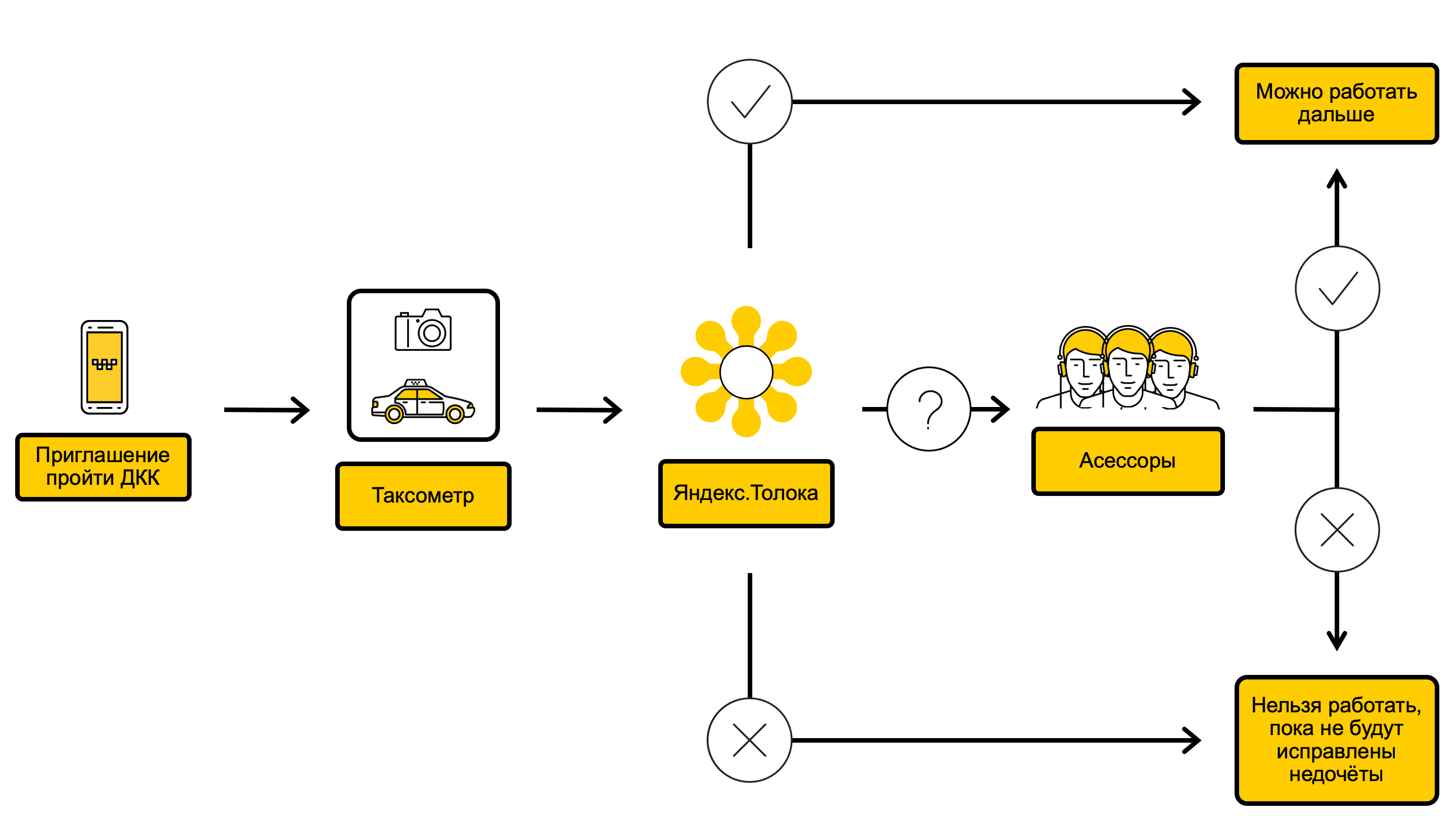
Diagramme de processus DCC
Dans le processus de DCC, nous vérifions les photos de la voiture et décidons s'il est possible d'exécuter les commandes sur une telle voiture ou, par exemple, elle doit être lavée avant. Tout commence par le fait que via l'application pilote Taximeter, nous appelons le conducteur sur le DCC. Cela se produit généralement une fois tous les 10 jours, mais parfois moins souvent ou plus souvent - selon la réussite du conducteur aux contrôles précédents. Immédiatement après un appel au DCC, le conducteur reçoit un message l'invitant à subir un photocontrôle. Dès que le conducteur a accepté l'invitation, dans la même application, il photographie l'extérieur et l'intérieur de la voiture sous différents angles et envoie des photos à Yandex.Taxi. Le conducteur peut prendre les commandes pendant que le DCC est allumé.

Écran de démarrage DCC dans l'application Taximeter

Écran pour photographier une voiture dans l'application Taximètre
Les photos résultantes tombent dans Yandex.Toloka - un service dans lequel, en utilisant le crowdsourcing, vous pouvez effectuer rapidement des tâches simples mais volumineuses. Sur la façon dont cela fonctionne et pourquoi Yandex.Tolok est nécessaire, nous avons écrit sur notre blog .
Dans Yandex.Tolok, au cours d'un contrôle, au moins trois artistes interprètes ou exécutants répondent à des questions sur l'état de la voiture, et si les artistes interprètes ou exécutants sont d'accord sur la base de leurs réponses, une décision est prise quant à savoir si le conducteur peut accepter des commandes. Les contrôles dans Yandex.Tolok ont deux résultats:
- Si tout va bien visuellement avec la voiture, le conducteur continue de prendre les commandes.
- Si la voiture est sale, endommagée ou si sa marque, sa couleur ou son numéro ne correspondent pas à ceux indiqués sur la carte de conducteur, Yandex.Taxi limite temporairement la capacité du conducteur à accepter des commandes.
Si les artistes ne parviennent pas à un consensus, les photos sont envoyées aux employés de Yandex.Taxi - des évaluateurs qui contrôlent la voiture de manière plus approfondie et prennent ensuite la décision finale. Les évaluateurs suivent un programme de formation spécial et ont plus d'expérience.

Ainsi voit l'exécuteur testamentaire de DCC Yandex.Tolki
Défi
Avec la croissance de Yandex.Taxi, le nombre d'inspections DCC augmente également, ce qui signifie que les coûts pour les tolkers et les évaluateurs augmentent. De plus, la vitesse de contrôle de la voiture diminue. Pendant que le DCC est en cours, vous pouvez autoriser les conducteurs à accepter des commandes ou non. Les deux options ont leurs inconvénients: dans le premier cas, un conducteur sans scrupules aura le temps d'accepter plusieurs commandes sur une voiture qui ne répond pas aux normes, dans le second - tous les conducteurs appelés pour le contrôle photo ne pourront pas travailler jusqu'à ce que le contrôle soit terminé. Par conséquent, il est important de vérifier rapidement les voitures afin que les utilisateurs et les conducteurs ne rencontrent aucun inconvénient.
En observant la croissance des graphiques des coûts et du temps d'analyse moyen, nous avons réalisé que nous voulions réduire le coût de Toloka, décharger les évaluateurs et réduire le temps d'analyse moyen, en d'autres termes, pour automatiser une partie des vérifications. Naturellement, nous ne voulions pas sacrifier la qualité de service et manquer plus de voitures qui ne répondaient pas aux normes de qualité de la ligne, et nous ne voulions pas non plus limiter l'acceptation des commandes par les conducteurs de bonne foi. Nous devions automatiser le DCC et en même temps ne pas augmenter la part des erreurs dans le flux global des contrôles.
Comment nous avons implémenté l'apprentissage automatique chez DCC
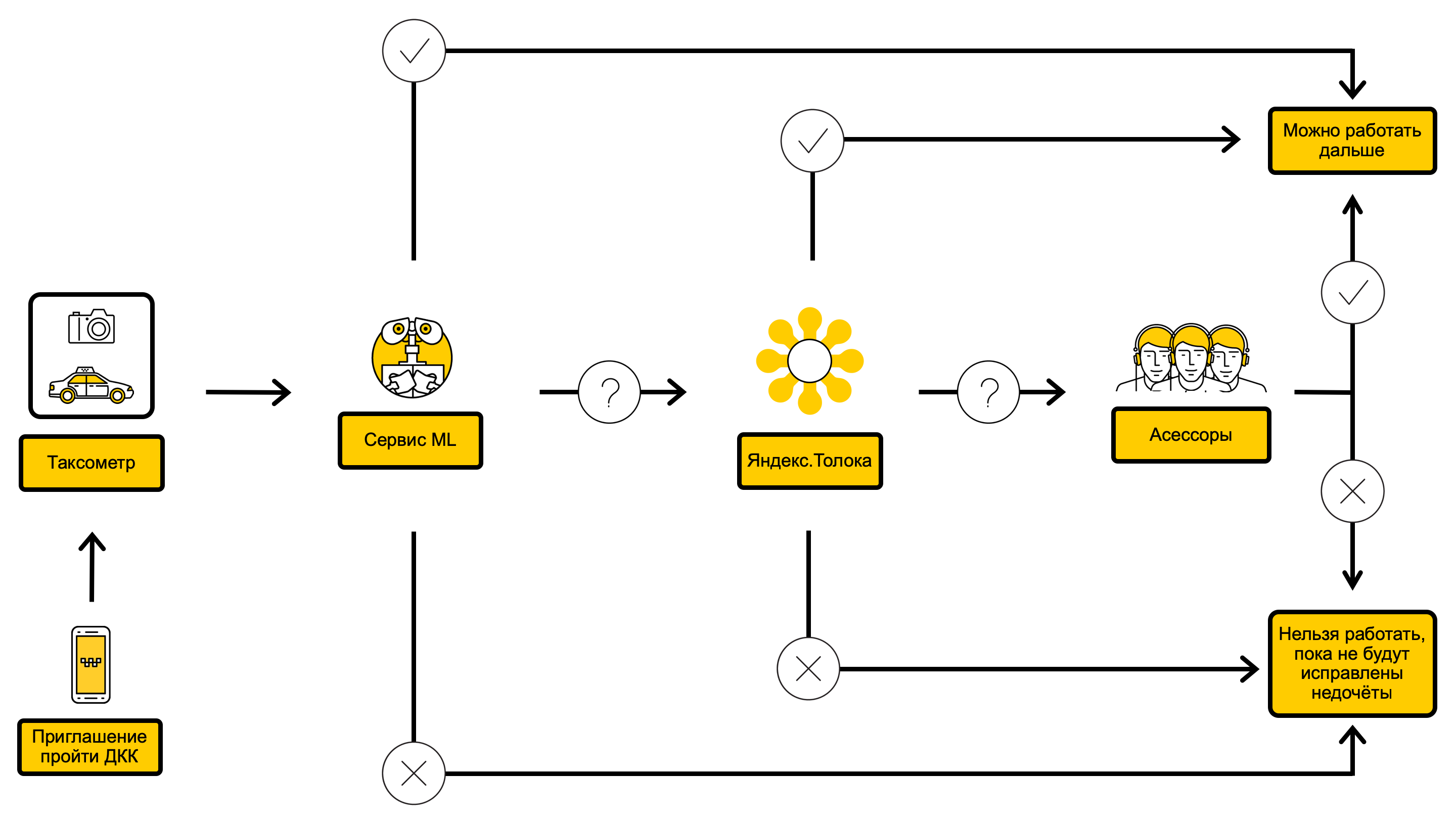
Diagramme de processus DCC avec ML à l'intérieur
Pour commencer, nous avons décidé de l'énoncé du problème: automatiser autant de contrôles que possible, sans augmenter le taux d'erreur dans le flux global.
Voyons quelles sont les erreurs dans notre tâche. Ils se présentent sous deux formes: faux positif et faux négatif . Dans notre terminologie, négatif est le résultat d'un contrôle avec lequel le conducteur peut continuer à travailler, et positif est le résultat qui implique un délai de réception des commandes. Ensuite, le faux négatif est un cas dans lequel nous avons été obligés d'autoriser un conducteur avec une mauvaise voiture à prendre des commandes, et un faux positif - au contraire, lorsque nous n'avons pas permis à un conducteur de travailler avec une voiture qui va bien. Il s'avère que le taux de faux négatifs (FNR) est la part des conducteurs avec de «mauvaises» voitures avec lesquelles nous avons été autorisés à accepter des commandes, et le taux de faux positifs (FPR) est le pourcentage de conducteurs avec lesquels nous n'étions pas autorisés à travailler, bien qu'ils soient bien avec les voitures. Ainsi, depuis l'introduction du machine learning dans le système, nous souhaitions: automatiser autant de contrôles que possible, sans augmenter le FPR et le FNR par rapport à un système sans machine learning.
De plus, il était nécessaire de comprendre les paramètres à guider lors du choix des modèles et des seuils pour prendre des décisions en fonction de leurs prédictions. Il ressort des conditions du problème que nous nous intéressons à trois quantités:
- La fraction du fil auquel les modèles d'apprentissage automatique peuvent répondre automatiquement.
- Systèmes FNR.
- Systèmes FPR.
Nous maximisons la première valeur tout en respectant les restrictions sur les deuxième et troisième.
Cela peut soulever la question: pourquoi ne pas maximiser les économies d'argent ou minimiser directement le temps de numérisation moyen, et non par la part des contrôles automatisés? Optimiser l'argent est une idée très intéressante, mais généralement difficile à mettre en œuvre. Dans notre cas, les économies se composent de deux facteurs: le premier est celui de chaque vérification automatisée, car chaque vérification chez les évaluateurs ou dans Yandex.Tolok coûte de l'argent; la seconde - économiser en réduisant le nombre d'erreurs, car chaque erreur coûte de l'argent à Yandex.Taxi. Calculer objectivement combien d'erreurs nous coûtent est une tâche très difficile, nous sommes donc limités à calculer les économies uniquement par le premier facteur. Cette valeur augmente de façon monotone dans la proportion de contrôles automatisés, de sorte que cette fraction peut être maximisée au lieu d'être enregistrée. Le même raisonnement s'applique au temps DCC moyen; il diminue également de façon monotone en fonction de la part des contrôles automatisés.
Sélection du modèle
Nous pouvons dire que le contrôle DCC se réduit au choix des options de réponse pour un certain nombre de questions sur l'état de la voiture à partir de ses photographies, et cela ressemble à une tâche de classification d'image. De telles tâches sont résolues par la vision par ordinateur, et à notre époque - un outil spécifique, les réseaux de neurones convolutifs. Nous avons décidé de les utiliser pour l'automatisation DCC.
La première solution ou approche «tout à la fois»
Maintenant que nous avons compris ce qu'il faut optimiser et pourquoi, il est temps de collecter des données et de former des modèles à leur sujet. La collecte de données a été facile, car tous les contrôles DCC sont enregistrés et stockés sous une forme pratique. Dans la première version de la solution, les photos de l'extérieur et de l'intérieur de la voiture sous quatre angles, la marque, le modèle et la couleur de la voiture, ainsi que les résultats de 10 inspections DCC précédentes, ont été utilisés comme panneaux. En tant que variables cibles, nous avons pris les réponses à toutes les questions de vérification, par exemple: "La voiture est-elle endommagée?" ou "La couleur de la voiture correspond-elle à celle de la carte de conducteur?" La variable cible principale était la réponse à la question principale: "Est-il nécessaire de limiter la capacité du conducteur à prendre des commandes?" Nous avons enseigné à un grand modèle, très similaire à VGG avec l'attention de SENet, à répondre à toutes les questions en même temps et, par conséquent, nous avons rencontré plusieurs problèmes.

Approche tout-en-un
Problèmes de l'approche «tout à la fois»:
- Nous n'avons pas pu répondre à la question sur la correspondance du numéro de voiture sur la photo indiquée sur la carte de conducteur. Un grand réseau de classification des images ne pouvait pas faire face à cette tâche, pour cela, nous avons besoin d'un modèle spécial de reconnaissance optique de caractères (OCR), affûté pour reconnaître les plaques d'immatriculation.
- La variable cible était incomplète et bruyante. Constatant un défaut grave dans l'apparence de la voiture, ce qui était suffisant pour prendre une décision, les évaluateurs ont souvent oublié de répondre à d'autres questions. Donc, si la voiture sur la photo était à la fois sale et cassée, alors avec une forte probabilité, nous n'avons observé qu'une seule des marques: «voiture sale» ou «voiture endommagée», alors que les deux modèles étaient requis pour notre modèle.
- Il n'y avait aucune interprétabilité de la solution du modèle. Le modèle pourrait répondre à la question de vérification principale avec une précision supérieure à la valeur aléatoire, mais cette réponse était faiblement corrélée avec les réponses aux autres questions. En d'autres termes, si la réponse était: «Il est nécessaire de limiter la capacité à prendre des commandes», nous n'avons presque jamais vu la raison d'une telle décision dans les réponses restantes du modèle. En général, l'exactitude des réponses à toutes les questions, à l'exception de la principale, était presque aléatoire. Nous n'avons pas pu expliquer au chauffeur ce qui devait être réparé pour reprendre les commandes, ce qui signifie que nous ne pouvions pas limiter la capacité du chauffeur à prendre les commandes.
- Le nombre de fausses erreurs négatives dans la réponse à la question: "Est-il nécessaire de limiter la capacité du conducteur à prendre des commandes?" - était trop volumineux pour commencer à approuver automatiquement les chèques. Nous ne pouvions pas fournir le même FNR que dans un système qui fonctionne sans apprentissage automatique, et c'était l'une des exigences de notre tâche.
Ensemble, ces quatre raisons ne nous ont pas permis de mettre en pratique la première solution, mais nous n'avons pas perdu courage et nous avons trouvé la seconde.
La deuxième solution, ou l'approche «tout sauf graduellement»
Nous avons décidé de nous concentrer sur la vérification de l'extérieur de la voiture, car ils représentent environ 70% du débit total. De plus, nous avons décidé de diviser la tâche générale en sous-tâches et d'apprendre à répondre séparément à toutes les questions de DCC.

Approchez «tout, mais progressivement»
Il était une fois, notre service était déjà engagé dans l'automatisation DCC et a réussi à introduire un modèle qui vous permet de filtrer les photos sombres et non pertinentes. Nous avons continué à utiliser ce modèle afin de répondre à la question: «Les vraies photos suivantes de la voiture sont-elles présentes: avant, côté gauche, côté droit, arrière?».
Notre travail sur la deuxième solution a commencé avec le fait que nous avons utilisé le modèle de service de vision par ordinateur Yandex. Search (des personnes mêmes qui ont créé DeepHD ) pour reconnaître les plaques d'immatriculation sur les voitures. Nous avons donc pu répondre à la question: "Le numéro et le code de la région de la voiture correspondent-ils pleinement à ceux indiqués sur la carte de conducteur?" Si nous en parlons plus en détail, nous avons comparé le résultat de la reconnaissance avec le numéro indiqué sur la carte de conducteur et, en fonction de la distance de Levenshtein entre eux, nous avons choisi l'une des options de réponse: "le nombre correspond", "le numéro ne correspond pas" ou "la question ne peut pas être répondue exactement".
Ensuite, nous avons formé des classificateurs de voitures pour reconnaître les marques et les modèles, ainsi que les couleurs. A partir de ce moment, nous avons pu répondre à la question: "La marque, le modèle et la couleur de la voiture sont-ils indiqués sur la carte de conducteur?"
En conclusion, nous avons formé des classificateurs pour trouver des voitures endommagées et sales, cela nous a permis de fermer les questions: "Y a-t-il des dommages ou des défauts sur la carrosserie?" et "Quelle est la saleté de la carrosserie?"
L'approche «tout sauf progressivement» nous a permis de résoudre le problème de la vérification du numéro de plaque d'immatriculation d'une voiture. Nous avons également pu nous débarrasser de l'incomplétude et du bruit de la variable cible, car nous avions maintenant une sélection où les objets de classe négatifs étaient des vérifications réussies et les objets de classe positifs vérifiés là où l'évaluateur ou les trois exécuteurs de Yandex ont trouvé un certain défaut, par exemple, des dommages au boîtier . Après avoir résolu les deux premiers problèmes, nos modèles sont devenus interprétables, et nous avons pu expliquer au conducteur la raison de la limitation, de sorte que lors du prochain test, il corrigerait les défauts. La qualité globale des réponses aux questions a également augmenté de manière significative, et le FPR et le FNR pour certaines combinaisons de seuils de confiance des modèles sont tombés au niveau Yandex.Tolki, ce qui a permis aux modèles d'être introduits en production.
Mise en œuvre en production
Nous avions le choix: lancer un processus régulier qui appliquera les modèles aux contrôles accumulés dans la file d'attente, ou créer un service distinct où vous pourrez passer par l'API et recevoir les réponses des modèles en temps réel. Puisqu'il est important pour nous de trouver rapidement les «mauvaises» voitures, nous avons choisi la deuxième option. Dès que la partie principale du service a été écrite et qu'elle a pu prendre en charge les fonctionnalités nécessaires, nous avons commencé à y ajouter des modèles.
Pour approuver pleinement le chèque, vous devez être en mesure de répondre à toutes les questions de l'instruction, mais afin de limiter l'accès des conducteurs sans scrupules au service, dans certains cas, il suffit de pouvoir répondre à au moins une question. Par conséquent, nous avons décidé de ne pas attendre que tous les modèles soient prêts, mais de les ajouter à mesure qu'ils deviennent disponibles. Un pipeline généralisé d'ajout d'un modèle ressemble à ceci:
- Récupérez l'échantillon.
- Former le modèle.
- Mesurez la qualité et choisissez des seuils hors ligne.
- Ajoutez un modèle au service en arrière-plan et mesurez la qualité en ligne.
- Incluez le modèle dans la production et commencez à prendre des décisions en fonction de ses prédictions.
Cette approche nous a permis non seulement de trouver instantanément de plus en plus de «mauvaises» voitures au fur et à mesure de l'introduction de nouveaux modèles, mais également de mesurer la qualité en ligne sans frais supplémentaires pendant que les modèles fonctionnaient en arrière-plan.
En fin de compte, le moment est venu où nous avons ajouté au service et testé le dernier modèle. Maintenant, nous pourrions répondre à toutes les questions des inspections, ce qui signifie qu'elles seront automatiquement approuvées. Puisqu'il y a beaucoup plus de «bonnes» voitures dans Yandex.Taxi que de «mauvaises», l'approbation automatique des inspections a entraîné une forte augmentation de notre métrique principale - une partie du flux d'inspection automatisé. Nous ne pouvions choisir que les bons seuils qui maximiseraient la part des contrôles automatisés, tout en maintenant le FPR et le FNR globaux de l'ensemble du système au même niveau. Pour sélectionner les seuils, nous avons utilisé un échantillon qui a été marqué de manière indépendante par les exécuteurs, les évaluateurs de Yandex.Tolki et un employé de Yandex.Taxi qui a formé des évaluateurs à contrôler les voitures. Nous avons utilisé son balisage comme vraies valeurs de la variable cible.
Résultats
Dès que nous avons inclus des modèles en production, il a fallu mesurer la qualité en ligne des décisions prises sur la base de leurs réponses. Et voici les chiffres que nous avons vus:
- 30% des vérifications extérieures des véhicules ont maintenant reçu une réponse automatique.
- Le FNR est resté au même niveau, tandis que le FPR a chuté, et nous avons commencé à restreindre moins souvent l'accès au service à ceux qui ne le méritaient pas.
- La charge imposée aux évaluateurs a diminué de 14% et ils ont pu consacrer plus de temps à des tests complexes que le service d'apprentissage automatique n'a pas pu effectuer.
- Le temps de détection des voitures présentant de graves défauts lors de l'inspection est passé de quelques heures à quelques secondes.
Ainsi, l'introduction du machine learning a non seulement permis d'économiser de l'argent, mais a également rendu le service plus sûr et plus confortable pour les utilisateurs. Cependant, c'est loin de la fin de l'histoire. Notre équipe en pleine croissance continuera de travailler activement pour automatiser encore plus de contrôles et rendre Yandex.Taxi encore plus pratique, confortable et sûr.
Morale de l'histoire
En travaillant sur l'automatisation DCC dans Yandex.Taxi, nous avons rencontré de nombreux problèmes, trouvé plusieurs solutions réussies et tiré six conclusions importantes:
- Il n'est pas toujours possible de résoudre le problème de front (même si vous avez le Deep learning).
- Le modèle est aussi bon que les données sur lesquelles il a été formé (ça semble ringard, mais ça l'est).
- Pour résoudre tout problème, il est important de s'appuyer sur les besoins réels de l'entreprise et non sur la minimisation de l'entropie croisée.
- Dans la résolution de certains problèmes, les gens sont toujours importants, malgré l'introduction de l'apprentissage automatique (bonjour, Yandex.Toloka!).
- Les décisions basées sur les prédictions des modèles d'apprentissage automatique peuvent ne pas être prises dans tous les cas, mais uniquement dans la partie où les modèles sont très confiants dans leurs réponses. Dans d'autres cas, il vaut probablement la peine de prendre des décisions à l'ancienne - avec l'aide de personnes.
- En plus du choix de l'architecture et de la formation sur les modèles, il existe de nombreuses autres étapes du projet qui peuvent grandement influer sur la résolution d'un problème commercial. Ces étapes sont: la collecte de données, la sélection de mesures de qualité, les options de mise en œuvre du modèle, la logique de prise de décision du produit basée sur les prédictions du modèle, et bien plus encore.
Plus d'informations intéressantes sur la technologie Taxi
Tarification dynamique ou Comment Yandex.Taxi prédit une forte demande .
Comment Yandex.Taxi prédit les délais de livraison des voitures à l'aide de l'apprentissage automatique .