Lors du développement d'un produit, ils prêtent rarement attention à ses performances avec une forte intensité de demandes entrantes. Peu ou pas du tout à faire cela - il n'y a pas assez de temps, les spécialistes, ou ils se justifient avec la phrase typique: "Tout fonctionne rapidement avec nous sur la prod, alors pourquoi vérifier autre chose?" Dans de tels cas, il peut arriver un moment où une production qui fonctionne bien tombe soudainement en raison du flux croissant de visiteurs, par exemple, sous le Habraeffect. Il devient alors clair que faire des recherches sur la productivité est vraiment nécessaire.
Cette tâche est déroutante pour beaucoup parce qu'il y a un besoin, mais il n'y a pas de compréhension claire de quoi et comment mesurer et comment interpréter le résultat, parfois il n'y a pas d'exigences formelles non fonctionnelles. Ensuite, je vais vous dire par où commencer si vous décidez de suivre cette voie, et expliquer quelles mesures sont importantes dans la recherche de performances et comment les utiliser.
Un peu de théorie
Imaginez que nous ayons une application sphérique dans le vide - elle reçoit des demandes et y répond. Pour simplifier, il peut s'agir d'un microservice avec une méthode qui ne va nulle part et ne dépend pas d'autres composants ou applications. Dans ce cas, nous ne sommes pas très intéressés par ce sur quoi il est écrit, comment cela fonctionne et dans quel environnement il est lancé.
Que voulons-nous savoir sur les performances en général? Il est probablement bon de connaître le flux maximal de demandes entrantes auquel le service est stable, ses performances avec ce flux et le temps nécessaire pour terminer une demande. C'est très bien si vous pouvez déterminer les raisons qui limitent la croissance de la productivité.
De toute évidence, vous devez mesurer le temps de réponse à la demande, respectivement, par le flux de demandes entrantes ou l'intensité, nous entendrons le nombre de demandes par unité de temps, généralement par seconde, et les performances - le nombre de réponses à la même unité de temps. Les temps de réponse peuvent être dispersés sur une large plage, donc pour commencer, il est logique de les présenter comme une moyenne par seconde.
De plus, des problèmes peuvent survenir à différents niveaux: en commençant par le fait que le service répond avec une erreur (et c'est bien si c'est cinq cents, et non «200 OK {" status ":" error "}", et en terminant par le fait qu'il cesse de répondre ou les réponses commencent à se perdre au niveau du réseau. Les demandes infructueuses doivent pouvoir être interceptées et il est pratique de les présenter en pourcentage du total. Le graphique des performances, du temps de réponse et du taux d'erreur en fonction de l'intensité ressemble à ceci:
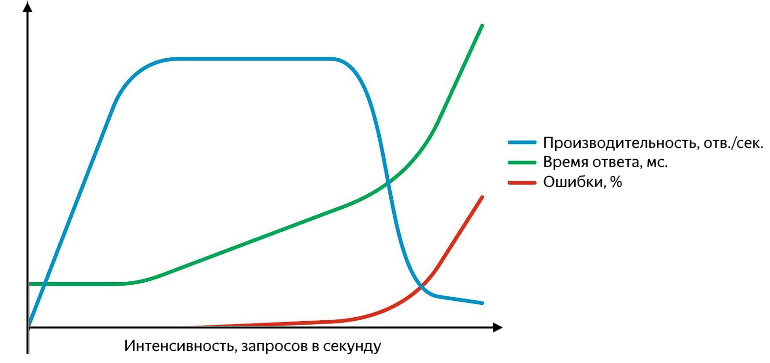
Avec l'augmentation de l'intensité des requêtes, le temps de réponse et le taux d'erreur augmentent
Alors que la productivité augmente linéairement avec l'intensité, le service se porte bien. Il traite avec succès l'ensemble du flux de demandes entrantes, le temps de réponse ne change pas, il n'y a aucune erreur. En continuant à augmenter l'intensité, on obtient un ralentissement de la croissance de la productivité jusqu'à saturation, où la productivité atteint son maximum et le temps de réponse commence à augmenter. Une augmentation ultérieure de l'intensité entraînera une confusion - une augmentation significative du temps de réponse et une baisse de la productivité, une croissance active des erreurs va commencer. Au stade de la croissance et de la saturation, il y a deux points importants - les performances normales et maximales.
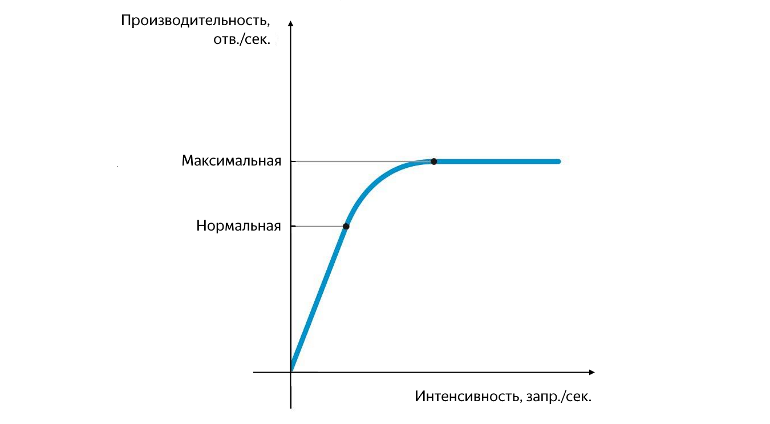
Position de performance normale et maximale
La productivité normale est atteinte au moment où son taux de croissance commence à diminuer, et maximale - au moment où son taux de croissance devient nul. La séparation des performances entre la normale et la maximale est très importante. À une intensité qui correspond aux performances normales, l'application doit fonctionner de manière stable et la valeur des performances normales caractérise le seuil après lequel le goulot d'étranglement du service commence à apparaître, ce qui a un impact négatif sur son fonctionnement. Lorsque les performances maximales sont atteintes, le goulot d'étranglement commence à limiter complètement la croissance future, le service est instable et, en règle générale, à ce moment, un arrière-plan d'erreurs petit mais stable commence à apparaître.
Le problème peut être dû à diverses raisons: les files d'attente sont bloquées, le nombre de threads est insuffisant, le pool a été épuisé, le processeur ou la RAM a été complètement utilisé, la vitesse de lecture / écriture insuffisante à partir du disque, etc. Il est important de comprendre que la correction d'un goulot d'étranglement entraînera une limitation des performances par le suivant, etc. Il est impossible de se débarrasser complètement d'un goulot d'étranglement, il ne peut être déplacé.
Les expériences
Tout d'abord, il est nécessaire de déterminer l'amplitude de l'intensité à laquelle le service atteint des performances normales et maximales, et le temps de réponse moyen correspondant. Pour ce faire, dans une expérience, il suffit d'augmenter simplement le flux de requêtes entrantes. Il est plus difficile de déterminer la valeur de l'intensité maximale et le temps de l'expérience.
Vous pouvez partir de ce qui est écrit dans les exigences non fonctionnelles (le cas échéant), de la charge utilisateur maximale de la vente, ou simplement prendre des valeurs du plafond. Si l'intensité du flux entrant n'est pas suffisante, le service n'aura pas le temps d'atteindre la saturation et il faudra refaire l'expérience. Si l'intensité est trop élevée, le service atteindra très rapidement la saturation, puis le débogage. Dans un tel cas, il est pratique d'avoir une surveillance afin qu'avec une augmentation significative du nombre d'erreurs, vous ne perdiez pas de temps en vain et arrêtiez l'expérience.
Dans nos expériences, nous augmentons progressivement l'intensité de 0 à 1000 requêtes par seconde pendant 10 minutes. Cela suffit pour que le service atteigne la saturation, puis, si nécessaire, nous ajustons le temps et l'intensité dans la prochaine expérience pour obtenir un résultat plus précis. Sur les graphiques ci-dessus, tout était lisse et beau, mais dans le monde réel, il peut être difficile à première vue de déterminer la valeur d'une performance normale.
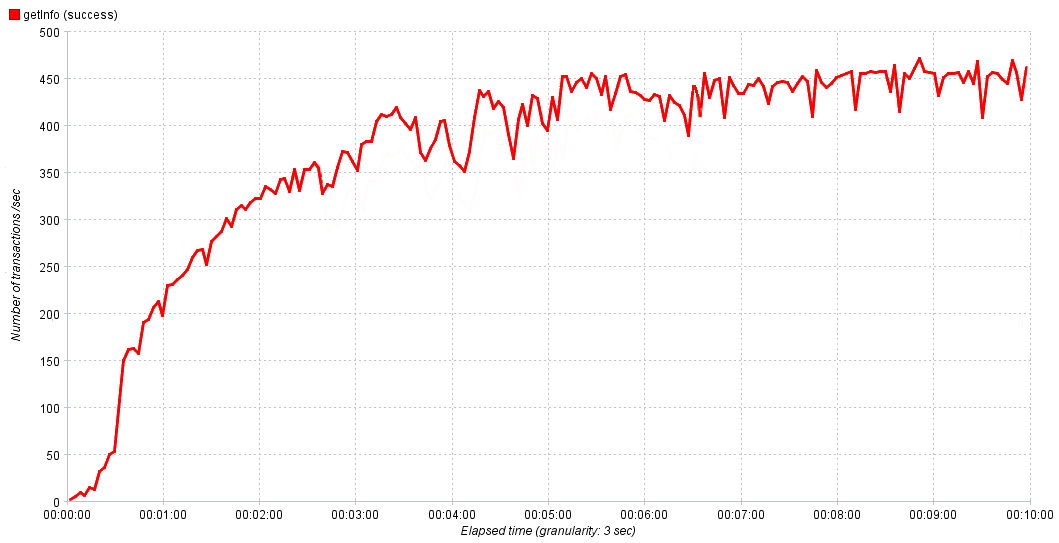
La réelle dépendance des performances du service dans le temps
Dans ce cas, nous prenons 80 à 90% du maximum pour des performances normales. Si nous observons une croissance active des erreurs après avoir atteint la saturation, il est logique de les étudier, car elles sont le résultat d'un goulot d'étranglement, les étudier aidera à les localiser et à les transmettre pour correction.
Ainsi, les premiers résultats sont obtenus. Nous connaissons maintenant les performances normales et maximales des applications, ainsi que les temps de réponse qui leur correspondent. C'est tout? Bien sûr que non! Avec des performances normales, le service devrait fonctionner de manière stable, ce qui signifie que vous devez vérifier son fonctionnement sous charge normale pendant un certain temps. Lequel? Vous pouvez à nouveau examiner les exigences non fonctionnelles, interroger les analystes ou surveiller la durée des périodes d'activité maximale sur le prod. Dans nos expériences, nous augmentons linéairement la charge de 0 à la normale et restons dessus pendant 10-15 minutes. Cela suffit si la charge maximale de l'utilisateur est nettement inférieure à la normale, mais si elles sont comparables, la durée de l'expérience doit être augmentée.
Pour évaluer rapidement le résultat d'une expérience, il est pratique d'agréger les données obtenues sous la forme des métriques suivantes:
- temps de réponse moyen
- médiane
- 90% percentile
- % d'erreurs
- performance.
Quel est le temps de réponse moyen est compréhensible, mais la moyenne n'est une mesure adéquate que dans le cas d'une distribution normale de l'échantillon, car il est trop sensible aux «valeurs aberrantes» - des valeurs trop grandes ou trop petites qui sont fortement décalées de la tendance générale. La médiane est le milieu de l'échantillon entier des temps de réponse, la moitié des valeurs sont inférieures à celle-ci, le reste est plus grand. Pourquoi est-il nécessaire?
Premièrement, d'après sa définition, il est moins sensible aux valeurs aberrantes, c'est-à-dire qu'il s'agit d'une mesure plus adéquate, et deuxièmement, en le comparant à la moyenne, on peut rapidement évaluer les caractéristiques de la distribution de la réponse. Dans une situation idéale, ils sont égaux - la distribution des temps de réponse est normale et le service est parfait!
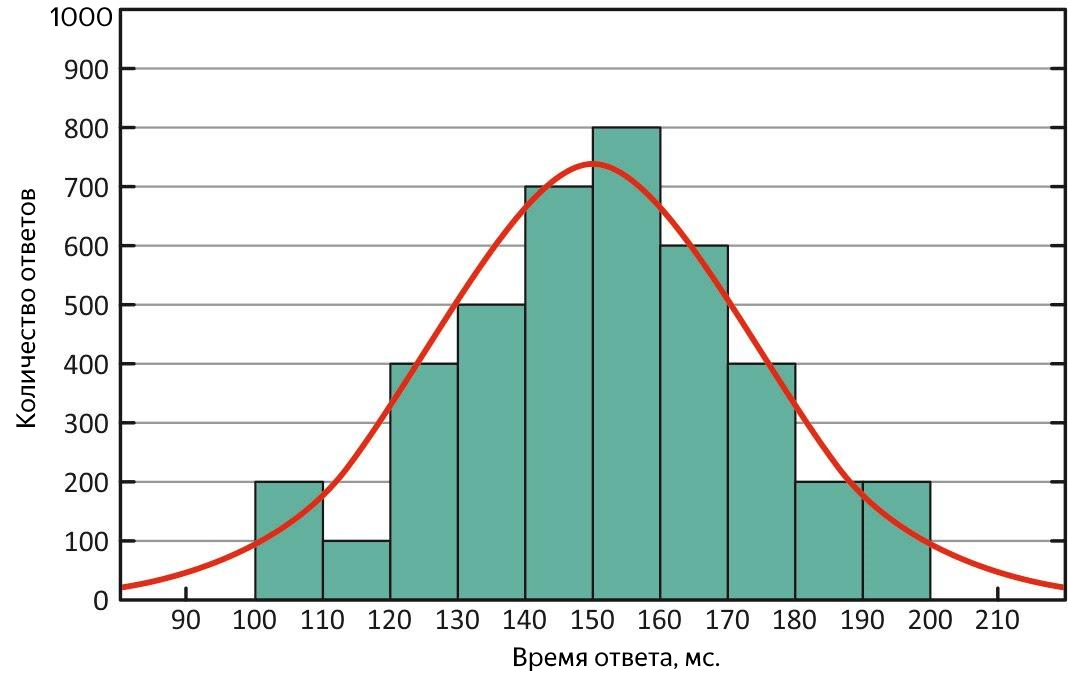
Distribution normale des temps de réponse. Avec cette distribution, la moyenne et la médiane sont équivalentes
Si la moyenne est très différente de la médiane, alors la distribution est asymétrique et des «valeurs aberrantes» pourraient être présentes pendant l'expérience. Si la moyenne est supérieure - il y a eu des périodes où le service a répondu très lentement, en d'autres termes, il a ralenti.
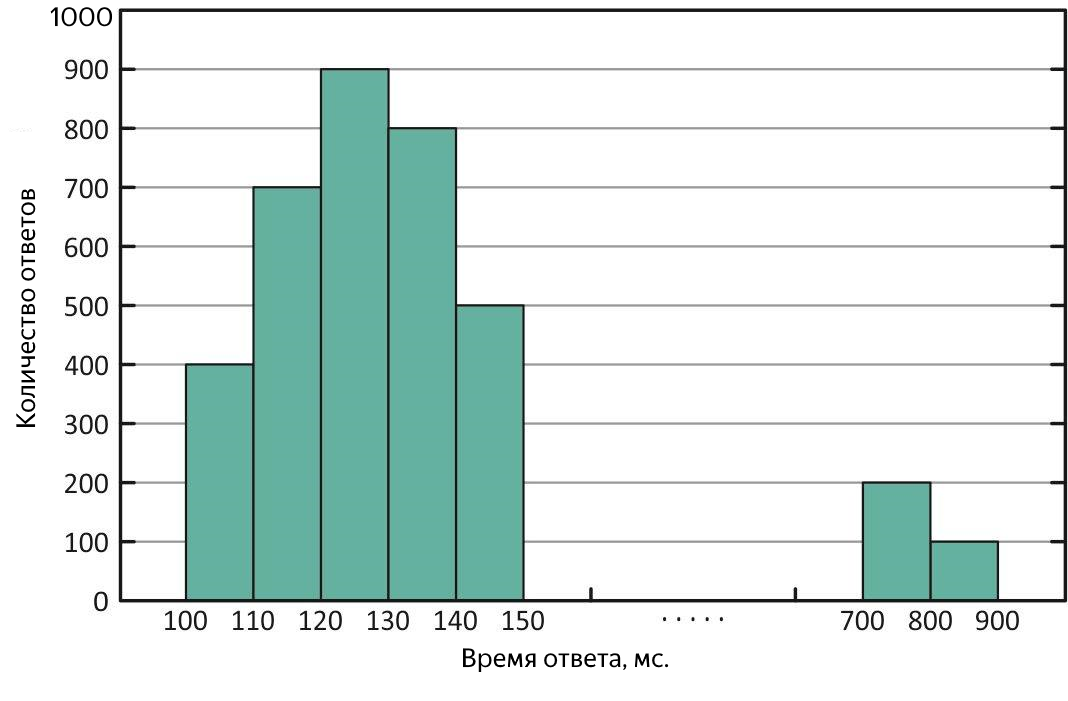
Répartition des temps de réponse avec des «valeurs aberrantes» de réponses longues. Avec cette distribution, la moyenne est supérieure à la médiane.
De tels cas nécessitent une analyse supplémentaire. Pour estimer l'ampleur des «émissions», les quantiles ou centiles viennent à la rescousse.
Un quantile, dans le contexte de l'échantillon obtenu, est la valeur du temps de réponse, à laquelle correspond la partie correspondante de toutes les demandes. Si vous utilisez% des requêtes, il s'agit du centile (au fait, la médiane est de 50%). Il est pratique d'utiliser un percentile de 90% pour estimer les émissions. Par exemple, à la suite de l'expérience, une médiane de 100 ms a été obtenue, et la moyenne - 250 ms, dépasse la médiane de 2,5 fois! De toute évidence, ce n'est pas entièrement bon, nous examinons un quantile à 90%, et il y a 1000 ms - jusqu'à 10% de toutes les demandes réussies ont été traitées pendant plus d'une seconde, un gâchis, vous devez le comprendre. Pour rechercher de longues requêtes, vous pouvez mordre le fichier avec les résultats de l'expérience ou immédiatement dans les journaux de service, mais il est encore mieux de présenter le temps de réponse moyen sous la forme d'un graphique en fonction du temps, il affichera immédiatement à la fois le temps et la nature des «valeurs aberrantes» disponibles.
Résumé
Vous avez donc mené avec succès les expériences et obtenu les résultats. Que ce soit bon ou mauvais, cela dépend des exigences du service, mais pas les chiffres obtenus sont plus importants, mais pourquoi ces chiffres sont, et comprendre ce que la croissance future est limitée. Si vous parvenez à trouver un goulot d'étranglement - très bien, sinon, alors tôt ou tard, le besoin de productivité peut augmenter, et vous devez toujours le rechercher, il est donc parfois plus facile de prévenir la situation.
Dans cette note, j'ai donné une approche de base de la recherche de performance en répondant aux questions que j'avais au tout début. N'ayez pas peur de rechercher la performance, c'est nécessaire!
PS
Visitez notre salon de discussion confortable sur les télégrammes où vous pouvez poser des questions, aider avec des conseils et simplement parler de la recherche de performances.