
Comme toujours, merci à Fred Hebert et Sargun Dhillon d' avoir lu un brouillon de cet article et d'avoir offert de précieux conseils.
Dans son exposé sur la vitesse, Tamar Berkovichi de Box a souligné l'importance des contrôles de performances pour le basculement automatique de la base de données. En particulier, elle a noté que la surveillance du temps d'exécution des requêtes de bout en bout, en tant que méthode pour déterminer l'intégrité d'une base de données, est meilleure que le simple ping (ping).
... en transférant le trafic vers un autre nœud (réplique) afin d'éliminer l'inaction, il est nécessaire de créer une protection contre les rebonds et autres situations frontalières. Ce n'est pas difficile. L'objectif de l'organisation d'un travail efficace est de savoir quand mettre la base de données en première position, c'est-à-dire Vous devez être en mesure d'évaluer correctement l'intégrité de la base de données. Maintenant, de nombreux paramètres auxquels nous sommes habitués - par exemple, la charge du processeur, la latence, le taux d'erreur - sont des signaux secondaires. Aucun de ces paramètres ne fait état de la capacité de la base de données à traiter le trafic client. Par conséquent, si vous les utilisez pour prendre une décision concernant le changement, vous pouvez obtenir des résultats faux positifs et faux négatifs. Notre vérificateur d'intégrité effectue en fait des requêtes simples sur les nœuds de la base de données et utilise les données sur les requêtes terminées et échouées pour évaluer plus précisément la santé de la base de données.
J’en ai discuté avec un ami et il a suggéré que les contrôles de santé soient extrêmement simples et que le trafic réel soit le meilleur critère pour évaluer la santé d’un processus.
Souvent, les discussions relatives à la mise en œuvre des bilans de santé s'articulent autour de deux options opposées: des tests de communication / signal simples ou des tests complexes de bout en bout. Dans cet article, je tiens à souligner le problème associé à l'utilisation de la forme susmentionnée de contrôles d'intégrité pour certains types de solutions d'équilibrage de charge, ainsi que la nécessité d'une approche plus détaillée pour évaluer la santé d'un processus.
Deux types de bilans de santé
Les contrôles d'intégrité, même dans de nombreux systèmes modernes, se répartissent généralement en deux catégories: les contrôles au niveau du nœud et au niveau du service.
Par exemple, Kubernetes implémente la validation en analysant l'état de préparation et la capacité de survie . Le contrôle de disponibilité est utilisé pour déterminer la capacité du foyer à desservir le trafic. Si la vérification de l'état de préparation n'est pas effectuée, elle est supprimée des points d'extrémité qui composent le service , et pour cette raison, dans l'âtre, jusqu'à la fin de la vérification, aucun trafic n'est acheminé. D'un autre côté, un contrôle de survie est utilisé pour déterminer si un service répond à un blocage ou à un verrou. En cas d'échec, le conteneur individuel dans kubelet est redémarré . De même, Consul autorise plusieurs formes de checks : basés sur des script basés sur HTTP et dirigés vers une URL spécifique, basés sur TTL ou même des alias.
La méthode la plus courante pour implémenter un contrôle d'intégrité au niveau du service consiste à déterminer le point final du contrôle d'intégrité. Par exemple, dans gRPC, un bilan de santé devient lui-même un appel RPC. gRPC permet également des vérifications de l' intégrité du niveau de service et des vérifications générales de l' intégrité du serveur gRPC .
Dans le passé, les contrôles de santé au niveau de l'hôte étaient utilisés comme signal pour déclencher une alerte. Par exemple, une alerte avec une charge moyenne du processeur (actuellement considérée comme un modèle anti-conception). Même si le bilan de santé n'est pas utilisé directement pour la notification, il sert toujours de base à un certain nombre d'autres décisions automatiques d'infrastructure, par exemple, concernant l'équilibrage de charge et (parfois) le circuit ouvert. Dans les schémas de données de grille de services tels qu'Envoy, les données de contrôle d' intégrité, lorsqu'il s'agit de déterminer le routage du trafic vers une instance, vont de l'avant en ce qui concerne les données de découverte de service.
L'efficacité est un spectre, pas une taxonomie binaire
Une demande d'écho, ou ping, peut uniquement établir si le service fonctionne , tandis que les tests de bout en bout sont des proxys pour établir si le système est capable d'exécuter une unité de travail spécifique, où l'unité de travail peut être une requête de base de données ou un calcul spécifique . Quelle que soit la forme d'un bilan de santé, son résultat est considéré comme purement binaire: «réussi» ou «échoué».
Dans les options d'infrastructure dynamiques et souvent «automatiquement évolutives» d'aujourd'hui, un processus unique qui «fonctionne» n'a pas d'importance s'il ne peut pas effectuer une unité de travail spécifique. Il s'avère que les contrôles simplifiés, tels que les tests d'écho, sont presque inutiles.
Il est facile de déterminer quand un service est complètement déconnecté , mais il est beaucoup plus difficile d'établir le degré d' opérabilité d'un service en cours d'exécution. Il est tout à fait possible que le processus soit en cours (c'est-à-dire que le bilan de santé passe) et que le trafic soit acheminé, mais pour effectuer une certaine unité de travail, par exemple, pendant la période de retard du service p99, cela ne suffit pas.
Souvent, le travail ne peut pas être terminé car le processus est surchargé. Dans les services hautement compétitifs, la «congestion» est parfaitement corrélée avec le nombre de demandes simultanées traitées par un seul processus avec une file d'attente excessive, ce qui peut entraîner une augmentation du délai pour un appel RPC (bien que le plus souvent, le service de niveau inférieur met simplement la demande en attente et réessaye sur délai d'attente). Cela est particulièrement vrai si le point de terminaison du contrôle d'intégrité est configuré pour revenir automatiquement au code d'état HTTP 200, tandis que l'opération réelle effectuée par le service implique des E / S réseau ou des calculs.

La performance du processus est un spectre. Tout d'abord, nous nous intéressons à la qualité de service , par exemple, le temps nécessaire au processus de restauration du résultat d'une unité de travail spécifique, et la précision du résultat.
Il est possible que le processus oscille entre différents degrés de capacité de travail au cours de sa durée de vie: de la pleine capacité de travail (par exemple, la capacité de fonctionner au niveau de parallélisme attendu) au point d'inopérabilité (lorsque les files d'attente commencent à se remplir) et le point où le processus entre complètement dans une zone inopérante (ressenti qualité de service réduite). Seuls les services les plus triviaux peuvent être construits sur l'hypothèse qu'il n'y a pas de degré d'échec partiel dans une période où un échec partiel implique que certaines fonctions fonctionnent et d'autres sont désactivées, et pas seulement «certaines demandes sont exécutées, d'autres ne sont pas exécutées». Si l'architecture de service ne permet pas de corriger correctement une défaillance partielle, le client corrige automatiquement la tâche de correction d'erreur.
Une infrastructure adaptative et auto-réparatrice doit être construite en sachant que de telles fluctuations sont parfaitement normales . Il est également important de se rappeler que cette différence n'a d'importance qu'en ce qui concerne l'équilibrage de charge - pour l'orchestrateur, par exemple, cela n'a aucun sens de redémarrer le processus simplement parce que le processus est au bord de la surcharge.
En d'autres termes, pour le niveau d'orchestration, il est tout à fait raisonnable de considérer l'opérabilité du processus comme un état binaire et de redémarrer le processus uniquement après une panne ou un gel. Mais dans la couche d' équilibrage de charge (qu'il s'agisse d'un proxy externe, par exemple, Envoy ou d'une bibliothèque interne côté client), il est extrêmement important qu'il agisse sur la base d'informations plus détaillées sur l'opérabilité du processus - lorsqu'il prend les décisions appropriées concernant la coupure du circuit et le déchargement de la charge. La dégradation progressive du service est impossible s'il est impossible de déterminer avec précision le niveau de performance du service à tout moment.
Laissez-moi vous dire par expérience: la concurrence illimitée est souvent le principal facteur conduisant à la dégradation du service ou à une baisse permanente de la productivité. L'équilibrage de charge (et, par conséquent, le délestage) se résume souvent à une gestion efficace de la concurrence et à l'application d'une contre-pression, empêchant le système de surcharger.
Le besoin de rétroaction lors de l'application de la contre-pression
Matt Ranney a écrit un article phénoménal sur la concurrence illimitée et le besoin de contre-pression dans Node.js. Tout l'article est curieux, mais la principale conclusion (du moins pour moi) était la nécessité d'un retour d'informations entre le processus et son unité de sortie (généralement un équilibreur de charge, mais parfois un autre service).
L'astuce est que lorsque les ressources sont épuisées, quelque chose doit être donné quelque part. La demande augmente et la productivité ne peut pas augmenter comme par magie. Pour limiter les tâches entrantes, la première chose à faire est de définir une limite de vitesse au niveau du site, par adresse IP, utilisateur, session ou, au mieux, par un élément important pour l'application. De nombreux équilibreurs de charge peuvent limiter la vitesse d'une manière plus compliquée que de limiter le serveur Node.js entrant, mais ils ne remarquent généralement pas de problèmes tant que le processus n'est pas dans une situation difficile.
Les limites de vitesse et les circuits ouverts basés sur des seuils et des limites statiques peuvent être peu fiables et instables en termes d'exactitude et d'évolutivité. Certains équilibreurs de charge (en particulier HAProxy) fournissent de nombreuses statistiques sur la longueur des files d'attente internes pour chaque serveur et chaque partie de serveur . De plus, HAProxy permet l'exécution d'un agent-check ( agent-check auxiliaire indépendant du contrôle d'intégrité normal), ce qui permet au processus de fournir au serveur proxy un retour d'informations d'intégrité plus précis et dynamique. Lien vers les documents :
La vérification de l'intégrité de l'agent est effectuée par une connexion TCP au port en fonction du paramètre de agent-port spécifié et en lisant la chaîne ASCII. Une ligne se compose d'une série de mots séparés par des espaces, des tabulations ou des virgules dans n'importe quel ordre, se terminant éventuellement par /r et / ou /n et comprenant les éléments suivants:
- Représentation d'un pourcentage entier positif de ASCII, par exemple 75% . Les valeurs de ce format déterminent le poids proportionnellement à la valeur initiale
La valeur de serveur pondérée configurée au démarrage de HAProxy. Veuillez noter qu'une valeur de poids zéro est indiquée sur la page des statistiques comme DRAIN partir du moment d'un impact similaire sur le serveur (elle est supprimée de la batterie LB).
- Paramètre de chaîne maxconn : suivi d'un entier (pas d'espace). Valeurs dans
Ce format définit le maxconn serveur maxconn . Nombre maximum
les connexions déclarées doivent être multipliées par le nombre d'équilibreurs de charge et les différentes parties du serveur à l'aide de ce contrôle d'intégrité pour obtenir le nombre total de connexions que le serveur peut établir. Par exemple: maxconn:30
- Le mot est ready . Cela traduit l'état administratif du serveur en
Mode READY , annulant l'état DRAIN ou MAINT .
- Le mot drain . Cela traduit l'état administratif du serveur en
Mode DRAIN ("drain"), après quoi le serveur n'acceptera pas de nouvelles connexions, à l'exception des connexions acceptées via la base de données.
- Le mot maint . Cela traduit l'état administratif du serveur en
Mode MAINT («maintenance»), après quoi le serveur n'acceptera aucune nouvelle connexion et les contrôles de santé s'arrêteront.
- Les mots down , failed ou stopped , qui peuvent être suivis d'une ligne de description après le symbole pointu (#). Tous indiquent l'état de fonctionnement du serveur DOWN («off»), mais puisque le mot lui-même est affiché sur la page des statistiques, la différence permet à l'administrateur de déterminer si la situation était attendue: le service peut être intentionnellement arrêté, certains tests de confirmation peuvent apparaître, mais échouer, ou être considéré comme désactivé (aucun processus, aucune réponse du port).
- Le mot up indique l'état de fonctionnement du serveur UP («on») si les contrôles d'intégrité confirment également la disponibilité du service.
Les paramètres non revendiqués par l'agent ne sont pas modifiés. Par exemple, un agent ne peut être conçu que pour surveiller l'utilisation du processeur et signaler uniquement une valeur de poids relatif sans interagir avec l'état de fonctionnement. De même, le programme agent peut être conçu comme une interface utilisateur final avec 3 commutateurs permettant à l'administrateur de modifier uniquement l'état administratif.
Cependant, il convient de garder à l'esprit que seul l'agent peut annuler ses propres actions.Par conséquent, si le serveur est défini sur DRAIN ou DOWN à l'aide de l'agent, l'agent doit effectuer d'autres actions équivalentes pour redémarrer le service.
L'échec de la connexion à l'agent n'est pas considéré comme une erreur, car la capacité de connexion est testée en effectuant régulièrement une vérification de l'état, qui est démarrée à l'aide du paramètre de vérification. Cependant, si un message d'arrêt arrive, un avertissement n'est pas une bonne idée d'arrêter l'agent, car seul l'agent signalant l'arrêt peut réactiver le serveur.
Ce schéma de communication dynamique du service avec l'unité de sortie est extrêmement important pour créer une infrastructure auto-adaptative. Un exemple serait l'architecture avec laquelle j'ai travaillé à un emploi précédent.
J'ai travaillé chez imgix , une start-up de traitement d'images en temps réel. À l'aide d'une simple URL API, les images sont récupérées et converties en temps réel, puis utilisées n'importe où dans le monde via CDN. Notre pile était assez complexe ( comme décrit ci-dessus ), mais en bref, notre infrastructure comprenait un niveau d'équilibrage et d'équilibrage de charge (en tandem avec le niveau de réception des données de la source), le niveau de mise en cache source, le niveau de traitement d'image et le niveau de livraison de contenu.

Le niveau d'équilibrage de charge était basé sur le service Spillway, qui faisait office de proxy inverse et de courtier de demandes. C'était un service purement interne; au bord du gouffre, nous avons démarré nginx et HAProxy et Spillway, il n'a donc pas été conçu pour compléter TLS ou exécuter d'autres fonctions à partir de cet ensemble innombrable qui est généralement de la compétence du proxy de frontière.
Spillway était composé de deux composants: la partie client (Spillway FE) et le courtier. Bien qu'au départ, les deux composants se trouvaient dans le même fichier binaire, à un moment donné, nous avons décidé de les séparer en fichiers binaires distincts qui étaient déployés simultanément sur le même hôte. Principalement parce que ces deux composants avaient des profils de performances différents et que la partie client était presque entièrement connectée au processeur. La tâche de la partie client était d'effectuer un traitement préliminaire de chaque demande, y compris une vérification préliminaire au niveau de la mise en cache source, pour s'assurer que l'image était mise en cache dans notre centre de données avant d'envoyer la demande de conversion d'image à l'exécuteur testamentaire.
À tout moment, nous avions un pool fixe (une douzaine, si ma mémoire est bonne) d'artistes qui pouvaient être connectés au même courtier Spillway. Les artistes étaient responsables de la conversion réelle de l'image (recadrage, redimensionnement, traitement PDF, rendu GIF, etc.). Ils ont tout traité, des PDF de centaines de pages et des GIF avec des centaines de cadres aux simples fichiers d'images. Une autre caractéristique de l'entrepreneur était que, bien que tous les réseaux soient complètement asynchrones, il n'y avait aucune conversion réelle sur le GPU lui-même. Étant donné que nous travaillions en temps réel, il était impossible de prédire à quoi ressemblerait notre trafic à un moment donné. Notre infrastructure a dû s'adapter aux différentes formes de trafic entrant - sans intervention manuelle de l'opérateur.
Compte tenu des schémas de trafic disparates et hétérogènes que nous avons souvent rencontrés, il est devenu nécessaire que les artistes interprètes ou exécutants refusent d'accepter les demandes entrantes (même lorsqu'ils sont pleinement opérationnels) si l'acceptation de la connexion menaçait de surcharger l'artiste. Chaque demande adressée à l'intervenant contenait un certain ensemble de métadonnées sur la nature de la demande, ce qui permettait à l'interprète de déterminer s'il était en mesure de répondre à cette demande. Chaque exécuteur avait son propre ensemble de données statistiques sur les demandes avec lesquelles il travaillait actuellement. L'employé a utilisé ces statistiques conjointement avec les métadonnées de la demande et d'autres données heuristiques, telles que les données de taille de tampon de socket, pour déterminer s'il a reçu correctement la demande entrante. Si l'employé a déterminé qu'il ne pouvait pas accepter la demande, il a créé une réponse qui ne différait pas de la vérification de l'agent HAProxy informant son évacuateur de crues sur son fonctionnement.
Spillway a surveillé la performance de tous les artistes de la piscine. Au début, j'ai essayé d'envoyer une demande trois fois de suite à différents exécuteurs (la préférence était donnée à ceux qui avaient l'image d'origine dans les bases de données locales et qui n'étaient pas surchargés), et si les trois exécuteurs refusaient d'accepter la demande, la demande était mise en file d'attente dans le courtier à l'intérieur de la mémoire. Le courtier a pris en charge trois formes de files d'attente: la file d'attente LIFO, la file d'attente FIFO et la file d'attente prioritaire. Si les trois files d'attente ont été remplies, le courtier a simplement rejeté la demande, permettant au client (HAProxy) de réessayer après la période de retard. Lorsqu'une demande était placée dans l'une des trois files d'attente, tout exécuteur libre pouvait la supprimer de là et la traiter. Il y a certaines difficultés associées à l'attribution d'une priorité à une demande et à la décision laquelle des trois files d'attente (LIFO, FIFO, files d'attente basées sur la priorité) doit être placée, mais c'est un sujet pour un article séparé.
Pour le bon fonctionnement du service, nous n'avons pas eu besoin de discuter de cette forme de retour dynamique. Nous avons soigneusement surveillé la taille de la file d'attente du courtier (les trois files d'attente) et Prometheus a émis l'un des principaux avertissements lorsque la taille de la file d'attente dépassait un certain seuil (ce qui était assez rare).
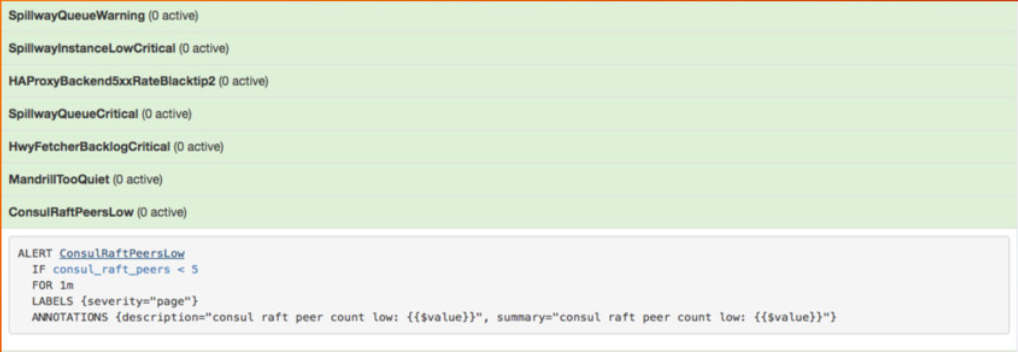
Image de ma présentation sur le système de surveillance Prometheus au Google NYC en novembre 2016

L'avertissement est tiré de ma présentation sur le système de surveillance Prometheus lors de la conférence OSCON en mai 2017.
Au début de cette année, Uber a publié un article intéressant dans lequel il a mis en lumière son approche de la mise en œuvre d'un niveau de délestage basé sur la qualité de service.
En analysant les échecs au cours des six derniers mois, nous avons constaté que 28% d'entre eux pouvaient être atténués ou évités par une dégradation en douceur .
Les trois types de défaillances les plus courants étaient associés aux facteurs suivants:
- Modifications du schéma de la demande entrante, y compris l'encombrement et les mauvais nœuds d'opérateur.
- Épuisement des ressources telles que processeur, mémoire, circuit d'entrée / sortie ou ressources réseau.
- Défaillances de dépendance, y compris l'infrastructure, l'entrepôt de données et les services en aval.
Nous avons implémenté un détecteur de surcharge basé sur l'algorithme CoDel . Pour chaque point de terminaison activé, un tampon de requête léger (implémenté sur la base de gourutin et de canaux ) est ajouté pour suivre les délais entre le moment de la réception de la requête de la source de l'appel et le début du traitement de la requête dans le gestionnaire. , , .
, , , - . 2013 Google «The Tail at Scale» , ( ), ( ) .
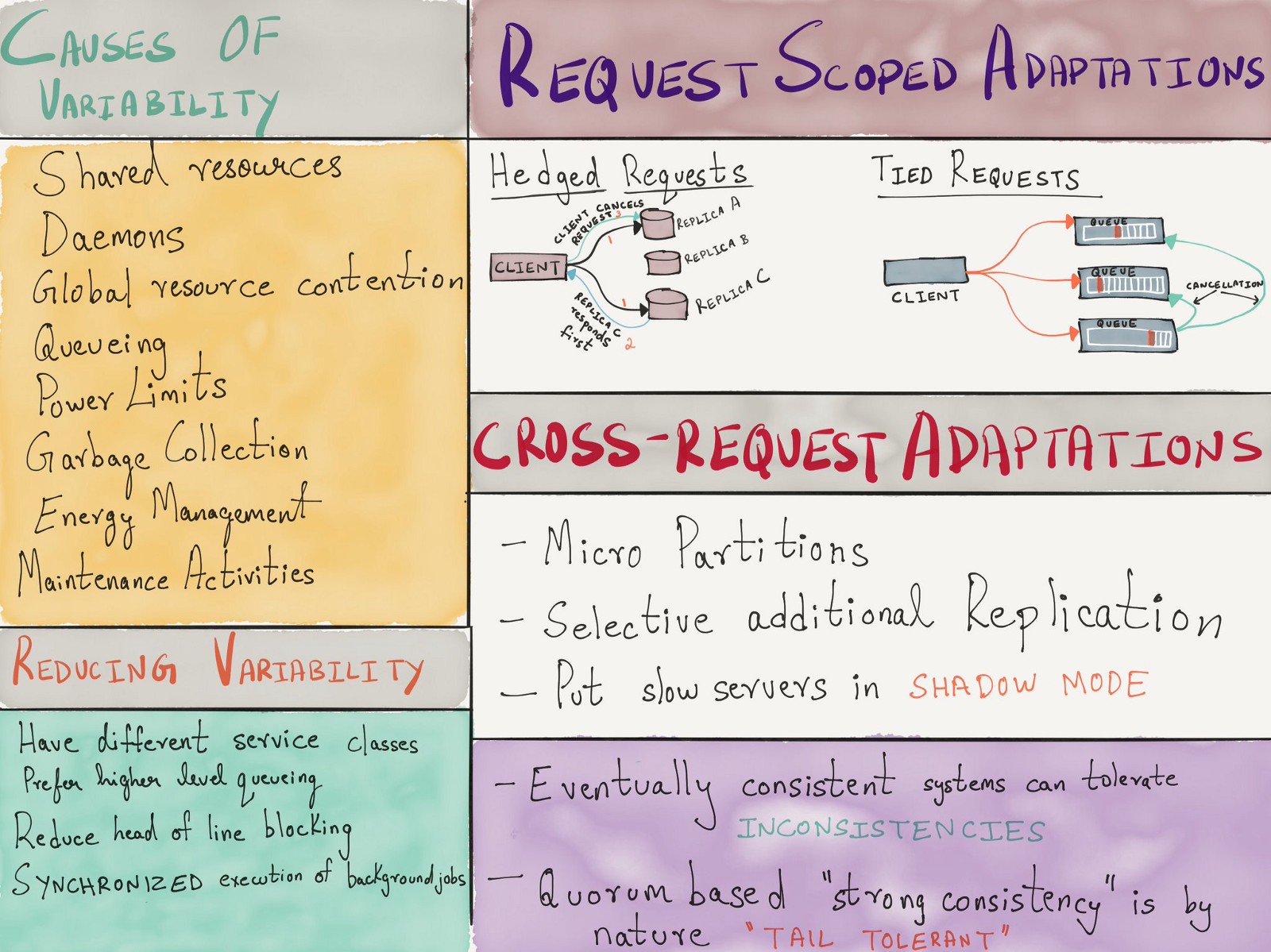
, . , .

( )
, , :
- , , QCon London 2018.
- : - , , LISA 2017.
- – , , Strangeloop 2017.
- : , , , Strangeloop 2017.
- « » .
Conclusion
, TCP/IP ( ), IP ECN ( IP ) Ethernet, , .
, . . , . .