Vous êtes ici si vous voulez savoir comment apprivoiser un framework qui est largement connu dans les cercles des développeurs Python appelé Celery. Et même si Celery exécute en toute confiance les commandes de base de votre projet, l'expérience fintech peut vous ouvrir des côtés inconnus. Parce que la fintech est toujours le Big Data, et avec elle le besoin de tâches en arrière-plan, de traitement par lots, d'API asynchrone, etc.

La beauté de l'histoire d'Oleg Churkin sur le céleri à
Moscou Python Conf ++, en plus d'instructions détaillées sur la façon de configurer le céleri sous charge et comment le surveiller, est que vous pouvez emprunter des idées utiles.
À propos du conférencier et du projet: Oleg Churkin (
Bahusss ) développe des projets Python de complexité
variable depuis 8 ans, a travaillé dans de nombreuses entreprises bien connues: Yandex, Rambler, RBC, Kaspersky Lab. Maintenant, techlide dans le démarrage de fintech-StatusPoney.
Le projet fonctionne avec une grande quantité de données financières des utilisateurs (1,5 téraoctets): comptes, transactions, commerçants, etc. Il exécute jusqu'à un million de tâches chaque jour. Peut-être que ce nombre ne semblera pas vraiment élevé à quelqu'un, mais pour une petite startup avec des capacités modestes, c'est une quantité importante de données, et les développeurs ont dû faire face à divers problèmes sur la voie d'un processus stable.
Oleg a parlé des principaux points de travail:
- Quelles tâches vouliez-vous résoudre avec le framework, pourquoi avez-vous choisi le céleri.
- Comment le céleri a aidé.
- Comment configurer Celery sous charge.
- Comment surveiller l'état du céleri.
Et il a partagé quelques utilitaires de conception qui implémentent les fonctionnalités manquantes dans Celery. En fait, en 2018, et cela pourrait l'être. Ce qui suit est une version texte du rapport à la première personne.
Problème
Il était nécessaire pour résoudre les tâches suivantes:
- Exécutez des tâches d'arrière-plan distinctes .
- Effectuez un traitement par lots de tâches , c'est-à-dire exécutez de nombreuses tâches à la fois.
- Intégrez le processus Extraire, Transformer, Charger .
- Implémentez l' API asynchrone . Il s'avère que l'API asynchrone peut être implémentée non seulement à l'aide de frameworks asynchrones, mais également complètement synchrone;
- Effectuez des tâches périodiques . Aucun projet ne peut se passer de tâches périodiques; pour certains, Cron peut être supprimé, mais il existe également des outils plus pratiques.
- Créez une architecture de déclencheur : pour déclencher un déclencheur, exécutez une tâche qui met à jour les données. Cette opération est effectuée afin de compenser le manque de puissance d'exécution en pré-calculant les données en arrière-plan.
Les tâches en arrière-plan incluent tout type de notification: e-mail, push, bureau - tout cela est envoyé dans les tâches en arrière-plan par un déclencheur. De la même manière, une mise à jour périodique des données financières est lancée.
En arrière-plan, diverses vérifications spécifiques sont effectuées, par exemple, la vérification d'un utilisateur pour fraude. Dans les startups financières,
beaucoup d'efforts et d'attention sont accordés spécifiquement à la sécurité des données , car nous permettons aux utilisateurs d'ajouter leurs comptes bancaires à notre système, et nous pouvons voir toutes leurs transactions. Les fraudeurs peuvent essayer d'utiliser notre service pour quelque chose de mauvais, par exemple, pour vérifier le solde d'un compte volé.
La dernière catégorie de tâches en arrière-plan est celle
des tâches de maintenance : modifier quelque chose, voir, réparer, surveiller, etc.
Pour les notifications
groupées ,
le traitement par lots est utilisé . Une grande quantité de données que nous recevons de nos utilisateurs doit être calculée et traitée d'une certaine manière, y compris en mode batch.
Le même concept inclut l'
extrait classique
, la transformation, la charge :
- charger des données à partir de sources externes (API externe);
- garder non traité;
- exécuter des tâches qui lisent et traitent des données;
- nous enregistrons les données traitées au bon endroit dans le bon format, afin que plus tard, il soit pratique de les utiliser dans l'interface utilisateur, par exemple.
Ce n'est un secret pour personne que l'API asynchrone peut être effectuée à l'aide de simples requêtes d'interrogation: le front-end lance le processus sur le back-end, le back-end lance une tâche qui se lance périodiquement, «déverse» les résultats et met à jour l'état dans la base de données. Le frontend montre à l'utilisateur que cet état interactif est en train de changer. Cela vous permet de:
- exécuter des tâches d'interrogation à partir d'autres tâches;
- exécuter différentes tâches en fonction des conditions.
Dans notre service, cela suffit pour le moment, mais à l'avenir, nous devrons probablement réécrire autre chose.
Exigences relatives aux outils
Pour implémenter ces tâches, nous avions les exigences suivantes pour les outils:
- Fonctionnalité nécessaire pour réaliser nos ambitions.
- Évolutivité sans béquilles.
- Surveiller le système afin de comprendre comment il fonctionne. Nous utilisons le rapport de bogues, donc l'intégration avec Sentry ne sera pas à sa place, avec Django aussi.
- La performance , car nous avons beaucoup de tâches.
- La maturité, la fiabilité et le développement actif sont des choses évidentes. Nous recherchions un outil qui sera soutenu et développé.
- Adéquation de la documentation - aucune documentation nulle part .
Quel outil choisir?
Quelles sont les options sur le marché en 2018 pour résoudre ces problèmes?
Il était une fois des tâches moins ambitieuses, j'ai écrit une
bibliothèque pratique qui est encore utilisée dans certains projets. Il est facile à utiliser et effectue des tâches en arrière-plan. Mais en même temps, aucun courtier n'est nécessaire (ni Celery, ni d'autres), seul le serveur d'applications
uwsgi , qui a un spouleur, est une chose qui commence comme un travailleur séparé. Il s'agit d'une solution très simple - toutes les tâches sont stockées de manière conditionnelle dans des fichiers. Pour des projets simples, cela suffit, mais pour le nôtre, cela ne suffit pas.
D'une manière ou d'une autre, nous avons considéré:
- Céleri (10 000 étoiles sur GitHub);
- RQ (5K étoiles sur GitHub);
- Huey (2K étoiles sur GitHub);
- Dramatiq (1K étoiles sur GitHub);
- Tasktiger (0,5 K étoiles sur GitHub);
- Flux d'air? Luigi
Candidat prometteur 2018
J'aimerais maintenant attirer votre attention sur
Dramatiq . Il s'agit d'une bibliothèque de l'adepte du céleri, qui connaissait tous les inconvénients du céleri et a décidé de tout réécrire, très joliment. Avantages de Dramatiq:
- Un ensemble de toutes les fonctionnalités nécessaires.
- Accent sur la productivité.
- Prise en charge de Sentry et des métriques pour Prometheus prêt à l'emploi
- Une petite base de code clairement écrite, le chargement automatique du code.
Il y a quelque temps, Dramatiq avait des problèmes avec les licences: d'abord il y avait AGPL, puis il a été remplacé par LGPL. Mais maintenant, vous pouvez essayer.
Mais en 2016, en plus du céleri, il n'y avait rien de spécial à prendre. Nous avons aimé sa riche fonctionnalité, puis il convenait parfaitement à nos tâches, car même alors, il était mature et fonctionnel:
- avait des tâches périodiques hors de la boîte;
- pris en charge plusieurs courtiers;
- Intégré à Django et Sentry.
Caractéristiques du projet
Je vais vous parler de notre contexte, pour que l’histoire soit plus claire.
Nous utilisons
Redis comme courtier de messages . J'ai entendu beaucoup d'histoires et de rumeurs selon lesquelles Redis perd des messages, qu'il n'est pas adapté pour être un courtier de messages. Sur l'expérience de production, cela n'est pas confirmé, mais, il s'avère que Redis fonctionne désormais plus efficacement que RabbitMQ (c'est avec Celery, au moins, apparemment, le problème est dans le code d'intégration avec les courtiers). Dans la version 4, le courtier Redis a été corrigé, il a vraiment cessé de perdre des tâches lors des redémarrages et fonctionne de manière assez stable. En 2016, Celery allait abandonner Redis et se concentrer sur l'intégration avec RabbitMQ, mais, heureusement, cela ne s'est pas produit.
En cas de problèmes avec Redis, si nous avons besoin d'une haute disponibilité sérieuse, nous, parce que nous utilisons la puissance d'Amazon, passerons à Amazon SQS ou Amazon MQ.
Nous
n'utilisons pas de backend de résultat pour stocker les résultats , car nous préférons stocker les résultats nous-mêmes où nous voulons et les vérifier comme nous le voulons. Nous ne voulons pas que le céleri fasse cela pour nous.
Nous utilisons un
pool pefork , c'est-à-dire des travailleurs de processus qui créent des fourches de processus distinctes pour une concurrence supplémentaire.
Unité de travail
Nous discuterons des éléments de base afin de mettre à jour ceux qui n'ont pas essayé le céleri, mais qui vont le faire.
L'unité de travail pour le céleri est un défi . Je vais donner un exemple d'une tâche simple qui envoie un e-mail.
Fonction simple et décorateur:
@current_app.task def send_email(email: str): print(f'Sending email to email={email}')
Le lancement de la tâche est simple: soit nous appelons la fonction et la tâche sera exécutée en runtime (send_email (email = "python@example.com")) ou dans le travailleur, c'est-à-dire l'effet même de la tâche en arrière-plan:
send_email.delay(email="python@example.com") send_email.apply_async( kwargs={email: "python@example.com"} )
Pendant deux ans de travail avec Céleri sous des charges élevées, nous avons élaboré des règles de bonne forme. Il y avait beaucoup de râteaux, nous avons appris à les contourner et je vais partager comment.
Conception du code
La tâche peut contenir une logique différente. En général, Celery vous aide à conserver des tâches dans des fichiers ou des packages, ou à les importer de quelque part. Parfois, vous obtenez un tas de logique métier dans un module. À notre avis, la bonne approche du point de vue de la modularité de l'application est de garder un
minimum de logique dans la tâche . Nous utilisons les puzzles uniquement comme «déclencheurs» du code. Autrement dit, la tâche ne porte pas de logique en soi, mais déclenche le lancement de code en arrière-plan.
@celery_app.task(queue='...') def run_regular_update(provider_account_id, *args, **kwargs): """...""" flow = flows.RegularSyncProviderAccountFlow(provider_account_id) return flow.run(*args, **kwargs)
Nous mettons tout le code dans des classes externes qui utilisent d'autres classes. Toutes les tâches consistent essentiellement en deux lignes.
Objets simples dans les paramètres
Dans l'exemple ci-dessus, un certain identifiant est transmis à la tâche. Dans toutes les tâches que nous utilisons, nous
ne transférons que de petites données scalaires , id. Nous ne sérialisons pas les modèles Django pour les transmettre. Même dans ETL, lorsqu'un gros blob de données provient d'un service externe, nous l'enregistrons d'abord, puis exécutons une tâche qui lit tout ce blob par id et le traite.
Si vous ne le faites pas, alors nous avons vu un très grand mélange de mémoire consommée dans Redis. Le message commence à prendre plus de mémoire, le réseau est lourdement chargé, le nombre de tâches traitées (performances) diminue. Tant que l'objet est terminé, les tâches ne sont plus pertinentes, l'objet a déjà été supprimé. Les données devaient être sérialisées - tout n'est pas bien sérialisé en JSON en Python. Nous avions besoin de l'occasion, lorsque nous réessayons des tâches, de décider d'une manière ou d'une autre rapidement que faire de ces données, de les récupérer, de les contrôler.
Si vous transférez des mégadonnées en paramètres, détrompez-vous! Il est préférable de transférer un petit scalaire avec une petite quantité d'informations dans le problème, et à partir de ces informations dans la tâche pour obtenir tout ce dont vous avez besoin.
Problèmes idempotents
Les développeurs de céleri eux-mêmes recommandent cette approche. Lorsque la section de code est répétée, aucun effet secondaire ne doit se produire, le résultat doit être le même. Ce n'est pas toujours facile à réaliser, surtout s'il y a une interaction avec de nombreux services ou des validations en deux phases.
Mais lorsque vous faites tout localement, vous pouvez toujours vérifier que les données entrantes existent et sont pertinentes, vous pouvez vraiment y travailler et utiliser des transactions. S'il existe de nombreuses requêtes dans la base de données pour une tâche et que quelque chose peut mal se passer lors de l'exécution, utilisez les transactions pour annuler les modifications inutiles.
Compatibilité descendante
Nous avons eu des effets secondaires intéressants lorsque nous avons déployé l'application. Quel que soit le type de déploiement que vous utilisez (mise à jour bleue + verte ou continue), il y aura toujours une situation où l'ancien code de service crée des messages pour le nouveau code de travail, et vice versa, l'ancien travailleur reçoit des messages du nouveau code de service, car il a été déployé «en premier» et là, le trafic est allé.
Nous avons détecté des erreurs et perdu des tâches jusqu'à ce que nous apprenions à maintenir la
compatibilité descendante entre les versions . La compatibilité descendante est qu'entre les versions, les tâches doivent fonctionner en toute sécurité, quels que soient les paramètres entrant dans cette tâche. Par conséquent, dans toutes les tâches, nous faisons maintenant une signature «en caoutchouc» (** kwargs). Lorsque vous devez ajouter un nouveau paramètre dans la prochaine version, vous le prendrez de ** kwargs dans la nouvelle version, mais ne le prendrez pas dans l'ancienne - rien ne se cassera. Dès que la signature change et que Celery ne le sait pas, elle se bloque et donne une erreur indiquant qu'il n'y a pas un tel paramètre dans la tâche.
Une manière plus rigoureuse d'éviter de tels problèmes est de versionner les files d'attente de tâches entre les versions, mais c'est assez difficile à implémenter et nous l'avons laissé dans le backlog pour l'instant.
Délais
Des problèmes peuvent survenir en raison d'un nombre insuffisant ou de délais d'attente incorrects.
Ne pas définir de délai d'expiration pour une tâche est mauvais. Cela signifie que vous ne comprenez pas ce qui se passe dans la tâche, comment la logique métier doit fonctionner.
Par conséquent, toutes nos tâches sont suspendues avec des délais d'expiration, y compris globaux pour toutes les tâches, et des délais d'expiration sont également définis pour chaque tâche spécifique.
Doit être apposé: soft_limit_timeout et
expire.Expire, c'est combien une tâche peut vivre en ligne. Il est nécessaire que les tâches ne s'accumulent pas dans les files d'attente en cas de problème. Par exemple, si nous voulons maintenant signaler quelque chose à l'utilisateur, mais que quelque chose s'est produit et que la tâche ne peut être terminée que demain - cela n'a aucun sens, demain le message ne sera plus pertinent. Par conséquent, pour les notifications, nous avons une expiration assez petite.
Notez l'utilisation de
eta (compte à rebours) + visibilité _timeout . La FAQ décrit un tel problème avec Redis - le soi-disant délai de visibilité du courtier Redis. Par défaut, sa valeur est d'une heure: si après une heure, le travailleur voit que personne n'a mis la tâche à exécution, il l'ajoute à nouveau à la file d'attente. Ainsi, si le compte à rebours est de deux heures, après une heure, le courtier découvrira que cette tâche n'est pas encore terminée et en créera une autre. Et en deux heures, deux tâches identiques seront réalisées.
Si le temps ou le compte à rebours estimé dépasse 1 heure, alors, très probablement, l'utilisation de Redis entraînera la duplication des tâches, sauf, bien sûr, si vous avez modifié la valeur de visibilité_timeout dans les paramètres de connexion au courtier.
Nouvelle tentative
Pour les tâches qui peuvent être répétées ou qui peuvent échouer, nous utilisons la stratégie Réessayer. Mais nous l'utilisons avec précaution afin de ne pas submerger les services externes. Si vous répétez rapidement des tâches sans spécifier une interruption exponentielle, un service externe, ou peut-être interne, peut tout simplement ne pas le supporter.
Les paramètres
retry_backoff ,
retry_jitter et
max_retries seraient bien à spécifier explicitement, en particulier max_retries. retry_jitter - un paramètre qui vous permet d'apporter un peu de chaos afin que les tâches ne commencent pas à se répéter en même temps.
Fuites de mémoire
Malheureusement, les fuites de mémoire sont très faciles, et les trouver et les réparer est difficile.
En général, l'utilisation de la mémoire en Python est très controversée. Vous passerez beaucoup de temps et de nerfs à comprendre pourquoi la fuite se produit, puis il s'avère que ce n'est même pas dans votre code. Par conséquent, toujours, lors du démarrage d'un projet, mettez une
limite de mémoire sur le travailleur : worker_max_memory_per_child.
Cela garantit que OOM Killer ne viendra pas un jour, ne tuera pas tous les travailleurs et vous ne perdrez pas toutes les tâches. Le céleri redémarrera les employés en cas de besoin.
Tâches prioritaires
Il y a toujours des tâches qui doivent être accomplies avant tout le monde, plus vite que quiconque - elles doivent être accomplies dès maintenant! Il y a des tâches qui ne sont pas si importantes - laissez-les être accomplies pendant la journée. Pour cela, la tâche a un paramètre
prioritaire. Dans Redis, cela fonctionne de manière assez intéressante - une nouvelle file d'attente est créée avec un nom auquel la priorité est ajoutée.
Nous utilisons une approche différente -
séparer les travailleurs pour les priorités , c'est-à-dire à l'ancienne, nous créons des travailleurs de céleri avec une «importance» différente:
celery multi start high_priority low_priority -c:high_priority 2 -c:low_priority 6 -Q:high_priority urgent_notifications -Q:low_priority emails,urgent_notifications
Celery multi start est un assistant qui vous aide à exécuter toute la configuration de Celery sur une seule machine et à partir de la même ligne de commande. Dans cet exemple, nous créons des nœuds (ou des travailleurs): high_priority et low_priority, 2 et 6 sont simultanés.
Deux travailleurs de haute priorité traitent en permanence la file d'attente des notifications urgentes. Personne d'autre ne prendra ces travailleurs, ils ne liront que les tâches importantes de la file d'attente urgent_notifications.
Pour les tâches sans importance, il existe une file d'attente low_priority. Il y a 6 employés qui reçoivent des messages de toutes les autres files d'attente. Nous abonnons également les travailleurs à faible priorité aux notifications urgentes afin qu'ils puissent aider si les travailleurs à haute priorité ne peuvent pas faire face.
Nous utilisons ce schéma classique pour hiérarchiser les tâches.
Extraire, transformer, charger
Le plus souvent, ETL ressemble à une chaîne de tâches, chacune recevant des informations de la tâche précédente.
@task def download_account_data(account_id) … return account_id @task def process_account_data(account_id, processing_type) … return account_data @task def store_account_data(account_data) …
L'exemple a trois tâches. Celery a une approche du traitement distribué et plusieurs utilitaires utiles, y compris la fonction de
chaîne , qui fait un pipeline sur trois de ces tâches:
chain( download_account_data.s(account_id), process_account_data.s(processing_type='fast'), store_account_data.s() ).delay()
Le céleri démontera le pipeline, effectuera la première tâche dans l'ordre, puis transférera les données reçues vers la seconde et transférera les données que la deuxième tâche renvoie à la troisième. C'est ainsi que nous implémentons des pipelines ETL simples.
Pour les chaînes plus complexes, vous devez connecter une logique supplémentaire. Mais il est important de garder à l'esprit que si un problème survient dans cette chaîne dans une tâche, alors la
chaîne entière s'effondrera . Si vous ne souhaitez pas ce comportement, gérez l'exception et poursuivez l'exécution, ou arrêtez la chaîne entière par exception.
En fait, cette chaîne à l'intérieur ressemble à une grosse tâche, qui contient toutes les tâches avec tous les paramètres. Par conséquent, si vous abusez du nombre de tâches dans la chaîne, vous obtiendrez une consommation de mémoire très élevée et un ralentissement du processus global.
Créer des chaînes de milliers de tâches est une mauvaise idée.Traitement des tâches par lots
Maintenant, la chose la plus intéressante: que se passe-t-il lorsque vous devez envoyer un e-mail à deux millions d'utilisateurs.
Vous écrivez une telle fonction pour contourner tous les utilisateurs:
@task def send_report_emails_to_users(): for user_id in User.get_active_ids(): send_report_email.delay(user_id=user_id)
Cependant, le plus souvent, la fonction recevra non seulement l'ID utilisateur, mais également la table entière des utilisateurs en général. Chaque utilisateur aura sa propre tâche.
Il y a plusieurs problèmes dans cette tâche:
- Les tâches sont lancées séquentiellement, c'est-à-dire que la dernière tâche (deux millionième utilisateur) commencera dans 20 minutes et peut-être que d'ici ce délai, elle fonctionnera déjà.
- Tous les identifiants utilisateur sont d'abord chargés dans la mémoire de l'application, puis dans la file d'attente - delay () effectuera 2 millions de tâches.
Je l'ai appelé Task flood, le graphique ressemble à ceci.
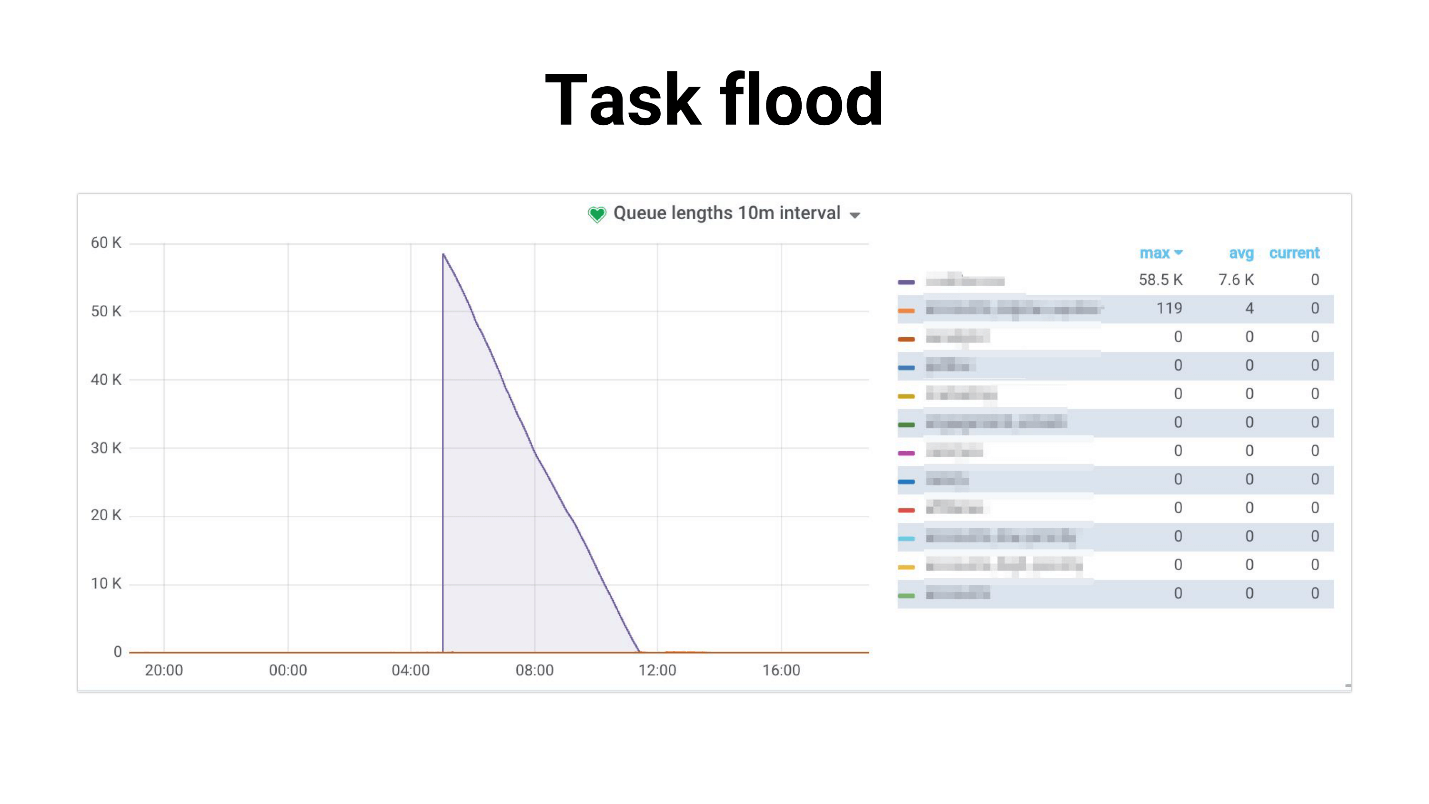
Il y a un afflux de tâches que les travailleurs commencent lentement à traiter. Ce qui suit se produit si les tâches utilisent une réplique maîtresse, le projet entier commence à se fissurer, rien ne fonctionne. Voici un exemple de notre pratique, où l'utilisation du processeur DB était de 100% pendant plusieurs heures, pour être honnête, nous avons réussi à avoir peur.

Le problème est que le système est fortement dégradé avec une augmentation du nombre d'utilisateurs. La tâche qui concerne la planification:
- nécessite de plus en plus de mémoire;
- s'exécute plus longtemps et peut être "tué" par le délai d'expiration.
Une inondation de tâches se produit: les tâches s'accumulent dans les files d'attente et créent une charge importante non seulement sur les services internes, mais également sur les services externes.
Nous avons essayé
de réduire la compétitivité des travailleurs , cela aide dans un sens - la charge sur le service est réduite. Ou vous pouvez faire
évoluer les services internes . Mais cela ne résoudra pas le problème du problème du générateur, qui prend encore beaucoup. Et n'affecte en rien la dépendance à l'égard des performances des services externes.
Génération de tâches
Nous avons décidé de prendre un chemin différent. Le plus souvent, nous n'avons pas besoin d'exécuter les 2 millions de tâches pour le moment. Il est normal que l'envoi de notifications à tous les utilisateurs prenne, par exemple, 4 heures si ces lettres ne sont pas si importantes.
Nous avons d'abord essayé d'utiliser
Celery.chunks :
send_report_email.chunks( ({'user_id': user.id} for user in User.objects.active()), n=100 ).apply_async()
Cela n'a pas changé la situation, car, malgré l'itérateur, tous les user_id seront chargés en mémoire. Et tous les travailleurs reçoivent une chaîne de tâches, et bien que les travailleurs se détendent un peu, nous ne sommes finalement pas satisfaits de cette décision.
Nous avons essayé de définir
rate_limit pour les travailleurs afin qu'ils ne traitent qu'un certain nombre de tâches par seconde, et nous avons découvert qu'en fait rate_limit spécifié pour la tâche est rate_limit pour le travailleur. Autrement dit, si vous spécifiez rate_limit pour la tâche, cela ne signifie pas que la tâche sera exécutée 70 fois par seconde. Cela signifie que le travailleur l'exécutera 70 fois par seconde, et selon ce que vous avez avec les travailleurs, cette limite peut changer dynamiquement, c'est-à-dire real limit rate_limit * len (travailleurs).
Si le travailleur démarre ou s'arrête, le total rate_limit change. De plus, si vos tâches sont lentes, alors toutes les prélecture de la file d'attente qui remplit le travailleur seront obstruées par ces tâches lentes. Le travailleur regarde: «Oh, j'ai cette tâche dans rate_limit, je ne peux plus l'exécuter. Et toutes les tâches suivantes dans la file d'attente sont exactement les mêmes - laissez-les se bloquer! » - et en attente.
Chunkificator
À la fin, nous avons décidé d'écrire la nôtre et avons créé une petite bibliothèque, qui s'appelait Chunkificator.
@task @chunkify_task(sleep_timeout=...l initial_chunk=...) def send_report_emails_to_users(chunk: Chunk): for user_id in User.get_active_ids(chunk=chunk): send_report_email.delay(user_id=user_id)
Il prend sleep_timeout et initial_chunk et s'appelle avec un nouveau morceau. Chunk est une abstraction sur des listes entières, ou sur des listes date ou datetime. Nous transmettons le bloc à une fonction qui reçoit les utilisateurs uniquement avec ce bloc et exécute les tâches pour ce bloc uniquement.
Ainsi, le générateur de tâches exécute uniquement le nombre de tâches nécessaires et ne consomme pas beaucoup de mémoire. L'image est devenue comme ça.

Le point culminant est que nous utilisons des morceaux épars, c'est-à-dire que nous utilisons des instances dans la base de données comme identifiant de morceau (certaines d'entre elles peuvent être ignorées, donc il peut y avoir moins de tâches). En conséquence, la charge s'est avérée plus uniforme, le processus est devenu plus long, mais tout le monde est bel et bien vivant, la base ne se fatigue pas.
La bibliothèque est implémentée pour Python 3.6+ et est disponible sur GitHub. Il y a une nuance que je prévois de corriger, mais pour l'instant le bloc datetime a besoin d'un sérialiseur de cornichons - beaucoup ne seront pas en mesure de le faire.
Quelques questions rhétoriques - d'où viennent toutes ces informations? Comment avons-nous découvert que nous avions des problèmes? Comment savez-vous qu'un problème deviendra bientôt critique et que vous devez déjà commencer à le résoudre?
La réponse est, bien sûr, la surveillance.
Suivi
J'aime vraiment la surveillance, j'aime tout surveiller et garder le doigt sur le pouls. Si vous ne gardez pas votre doigt sur le pouls, vous marcherez constamment sur le râteau.
Questions de surveillance standard:
- La configuration de travail / simultanée actuelle gère-t-elle la charge?
- Quelle est la dégradation du temps d'exécution des tâches?
- Combien de temps les tâches sont-elles alignées? Soudain, la ligne est déjà bondée?
Nous avons essayé plusieurs options. Le céleri a une interface
CLI , il est assez riche et donne:
- inspecter - informations sur le système;
- contrôle - gérer les paramètres du système;
- purge - effacer les files d'attente (force majeure);
- événements - interface utilisateur de la console pour afficher des informations sur les tâches en cours.
Mais il est difficile de vraiment surveiller quelque chose. Il est mieux adapté aux fioritures locales ou si vous souhaitez modifier un certain rate_limit lors de l'exécution.
NB: vous devez avoir accès au courtier de production pour utiliser l'interface CLI.
Celery Flower vous permet de faire la même chose que la CLI, uniquement via l'interface web, et ce n'est pas tout. Mais il construit des graphiques simples et vous permet de modifier les paramètres à la volée.
En général, Celery Flower convient pour voir comment tout fonctionne dans de petites configurations. De plus, il prend en charge l'API HTTP, ce qui est pratique si vous écrivez l'automatisation.
Mais nous nous sommes
installés sur Prométhée. Ils ont pris l'
exportateur actuel: correction de fuites de mémoire; métriques ajoutées pour les types d'exceptions; ajout de mesures pour le nombre de messages dans les files d'attente; Intégré avec des alertes dans Grafana et réjouissez-vous. Il est également publié sur GitHub, vous pouvez le voir
ici .
Exemples à Grafana

Statistiques ci-dessus pour toutes les exceptions: quelles exceptions pour quelles tâches. Vous trouverez ci-dessous le temps de terminer les tâches.

Qu'est-ce qui manque dans le céleri?
Ceci est un cadre verdoyant, il a beaucoup de choses, mais nous manquons! Il n'y a pas assez de petites fonctionnalités, telles que:
- Rechargement automatique du code pendant le développement - ne prend pas en charge ce céleri - redémarrage.
- Les mesures pour Prométhée sont prêtes à l'emploi, mais Dramatiq le peut.
- Prise en charge du verrouillage des tâches - de sorte qu'une seule tâche s'exécute à la fois. Vous pouvez le faire vous-même, mais Dramatiq et Tasktiger ont un décorateur pratique qui garantit que toutes les autres tâches similaires seront bloquées.
- Rate_limit pour une tâche - pas pour le travailleur.
Conclusions
Malgré le fait que Celery est un framework que beaucoup utilisent dans la production, il se compose de 3 bibliothèques - Celery, Kombu et Billiard. Ces trois bibliothèques sont développées par des co-développeurs et peuvent libérer une dépendance et casser votre assembly.
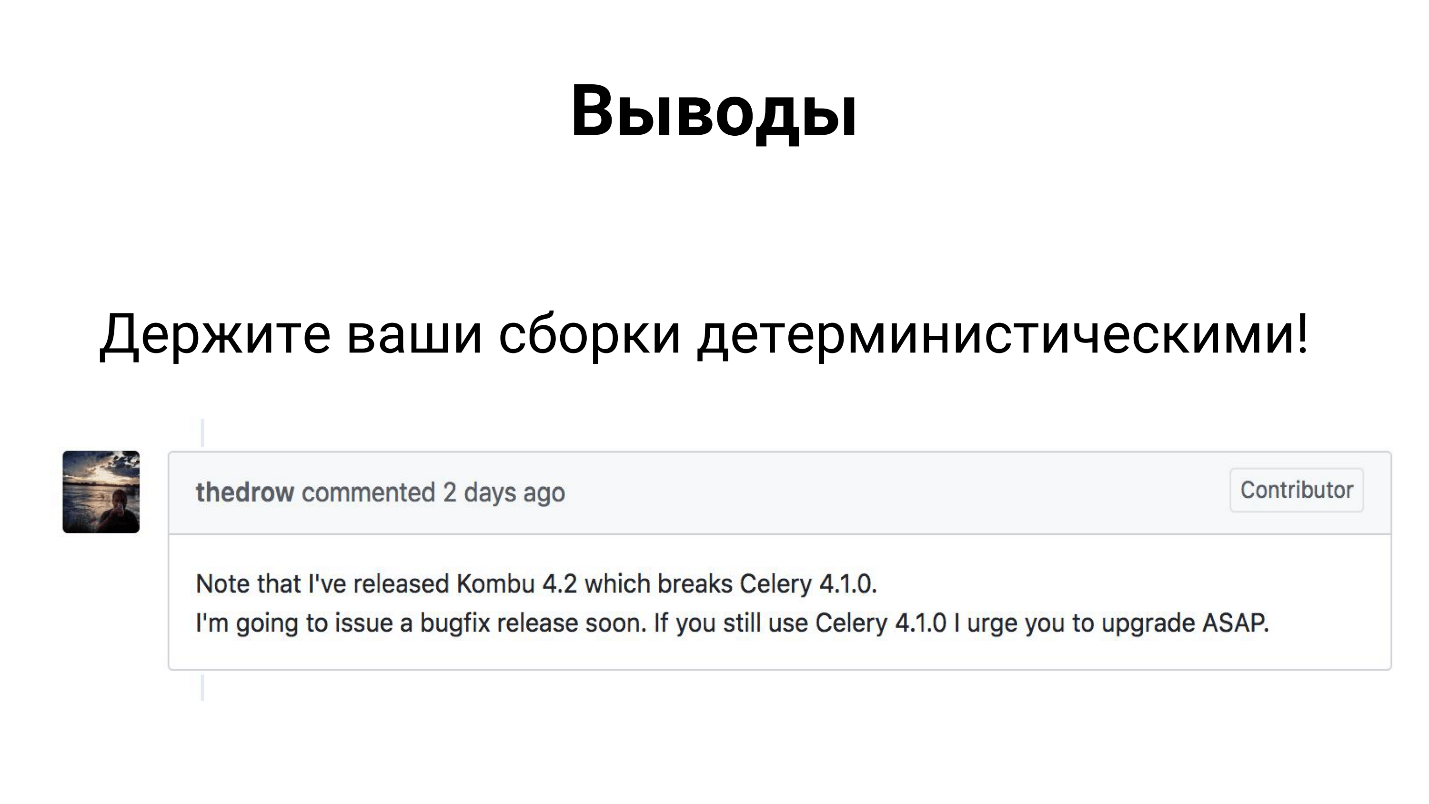
Par conséquent, j'espère que vous l'avez déjà réglé d'une manière ou d'une autre et rendu vos assemblages déterministes.
En fait, les conclusions ne sont pas si tristes.
Le céleri fait face à ses tâches dans notre projet fintech sous notre charge. Nous avons acquis une expérience que j'ai partagée avec vous, et vous pouvez appliquer nos solutions ou les affiner et aussi surmonter toutes vos difficultés.
N'oubliez pas que le
suivi doit être un élément essentiel de votre projet . Ce n'est que par la surveillance que vous pouvez savoir où vous avez quelque chose de mal, ce qui doit être corrigé, ajouté, corrigé.
Contactez le conférencier Oleg Churkin :
Bahusss ,
facebook et
github .
Le prochain grand Python Conf ++ de Moscou se tiendra à Moscou le 5 avril . Cette année, nous essaierons d'intégrer tous les avantages en une journée en mode expérimental. Il n'y aura pas moins de rapports, nous allouerons un flux entier aux développeurs étrangers de bibliothèques et de produits bien connus. De plus, le vendredi est une journée idéale pour les after parties, qui, comme vous le savez, fait partie intégrante de la conférence sur la communication.
Rejoignez notre conférence Python professionnelle - soumettez votre rapport ici , réservez votre billet ici . En attendant, les préparatifs sont en cours, des articles sur Moscow Python Conf ++ 2018 apparaîtront ici.