Nous écrivons tous du code. Beaucoup de code. Bien sûr, il y a des erreurs. Parfois, c'est juste un code tordu, et parfois le prix d'une erreur est un
vaisseau spatial éclaté. Bien sûr, personne ne fait des jambages intentionnels, tout le monde essaie de surveiller la qualité au mieux de ses capacités, mais sans outils d'analyse statique, il est à peine possible d'être sûr que tout est parfait.
Les linters aident à apporter du code à un seul style et à éviter les erreurs. Certes, seulement si vous êtes prêt à souffrir, et ne rejetez pas finalement «pylint: disable», seulement pour le retarder. Ce qui devrait être un linter et pourquoi Pylint ne peut pas le faire, connaît Nikita
Sobolevn , qui comprend et aime tellement les linters qu'il a même nommé son entreprise pour ne pas les contrarier - wemake.services.
Vous trouverez ci-dessous la version texte du rapport sur
Moscou Python Conf ++ sur les linters, comment les faire correctement et comment ne pas le faire. La présentation a eu beaucoup d'interactivité, en ligne et de communication avec le public. L'orateur, en cours de route, a mené des sondages et tenté de convaincre le public: il a regardé la tendance, et comme dans le débat, il a essayé d'égaliser le rapport et de changer l'opinion publique. Une partie des sondages est tombée dans le décryptage, mais pas tous, donc une vidéo est jointe pour compléter l'image.
Pourquoi avons-nous besoin de linters?
La tâche la plus importante de linter consiste
à uniformiser le code . Il existe de nombreuses options pour écrire la même chose en Python: mettez une virgule ici ou là, oubliez de fermer les crochets ou n’oubliez pas. Lorsque les gens écrivent du code depuis longtemps, cela devient comme une courtepointe patchwork de pièces disparates cousues à différents moments. C'est désagréable de travailler avec une telle couverture, cela décourage la lecture du code, ce qui est très mauvais.
Les linters facilitent la vie lors d'un examen . J'en viens à la révision du code et je pense: «Je ne veux pas faire ça! Maintenant, il y aura des espaces supplémentaires et d'autres bêtises! » J'aimerais que quelqu'un d'autre prépare un bon code, et après cela j'apprécierai les grandes choses conceptuelles.
Parfois, je regarde le code et je pense que tout va bien, puis je vois dans certaines fonctions trop de variables ou une erreur à laquelle je n'ai pas fait attention. L'automatisation trouverait cette erreur, mais j'ai regardé. Afin de ne pas tomber dans de telles situations - j'utilise le
linter - il
trouve tout ce qui est caché et difficile à trouver.Que sont les linters?
Les plus simples ne vérifient que le style , par exemple
Flake8 . Dans une certaine mesure, également noir, mais c'est plutôt un autoformeur-linter.
Les linters testent la sémantique plus difficile , et pas seulement la stylistique: ce que vous faites, pourquoi et vous frappent sur les mains si vous écrivez avec des erreurs. Un bon exemple est
Pylint , que nous connaissons, utilisons et aimons tous. J'appelle ces linters -
Meilleures pratiques . Le troisième type est la
vérification de type , ces linter sont un peu sur le côté. La vérification de type en Python est nouvelle, elle est maintenant effectuée par deux plates-formes concurrentes:
Mypy et
Pyre .
Comment utiliser linter?
Je ne prétends pas que le linter est une panacée et un remplacement pour tout. Ce n'est pas le cas. Linter - la première étape de la pyramide, par laquelle le code entre en production.
Il y a trois étapes dans la pyramide:
- Lancez linter . Il est très rapide et n'a besoin que du code source - pas d'infrastructure, pas de paramètres. Vérifiez: le premier bilan de santé est passé - tout va bien, nous y travaillons.
- Étape de test . Ce processus est plus compliqué et plus long en raison d'erreurs non codées. Nous aurons déjà besoin d'une configuration correcte et complète de l'ensemble de l'application.
- Revue d'étape .
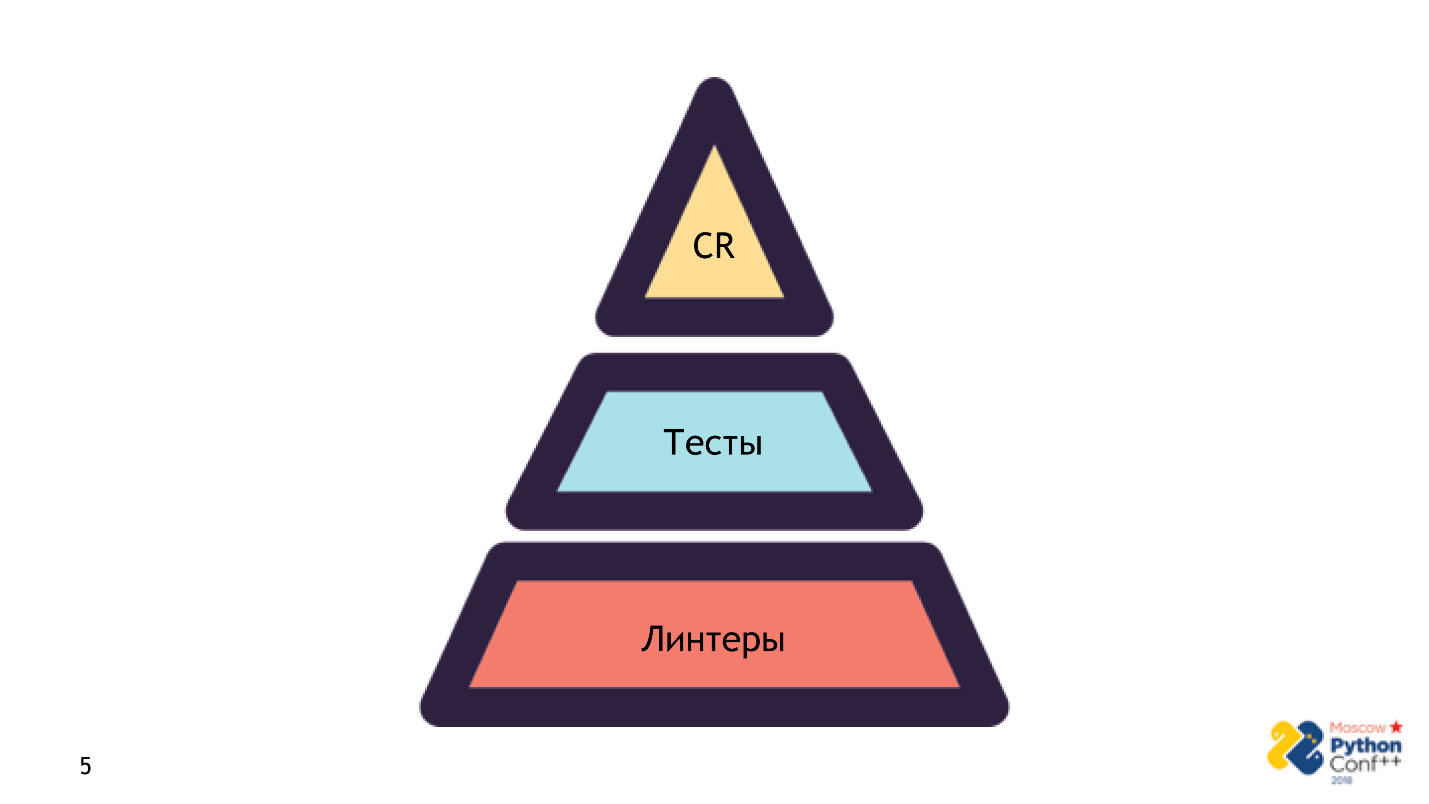 Ce sont les étapes nécessaires
Ce sont les étapes nécessaires pour que le code entre en production. Si vous n'avez pas franchi une étape, oublié quelque chose ou que le critique a dit que cela ne fonctionnerait pas, vous verrez l'inscription: échoué - le mauvais code ne se met pas en production.
Utilisez-vous un linter au travail?
Si vous demandez aux développeurs d'une entreprise difficile, dans laquelle ils travaillent 7 jours par semaine, s'ils utilisent un linter, alors il s'avère qu'au moins un tiers d'entre eux utilisent des linters très strictement:
les baisses de CI, les contrôles sont sévères . Les autres appliquent à peu près également le linter
au style de test ,
jamais et en tant que
système de rapport : ils démarrent le linter, génèrent un rapport et voient à quel point tout est mauvais. Les linters sont utilisés, et c'est bien. Dans notre entreprise, tout a été construit très durement: liens durs, beaucoup de contrôles, double revue de code.
Examen du code
Des problèmes surviennent juste à ce stade. Il s'agit de l'étape la plus difficile et la plus difficile de la pyramide: la révision du code ne peut pas être automatisée et, si possible, elle conduira à l'automatisation de l'écriture du code. Ensuite, les programmeurs ne seront pas nécessaires.
Le processus standard ressemble à ceci: le code vient pour un examen, je trouve des erreurs et je ne veux plus les faire. Par exemple, j'ai vu que le développeur a attrapé BaseException: «Ne faites pas ça. Veuillez ne pas attraper! " Après 10 jours, la même chose. Je vous rappelle encore:
-
Nous n'attrapons pas BaseException."
Bien, je comprends."Une année passe - la même erreur. Un nouvel homme arrive - la même erreur. Je pense - comment pouvons-nous tout automatiser pour que la situation ne se reproduise plus et ne nous vienne à l'esprit: «
Entaillons notre linter? »Créons un package ouvert, y mettons toutes les règles que nous utilisons dans le travail et automatisons le contrôle des règles afin que chaque fois que nous n'écrivions pas à la main. Nous automatisons tout bien et tout de suite!
Naturellement, vous pouvez dire: «Les
linters prêts à l'emploi existent déjà, ils fonctionnent, tout le monde les utilise - pourquoi faire les leurs?», Et vous aurez tout à fait raison, car il y a vraiment des linters. Voyons lesquels et ce qu'ils font.
Pylint
Sur la rubrique "
Pourquoi pas Pylint?" "J'ai entendu cette question à plusieurs reprises. Je vais lui répondre plus doucement. Pylint est un excellent outil de rock star pour le code Python, mais il a des fonctionnalités que je ne veux pas voir dans mon linter.
Il mélange tout ensemble: vérifications stylistiques, meilleures pratiques et vérification de type . La vérification de type Pylint est sous-développée car il n'y a pas d'informations sur le type: elle essaie de l'afficher d'une manière ou d'une autre, mais cela ne fonctionne pas très bien. Par conséquent, souvent lorsque j'écris
model_name.some_property sur Django, je peux voir l'erreur: "Désolé, il n'y a pas une telle propriété - vous ne pouvez pas l'utiliser!" Je me souviens qu'il y a un plugin, je l'installe, puis j'utilise Celery, cela commence aussi une sorte de problème, j'installe le plugin pour Celery, j'utilise une autre bibliothèque magique, et en conséquence, j'écris partout: "pylint: disable" ... Ce n'est pas ça ce que je veux obtenir de linter.
Une autre fonctionnalité cachée à l'utilisateur est
que Pylint a sa propre implémentation de l'arbre de syntaxe abstraite en Python . Voici à quoi ressemble le code lorsque vous l'analysez et obtenez des informations sur l'arborescence des nœuds qui composent le code. Je ne fais pas vraiment confiance à mes propres implémentations, car elles ont toujours tort.
En plus de Pylint, il existe d'autres linters qui font également leur travail.
Sonarquube
Un outil merveilleux, mais distinct, qui vit quelque part près de votre projet.
- SonarQube ne pourra pas fonctionner souvent : il doit être déployé quelque part, regarder, surveiller, configurer.
- Il est écrit en Java . Si vous souhaitez corriger votre linter pour Python, vous écrirez du code en Java. Je pense que conceptuellement, c'est faux - un développeur qui peut écrire en Python devrait être capable d'écrire du code pour tester Python.
La société qui développe SonarQube se penche spécifiquement sur le concept de développement de produits. Cela peut être un problème.
L'avantage de SonarQube est qu'il a des contrôles très sympas qui montrent la complexité, les erreurs cachées possibles et les bogues. J'aime les chèques, je les quitterais et changerais de plateforme.
Flake8
Un merveilleux linter est très simple, mais avec un problème:
il y a peu de règles par lesquelles il vérifie la qualité de l'écriture du code. Dans le même temps, Flake8 a beaucoup de plugins très simples: le plugin minimum est 2 méthodes qui doivent être implémentées. J'ai pensé - prenons Flake8 comme base et écrivons des plugins, mais avec notre compréhension des avantages pour l'entreprise. Et nous l'avons fait.
Le linter le plus rigoureux au monde
Nous avons créé un outil dans lequel nous avons collecté tout ce que nous pensons être bon pour Python et appelé
wemake-python-styleguide . Le plugin a été publié publiquement, car je pense que l'
Open Source par défaut est une bonne pratique . Je suis profondément convaincu que de nombreux outils bénéficieront s'ils sont téléchargés sur Open Source. Pour notre instrument, nous avons trouvé le slogan:
"Le linter le plus rigoureux du monde!"Le mot clé dans notre linter est strict, ce qui signifie douleur et souffrance.
Si vous utilisez le linter, et cela ne vous fait pas souffrir, vous vous agrippez la tête: "Pourquoi ne l'aimez-vous pas, maudit", alors c'est un mauvais linter. Il ignore les erreurs, ne surveille pas suffisamment la qualité du code et nous n'en avons pas besoin. Nous avons besoin des plus strictes au monde, ce qui vérifie beaucoup. Nous avons maintenant environ
250 tests différents dans les deux catégories : stylistique et meilleures pratiques, mais sans vérification de type. Mypy s'y est engagé, nous ne le concernons en aucune façon.
Notre linter n'a
aucun compromis . Nous n'avons pas de règles de la catégorie "Je ne voudrais pas faire ça, mais si tu le veux vraiment, alors tu peux." Non, nous parlons toujours durement - nous ne le faisons pas, parce que c'est mauvais. Ensuite, les gens viennent et disent: "Il y a 2,5 cas d'utilisation où cela est possible en principe!". S'il y a de tels cas, écrivez clairement que cette ligne est autorisée pour que le linter l'ignore, mais expliquez pourquoi. Ce devrait être un commentaire sur pourquoi vous avez autorisé une pratique étrange et pourquoi vous le faites. Cette approche est également utile pour documenter du code.
Le linter le plus strict
ne nécessite pas de paramètres (WIP) . Nous avons encore des paramètres, mais nous voulons nous en débarrasser: en toute liberté, l'utilisateur va sûrement configurer pour que le linter ne fonctionne pas correctement.
Un bon outil n'a pas besoin de paramètres - il a de bonnes valeurs par défaut.
Avec cette approche, le code sera cohérent et fonctionnera de la même manière pour tout le monde, du moins en théorie. Nous y travaillons toujours, et bien qu'il existe des paramètres, vous pouvez utiliser notre outil et le personnaliser par vous-même.
De qui dépendons-nous?
À partir d'un grand nombre d'outils.
- Flake8 .
- Eradicate est un plugin sympa qui trouve des fragments commentés dans le code et vous fait les supprimer, car stocker du code mort dans un projet est mauvais. Nous n'y sommes pas autorisés.
- Isort est un outil qui vous oblige à trier correctement les importations: dans l'ordre, en retrait, de belles citations.
- Bandit est un excellent outil pour vérifier statiquement la sécurité du code. Il trouve des mots de passe câblés, une utilisation maladroite d'
assert dans le code, appelle Popen , sys.exit et dit que tout cela ne peut pas être utilisé, mais si vous le souhaitez, il vous demande d'écrire la raison. - Et plus de 20 plugins qui vérifient les crochets, les guillemets et les virgules.
Que vérifions-nous?
Nous utilisons et appliquons quatre groupes de règles.
La complexité est le plus gros problème. Nous ne savons pas ce qu'est la complexité et nous ne la voyons pas dans le code. Nous regardons le code avec lequel nous travaillons tous les jours et il semble que ce ne soit pas compliqué - prenez-le, lisez-le, tout fonctionne. Ce n'est pas le cas. Le code simple est un code familier. La complexité a des critères clairs que nous testons. À propos des critères eux-mêmes - plus tard. Si le code viole les critères, alors nous disons: "Le code est complexe, réécrivez!"
Les noms des variables sont un problème de programmation non résolu. Qui lira quand et dans quel contexte n'est pas clair. Nous essayons de rendre les noms aussi cohérents et compréhensibles que possible, mais bien que nous essayions, le problème n'est pas encore complètement résolu.
Par
souci de cohérence , nous avons une règle simple - écrivez la même partout. S'il existe une approche approuvée, utilisez-la partout. Peu importe que cela vous plaise ou non, la cohérence est plus importante.
Nous essayons d'utiliser uniquement les
meilleures pratiques. Si nous savons que certaines pratiques ne sont pas très bonnes, nous interdisons leur utilisation. Si le développeur veut utiliser une pratique interdite, nous attendons de lui des arguments: pourquoi et pourquoi appliquer. Peut-être, au cours du processus de description, une compréhension viendra de pourquoi elle est mauvaise.
Qu'est-ce que la complexité?
La complexité a des mesures spécifiques que vous pouvez consulter et dire si elles sont difficiles ou non. Il y en a beaucoup.
Complexité cyclomatique - la complexité cyclomatique préférée de tous. Il trouve dans le code un grand nombre de structures imbriquées
if ,
for , d'autres, et indique trop de branchement du code et des difficultés de lecture. Avec le code embarqué, tout va mal: vous lisez, lisez, lisez - revenez en arrière, lisez, lisez, lisez - sautez, puis passez à un autre cycle. Il est impossible de passer un tel code en toute sécurité de haut en bas.
Arguments, instructions et retours. Il s'agit de métriques quantitatives: combien d'arguments se trouvent dans la fonction ou dans la méthode, combien se trouvent dans le corps de cette fonction ou dans la méthode des instructions et des retours.
La cohésion et le couplage sont des métriques de POO populaires.
La cohésion montre la connectivité de la classe à l'intérieur. Par exemple, il y a une classe, et à l'intérieur vous utilisez toutes les méthodes et propriétés - tout ce que vous avez déclaré. C'est une bonne classe avec une connectivité élevée à l'intérieur.
Le couplage est la mesure dans laquelle les différentes parties du système sont connectées: modules et classes. Nous voulons atteindre une connectivité maximale au sein de la classe et une connectivité minimale à l'extérieur. Ensuite, le système est facilement entretenu et fonctionne bien.
Jones Complexity - J'ai emprunté cette métrique, mais seulement parce que c'est une bombe! La complexité de Jones détermine la complexité d'une ligne - plus la ligne est complexe, plus elle est difficile à comprendre, car la mémoire humaine à court terme ne peut pas traiter plus de 5 à 9 objets à la fois. Ceci est le soi-disant
portefeuille de Miller .
Nous examinons ces métriques importantes et quelques autres, qui sont beaucoup plus grandes, et déterminons si le code est approprié ou non. À notre avis, la
complexité est une cascade .
Difficulté de la cascade
La difficulté commence par le fait que nous avons écrit la ligne, et c'est toujours bon. Mais ensuite, l'entreprise vient et dit que les prix ont doublé, et nous multiplions par 2. À ce stade, Jones Complexity devient fou et rapporte que maintenant la ligne est trop compliquée - il y a trop de logique.
Eh bien, nous commençons une nouvelle variable, et l'analyseur de complexité de la fonction dit:
-
Non, ce n'est pas le cas - maintenant il y a trop de variables à l'intérieur de la fonction.Je vais créer une nouvelle
méthode et je vais lui passer des arguments. Maintenant, vérifier le nombre d'arguments de fonction, ou le nombre de méthodes à l'intérieur de la
classe, dit que cela est également impossible - la classe est trop complexe et doit être divisée en deux parties. Crashed en mettant en évidence une autre classe. Maintenant, il y a plus de classes et tout va bien, mais vérifier la complexité du
module signale que le module est maintenant trop complexe et doit être refactorisé. Pourquoi?!
C'est ce qu'on appelle la souffrance. C'est pourquoi je dis qu'un linter devrait vous faire souffrir. Nous avons commencé par multiplier par 2 sur une seule ligne et nous avons fini par
refactoriser l'ensemble du système . L'ajout d'un petit morceau de code conduit à la refactorisation de modules entiers, car la complexité se déploie comme une cascade et couvre tout ce qui est possible.
"Besoin de refactoriser" - cette chose vous fait refactoriser le code. Vous ne pouvez pas vous contenter de vous asseoir: "Je ne touche pas à ce code, il semble fonctionner." Non, un jour vous changerez le code ailleurs, et une cascade de complexité inondera le module que vous n'avez pas touché et vous devrez le refactoriser. Je pense que le refactoring est bon, et plus il l'est, plus votre système est stable et performant.
Et tout le reste est subjectif!Parlons maintenant des goûts. Ceci est une partie holistique et interactive!
Holivar
Supportons, les commentaires sont ouverts. Tout d'abord, permettez-moi de vous rappeler que les noms sont un problème complexe et non résolu. Vous pouvez vous battre pour nommer une variable, mais nous avons quelques approches qui aident au moins à ne pas faire d'erreurs évidentes.
Noms
Comment aimez-vous:
var, value, item, obj, data, result ? Qu'est-ce que les
données ? Quelques données. Quel est le
résultat ? Une sorte de résultat. Souvent, je vois la variable de
résultat et un appel à une méthode infernale dans une classe incompréhensible - et je pense: «Quel est ce résultat? Pourquoi est-il ici? "
De nombreux développeurs sont en désaccord avec moi et disent que la
valeur est un nom de variable parfaitement normal:
-
J'utilise toujours la clé et la valeur!-
Pourquoi ne pas utiliser la clé et la valeur, mais dire que la clé est le nom et la valeur est le nom de famille? Pourquoi il est impossible de nommer prénom et nom - maintenant il y a un contexte.Habituellement, les gens sont d'accord, mais ils se disputent quand même. C'est une chose très holistique: au moins 3 personnes ont passé une heure de leur vie sur moi pour en discuter avec moi.
Est-il correct de nommer les variables avec une seule lettre?
Par exemple,
q ? Nous connaissons tous le cas classique:
for i in some_iterable: Qu'est-ce que
je suis ? En C, c'est une pratique standard, et tout en découle. Mais en Python, les collections et les itérateurs. Les collections contiennent des éléments qui ont des noms - appelons-les différemment.
La moitié des développeurs pensent que l'appel des variables i, x, y, z est normal.
Je crois que vous ne pouvez pas nommer de noms avec une seule lettre. Je veux plus de contexte et c'est bien que la seconde moitié des développeurs soit d'accord avec moi. Si en C, cela est toujours permis en raison de l'héritage historique, alors en Python c'est un très gros problème et vous n'avez pas besoin de le faire.
Cohérence
Choisissons simplement un moyen parmi tant d'autres et disons: «Faisons-le.» Qu'elle soit bonne ou mauvaise - cela n'a plus d'importance - est tout simplement cohérent.
Nous ne parlons que de Python 3, Legacy n'est pas du tout pris en compte.
J'ai un argument: quand nous héritons de quelque chose, nous devons savoir de quoi - ce serait bien de voir le nom du parent. Le plus drôle, c'est qu'en général, nous voyons le nom du parent, sauf lorsqu'il s'agit d'un
objet . Par conséquent, j'ai formulé une règle pour moi-même: lorsque j'écris une classe, j'hérite de quelque chose - j'écris toujours le nom du parent. Peu importe ce que ce sera - Modèle, objet ou autre chose.
S'il y a le choix d'écrire la
Class Some(object) ou la
class Some , alors je choisirai la première. D'une part, cela montre que nous écrivons clairement toujours ce dont nous héritons. Par contre, il n'y a pas de
verbosité particulière: on ne perd rien de quelques frappes supplémentaires.
Les deux tiers des développeurs connaissent mieux la deuxième option, et je sais même pourquoi. Mon hypothèse: tout cela parce que nous avons depuis longtemps migré de la deuxième version de Python vers la troisième, et maintenant nous montrons que nous écrivons dans le troisième Python. Je ne sais pas comment l'hypothèse est correcte, mais il me semble que c'est le cas.
Les lignes F sont terribles?
Options de réponse:
- Oui: ils perdent leur contexte, mettent de la logique dans le modèle et ne peluchent pas (38%).
- Non! Ils sont un miracle! - (62%).
Il existe une hypothèse selon laquelle les lignes f sont terribles. Ils poussent n'importe quoi en eux! les lignes f ne sont pas les mêmes que
.format , les différences sont dramatiques. Lorsque nous déclarons un modèle, puis le formater, nous effectuons deux actions séparément: d'abord nous définissons le modèle, puis le formater. Lorsque nous déclarons une ligne f, nous effectuons deux actions simultanément: nous déclarons immédiatement le modèle et le formatons au même moment.
Il y a deux problèmes avec les lignes f. Nous avons déclaré un modèle pour la f-line et tout fonctionne. Et puis nous décidons de déplacer le modèle 2 lignes vers le haut ou de le déplacer vers une autre fonction - et tout se casse.
Désormais, aucun contexte ne nous a permis de formater des chaînes et nous ne pouvons pas les traiter correctement. Le deuxième gros problème avec les lignes f: elles vous permettent de faire la chose terrible -
coller la logique dans le modèle . Supposons qu'il y ait une ligne dans laquelle nous insérons simplement le nom d'utilisateur et le mot "Bonjour" - c'est normal. Il n'y a rien de particulièrement effrayant, mais ensuite nous voyons que le nom d'utilisateur vient en majuscules, nous décidons de le traduire dans une casse de titre et d'écrire directement dans le modèle
username.title() . Ensuite, les conditions, les cycles, les importations apparaissent dans le modèle. Et toutes les autres parties de php.
Tous ces problèmes me font dire que les
lignes f sont un mauvais sujet , nous ne les utilisons pas. Le plus drôle, c'est que nous n'avons pas de boîtier dans lequel seules les lignes f nous conviennent. Habituellement, tout formatage convient, mais nous avons choisi
.format - tout le reste est impossible - ni
% , ni f-lines. Le travail de
.format également pelucheux, car à l'intérieur, vous pouvez mettre des guillemets bouclés et écrire le nom de la variable ou son ordre.
Au cours du rapport, le nombre d'adversaires de la ligne f est passé de 33 à 38% - c'est une petite mais une victoire.
Les chiffres
Aimez-vous les nombres comme celui-ci:
final_score = 69 * previous result / 3.14 . Cela ressemble à une ligne de code standard, mais qu'est-ce que 69? De telles questions se posent souvent lorsque je regarde le code que j'ai écrit il y a quelque temps, et le gestionnaire à ce moment-là dit:
-
Veuillez multiplier par 147.-
Pourquoi à 147?-
Nous avons une telle tarification.J'ai multiplié et oublié, ou pendant longtemps j'ai pris une certaine valeur du coefficient pour que tout fonctionne - puis j'ai oublié comment je l'ai ramassé et pourquoi. Il s'avère que d'importants travaux de recherche sont restés cachés derrière un nombre sans titre. Je ne sais même pas ce qu'est ce numéro, mais je ne peux que le trouver, le rappeler et le restaurer d'une manière ou d'une autre en m'engageant plus tard.
Pourquoi ne pas le faire différemment - mettez tous les nombres complexes dans votre propre variable avec le nom et la documentation? Par exemple, pour le nombre 69, écrivez qu'il s'agit de l'indicateur moyen sur le marché, et maintenant la constante a un nom et un contexte. J'écrirai un commentaire que j'ai pris la constante sur le site d'une telle étude. Si la recherche change à l'avenir, je viendrai mettre à jour les données.
Ainsi, nous garantissons qu'aucun chiffre magique ne traversera notre code et ne le compliquera de l'intérieur. Ils font leur chemin en vérifiant la complexité de chaque ligne et disent: "Voici le numéro 4766. Qu'est-ce que c'est, je ne sais pas, triez-le vous-même!" Ce fut une grande découverte pour moi.
En conséquence, nous avons réalisé que nous devons suivre cela, et nous ne manquons aucun chiffre magique dans le code. Il est bon que près de 100% de nos collègues soient d'accord avec nous, et ils n'utilisent pas non plus ces chiffres.
Mais il y a des exceptions - ce sont des nombres de -10 à 10, des nombres 100, 1000 et similaires, simplement parce qu'ils sont souvent trouvés et sans eux est difficile.
Nous sommes durs, mais pas sadiques et réfléchissons un peu.
Utilisez-vous '@staticmethod'?
Réfléchissons à ce qu'est la
méthode statique . Vous êtes-vous déjà demandé pourquoi il se trouve en Python? Non. J'avais un beau Pylint qui disait:
-
Écoutez, vous n'utilisez pas vous- self ,
cls -
faites une méthode statique!-
D'accord, Pylint, je vais faire une méthode statique.Ensuite, j'ai enseigné Python aux débutants, et ils ont demandé ce qu'est la méthode statique et pourquoi elle est nécessaire. Je ne connaissais pas la réponse et je me demandais s'il était possible d'écrire la même chose avec une fonction, ou de ne pas utiliser
self dans une fonction régulière, simplement parce que c'est une telle classe et que quelque chose se passe. Pourquoi avons-nous besoin d'une construction de méthode statique?
J'ai googlé la question, et elle s'est avérée être aussi profonde qu'un trou de lapin. Il existe de nombreux autres langages de programmation dans lesquels la méthode statique n'est pas non plus appréciée. Et bien raisonné - staticmethod casse le modèle objet. En conséquence, je me suis rendu compte - la
méthode statique n'est pas ici , et nous l'avons vu. Maintenant, si nous utilisons le décorateur de méthode statique, le linter dira: "Non, désolé, refactoriser!"
La plupart des développeurs ne sont pas d'accord avec moi, mais environ la moitié pense toujours qu'il vaut mieux écrire des méthodes régulières ou des fonctions régulières au lieu d'une méthode statique.
Logique dans __init __. Ru - bon ou mauvais?
Ceci est mon sujet préféré. Sûrement, quand vous créez un nouveau paquet et que vous l'appelez d'une manière ou d'une autre - cela crée __init __. Ru et vous vous demandez quoi y mettre? Que mettre dans __init __. Ru, et quoi - dans les fichiers côte à côte? Pour moi, c'était une question non triviale, et j'étais toujours perdu: probablement quelque chose de plus important? Alors j'ai pensé - non, au contraire, je mettrai le plus important dans le contexte le plus compréhensible. Si vous mettez quelque chose dans __init __. Ru, puis importez le tout, il s'avère que les importations cycliques sont également mauvaises.
J'ai regardé diverses bibliothèques populaires, j'ai grimpé leur __init __. Ru, et j'ai remarqué qu'il y avait essentiellement des ordures ou une compatibilité descendante. Pour moi, cette question s'est posée brusquement lorsque j'ai commencé à créer de gros packages avec de nombreux sous-packages - vous vous perdez. , . Python, , , __init__. , 90% .
— , API, , - , , ? , , . API . , __init__. - : , , .
,
I_CONTROL_CODE — . , . , , __init__. — . , , , - , .
hasattr ?
hasattr ? , , Python — . hasattr , ().
, , hasattr , , . , hasattr, , . - , Python -, hasattr . , .
getattr « , ». hasattr — getattr,
exception .
50 50 — , , .
,
layer-linter . ? : , , , . , - . - . Je le recommande vivement.
cohesion . , . Cohesion , . False Positive , — , , .
vulture Python . - , Python , . ohesion.
Radon , :
Halstead ,
Maintainability Index , . , — .
Final type
Final- Python. Typing Extensions, , . , - , — , . , - - , ? . . - — , , , .
Gratis
, .

, .
, . , . , Python- , .
, Moscow Python Conf++ , . , , Python-.
. . , , , .