À l'aube de l'apprentissage automatique, la plupart des solutions semblaient très étranges, isolées et inhabituelles. Aujourd'hui, de nombreux algorithmes ML sont déjà alignés dans un familier pour un ensemble de programmeurs de cadres et de boîtes à outils avec lesquels vous pouvez travailler sans entrer dans les détails de leur implémentation.
Soit dit en passant, je m'oppose à une telle approche superficielle, mais je voudrais montrer à mes collègues que cette industrie évolue à pas de géant et qu'il n'y a rien de difficile à appliquer ses réalisations dans des projets de production.
À titre d'exemple, je vais montrer comment vous pouvez aider l'utilisateur à trouver le bon matériel vidéo parmi des centaines d'autres dans notre service de flux de travail.
Dans mon projet, les utilisateurs créent et partagent des centaines de matériaux différents: texte, images, vidéos, articles, documents dans différents formats.
La recherche de documents semble assez simple. Mais que faire de la recherche de contenu multimédia? Pour un service utilisateur complet, vous devez obligatoirement remplir une description, donner un nom à la vidéo ou à l'image, plusieurs balises ne feront pas de mal. Malheureusement, tout le monde ne veut pas passer du temps sur de telles améliorations de contenu. Habituellement, l'utilisateur télécharge un lien vers YouTube, signale qu'il s'agit d'une nouvelle vidéo et clique sur Enregistrer. Que peut faire un service avec un tel contenu «gris»? La première idée est de demander à YouTube? Mais YouTube est également rempli d'utilisateurs (souvent le même utilisateur). Souvent, le matériel vidéo peut ne pas provenir du service Youtube.
L'idée m'est donc venue d'apprendre à notre service à «écouter» une vidéo et à «comprendre» de quoi il s'agit.
J'avoue que cette idée n'est pas nouvelle, mais aujourd'hui pour sa mise en œuvre il n'est pas nécessaire d'avoir une équipe de dix Data Scientists, juste deux jours et un peu de ressources matérielles.
Énoncé du problème
Notre microservice, appelons-le
Summarizer , devrait:
- Télécharger la vidéo du service multimédia;
- Extraire la piste audio;
- Écoutez la piste audio, en fait Speech to text;
- Trouvez 20 mots-clés;
- Sélectionnez une phrase dans le texte, ce qui pourrait maximiser l'essence de la vidéo;
- Envoyez tous les résultats au service de contenu;
Nous ferons confiance à l'implémentation de
Python , vous n'aurez donc pas à gérer l'intégration avec des solutions ML prêtes à l'emploi.
Première étape: audio au texte.
Tout d'abord, installez tous les composants nécessaires.
pip3 install wave numpy tensorflow youtube_dl ffmpeg-python deepspeech nltk networkx brew install ffmpeg wget
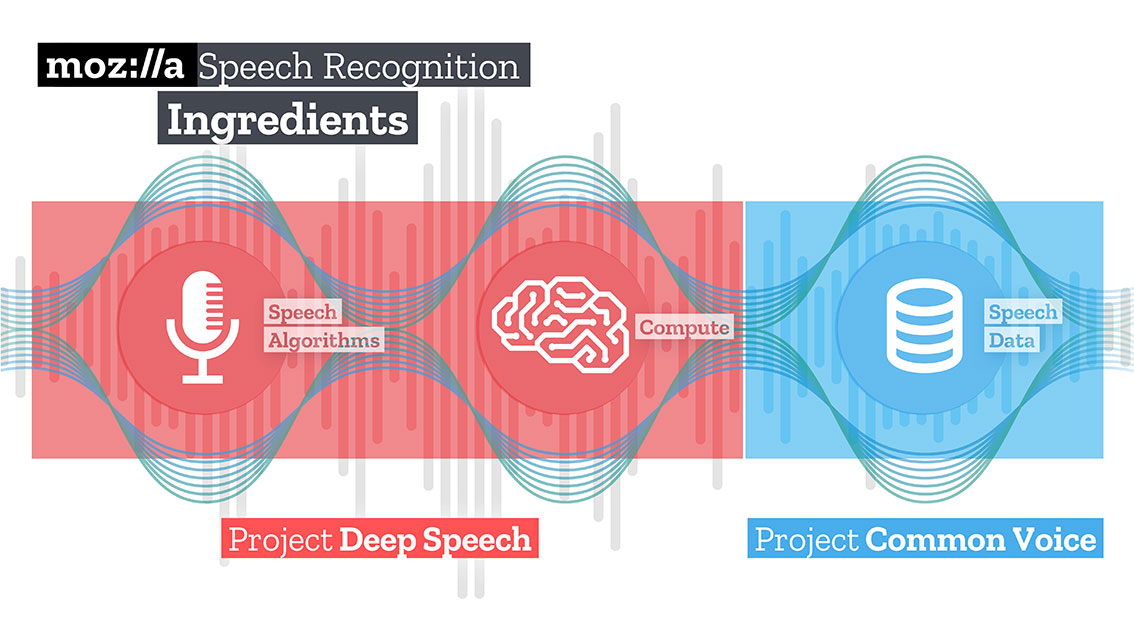
Ensuite, téléchargez et décompressez le modèle formé pour la solution Speech to text de Mozilla - Deepspeech.
mkdir /Users/Volodymyr/Projects/deepspeech/ cd /Users/Volodymyr/Projects/deepspeech/ wget https://github.com/mozilla/DeepSpeech/releases/download/v0.3.0/deepspeech-0.3.0-models.tar.gz tar zxvf deepspeech-0.3.0-models.tar.gz
L'équipe Mozilla a créé et formé une assez bonne solution qui, à l'aide de TensorFlow, peut transformer de longs clips audio en gros morceaux de texte de haute qualité.
TensorFlow vous permet également de travailler à la fois sur le CPU et le GPU.
Notre code commencera par télécharger du contenu. La merveilleuse bibliothèque
youtube-dl , qui possède un post-processeur intégré capable de convertir la vidéo au format requis, l'aidera à cet égard. Malheureusement, le code du post-processeur est un peu limité, il ne sait pas comment rééchantillonner, nous allons donc l'aider.
À l'entrée Deepspeech, vous devez soumettre un fichier audio avec une piste mono et un échantillon 16K. Pour ce faire, nous devons retraiter notre fichier reçu.
_ = ffmpeg.input(youtube_id + '.wav').output(output_file_name, ac=1, t=crop_time, ar='16k').overwrite_output().run(capture_stdout=False)
Dans la même opération, nous pouvons également limiter la durée de notre fichier en passant un paramètre supplémentaire «t».
Téléchargez le modèle deepspeech.
deepspeech = Model(args.model, N_FEATURES, N_CONTEXT, args.alphabet, BEAM_WIDTH)
À l'aide de la bibliothèque Wave, nous extrayons des images au format np.array et les transférons à l'entrée de la bibliothèque deepspeech.
fin = wave.open(file_name, 'rb') framerate_sample = fin.getframerate() if framerate_sample != 16000: print('Warning: original sample rate ({}) is different than 16kHz. Resampling might produce erratic speech recognition.'.format(framerate_sample), file=sys.stderr) fin.close() return else: audio = np.frombuffer(fin.readframes(fin.getnframes()), np.int16) audio_length = fin.getnframes() * (1/16000) fin.close() print('Running inference.', file=sys.stderr) inference_start = timer() result = deepspeech.stt(audio, framerate_sample)
Après un certain temps, proportionnel à vos ressources matérielles, vous recevrez du texte.
Deuxième étape: trouver le «sens»
Pour rechercher des mots qui décrivent le texte résultant, j'utiliserai la méthode graphique. Cette méthode est basée sur la distance entre les séquences. On trouve d'abord tous les mots «uniques», imaginez que ce sont les sommets de notre graphe. Après avoir parcouru le texte avec une «fenêtre» d'une longueur donnée, on retrouve la distance entre les mots, ce seront les bords de notre gaffe. Les sommets ajoutés au graphique peuvent être limités par des filtres de syntaxe qui ne sélectionnent que les unités lexicales d'une certaine partie du discours. Par exemple, vous ne pouvez considérer que les noms et les verbes à ajouter au graphique. Par conséquent, nous allons construire des arêtes potentielles basées uniquement sur des relations qui peuvent être établies entre les noms et les verbes.
Le score associé à chaque sommet est défini sur une valeur initiale de 1 et l'algorithme de classement est lancé. L'algorithme de classement est un «vote» ou une «recommandation». Lorsqu'un sommet est connecté à un autre, il «vote» pour ce sommet (connecté). Plus le nombre de votes exprimés pour un pic est élevé, plus l'importance de ce pic est élevée. De plus, l'importance du sommet du vote détermine l'importance du vote lui-même, et cette information est également prise en compte par le modèle de classement. Par conséquent, le score associé au sommet est déterminé en fonction des votes exprimés pour celui-ci et de la note des pics exprimant ces votes.
Supposons que nous ayons un graphe G = (V, E) décrit par les sommets V et les arêtes E. Pour un sommet V donné, qu'il y ait un ensemble de sommets E qui lui sont connectés. Pour chaque sommet Vi, il existe des sommets In (Vi) qui lui sont associés et des sommets Out (Vi) auxquels le sommet Vi est associé. Ainsi, le poids du sommet Vi peut être représenté par la formule.
Où d est le facteur d'atténuation / suppression, prenant une valeur de 1 à 0.
L'algorithme doit itérer le graphique plusieurs fois pour obtenir des estimations approximatives.
Après avoir obtenu une estimation approximative pour chaque sommet du graphique, les sommets sont triés par ordre décroissant. Les sommets qui apparaissent en haut de la liste seront nos mots clés souhaités.
La phrase la plus pertinente du texte se trouve en trouvant la moyenne de l'addition des notes de tous les mots de la phrase. Autrement dit, nous additionnons toutes les estimations et divisons par le nombre de mots dans la phrase.
iMac:YoutubeSummarizer $ cd /Users/Volodymyr/Projects/YoutubeSummarizer ; env "PYTHONIOENCODING=UTF-8" "PYTHONUNBUFFERED=1" /usr/local/bin/python3 /Users/Volodymyr/.vscode/extensions/ms-python.python-2018.11.0/pythonFiles/experimental/ptvsd_launcher.py --default --client --host localhost --port 53730 /Users/Volodymyr/Projects/YoutubeSummarizer/summarizer.py --youtube-id yA-FCxFQNHg --model /Users/Volodymyr/Projects/deepspeech/models/output_graph.pb --alphabet /Users/Volodymyr/Projects/deepspeech/models/alphabet.txt --lm /Users/Volodymyr/Projects/deepspeech/models/lm.binary --trie /Users/Volodymyr/Projects/deepspeech/models/trie --crop-time 900 Done downloading, now converting ... ffmpeg version 4.1 Copyright (c) 2000-2018 the FFmpeg developers built with Apple LLVM version 10.0.0 (clang-1000.11.45.5) configuration: --prefix=/usr/local/Cellar/ffmpeg/4.1 --enable-shared --enable-pthreads --enable-version3 --enable-hardcoded-tables --enable-avresample --cc=clang --host-cflags= --host-ldflags= --enable-ffplay --enable-gpl --enable-libmp3lame --enable-libopus --enable-libsnappy --enable-libtheora --enable-libvorbis --enable-libvpx --enable-libx264 --enable-libx265 --enable-libxvid --enable-lzma --enable-opencl --enable-videotoolbox libavutil 56. 22.100 / 56. 22.100 libavcodec 58. 35.100 / 58. 35.100 libavformat 58. 20.100 / 58. 20.100 libavdevice 58. 5.100 / 58. 5.100 libavfilter 7. 40.101 / 7. 40.101 libavresample 4. 0. 0 / 4. 0. 0 libswscale 5. 3.100 / 5. 3.100 libswresample 3. 3.100 / 3. 3.100 libpostproc 55. 3.100 / 55. 3.100 Guessed Channel Layout for Input Stream
Résumé
Les idées qui vous viennent à l'esprit peuvent être réalisées beaucoup plus rapidement aujourd'hui qu'il y a même trois ou quatre ans. Essayez-le, expérimentez! Je pense que l'intelligence artificielle est avant tout l'intelligence des ingénieurs qui y travaillent.
Le code est disponible dans
mon référentiel Github .