Probablement, tout service qui a généralement une recherche, tôt ou tard, vient à la nécessité d'apprendre à corriger les erreurs dans les requêtes des utilisateurs. Errare humanum est; les utilisateurs sont constamment scellés et se trompent, et la qualité de la recherche en souffre inévitablement - et avec elle, l'expérience utilisateur.
De plus, chaque service a ses spécificités, son propre vocabulaire, qui devraient pouvoir faire fonctionner le correcteur de typographie, ce qui complique grandement l'utilisation des solutions existantes. Par exemple, de telles demandes devaient apprendre à modifier notre tuteur:
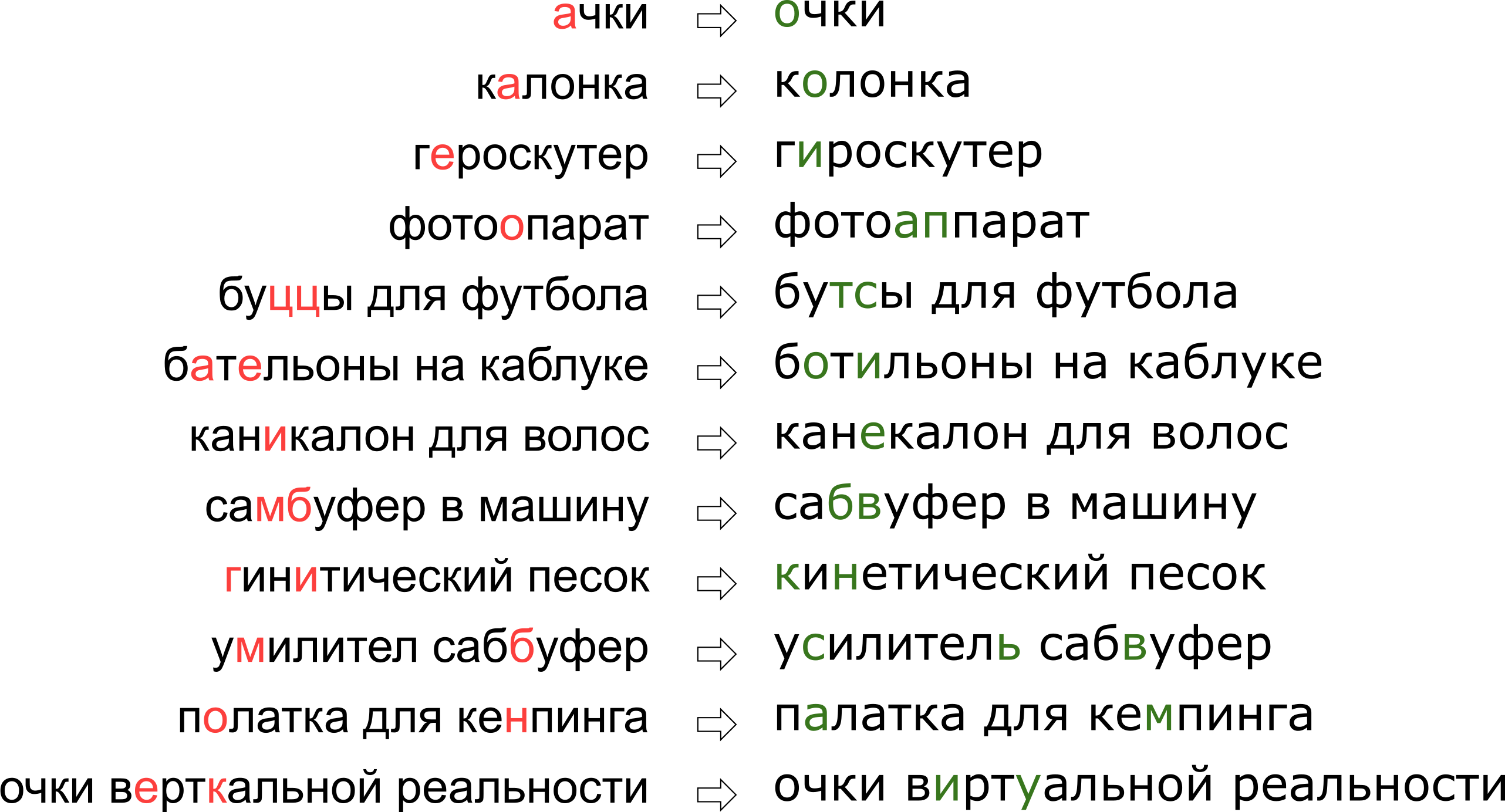 Il peut sembler que nous avons refusé à l'utilisateur son rêve de réalité verticale, mais en fait la lettre K se trouve simplement sur le clavier à côté de la lettre U.
Il peut sembler que nous avons refusé à l'utilisateur son rêve de réalité verticale, mais en fait la lettre K se trouve simplement sur le clavier à côté de la lettre U.Dans cet article, nous examinerons l'une des approches classiques pour corriger les fautes de frappe, de la construction d'un modèle à l'écriture de code en Python et Go. Et en bonus - une vidéo de mon rapport «
Lunettes de réalité verticale»: nous corrigeons les
fautes de frappe dans les requêtes de recherche »sur Highload ++.
Énoncé du problème
Nous avons donc reçu une demande scellée et nous devons y remédier. Habituellement, le problème est mathématiquement posé comme suit:
- étant donné le mot s transmis à nous avec des erreurs;
- avoir un dictionnaire S i g m a les bons mots;
- pour tous les mots w du dictionnaire, il y a des probabilités conditionnelles P ( w | s ) que signifiait le mot w à condition que nous ayons le mot s ;
- vous devez trouver le mot w dans le dictionnaire avec une probabilité maximale P ( w | s ) .
Cette affirmation - la plus élémentaire - suggère que si nous recevons une demande de plusieurs mots, nous corrigeons chaque mot individuellement. En réalité, bien sûr, nous voudrons corriger la phrase entière dans son ensemble, étant donné la compatibilité des mots adjacents; J'en parlerai plus tard dans la section "Comment corriger les phrases".
Il y a deux moments flous - où trouver le dictionnaire et comment compter
P ( w | s ) . La première question est considérée comme simple. En 1990 [1], le dictionnaire a été compilé à partir de la base de données d'utilité
orthographique et de dictionnaires disponibles électroniquement; en 2009, Google [4] a fait plus simple et a simplement pris les mots les plus populaires sur Internet (avec les fautes d'orthographe populaires). J'ai adopté cette approche pour construire mon tuteur.
La deuxième question est plus compliquée. Ne serait-ce que parce que sa décision commence généralement par l'application de la formule Bayes!
P ( w | s ) = m a t h r m c o n s t c d o t P ( s | w ) c d o t P ( w )
Maintenant, au lieu de la probabilité initiale incompréhensible, nous devons évaluer deux nouvelles, légèrement plus compréhensibles:
P ( s | w ) - la probabilité qu'en tapant un mot
w peut être scellé et obtenir
s et
P ( w ) - en principe, la probabilité que l'utilisateur utilise le mot
w .
Comment évaluer
P ( s | w ) ? De toute évidence, l'utilisateur est plus susceptible de confondre A avec O que b avec S. Et si nous corrigeons le texte reconnu à partir du document numérisé, il y a alors une forte probabilité de confusion entre rn et m. D'une manière ou d'une autre, nous avons besoin d'une sorte de modèle qui décrit les erreurs et leurs probabilités.
Un tel modèle est appelé le modèle de canal bruyant (le modèle de canal bruyant; dans notre cas, le canal bruyant commence quelque part au
centre du Brock de l' utilisateur et se termine de l'autre côté de son clavier) ou, plus brièvement, le modèle d'erreur est le modèle d'erreur. Ce modèle, qui est examiné dans une section distincte ci-dessous, sera chargé de prendre en compte à la fois les fautes d'orthographe et, en fait, les fautes de frappe.
Évaluez la probabilité d'utiliser le mot -
P ( w ) - il est possible de différentes manières. L'option la plus simple est de prendre pour elle la fréquence à laquelle le mot apparaît dans certains grands corpus de textes. Pour notre tuteur, compte tenu du contexte de la phrase, bien sûr, quelque chose de plus compliqué est nécessaire - un autre modèle. Ce modèle est appelé modèle de langage, un modèle de langage.
Modèle d'erreur
Les premiers modèles d'erreur ont été considérés
P ( s | w ) , calculant les probabilités de substitutions élémentaires dans l'ensemble d'apprentissage: combien de fois au lieu de E ils ont écrit Et, combien de fois au lieu de T ont écrit T, au lieu de T - T et ainsi de suite [1]. Le résultat a été un modèle avec un petit nombre de paramètres qui pourraient apprendre certains effets locaux (par exemple, que les gens confondent souvent E et I).
Dans nos recherches, nous avons opté pour un modèle d'erreur plus développé, proposé en 2000 par Brill et Moore [2] et réutilisé plus tard (par exemple, par des experts de Google [4]). Imaginez que les utilisateurs ne pensent pas en caractères séparés (confondez E et I, appuyez sur K au lieu de Y, sautez un signe souple), mais pouvez changer des morceaux arbitraires d'un mot en n'importe quel autre - par exemple, remplacez TSYA par TYSYA, Y avec K, SHA avec SHCHYA, SS à C et ainsi de suite. La probabilité que l'utilisateur soit scellé et au lieu de TSYA a écrit THY, nous notons
P( textmille rightarrow textmille) Est un paramètre de notre modèle. Si pour tous les fragments possibles
alpha, beta on peut compter
P( alpha rightarrow beta) , puis la probabilité souhaitée
P(s|w) un ensemble de mots s lorsque vous essayez de taper le mot w dans le modèle de Brill et Moore peut être obtenu comme suit: nous divisons les mots w et s en fragments plus courts de toutes les manières possibles afin qu'il y ait le même nombre de fragments en deux mots. Pour chaque partition, nous calculons le produit des probabilités de tous les fragments w à se transformer en fragments correspondants s. Le maximum pour toutes ces partitions sera considéré comme la valeur de
P(s|w) :
P(s|w)= maxs= alpha1 alpha2 ldots alphak,w= beta1 beta2 ldots betakP( alpha1 rightarrow beta1) cdotP( alpha2 rightarrow beta2) cdot ldots cdot P ( a l p h a k r i g h t a r r o w b e t a k ) , .
Regardons un exemple de partition qui se produit lors du calcul de la probabilité d'imprimer "accessoire" au lieu de "accessoire":
\ begin {matrix} \ text {ak} & \ text {cec} & \ text {sou} & \ text {a} & \ text {p} \\ \ downarrow & \ downarrow & \ downarrow & \ downarrow & \ downarrow \\ \ text {a} & \ text {cc} & \ text {e} & \ text {soua} & \ text {p} \ end {matrix}
Comme vous l'avez probablement remarqué, ceci est un exemple de partition pas très réussie: il est clair que certaines parties des mots ne se sont pas trouvées aussi bien que possible. Si les quantités
P( textak rightarrow texta) et
P( textp rightarrow textp) toujours pas si mal alors
P( textsou rightarrow texte) et
P( texta rightarrow textsoua) très probablement, ils rendront le «score» final de cette partition complètement triste. Une partition plus réussie ressemble à ceci:
\ begin {matrix} \ text {ak} & \ text {ce} & \ text {ss} & \ text {y} & \ text {ar} \\ \ downarrow & \ downarrow & \ downarrow & \ downarrow & \ downarrow \\ \ text {ak} & \ text {ce} & \ text {c} & \ text {y} & \ text {ar} \ end {matrix}
Ici, tout s'est immédiatement mis en place, et il est clair que la probabilité finale sera déterminée principalement par la valeur
P( textss rightarrow texts) .
Comment calculer P(s|w)
Malgré le fait qu'il existe des ordres de partitions possibles pour deux mots
O(2|s|+|w|) utilisant un algorithme de calcul de programmation dynamique
P(s|w) peut être fait assez rapidement - pour
O(|s|2|w|2) . L'algorithme lui-même ressemblera fortement à
l'algorithme de Wagner-Fisher pour calculer la
distance de Levenshtein .
Nous allons créer un tableau rectangulaire, dont les lignes correspondront aux lettres du mot correct, et les colonnes au mot scellé. La cellule à l'intersection de la ligne i et de la colonne j à la fin de l'algorithme aura exactement la probabilité d'obtenir
s[:j] en essayant d'imprimer
w[:i] . Pour le calculer, il suffit de calculer les valeurs de toutes les cellules des lignes et colonnes précédentes et de les parcourir, en multipliant par les valeurs correspondantes
P( alpha rightarrow beta) . Par exemple, si nous avons un tableau rempli
, puis pour remplir la cellule de la quatrième ligne et de la troisième colonne (grise), vous devez prendre le maximum de

et

. En même temps, nous avons parcouru toutes les cellules surlignées en vert. Si nous considérons également des modifications du formulaire
P( alpha rightarrow textlignevide) et
P( textlignevide rightarrow beta) , vous devez ensuite parcourir les cellules surlignées en jaune.
La complexité de cet algorithme, comme je l'ai mentionné ci-dessus, est
O(|s|2|w|2) : nous remplissons le tableau
|s| times|w| , et pour remplir la cellule (i, j) dont vous avez besoin
O(i cdotj) opérations. Cependant, si nous limitons notre considération aux fragments pas plus qu'une certaine longueur limitée
L (par exemple, pas plus de deux lettres, comme dans [4]), la complexité diminuera jusqu'à
O(|s| cdot|w| cdotL2) . Pour la langue russe dans mes expériences, j'ai pris
L=3 .
Comment maximiser P(s|w)
Nous avons appris à trouver
P(s|w) car le temps polynomial est bon. Mais nous devons apprendre à trouver rapidement les meilleurs mots dans tout le dictionnaire. Et les meilleurs ne le sont pas
P(s|w) , mais
P(w|s) ! En fait, il nous suffit d’obtenir des mots raisonnables (par exemple, les 20 meilleurs)
P(s|w) , que nous enverrons ensuite au modèle de langue pour sélectionner les corrections les plus appropriées (plus de détails ci-dessous).
Pour savoir comment parcourir rapidement l'ensemble du dictionnaire, notons que le tableau présenté ci-dessus aura beaucoup en commun pour deux mots avec des préfixes communs. En effet, si nous, en corrigeant le mot «accessoire», essayons de le remplir pour les deux mots de vocabulaire «accessoire» et «accessoires», nous remarquerons que les neuf premières lignes ne diffèrent pas du tout! Si nous pouvons organiser une passe de dictionnaire pour que les deux mots suivants aient des préfixes communs suffisamment longs, nous pouvons économiser beaucoup de calculs.
Et nous le pouvons. Prenons les mots de vocabulaire et faisons-les
trier . En le parcourant en profondeur, nous obtenons la propriété souhaitée: la plupart des étapes sont des étapes du nœud à son descendant, lorsque le tableau doit remplir les dernières lignes.
Cet algorithme, avec quelques optimisations supplémentaires, nous permet de trier un dictionnaire d'une langue européenne typique en 50-100 mille mots en une centaine de millisecondes [2]. Et la mise en cache des résultats rendra le processus encore plus rapide.
Comment arriver P( alpha rightarrow beta)
Calcul
P( alpha rightarrow beta) pour tous les fragments considérés - la partie la plus intéressante et non triviale de la construction d'un modèle d'erreur. C'est à partir de ces quantités que dépendra sa qualité.
L'approche utilisée dans [2, 4] est relativement simple. Trouvons beaucoup de couples
(si,wi) où
wi Est le mot correct du dictionnaire, et
si - sa version scellée. (Comment les trouver exactement est un peu plus bas.) Maintenant, nous devons extraire les probabilités de fautes de frappe spécifiques de ces paires (en remplaçant certains fragments par d'autres).
Pour chaque paire, nous prenons ses composants
w et
s et construire une correspondance entre leurs lettres, minimisant la distance Levenshtein:
\ begin {matrix} \ text {a} & \ text {c} & \ text {c} & \ text {e} & \ text {c} & \ text {c} & \ text {y} & \ text {a} & \ text {p} \\ \ text {a} & \ text {k} & \ text {c} & \ text {e} & \ text {c} & \ text {} & \ text {y } & \ text {a} & \ text {p} \ end {matrix}
Maintenant, nous voyons immédiatement les substitutions: a → a, e → et, c → c, c → une chaîne vide et ainsi de suite. Nous voyons également des remplacements de deux ou plusieurs caractères: ak → ak, ce → si, ec → is, ss → s, ses → sis, ess → is et autre, et ainsi de suite. Tous ces remplacements doivent être comptés, et chacun autant de fois que le mot s apparaît dans le corpus (si l'on prend les mots du corpus, ce qui est très probable).
Après être passé dans toutes les paires
(si,wi) pour la probabilité
P( alpha rightarrow beta) le nombre de substitutions α → β qui se sont produites dans nos paires est accepté (en tenant compte de l'occurrence des mots correspondants) divisé par le nombre de répétitions du fragment α.
Comment trouver des couples
(si,wi) ? Dans [4], cette approche a été proposée. Prenez le grand corps de contenu généré par l'utilisateur (UGC). Dans le cas de Google, il ne s'agissait que des textes de centaines de millions de pages Web; Le nôtre a des millions de recherches et d'avis d'utilisateurs. On suppose que le mot correct se trouve généralement plus souvent dans le corpus que n'importe laquelle des variantes erronées. Donc, trouvons des mots pour chaque mot proche de Levenshtein du corpus, qui sont beaucoup moins populaires (par exemple, dix fois). Prenez populaire
w , moins populaire - pour
s . Nous obtenons donc un ensemble de paires bruyant mais assez large sur lequel nous entraîner.
Cet algorithme d'appariement de paires laisse beaucoup de place à l'amélioration. Dans [4], seul un filtre par occurrence (
w dix fois plus populaire que
s ), mais les auteurs de cet article tentent de faire des potins, sans utiliser aucune connaissance a priori de la langue. Si nous considérons uniquement la langue russe, nous pouvons, par exemple, prendre un
ensemble de dictionnaires de formes de mots russes et ne laisser que des paires avec le mot
w trouvé dans le dictionnaire (pas une bonne idée, car le dictionnaire n'aura probablement pas de vocabulaire spécifique au service) ou, à l'inverse, jetez les paires avec les mots s trouvés dans le dictionnaire (c'est-à-dire, il est presque garanti de ne pas être scellé).
Pour améliorer la qualité des paires reçues, j'ai écrit une fonction simple qui détermine si les utilisateurs utilisent deux mots comme synonymes. La logique est simple: si les mots w et s se trouvent souvent entourés des mêmes mots, alors ce sont probablement des synonymes - ce qui, compte tenu de leur proximité selon Levenshtein, signifie qu'un mot moins populaire est très probablement une version erronée d'un mot plus populaire. Pour ces calculs, j'ai utilisé les statistiques d'occurrence de trigrammes (phrases de trois mots) construites pour le modèle de langage ci-dessous.
Modèle de langage
Donc, maintenant, pour un mot donné du dictionnaire w, nous devons calculer
P(w) - la probabilité de son utilisation par l'utilisateur. La solution la plus simple consiste à prendre l'occurrence d'un mot dans une sorte de grand cas. En général, probablement, tout modèle de langage commence par collecter un grand corpus de textes et compter l'occurrence de mots qu'il contient. Mais nous ne devons pas nous limiter à cela: en fait, lors du calcul de P (w), nous pouvons également prendre en compte la phrase dans laquelle nous essayons de corriger le mot, et tout autre contexte externe. La tâche se transforme en tâche de calcul
P(w1w2 ldotswk) où l'un des
wi - le mot dans lequel nous avons corrigé la faute de frappe et pour lequel nous comptons maintenant
P(w) et le reste
wi - Les mots entourant le mot corrigé dans la demande de l'utilisateur.
Pour savoir comment les prendre en compte, il vaut la peine de parcourir à nouveau le corpus et de compiler des statistiques de n-grammes, des séquences de mots. Prend généralement des séquences de longueur limitée; Je me suis limité aux trigrammes pour ne pas gonfler l'indice, mais tout dépend de votre force d'esprit (et de la taille du boîtier - sur un petit boîtier même les statistiques sur les trigrammes seront trop bruyantes).
Le modèle de langage n-gram traditionnel ressemble à ceci. Pour la phrase
w1w2 ldotswk sa probabilité est calculée par la formule
P(w1w2 ldotswk)=P(w1) cdotP(w2|w1) cdotP(w3|w1w2)P(wk|w1w2wk−1) ,,
où
P(w1) - directement la fréquence du mot, et
P(w3|w1w2) - probabilité de mot
w3 à condition qu'avant d'aller
w1w2 - rien que le rapport de la fréquence du trigramme
w1w2w3 à la fréquence bigramme
w1w2 . (Notez que cette formule est simplement le résultat de l'utilisation répétée de la formule Bayes.)
En d'autres termes, si nous voulons calculer
P( textcadredesavonmaman) , indiquant la fréquence d'un n-gramme arbitraire dans
f nous obtenons la formule
P( textmomsoapframe)=f( textmom) cdot fracf( textmomsoap)f( textmom) cdot fracf( textmomsoapframe)f( textmomsoap)=f( textmomsoapframe).
Est-ce logique? Est logique. Cependant, les difficultés commencent lorsque les phrases deviennent plus longues. Et si un utilisateur saisissait une requête de recherche de dix mots avec des détails impressionnants? Nous ne voulons pas conserver de statistiques pour tous les 10 grammes - cela coûte cher, et les données sont susceptibles d'être bruyantes et non indicatives. Nous voulons nous en tirer avec des n-grammes d'une longueur limitée - par exemple, la longueur 3 déjà proposée ci-dessus.
C'est là que la formule ci-dessus est utile. Supposons que la probabilité qu'un mot apparaisse à la fin d'une phrase n'est significativement affectée que par quelques mots immédiatement en face, c'est-à-dire,
P(wk|w1w2 ldotswk−1) approxP(wk|wk−L+1 ldotswk−1).
Mettre
L=3 , pour une phrase plus longue, nous obtenons la formule
P( textcarlavolédescorauxdeClara) approxf( textcarl) cdot fracf( textcarl)f( textcarl) cdot fracf( textcarlfromclara)f( textcarlfrom) cdot fracf( textvolédeclara)f( textfromclara) cdot fracf( textclairestolecoral)f( textclairestole).Remarque: l'expression se compose de cinq mots, mais les n-grammes ne dépassant pas trois apparaissent dans la formule. C'est exactement ce que nous recherchions.
Il ne restait plus qu'un instant. Et si l'utilisateur saisissait une phrase très étrange et les n-grammes correspondants dans nos statistiques et pas du tout? Il serait facile pour les n-grammes inconnus de mettre
f=0 s'il n'était pas nécessaire de diviser par cette valeur. Voici à l'aide du lissage (lissage), qui peut être fait de différentes manières; cependant, une discussion détaillée des approches anti-aliasing sérieuses comme le
lissage de Kneser-Ney est bien au-delà de la portée de cet article.
Comment corriger des phrases
Nous discutons du dernier point subtil avant de passer à la mise en œuvre. L'énoncé du problème que j'ai décrit ci-dessus implique qu'il y a un mot et qu'il doit être corrigé. Ensuite, nous avons précisé que ce seul mot peut être au milieu d'une phrase parmi d'autres mots et qu'ils doivent également être pris en compte, en choisissant la meilleure correction. Mais en réalité, les utilisateurs nous envoient simplement des phrases sans préciser quel mot est orthographié; souvent quelques mots ou même tous doivent être corrigés.
Il peut y avoir de nombreuses approches. Par exemple, vous ne pouvez prendre en compte que le contexte gauche du mot dans la phrase. Ensuite, en suivant les mots de gauche à droite et en les corrigeant si nécessaire, nous obtiendrons une nouvelle phrase d'une certaine qualité. La qualité sera mauvaise si, par exemple, le premier mot s'est avéré être comme plusieurs mots populaires et si nous choisissons la mauvaise option. Toute la phrase restante (peut-être initialement totalement sans erreur) sera ajustée par nous au premier mauvais mot et nous pourrons obtenir le texte qui n'a absolument rien à voir avec l'original.
Vous pouvez considérer les mots individuellement et appliquer un certain classificateur pour comprendre si le mot donné est scellé ou non, comme suggéré dans [4]. Le classificateur est formé sur les probabilités que nous savons déjà compter, et sur un certain nombre d'autres fonctionnalités. Si le classificateur dit ce qui doit être corrigé, nous le corrigeons, compte tenu du contexte existant. Encore une fois, si plusieurs mots sont mal orthographiés, vous devrez prendre une décision sur le premier d'entre eux en fonction du contexte des erreurs, ce qui peut entraîner des problèmes de qualité.
Dans la mise en œuvre de notre tuteur, nous avons utilisé cette approche. Faisons pour chaque mot
si dans notre phrase, en utilisant le modèle d'erreur, nous trouvons les mots du dictionnaire top-N qui pourraient être signifiés, nous les concaténons en phrases de toutes les manières possibles et pour chacun des
NK phrases résultantes où
K - le nombre de mots dans la phrase d'origine, calculez honnêtement la valeur
P(s1|w1) cdotP(sK|wK) cdotP(sK|wK) cdotP(w1w2 ldotswK) lambda.
Ici
si - mots saisis par l'utilisateur,
wi - les corrections sélectionnées pour eux (que nous sommes en train de trier), et
lambda - coefficient déterminé par la qualité comparative du modèle d'erreur et du modèle de langage (grand coefficient - nous faisons davantage confiance au modèle de langage, petit coefficient - nous faisons davantage confiance au modèle d'erreur), proposé dans [4]. Au total pour chaque phrase, nous multiplions les probabilités de mots individuels à corriger dans les options de vocabulaire correspondantes, et nous multiplions également cela par la probabilité de la phrase entière dans notre langue. Le résultat de l'algorithme est une phrase de mots du dictionnaire qui maximise cette valeur.
Alors arrête quoi? Force brute
NK phrases?
Heureusement, étant donné que nous avons limité la longueur des n-grammes, il est possible de trouver un maximum dans toutes les phrases beaucoup plus rapidement. Rappelez-vous: ci-dessus, nous avons simplifié la formule
P(w1w2 ldotswK) de sorte qu'il a commencé à dépendre uniquement de fréquences de n-grammes de longueur ne dépassant pas trois:
P(w1w2 ldotswK)=P(w1) cdotP(w2|w1) cdotP(w3|w1w2) cdot ldots cdotP(wK|wK−2wK−1).
Si nous multiplions cette valeur par
P(si|wi) et essayez de maximiser en
wK , nous verrons qu'il suffit de trier toutes sortes de
wK−2 et
wK−1 et résoudre le problème pour eux - c'est-à-dire pour les phrases
w1w2 ldotswK−2wK−1 . Au total, le problème est résolu par une programmation dynamique dans
O(KN3) .
Implémentation
Assembler le boîtier et compter les n-grammes
Je ferai une réservation tout de suite: il n'y avait pas tellement de données à ma disposition pour démarrer un MapReduce complexe. J'ai donc rassemblé tous les textes des avis, commentaires et requêtes de recherche en russe (les descriptions des marchandises, hélas, viennent en anglais, et l'utilisation des résultats de la traduction automatique a plutôt empiré que amélioré les résultats) de notre service dans un fichier texte et réglé le serveur pour que la nuit compte trigrammes avec un simple script Python.
En tant que dictionnaire, j'ai pris les meilleurs mots en fréquence pour obtenir environ cent mille mots. Les mots trop longs (plus de 20 caractères) et trop courts (moins de trois caractères, à l'exception des mots russes bien connus codés en dur) ont été exclus. Épargné séparément les mots sur la régularité
r"^[a-z0-9]{2}$" - de sorte que des versions d'iPhones et d'autres identifiants intéressants de longueur 2 ont survécu.
Lors du comptage de bigrammes et de trigrammes dans une phrase, un mot non-dictionnaire peut apparaître. Dans ce cas, j'ai jeté ce mot et battu toute la phrase en deux parties (avant et après ce mot), avec lesquelles j'ai travaillé séparément. Donc, pour la phrase "
Savez-vous ce qu'est" abyrvalg "? C'est ... LE CHEF DE FILE, collègue "prendra en compte les trigrammes" Savez-vous "," vous savez quoi "," savez ce qui est "et" c'est le collègue pêcheur en chef "(à moins, bien sûr, que le mot" chef "ne tombe dans le dictionnaire ...).
Nous formons le modèle d'erreur
De plus, j'ai effectué tous les traitements de données dans Jupyter. Les statistiques sur les n-grammes sont chargées à partir de JSON, un post-traitement est effectué pour trouver rapidement des mots proches les uns des autres selon Levenshtein, et pour les paires dans la boucle, une fonction (plutôt lourde) est appelée qui organise les mots et extrait de courtes modifications de la forme ss → c (sous le spoiler).
Code Python def generate_modifications(intended_word, misspelled_word, max_l=2):
Le calcul des modifications lui-même semble élémentaire, bien qu'il puisse prendre beaucoup de temps.
Appliquer le modèle d'erreur
Cette partie est implémentée comme un micro service on Go, connecté au backend principal via gRPC. L'algorithme décrit par Brill et Moore eux-mêmes [2], avec des optimisations mineures, a été implémenté. En conséquence, cela fonctionne pour moi, environ deux fois plus lentement que les auteurs l'ont prétendu; Je ne prétends pas juger si c'est en Go ou en moi. Mais au cours du profilage, j'ai appris un peu de nouvelles sur Go.
- N'utilisez pas
math.Max pour compter le maximum. C'est environ trois fois plus lent que if a > b { b = a } ! Regardez simplement l' implémentation de cette fonction :
Sauf si vous avez SOUVENT besoin que +0 soit nécessairement supérieur à -0, n'utilisez pas math.Max .
- N'utilisez pas de table de hachage si vous pouvez utiliser un tableau. Ceci, bien sûr, est un conseil assez évident. J'ai dû renuméroter les caractères Unicode en nombres au début du programme pour les utiliser comme index dans le tableau des descendants du nœud trie (une telle recherche était une opération très courante).
- Les rappels dans Go ne sont pas bon marché. Lors de la refactorisation lors de la révision du code, certaines de mes tentatives de découplage ont considérablement ralenti le programme malgré le fait que l'algorithme n'a pas officiellement changé. Depuis lors, je suis d'avis que le compilateur d'optimisation Go a de la place pour se développer.
Appliquer un modèle de langue
Ici, sans surprise, l'algorithme de programmation dynamique décrit dans la section ci-dessus a été implémenté. Cette composante a eu le moins de travail - la partie la plus lente est l'application du modèle d'erreur.
Par conséquent, entre ces deux couches, la mise en cache des résultats du modèle d'erreur dans Redis a également été vissée.Résultats
Sur la base des résultats de ces travaux (qui ont duré environ un mois), nous avons effectué un test test A / B sur nos utilisateurs. Au lieu de 10% de résultats de recherche vides parmi toutes les requêtes de recherche que nous avions avant l'introduction du tuteur, il y en avait 5%; en gros, les demandes restantes concernent des marchandises que nous n'avons tout simplement pas sur la plateforme. Le nombre de sessions sans deuxième requête de recherche a également augmenté (et plusieurs autres mesures de ce type liées à l'UX). Les paramètres liés à l'argent, cependant, n'ont pas changé de manière significative - cela était inattendu et nous a conduit à une analyse approfondie et à une vérification croisée d'autres paramètres.Conclusion
On a dit à Stephen Hawking que chaque formule qu'il inclurait dans le livre réduirait de moitié le nombre de lecteurs. Eh bien, dans cet article, il y a une cinquantaine d'entre eux - je vous félicite, l'un d'environ10−10 Les lecteurs atteignent cet endroit!Bonus
Les références
[1] MD Kernighan, KW Church, WA Gale. Un programme de correction d'orthographe basé sur un modèle de canal bruyant . Actes de la 13e conférence sur la linguistique informatique - Volume 2, 1990.[2] E.Brill, RC Moore. Un modèle d'erreur amélioré pour la correction orthographique des canaux bruyants . Actes de la 38e réunion annuelle de l'Association for Computational Linguistics, 2000.[3] T. Brants, AC Popat, P. Xu, FJ Och, J. Dean. Grands modèles de langage dans la traduction automatique . Actes de la Conférence de 2007 sur les méthodes empiriques dans le traitement du langage naturel.[4] C. Whitelaw, B. Hutchinson, GY Chung, G. Ellis. Utilisation du Web pour la vérification orthographique indépendante de la langue et la correction automatique. Actes de la Conférence 2009 sur les méthodes empiriques dans le traitement du langage naturel: Volume 2.