Il convient de noter tout de suite que cet article n'est qu'une réflexion subjective sur la façon dont le comportement des éléments d'interface qui savent ce que l'utilisateur fait à un moment donné peut ressembler et être mis en œuvre. Cependant, les réflexions sont étayées par un peu de recherche et de mise en œuvre. Allons-y.
À l'aube d'Internet, les sites ne recherchaient pas l'individualité dans le style des éléments d'interface de base. La variabilité était faible, de sorte que les pages étaient assez uniformes dans leurs composants.
Chaque lien ressemblait à un lien, un bouton comme un bouton et une case à cocher comme une case à cocher. L'utilisateur savait à quoi aboutirait son action, car il avait une idée claire du principe de fonctionnement de chaque élément.
Le lien doit être envoyé vers une autre page, quelle que soit sa provenance, depuis le menu de navigation ou depuis le texte de la description. Le bouton modifiera le contenu de la page en cours, éventuellement en envoyant une demande au serveur. L'état de la case à cocher, très probablement, n'affectera en aucune façon le contenu, jusqu'à ce que nous appuyions sur le bouton pour une action qui utilise cet état. Ainsi, il suffisait à l'utilisateur de regarder l'élément d'interface afin de comprendre avec un haut degré de probabilité comment interagir avec lui et à quoi il aboutirait.
Les sites modernes offrent à l'utilisateur un nombre beaucoup plus important de puzzles. Tous les liens sont complètement différents, les boutons ne ressemblent pas à des boutons, etc. Pour comprendre si une ligne est un lien, l'utilisateur doit passer la souris dessus pour voir la couleur changer en une couleur plus contrastée. Pour comprendre si un élément est un bouton, nous survolons également la souris pour voir le changement de tonalité de remplissage. Avec les éléments des différents menus, tout est également compliqué, certains élargiront probablement un sous-menu supplémentaire, d'autres non, même s'ils sont identiques à l'extérieur.
Cependant, nous nous habituons rapidement aux interfaces que nous utilisons régulièrement et ne sommes plus confondus dans la fonctionnalité des éléments. Un rôle majeur est joué par la continuité globale des interfaces. Après avoir regardé la page ci-dessus, nous réaliserons très probablement immédiatement que la flèche jaune avec les mots "Find" n'est pas seulement un élément décoratif, mais un bouton, bien qu'elle ne ressemble pas du tout à un bouton HTML standard. Ainsi, en termes de prévisibilité et de personnalité, la plupart des ressources sont parvenues à un consensus stable accepté par les utilisateurs.
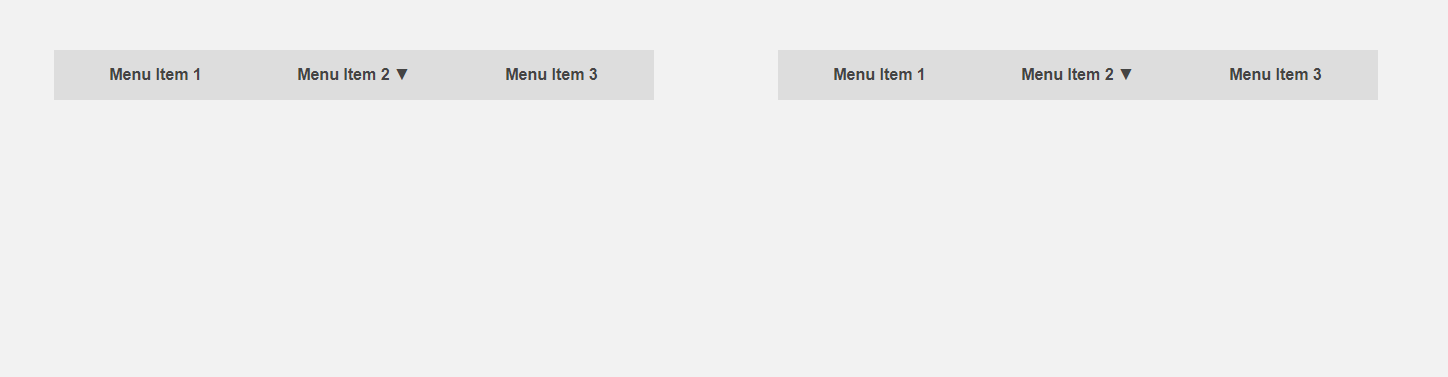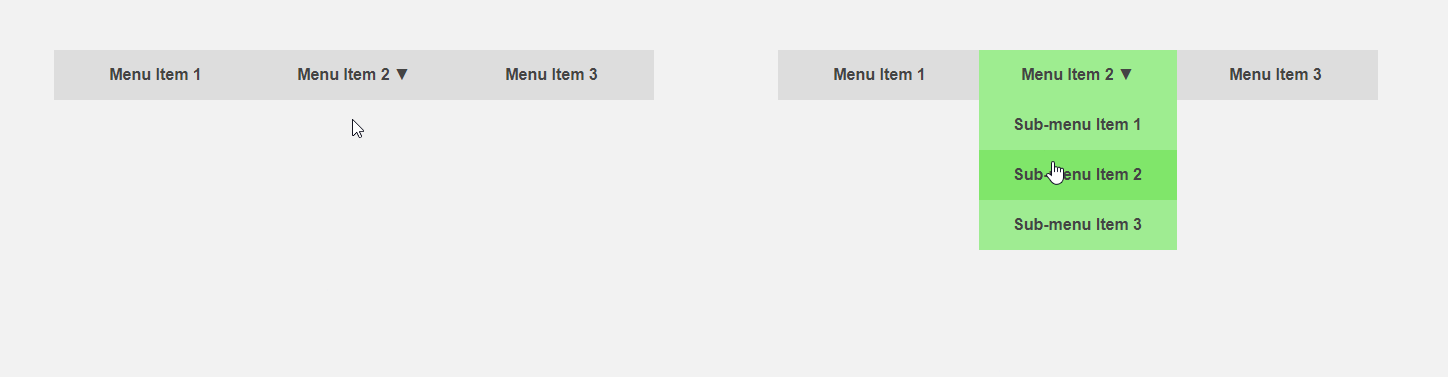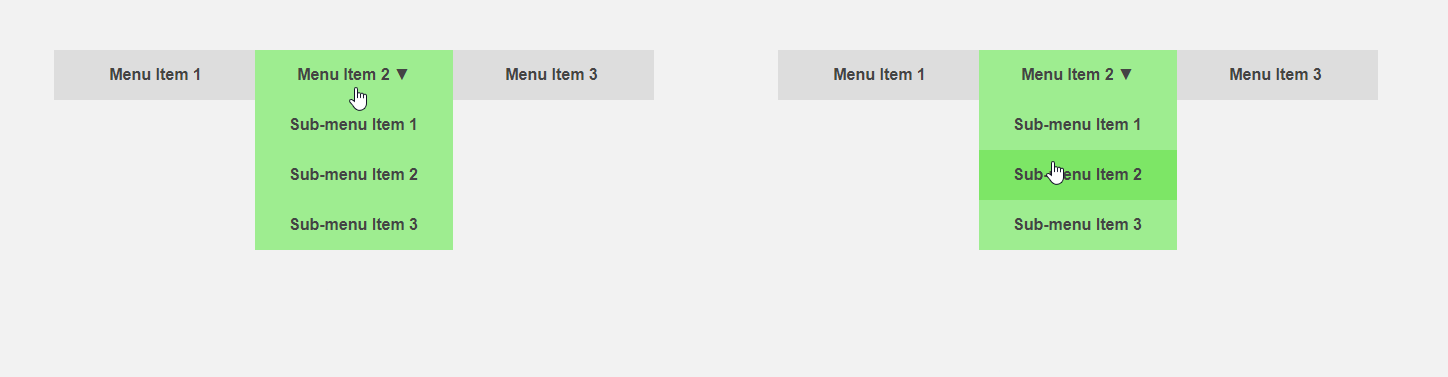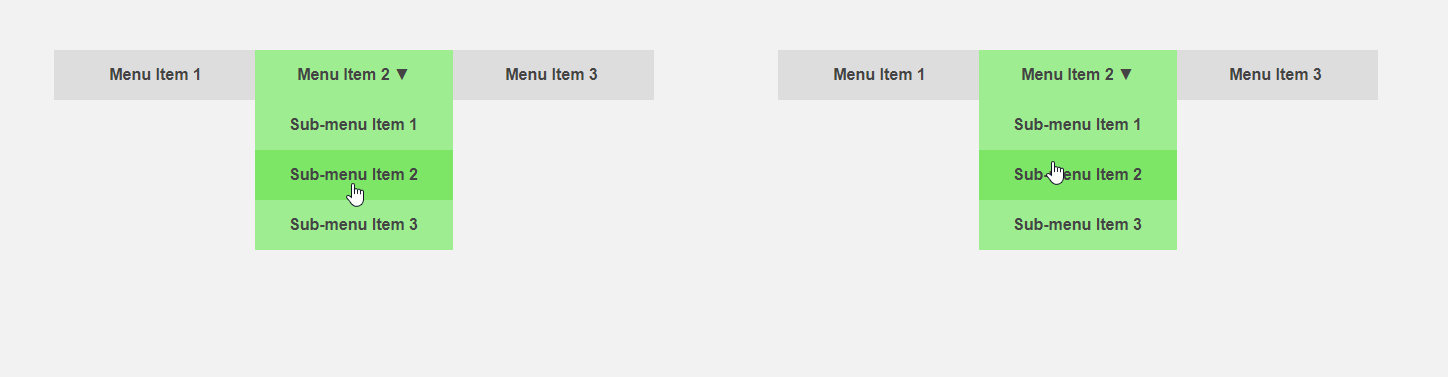
D'un autre côté, il serait intéressant d'obtenir une interface qui informe à l'avance l'utilisateur des spécificités d'un élément ou fait une partie de la routine pour lui. Le curseur se déplace vers l'élément de menu - vous pouvez étendre le sous-menu à l'avance, accélérant ainsi l'interaction avec l'interface, l'utilisateur déplace le curseur sur le bouton - vous pouvez charger du contenu supplémentaire qui n'est requis qu'après avoir cliqué. Le titre de l'article compare l'interface standard (à gauche) et prédictive.
Un test visuel simple montre qu'en analysant la vitesse du curseur et ses dérivées, il est possible de prédire la direction du mouvement et les coordonnées de l'arrêt en un certain nombre de pas. Étant donné que les événements de mouvement sont déclenchés avec une fréquence constante par rapport à l'amplitude de l'accélération, la vitesse diminue à l'approche de la cible. Ainsi, vous pouvez connaître à l'avance l'action prévue par l'utilisateur, ce qui conduit aux avantages déjà annoncés.

Ainsi, le problème comprend deux tâches: déterminer les futures coordonnées du curseur et déterminer les intentions de l'utilisateur (survoler, cliquer, surligner, etc.). Toutes ces données ne doivent être obtenues que sur la base de l'analyse des valeurs précédentes des coordonnées du curseur.
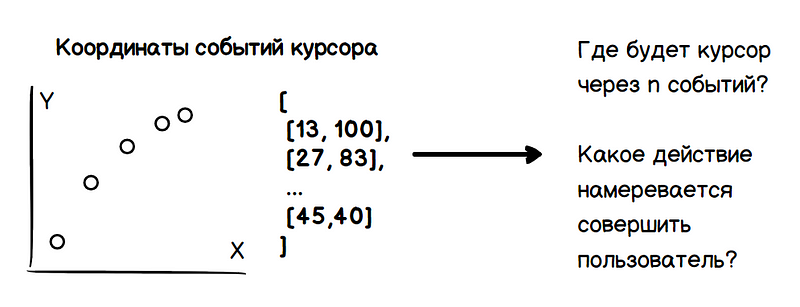
La tâche principale est d'évaluer la direction du mouvement du curseur plutôt que de prédire le moment d'arrêt, qui est un problème plus complexe. En tant qu'estimation des paramètres d'une quantité bruyante, le problème du calcul de la direction du mouvement peut être résolu par une masse de méthodes connues.
La première option qui vient à l'esprit est un filtre à
moyenne mobile . En faisant la moyenne de la vitesse dans les moments précédents, vous pouvez obtenir sa valeur dans ce qui suit. Les valeurs précédentes peuvent être pondérées selon une certaine loi (linéaire, exponentielle, exponentielle) pour renforcer l'influence des états les plus proches, réduisant la contribution des valeurs plus éloignées.
Une autre option consiste à utiliser un algorithme récursif, tel qu'un
filtre à particules . Pour évaluer la vitesse du curseur, le filtre crée de nombreuses hypothèses sur la valeur actuelle de la vitesse, également appelées particules. Au moment initial, ces hypothèses sont complètement aléatoires, mais plus loin, le filtre supprime les hypothèses invalides et périodiquement au stade de la redistribution en génère de nouvelles basées sur des hypothèses fiables. Ainsi, de l'ensemble des hypothèses, il ne reste que celles qui se rapprochent le plus de la vraie valeur de la vitesse.
Dans l'exemple ci-dessous, lorsque vous déplacez le curseur de chaque particule pour la visualisation, la valeur du rayon est directement proportionnelle à son poids. Ainsi, la région avec la plus forte concentration de particules lourdes caractérise la direction la plus probable du mouvement du curseur.
Cependant, la direction de mouvement obtenue n'est pas suffisante pour déterminer les intentions de l'utilisateur. Avec une densité élevée d'éléments d'interface, le chemin du curseur peut se trouver sur plusieurs d'entre eux, ce qui entraînera une masse de faux positifs de l'algorithme de prédiction. Ici, les méthodes d'apprentissage automatique viennent à la rescousse, à savoir les réseaux de neurones récurrents.
Les coordonnées du curseur sont une séquence de valeurs fortement corrélées. Lorsque le mouvement est ralenti, la différence entre les coordonnées des positions voisines sur la chronologie diminue d'un événement à l'autre. La tendance inverse est perceptible au début du mouvement - les intervalles de coordonnées augmentent. Probablement, avec une précision acceptable, ce problème peut également être résolu analytiquement en examinant les valeurs des dérivées à différentes parties du chemin et en codant le seuil de réponse en fonction du comportement de ces valeurs. Mais de par sa nature, la séquence de coordonnées des positions des curseurs ressemble à un ensemble de données qui correspond bien aux principes de fonctionnement des réseaux de mémoire à court terme à long terme.
Les réseaux
LSTM sont un type spécifique d'architecture de réseaux de neurones récurrents, adaptés à la formation de dépendances à long terme. Ceci est facilité par la possibilité de stocker des informations par les modules de réseau sur un certain nombre d'états. Ainsi, le réseau peut détecter des signes en fonction, par exemple, de la durée du ralentissement du curseur, de ce qui l'a précédé, de la modification de la vitesse du curseur au début du ralentissement, etc. Ces signes caractérisent des modèles spécifiques de comportement des utilisateurs lors de certaines actions, par exemple en cliquant sur un bouton.
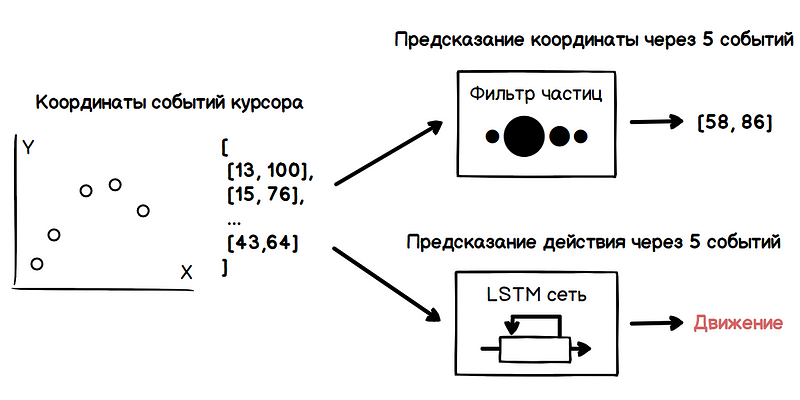
Ainsi, en analysant en continu les données obtenues à la sortie du filtre à particules et du réseau neuronal, nous obtenons un moment où, par exemple, vous pouvez afficher un menu déroulant, lorsque l'utilisateur déplace le curseur vers lui pour l'ouvrir dans la seconde suivante. En effectuant cette analyse pour chaque événement de souris, il est difficile de manquer le bon moment.
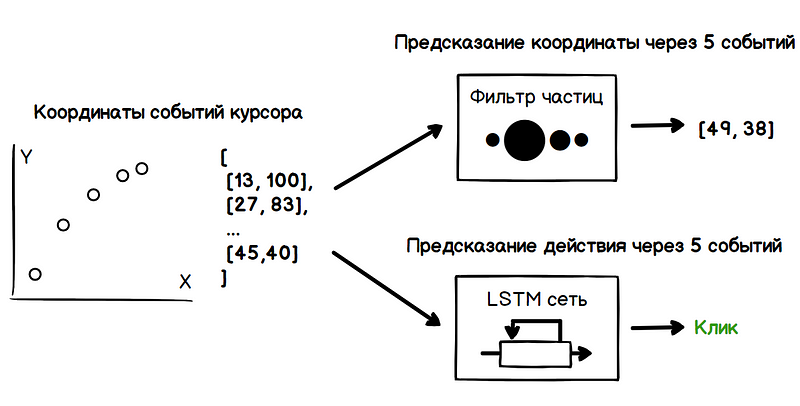
La formation au réseau LSTM peut être effectuée sur un ensemble de données obtenues au cours de l'analyse du comportement de l'utilisateur, en effectuant une série de tâches conçues pour identifier ses fonctionnalités lors de l'interaction avec l'interface: cliquez sur un bouton, déplacez le curseur sur un lien, ouvrez le menu, etc. Ce qui suit est un exemple de déclenchement d'une matrice d'éléments prédictifs basée uniquement sur un filtre à particules, sans analyse de réseau neuronal.

Les animations ci-dessous démontrent la contribution du réseau neuronal au processus de prédiction du comportement des utilisateurs. Les faux positifs deviennent beaucoup moins.

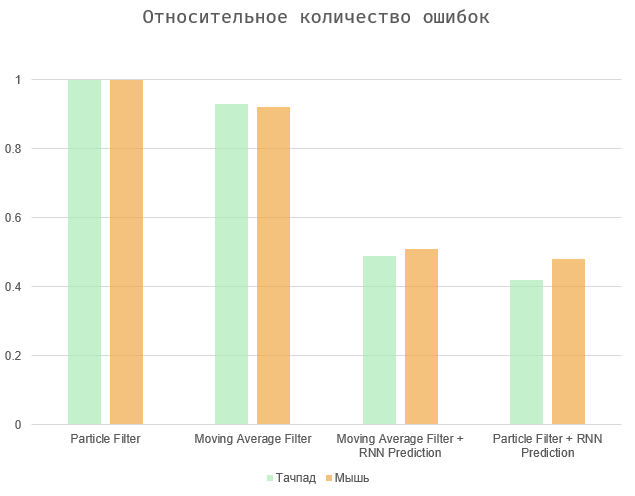
En général, la tâche se résume à équilibrer entre deux quantités - la période de temps entre l'action et sa prédiction et le nombre d'erreurs (faux positifs et omissions). Deux cas extrêmes sont de sélectionner tous les éléments de la page (période de prédiction maximale, un grand nombre d'erreurs), ou de faire fonctionner l'algorithme immédiatement lorsque l'utilisateur agit (période de prédiction nulle et erreurs manquantes).
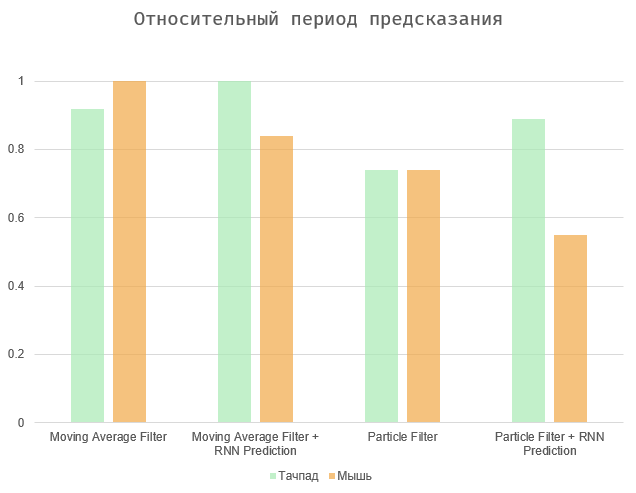
Les diagrammes montrent les résultats normalisés aux valeurs maximales, car la vitesse de l'utilisateur est purement individuelle et le nombre d'erreurs dépend de l'interface en question. Les algorithmes de moyenne mobile et de filtre à particules montrent des résultats à peu près similaires. Le second est un peu plus précis, surtout dans le cas de l'utilisation du pavé tactile. En fin de compte, toutes ces options peuvent dépendre fortement de l'utilisateur et de l'appareil spécifiques.
En conclusion, une petite démo du comportement prédictif des éléments HTML, loin d'être idéale, mais un peu révélatrice.
Bien sûr, dans de telles tâches, il est essentiel de trouver un équilibre entre fonctionnalité et prévisibilité. Si le comportement résultant n'est pas clair pour l'utilisateur, l'irritation causée annulera tous les efforts. Il est difficile de se demander s'il est possible de rendre le processus d'apprentissage de l'algorithme invisible à l'utilisateur, par exemple, dans les premières sessions de sa communication avec l'interface de page, de sorte que, en utilisant les algorithmes formés, les éléments d'interface se comportent alors de manière prédictive. Dans tous les cas, une formation supplémentaire sera nécessaire en raison des caractéristiques individuelles de chaque personne et cela fait l'objet de recherches supplémentaires.