Bonsoir
De notre cours
"Développeur C ++", nous vous proposons une petite et intéressante étude sur les algorithmes parallèles.
Allons-y.
Avec l'avènement des algorithmes parallèles en C ++ 17, vous pouvez facilement mettre à jour votre code «informatique» et bénéficier de l'exécution parallèle. Dans cet article, je veux considérer l'algorithme STL, qui révèle naturellement l'idée de l'informatique indépendante. Peut-on s'attendre à une accélération 10x avec un processeur 10 cœurs? Ou peut-être plus? Ou moins? Parlons-en.
Introduction aux algorithmes parallèles
C ++ 17 offre un paramètre de stratégie d'exécution pour la plupart des algorithmes:
- sequenced_policy - type de politique d'exécution, utilisé comme type unique pour éliminer la simultanéité de l'algorithme parallèle et l'exigence que la parallélisation de l'exécution de l'algorithme parallèle soit impossible: l'objet global correspondant est
std::execution::seq ; - parallel_policy - un type de politique d'exécution utilisé comme type unique pour éliminer la surcharge de l'algorithme parallèle et indiquer que la parallélisation de l'exécution de l'algorithme parallèle est possible: l'objet global correspondant est
std::execution::par ; - parallel_unsequenced_policy - un type de politique d'exécution utilisé comme type unique pour éliminer la surcharge de l'algorithme parallèle et indiquer que la parallélisation et la vectorisation de l'exécution de l'algorithme parallèle sont possibles: l'objet global correspondant est
std::execution::par_unseq ;
En bref:
- utiliser
std::execution::seq pour l'exécution séquentielle de l'algorithme; - utiliser
std::execution::par pour exécuter l'algorithme en parallèle (généralement en utilisant une implémentation de pool de threads (pool de threads)); - utilisez
std::execution::par_unseq pour l'exécution parallèle de l'algorithme avec la possibilité d'utiliser des commandes vectorielles (par exemple, SSE, AVX).
Comme exemple rapide, appelez
std::sort en parallèle:
std::sort(std::execution::par, myVec.begin(), myVec.end());
Notez combien il est facile d'ajouter un paramètre d'exécution parallèle à l'algorithme! Mais y aura-t-il une amélioration significative des performances? Cela augmentera-t-il la vitesse? Ou y a-t-il des ralentissements?
Parallèle std::transformDans cet article, je veux faire attention à l'algorithme
std::transform , qui pourrait potentiellement être la base d'autres méthodes parallèles (avec
std::transform_reduce ,
for_each ,
scan ,
sort ...).
Notre code de test sera construit selon le modèle suivant:
std::transform(execution_policy,
Supposons que la fonction
ElementOperation n'a pas de méthodes de synchronisation, auquel cas le code a le potentiel d'exécution parallèle ou même de vectorisation. Chaque calcul d'élément est indépendant, l'ordre n'a pas d'importance, donc une implémentation peut générer plusieurs threads (éventuellement dans un pool de threads) pour un traitement indépendant des éléments.
Je voudrais expérimenter les choses suivantes:
- la taille du champ vectoriel est grande ou petite;
- une conversion simple qui passe la plupart du temps à accéder à la mémoire;
- opérations plus arithmétiques (ALU);
- ALU dans un scénario plus réaliste.
Comme vous pouvez le voir, je veux non seulement tester le nombre d'éléments qui sont «bons» pour utiliser l'algorithme parallèle, mais aussi les opérations ALU qui prennent le processeur.
D'autres algorithmes, tels que le tri, l'accumulation (sous la forme de std :: Reduce) offrent également une exécution parallèle, mais nécessitent également plus de travail pour calculer les résultats. Par conséquent, nous les considérerons comme candidats pour un autre article.
Note de référence
Pour mes tests, j'utilise Visual Studio 2017, 15.8 - puisque c'est la seule implémentation de l'implémentation populaire du compilateur / STL pour le moment (novembre 2018) (GCC en route!). De plus, je me suis concentré uniquement sur
execution::par , puisque
execution::par_unseq pas disponible dans MSVC (il fonctionne de manière similaire à
execution::par ).
Il y a deux ordinateurs:
- i7 8700 - PC, Windows 10, i7 8700 - 3,2 GHz, 6 cœurs / 12 threads (hyperthreading);
- i7 4720 - Ordinateur portable, Windows 10, i7 4720, 2,6 GHz, 4 cœurs / 8 threads (hyperthreading).
Le code est compilé en x64, Release more, la vectorisation automatique est activée par défaut, j'ai également inclus un ensemble étendu de commandes (SSE2) et OpenMP (2.0).
Le code est dans mon github:
github / fenbf / ParSTLTests / TransformTests / TransformTests.cppPour OpenMP (2.0), j'utilise le parallélisme uniquement pour les boucles:
#pragma omp parallel for for (int i = 0; ...)
J'exécute le code 5 fois et regarde les résultats minimum.
Avertissement : Les résultats ne reflètent que des observations approximatives; vérifiez votre système / configuration avant de l'utiliser en production. Vos besoins et votre environnement peuvent différer des miens.Vous pouvez en savoir plus sur la mise en œuvre de MSVC dans
cet article . Et
voici le dernier
rapport de Bill O'Neill avec CppCon 2018 (Bill implémenté Parallel STL dans MSVC).
Eh bien, commençons par des exemples simples!
Conversion simpleConsidérez le cas lorsque vous appliquez une opération très simple à un vecteur d'entrée. Il peut s'agir de copie ou de multiplication d'éléments.
Par exemple:
std::transform(std::execution::par, vec.begin(), vec.end(), out.begin(), [](double v) { return v * 2.0; } );
Mon ordinateur a 6 ou 4 cœurs ... puis-je m'attendre à une exécution séquentielle 4..6x plus rapide? Voici mes résultats (temps en millisecondes):
| Fonctionnement | Taille du vecteur | i7 4720 (4 cœurs) | i7 8700 (6 cœurs) |
|---|
| exécution :: seq | 10k | 0,002763 | 0,001924 |
| exécution :: par | 10k | 0,009869 | 0,008983 |
| openmp parallèle pour | 10k | 0,003158 | 0,002246 |
| exécution :: seq | 100k | 0,051318 | 0,028872 |
| exécution :: par | 100k | 0,043028 | 0,025664 |
| openmp parallèle pour | 100k | 0,022501 | 0,009624 |
| exécution :: seq | 1000k | 1,69508 | 0,52419 |
| exécution :: par | 1000k | 1,65561 | 0,359619 |
| openmp parallèle pour | 1000k | 1.50678 | 0,344863 |
Sur une machine plus rapide, nous pouvons voir qu'il faudra environ 1 million d'éléments pour constater une amélioration des performances. En revanche, sur mon ordinateur portable, toutes les implémentations parallèles étaient plus lentes.
Ainsi, il est difficile de constater une amélioration significative des performances à l'aide de telles transformations, même avec une augmentation du nombre d'éléments.
Pourquoi
Comme les opérations sont élémentaires, les cœurs de processeur peuvent l'appeler presque instantanément, en utilisant seulement quelques cycles. Cependant, les cœurs de processeur passent plus de temps à attendre la mémoire principale. Donc, dans ce cas, la plupart du temps, ils attendent, ne font pas de calculs.
La lecture et l'écriture d'une variable en mémoire prend environ 2 à 3 cycles si elle est mise en cache et plusieurs centaines de cycles si elle n'est pas mise en cache.https://www.agner.org/optimize/optimizing_cpp.pdfVous pouvez à peu près noter que si votre algorithme dépend de la mémoire, vous ne devez pas vous attendre à des améliorations des performances avec le calcul parallèle.
Plus de calculsPuisque la bande passante mémoire est cruciale et peut affecter la vitesse des choses ... augmentons la quantité de calcul qui affecte chaque élément.
L'idée est qu'il est préférable d'utiliser des cycles de processeur plutôt que de perdre du temps à attendre de la mémoire.
Pour commencer, j'utilise des fonctions trigonométriques, par exemple
sqrt(sin*cos) (ce sont des calculs conditionnels sous forme non optimale, juste pour occuper le processeur).
Nous utilisons
sqrt ,
sin et
cos , qui peuvent prendre ~ 20 par
sqrt et ~ 100 par fonction trigonométrique. Cette quantité de calcul peut couvrir le délai d'accès à la mémoire.
Pour plus d'informations sur les retards d'équipe, consultez l'excellent
guide Perf d'Agner Fogh .
Voici le code de référence:
std::transform(std::execution::par, vec.begin(), vec.end(), out.begin(), [](double v) { return std::sqrt(std::sin(v)*std::cos(v)); } );
Et maintenant quoi? Peut-on compter sur une amélioration des performances par rapport à la précédente tentative?
Voici quelques résultats (temps en millisecondes):
| Fonctionnement | Taille du vecteur | i7 4720 (4 cœurs) | i7 8700 (6 cœurs) |
|---|
| exécution :: seq | 10k | 0,105005 | 0,070577 |
| exécution :: par | 10k | 0,055661 | 0,03176 |
| openmp parallèle pour | 10k | 0,096321 | 0,024702 |
| exécution :: seq | 100k | 1.08755 | 0,707048 |
| exécution :: par | 100k | 0,259354 | 0,17195 |
| openmp parallèle pour | 100k | 0,898465 | 0,189915 |
| exécution :: seq | 1000k | 10.5159 | 7.16254 |
| exécution :: par | 1000k | 2,44472 | 1.10099 |
| openmp parallèle pour | 1000k | 4.78681 | 1,89017 |
Enfin, nous voyons de beaux chiffres :)
Pour 1000 éléments (non représentés ici), les temps de calcul parallèles et séquentiels étaient similaires, donc pour plus de 1000 éléments, nous voyons une amélioration dans la version parallèle.
Pour 100 000 éléments, le résultat sur un ordinateur plus rapide est presque 9 fois meilleur que la version série (de même pour la version OpenMP).
Dans la plus grande version d'un million d'éléments, le résultat est 5 ou 8 fois plus rapide.
Pour de tels calculs, j'ai réalisé une accélération «linéaire», en fonction du nombre de cœurs de processeur. Ce qui était à prévoir.
Fresnel et vecteurs tridimensionnelsDans la section ci-dessus, j'ai utilisé des calculs «inventés», mais qu'en est-il du vrai code?
Résolvons les équations de Fresnel décrivant la réflexion et la courbure de la lumière à partir d'une surface lisse et plate. Il s'agit d'une méthode populaire pour générer un éclairage réaliste dans les jeux 3D.
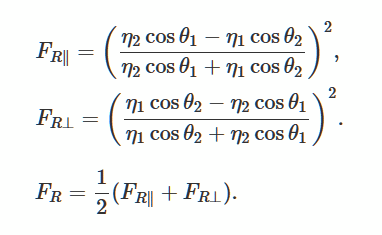
 Photo de Wikimedia
Photo de WikimediaComme bon exemple, j'ai trouvé
cette description et cette implémentation .
À propos de l'utilisation de la bibliothèque GLMAu lieu de créer ma propre implémentation, j'ai utilisé
la bibliothèque glm . Je l'utilise souvent dans mes projets OpenGl.
La bibliothèque est facile d'accès via le
Conan Package Manager , je vais donc l'utiliser aussi.
Lien vers le package.
Fichier Conan:
[requires] glm/0.9.9.1@g-truc/stable [generators] visual_studio
et la ligne de commande pour installer la bibliothèque (elle génère des fichiers d'accessoires que je peux utiliser dans un projet Visual Studio):
conan install . -s build_type=Release -if build_release_x64 -s arch=x86_64
La bibliothèque se compose d'un en-tête, vous pouvez donc simplement le télécharger manuellement si vous le souhaitez.
Code réel et référenceJ'ai adapté le code pour glm de
scratchapixel.com :
Le code utilise plusieurs instructions mathématiques, produit scalaire, multiplication, division, de sorte que le processeur a quelque chose à faire. Au lieu du double vecteur, nous utilisons un vecteur de 4 éléments pour augmenter la quantité de mémoire utilisée.
Référence:
std::transform(std::execution::par, vec.begin(), vec.end(), vecNormals.begin(),
Et voici les résultats (temps en millisecondes):
| Fonctionnement | Taille du vecteur | i7 4720 (4 cœurs) | i7 8700 (6 cœurs) |
|---|
| exécution :: seq | 1k | 0,032764 | 0,016361 |
| exécution :: par | 1k | 0,031186 | 0,028551 |
| openmp parallèle pour | 1k | 0,005526 | 0,007699 |
| exécution :: seq | 10k | 0,246722 | 0,169383 |
| exécution :: par | 10k | 0,090794 | 0,067048 |
| openmp parallèle pour | 10k | 0,049739 | 0,029835 |
| exécution :: seq | 100k | 2.49722 | 1,69768 |
| exécution :: par | 100k | 0,530157 | 0,283268 |
| openmp parallèle pour | 100k | 0,495024 | 0,291609 |
| exécution :: seq | 1000k | 25/08/28 | 16.9457 |
| exécution :: par | 1000k | 5.15235 | 2,33368 |
| openmp parallèle pour | 1000k | 5.11801 | 2.95908 |
Avec le «vrai» calcul, nous constatons que les algorithmes parallèles offrent de bonnes performances. Pour de telles opérations sur mes deux machines Windows, j'ai réalisé une accélération avec une dépendance presque linéaire sur le nombre de cœurs.
Pour tous les tests, j'ai également montré les résultats d'OpenMP et de deux implémentations: MSVC et OpenMP fonctionnent de manière similaire.
ConclusionDans cet article, j'ai examiné trois cas d'utilisation de calcul parallèle et d'algorithmes parallèles. Remplacer les algorithmes standard par la version std :: execution :: par peut sembler très tentant, mais cela ne vaut pas toujours la peine! Chaque opération que vous utilisez dans l'algorithme peut fonctionner différemment et être plus dépendante du processeur ou de la mémoire. Par conséquent, considérez chaque changement séparément.
À retenir:
- l'exécution parallèle fait généralement plus que séquentielle, car la bibliothèque doit se préparer à l'exécution parallèle;
- non seulement le nombre d'éléments est important, mais aussi le nombre d'instructions dont s'occupe le processeur;
- il vaut mieux prendre des tâches indépendantes les unes des autres et des autres ressources partagées;
- les algorithmes parallèles offrent un moyen facile de diviser le travail en threads séparés;
- si vos opérations dépendent de la mémoire, vous ne devez pas vous attendre à des améliorations des performances et, dans certains cas, les algorithmes peuvent être plus lents;
- pour obtenir une amélioration décente des performances, mesurez toujours les délais de chaque problème, dans certains cas, les résultats peuvent être complètement différents.
Un merci spécial à JFT pour son aide avec cet article!
Faites également attention à mes autres sources sur les algorithmes parallèles:
Jetez un coup d'œil à un autre article relatif aux algorithmes parallèles:
comment améliorer les performances avec les algorithmes parallèles Intel Parallel STL et C ++ 17LA FIN
Nous attendons des commentaires et des questions que vous pouvez laisser ici ou à notre
professeur à
la porte ouverte .