Le compilateur d'optimisation AOT est généralement structuré comme suit:
- frontend conversion de code source en représentation intermédiaire
- pipeline d'optimisation indépendant de la machine (IR): une séquence de passes qui réécrit IR pour éliminer les sections et les structures inefficaces qui ne peuvent pas être directement converties en code machine. Parfois, cette partie est appelée milieu de gamme.
- Backend dépendant de la machine pour générer le code assembleur ou le code machine.

Dans certains compilateurs, le format IR reste inchangé tout au long du processus d'optimisation, dans d'autres, son format ou ses modifications sémantiques. Dans LLVM, le format et la sémantique sont fixes, et il est donc possible d'exécuter des passes dans n'importe quel ordre sans risque de compilation incorrecte ou de plantages du compilateur.
La séquence des passes d'optimisation a été développée par les développeurs du compilateur, l'objectif étant de terminer le travail dans un délai acceptable. Il change de temps en temps et, bien sûr, il existe un ensemble différent de passes à exécuter à différents niveaux d'optimisation. L'un des sujets à long terme de la recherche informatique est l'utilisation de l'apprentissage automatique ou d'autres méthodes pour trouver le meilleur pipeline d'optimisation pour une utilisation générale et pour des applications spécifiques pour lesquelles le pipeline par défaut n'est pas bien adapté.
Les principes de conception des passages sont le minimalisme et l'orthogonalité: chaque passage doit bien faire une chose et leur fonctionnalité ne doit pas se chevaucher. En pratique, des compromis sont parfois possibles. En pratique, lorsque deux passes génèrent du travail l'une pour l'autre, elles peuvent être combinées en une seule passe plus grande. De plus, certaines fonctionnalités de niveau IR, telles que le pliage d'opérateurs constants, sont si utiles qu'il est inutile de les mettre dans une passe distincte, LLVM minimise par défaut les opérations constantes lors de la création d'une instruction.
Dans cet article, nous verrons comment certaines optimisations LLVM fonctionnent. Je veux dire que vous avez lu
cette partie sur la façon dont Clang compile la fonction ou que vous comprenez plus ou moins comment fonctionne LLVM IR. Comprendre le formulaire SSA (assignation unique statique) est particulièrement utile:
Wikipedia vous donnera une introduction et
ce livre vous donnera plus d'informations que vous ne le souhaiteriez. Lisez également la
référence du langage LLVM et une
liste de passes d'optimisation .
Voyons comment Clang / LLVM 6.0.1 optimise ce code C ++:
bool is_sorted(int *a, int n) { for (int i = 0; i < n - 1; i++) if (a[i] > a[i + 1]) return false; return true; }
Dans le même temps, nous nous souvenons que le pipeline d'optimisation est un endroit très occupé et nous manquerons beaucoup de moments amusants, tels que:
L'insertion est une optimisation simple mais très importante qui ne se produit pas dans cet exemple, car nous considérons une seule fonction. Presque toutes les optimisations spécifiques à C ++, mais pas à C. Auto-vectorisation, qui empêche une sortie anticipée de la boucle
Dans le texte ci-dessous, je vais ignorer toutes les passes qui n'apportent aucune modification au code. De plus, nous ne nous pencherons pas sur le backend, qui fait également beaucoup de travail. Mais même les passages restants sont beaucoup! (Désolé pour les images, mais cela semble être le meilleur moyen d'éviter les difficultés de formatage).
Voici le fichier IR créé par Clang (j'ai supprimé manuellement l'attribut «optnone» que Clang a inséré) et la ligne de commande utilisée pour voir l'effet de chaque passe d'optimisation:
opt -O2 -print-before-all -print-after-all is_sorted2.ll
Le premier passage est la
simplification du
CFG (graphe de flux de contrôle). Puisque Clang n'effectue pas d'optimisation, l'IR qu'il génère contient des options d'optimisation simples:

Ici, l'unité de base 26 se déplace simplement vers le bloc 27. De tels blocs peuvent être supprimés en redirigeant les références vers eux par le bloc de destination. LLVM renumérote automatiquement les blocs. La liste complète des conversions produites par SimplifyCFG est répertoriée en haut de l'allée.
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
La plupart des opportunités d'optimisation CFG apparaissent grâce au travail d'autres passes LLVM. Par exemple, la suppression de l'élimination du code mort et des invariants de boucles mobiles peut facilement conduire à des blocs de base vides.
Le passage suivant,
SROA (remplacement scalaire des agrégats), est l'un des plus utilisés. Son nom prête à confusion car SROA n'est qu'une de ses fonctions. La passe vérifie chaque instruction alloca (allocation de mémoire sur la pile de fonctions) et essaie de la convertir en registres SSA. Une instruction alloca (
c'est-à-dire, en fait, une variable sur la pile d' environ Transl.) Se transforme en plusieurs registres si elle est affectée statiquement plusieurs fois, et si alloca est une classe ou une structure, elle est divisée en composants (c'est ce qu'on appelle «scalaire» remplacement »mentionné au nom du passage). Une version simple de SROA se rendrait pour empiler les variables pour lesquelles l'opération de prise d'adresse est utilisée, mais la version LLVM interagit avec un algorithme d'analyse d'alias et agit de manière intelligente (bien que cela ne soit pas requis dans l'exemple suivant).

Après SROA, les instructions d'allocation (et les instructions de chargement et de stockage correspondantes) disparaissent et le code devient plus propre et plus adapté aux optimisations suivantes (bien sûr, SROA ne peut pas supprimer toutes les allocations dans le cas général, cela ne se produit que si l'analyse du pointeur peut se débarrasser complètement des alias). Dans le processus, SROA insère des instructions phi dans le code. Les instructions phi forment le cœur de la représentation SSA, et le manque de phi dans le code que Clang génère nous indique que Clang génère une version triviale de SSA, dans laquelle les blocs de base sont connectés via la mémoire et non via les registres SSA.
Ce qui suit est «
élimination précoce de la sous-expression commune », ESC (élimination précoce des sous-expressions communes). CSE essaie d'éliminer les cas de sous-expressions excessives qui peuvent se produire à la fois dans le code écrit par l'homme et dans le code partiellement optimisé. «Early CSE» est une version rapide et facile de CSE qui identifie les calculs redondants triviaux.

Ici,% 10 et% 17 font la même chose, c'est-à-dire que le code peut être réécrit afin qu'une valeur soit utilisée et que la seconde soit supprimée. Cela donne un aperçu des avantages de SSA: lorsque chaque registre n'est attribué qu'une seule fois, il n'existe pas de versions multiples d'un même registre. Ainsi, des calculs redondants peuvent être détectés en utilisant l'équivalence syntaxique, sans utiliser une analyse approfondie du programme (ce n'est pas le cas pour les emplacements de mémoire qui existent en dehors du monde SSA).
Ensuite, plusieurs passes sont lancées qui n'ont aucun effet dans notre cas, puis "
l'optimiseur de variable globale " est lancé, qui est décrit comme suit:
, . , , , , ..Ce passage apporte les modifications suivantes:
Il a ajouté un attribut de fonction: les métadonnées utilisées par une partie du compilateur pour stocker des informations sur ce qui pourrait être utile pour une autre partie du compilateur. Vous pouvez lire sur le but de cet attribut
ici .
Contrairement à d'autres optimisations que nous avons considérées, l'optimiseur de variables globales est interprocédural; il regarde entièrement le module LLVM. Un module est (plus ou moins) l'équivalent d'une unité de compilation en C et C ++. Contrairement à l'optimisation interprocédurale, l'intraprocédural ne voit qu'une seule fonction à la fois.
Le passage suivant combine des instructions et est appelé «
combinateur d'instructions », InstCombine. Il s'agit d'un ensemble important et diversifié d'
optimisations de
judas , qui (généralement) réécrivent certaines instructions, combinées par des données communes, sous une forme plus efficace. InstCombine ne modifie pas le flux de contrôle d'une fonction. Dans l'exemple ci-dessus, il n'a pas beaucoup changé:
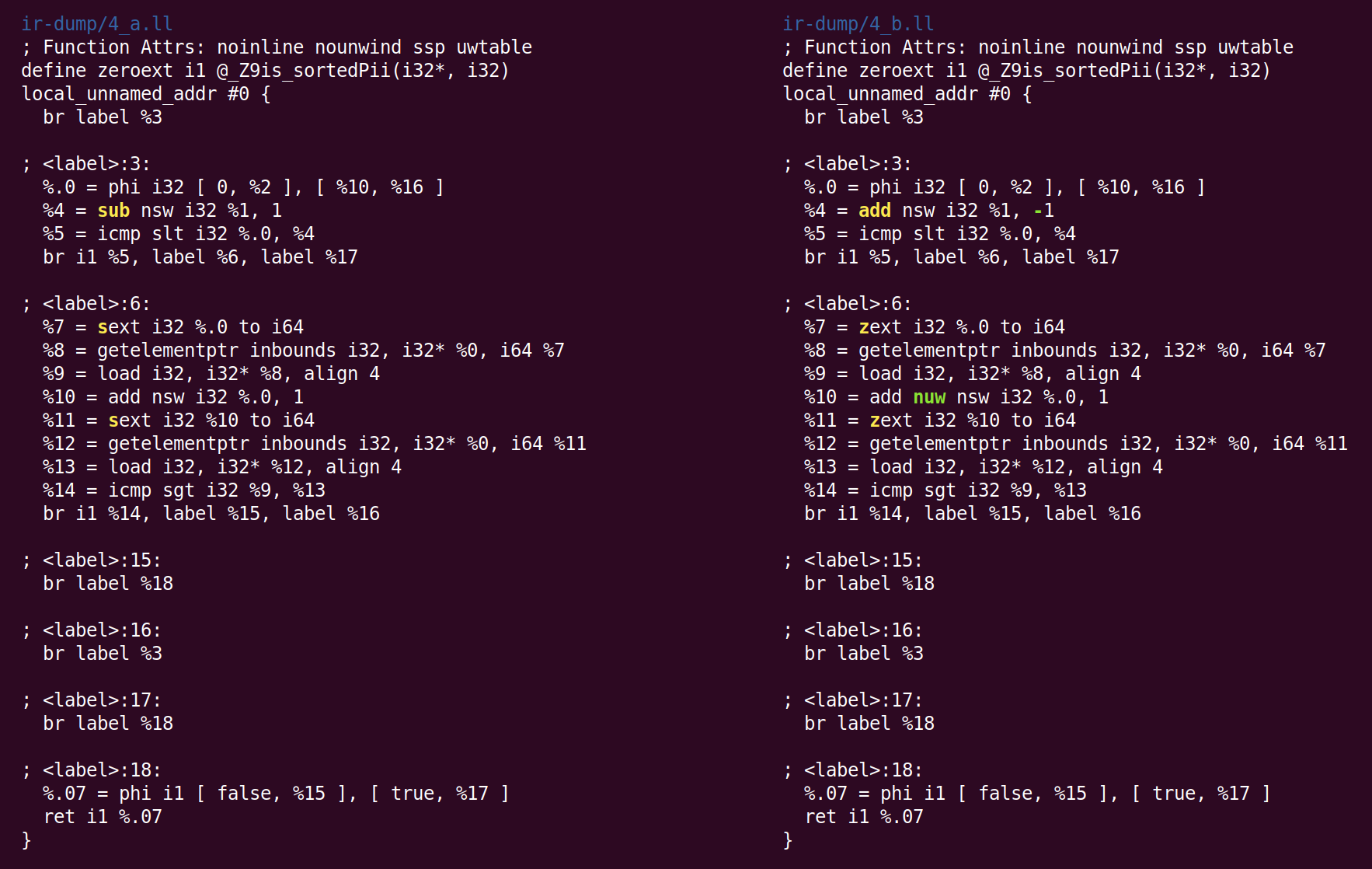
Ici, au lieu de soustraire 1 de% 1, afin de calculer% 4, nous ajoutons -1. Ce n'est pas une optimisation, mais une canonisation. Lorsqu'il existe de nombreuses façons de faire le calcul, LLVM essaie de l'amener à la forme canonique (souvent choisie au hasard) que les passes et les backends suivants s'attendent à voir. La deuxième modification apportée par InstCombine est la forme canonique de deux opérations d'expansion signées (l'instruction sext), qui calculent% 7 et% 11 convertis en expansion nulle (zext). Cette conversion est sûre lorsque le compilateur peut prouver que l'opérande sext n'est pas négatif. Dans ce cas, cela est dû au fait que la variable de boucle passe de 0 à n (si n est négatif, la boucle ne s'exécute pas du tout). La dernière modification a été l'ajout de l'indicateur «nuw» (pas de retour à la ligne non signé) à l'instruction qui calcule% 10. Nous pouvons voir que cela est sûr, du fait que (1) la variable de boucle augmente toujours et (2) si la variable commence à zéro et augmente, elle deviendrait indéfinie lorsque le signe change à l'intersection INT_MAX avant d'atteindre un débordement non signé, suivant UINT_MAX. Cet indicateur peut être utilisé pour des optimisations ultérieures.
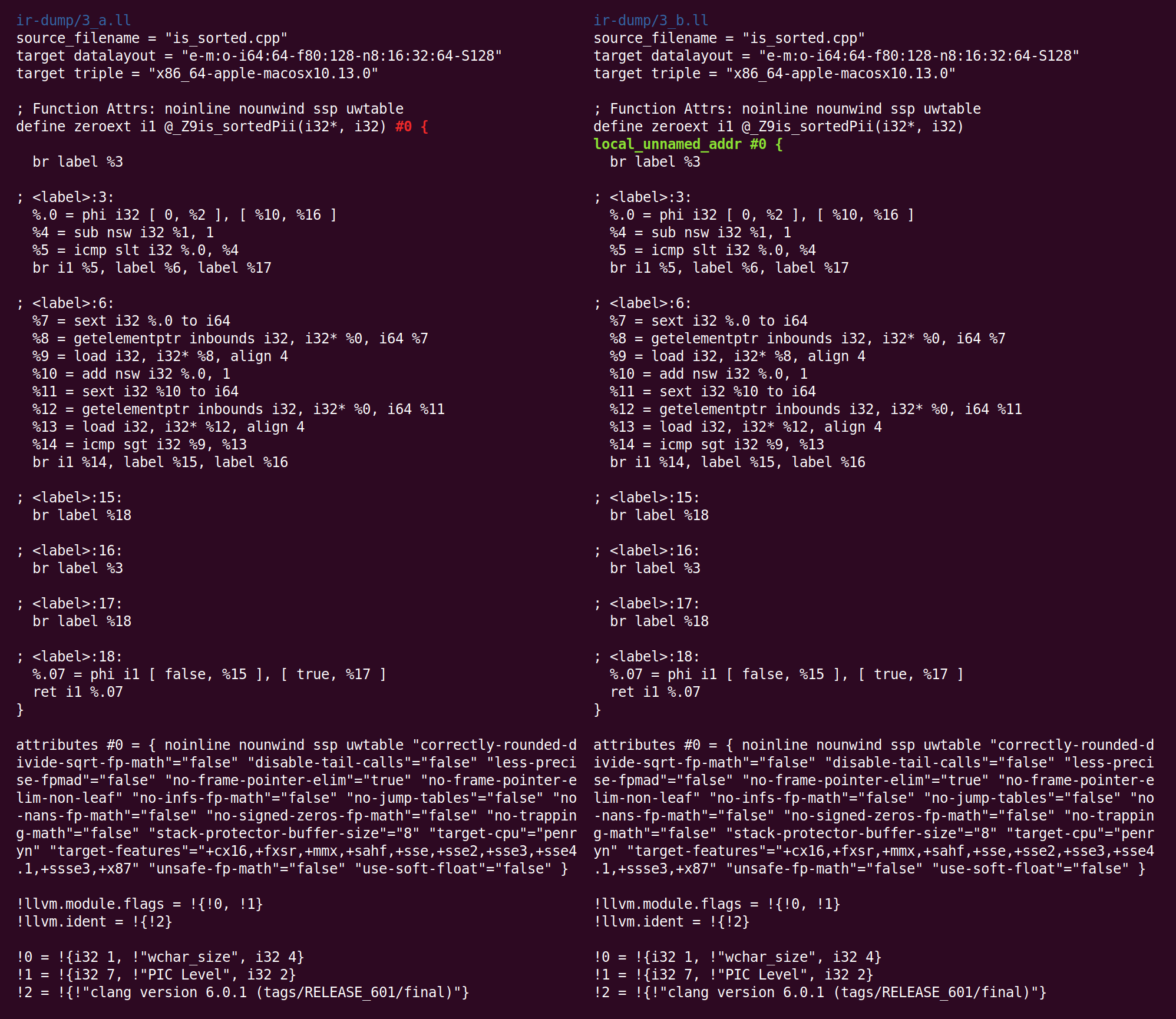
Ensuite, SimplifyCFG démarre une deuxième fois et supprime deux blocs de base vides:
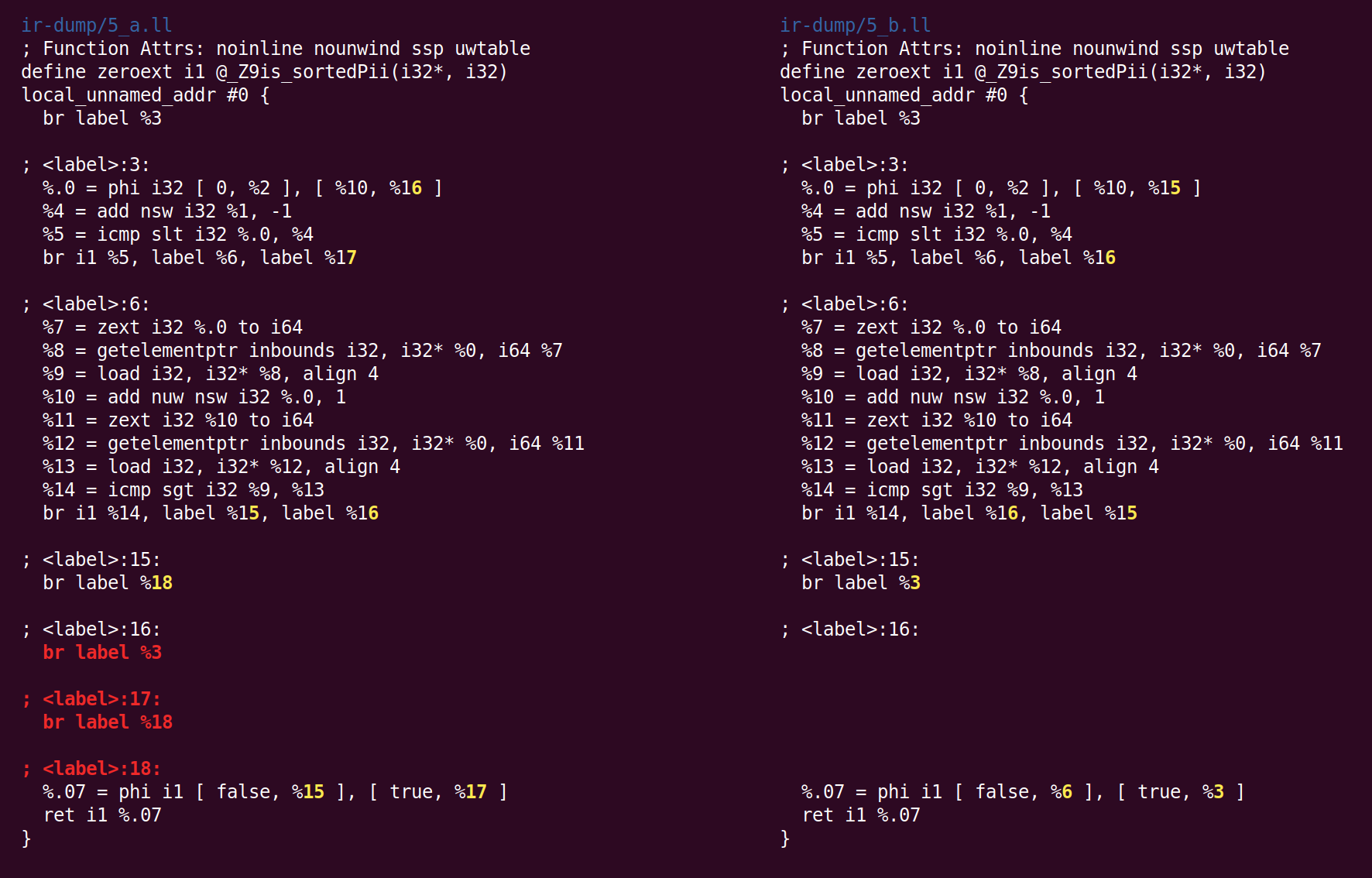
Ensuite, le passage "Déduire les attributs de fonction" annote la fonction:

«Norecurse» signifie que la fonction n'est incluse dans aucun appel récursif, «en lecture seule» signifie que la fonction ne change pas l'état global. L'attribut de paramètre «nocapture» signifie que le paramètre n'est enregistré nulle part après avoir quitté la fonction, et «en lecture seule» signifie que la mémoire n'est pas modifiée par la fonction. Vous pouvez voir une
liste d' attributs de fonction et d'
attributs de paramètre .
Ensuite, la passe «
faire tourner les boucles » déplace le code dans le but d'améliorer les conditions des optimisations suivantes:

Bien que la différence semble intimidante, les changements sont en fait minimes. Nous pouvons voir ce qui s'est passé, d'une manière plus lisible, si nous demandons à LLVM de dessiner un graphique de transfert de contrôle avant et après avoir traversé les cycles de rotation. Voici leur vue avant (gauche) et après (droite):
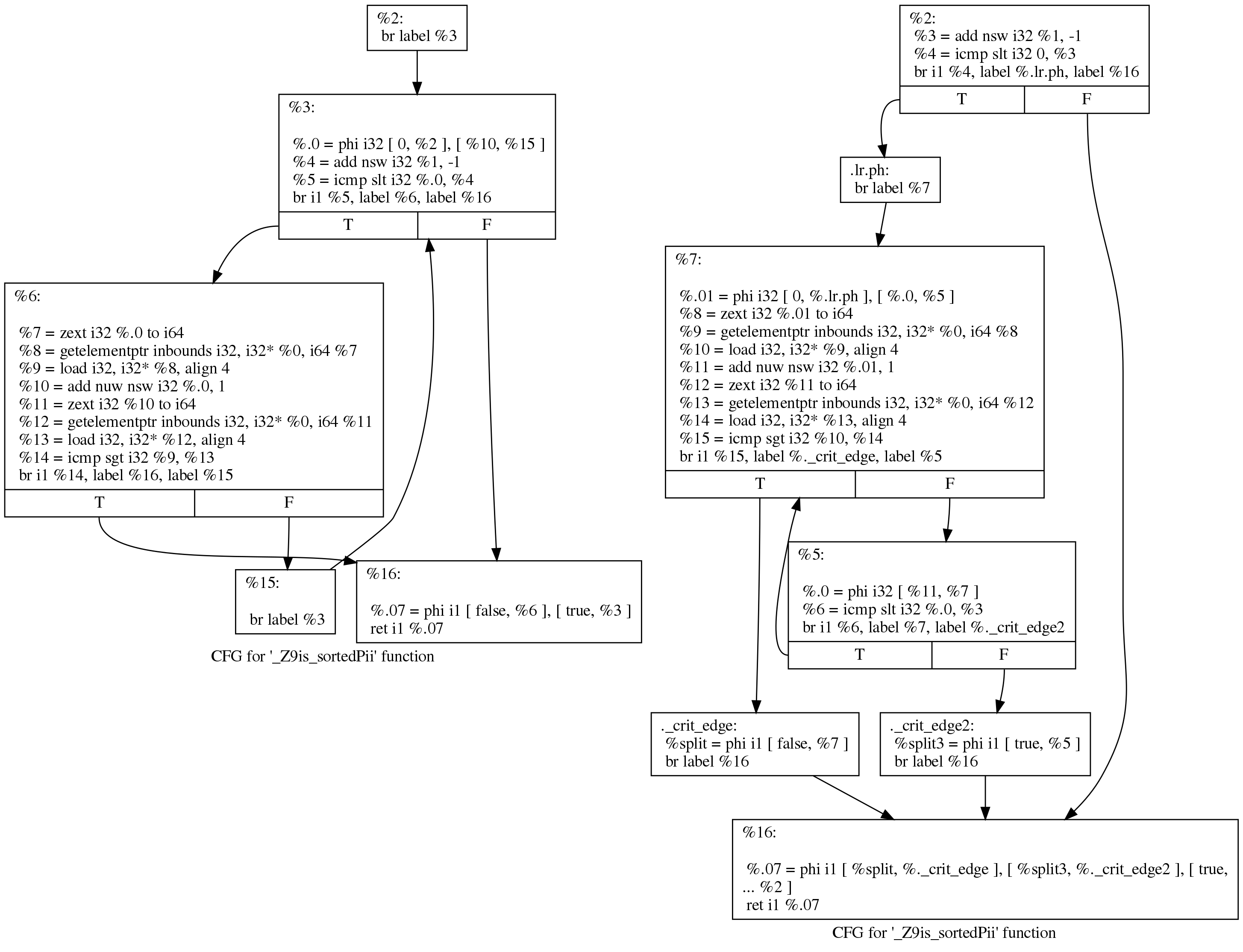
Le code d'origine suit toujours la structure de boucle générée par Clang:
initializer goto COND COND: if (condition) goto BODY else goto EXIT BODY: body modifier goto COND EXIT:
Après l'exécution, la boucle ressemble à ceci:
initializer if (condition) goto BODY else goto EXIT BODY: body modifier if (condition) goto BODY else goto EXIT EXIT:
(Les corrections proposées par Johannes Durfert sont listées ci-dessous - merci!)
Le but de la passe de rotation de boucle est de supprimer une branche, ce qui permet d'autres optimisations. Je n'ai pas trouvé de meilleure description de cette conversion sur Internet.
La passe de simplification CFG minimise deux blocs de base qui contiennent uniquement des instructions phi dégénérées (entrée unique):

La passe du combinateur d'instructions transforme «% 4 = 0 s <(% 1 - 1)» en «% 4 =% 1 s> 1» (où s <et s> sont des opérations de comparaison d'opérandes signés), ceci transformation utile, elle réduit la longueur des chaînes de dépendances et peut également créer des instructions «mortes» (inaccessibles) (voir le
patch qui fait ça). Cette passe supprime également les instructions phi triviales qui ont été ajoutées par la passe de rotation de boucle.

Ce qui suit est le passage «
canonicalize natural loops », qui est décrit dans son propre code source comme suit:
, .
(Loop pre-header) , , . ,, LICM.
, , ( ) ( ). , , "store-sinking", LICM.
, (backedge).
Indirectbr . , . , , .
, simplifycfg , , , .
, , CFG, .
Ici, nous voyons que le bloc de sortie a été inséré:
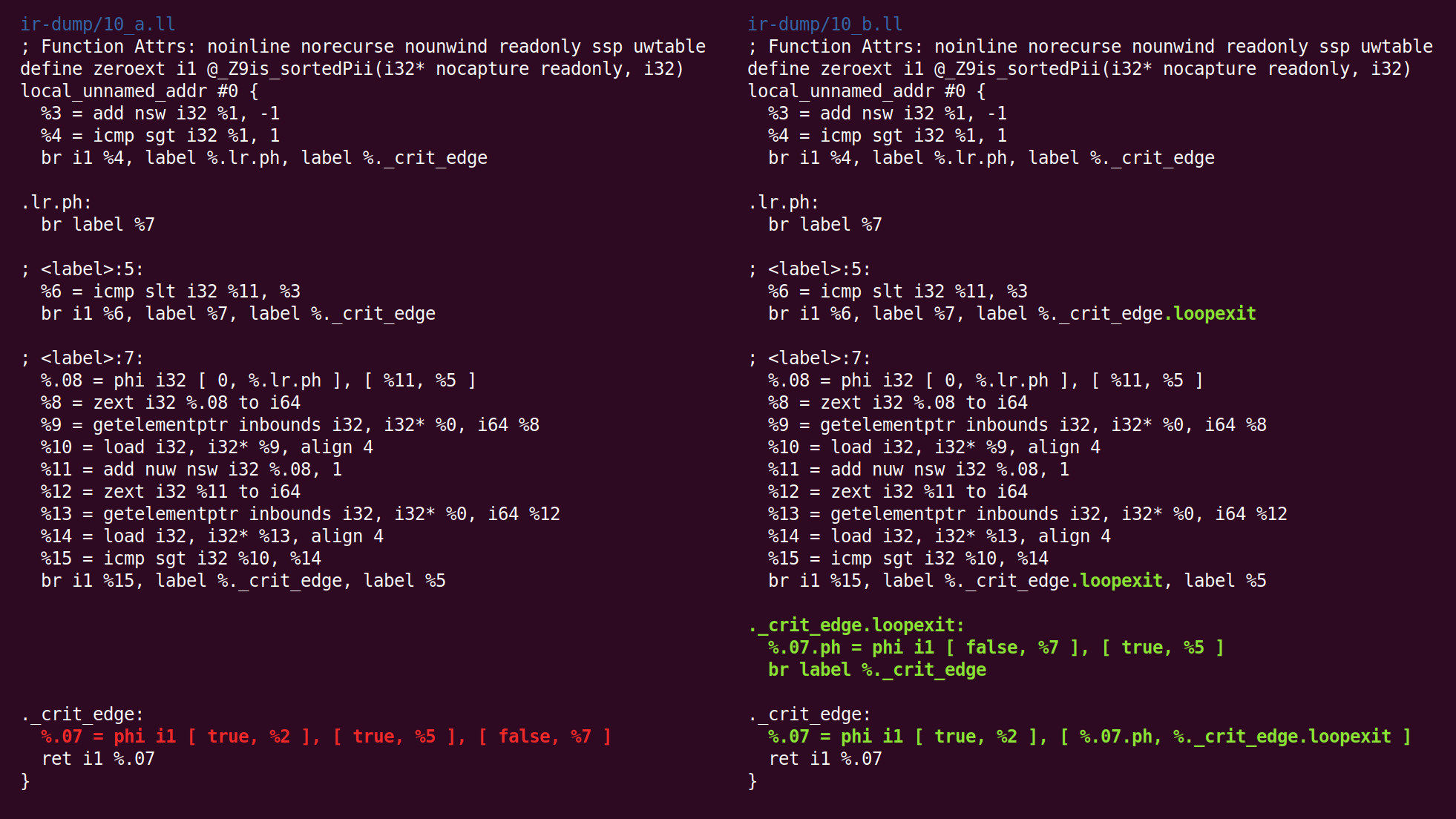
Suit ensuite la "
simplification de la variable de boucle ":
( , ), , .
, :
, . , 'for (i = 7; i*i < 1000; ++i)' 'for (i = 0; i != 25; ++i)'.
indvar , . , "".
L'effet de cette passe sera de changer la variable de boucle 32 bits en 64 bits:
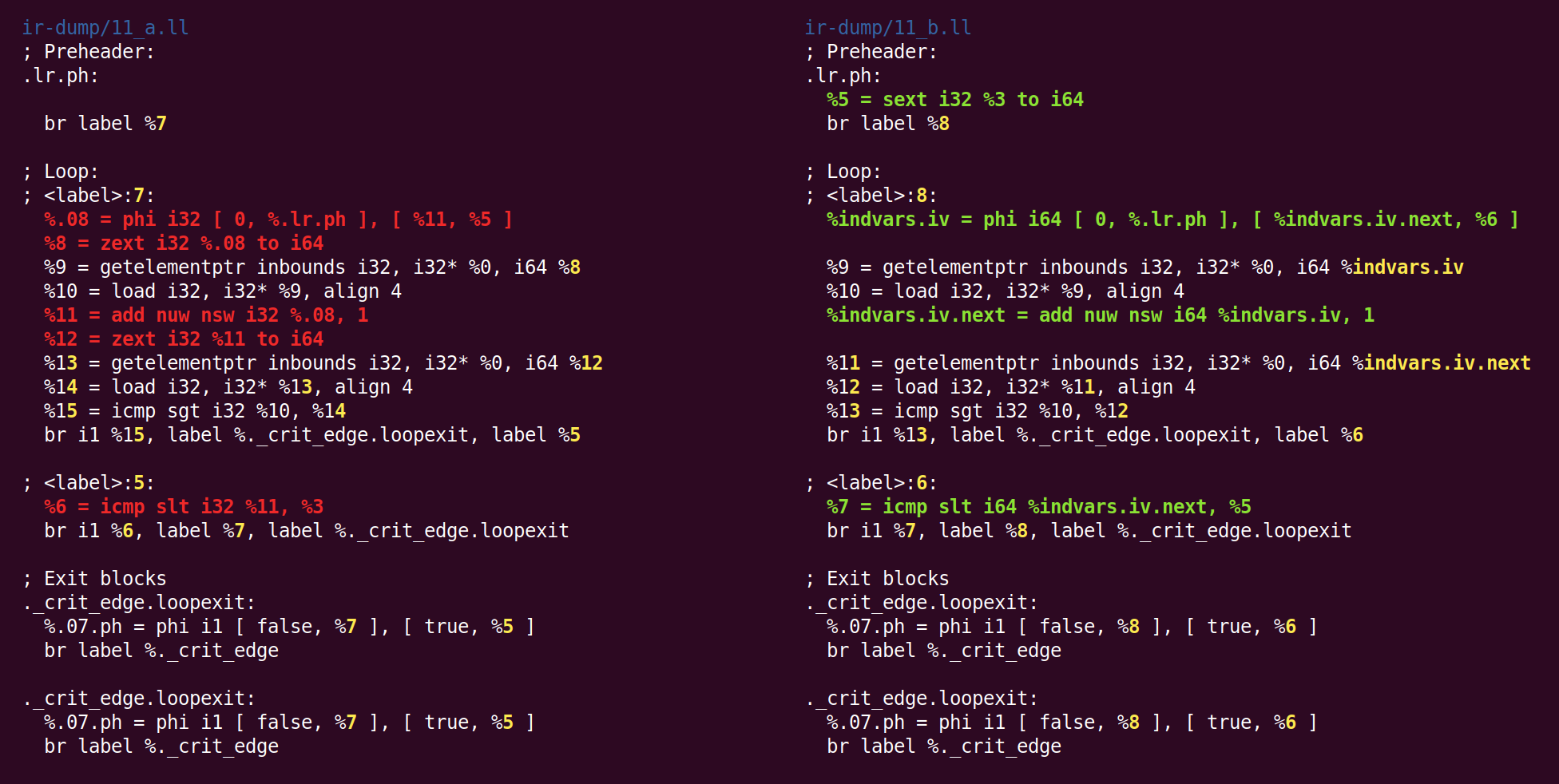
Je ne sais pas pourquoi zext - précédemment converti en forme canonique à partir du sext, est revenu à nouveau au sext.
Maintenant, le passage «
numérotation de valeur globale » effectue une optimisation très intelligente. L'une des raisons de la rédaction de ce message est le désir de le montrer. La voyez-vous ici?

Tu as vu? Oui, deux instructions de chargement dans la boucle de gauche, correspondant à un [i] et un [i + 1]. Ici, le GVN a constaté qu'un [i] n'était pas nécessaire pour charger, car un [i + 1] d'une itération de la boucle pouvait être transféré à la suivante, comme un [i]. Cette astuce simple réduit de moitié le nombre de lectures en mémoire effectuées par la fonction. LLVM et
GCC n'ont appris à effectuer cette transformation que récemment.
Vous pourriez vous demander si cette astuce fonctionnera si nous comparons un [i] avec un [i + 2]. Il s'avère que non, mais GCC peut allouer
jusqu'à quatre registres pour de tels cas.
Ensuite, la passe «
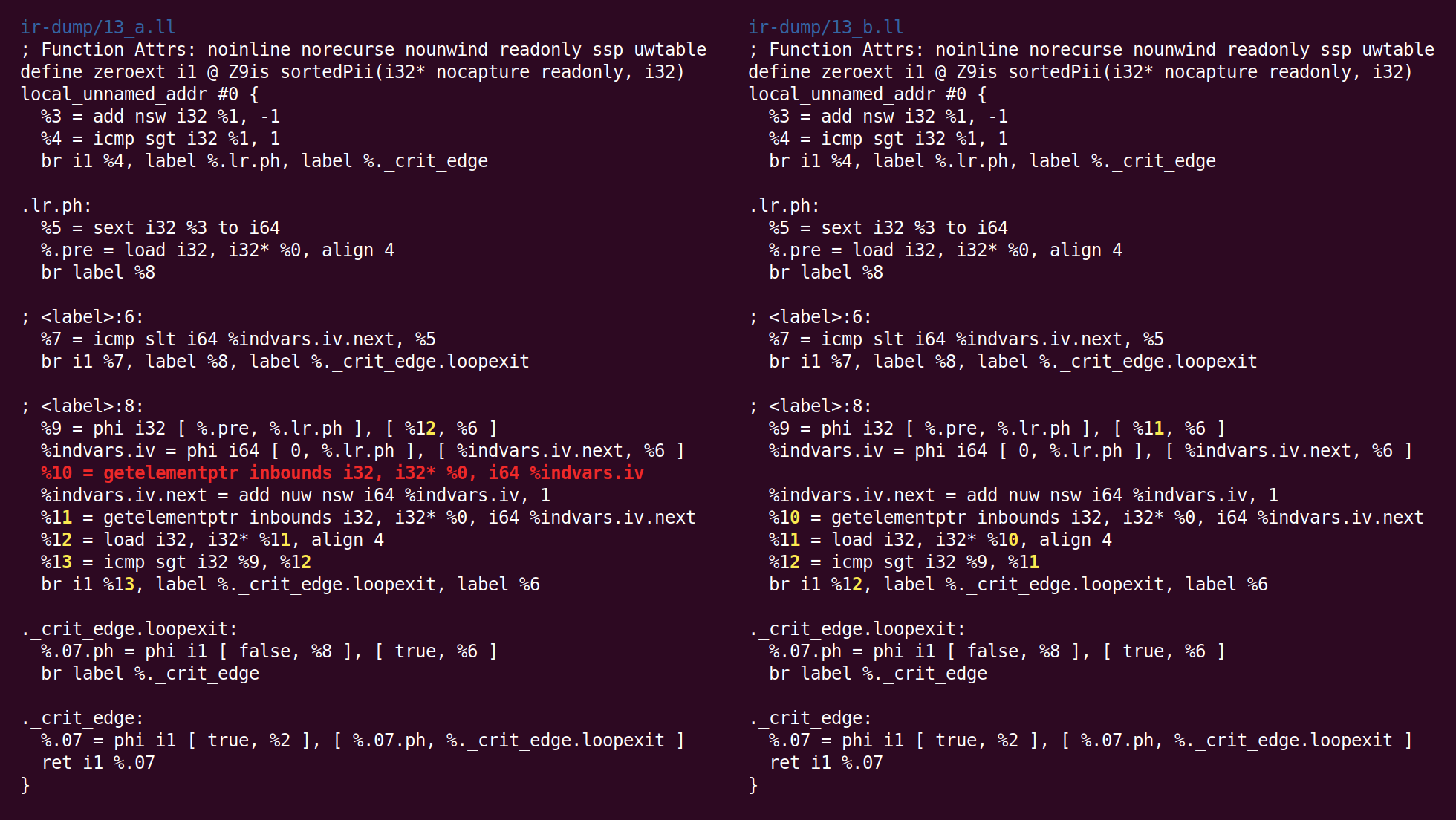
élimination du code mort de suivi des bits » commence:
"Bit-Tracking Dead Code Elimination". (, "" "" ..) "" . , "" .Mais ici, il s'avère que de telles astuces ne sont pas nécessaires, car le seul code mort est l'instruction GEP (get element pointer), et il est trivialement mort (la passe GVN a supprimé l'instruction de chargement qui utilisait l'adresse calculée par cette instruction):
Maintenant, l'algorithme de combinaison des instructions a placé add dans une autre unité de base. La logique par laquelle cette transformation a été placée dans InstCombine n'est pas claire pour moi, peut-être qu'il n'y avait aucun endroit évident où elle pourrait être placée:

Quelque chose de plus étrange se produit maintenant: le pass «
jump threading » a supprimé ce que le pass «canonicalize natural loops» a fait auparavant:

Ensuite, nous avons à nouveau coulé sous la forme canonique:
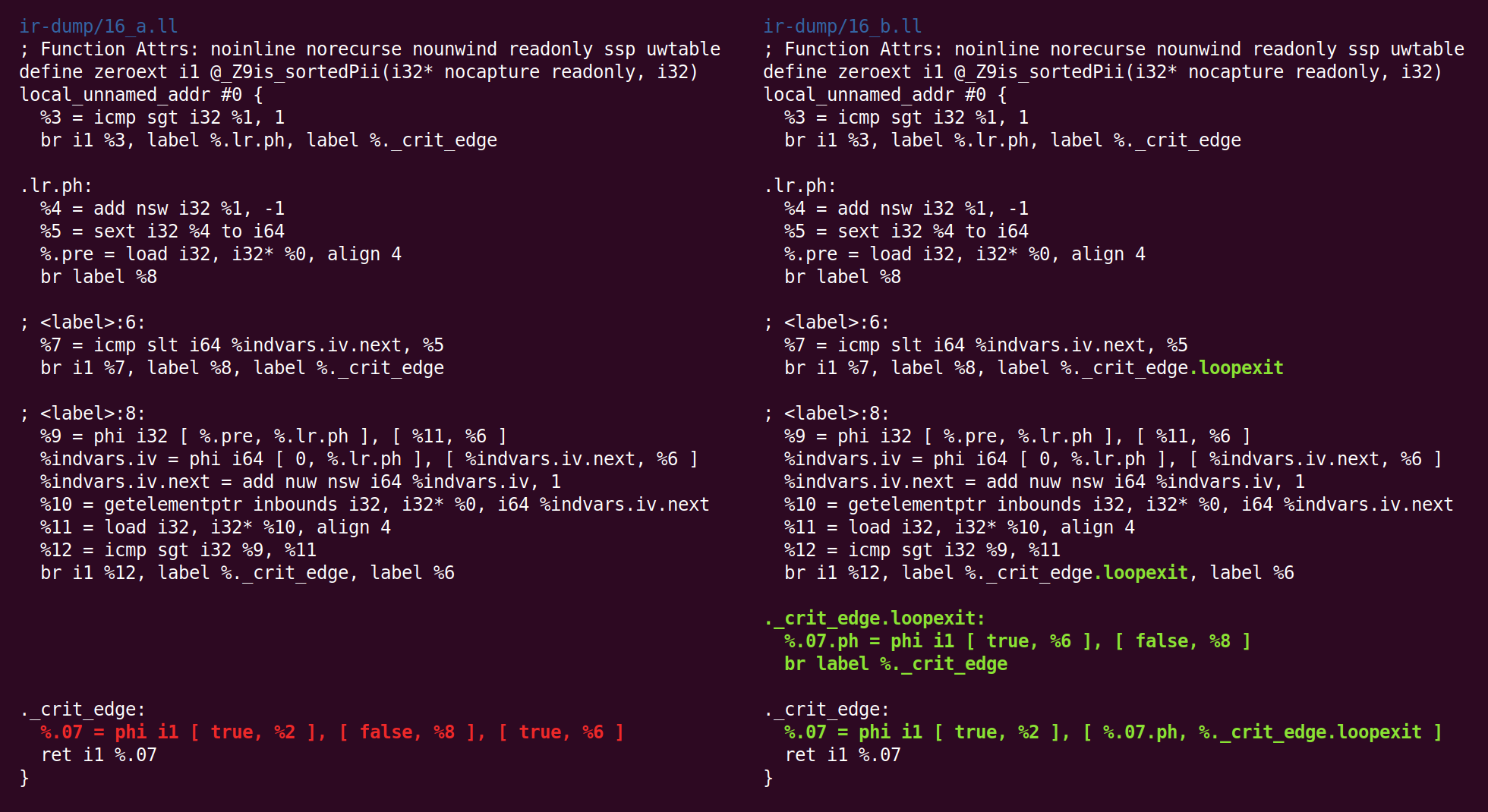
Et la simplification du CFG le transforme différemment:
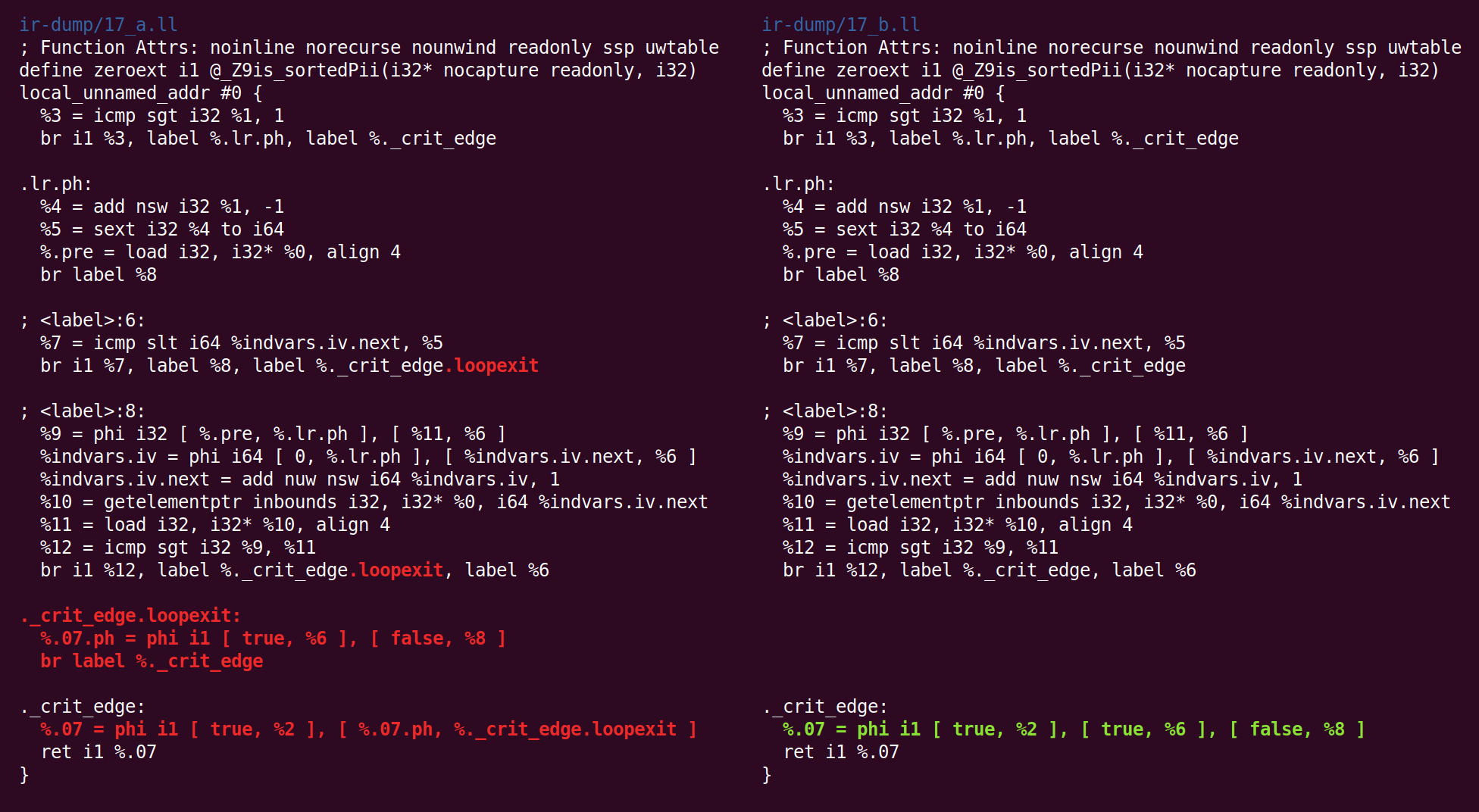
Et retour:
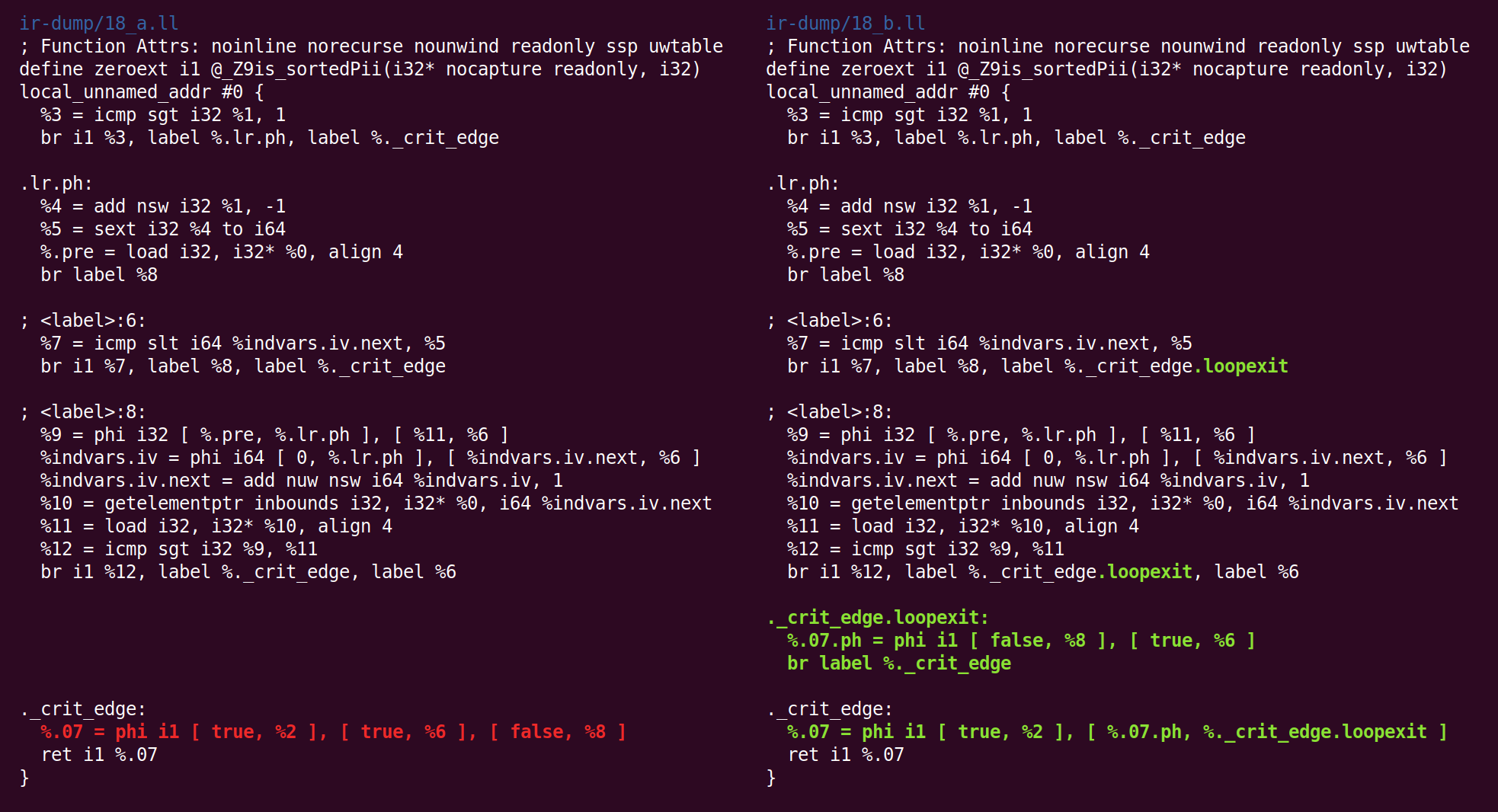
Et là encore:

Et retour:
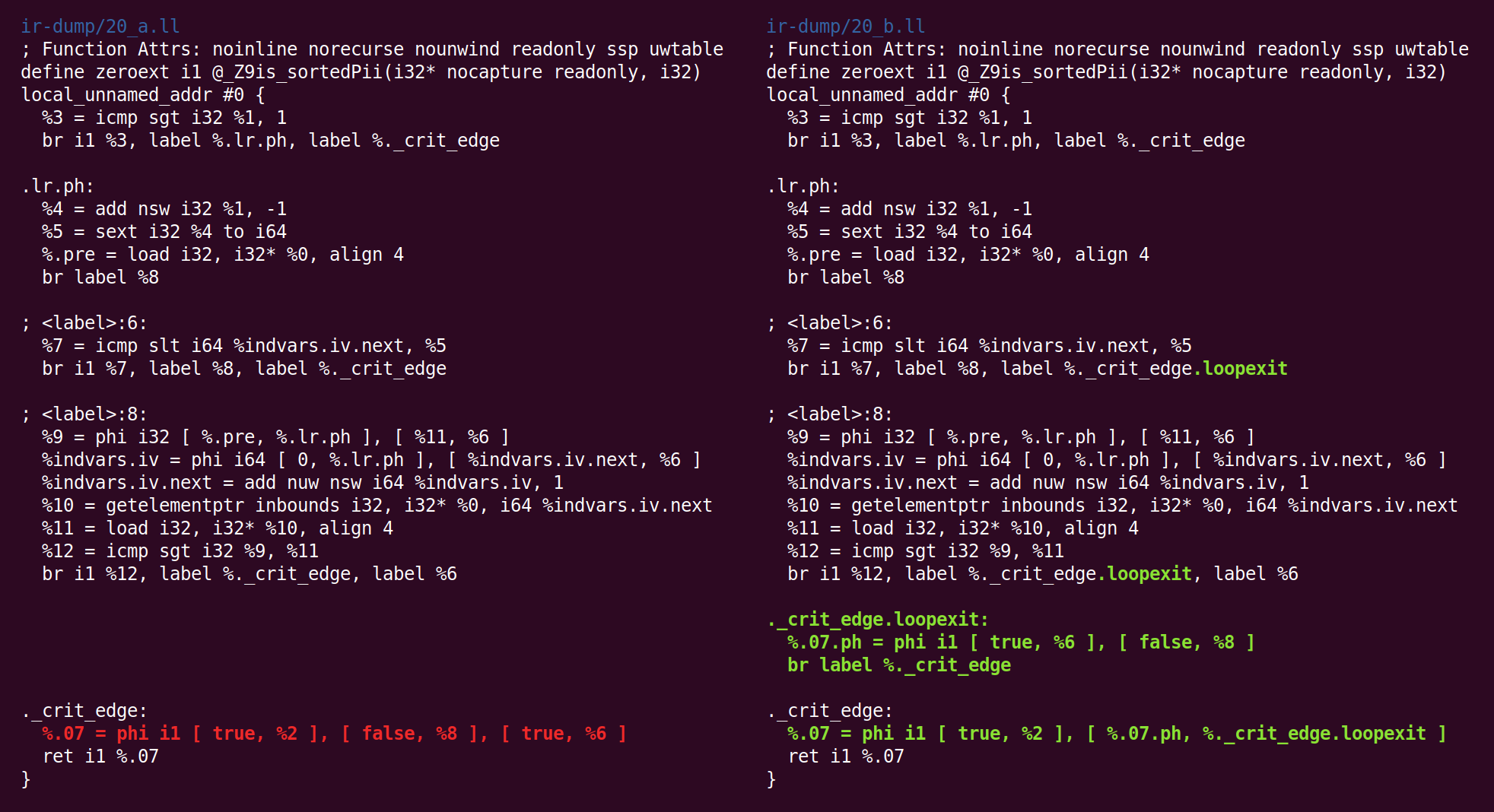
Et là:

Et enfin, nous avons fini avec le Midland! Le code à droite est le code que nous transmettrons (dans notre cas) au backend x86-64.
Vous pouvez être curieux si les fluctuations du comportement à la fin du pipeline sont le résultat d'un bogue du compilateur, mais prenons en compte que cette fonction est très, très simple et qu'il y a beaucoup de passes impliquées dans son traitement, mais je ne les ai même pas mentionnées car elles n'a apporté aucune modification au code. Tout au long de la seconde moitié du pipeline d'optimisation, nous observons principalement des cas dégénérés pour cette fonction.
Remerciements: certains étudiants de mon cours de compilateur approfondi cet automne ont laissé des commentaires sur une ébauche de ce message (et j'ai également utilisé ce matériel pour les devoirs). J'ai parcouru les fonctions discutées ici dans
ce bon ensemble de conférences sur l'optimisation de boucle.