Comment normaliser correctement l'événement? Comment normaliser des événements similaires de différentes sources sans rien oublier ou confondre? Mais que se passe-t-il si deux experts le font indépendamment? Dans cet article, nous partagerons une méthodologie de normalisation commune qui peut aider à résoudre ce problème.
Image: Martinoflynn.comLe plus souvent, les règles de corrélation sont basées sur des événements normalisés. Ainsi, la normalisation des événements et leur exécution correcte affectent directement la précision des règles de corrélation.
Les problèmes posés par la normalisation des événements ont été formulés dans le premier article (
ici ), et les solutions ont été proposées dans les articles suivants (
ici et
ici ). Nous résumons maintenant ce qui a été décrit précédemment et formons une approche générale de la normalisation des événements.
Pour commencer, nous rappelons quels outils du niveau de normalisation nous avons développés:
- Schéma de champ générique requis pour stocker les données extraites des événements. Ses caractéristiques:
- Il prend en compte la présence d'entités dans l'événement: sujet, objet, source et émetteur d'événements, ainsi que ressource.
- Fournit une normalisation correcte dans les cas où l'événement contient des entités de niveau réseau et des applications , et lorsqu'il a plus d'un sujet et / ou objet.
- Vous permet d'identifier et de maintenir explicitement la structure du processus d'interaction entre le sujet et l'objet
- Système de catégorisation d'événements capable de refléter la sémantique d'un événement IT ou IB.
Méthodologie de normalisation des événements
L'ensemble de la méthodologie de normalisation des événements comprend trois étapes:
- Expertise de l'événement.
- Définition du schéma d'interaction.
- Définition de catégorie d'événement.
Pour faciliter la compréhension du fonctionnement de l'outil, nous sélectionnerons un événement et considérerons en détail toutes les étapes de normalisation selon notre méthodologie.
Supposons que nous ayons une source - SGBD Oracle Database avec l'adressage réseau suivant:
- IP : 10.0.0.1;
- Nom d'hôte : myoracle;
- FQDN : myoracle.local.
À partir de cette source, l'agent SIEM décharge l'événement suivant:

Étape 1. Évaluation experte de l'événement
Au tout début du processus de normalisation d'un événement, il est important de comprendre de quoi il s'agit. Il suffit de se dire son essence. Si un expert, à partir de l'événement initial, pas encore normalisé, ne comprend pas quels processus se produisent à la source, nous parlons, avec une forte probabilité qu'il le normalisera incorrectement. De quel type de fonctionnement correct des règles de corrélation peut-on alors parler?
Le problème avec la façon dont l'expert interprète correctement l'événement est réel. Par exemple, un expert peut-il comprendre ce que signifie le prochain événement?
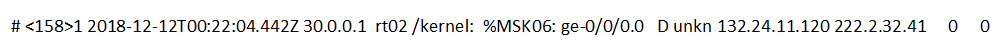
Si, dans l'exemple d'origine, l'essence peut être capturée dans le texte de l'événement lui-même, alors dans ce cas, vous devez bien comprendre avec quelle source vous travaillez et dans quels cas il génère un événement similaire. Parfois, vous devez même déployer un stand séparé avec une source afin de reproduire pleinement la situation dans laquelle il envoie un événement complexe et difficile à interpréter au SIEM.
Revenons à l'
exemple d' origine avec un événement de la base de données Oracle. À ce stade, l'expert devrait penser comme ceci:
"
En tant qu'expert, je pense que l'événement initial décrit le processus de révocation d'un rôle par un utilisateur d'un autre dans une base de données Oracle ."
Étape 2. Détermination du schéma d'interaction
L'étape précédente nous permet de nous assurer que nous pouvons comprendre au moins la signification générale de l'événement. Nous allons maintenant analyser en détail comment distinguer les entités et déterminer le schéma de leur interaction.
Selon cette méthodologie, pour chaque
schéma d'interaction, il est nécessaire de décrire les règles de distribution des identifiants d'entités clés dans les champs d'un événement normalisé. Dans le même temps, des règles sont définies pour:
- Entités au niveau du réseau
- Entités du niveau application.
Il est important de se rappeler qu'il existe des schémas dans lesquels le sujet est égal à l'objet et égal à la source. Pour de tels régimes, il est nécessaire de définir clairement les règles de remplissage des champs des trois entités. Si cela n'est pas fait, alors, au niveau des règles de corrélation ou de la recherche d'événements, des problèmes vont commencer et une logique supplémentaire apparaîtra pour l'interprétation correcte des champs vides. À ce sujet - dans l'article consacré
aux schémas d'interaction .
Voyons comment cette étape de la méthodologie fonctionne sur l'
exemple initial:
- Schéma d'interaction au niveau du réseau : schéma complet de collecte directe, sans émetteur.
- Schéma d'interaction au niveau de l'application : interaction via une ressource.
Pour ces schémas, les règles de normalisation suivantes peuvent être définies:
- Entités de couche réseau:
- Objet :
- Champ: src.ip = <empty>
- Champ: src.hostname = alex_host
- Champ: src.fqdn = <empty>
- Objet
- Champ: dst.ip = 10.0.0.1
- Champ: dst.hostname = myoracle
- Champ: dst.fqdn = myoracle.local
- Source (correspond à l'objet) :
- Champ: event_source.ip = 10.0.0.1
- Champ: event_source.hostname = myoracle
- Champ: event_source.fqdn = myoracle.local
- Emetteur :
- Champ: forwarder.ip = <empty>
- Champ: forwarder.hostname = <empty>
- Champ: forwarder.fqdn = <empty>
- Canal d'interaction :
- Champ: interaction.id = 2342594
- Entités du niveau application (collection d'éléments):
- Objet :
- Champ: sujet [1] .name = “Alex”
- Champ: subject [1] .type = “account”
- Objet
- Champ: objet [1] .name = "Bob"
- Champ: objet [1] .type = “account”
- Ressource :
- Champ: ressource [1] .name = "MYROLE"
- Champ: ressource [1] .type = “role”
Étape 3. Définition d'une catégorie d'événement
Une fois que toutes les entités clés de l'événement ont été identifiées, il est nécessaire de décrire l'essence du processus reflété dans l'événement et de le transférer dans le langage de normalisation. À ces fins, un système de catégorisation des événements est utilisé. Le système de catégorisation des événements a été discuté en détail dans un
article séparé, voyons maintenant comment il fonctionne dans la pratique.
Afin d'unifier la normalisation, le système de catégorisation définit les règles suivantes:
- Pour chaque catégorie de chaque niveau d'événements informatiques et de sécurité de l'information, un expert forme un répertoire avec une liste des informations qui doivent être trouvées dans l'événement initial et normalisées.
- Si un événement a été affecté à une catégorie, l'expert, conformément au répertoire, est obligé de trouver les informations requises et de les normaliser.
- Chaque catégorie définit un ensemble de champs de schéma d'événements normalisés qui doivent être remplis.
Ainsi, la catégorie sélectionnée pour l'événement établit une correspondance directe entre:
- sémantique des événements;
- informations importantes à extraire de l'événement, selon la catégorie apposée;
- un ensemble de champs du schéma d'un événement normalisé dans lequel ces informations doivent être "mises".
Cette approche vous permet de comprendre clairement à partir de la catégorie de tout événement quelles données se trouvent dans quels champs de l'événement normalisé.
Si, avec le soutien de nouvelles sources, il s'avère que certaines informations importantes doivent être extraites en plus des événements d'une certaine catégorie, alors elles sont entrées dans le répertoire. Dans ce cas, vous avez besoin de:
- définir des règles pour remplir les champs du schéma d'événement;
- effectuer un audit de normalisation des événements de cette catégorie de toutes les sources précédemment prises en charge;
- Ajoutez de nouvelles informations aux événements précédemment normalisés.
De cette façon, la cohérence des modifications apportées est maintenue. Prenons l'exemple original.
Selon le système de catégorisation, cet événement a les catégories suivantes:
- Système de catégorisation : événements informatiques
- Catégorie de premier niveau (niveau 1) : utilisateur et droits
- Catégorie de deuxième niveau (niveau 2) : utilisateur
- Catégorie de troisième niveau (niveau 3) : manipulation
Le répertoire de cette catégorie ressemble à ceci:
- Lors de la normalisation des événements dans la catégorie Utilisateur et droits , il est important de comprendre:
- Si une élévation de privilèges a été utilisée, alors au nom de qui le processus est mis en œuvre.
- Les actions ont-elles réussi?
- Quel est le code retour.
- Champ: result.status.code
- Lors de la normalisation des événements de la catégorie Utilisateur , il est important de comprendre:
- Existe-t-il des informations sur l'adresse IP, le nom d'hôte ou le nom de domaine complet de la machine de l'utilisateur?
- Champs: src.ip, src.hostname, src.fqdn
- Champs: dst.ip, dst.hostname, dst.fqdn
- Sous quel compte l'utilisateur s'est connecté.
- Champs: sujet [i] .name, objet [i] .name
- Existe-t-il des informations sur son compte dans le système d'exploitation?
- Champs: sujet [i] .osname, objet [i] .osname
- Existe-t-il des informations sur le compte de domaine?
- Champs: sujet [i] .domain, objet [i] .domain
- Existe-t-il des informations sur l'application de l'utilisateur?
- Champs: sujet [i] .application, objet [i] .application
- Lors de la normalisation des événements dans la catégorie Manipulation , il est important de comprendre:
- Type d'opération.
- Ce qui a changé.
- Champ: objet [i] .name, objet [i] .type - lors du changement de compte
- Champ: ressource [i] .nom, ressource [i] .type - lors du changement de ressources
- Ce qui a changé.
- Champ: objet [i] .modify
- Champ: ressource [i] .modify
- Si l'opération était sur une ressource, qui en est le propriétaire.
- Champ: ressource [i] .owner
Nous avons donné ce guide pour démontrer le principe de sa formation, donc il ne prétend pas être précis et complet.
En conséquence, l'événement normalisé par cette méthodologie ressemble à ceci:
 Un exemple d'événement normalisé dans la troisième étape de la méthodologie.
Un exemple d'événement normalisé dans la troisième étape de la méthodologie.Conclusions
L'expérience montre que ce sont souvent les erreurs de normalisation et l'absence de règles de normalisation uniformes qui conduisent souvent à des faux positifs des règles de corrélation. Nous avons maintenant une approche qui permet, sinon de se débarrasser, de minimiser au minimum l'impact du problème.
Donc, pour résumer - l'approche comprend trois étapes:
- Étape 1 L'expert essaie de comprendre l'essence générale du phénomène décrit dans l'événement initial.
- Étape 2 L'expert identifie les principales entités du réseau et le niveau d'application dans l'événement: sujet, objet, source, émetteur, ressource, canal d'interaction. Il les isole dans l'événement et détermine le modèle d'interaction de ces entités. Chaque schéma génère des règles pour placer ces entités dans les champs d'un événement normalisé - un schéma. Cela a été décrit en détail dans un article consacré aux schémas d'interaction d'entité.
- Étape 3 L'expert détermine la catégorie des premier, deuxième et troisième niveaux. Pour chaque catégorie, il crée un répertoire qui comprend une description des données qu'il est important de trouver dans l'événement lors de sa normalisation, des informations sur les champs de l'événement normalisé qu'il est nécessaire de "mettre" les données trouvées.
Maintenant, de la construction des règles de corrélation pour «travailler hors de la boîte», nous ne sommes séparés que par le problème des changements constants dans les entités elles-mêmes - les actifs. Leurs adresses changent, de nouveaux actifs sont introduits, les anciens sont mis hors service, les nœuds de cluster passent et les machines virtuelles passent d'un centre de données à un autre et, parfois, même avec un changement d'adressage. Comment surmonter ces problèmes, nous parlerons dans le prochain article du cycle.
Série d'articles:Profondeurs SIEM: corrélations prêtes à l'emploi. Partie 1: Marketing pur ou problème insoluble?Profondeurs SIEM: corrélations prêtes à l'emploi. Partie 2. Le schéma de données comme reflet du modèle «monde»Profondeurs SIEM: corrélations prêtes à l'emploi. Partie 3.1. Catégorisation des événementsProfondeurs SIEM: corrélations prêtes à l'emploi. Partie 3.2. Méthodologie de normalisation des événements (
cet article )
Profondeurs SIEM: corrélations prêtes à l'emploi. Partie 4. Modèle de système comme contexte de règles de corrélationProfondeurs SIEM: corrélations prêtes à l'emploi. Partie 5. Méthodologie pour développer des règles de corrélation