Dans des conditions de charge élevée, la complexité de l'optimisation des bases de données relationnelles augmente d'un ordre de grandeur, car l'achat de matériel encore plus puissant coûte cher et il n'y a aucun moyen de désactiver l'application la nuit pour un long processus de modification de la base de données et la migration des données.
Nous avons récemment expliqué comment nous avons
optimisé le code PHP pour notre application . Maintenant, le tour de l'article est venu sur la façon dont nous avons complètement changé la structure interne de la base de données la plus chargée et la plus importante de Badoo, sans perdre une seule demande.
Patient
Les utilisateurs DataBase, ou UDB, est un service qui lance presque n'importe quelle demande à Badoo. Il résout plusieurs problèmes: tout d'abord, c'est le référentiel central des principales données utilisateur pour lesquelles l'autorisation a lieu (par exemple, email, user_id ou facebook_id). En plus de stocker ces données, le service offre un contrôle d'unicité (de sorte que deux utilisateurs avec le même e-mail, facebook_id, etc. ne peuvent pas s'enregistrer dans le système). Et le même service donne des informations sur lequel des milliers de fragments contient toutes les autres données utilisateur.
Fin 2018, UDB stocke les données de plus de 800 millions d'utilisateurs, qui occupent environ 1 To d'espace disque. Tout cela est servi par des paires de serveurs MySQL maître-esclave dans chacun de nos centres de données. Au total, ils traitent plus de 140 000 demandes par seconde.
La chute de l'UDB signifie l'inaccessibilité de tous les Badoo, car le code ne pourra pas trouver le fragment sur lequel se trouvent les données utilisateur. Par conséquent, des exigences énormes lui sont imposées en termes de fiabilité et de disponibilité.
En raison de cette spécificité, il est très coûteux d'apporter des modifications à la structure de stockage, nous avons donc pris très au sérieux la conception UDB en 2013. Cependant, au fil du temps, les exigences ainsi que les profils de charge changent. Dans le but d'adapter le système aux nouvelles exigences et niveaux de charge, de nombreuses modifications petites et simples ont été apportées, mais, malheureusement, de telles modifications sont loin d'être les plus efficaces. Et le jour est venu où, au lieu du hack suivant ou de l'achat de matériel coûteux, il était plus sage de faire une optimisation plus globale. Nous examinerons plus loin les principales étapes de cette voie.
Optimisations non invasives
Toute modification de la structure d'une base de données volumineuse et chargée est assez coûteuse en raison de la complexité du processus de migration des données. Par conséquent, tout d'abord, vous devez épuiser toutes les options d'optimisation qui n'affectent pas la structure des données, mais sont limitées aux requêtes de code et SQL. Peut-être que cela suffira à reporter le problème de la charge de travail excessive pour quelques années, ce qui vous permettra de faire quelque chose de plus important pour l'entreprise en ce moment.
Mieux vous comprendrez votre système, plus il vous sera facile de trouver des approches pour de telles optimisations. Assurez-vous de collecter toutes les métriques qui peuvent vous aider. Il ne s'agit pas seulement des mesures du système telles que l'utilisation du processeur et de la RAM ou des mesures d'une base de données spécifique, mais également des mesures au niveau de l'application d'une application liée à une base de données optimisée. Combien de demandes par seconde les différents types d'opérations ont-ils? Quel est leur temps de réponse? Quelle est la taille de l'entrée et de la sortie? C'est sur ces métriques que vous pouvez juger du succès de l'optimisation. Il est peu probable que vous ayez besoin d'une optimisation qui réduira légèrement l'utilisation du processeur sur le serveur de base de données, mais augmentera en même temps le temps de réponse de votre application de dix fois.

Après avoir commencé à collecter des métriques supplémentaires au niveau de l'application pour UDB, nous avons pu mieux comprendre lesquelles des opérations effectuées créent 80% de la charge et sont les premiers candidats à l'étude, et lesquelles sont peu ou pas utilisées.
Une analyse détaillée de l'opération la plus fréquente (extraction des utilisateurs répondant à certains critères) a montré que, bien que toutes les données utilisateur disponibles soient demandées à la base de données, en réalité l'application dans 95% des cas utilise uniquement user_id. Juste en séparant ce cas dans une méthode API distincte qui extrait une seule colonne de la table, nous avons pu bénéficier de l'utilisation de l'index de couverture et supprimer environ 5% de la charge CPU du serveur de base de données avec cela.
L'analyse d'une autre opération fréquente a montré que, malgré le fait qu'elle soit effectuée pour chaque requête HTTP, en réalité, les données qu'elle récupère sont extrêmement rares. Nous avons traduit cette demande en un modèle paresseux.
L'objectif principal des métriques dans le cas d'un projet d'optimisation est de mieux comprendre votre base de données et de trouver les pièces les plus grasses. Cela n'a aucun sens de passer beaucoup de temps et d'efforts à optimiser les requêtes qui représentent moins de 1% de votre profil de charge. Si vous ne disposez pas de mesures vous permettant de comprendre le profil de votre charge, collectez-les. Avec de telles optimisations du côté du code, nous avons réussi à supprimer environ 15% de l'utilisation du processeur de 80% de la base de données consommée.
Tester des idées
Si vous souhaitez optimiser une base de données chargée en modifiant sa structure, vous devriez commencer par vérifier vos idées sur un banc de test, car même les optimisations qui semblent très prometteuses en théorie peuvent ne pas avoir un effet positif dans la pratique (et parfois elles peuvent même avoir un effet négatif). Et il est peu probable que vous souhaitiez le savoir uniquement après une longue migration de données sur la production.
Plus la configuration de votre stand est proche de la configuration de production, plus vous obtiendrez des résultats fiables. Un point important est d'assurer la charge correcte du support. L'exécution de requêtes aléatoires ou identiques peut conduire à de faux résultats. La meilleure option est d'utiliser des demandes réelles de la production. Pour UDB, nous nous sommes déconnectés de la production chaque dixième demande de lecture d'API (y compris les paramètres) sous la forme d'un simple journal JSON dans un fichier. Pendant une journée, nous avons collecté un journal de 65 Go à partir de 700 millions de demandes.
Nous n'avons pas testé l'enregistrement, par rapport au nombre de demandes de lecture, il est très petit et n'affecte pas notre charge. Cependant, cela peut ne pas être le cas dans votre cas. Si vous souhaitez charger le banc de test avec des demandes d'écriture, vous devrez collecter chaque demande, car ignorer les demandes d'écriture peut entraîner des erreurs de cohérence sur le banc de test.
L'étape suivante consiste à perdre correctement le journal sur le support. Nous avons utilisé 400 travailleurs PHP, lancés à partir de notre
nuage de scripts , qui lisent le journal collecté à partir de la file d'attente rapide et exécutent séquentiellement les demandes. Dans ce cas, la file d'attente est remplie d'un autre script avec une vitesse strictement définie. Pour tester les idées, nous avons utilisé la vitesse de x10, qui, multipliée par le fait que nous n'avons collecté de la production qu'une fois sur dix, a donné le même nombre de RPS qu'en production.
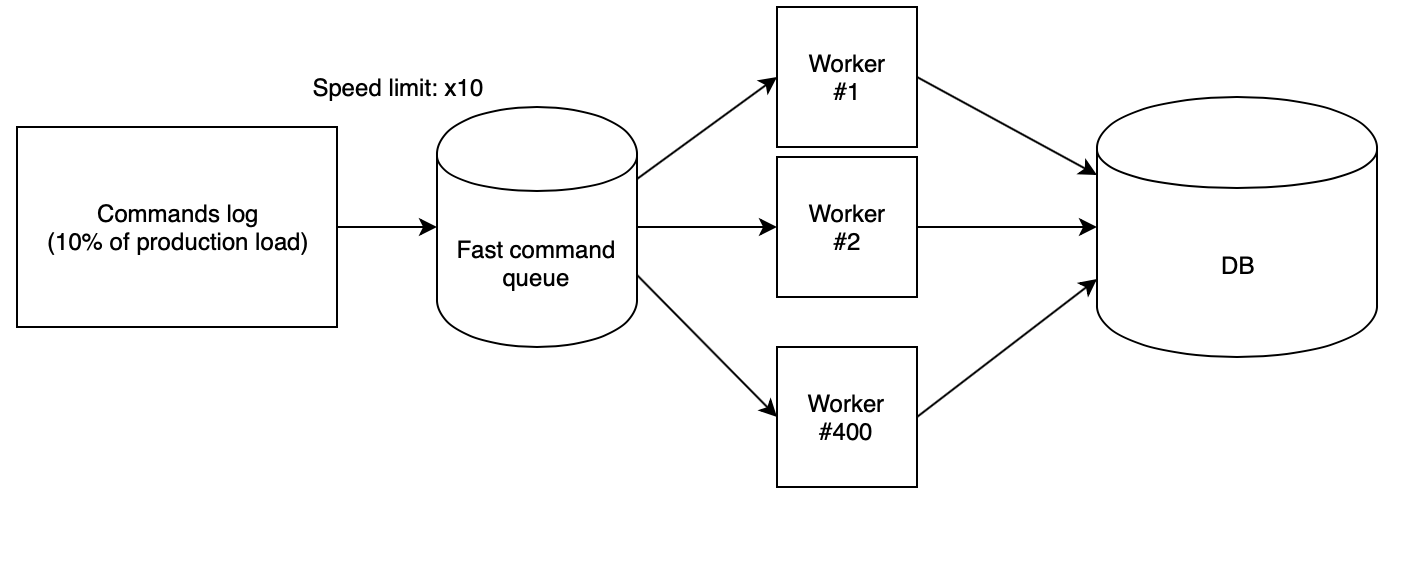
Avec ces coefficients, il s'avère que la journée de production avec toutes les chutes de charge sur le banc d'essai s'envole en seulement deux heures et demie.
Ainsi, par exemple, le premier test que nous avons exécuté à une vitesse de x5 (50% de la charge de production) sur le journal des requêtes pendant une demi-journée ressemblait à:
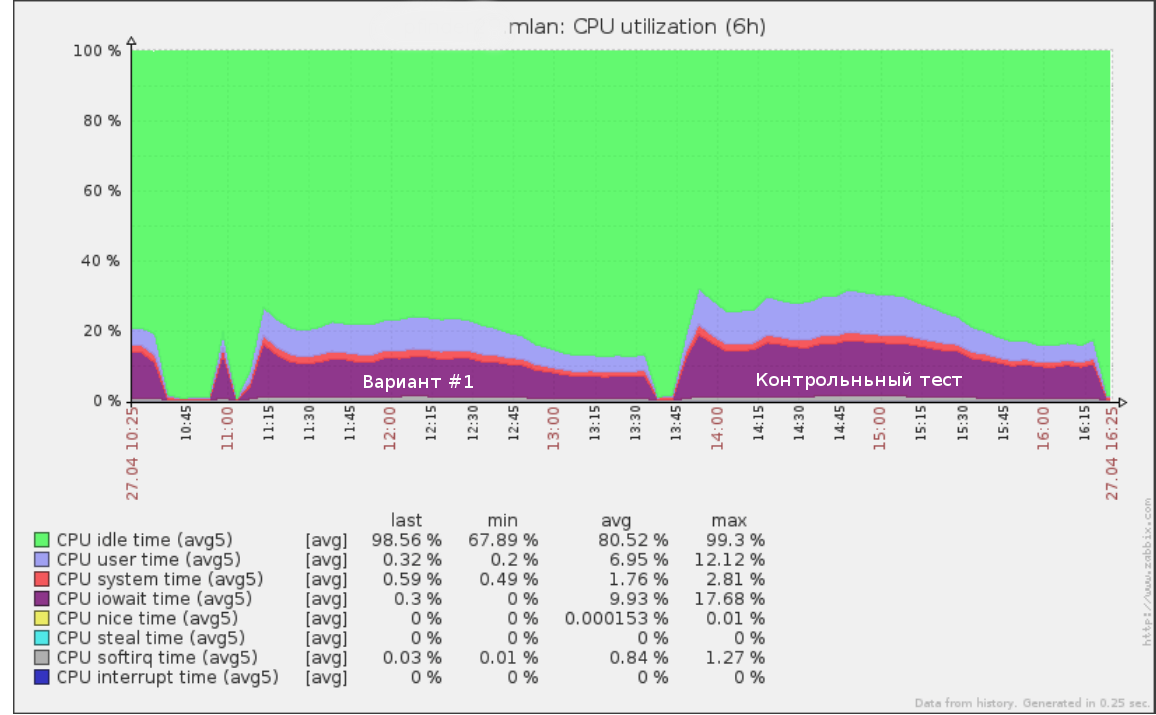
Les mêmes outils peuvent être utilisés pour effectuer un test de défaillance: augmentation de la vitesse (et donc du RPS) jusqu'à ce que la base du stand commence à se dégrader. Cela vous donnera une compréhension claire de la charge supplémentaire que votre base de données peut supporter.
Après avoir testé le nouveau schéma de données, il est également important d'effectuer un test de contrôle sur la structure de base de données d'origine. Si ses résultats et ses performances actuelles sur la production sont très différents, vous devez d'abord comprendre les raisons. Le serveur de test est peut-être mal configuré et vous ne pouvez pas faire confiance aux données de test de charge.
Il convient également de s'assurer que le nouveau code fonctionne correctement. Il est peu logique de tester les performances des requêtes qui ne font pas le travail. Vous serez bien servi par des tests d'intégration qui vérifient si les anciennes et les nouvelles API renvoient les mêmes valeurs sur les mêmes appels d'API.
Après avoir reçu des résultats sur toutes les idées, il ne reste plus qu'à choisir les options avec le meilleur équilibre entre prix et qualité et introduire un nouveau schéma de production.
Changement de schéma
Tout d'abord, je note que changer le schéma de données sans arrêter le fonctionnement du service est toujours assez difficile, coûteux et risqué. Par conséquent, si vous avez la possibilité d'arrêter votre application tout en changeant la structure, faites-le. Dans le cas de l'UDB, malheureusement, nous ne pouvions pas nous le permettre.
Le deuxième facteur affectant la complexité du changement d'un circuit est l'échelle prévue du changement. Si toutes les modifications proposées aux tables ne vont pas au-delà d'un simple changement (par exemple, l'ajout d'une paire de nouveaux index ou colonnes), vous pouvez les activer avec des processus typiques comme
pt-online-schema-change et
gh-ost pour MySQL ou un esclave alternatif suivi de changer leur place .
Dans notre cas, un excellent résultat a été montré dans le découpage vertical d'une table géante environ une douzaine plus petite avec d'autres colonnes et index et données dans un format différent. Une telle conversion avec des outils typiques n'est plus possible. Alors que faire?
Nous avons appliqué l'algorithme suivant:
- Nous atteignons un état où les anciens et les nouveaux schémas avec des données actuelles existent simultanément. L'enregistrement va dans les deux, et en même temps, il y a une garantie de cohérence des données dans les deux versions. Nous examinerons cet article en détail ci-dessous.
- Passez progressivement la lecture entière à un nouveau circuit, contrôlant la charge.
- Désactivez l'enregistrement dans l'ancien schéma et supprimez-le.
Les principaux avantages de cette approche:
- sécurité: il y a la possibilité d'un retour instantané jusqu'à la dernière étape (il suffit de revenir à l'ancien schéma en cas de problème);
- contrôle à pleine charge pendant la migration des données;
- aucune modification lourde de la grande table de l'ancien circuit n'est nécessaire.
Cependant, il existe également des inconvénients:
- la nécessité de conserver les deux versions des schémas sur disque pendant le processus de migration (cela peut être un problème si vous avez peu d'espace et que la table en cours de migration est très grande);
- beaucoup de code temporaire pour soutenir le processus de migration, qui sera coupé à la fin;
- il est possible de laver le cache en lisant à partir de deux schémas en parallèle; on craignait que les anciennes et les nouvelles versions ne se disputent la RAM, ce qui pourrait entraîner une dégradation du service (en réalité, cela a vraiment créé une charge supplémentaire, cependant, puisque la migration a été effectuée hors pointe, cela ne nous a pas posé de problèmes).
La principale difficulté de cet algorithme est le premier point. Nous allons l'examiner en détail.
Modifier la synchronisation
La migration de données statiques n'est pas particulièrement difficile. Cependant, que se passe-t-il si vous ne pouvez pas simplement arrêter l'enregistrement entier pendant la migration de la base de données?
Il existe plusieurs options pour synchroniser le nouveau schéma: migration avec roulement du journal et enregistrement idempotent de la migration.
Migration d'un instantané de données suivi de la lecture du journal des modifications suivantes
Chaque transaction de mise à jour des données est enregistrée dans une table spéciale via des déclencheurs au niveau de l'application, ou le journal des opérations de réplication est utilisé comme journal. Une fois que vous disposez d'un tel journal, vous pouvez ouvrir une transaction et migrer un instantané de données, en vous souvenant de la position dans le journal. Il reste alors à commencer à appliquer le journal collecté sur le nouveau schéma. De même, par exemple, l'
outil de sauvegarde populaire MySQL
Percona XtraBackup fonctionne .
Une fois que le nouveau schéma a rattrapé le journal de l'enregistrement en cours, l'étape la plus cruciale commence: vous devez toujours suspendre l'enregistrement dans l'ancien schéma pendant une courte période et, en vous assurant que l'intégralité du journal disponible est appliqué au nouveau schéma, ce qui signifie que les données entre les schémas sont cohérentes, Au niveau de l'application, activez l'enregistrement simultanément dans les deux sources.
Les principaux inconvénients de cette approche sont que vous devrez en quelque sorte stocker le journal des opérations, ce qui en soi peut créer une charge dans le processus de commutation complexe, ainsi que dans la probabilité de battre le record si, pour une raison quelconque, les circuits s'avèrent incohérents.
Record idempotent
L'idée principale de cette approche est de commencer à écrire dans le nouveau schéma en parallèle avec l'écriture dans l'ancien avant que les modifications ne soient complètement synchronisées, puis de terminer la migration des données restantes. De même, les nouvelles colonnes sont généralement remplies dans de grands tableaux.
L'enregistrement synchrone peut être implémenté à la fois sur les déclencheurs de base de données et dans le code source. Je vous conseille de le faire précisément dans le code, car dans tous les cas, vous devrez éventuellement écrire du code qui va écrire des données dans le nouveau schéma, et la mise en œuvre de la migration côté code vous donnera plus de contrôle.
Un point important à considérer est que tant que la migration n'est pas terminée, le nouveau schéma sera dans un état incohérent. Pour cette raison, un scénario est possible lorsque la mise à jour d'une nouvelle table entraîne une violation de la constante de la base de données (clés étrangères ou un index unique), tandis que du point de vue du schéma actuel, la transaction est complètement correcte et doit être effectuée.
Cette situation peut entraîner une annulation de bonnes transactions en raison du processus de migration. Le moyen le plus simple de contourner ce problème consiste à ajouter le modificateur IGNORE à toutes les demandes d'écriture de données dans un nouveau schéma ou d'intercepter l'annulation d'une telle transaction et d'exécuter la version sans écrire dans le nouveau schéma.
L'algorithme de synchronisation par enregistrement idempotent dans notre cas est le suivant:
- Nous permettons l'enregistrement dans un nouveau schéma en parallèle avec l'enregistrement dans l'ancien en mode de compatibilité (IGNORE).
- Nous exécutons un script qui contourne progressivement le nouveau schéma et capture des données incohérentes. Après cela, les données des deux tables doivent être synchronisées, mais cela est inexact en raison des conflits possibles dans la clause 1.
- Nous commençons le vérificateur de cohérence des données - nous ouvrons la transaction et lisons séquentiellement les lignes des nouveaux et anciens schémas en comparant leur correspondance.
- S'il y a des conflits, nous terminons et revenons au paragraphe 3.
- Après que le vérificateur a montré que les données des deux schémas sont synchronisées, il ne devrait plus y avoir de divergences entre les schémas, sauf si, bien sûr, nous avons manqué une nuance. Par conséquent, nous attendons un certain temps (par exemple, une semaine) et exécutons une vérification de contrôle. S'il montre que tout va bien, alors la tâche est terminée avec succès et vous pouvez traduire la lecture.
Résultats
Suite à la modification du format des données, nous avons pu réduire la taille de la table principale de 544 Go à 226 Go, réduisant ainsi la charge sur le disque et augmentant la quantité de données utiles qui tient dans la RAM.
Au total, depuis le début du projet, en utilisant toutes les approches décrites, nous avons pu réduire l'utilisation du processeur du serveur de base de données de 80% à 35% au pic de trafic. Les résultats du test de résistance qui a suivi ont montré qu'au rythme de croissance actuel de la charge, nous pouvons rester sur le matériel existant pendant au moins trois autres années.
La division d'une énorme table en plusieurs a simplifié le processus de réalisation de futures modifications dans la base de données, et a également accéléré considérablement certains scripts qui collectaient des données pour la BI.