 D'un traducteur:
D'un traducteur: nous publions aujourd'hui pour vous un article conjoint de trois développeurs, Akaash Chikarmane, Erte Bablu et Nikhil Gaur, qui décrit la méthode de prévision de la notation des applications dans le Google Play Store.
Dans cet article, nous allons montrer comment nous traitons les informations que nous utilisons pour prédire les notes. Nous expliquerons également pourquoi nous utilisons ceux-ci ou ceux-là. Nous parlerons des transformations du paquet de données avec lequel nous travaillons et de ce qui peut être réalisé à l'aide de la visualisation.
Skillbox recommande: Cours pratique de deux ans "Je suis un développeur Web PRO . "
Nous vous rappelons: pour tous les lecteurs de «Habr» - une remise de 10 000 roubles lors de l'inscription à un cours Skillbox en utilisant le code promo «Habr».
Pourquoi nous avons décidé de le faire
Les applications mobiles font depuis longtemps partie intégrante de la vie, de plus en plus de développeurs sont seuls engagés dans leur création. De plus, beaucoup dépendent directement des revenus générés par les applications. Par conséquent, la prévision du succès est d'une grande importance pour eux.
Notre objectif est de déterminer la note globale de l'application, pour le faire de manière exhaustive, car trop de gens jugent le programme, en se basant uniquement sur le nombre "d'étoiles" défini par les utilisateurs. Les applications avec 4-5 points sont plus crédibles.
La préparation
La plupart de ce projet utilise des données, y compris le prétraitement. Étant donné que toutes les informations ont été extraites du Google Play Store, les tableaux résultants contenaient de nombreuses erreurs. Nous avons utilisé plusieurs modèles de régression, y compris le régresseur boostant le gradient du package XGBoost, la régression linéaire et la RidgeRegression.
Collecte et analyse des données
L'ensemble de données avec lequel nous avons travaillé se
trouve ici . Il se compose de deux parties. Le premier est une information objective, comme la taille de l'application, le nombre d'installations, la catégorie, le nombre d'avis, le type d'application, son genre, la date de la dernière mise à jour, etc., et subjective, c'est-à-dire les avis des utilisateurs.
Les examens eux-mêmes ont fait l'objet d'une analyse. Après avoir comparé les résultats, nous avons décidé d'inclure ou non les données de l'enquête dans le modèle final.
Nous avons formé un ensemble de données objectives par 12 fonctions et une variable cible (notation). Le forfait comprenait 10,8 mille unités d'informations. En ce qui concerne les avis des utilisateurs, nous avons sélectionné les 100 fonctions les plus pertinentes et utilisé cinq fonctions pour 64,3 mille éléments. Toutes les données ont été collectées directement sur le Google Play Store, la dernière fois qu'elles ont été mises à jour il y a trois mois.
Prétraitement des données
L'ensemble initial d'informations ressemblait à ceci:
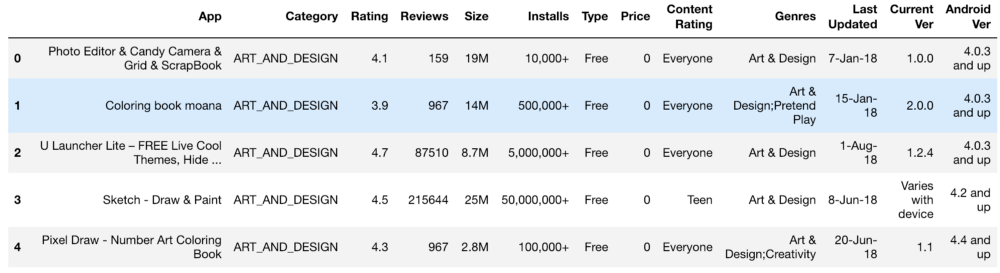
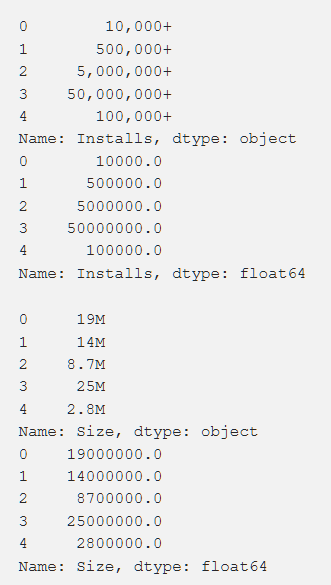
Paramètres, évaluation, coût et taille - nous avons traité tout cela de manière à obtenir des chiffres accessibles à la compréhension de la machine. Lors du traitement de diverses fonctions, des problèmes sont survenus, tels que la nécessité de supprimer le "+". Dans le coût, nous avons supprimé $. Le volume de l'application s'est avéré être le plus problématique en termes de traitement, car KB et MB étaient apparus, il était donc nécessaire de faire un travail pour tout réduire à un seul format. Les données primaires sont présentées ci-dessous et elles le sont également après traitement.
De plus, nous avons transformé certaines données, les rendant plus pertinentes pour notre travail. Par exemple, les informations sur la dernière mise à jour de l'application n'étaient pas très utiles. Afin de les rendre plus significatifs, nous les avons convertis en informations sur le temps écoulé depuis la dernière mise à jour. Le code de cette tâche est indiqué ci-dessous.
from datetime import datetime from dateutil.relativedelta import relativedelta n = 3
Il était également nécessaire de ramener à un seul standard des variables avec plusieurs valeurs différentes (par exemple, "Genre"). Comment cela a été fait est indiqué ci-dessous.
from copy import deepcopy from sklearn.preprocessing import LabelEncoder def one_hot_encode_by_label(df, labels): df_new = deepcopy(df) for label in labels: dummies = df_new[label].str.get_dummies(sep = ";") df_new = df_new.drop(labels = label, axis = 1) df_new = df_new.join(dummies) return df_new def label_encode_by_label(df, labels): df_new = deepcopy(df) le = LabelEncoder() for label in labels: print(label + " is label encoded") le.fit(df_new[label]) dummies = le.transform(df_new[label]) df_new.drop(label, axis = 1) df_new[label] = pd.Series(dummies) return df_new
Pour normaliser les données, nous avons essayé la conversion log1p. Avant lui:
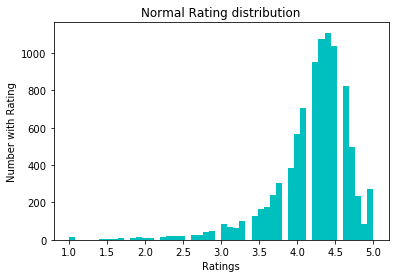
Après:
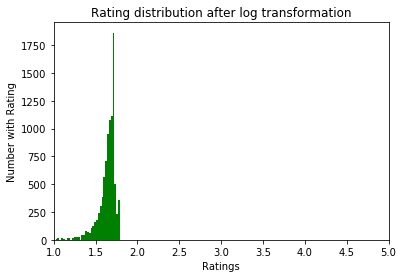
Exploration des données
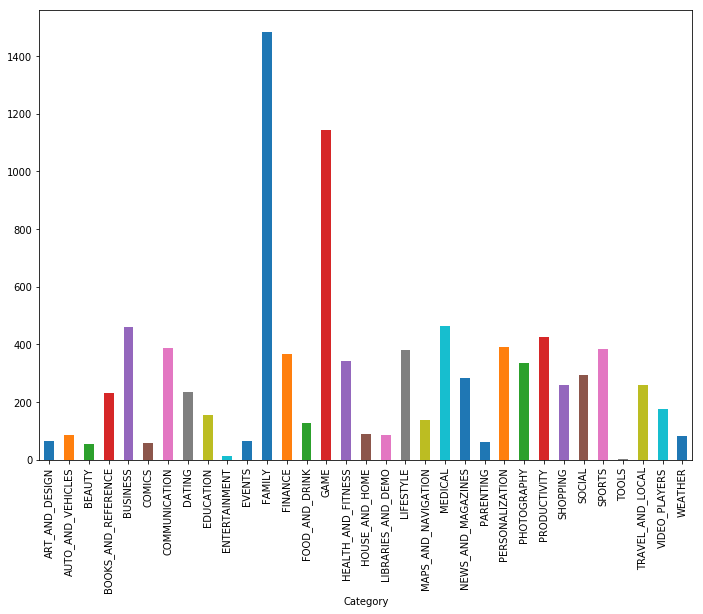
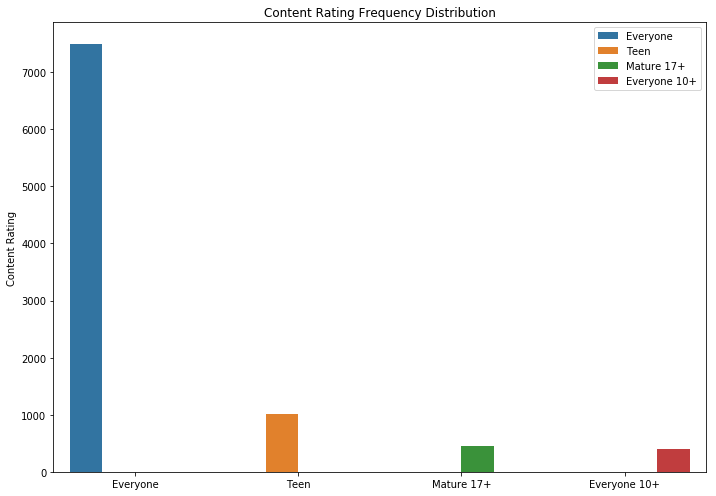
Comme vous pouvez le voir, les jeux et les applications pour la famille sont les deux catégories les plus populaires. La plupart des demandes étaient également dans la catégorie «Pour tous les âges».

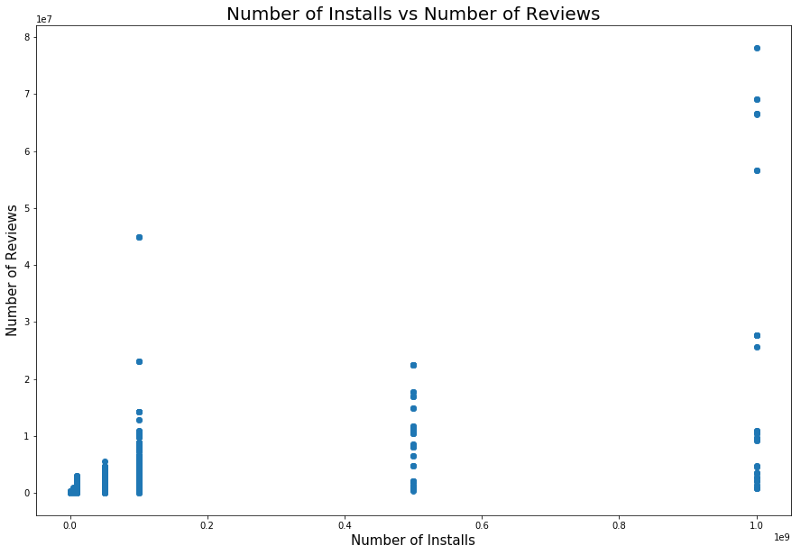
Il est logique que les applications avec une note maximale aient plus de commentaires que les notes basses. Certains d'entre eux ont beaucoup plus d'avis que tous les autres. La raison en est peut-être un message contextuel, un appel à évaluer ou d'autres techniques similaires.

Il existe également une relation entre le nombre d'installations et le nombre d'examens. La corrélation est montrée dans la capture d'écran ci-dessous.
Une analyse détaillée de cette dépendance permet de comprendre pourquoi les catégories d'applications populaires ont plus d'installations et plus de révisions.
Modèles et résultats
Nous avons utilisé le fractionnement des tests pour diviser les données en ensembles de tests et de formation. La validation croisée avec GridSearchCV a été utilisée pour améliorer les résultats de formation des modèles afin de trouver le meilleur alpha avec Lasso, Ridge Regression et XGBRegressor à partir du package XGBoost. Ce dernier modèle est généralement extrêmement efficace, mais en l'utilisant, il faut se garder d'ajuster les résultats - c'est l'un des dangers qui attendent les chercheurs. La valeur efficace initiale sans aucun traitement particulièrement soigné des objets (codage et nettoyage uniquement) était d'environ 0,228.
Après la conversion logarithmique des notes, l'erreur-type est tombée à 0,219, ce qui représente une légère amélioration, mais nous avons réalisé que nous avions tout fait correctement.
Nous avons utilisé la régression linéaire après avoir évalué la relation entre les avis, les attitudes et les notes. En particulier, nous avons analysé les informations statistiques de ces variables, y compris le r au carré et p, en prenant une décision sur la régression linéaire en conséquence. Le premier modèle de régression linéaire utilisé a montré une corrélation entre les paramètres et une note de 0,2233, le modèle de régression linéaire Nos commentaires et évaluations nous ont donné un MSE de 0,2107, et le modèle de régression linéaire combiné, Avis, paramètres et notes ", Nous a donné un MSE de 0,214.
De plus, nous avons utilisé le modèle KNeighborsRegressor. Les résultats de son utilisation sont présentés ci-dessous.

Conclusions
Après la conversion des données primaires du Google Play Store dans un format utilisable, nous avons tracé et dérivé des fonctions pour comprendre les corrélations entre les valeurs individuelles. Ces résultats ont ensuite été utilisés afin de construire un modèle optimal.
Au départ, nous pensions qu'il ne serait pas trop difficile de le trouver, afin de pouvoir construire un modèle précis. Mais la tâche a été plus difficile que prévu.
En plus de ce qui a été fait, vous pouvez également:
- créer un modèle distinct pour chaque genre;
- Créez de nouvelles fonctionnalités à partir des versions d'Android OS, comme nous l'avons fait précédemment avec les dates;
- pour approfondir l'algorithme - nous disposions d'un nombre suffisant de points de données catégoriques et numériques;
- analyser et effacer indépendamment les données de Google App Store.
Tous les résultats sont
disponibles ici .
Skillbox recommande: