Le message a été préparé par les membres de l'équipe Yandex.Cloud: Ivan Vetkasov - architecte, Leonid Klyuyev - éditeur
 Récemment, nous avons parlé de l'architecture de Yandex.Cloud . Passons maintenant de la théorie à la pratique. Il existe plusieurs services dans le cloud pour le contrôle automatisé du SGBD: le service géré pour ClickHouse, le service géré pour PostgreSQL et le service géré pour MongoDB. Tous sont basés sur une plate-forme et vous permettent de vous concentrer sur la tâche de stockage des données, et non sur l'administration de l'infrastructure. Mais parfois, il est également important de contrôler les machines virtuelles du cluster. Par exemple, une tâche de mise à l'échelle peut survenir en réponse à une augmentation ou une diminution de la charge. Habituellement, ce scénario est l'un des plus longs d'un point de vue pratique. Aujourd'hui, nous expliquerons comment Yandex.Cloud vous permet d'automatiser des tâches de mise à l'échelle complexes et de vous assurer que la base de données reste disponible dans le processus de redimensionnement du cluster.
Récemment, nous avons parlé de l'architecture de Yandex.Cloud . Passons maintenant de la théorie à la pratique. Il existe plusieurs services dans le cloud pour le contrôle automatisé du SGBD: le service géré pour ClickHouse, le service géré pour PostgreSQL et le service géré pour MongoDB. Tous sont basés sur une plate-forme et vous permettent de vous concentrer sur la tâche de stockage des données, et non sur l'administration de l'infrastructure. Mais parfois, il est également important de contrôler les machines virtuelles du cluster. Par exemple, une tâche de mise à l'échelle peut survenir en réponse à une augmentation ou une diminution de la charge. Habituellement, ce scénario est l'un des plus longs d'un point de vue pratique. Aujourd'hui, nous expliquerons comment Yandex.Cloud vous permet d'automatiser des tâches de mise à l'échelle complexes et de vous assurer que la base de données reste disponible dans le processus de redimensionnement du cluster.
Énoncé du problème
Lors de la création d'un cluster de chaque service, l'utilisateur peut déterminer le nombre d'hôtes de cluster et la zone de disponibilité (AZ), qui correspond au centre de données physique. Maintenant, Yandex.Cloud utilise trois centres de données Yandex situés dans la région centrale de la Russie. Par conséquent, la configuration recommandée est le cluster SGBD avec trois hôtes - comme étant le plus cohérent avec les principes de construction d'une architecture à sécurité intégrée et résistante aux catastrophes.
Imaginez donc une situation où la charge sur le cluster SGBD dépasse les capacités de la base de données et il est temps d'ajouter des ressources informatiques. Cela peut être fait à la fois horizontalement - en ajoutant des hôtes au cluster et verticalement - en ajoutant des ressources à chaque machine du cluster. Considérez la deuxième option, comme la plus longue et la plus risquée d'erreurs. Pourquoi cette option est-elle laborieuse? Parce que dans le cas général, la procédure d'ajout de ressources ressemblera à ceci: changez le rôle de l'hôte; si nécessaire, arrêtez le SGBD; éteignez la machine virtuelle; changer sa configuration; nous commençons; changer les paramètres du SGBD; nous démarrons un SGBD; Nous attendons la synchronisation des modifications des données accumulées. Et donc pour les trois hôtes à tour de rôle. De nombreuses étapes - le risque d'erreurs est élevé. Vous pouvez automatiser ce processus - uniquement avant de démarrer, la solution d'automatisation sélectionnée doit être testée. Habituellement, il n'y a pas assez de temps pour les tests, mais dans Yandex.Cloud, il s'exécute rapidement et sans actions inutiles de votre part. Commençons.
Étapes préliminaires et processus de test
Pour la préparation, nous aurons besoin de:
- Accès à la plateforme. Désormais, tout le monde peut mettre en place une période d'essai sur le site Web sur le site Web Yandex.Cloud .
- Un réseau cloud (je l'appellerai testvpc dans mon exemple) et trois sous-réseaux situés dans différents AZ. Les plages d'adresses de sous-réseau dans ce cas ne sont pas importantes.
- Hôte du bastion. Malgré le fait que dans Yandex.Cloud, vous pouvez ouvrir un accès externe au SGBD via IP publique, la publication d'un SGBD dans le domaine public n'est pas la bonne décision. Par conséquent, nous ajoutons un hôte bastion au schéma, à partir duquel nous ouvrirons des connexions aux hôtes. En tant qu'hôte, vous pouvez utiliser une machine avec une utilisation partielle (5%) du noyau. Clickhouse-client doit être installé sur la machine virtuelle. De plus, selon les instructions de connexion au service, vous devez télécharger un certificat SSL.
- CLI Nous travaillerons avec Yandex.Cloud non pas via la console, mais via l'utilitaire de ligne de commande, qui doit également être installé et lancé conformément à la documentation .
Le scénario de test sera simple: ouvrir trois sessions connectant l'hôte bastion à chaque hôte du cluster de base de données, exécuter une requête SQL dans un cycle avec une période de, disons, 1 seconde, après quoi nous envoyons une commande pour mettre à l'échelle le cluster et examiner le comportement du système.
Moment de vérité
Choisissez un SGBD pour démontrer la mise à l'échelle. Dans PostgreSQL, les hôtes se voient attribuer des rôles, mais le service n'a pas encore leur commutation transparente lors de la mise à l'échelle - cette fonctionnalité est dans nos plans. Dans le cas contraire, les mécanismes d'augmentation et de diminution du cluster sont approximativement les mêmes dans le cas des trois SGBD, par exemple, prenez ClickHouse.
Créons un objet d'expérience - un cluster composé de trois hôtes situés sur différents sous-réseaux virtuels. Pour ce faire, entrez la commande
yc managed-clickhouse cluster create avec les arguments nécessaires. L'ordre des arguments correspond à leur liste dans la sortie de «yc --help». L'essence de la commande est simple: nous créons un cluster ch-to-resize dans un environnement de production avec testvpc situé sur le réseau virtuel, définissons un nom et un mot de passe, 10 gigaoctets d'espace disque et la classe minimale s1.nano. Les caractéristiques suivantes correspondent à cette classe: 1 CPU, 4 Go de RAM. À l'avenir, pour la mise à l'échelle, nous passerons à la classe s1.micro, de sorte que le nombre de CPU et de RAM double. Pour savoir quelles autres classes d'hôtes vous pouvez attribuer, entrez simplement la commande
yc managed-clickhouse resource-preset list .
Ainsi, la commande pour créer le cluster doit être la suivante:
yc managed-clickhouse cluster create --name ch-to-resize --environment production --network-name testvpc --host zone-id=ru-central1-a,subnet-id=e9bfnjacigdo9p6j7j2s,assign-public-ip=false,type=clickhouse --host zone-id=ru-central1-b,subnet-id=e2l8iamol3b9mrtskb8q,assign-public-ip=false,type=clickhouse --host zone-id=ru-central1-c,subnet-id=b0c6qit7u9e8r0egedvj,assign-public-ip=false,type=clickhouse --user name=test,password=test123123 --database name=testdb --clickhouse-disk-size 10 --clickhouse-resource-preset s1.nano --clickhouse-disk-type network-nvme –async
En réponse, nous obtenons l'ID du cluster et une liste des noms d'hôtes de ses hôtes:
yc managed-clickhouse cluster list +----------------------+--------------+-----------------------------+--------+---------+ | ID | NAME | CREATED AT | HEALTH | STATUS | +----------------------+--------------+-----------------------------+--------+---------+ | c9q7cr4ji2fe462qej8p | ch-to-resize | 2018-12-10T08:59:09.100272Z | ALIVE | RUNNING | +----------------------+--------------+-----------------------------+--------+---------+ yc managed-clickhouse host list --cluster-id c9q7cr4ji2fe462qej8p +-------------------------------------------+----------------------+---------+---------------+ | NAME | CLUSTER ID | HEALTH | ZONE ID | +-------------------------------------------+----------------------+---------+---------------+ | rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net | c9q7cr4ji2fe462qej8p | ALIVE | ru-central1-a | | rc1a-sgxazra54xv6lhni.mdb.yandexcloud.net | c9q7cr4ji2fe462qej8p | UNKNOWN | ru-central1-a | | rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net | c9q7cr4ji2fe462qej8p | ALIVE | ru-central1-b | | rc1b-j1rtvsuz6t8x6ev2.mdb.yandexcloud.net | c9q7cr4ji2fe462qej8p | UNKNOWN | ru-central1-b | | rc1c-emo0f2990povj7ie.mdb.yandexcloud.net | c9q7cr4ji2fe462qej8p | UNKNOWN | ru-central1-c | | rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net | c9q7cr4ji2fe462qej8p | ALIVE | ru-central1-c | +-------------------------------------------+----------------------+---------+---------------+
Ouvrons une connexion à chaque hôte et exécutons une requête sur la base de données:
clickhouse-client --host rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net --secure --user test --password test123123 --database testdb --port 9440 -q "select concat(host_name, ' is alive\!') from system.clusters where replica_num = 1" clickhouse-client --host rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net --secure --user test --password test123123 --database testdb --port 9440 -q "select concat(host_name, ' is alive!') from system.clusters where replica_num = 2" clickhouse-client --host rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net --secure --user test --password test123123 --database testdb --port 9440 -q "select concat(host_name, ' is alive\!') from system.clusters where replica_num = 3"
Enfin, envoyez une demande pour augmenter le cluster:
yc managed-clickhouse cluster update --id c9q7cr4ji2fe462qej8p --clickhouse-resource-preset s1.micro -–async
Explication de la réduction de clusterSi nous voulons réduire, plutôt que d'augmenter la quantité de ressources, nous devons spécifier une classe plus petite, en se référant à la sortie
yc managed-clickhouse resource-preset list - par exemple, s1.nano. Dans le même temps, la structure de l'équipe elle-même reste la même.
J'ai redirigé la sortie de la requête vers un fichier. Voici une liste abrégée:
rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net Mon Dec 10 12:47:35 UTC 2018 rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net is alive! Mon Dec 10 12:47:36 UTC 2018 rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net is alive! Mon Dec 10 12:47:37 UTC 2018 rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net is alive! Mon Dec 10 12:47:38 UTC 2018 rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net is alive! Mon Dec 10 12:47:39 UTC 2018 rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net is alive! Mon Dec 10 12:47:40 UTC 2018 Code: 209. DB::NetException: Timeout: connect timed out: 192.168.58.7:9440: (rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net:9440, 192.168.58.7) Mon Dec 10 12:47:51 UTC 2018 Code: 209. DB::NetException: Timeout: connect timed out: 192.168.58.7:9440: (rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net:9440, 192.168.58.7) Mon Dec 10 12:48:02 UTC 2018 Code: 209. DB::NetException: Timeout: connect timed out: 192.168.58.7:9440: (rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net:9440, 192.168.58.7) Mon Dec 10 12:48:11 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net:9440, 192.168.58.7) Mon Dec 10 12:48:12 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net:9440, 192.168.58.7) Mon Dec 10 12:48:13 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net:9440, 192.168.58.7) Mon Dec 10 12:48:14 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net:9440, 192.168.58.7) Mon Dec 10 12:48:15 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net:9440, 192.168.58.7) Mon Dec 10 12:48:16 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net:9440, 192.168.58.7) Mon Dec 10 12:48:17 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net:9440, 192.168.58.7) Mon Dec 10 12:48:18 UTC 2018 rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net is alive! Mon Dec 10 12:48:19 UTC 2018 rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net is alive! Mon Dec 10 12:48:20 UTC 2018 rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net is alive! rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net: Mon Dec 10 12:50:58 UTC 2018 rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net is alive! Mon Dec 10 12:50:59 UTC 2018 rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net is alive! Mon Dec 10 12:51:00 UTC 2018 rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net is alive! Mon Dec 10 12:51:01 UTC 2018 Code: 209. DB::NetException: Timeout: connect timed out: 192.168.58.6:9440: (rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net:9440, 192.168.58.6) Mon Dec 10 12:51:12 UTC 2018 Code: 209. DB::NetException: Timeout: connect timed out: 192.168.58.6:9440: (rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net:9440, 192.168.58.6) Mon Dec 10 12:51:23 UTC 2018 Code: 209. DB::NetException: Timeout: connect timed out: 192.168.58.6:9440: (rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net:9440, 192.168.58.6) Mon Dec 10 12:51:34 UTC 2018 Code: 209. DB::NetException: Timeout: connect timed out: 192.168.58.6:9440: (rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net:9440, 192.168.58.6) Mon Dec 10 12:51:35 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net:9440, 192.168.58.6) Mon Dec 10 12:51:36 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net:9440, 192.168.58.6) Mon Dec 10 12:51:37 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net:9440, 192.168.58.6) Mon Dec 10 12:51:38 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net:9440, 192.168.58.6) Mon Dec 10 12:51:39 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net:9440, 192.168.58.6) Mon Dec 10 12:51:40 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net:9440, 192.168.58.6) Mon Dec 10 12:51:41 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net:9440, 192.168.58.6) Mon Dec 10 12:51:42 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net:9440, 192.168.58.6) Mon Dec 10 12:51:43 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net:9440, 192.168.58.6) Mon Dec 10 12:51:44 UTC 2018 rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net is alive! Mon Dec 10 12:51:45 UTC 2018 rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net is alive! Mon Dec 10 12:51:46 UTC 2018 rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net is alive! rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net: Mon Dec 10 12:49:15 UTC 2018 rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net is alive! Mon Dec 10 12:49:16 UTC 2018 rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net is alive! Mon Dec 10 12:49:17 UTC 2018 rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net is alive! Mon Dec 10 12:49:18 UTC 2018 rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net is alive! Mon Dec 10 12:49:19 UTC 2018 Code: 209. DB::NetException: Timeout: connect timed out: 192.168.58.8:9440: (rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net:9440, 192.168.58.8) Mon Dec 10 12:49:30 UTC 2018 Code: 209. DB::NetException: Timeout: connect timed out: 192.168.58.8:9440: (rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net:9440, 192.168.58.8) Mon Dec 10 12:49:41 UTC 2018 Code: 209. DB::NetException: Timeout: connect timed out: 192.168.58.8:9440: (rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net:9440, 192.168.58.8) Mon Dec 10 12:49:52 UTC 2018 Code: 209. DB::NetException: Timeout: connect timed out: 192.168.58.8:9440: (rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net:9440, 192.168.58.8) Mon Dec 10 12:49:56 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net:9440, 192.168.58.8) Mon Dec 10 12:49:57 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net:9440, 192.168.58.8) Mon Dec 10 12:49:58 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net:9440, 192.168.58.8) Mon Dec 10 12:49:59 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net:9440, 192.168.58.8) Mon Dec 10 12:50:00 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net:9440, 192.168.58.8) Mon Dec 10 12:50:01 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net:9440, 192.168.58.8) Mon Dec 10 12:50:03 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net:9440, 192.168.58.8) Mon Dec 10 12:50:04 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net:9440, 192.168.58.8) Mon Dec 10 12:50:05 UTC 2018 rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net is alive! Mon Dec 10 12:50:06 UTC 2018 rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net is alive! Mon Dec 10 12:50:07 UTC 2018 rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net is alive!
La liste affiche les moments où chaque hôte du cluster est désactivé (lorsque le délai de connexion commence), les moments où l'hôte est activé et ClickHouse commence à se charger (lorsque la connexion est refusée), ainsi que les moments où l'hôte redevient opérationnel. La chose la plus importante est la séparation des périodes où les hôtes n'étaient pas disponibles. Pendant la mise à l'échelle, au moins deux hôtes étaient disponibles pour l'exécution des requêtes. Cela peut être vu dans le graphique:
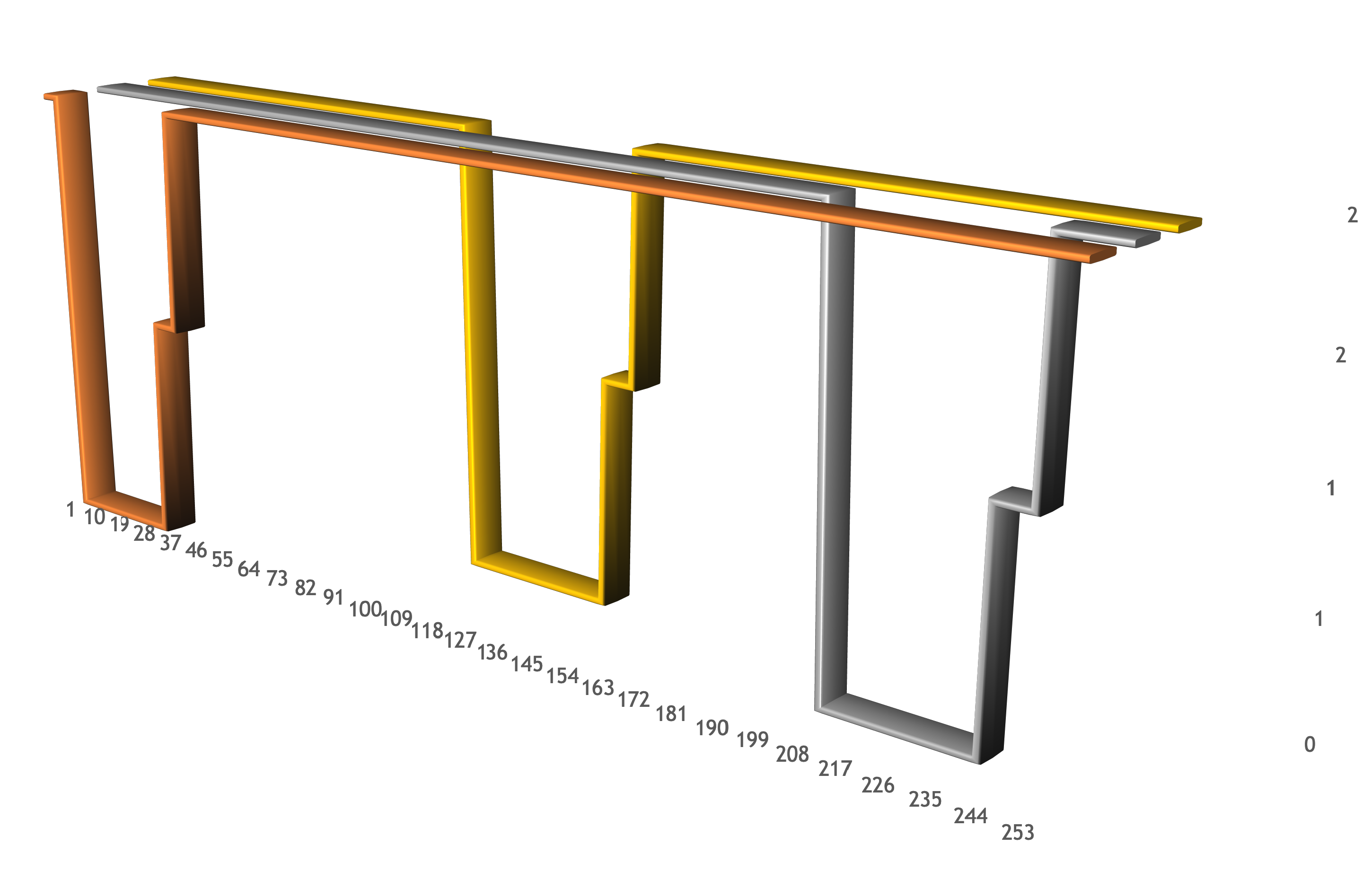
Conclusions et meilleures pratiques
À première vue, le développement de projets avec des bases de données comprend une grande quantité de travail de routine. La base de données doit être maintenue, c'est-à-dire pour créer des copies de sauvegarde, pour établir le processus de mises à jour régulières du SGBD, etc. Cependant, dans un environnement de production réel, il est utile que les systèmes soient non seulement gérables du point de vue du service, mais également flexibles - sensibles aux charges montantes et descendantes. Nous avons expliqué comment augmenter les performances de la base de données dans Yandex.Cloud, tout en maintenant la capacité de travail du projet pour les utilisateurs. Si la base de données est configurée correctement, l'augmentation du trafic entraîne une augmentation de la quantité de ressources disponibles et une récession - une diminution multiple, ce qui réduit également vos coûts.
Quelles approches, outils ou technologies basés sur le cloud aimeriez-vous découvrir? Suggérez des sujets dans les commentaires pour les articles Yandex.Cloud suivants.