Le deuxième article de la série "Développement piloté par les tests d'applications sur Spring Boot" et cette fois je vais parler du test d'accès à la base de données, un aspect important des tests d'intégration. Je vais vous expliquer comment utiliser les tests pour déterminer l'interface d'un futur service d'accès aux données, comment utiliser les bases de données en mémoire intégrées pour les tests, travailler avec les transactions et télécharger les données de test dans la base de données.
Je ne parlerai pas beaucoup de TDD et des tests en général, j'invite tout le monde à lire le premier article - Comment construire une pyramide dans le tronc ou le développement piloté par les tests d'applications sur Spring Boot / geek magazine
Je vais commencer, comme la dernière fois, par une petite partie théorique, et passer au test de bout en bout.
Test de la pyramide
Pour commencer, une petite mais nécessaire description d'une entité aussi importante dans les tests que la pyramide de test ou la pyramide de test .
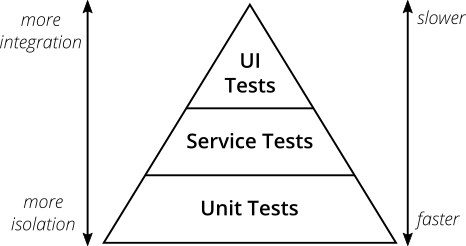
(extrait de la pyramide des tests pratiques )
La pyramide des tests est l'approche lorsque les tests sont organisés à plusieurs niveaux.
- Les tests d' interface utilisateur (ou de bout en bout, E2E ) sont peu nombreux et ils sont lents, mais ils testent l'application réelle - pas de simulacres et testent des homologues. Les entreprises pensent souvent à ce niveau et tous les cadres BDD vivent ici (voir Cucumber dans un article précédent).
- Ils sont suivis de tests d'intégration (service, composant - chacun a sa propre terminologie), qui se concentrent déjà sur un composant spécifique (service) du système, l'isolant des autres composants via moki / doubles, mais vérifiant toujours l'intégration avec de vrais systèmes externes - ces tests sont connectés à la base de données, envoyer des demandes REST, je travaille avec une file d'attente de messages. En fait, ce sont des tests qui vérifient l'intégration de la logique métier avec le monde extérieur.
- Tout en bas se trouvent des tests unitaires rapides qui testent les blocs minimum de code (classes, méthodes) de manière complètement isolée.
Spring aide à écrire des tests pour chaque niveau - même pour les tests unitaires , bien que cela puisse sembler étrange, car dans le monde des tests unitaires, aucune connaissance du framework ne devrait exister. Après avoir écrit le test E2E, je vais simplement montrer comment Spring permet même à des choses purement «d'intégration» comme les contrôleurs de tester de manière isolée.
Mais je vais commencer tout en haut de la pyramide - le test de l'interface utilisateur lente, qui démarre et teste une application à part entière.
Test de bout en bout
Donc, une nouvelle fonctionnalité:
Feature: A list of available cakes Background: catalogue is updated Given the following items are promoted | Title | Price | | Red Velvet | 3.95 | | Victoria Sponge | 5.50 | Scenario: a user visiting the web-site sees the list of items Given a new user, Alice When she visits Cake Factory web-site Then she sees that "Red Velvet" is available with price £3.95 And she sees that "Victoria Sponge" is available with price £5.50
Et voici un aspect immédiatement intéressant - que faire du test précédent, à propos du message d'accueil sur la page principale? Cela ne semble plus pertinent, après le lancement du site sur la page principale, il y aura déjà un répertoire, pas un message d'accueil. Il n'y a pas de réponse unique, je dirais - cela dépend de la situation. Mais le principal conseil - ne vous attachez pas aux tests! Supprimez-les lorsqu'ils perdent leur pertinence, réécrivez pour en faciliter la lecture. Surtout les tests E2E - cela devrait être, en fait, une spécification vivante et actuelle . Dans mon cas, je viens de supprimer les anciens tests et de les remplacer par de nouveaux, en utilisant certaines des étapes précédentes et en ajoutant des tests inexistants.
J'en arrive maintenant à un point important - le choix de la technologie pour le stockage des données. Conformément à l'approche Lean , je voudrais reporter le choix jusqu'au tout dernier moment - quand je saurai avec certitude si le modèle relationnel ou non, quelles sont les exigences de cohérence, de transactionnalité. En général, il existe des solutions pour cela - par exemple, la création de jumeaux de test et de divers stockages en mémoire , mais jusqu'à présent, je ne veux pas compliquer l'article et choisir immédiatement la technologie - les bases de données relationnelles. Mais afin de conserver au moins une certaine possibilité de choisir une base de données, j'ajouterai une abstraction - Spring Data JPA . JPA lui-même est une spécification assez abstraite pour accéder aux bases de données relationnelles, et Spring Data rend son utilisation encore plus facile.
Spring Data JPA utilise Hibernate comme fournisseur par défaut, mais prend également en charge d'autres technologies, telles que EclipseLink et MyBatis. Pour les personnes peu familiarisées avec l'API Java Persistence - JPA est comme une interface et Hibernate est une classe qui l'implémente.
Donc, pour ajouter le support JPA, j'ai ajouté quelques dépendances:
implementation('org.springframework.boot:spring-boot-starter-data-jpa') runtime('com.h2database:h2')
En tant que base de données, j'utiliserai H2 - une base de données intégrée écrite en Java, avec la possibilité de travailler en mode en mémoire.
En utilisant Spring Data JPA, je définis immédiatement une interface pour accéder aux données:
interface CakeRepository extends CrudRepository<CakeEntity, String> { }
Et l'essence:
@Entity @Builder @AllArgsConstructor @Table(name = "cakes") class CakeEntity { public CakeEntity() { } @Id @GeneratedValue(strategy = GenerationType.IDENTITY) Long id; @NotBlank String title; @Positive BigDecimal price; @NotBlank @NaturalId String sku; boolean promoted; @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; CakeEntity cakeEntity = (CakeEntity) o; return Objects.equals(title, cakeEntity.title); } @Override public int hashCode() { return Objects.hash(title); } }
Il y a quelques éléments moins évidents dans la description de l'entité.
@NaturalId pour le champ sku . Ce champ est utilisé comme «identifiant naturel» pour vérifier l'égalité des entités - utiliser tous les champs ou les champs @Id dans les méthodes equals / hashCode est plutôt un anti-modèle. Il est bien écrit sur la façon de vérifier correctement l'égalité des entités, par exemple ici .- Pour réduire un peu le code passe-partout, j'utilise Project Lombok - processeur d'annotation pour Java. Il vous permet d'ajouter diverses choses utiles, comme
@Builder - pour générer automatiquement un générateur pour une classe et @AllArgsConstructor pour créer un constructeur pour tous les champs.
Une implémentation d'interface sera fournie automatiquement par Spring Data.
En bas de la pyramide
Il est maintenant temps de descendre au niveau suivant de la pyramide. En règle générale, je vous recommande de toujours commencer par le test e2e , car cela vous permettra de déterminer le "but final" et les limites de la nouvelle fonctionnalité, mais il n'y a pas de règles strictes plus loin. Il n'est pas nécessaire d'écrire un test d'intégration avant de passer au niveau unitaire. C'est le plus souvent que c'est plus pratique et plus simple - et c'est tout à fait naturel de descendre.
Mais spécifiquement maintenant, je voudrais briser immédiatement cette règle et écrire un test unitaire qui aidera à déterminer l'interface et le contrat d'un nouveau composant qui n'existe pas encore. Le contrôleur doit renvoyer un modèle qui sera rempli à partir d'un certain composant X, et j'ai écrit ce test:
@ExtendWith(MockitoExtension.class) class IndexControllerTest { @Mock CakeFinder cakeFinder; @InjectMocks IndexController indexController; private Set<Cake> cakes = Set.of(new Cake("Test 1", "£10"), new Cake("Test 2", "£10")); @BeforeEach void setUp() { when(cakeFinder.findPromotedCakes()).thenReturn(cakes); } @Test void shouldReturnAListOfFoundPromotedCakes() { ModelAndView index = indexController.index(); assertThat(index.getModel()).extracting("cakes").contains(cakes); } }
Il s'agit d'un test unitaire pur - pas de contextes, pas de bases de données ici, seulement Mockito pour mok. Et ce test est juste une bonne démonstration de la façon dont Spring aide les tests unitaires - le contrôleur dans Spring MVC est juste une classe dont les méthodes acceptent des paramètres de types ordinaires et renvoient des objets POJO - Afficher les modèles . Il n'y a pas de requêtes HTTP, pas de réponses, en-têtes, JSON, XML - tout cela sera automatiquement appliqué sur la pile sous la forme de convertisseurs et de sérialiseurs. Oui, il y a un petit "indice" à Spring sous la forme de ModelAndView , mais c'est un POJO régulier et vous pouvez même vous en débarrasser si vous le souhaitez, il est nécessaire spécifiquement pour les contrôleurs d'interface utilisateur.
Je ne parlerai pas beaucoup de Mockito, vous pouvez tout lire dans la documentation officielle. Plus précisément, il n'y a que des points intéressants dans ce test - j'utilise MockitoExtension.class comme MockitoExtension.class de test, et il générera automatiquement des mokas pour les champs annotés par @Mock , puis injectera ces mokas en tant que dépendances dans le constructeur de l'objet dans le champ marqué @InjectMocks . Vous pouvez faire tout cela manuellement en utilisant la méthode Mockito.mock() , puis créer une classe.
Et ce test permet de déterminer la méthode du nouveau composant - findPromotedCakes , une liste de gâteaux que nous voulons afficher sur la page principale. Il ne détermine pas ce que c'est ni comment cela devrait fonctionner avec la base de données. La seule responsabilité du contrôleur est de prendre ce qui lui a été transféré et de retourner les modèles ("gâteaux") dans un champ spécifique. Néanmoins, CakeFinder déjà la première méthode dans mon interface, ce qui signifie que vous pouvez écrire un test d'intégration pour cela.
J'ai délibérément rendu toutes les classes à l'intérieur du paquet cakes privées afin que personne en dehors du paquet ne puisse les utiliser. La seule façon d'obtenir des données de la base de données est avec l'interface CakeFinder, qui est mon «composant X» pour accéder à la base de données. Il devient un «connecteur» naturel, que je peux facilement verrouiller si je dois tester quelque chose isolément et ne pas toucher la base. Et sa seule implémentation est JpaCakeFinder. Et si, par exemple, le type de base de données ou la source de données change à l'avenir, vous devrez ajouter une implémentation de l'interface CakeFinder sans changer le code qui l'utilise.
Test d'intégration pour JPA à l'aide de @DataJpaTest
Les tests d'intégration sont le pain et le beurre de printemps. En fait, tout a été si bien fait pour les tests d'intégration que les développeurs ne veulent parfois pas aller au niveau de l'unité ou négliger le niveau de l'interface utilisateur. Ce n'est ni mauvais ni bon - je répète que l'objectif principal des tests est la confiance. Et un ensemble de tests d'intégration rapides et efficaces peut suffire à fournir cette confiance. Cependant, il existe un risque qu'avec le temps, ces tests soient plus lents ou plus lents, ou commencent simplement à tester les composants de manière isolée, au lieu de l'intégration.
Les tests d'intégration peuvent exécuter l'application telle qu'elle est ( @SpringBootTest ) ou son composant distinct (JPA, Web). Dans mon cas, je veux écrire un test ciblé pour JPA - donc je n'ai pas besoin de configurer de contrôleurs ou d'autres composants. L'annotation @DataJpaTest est responsable dans le Spring Boot Test. Il s'agit d'une méta annotation, c'est-à-dire Il combine plusieurs annotations différentes qui configurent différents aspects du test.
- @AutoConfigureDataJpa
- @AutoConfigureTestDatabase
- @AutoConfigureCache
- @AutoConfigureTestEntityManager
- @Transactional
Je vais d'abord vous parler de chacun individuellement, puis je vais vous montrer le test terminé.
@AutoConfigureDataJpa
Il charge un ensemble complet de configurations et met en place des référentiels (génération automatique d'implémentations pour CrudRepositories ), des outils de migration pour les bases de données FlyWay et Liquibase, se connectant à la base de données à l'aide de DataSource, du gestionnaire de transactions et enfin d'Hibernate. En fait, ce n'est qu'un ensemble de configurations pertinentes pour accéder aux données - ni DispatcherServlet de Web MVC, ni d'autres composants ne sont inclus ici.
@AutoConfigureTestDatabase
C'est l'un des aspects les plus intéressants du test JPA. Cette configuration recherche le chemin de classe pour l'une des bases de données incorporées prises en charge et reconfigure le contexte afin que le DataSource pointe vers une base de données en mémoire créée de façon aléatoire . Depuis que j'ai ajouté la dépendance à la base H2, je n'ai pas besoin de faire autre chose, le fait d'avoir cette annotation automatiquement pour chaque test fournira une base vide, et c'est tout simplement incroyablement pratique.
Il convient de rappeler que cette base sera complètement vide, sans schéma. Pour générer le circuit, il existe deux options.
- Utilisez la fonction DDL automatique d'Hibernate. Le Spring Boot Test définira automatiquement cette valeur sur
create-drop afin qu'Hibernate génère un schéma à partir de la description de l'entité et le supprime à la fin de la session. Il s'agit d'une fonctionnalité incroyablement puissante d'Hibernate, qui est très utile pour les tests. - Utilisez les migrations créées par Flyway ou Liquibase .
Vous pouvez en savoir plus sur les différentes approches d'initialisation de la base de données dans la documentation .
@AutoConfigureCache
Il configure simplement le cache pour utiliser NoOpCacheManager - c'est-à-dire ne cache rien. Ceci est utile pour éviter les surprises lors des tests.
@AutoConfigureTestEntityManager
Ajoute un objet TestEntityManager spécial au TestEntityManager , qui en soi est une bête intéressante. EntityManager est la classe principale de JPA, qui est responsable de l'ajout d'entités à la session, de la suppression et d'autres choses similaires. Ce n'est que lorsque, par exemple, Hibernate entre en service - l'ajout d'une entité à une session ne signifie pas qu'une demande à la base de données sera exécutée et le chargement à partir d'une session ne signifie pas qu'une demande de sélection sera exécutée. En raison des mécanismes internes d'Hibernate, les opérations réelles avec la base de données seront effectuées au bon moment, ce que le cadre lui-même déterminera. Mais dans les tests, il peut être nécessaire d'envoyer de force quelque chose à la base de données, car le but des tests est de tester l'intégration. Et TestEntityManager est juste une aide qui aidera à effectuer de force certaines opérations avec la base de données - par exemple, persistAndFlush() forcera Hibernate à exécuter toutes les requêtes.
@Transactional
Cette annotation rend tous les tests de la classe transactionnels, avec restauration automatique de la transaction à la fin du test. Il s'agit simplement d'un mécanisme de «nettoyage» de la base de données avant chaque test, car sinon vous devrez supprimer manuellement les données de chaque table.
La question de savoir si un test doit gérer une transaction n'est pas une question aussi simple et évidente que cela puisse paraître. Malgré la commodité de l'état «propre» de la base de données, la présence de @Transactional dans les tests peut être une surprise désagréable si le code de «bataille» ne démarre pas la transaction lui-même, mais nécessite un code existant. Cela peut conduire au fait que le test d'intégration réussit, mais lorsque le code réel est exécuté à partir du contrôleur, et non à partir du test, le service n'aura pas de transaction active et la méthode lèvera une exception. Bien que cela semble dangereux, avec des tests de haut niveau de tests d'interface utilisateur, les tests transactionnels ne sont pas si mauvais. D'après mon expérience, je n'ai vu qu'une seule fois, lors d'un test d'intégration réussi, le code de production s'est écrasé, ce qui a clairement exigé l'existence d'une transaction existante. Mais si vous devez toujours vérifier que les services et les composants gèrent eux-mêmes correctement les transactions, vous pouvez «bloquer» l'annotation @Transactional sur le test avec le mode souhaité (par exemple, ne démarrez pas la transaction).
Test d'intégration avec @SpringBootTest
Je tiens également à noter que @DataJpaTest n'est pas un exemple unique de test d'intégration focale, il existe @WebMvcTest , @DataMongoTest et bien d'autres. Mais l'une des annotations de test les plus importantes reste @SpringBootTest , qui lance l'application «telle quelle » pour les tests - avec tous les composants et intégrations configurés. Une question logique se pose - si vous pouvez exécuter l'application entière, pourquoi faire des tests focaux DataJpa, par exemple? Je dirais qu'il n'y a pas de règles strictes ici encore.
S'il est possible d'exécuter des applications à chaque fois, d'isoler les plantages dans les tests, de ne pas surcharger et de ne pas compliquer à nouveau la configuration du test, alors bien sûr, vous pouvez et devez utiliser @SpringBootTest.
Cependant, dans la vie réelle, les applications peuvent nécessiter de nombreux paramètres différents, se connecter à différents systèmes et je ne voudrais pas que mes tests d'accès à la base de données tombent, car la connexion à la file d'attente des messages n'est pas configurée. Par conséquent, il est important d'utiliser le bon sens, et si pour que le test avec l'annotation @SpringBootTest fonctionne, vous devez verrouiller la moitié du système - est-ce que cela a du sens alors dans @SpringBootTest?
Préparation des données pour le test
L'un des points clés des tests est la préparation des données. Chaque test doit être effectué de manière isolée et préparer l'environnement avant de démarrer, amenant le système à son état d'origine souhaité. L'option la plus simple pour ce faire consiste à utiliser les annotations @BeforeEach / @BeforeAll et à y ajouter des entrées à la base de données à l'aide du référentiel, TestEntityManager ou TestEntityManager . Mais il existe une autre option qui vous permet d'exécuter un script préparé ou d'exécuter la requête SQL souhaitée, c'est l'annotation @Sql . Avant d'exécuter le test, le Spring Boot Test exécutera automatiquement le script spécifié, éliminant la nécessité d'ajouter le bloc @BeforeAll , et @Transactional se chargera du @Transactional données.
@DataJpaTest class JpaCakeFinderTest { private static final String PROMOTED_CAKE = "Red Velvet"; private static final String NON_PROMOTED_CAKE = "Victoria Sponge"; private CakeFinder finder; @Autowired CakeRepository cakeRepository; @Autowired TestEntityManager testEntityManager; @BeforeEach void setUp() { this.testEntityManager.persistAndFlush(CakeEntity.builder().title(PROMOTED_CAKE) .sku("SKU1").price(BigDecimal.TEN).promoted(true).build()); this.testEntityManager.persistAndFlush(CakeEntity.builder().sku("SKU2") .title(NON_PROMOTED_CAKE).price(BigDecimal.ONE).promoted(false).build()); finder = new JpaCakeFinder(cakeRepository); } ... }
Cycle de refactorisation rouge-vert
Malgré cette quantité de texte, pour le développeur, le test ressemble toujours à une classe simple avec l'annotation @DataJpaTest, mais j'espère que j'ai pu montrer combien de choses utiles se passent sous le capot, auxquelles le développeur ne peut pas penser. Nous pouvons maintenant passer au cycle TDD et cette fois, je vais montrer quelques itérations TDD, avec des exemples de refactoring et de code minimal. Pour le rendre plus clair, je vous recommande fortement de regarder l'historique dans Git, où chaque commit est une étape distincte et significative avec une description de ce qu'il fait et comment il le fait.
Préparation des données
J'utilise l'approche avec @BeforeAll / @BeforeEach et crée manuellement tous les enregistrements de la base de données. L'exemple avec l'annotation @Sql a été déplacé dans une classe distincte JpaCakeFinderTestWithScriptSetup , il duplique les tests, ce qui, bien sûr, ne devrait pas l'être, et existe dans le seul but de démontrer l'approche.
L'état initial du système - il y a deux entrées dans le système, un gâteau participe à la promotion et doit être inclus dans le résultat retourné par la méthode, le second - non.
Premier test test d'intégration
Le premier test est le plus simple - findPromotedCakes doit inclure une description et le prix du gâteau participant à la promotion.
Rouge
@Test void shouldReturnPromotedCakes() { Iterable<Cake> promotedCakes = finder.findPromotedCakes(); assertThat(promotedCakes).extracting(Cake::getTitle).contains(PROMOTED_CAKE); assertThat(promotedCakes).extracting(Cake::getPrice).contains("£10.00"); }
Le test se bloque, bien sûr, l'implémentation par défaut renvoie un ensemble vide.
Vert
Naturellement, nous aimerions écrire immédiatement le filtrage, faire une demande à la base de données avec where et ainsi de suite. Mais suivant la pratique TDD, je dois écrire le code minimum pour que le test réussisse . Et ce code minimal consiste à renvoyer tous les enregistrements de la base de données. Oui, si simple et ringard.
public Set<Cake> findPromotedCakes() { Spliterator<CakeEntity> cakes = this.cakeRepository.findAll() .spliterator(); return StreamSupport.stream(cakes, false).map( cakeEntity -> new Cake(cakeEntity.title, formatPrice(cakeEntity.price))) .collect(Collectors.toSet()); } private String formatPrice(BigDecimal price) { return "£" + price.setScale(2, RoundingMode.DOWN).toPlainString(); }
Certains diront probablement qu'ici, vous pouvez rendre le test vert même sans base - il suffit de coder en dur le résultat attendu par le test. J'entends parfois un tel argument, mais je pense que tout le monde comprend que le TDD n'est pas un dogme ou une religion, cela n'a aucun sens d'amener cela au point d'absurdité. Mais si vous le voulez vraiment, vous pouvez, par exemple, randomiser des données sur l'installation afin qu'elles ne soient pas codées en dur.
Refactor
Je ne vois pas beaucoup de refactoring ici, donc cette phase peut être ignorée pour ce test particulier. Mais je ne recommanderais toujours pas d'ignorer cette phase, il vaut mieux s'arrêter et penser à chaque fois dans l'état «vert» du système - est-il possible de refactoriser quelque chose pour le rendre meilleur et plus facile?
Deuxième test
Mais le deuxième test vérifiera déjà qu'aucun gâteau promu ne tombera dans le résultat renvoyé par findPromotedCakes .
@Test void shouldNotReturnNonPromotedCakes() { Iterable<Cake> promotedCakes = finder.findPromotedCakes(); assertThat(promotedCakes).extracting(Cake::getTitle) .doesNotContain(NON_PROMOTED_CAKE); }
Rouge
Comme prévu, le test se bloque - il y a deux enregistrements dans la base de données et le code les renvoie simplement tous.
Vert
Et encore une fois, vous pouvez penser - et quel est le code minimum que vous pouvez écrire pour réussir le test? Puisqu'il y a déjà un flux et son assemblage, vous pouvez simplement y ajouter un bloc de filter .
public Set<Cake> findPromotedCakes() { Spliterator<CakeEntity> cakes = this.cakeRepository.findAll() .spliterator(); return StreamSupport.stream(cakes, false) .filter(cakeEntity -> cakeEntity.promoted) .map(cakeEntity -> new Cake(cakeEntity.title, formatPrice(cakeEntity.price))) .collect(Collectors.toSet()); }
Nous recommençons les tests - les tests d'intégration sont désormais verts. Un moment important est venu - grâce à la combinaison du test unitaire du contrôleur et du test d'intégration pour travailler avec la base de données, ma fonctionnalité est prête - et le test de l'interface utilisateur passe maintenant!
Refactor
Et puisque tous les tests sont verts - il est temps de refactoriser. Je pense qu'il n'est pas nécessaire de préciser que le filtrage en mémoire n'est pas une bonne idée, il vaut mieux le faire dans la base de données. Pour ce faire, j'ai ajouté une nouvelle méthode dans le CakesRepository - CakesRepository :
interface CakeRepository extends CrudRepository<CakeEntity, String> { Iterable<CakeEntity> findByPromotedIsTrue(); }
Pour cette méthode, Spring Data a généré automatiquement une méthode qui exécutera une requête du formulaire de select from cakes where promoted = true . En savoir plus sur la génération de requêtes dans la documentation Spring Data.
public Set<Cake> findPromotedCakes() { Spliterator<CakeEntity> cakes = this.cakeRepository.findByPromotedIsTrue() .spliterator(); return StreamSupport.stream(cakes, false).map( cakeEntity -> new Cake(cakeEntity.title, formatPrice(cakeEntity.price))) .collect(Collectors.toSet()); }
C'est un bon exemple de la flexibilité offerte par les tests d'intégration et l'approche par boîte noire. Si le référentiel était verrouillé, il n'était pas impossible d'ajouter une nouvelle méthode sans modifier les tests.
Connexion à la base de production
Pour ajouter un peu de «réalisme» et montrer comment séparer la configuration des tests et l'application principale, j'ajouterai une configuration d'accès aux données pour l'application «production».
Tout est traditionnellement ajouté par la section dans application.yml :
datasource: url: jdbc:h2:./data/cake-factory
Cela enregistrera automatiquement les données du système de fichiers dans le dossier ./data . Je note que ce dossier ne sera pas créé dans les tests - @DataJpaTest remplacera automatiquement la connexion à la base de données de fichiers par une base de données aléatoire en mémoire en raison de la présence de l'annotation @AutoConfigureTestDatabase .
, — data.sql schema.sql . , Spring Boot . , , , .
Conclusion
, , , TDD .
Spring Security — Spring, .