"
Entreprise " - opérateur télécom PJSC "Megafon"
"
Noda " est le serveur RabbitMQ.
Un «
cluster » est une combinaison, dans notre cas de trois, de nœuds RabbitMQ fonctionnant dans leur ensemble.
«
Contour » - un ensemble de clusters RabbitMQ, dont les règles de travail sont déterminées sur l'équilibreur en face d'eux.
"
Balancer ", "
hap " - Haproxy - équilibreur qui remplit la fonction de commutation de la charge sur les clusters dans la boucle. Une paire de serveurs Haproxy fonctionnant en parallèle est utilisée pour chaque boucle.
"
Sous-système " - l'éditeur et / ou consommateur de messages transmis par le lapin
"
SYSTEM " - un ensemble de sous-systèmes, qui est une solution logicielle et matérielle unique utilisée par la société, caractérisée par sa distribution dans toute la Russie, mais avec plusieurs centres où toutes les informations circulent et où les principaux calculs et calculs ont lieu.
SYSTÈME - un système géographiquement réparti - de Khabarovsk et Vladivostok à Saint-Pétersbourg et Krasnodar. Sur le plan architectural, il s'agit de plusieurs contours centraux, divisés par les caractéristiques des sous-systèmes qui leur sont connectés.
Quelle est la mission du transport dans les réalités des télécoms?
En bref: la réponse des sous-systèmes à l'action de chaque abonné suit, qui à son tour informe les autres sous-systèmes des événements et des changements ultérieurs. Les messages sont générés par toutes les actions avec le SYSTÈME, non seulement des abonnés, mais aussi du côté des employés de la Société et des sous-systèmes (un très grand nombre de tâches sont effectuées automatiquement).
Caractéristiques du transport dans les télécommunications: grand, pas de mal, GRAND flux de données diverses transmises par transport asynchrone.
Certains sous-systèmes vivent sur des clusters séparés en raison de la lourdeur des flux de messages - il n'y a tout simplement plus de ressources sur le cluster, par exemple, avec un flux de messages de 5-6 mille messages / seconde, la quantité de données transférées peut atteindre 170-190 mégaoctets / seconde. Avec un tel profil de charge, une tentative de débarquer quelqu'un d'autre sur ce cluster entraînera de tristes conséquences: comme il n'y a pas assez de ressources pour traiter toutes les données en même temps, le lapin commencera à conduire les connexions entrantes dans un
flux - un processus de publication simple commencera, avec toutes les conséquences pour tous les sous-systèmes et systèmes dans ensemble.
Exigences de base pour le transport:
- L'accessibilité des véhicules devrait être de 99,99%. En pratique, cela se traduit par une exigence opérationnelle 24/7 et la capacité de répondre automatiquement à toutes les situations d'urgence.
- Sécurité des données: le pourcentage de messages perdus sur le transport devrait tendre à 0.
Par exemple, lors du fait d'appeler, plusieurs messages différents transitent par le transport asynchrone. certains messages sont destinés à des sous-systèmes vivant dans le même circuit, et certains sont destinés à être transmis à des nœuds centraux. Le même message peut être revendiqué par plusieurs sous-systèmes, par conséquent, au stade de la publication du message chez le lapin, il est copié et envoyé à différents consommateurs. Et dans certains cas, la copie des messages est obligatoirement mise en œuvre sur un circuit intermédiaire - lorsque des informations doivent être transmises du circuit de Khabarovsk au circuit de Krasnodar. La transmission se fait par l'un des contours centraux, où des copies des messages sont faites, pour les destinataires centraux.
Outre les événements provoqués par les actions de l'abonné, les messages de service qui échangent les sous-systèmes passent par le transport. Ainsi, plusieurs milliers de routes de messagerie différentes sont obtenues, certaines se croisent, certaines existent isolément. Il suffit de nommer le nombre de files d'attente impliquées dans les itinéraires sur différents Contours pour comprendre l'échelle approximative de la carte de transport: Sur les circuits centraux 600, 200, 260, 15 ... et sur les Circuits distants 80-100 ...
Avec une telle implication du transport, les exigences d'accessibilité à 100% de tous les nœuds de transport ne semblent plus excessives. Nous passons à la mise en œuvre de ces exigences.
Comment nous résolvons les tâches
En plus de
RabbitMQ lui -
même ,
Haproxy est utilisé pour équilibrer la charge et fournir une réponse automatique aux urgences.
Quelques mots sur l'environnement matériel et logiciel dans lequel nos lapins existent:
- Tous les serveurs de lapin sont virtuels, avec des paramètres de 8-12 CPU, 16 Gb Mem, 200 Gb HDD. Comme l'expérience l'a montré, même l'utilisation de serveurs non virtuels effrayants avec 90 cœurs et un tas de RAM offre une petite amélioration des performances à des coûts nettement plus élevés. Versions utilisées: 3.6.6 (en pratique - la plus stable de 3.6) avec un erlang de 18.3, 3.7.6 avec un erlang de 20.1.
- Pour Haproxy, les exigences sont beaucoup plus faibles: 2 CPU, 4 Gb Mem, la version haproxy est stable 1.8. La charge sur les ressources sur tous les serveurs haproxy ne dépasse pas 15% CPU / Mem.
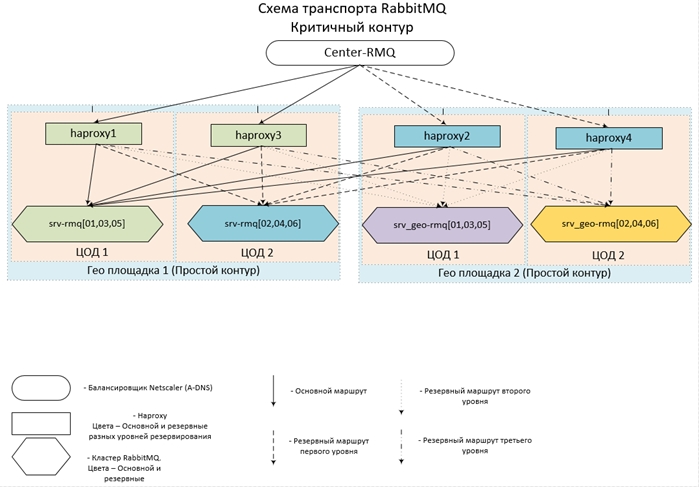
- L'ensemble du zoo est situé dans 14 centres de données répartis sur 7 sites à travers le pays, réunis en un seul réseau. Dans chacun des centres de données, il existe un cluster de trois nœuds et un concentrateur.
- Pour les circuits distants, 2 centres de données sont utilisés, pour chacun des circuits centraux - 4.
- Les circuits centraux interagissent entre eux ainsi qu'avec les circuits distants; à leur tour, les circuits distants fonctionnent uniquement avec les circuits centraux; ils n'ont pas de communication directe entre eux.
- Les configurations de Haps et Clusters au sein d'un même Circuit sont complètement identiques. Le point d'entrée pour chaque circuit est un alias pour plusieurs enregistrements A-DNS. Ainsi, pour éviter que cela ne se produise, au moins un hap et au moins un des clusters (au moins un nœud du cluster) dans chaque circuit seront disponibles. Étant donné que le cas de défaillance de même 6 serveurs dans deux centres de données en même temps est extrêmement improbable, l'acceptabilité est supposée proche de 100%.
Il semble conçu (et mis en œuvre) tout cela comme ceci:

Maintenant quelques configs.
Configuration haproxy| frontend center-rmq_5672 | |
| lier | *: 5672 |
| mode | TCP |
| maxconn | 10 000 |
| client de délai d'attente | 3h |
| option | tcpka |
| option | tcplog |
| default_backend | center-rmq_5672 |
| frontend center-rmq_5672_lvl_1 | |
| lier | localhost: 56721 |
| mode | TCP |
| maxconn | 10 000 |
| client de délai d'attente | 3h |
| option | tcpka |
| option | tcplog |
| default_backend | center-rmq_5672_lvl_1 |
| backend center-rmq_5672 |
| équilibre | lessconn |
| mode | TCP |
| fullconn | 10 000 |
| délai | serveur 3h |
| serveur | srv-rmq01 10/10/10/10/106767 vérification inter 5s montée 2 chute 3 arrêt-sauvegarde-sessions marquées |
| serveur | srv-rmq03 10/10/10/2011 11672 vérification inter 5s montée 2 chute 3 arrêt-sauvegarde-sessions balisées |
| serveur | srv-rmq05 10/10/10/126767 contrôle inter 5 s montée 2 chute 3 arrêt-sauvegarde-sessions marquées |
| serveur | localhost 127.0.0.1 ∗ 6721 check inter 5s rise 2 fall 3 backup on-marked-down shutdown-sessions |
| backend center-rmq_5672_lvl_1 |
| équilibre | lessconn |
| mode | TCP |
| fullconn | 10 000 |
| délai | serveur 3h |
| serveur | srv-rmq02 10/10/10/136767 contrôle inter 5s montée 2 chute 3 arrêt-sauvegarde-sessions marquées |
| serveur | srv-rmq04 10/10/10/14/1067 check inter 5s montée 2 chute 3 arrêt-sauvegarde-sessions balisées |
| serveur | srv-rmq06 10.10.10.5:0767 vérification inter 5 s montée 2 chute 3 arrêt-sauvegarde-sessions marquées |
La première section du front décrit le point d'entrée - menant au cluster principal, la deuxième section est conçue pour équilibrer le niveau de réserve. Si vous décrivez simplement tous les serveurs de sauvegarde de lapin dans la section backend (instruction de sauvegarde), cela fonctionnera de la même manière - si le cluster principal est complètement inaccessible, les connexions iront au serveur de sauvegarde, cependant, toutes les connexions iront au premier serveur de sauvegarde de la liste. Pour assurer l'équilibrage de la charge sur tous les nœuds de sauvegarde, nous introduisons simplement un front supplémentaire, que nous rendons disponible uniquement avec localhost, et nous lui attribuons le serveur de sauvegarde.
L'exemple ci-dessus décrit l'équilibrage de la boucle distante - qui fonctionne dans deux centres de données: le serveur srv-rmq {01,03,05} - vivent dans le centre de données n ° 1, srv-rmq {02,04,06} - dans le centre de données n ° 2. Ainsi, pour implémenter la solution à quatre codas, nous avons seulement besoin d'ajouter deux fronts locaux supplémentaires et deux sections backend des serveurs rabbit correspondants.
Le comportement de l'équilibreur avec cette configuration est le suivant: tant qu'au moins un serveur principal est vivant, nous l'utilisons. Si les serveurs principaux ne sont pas disponibles, nous travaillons avec une réserve. Si au moins un serveur principal devient disponible, toutes les connexions aux serveurs de sauvegarde sont déconnectées et, lorsque la connexion est restaurée, elles tombent déjà sur le cluster principal.
L'expérience de fonctionnement de cette configuration montre une disponibilité de presque 100% de chacun des circuits. Cette solution nécessite que les sous-systèmes soient parfaitement légaux et simples: pouvoir se reconnecter avec le lapin après déconnexion.
Nous avons donc fourni l'équilibrage de charge à un nombre arbitraire de clusters et basculé automatiquement entre eux, il est temps d'aller directement aux lapins.
Chaque cluster est créé à partir de trois nœuds, comme le montre la pratique - le nombre de nœuds le plus optimal, ce qui garantit l'équilibre optimal entre disponibilité / tolérance aux pannes / vitesse. Étant donné que le lapin n'évolue pas horizontalement (les performances du cluster sont égales aux performances du serveur le plus lent), nous créons tous les nœuds avec les mêmes paramètres optimaux pour CPU / Mem / Hdd. Nous positionnons les serveurs aussi près que possible les uns des autres - dans notre cas, nous classons les machines virtuelles dans la même batterie de serveurs.
En ce qui concerne les conditions préalables, à la suite desquelles de la part des sous-systèmes assureront le fonctionnement le plus stable et le respect de l'exigence de sauvegarde des messages reçus:
- Le travail avec le lapin se fait uniquement via le protocole amqp / amqps - via l'équilibrage. Autorisation sous les comptes locaux - au sein de chaque cluster (enfin, et tout le circuit)
- Les sous-systèmes sont connectés au lapin en mode passif: aucune manipulation avec les entités des lapins (création de files d'attente / eschendzhey / bind) n'est autorisée et limitée au niveau des droits de compte - nous ne donnons tout simplement pas de droits de configuration.
- Toutes les entités nécessaires sont créées de manière centralisée, et non au moyen de sous-systèmes, et sur tous les clusters de cluster sont effectuées de la même manière - pour assurer la commutation automatique vers le cluster de sauvegarde et vice versa. Sinon, nous pouvons obtenir une image: nous sommes passés à la réserve, mais la file d'attente ou la liaison n'est pas là, et nous pouvons obtenir le choix d'une erreur de connexion ou d'une perte de messages.
Maintenant, les paramètres directement sur les lapins:
- Les hôtes locaux n'ont pas accès à l'interface Web
- L'accès au Web est organisé via LDAP - nous nous intégrons à AD et obtenons la journalisation de qui et où est allé sur la webcam. Au niveau de la configuration, nous restreignons les droits des comptes AD, non seulement nous exigeons d'être dans un certain groupe, mais nous ne donnons que les droits de «voir». Les groupes de surveillance sont plus que suffisants. Et nous suspendons les droits d'administrateur à un autre groupe dans AD, ainsi le cercle d'influence sur le transport est considérablement limité.
- Pour faciliter l'administration et le suivi:
Sur tous les VHOST, nous suspendons immédiatement une politique de niveau 0 avec application à toutes les files d'attente (modèle :. *):
- ha-mode: all - stocke toutes les données sur tous les nœuds du cluster, la vitesse de traitement des messages diminue, mais leur sécurité et leur disponibilité sont assurées.
- ha-sync-mode: automatic - demande au robot de synchroniser automatiquement les données sur tous les nœuds du cluster: la sécurité et la disponibilité des données augmentent également.
- mode file d'attente: paresseux - peut-être l'une des options les plus utiles apparues chez les lapins depuis la version 3.6 - enregistrement immédiat des messages sur le disque dur. Cette option réduit considérablement la consommation de RAM et augmente la sécurité des données lors des arrêts / chutes de nœuds ou du cluster dans son ensemble.
- Paramètres dans le fichier de configuration ( rabbitmq-main / conf / rabbitmq.config ):
- Section lapin : {vm_memory_high_watermark_paging_ratio, 0,5} - seuil de téléchargement des messages sur le disque à 50%. Avec paresseux activé, il sert plus d'assurance lorsque nous souscrivons une police, par exemple, niveau 1, dans laquelle nous oublions d'inclure paresseux .
- {vm_memory_high_watermark, 0,95} - nous limitons le lapin à 95% de la RAM totale, car seul le lapin vit sur les serveurs, cela n'a aucun sens d'introduire des restrictions plus strictes. 5% "geste large" qu'il en soit - quittez le système d'exploitation, la surveillance et d'autres petites choses utiles. Comme cette valeur est la limite supérieure, il y en a assez pour tout le monde.
- {cluster_partition_handling, pause_minority} - décrit le comportement du cluster lorsque la partition réseau se produit, pour trois clusters de nœuds ou plus, cet indicateur est recommandé - il permet au cluster de se récupérer.
- {disk_free_limit, "500MB"} - tout est simple, quand il y a 500 Mo d'espace disque libre - la publication des messages sera arrêtée, seule la soustraction sera disponible.
- {auth_backends, [rabbit_auth_backend_internal, rabbit_auth_backend_ldap]} - ordre d'autorisation pour les lapins: Tout d'abord, la présence d'une échographie dans la base de données locale est vérifiée, et sinon, allez sur le serveur LDAP.
- Section rabbitmq_auth_backend_ldap - configuration de l'interaction avec AD: {serveurs, ["srv_dc1", "srv_dc2"]} - une liste de contrôleurs de domaine sur lesquels l'authentification aura lieu.
- Les paramètres qui décrivent directement l'utilisateur dans AD, le port LDAP, etc. sont purement individuels et sont décrits en détail dans la documentation.
- La chose la plus importante pour nous est une description des droits et restrictions sur l'administration et l'accès à l'interface Web des lapins: tag_queries:
[{administrateur, {in_group, "cn = rabbitmq-admins, ou = GRP, ou = GRP_MAIN, dc = My_domain, dc = ru"}},
{surveillance,
{in_group, "cn = rabbitmq-web, ou = GRP, ou = GRP_MAIN, dc = My_domain, dc = ru"}
}] - cette conception fournit des privilèges administratifs à tous les utilisateurs du groupe rabbitmq-admins et des droits de surveillance (au minimum suffisants pour visualiser l'accès) pour le groupe rabbitmq-web.
- requête_accès_ressource :
{pour,
[{permission, configure, {in_group, "cn = rabbitmq-admins, ou = GRP, ou = GRP_MAIN, dc = My_domain, dc = ru"}},
{permission, write, {in_group, "cn = rabbitmq-admins, ou = GRP, ou = GRP_MAIN, dc = My_domain, dc = ru"}},
{permission, lecture, {constant, true}}
]
} - nous fournissons les droits de configuration et d'écriture uniquement au groupe d'administrateurs, à tous ceux qui se connectent avec succès, les droits sont en lecture seule - il peut lire les messages via l'interface Web.
Nous obtenons un cluster configuré (au niveau du fichier de configuration et des paramètres dans le lapin lui-même) qui maximise la disponibilité et la sécurité des données. Par cela, nous mettons en œuvre l'exigence - assurer la disponibilité et la sécurité des données ... dans la plupart des cas.
Il y a plusieurs points à prendre en compte lors de l'utilisation de tels systèmes très chargés:
- Il est préférable d'organiser toutes les propriétés supplémentaires des files d'attente (TTL, expiration, longueur maximale, etc.) par les politiciens, plutôt que de suspendre les paramètres lors de la création des files d'attente. Il en résulte une structure personnalisable de manière flexible qui peut être personnalisée à la volée en fonction des réalités changeantes.
- Utilisation de TTL. Plus la file d'attente est longue, plus la charge sur le processeur est élevée. Pour éviter de "percer le plafond", il est préférable de limiter la longueur de la file d'attente via max-length également.
- En plus du lapin lui-même, un certain nombre d'applications utilitaires tournent sur le serveur, ce qui, curieusement, nécessite également des ressources CPU. Un lapin gourmand, par défaut, prend tous les noyaux disponibles ... Une situation désagréable peut se révéler: une lutte pour les ressources, qui peut facilement conduire à des freins sur le lapin. Pour éviter l'occurrence d'une telle situation, par exemple, comme suit: Modifiez les paramètres du lancement de l'erlang - introduisez une limite obligatoire sur le nombre de cœurs utilisés. Nous procédons comme suit: recherchez le fichier rabbitmq-env , recherchez le paramètre SERVER_ERL_ARGS = et ajoutez + sct L0-Xc0-X + SY: Y. Où X est le nombre de cœurs-1 (le comptage commence à 0), Y - Le nombre de cœurs -1 (à partir de 1). + sct L0-Xc0-X - change la liaison aux noyaux, + SY: Y - change le nombre de shedulers lancés par l'erlang. Donc pour un système de 8 cœurs, les paramètres ajoutés prendront la forme: + sct L0-6c0-6 + S 7: 7. De cette façon, nous ne donnons au lapin que 7 cœurs et nous nous attendons à ce que le système d'exploitation, en lançant d'autres processus, agisse de manière optimale et les accroche sur un noyau non chargé.
Les nuances de l'exploitation du zoo résultant
Ce que n'importe quel paramètre ne peut pas protéger, c'est la base effondrée de la mnésie - malheureusement, cela se produit avec une probabilité non nulle. Un résultat aussi désastreux n'est pas causé par des défaillances globales (par exemple, une défaillance complète d'un centre de données entier - la charge basculera simplement vers un autre cluster), mais davantage de défaillances locales - au sein du même segment de réseau.
De plus, ce sont les défaillances du réseau local qui font peur, car l'arrêt d'urgence d'un ou deux nœuds n'entraînera pas de conséquences fatales - simplement toutes les demandes iront à un nœud, et comme nous nous en souvenons, les performances dépendent des performances du seul nœud lui-même. Les pannes de réseau (nous ne prenons pas en compte les petites interruptions de communication - elles se produisent sans douleur) conduisent à une situation où les nœuds commencent le processus de synchronisation les uns avec les autres, puis la connexion se brise encore et encore pendant quelques secondes.
Par exemple, plusieurs clignotements du réseau et avec une fréquence de plus de 5 secondes (un tel délai est défini dans les paramètres Hapov, vous pouvez certainement les lire, mais pour vérifier l'efficacité, vous devrez répéter l'échec, ce que personne ne veut).
Le cluster peut toujours résister à une ou deux itérations de ce type, mais plus - les chances sont déjà minimes. Dans une telle situation, l'arrêt d'un nœud tombé peut enregistrer, mais il est presque impossible de le faire manuellement. Le plus souvent, le résultat n'est pas seulement la perte d'un nœud du cluster avec le message
«Partition réseau» , mais aussi l'image lorsque les données de la partie des files d'attente ont vécu uniquement ce nœud et n'ont pas eu le temps de se synchroniser avec les autres. Visuellement - dans la file d'attente, les données sont
NaN .
Et maintenant, c'est un signal non ambigu - basculez vers le cluster de sauvegarde. La commutation fournira un bonheur, il vous suffit d'arrêter les lapins sur le cluster principal - une question de plusieurs minutes. En conséquence, nous obtenons la restauration de la capacité de travail du transport et nous pouvons procéder en toute sécurité à l'analyse de l'accident et à son élimination.
Afin de retirer une grappe endommagée de sous la charge, afin d'éviter une dégradation supplémentaire, la chose la plus simple est de faire fonctionner le lapin sur des ports autres que 5672. Puisque nous surveillons les lapins par le port régulier, son déplacement, par exemple, par 5673 dans les paramètres du lapin, il vous permettra de lancer complètement le cluster sans douleur et d'essayer de restaurer son opérabilité et les messages qui y restent.
Nous le faisons en quelques étapes:
- Arrêtez tous les nœuds du cluster défaillant - le hap basculera la charge vers le cluster de sauvegarde
- RABBITMQ_NODE_PORT=5673 rabbitmq-env – , Web - 15672.
- .
Au démarrage, les index seront reconstruits et, dans la grande majorité des cas, toutes les données seront entièrement restaurées. Malheureusement, des plantages se produisent, qui obligent à supprimer physiquement tous les messages du disque, ne laissant que la configuration - les répertoires msg_store_persistent , msg_store_transient , files d'attente (pour la version 3.6) ou msg_stores (pour la version 3.7) sont supprimés dans le dossier contenant la base de données .Après une telle thérapie radicale, le cluster est lancé avec la préservation de la structure interne, mais sans messages.Et l'option la plus désagréable (observée une fois): les dommages à la base étaient tels qu'il était nécessaire de supprimer complètement la base entière et de reconstruire le cluster à partir de zéro.Pour la commodité de la gestion et de la mise à jour des lapins, pas un assemblage prêt à l'emploi en rpm n'est utilisé, mais un lapin démonté à l'aide de cpio et reconfiguré (changé les chemins dans les scripts). La principale différence: il ne nécessite pas de privilèges root pour installer / configurer, n'est pas installé sur le système (le lapin reconstruit est parfaitement emballé dans tgz) et fonctionne à partir de n'importe quel utilisateur. Cette approche vous permet de mettre à niveau les versions de manière flexible (si elle ne nécessite pas un arrêt complet du cluster - dans ce cas, passez simplement au cluster de sauvegarde et mettez à jour, sans oublier de spécifier le port décalé pour le fonctionnement). Il est même possible d'exécuter plusieurs instances de RabbitMQ sur la même machine - pour tester l'option est très pratique - vous pouvez déployer une copie architecturale réduite du zoo de la bataille.À la suite du chamanisme avec cpio et les chemins dans les scripts, nous avons eu une option de construction: deux dossiers rabbitmq-base (dans l'assemblage d'origine - le dossier mnesia) et rabbimq-main - ici, je mets tous les scripts nécessaires du lapin et erlang lui-même.Dans rabbimq-main / bin - liens symboliques vers des scripts lapin et erlang et un script de suivi de lapin (description ci-dessous).Dans rabbimq-main / init.d - le script rabbitmq-server à travers lequel les journaux démarrent / s'arrêtent / tournent; en lib, le lapin lui-même; dans lib64 - erlang (utilise une version allégée, uniquement pour le lapin, version d'erlang).Il est extrêmement facile de mettre à jour l'assembly résultant lorsque de nouvelles versions sont publiées - ajoutez le contenu de rabbimq-main / lib et rabbimq-main / lib64 à partir des nouvelles versions et remplacez les liens symboliques dans bin. Si la mise à jour affecte également les scripts de contrôle, modifiez simplement les chemins d'accès aux nôtres.Un avantage significatif de cette approche est la continuité complète des versions - tous les chemins, scripts, commandes de contrôle restent inchangés, ce qui vous permet d'utiliser tous les scripts utilitaires auto-écrits sans dopage pour chaque version.Depuis la chute des lapins, bien que rare, mais survenant, il a fallu mettre en place un mécanisme de suivi de leur bien-être - remontée en cas de chute (tout en conservant les logs des raisons de la chute). L'échec d'un nœud dans 99% des cas s'accompagne d'une entrée de journal, voire de tuer même laisse des traces, cela a permis de mettre en place une surveillance de l'état du lapin à l'aide d'un simple script.Pour les versions 3.6 et 3.7, le script est légèrement différent en raison des différences dans les entrées de journal.Pour 3.7, seules deux lignes sont modifiées if (os.path.isfile('/data/logs/rabbitmq/startup_log')) and (os.path.isfile('/data/logs/rabbitmq/startup_err')): if ((b' OK ' in LastRow('/data/logs/rabbitmq/startup_log')) or (b'FAILED' in LastRow('/data/logs/rabbitmq/startup_log'))) and not (b'Gracefully halting Erlang VM' in LastRow('/data/logs/rabbitmq/startup_err')):
Nous mettons en place un compte crontab sous lequel le lapin travaillera (par défaut rabbitmq) exécutant ce script (nom du script: check_and_run) toutes les minutes (d'abord, nous demandons à l'administrateur de donner au compte le droit d'utiliser crontab, mais si nous avons des droits root, nous le faisons nous-mêmes):
* / 1 * * * * ~ / rabbitmq-main / bin / check_and_runLe deuxième point d'utilisation du lapin remonté est la rotation des bûches.
Comme nous ne sommes pas liés au système logrotate, nous utilisons la fonctionnalité fournie par le développeur: le
script rabbitmq-server de init.d (pour la version 3.6)
En apportant de petites modifications à
rotation_logs_rabbitmq ()Ajouter:
find ${RABBITMQ_LOG_BASE}/http_api/*.log.* -maxdepth 0 -type f ! -name "*.gz" | xargs -i gzip --force {} find ${RABBITMQ_LOG_BASE}/*.log.*.back -maxdepth 0 -type f | xargs -i gzip {} find ${RABBITMQ_LOG_BASE}/*.gz -type f -mtime +30 -delete find ${RABBITMQ_LOG_BASE}/http_api/*.gz -type f -mtime +30 -delete
Résultat de l'exécution du script rabbitmq-server avec la clé rotation-logs: les journaux sont compressés par gzip et ne sont stockés que pendant les 30 derniers jours.
http_api - le chemin où le lapin place les journaux http - configuré dans le fichier de configuration:
{rabbitmq_management, [{rates_mode, détaillé}, {http_log_dir, path_to_logs / http_api "}]}Dans le même temps, je fais attention à
{rates_mode, détaillé } - l'option augmente légèrement la charge, mais elle vous permet de voir des informations sur qui publie des messages dans l'EXCHENGE sur l'interface WEB (et donc de passer par l'API). L'information est extrêmement nécessaire, car toutes les connexions passent par l'équilibreur - nous ne verrons que l'IP des équilibreurs eux-mêmes. Et si vous cassez tous les sous-systèmes qui fonctionnent avec le lapin pour qu'ils remplissent les paramètres des propriétés du client dans les propriétés de leurs connexions aux lapins, il sera possible d'obtenir des informations détaillées au niveau de la connexion qui exactement, où et avec quelle intensité publie les messages.
Avec la sortie des nouvelles versions 3.7, il y a eu un rejet complet du script
rabbimq-server dans init.d. Afin de faciliter le fonctionnement (l'uniformité des commandes de contrôle quelle que soit la version du lapin) et une transition plus fluide entre les versions, dans le lapin réassemblé, nous continuons à utiliser ce script. La vérité est encore une fois: nous
allons changer
un peu
rotation_logs_rabbitmq () , car le mécanisme de nommage des journaux après rotation a changé dans 3.7:
mv ${RABBITMQ_LOG_BASE}/$NODENAME.log.0 ${RABBITMQ_LOG_BASE}/$NODENAME.log.$(date +%Y%m%d-%H%M%S).back mv ${RABBITMQ_LOG_BASE}/$(echo $NODENAME)_upgrade.log.0 ${RABBITMQ_LOG_BASE}/$(echo $NODENAME)_upgrade.log.$(date +%Y%m%d-%H%M%S).back find ${RABBITMQ_LOG_BASE}/http_api/*.log.* -maxdepth 0 -type f ! -name "*.gz" | xargs -i gzip --force {} find ${RABBITMQ_LOG_BASE}/*.log.* -maxdepth 0 -type f ! -name "*.gz" | xargs -i gzip --force {} find ${RABBITMQ_LOG_BASE}/*.gz -type f -mtime +30 -delete find ${RABBITMQ_LOG_BASE}/http_api/*.gz -type f -mtime +30 -delete
Maintenant, il ne reste plus qu'à ajouter la tâche de rotation des journaux à crontab - par exemple, tous les jours à 23h00:
00 23 * * * ~ / rabbitmq-main / init.d / rabbitmq-server rotation-journauxPassons aux tâches à résoudre dans le cadre du fonctionnement de la "ferme aux lapins":
- Manipulations avec des entités de lapin - création / suppression d'entités de lapin: ekschendzhey, files d'attente, liaisons, pelles, utilisateurs, politiques. Et pour ce faire, c'est absolument identique sur tous les clusters.
- Après avoir basculé vers / depuis le cluster de sauvegarde, il est nécessaire de transférer les messages qui y sont restés vers le cluster actuel.
- Création de copies de sauvegarde des configurations de tous les clusters de tous les circuits
- Synchronisation complète des configurations de cluster dans le contour
- Arrêter / démarrer les lapins
- Pour analyser les flux de données actuels: tous les messages vont-ils et s'ils vont, alors où doivent-ils aller ou ...
- Trouvez et capturez les messages qui passent en fonction de tous les critères
Le fonctionnement de notre zoo et la solution des tâches sondées au moyen du plug-in régulier fourni
rabbitmq_management est possible, mais extrêmement gênant, c'est pourquoi un shell a été développé et mis en œuvre pour
contrôler toute la variété de lapins .