La sémantique ouverte de la langue russe, sur l'histoire dont vous pouvez lire
ici et
ici , a reçu une grande mise à jour. Nous avons collecté suffisamment de données pour appliquer l'apprentissage automatique au-dessus du balisage collecté et créer un modèle de langage sémantique. Ce qui en est sorti, voir sous la coupe.

Ce que nous faisons
Prenez deux groupes de mots:
- courir, tirer, comploter, marcher, marcher;
- coureur, photographe, ingénieur, touriste, athlète.
Il n'est pas difficile pour une personne de déterminer que le premier groupe contient des noms qui nomment des
actions ou des événements ; dans le second - appeler les
gens . Notre objectif est d'apprendre à une machine à résoudre de tels problèmes.
Pour ce faire, vous devez:
- Découvrez quelles classes naturelles existent dans la langue.
- Marquez un nombre suffisant de mots au sujet de l'appartenance aux classes du paragraphe 1 .
- Créez un algorithme qui apprend sur le balisage de l' élément 2 et reproduit la classification dans des mots inconnus.
Est-il possible de résoudre ce problème à l'aide de la sémantique de distribution?word2vec est un excellent outil, mais il préfère toujours la proximité thématique des mots, plutôt que la similitude de leurs classes sémantiques. Pour démontrer ce fait, exécutez l'algorithme en mots de l'exemple:
w1 | w2 | cosine_sim | | | | | | 1.0000 | | | 0.6618 | | | 0.5410 | | | 0.3389 | | | 0.1531 | | | 0.1342 | | | 0.1067 | | | 0.0681 | | | 0.0458 | | | 0.0373 | | | | | | 1.0000 | | | 0.5782 | | | 0.2525 | | | 0.2116 | | | 0.1644 | | | 0.1579 | | | 0.1342 | | | 0.1275 | | | 0.1100 | | | 0.0975 | | | | | | 1.0000 | | | 0.3575 | | | 0.2116 | | | 0.1587 | | | 0.1207 | | | 0.1067 | | | 0.0889 | | | 0.0794 | | | 0.0705 | | | 0.0430 | | | | | | 1.0000 | | | 0.1896 | | | 0.1753 | | | 0.1644 | | | 0.1548 | | | 0.1531 | | | 0.0889 | | | 0.0794 | | | 0.0568 | | | -0.0013 | | | | | | 1.0000 | | | 0.5410 | | | 0.3442 | | | 0.2469 | | | 0.1753 | | | 0.1650 | | | 0.1207 | | | 0.1100 | | | 0.0673 | | | 0.0642 | | | | | | 1.0000 | | | 0.6618 | | | 0.4909 | | | 0.3442 | | | 0.1548 | | | 0.1427 | | | 0.1422 | | | 0.1275 | | | 0.1209 | | | 0.0705 | | | | | | 1.0000 | | | 0.5782 | | | 0.3687 | | | 0.2334 | | | 0.1911 | | | 0.1587 | | | 0.1209 | | | 0.0642 | | | 0.0373 | | | -0.0013 | | | | | | 1.0000 | | | 0.3575 | | | 0.2334 | | | 0.1579 | | | 0.1503 | | | 0.1447 | | | 0.1422 | | | 0.0673 | | | 0.0568 | | | 0.0458 | | | | | | 1.0000 | | | 0.3687 | | | 0.2525 | | | 0.1896 | | | 0.1650 | | | 0.1503 | | | 0.1495 | | | 0.1427 | | | 0.0681 | | | 0.0430 | | | | | | 1.0000 | | | 0.4909 | | | 0.3389 | | | 0.2469 | | | 0.1911 | | | 0.1495 | | | 0.1447 | | | 0.0975 | | | 0.0889 | | | 0.0889 |
Comment la sémantique ouverte résout ce problèmeUne recherche dans le
dictionnaire sémantique donne le résultat suivant:
| | | | | ABSTRACT:ACTION | | ABSTRACT:ACTION | | ABSTRACT:ACTION | | ABSTRACT:ACTION | | ABSTRACT:ACTION | | HUMAN | | HUMAN | | HUMAN | | HUMAN | | HUMAN |
Ce qui a été fait et où télécharger
Le résultat du travail publié dans le
référentiel sur le GC et disponible en téléchargement est une description de la hiérarchie des classes et du balisage (manuel et automatique) des noms pour ces classes.
Pour vous familiariser avec l'ensemble de données, vous pouvez utiliser le navigateur interactif (lien dans le référentiel). Il existe également une version simplifiée de l'ensemble dans laquelle nous avons supprimé toute la hiérarchie et attribué une seule grande balise sémantique à chaque mot: "personnes", "animaux", "lieux", "choses", "actions", etc.
Lien vers Github: sémantique ouverte de la langue russe (jeu de données) .
À propos des classes de mots
Dans les problèmes de classification, les classes elles-mêmes sont souvent dictées par le problème résolu, et le travail de l'ingénieur des données se résume à trouver un ensemble d'attributs réussi sur lequel vous pouvez créer un modèle de travail.
Dans notre problème, les classes de mots, à proprement parler, ne sont pas connues à l'avance. Ici, une vaste couche de recherches sur la sémantique effectuée par des spécialistes de la linguistique nationaux et étrangers, la familiarité avec les dictionnaires sémantiques existants et WordNet'es vient à la rescousse.
C'est une bonne aide, mais la décision finale est toujours prise dans le cadre de nos propres recherches. Voici le truc. De nombreuses ressources sémantiques ont commencé à être créées à l'ère pré-informatique (au moins dans la compréhension moderne de l'ordinateur) et le choix des classes a été largement dicté par l'intuition langagière de leurs créateurs. À la fin du siècle précédent, WordNet était activement utilisé dans les tâches d'analyse automatique de texte, et de nombreuses ressources nouvellement créées ont été affinées pour des applications pratiques spécifiques.
Le résultat a été que ces ressources linguistiques contiennent simultanément des informations encyclopédiques linguistiques et extralinguistiques sur les unités de la langue. Il est logique de supposer qu'il est impossible de construire un modèle qui vérifierait les informations extralinguistiques, en s'appuyant uniquement sur l'analyse statistique des textes, car la source de données ne contient tout simplement pas les informations nécessaires.
Sur la base de cette hypothèse, nous ne recherchons que des classes naturelles pouvant être détectées et vérifiées automatiquement sur la base d'un modèle purement linguistique. Dans le même temps, l'architecture du système permet l'ajout d'un nombre arbitrairement élevé de couches supplémentaires d'informations sur les unités linguistiques, qui peuvent être utiles dans des applications pratiques.
Nous allons démontrer ce qui précède avec un exemple spécifique, en analysant le mot «réfrigérateur». A partir du modèle linguistique, on peut découvrir qu'un «réfrigérateur» est un objet matériel, un design, un conteneur de type «boîte ou sac», c'est-à-dire non destiné au stockage de liquides ou de solides sans récipient supplémentaire. De plus, il ne ressort pas clairement de ce modèle que le «réfrigérateur» est une marchandise, en outre, un produit durable, et il n'est pas non plus clair qu'il s'agit d'un artefact, c'est-à-dire objet fabriqué par l'homme. Il s'agit d'informations non linguistiques, qui doivent être fournies séparément.
Le résultat du modèle pour le mot "réfrigérateur" Pourquoi tout cela est nécessaire
Quoi qu'il en soit, dans le processus d'apprentissage et de connaissance de la réalité, une personne enfile des informations supplémentaires sur les objets et les phénomènes qui l'entourent sur le cadre naturel, qu'elle a appris dans l'enfance. Cependant, certains concepts sont universels, indépendants du domaine et peuvent être réutilisés avec succès.
Disons que "vendeur" est une
personne + un
rôle fonctionnel . Dans certains cas, le vendeur peut être un groupe de personnes ou une organisation, mais la subjectivité est toujours préservée: sinon, l'action cible ne sera pas possible. Les mots "échange" ou "formation" se réfèrent à des actions, c'est-à-dire ils ont des participants, la durée et le résultat. Le contenu exact de ces actions peut varier considérablement en fonction de la situation et du domaine, mais certains aspects seront invariants. Il s'agit du cadre de langage sur lequel les connaissances extralinguistiques variables sont superposées.
Notre objectif est de trouver et d'explorer le maximum d'informations intralinguistiques disponibles et de construire sur sa base un modèle explicatif de langage. Cela améliorera les algorithmes existants pour le traitement automatique de texte, y compris des problèmes aussi complexes que la résolution d'ambiguïtés lexicales, la résolution d'anaphores, des cas compliqués de marquage morphologique. Dans le processus, nous nous appuierons nécessairement quelque part contre la nécessité d'attirer des connaissances extra-linguistiques, mais au moins nous saurons où va la frontière lorsque les connaissances internes de la langue ne seront plus suffisantes.
Classification et formation, ensemble d'attributs
Pour le moment, nous ne travaillons qu'avec des noms, donc ci-dessous, lorsque nous disons «mot», nous entendrons des signes qui ne concernent que cette partie du discours. Puisque nous avons décidé de n'utiliser que des informations intralinguistiques, nous travaillerons avec des textes équipés d'un balisage morphologique.
Comme signes, nous prenons tous les microcontextes possibles dans lesquels ce mot apparaît. Pour les noms, ce seront:
- APP + X (beau X: yeux)
- GLAG + X (vdite X: filetage)
- VL + PRED + X (entrez X: porte)
- X + SUSCH_ROD (X: bord de la table)
- SUSHCH + X_ROD (poignée X: sabres)
- X_ SUBJECT + GL (X: l'intrigue se développe)
Il existe plus de types de microcontextes, mais ceux-ci sont les plus fréquents et donnent déjà un bon résultat lors de l'apprentissage.
Tous les microcontextes sont réduits à la forme de base et nous en composons un ensemble de fonctionnalités. Ensuite, pour chaque mot, nous composons un vecteur dont la
i-ème coordonnée sera corrélée avec l'occurrence d'un mot donné dans le
i-ème microcontexte.
Tableau de microcontexte pour le mot "sac à dos" | | | | | | | | | VBP_ | 3043 | 1.0000 | | ADJ | 2426 | 0.9717 | | NX_NG | 1438 | 0.9065 | | VBP_ | 1415 | 0.9045 | | VBP__ | 1300 | 0.8940 | | NX_NG | 1292 | 0.8932 | | NX_NG | 1259 | 0.8900 | | ADJ | 1230 | 0.8871 | | ADJ | 1116 | 0.8749 | | ADJ | 903 | 0.8485 | | ADJ | 849 | 0.8408 | | NX_NG | 814 | 0.8356 | | ADJ | 795 | 0.8326 | | ADJ | 794 | 0.8325 | | VBP_ | 728 | 0.8217 | | ADJ | 587 | 0.7948 | | ADJ | 587 | 0.7948 | | VBP__ | 567 | 0.7905 | | VBP_ | 549 | 0.7865 | | VBP__ | 538 | 0.7840 | | VBP_ | 495 | 0.7736 | | VBP_ | 484 | 0.7708 | | NX_NG | 476 | 0.7687 | | ADJ | 463 | 0.7652 | | NX_NG | 459 | 0.7642 |
Valeur cible, hiérarchie de découpage sémantique
La langue a des mécanismes naturels pour la réutilisation des mots, ce qui provoque l'apparition d'un phénomène tel que la polysémie. De plus, parfois non seulement des mots individuels sont réutilisés, mais un transfert métaphorique de concepts entiers est effectué. Cela est particulièrement visible dans la transition des concepts matériels aux concepts abstraits.
Ce fait dicte la nécessité d'une classification hiérarchique, dans laquelle les sections sémantiques sont organisées dans une structure arborescente et la partition se produit dans chaque nœud interne. Cela vous permet de gérer plus efficacement l'ambiguïté dans les microcontextes.
Exemples de transfert de concept métaphoriqueEn plus de résoudre des problèmes pratiques pressants de la linguistique informatique, notre travail vise à étudier le mot et divers phénomènes linguistiques. Le transfert métaphorique de concepts du plan réel à l'abstrait est un phénomène bien connu des linguistes cognitifs. Ainsi, par exemple, l'un des concepts les plus brillants du monde matériel est la classe «conteneur» (souvent appelée «conteneur» dans la littérature en langue russe).
Une autre métaphore ontologique omniprésente est la métaphore du conteneur, ou conteneur, qui implique de tracer des limites dans le continuum de notre expérience et de la comprendre à travers des catégories spatiales. Selon les auteurs, la façon dont une personne perçoit le monde qui l'entoure est déterminée par son expérience de la manipulation d'objets matériels discrets et, en particulier, sa perception de lui-même, de son corps. L'homme est une créature délimitée du reste du monde par la peau. Il est un conteneur, et donc il est courant pour lui de percevoir d'autres entités comme des conteneurs avec une partie intérieure et une surface extérieure.
Skrebtsova T. G. Linguistique cognitive: théories classiques, nouvelle
approches
Le modèle que nous avons construit fonctionne dans un seul espace d'attributs et nous permet d'apprendre à partir d'exemples réels et de faire des prédictions dans le domaine de l'abstrait. Cela vous permet d'effectuer le transfert décrit ci-dessus. Ainsi, par exemple, les mots suivants sont des conteneurs abstraits, ce qui est cohérent avec l'idée intuitive:

Un autre exemple intéressant est le transfert du concept de "liquide" dans la sphère de l'immatériel:
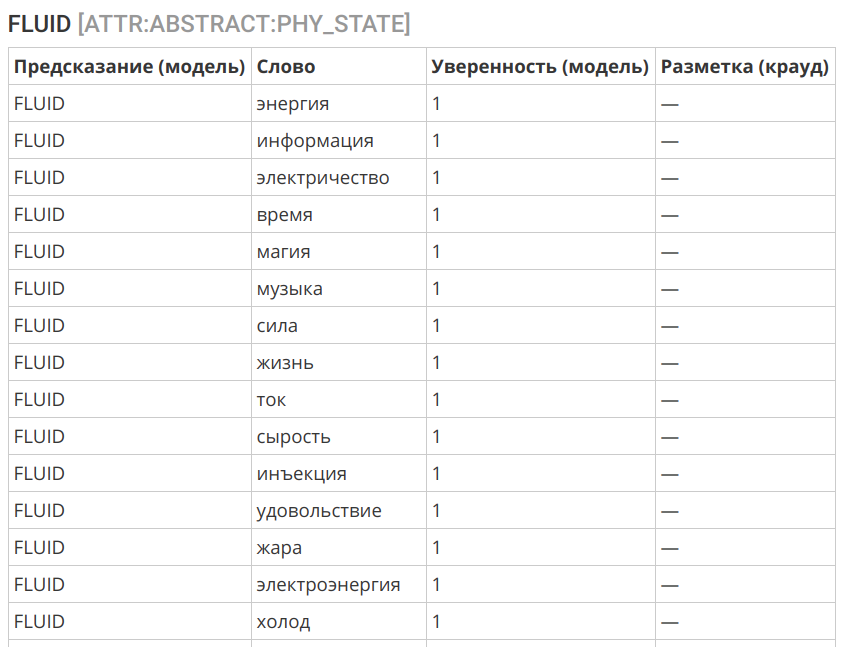
Sélection d'algorithme
Comme algorithme, nous avons utilisé la régression logistique. Cela est dû à plusieurs facteurs:
- D'une manière ou d'une autre, le balisage initial contient une certaine quantité d'erreurs et de bruit.
- Les signes peuvent être déséquilibrés et contenir également des erreurs - polysémie et utilisation métaphorique (figurative) du mot.
- Une analyse préliminaire suggère qu'une interface correctement sélectionnée devrait être corrigée avec un algorithme assez simple.
- Une bonne interprétabilité de l'algorithme est importante.
L'algorithme a montré une assez bonne précision:
Journaux de l'algorithme de balisage == ENTITY == slice | label | count | correctCount | accuracy | | | | | | ENTITY | PHYSICAL | 12249 | 11777 | 0.9615 | ENTITY | ABSTRACT | 9854 | 9298 | 0.9436 | | | | | | | | | | 0.9535 | == PHYSICAL:ROLE == slice | label | count | correctCount | accuracy | | | | | | PHYSICAL:ROLE | ORGANIC | 7001 | 6525 | 0.9320 | PHYSICAL:ROLE | INORGANIC | 3805 | 3496 | 0.9188 | | | | | | | | | | 0.9274 | == PHYSICAL:ORGANIC:ROLE == slice | label | count | correctCount | accuracy | | | | | | PHYSICAL:ORGANIC:ROLE | HUMAN | 4879 | 4759 | 0.9754 | PHYSICAL:ORGANIC:ROLE | ANIMAL | 675 | 629 | 0.9319 | PHYSICAL:ORGANIC:ROLE | FOOD | 488 | 411 | 0.8422 | PHYSICAL:ORGANIC:ROLE | ANATOMY | 190 | 154 | 0.8105 | PHYSICAL:ORGANIC:ROLE | PLANT | 285 | 221 | 0.7754 | | | | | | | | | | 0.9474 | == PHYSICAL:INORGANIC:ROLE == slice | label | count | correctCount | accuracy | | | | | | PHYSICAL:INORGANIC:ROLE | CONSTRUCTION | 1045 | 933 | 0.8928 | PHYSICAL:INORGANIC:ROLE | THING | 2385 | 2123 | 0.8901 | PHYSICAL:INORGANIC:ROLE | SUBSTANCE | 399 | 336 | 0.8421 | | | | | | | | | | 0.8859 | == PHYSICAL:CONSTRUCTION:ROLE == slice | label | count | correctCount | accuracy | | | | | | PHYSICAL:CONSTRUCTION:ROLE | TRANSPORT | 188 | 178 | 0.9468 | PHYSICAL:CONSTRUCTION:ROLE | APARTMENT | 270 | 241 | 0.8926 | PHYSICAL:CONSTRUCTION:ROLE | TERRAIN | 285 | 253 | 0.8877 | | | | | | | | | | 0.9044 | == PHYSICAL:THING:ROLE == slice | label | count | correctCount | accuracy | | | | | | PHYSICAL:THING:ROLE | WEARABLE | 386 | 357 | 0.9249 | PHYSICAL:THING:ROLE | TOOLS | 792 | 701 | 0.8851 | PHYSICAL:THING:ROLE | DISHES | 199 | 174 | 0.8744 | PHYSICAL:THING:ROLE | MUSIC_INSTRUMENTS | 63 | 51 | 0.8095 | PHYSICAL:THING:ROLE | WEAPONS | 107 | 69 | 0.6449 | | | | | | | | | | 0.8739 | == PHYSICAL:TOOLS:ROLE == slice | label | count | correctCount | accuracy | | | | | | PHYSICAL:TOOLS:ROLE | PHY_INTERACTION | 213 | 190 | 0.8920 | PHYSICAL:TOOLS:ROLE | INFORMATION | 101 | 71 | 0.7030 | PHYSICAL:TOOLS:ROLE | EM_ENERGY | 72 | 49 | 0.6806 | | | | | | | | | | 0.8031 | == ATTR:INORGANIC:WEARABLE == slice | label | count | correctCount | accuracy | | | | | | ATTR:INORGANIC:WEARABLE | NON_WEARABLE | 538 | 526 | 0.9777 | ATTR:INORGANIC:WEARABLE | WEARABLE | 282 | 269 | 0.9539 | | | | | | | | | | 0.9695 | == ATTR:PHYSICAL:CONTAINER == slice | label | count | correctCount | accuracy | | | | | | ATTR:PHYSICAL:CONTAINER | CONTAINER | 636 | 627 | 0.9858 | ATTR:PHYSICAL:CONTAINER | NOT_A_CONTAINER | 1225 | 1116 | 0.9110 | | | | | | | | | | 0.9366 | == ATTR:PHYSICAL:CONTAINER:TYPE == slice | label | count | correctCount | accuracy | | | | | | ATTR:PHYSICAL:CONTAINER:TYPE | CONFINED_SPACE | 291 | 287 | 0.9863 | ATTR:PHYSICAL:CONTAINER:TYPE | CONTAINER | 140 | 131 | 0.9357 | ATTR:PHYSICAL:CONTAINER:TYPE | OPEN_AIR | 72 | 64 | 0.8889 | ATTR:PHYSICAL:CONTAINER:TYPE | BAG_OR_BOX | 43 | 31 | 0.7209 | ATTR:PHYSICAL:CONTAINER:TYPE | CAVITY | 30 | 20 | 0.6667 | | | | | | | | | | 0.9253 | == ATTR:PHYSICAL:PHY_STATE == slice | label | count | correctCount | accuracy | | | | | | ATTR:PHYSICAL:PHY_STATE | SOLID | 308 | 274 | 0.8896 | ATTR:PHYSICAL:PHY_STATE | FLUID | 250 | 213 | 0.8520 | ATTR:PHYSICAL:PHY_STATE | FABRIC | 72 | 51 | 0.7083 | ATTR:PHYSICAL:PHY_STATE | PLASTIC | 78 | 42 | 0.5385 | ATTR:PHYSICAL:PHY_STATE | SAND | 70 | 31 | 0.4429 | | | | | | | | | | 0.7853 | == ATTR:PHYSICAL:PLACE == slice | label | count | correctCount | accuracy | | | | | | ATTR:PHYSICAL:PLACE | NOT_A_PLACE | 855 | 821 | 0.9602 | ATTR:PHYSICAL:PLACE | PLACE | 954 | 914 | 0.9581 | | | | | | | | | | 0.9591 | == ABSTRACT:ROLE == slice | label | count | correctCount | accuracy | | | | | | ABSTRACT:ROLE | ACTION | 1497 | 1330 | 0.8884 | ABSTRACT:ROLE | HUMAN | 473 | 327 | 0.6913 | ABSTRACT:ROLE | PHYSICS | 257 | 171 | 0.6654 | ABSTRACT:ROLE | INFORMATION | 222 | 146 | 0.6577 | ABSTRACT:ROLE | ABSTRACT | 70 | 15 | 0.2143 | | | | | | | | | | 0.7896 |
Analyse des erreurs
Les erreurs résultant de la classification automatique sont causées par trois facteurs principaux:
- Homonymie et polysémie: les mots de même type peuvent avoir des sens différents (tourmenter a et m u ka, s'arrêter comme processus et s'arrêter comme lieu ). Cela peut également inclure l'utilisation métaphorique des mots et la métonymie (par exemple, une porte sera classée comme un espace fermé - c'est une caractéristique attendue de la langue).
- Déséquilibre dans le contexte de l'utilisation du mot. Certaines utilisations biologiques peuvent ne pas être disponibles dans l'emballage d'origine, ce qui entraîne des erreurs de classification.
- Limite de classe non valide. Vous pouvez tracer des frontières qui ne sont pas calculables à partir de contextes et nécessitent l'implication de connaissances extra-linguistiques. Ici, l'algorithme sera impuissant.
À ce stade, nous ne prêtons attention qu'aux erreurs du troisième type et ajustons la limite sélectionnée entre les classes. Les erreurs des deux premiers types dans une configuration donnée du système ne peuvent pas être éliminées, mais avec une quantité suffisante de données étiquetées, elles ne représentent pas un gros problème - cela peut être vu à partir de la précision du balisage des projections supérieures.
Et ensuite
À l'heure actuelle, l'ensemble de données couvre la plupart des noms existant dans la langue russe et représentés dans le corpus dans une variété suffisante de contextes. L'accent a été mis sur les objets matériels - comme les plus compréhensibles et élaborés dans les travaux scientifiques. Les tâches restent à affiner le balisage existant, en tenant compte des données reçues de l'algorithme, et à travailler avec les classes des niveaux inférieurs, où une diminution de la précision de la prédiction est observée, en raison du flou des frontières entre les catégories.
Mais c'est une sorte de travail de routine, qui est toujours là. Une couche de recherche qualitativement nouvelle concernera la possibilité de classer un mot particulier dans un contexte ou une phrase spécifique, ce qui permettra de prendre en compte les phénomènes d'homonymie et de polysémie, y compris la métaphore (significations figuratives).
De plus, nous travaillons actuellement sur plusieurs projets connexes:
- dictionnaire de reconnaissance des mots RY: une variation du dictionnaire de fréquence, où la compréhensibilité et la familiarité du mot sont évaluées à la suite du balisage du crowdsourcing, et non calculées en fonction du corps des textes.
- corps ouvert pour résoudre l'ambiguïté lexicale: sur la base du concours RUSSE 2018 WSI & D Shared Task organisé dans le cadre de la conférence Dialogue 2018 , l'utilité du corpus avec ambiguïté lexicale supprimée pour tester des algorithmes automatiques de désambiguïsation et de regroupement des significations de mots est devenue claire. Nous aurons également besoin de cet organe pour passer à l'étape des travaux sur la sémantique ouverte décrits dans le paragraphe précédent.
Dictionnaire tonal de la langue russe
Le dictionnaire tonal est les mots et les expressions du JO, marqués par la tonalité et la force de la gravité de la charge émotionnelle-évaluative. Autrement dit, combien un mot particulier est «mauvais» ou «bon».
Actuellement, 67,392 caractères sont marqués (dont 55,532 mots et 11,860 expressions).
Rétroaction et distribution
Nous apprécions tout commentaire dans les commentaires - de la critique du travail et de nos approches de liens vers des études intéressantes et des articles connexes.
Si vous avez des connaissances ou des collègues qui pourraient être intéressés par l'ensemble de données publié, envoyez-leur un lien vers l'article ou le référentiel pour aider à diffuser les données ouvertes.
Lien de téléchargement et licence
Jeu de données: sémantique ouverte de la langue russeL'ensemble de données est autorisé sous
CC BY-NC-SA 4.0 .