
Je travaille dans l'équipe de la plateforme Odnoklassniki et aujourd'hui je parlerai des détails d'architecture, de conception et d'implémentation du service de distribution de musique.
L'article est une transcription du rapport du Joker 2018 .
Quelques statistiques
Tout d'abord, quelques mots sur OK. Il s'agit d'un gigantesque service utilisé par plus de 70 millions d'utilisateurs. Ils sont desservis par 7 mille voitures dans 4 centres de données. Récemment, nous avons franchi la barre du trafic à 2 Tb / s sans tenir compte des nombreux sites CDN. Nous tirons le maximum de notre matériel, les services les plus chargés desservent jusqu'à 100 000 requêtes par seconde à partir d'un nœud quadricœur. De plus, presque tous les services sont écrits en Java.
Il existe de nombreuses sections dans OK, l'une des plus populaires est «Musique». Dans ce document, les utilisateurs peuvent télécharger leurs pistes, acheter et télécharger de la musique de qualité différente. La section a un merveilleux catalogue, un système de recommandation, une radio et bien plus encore. Mais le but principal du service, bien sûr, est de jouer de la musique.
Le distributeur de musique est responsable du transfert des données vers les lecteurs utilisateurs et les applications mobiles. Vous pouvez l'attraper dans l'inspecteur Web si vous regardez les demandes au domaine musicd.mycdn.me. L'API du distributeur est extrêmement simple. Il répond aux requêtes HTTP
GET et émet la plage de pistes demandée.
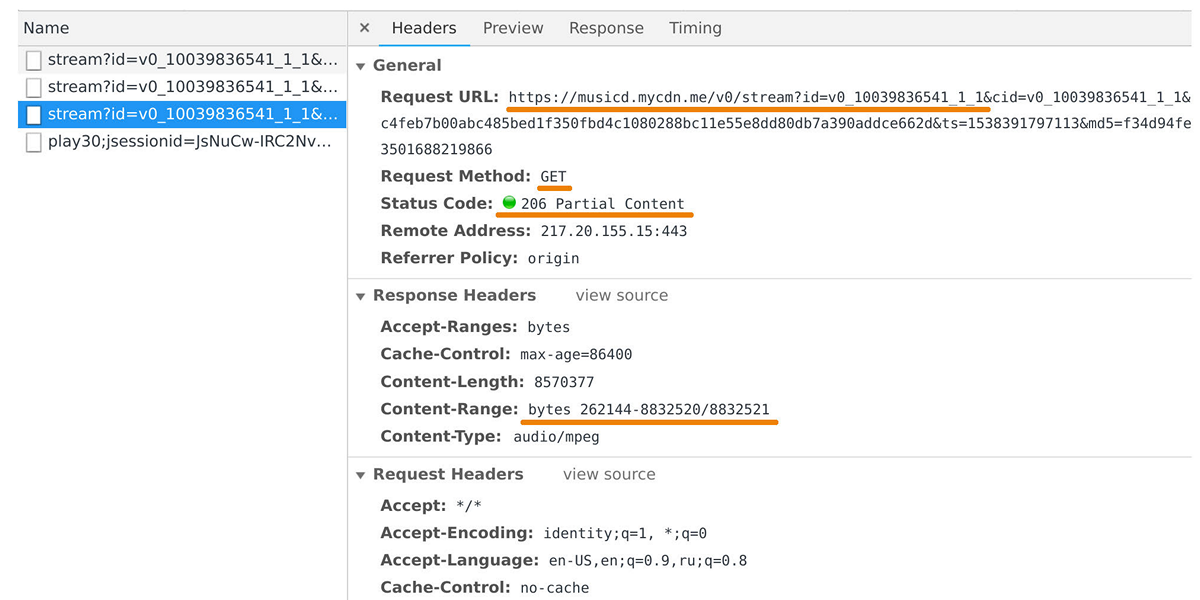
En période de pointe, la charge atteint 100 Gb / s via un demi-million de connexions. En fait, le distributeur de musique est une interface de mise en cache devant notre référentiel de pistes interne, qui est basé sur
One Blob Storage et
One Cold Storage et contient des pétaoctets de données.
Puisque j'ai parlé de mise en cache, regardons les statistiques de lecture. Nous voyons un TOP prononcé.
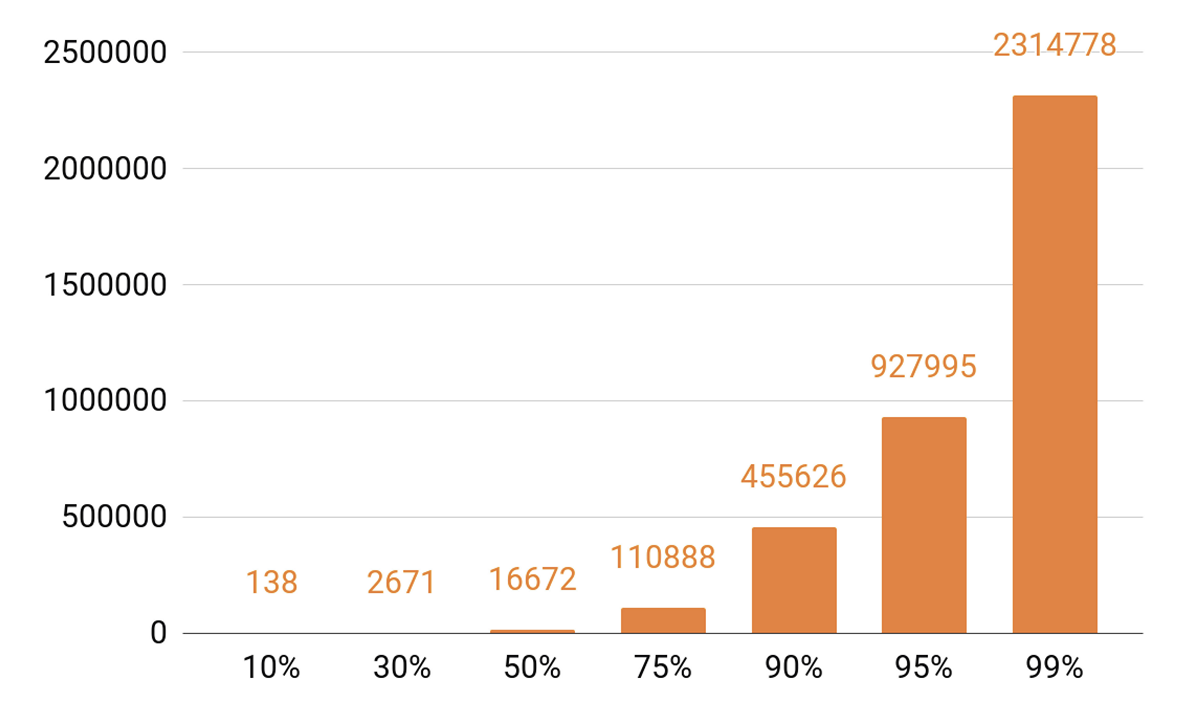
Environ 140 titres couvrent 10% de toutes les pièces par jour. Si nous voulons que notre serveur de cache ait un hit de cache d'au moins 90%, nous avons besoin d'un demi-million de pistes pour y entrer. 95% - près d'un million de pistes.
Exigences du distributeur
Quels objectifs nous sommes-nous fixés lors du développement de la prochaine version du distributeur?
Nous voulions qu'un nœud puisse contenir 100 000 connexions. Et ce sont des connexions client lentes: un tas de navigateurs et d'applications mobiles sur des réseaux à des vitesses variables. Dans le même temps, le service, comme tous nos systèmes, doit être évolutif et tolérant aux pannes.
Tout d'abord, nous devons augmenter la bande passante du cluster afin de suivre la popularité croissante du service et être en mesure de donner de plus en plus de trafic. Il est également nécessaire de pouvoir faire évoluer la capacité totale du cache de cluster, car le cache atteint et le pourcentage de requêtes qui tomberont dans le stockage des pistes en dépendent directement.
Aujourd'hui, il est nécessaire de pouvoir faire évoluer horizontalement tout système distribué, c'est-à-dire ajouter des machines et des centres de données. Mais nous voulions également mettre en œuvre une mise à l'échelle verticale. Notre serveur moderne typique contient 56 cœurs, 0,5 à 1 To de RAM, une interface réseau de 10 ou 40 Go et une douzaine de disques SSD.
En parlant d'évolutivité horizontale, un effet intéressant se produit: lorsque vous avez des milliers de serveurs et des dizaines de milliers de disques, quelque chose se brise constamment. La défaillance du disque est une routine, nous les changeons à 20-30 pièces par semaine. Et les pannes de serveur ne surprennent personne; 2-3 voitures par jour sont remplacées. J'ai également dû faire face à des défaillances de centres de données, par exemple, en 2018, il y a eu trois défaillances de ce type, et ce n'est probablement pas la dernière fois.
Pourquoi suis-je tout ça? Lorsque nous concevons des systèmes, nous savons qu'ils se briseront tôt ou tard. Par conséquent, nous
étudions toujours
attentivement les scénarios de défaillance de tous les composants du système. La principale façon de gérer les défaillances est la réplication des données: plusieurs copies de données sont stockées sur différents nœuds.
Nous réservons également la bande passante du réseau. Ceci est important car si un composant du système tombe en panne, il ne peut pas être autorisé de réduire la charge sur les composants restants.
Équilibrage
Vous devez d'abord apprendre à équilibrer les requêtes des utilisateurs entre les centres de données et à le faire automatiquement. C'est le cas si vous devez effectuer des travaux sur le réseau ou si le centre de données est en panne. Mais l'équilibrage est également nécessaire à l'intérieur des centres de données. Et nous voulons répartir les demandes entre les nœuds non pas au hasard, mais avec des poids. Par exemple, lorsque nous téléchargeons une nouvelle version d'un service et que nous voulons entrer en douceur un nouveau nœud en rotation. Les poids aident également beaucoup lors des tests de résistance: nous augmentons le poids et imposons une charge beaucoup plus lourde au nœud afin de comprendre les limites de ses capacités. Et lorsqu'un nœud tombe en panne sous charge, nous éliminons rapidement le poids et le retirons de la rotation à l'aide de mécanismes d'équilibrage.
À quoi ressemble le chemin de demande de l'utilisateur au nœud, qui renverra les données en tenant compte de l'équilibrage?

L'utilisateur se connecte via le site Internet ou l'application mobile et reçoit l'URL de la piste:
musicd.mycdn.me/v0/stream?id=...Pour obtenir l'adresse IP du nom d'hôte dans l'URL, le client contacte notre DNS GSLB, qui connaît tous nos centres de données et sites CDN. GSLB DNS donne au client l'adresse IP de l'équilibreur de l'un des centres de données et le client établit une connexion avec lui. L'équilibreur connaît tous les nœuds à l'intérieur des centres de données et leur poids. Il établit, au nom de l'utilisateur, une connexion avec l'un des nœuds. Nous
utilisons des équilibreurs L4 basés sur N4Ware . Noda donne directement les données de l'utilisateur, contournant l'équilibreur. Dans des services comme un distributeur, le trafic sortant est nettement supérieur à celui entrant.
Si un centre de données tombe en panne, GSLB DNS le détecte et le supprime rapidement de la rotation: il cesse de donner aux utilisateurs l'adresse IP de l'équilibreur de ce centre de données. Si un nœud du centre de données tombe en panne, son poids est réinitialisé et l'équilibreur à l'intérieur du centre de données cesse de lui envoyer des demandes.
Envisagez maintenant d'équilibrer les pistes par nœuds à l'intérieur d'un centre de données. Nous considérerons les centres de données comme des unités autonomes indépendantes, chacune vivra et travaillera, même si tous les autres sont morts. Les pistes doivent être équilibrées uniformément sur les machines afin qu'il n'y ait pas de distorsions de charge et les répliquer sur différents nœuds. Si un nœud tombe en panne, la charge doit être répartie uniformément entre les autres.
Ce problème peut être
résolu de différentes manières . Nous avons opté pour
un hachage cohérent . Nous enveloppons toute la gamme possible de hachages d'identifiants de piste dans un anneau, puis chaque piste est affichée à un point de cet anneau. Ensuite, nous répartissons plus ou moins uniformément les plages d'anneaux entre les nœuds du cluster. Les nœuds qui stockeront la piste sont sélectionnés en hachant les pistes en un point de l'anneau et en les déplaçant dans le sens horaire.
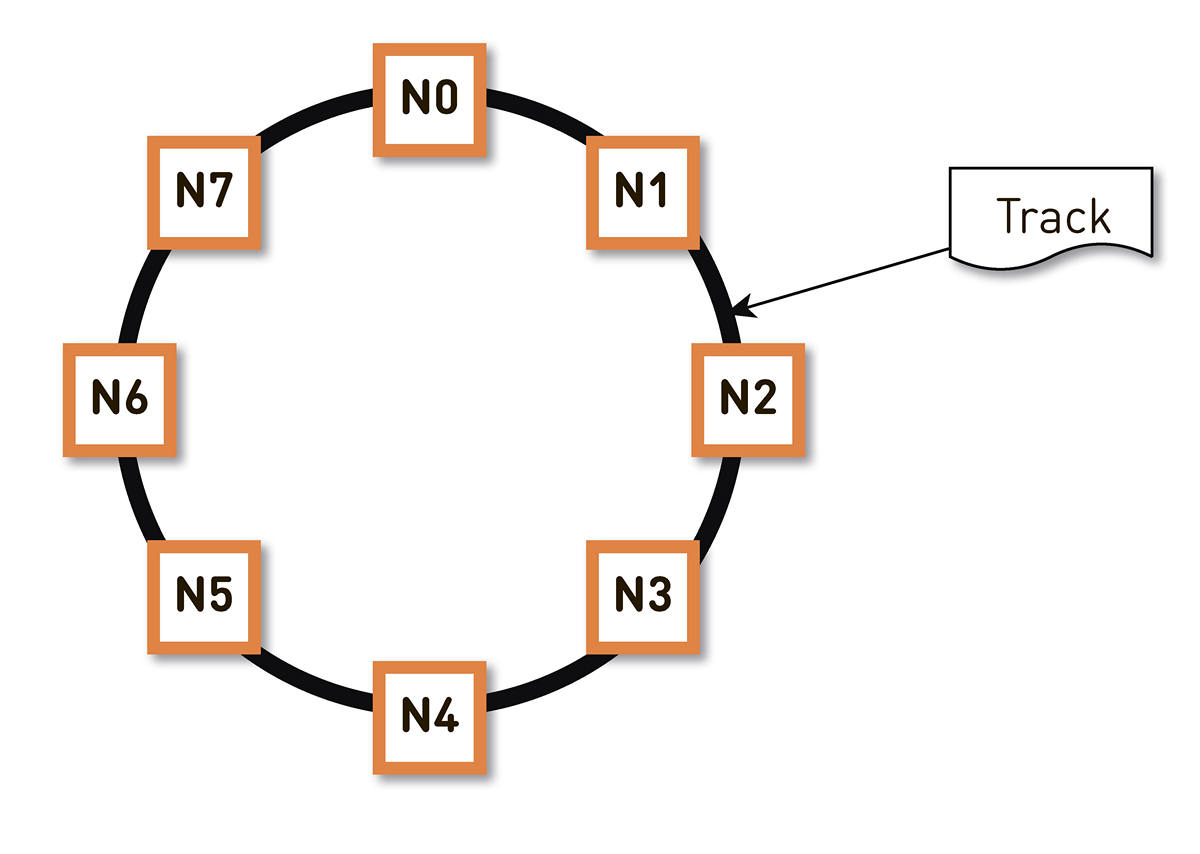
Mais un tel schéma a un inconvénient: en cas de défaillance du nœud N2, par exemple, toute sa charge tombera sur la prochaine réplique de l'anneau - N3. Et s'il n'a pas une double marge de performance - et ce n'est pas économiquement justifié - alors, très probablement, le deuxième nœud aura également un mauvais moment. N3 avec un degré élevé de probabilité se développera, la charge ira à N4, et ainsi de suite - il y aura une défaillance en cascade le long de l'anneau entier.
Ce problème peut être résolu en augmentant le nombre de répliques, mais la capacité utile totale du cluster dans l'anneau diminue. Par conséquent, nous faisons autrement. Avec le même nombre de nœuds, l'anneau est divisé en un nombre significativement plus grand de plages dispersées de manière aléatoire autour de l'anneau. Les répliques de la piste sont sélectionnées selon l'algorithme ci-dessus.

Dans l'exemple ci-dessus, chaque nœud est responsable de deux plages. Si l'un des nœuds tombe en panne, toute sa charge ne reposera pas sur le nœud suivant de l'anneau, mais sera répartie entre les deux autres nœuds du cluster.
L'anneau est calculé sur la base d'un petit ensemble de paramètres de manière algorithmique et est déterminé sur chaque nœud. Autrement dit, nous ne le stockons pas dans une sorte de configuration. Nous avons plus de cent mille de ces gammes en production, et en cas de défaillance de l'un des nœuds, la charge est répartie de manière absolument égale entre tous les autres nœuds vivants.
À quoi ressemble la piste de retour à l'utilisateur dans un tel système avec un hachage cohérent?
L'utilisateur via l'équilibreur L4 accède à un nœud aléatoire. La sélection des nœuds est aléatoire, car l'équilibreur ne sait rien de la topologie. Mais chaque réplique du cluster le sait. Le nœud qui a reçu la demande détermine s'il s'agit d'une réplique de la piste demandée. Sinon, il passe en mode proxy avec l'une des répliques, établit une connexion avec lui et recherche les données dans son stockage local. Si la piste n'est pas là, la réplique la extrait du magasin de pistes, l'enregistre dans le magasin local et donne le proxy, qui redirige les données vers l'utilisateur.
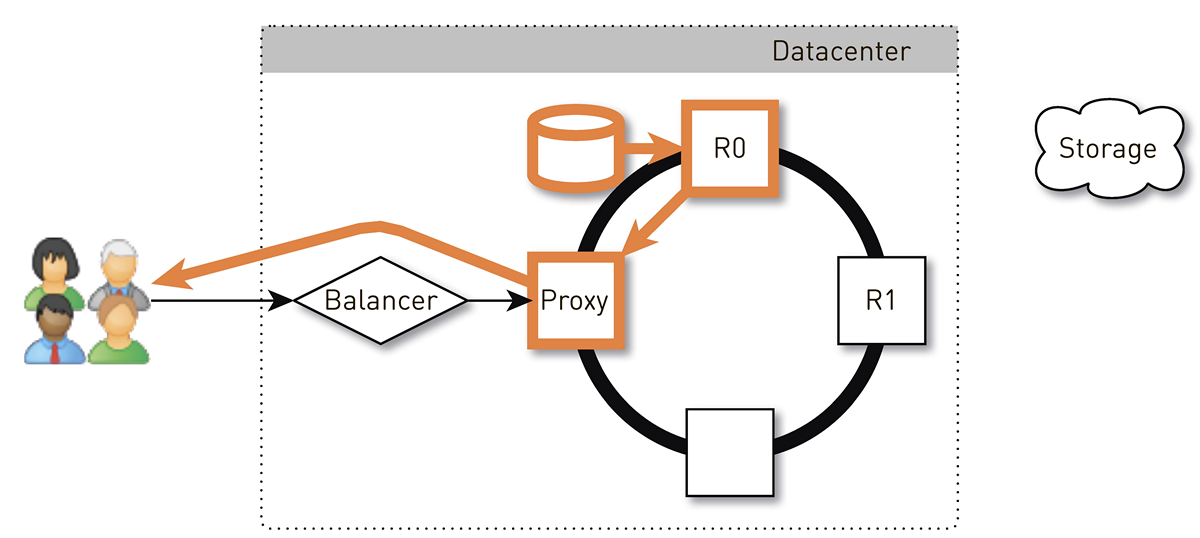
Si le lecteur de la réplique tombe en panne, les données du stockage seront transférées directement à l'utilisateur. Et si la réplique échoue, le proxy connaît toutes les autres répliques de cette piste, il établira une connexion avec une autre réplique en direct et en recevra les données. Nous garantissons donc que si un utilisateur demande une piste et qu'au moins une réplique est vivante, il recevra une réponse.
Comment fonctionne un nœud?
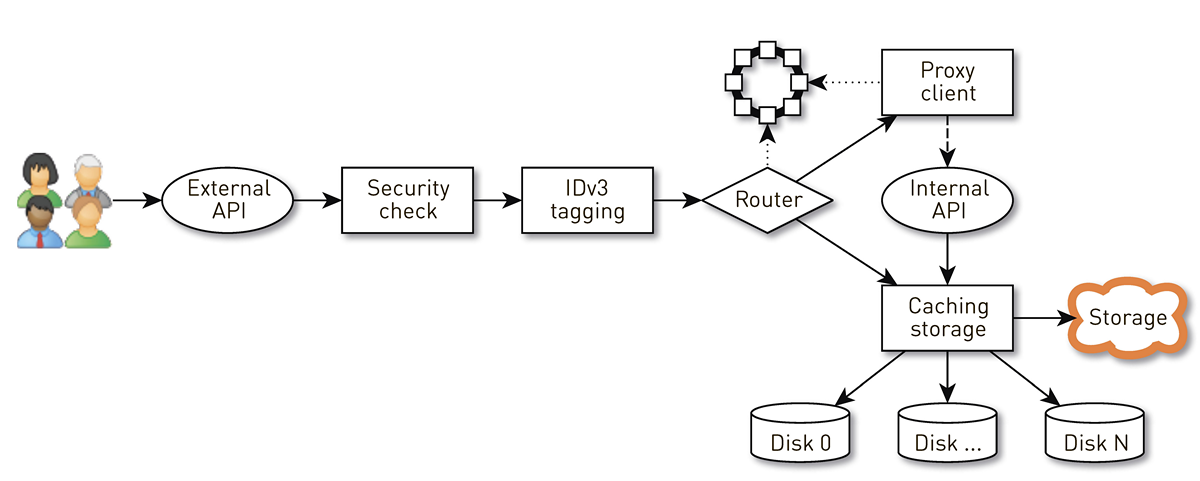
Un nœud est un pipeline à partir d'un ensemble d'étapes par lesquelles passe la demande d'un utilisateur. Tout d'abord, la demande est envoyée à une API externe (nous envoyons tout via HTTPS). Ensuite, la demande est validée - les signatures sont vérifiées. Ensuite, les balises IDv3 sont construites si nécessaire, par exemple, lors de l'achat d'une piste. La demande passe à l'étape de routage, où, sur la base de la topologie du cluster, il est déterminé comment les données seront renvoyées: soit le nœud actuel est une réplique pour cette piste, soit nous procurons un proxy à partir d'un autre nœud. Dans le second cas, le nœud via le client proxy établit une connexion au réplica via l'API HTTP interne sans vérification des signatures. Le réplica recherche les données dans le stockage local, s'il trouve une piste, il les donne à partir de son disque; et si ce n'est pas le cas, il extrait les pistes du stockage, met en cache et donne.
Charge de nœud
Estimons quelle charge un nœud devrait contenir dans cette configuration. Ayons trois centres de données avec quatre nœuds chacun.

L'ensemble du service devrait desservir 120 Gbit / s, soit 40 Gbit / s par centre de données. Supposons que les networkers aient fait des manœuvres ou qu'un accident se soit produit et qu'il reste deux centres de données DC1 et DC3. Maintenant, chacun d'eux devrait donner 60 Gbit / s. Mais ici, c'était aux développeurs de déployer une mise à jour, dans chaque centre de données il restait 3 nœuds actifs et chacun d'entre eux devrait donner 20 Gbit / s.
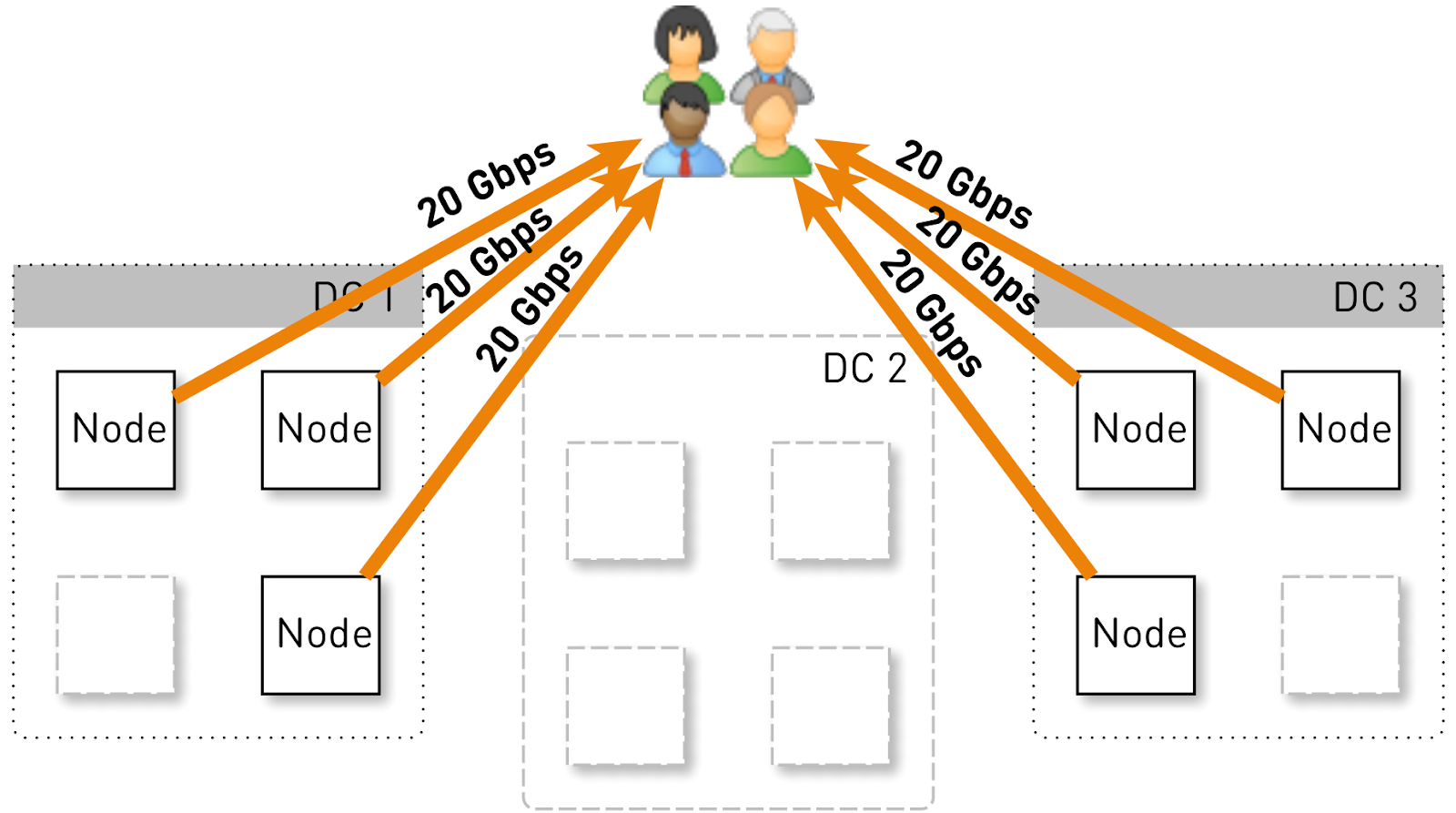
Mais au départ, dans chaque centre de données, il y avait 4 nœuds. Et si nous stockons deux répliques dans le centre de données, alors avec une probabilité de 50%, le nœud qui a reçu la demande ne sera pas une réplique de la piste demandée et proxy les données. Autrement dit, la moitié du trafic à l'intérieur du centre de données est mandatée.
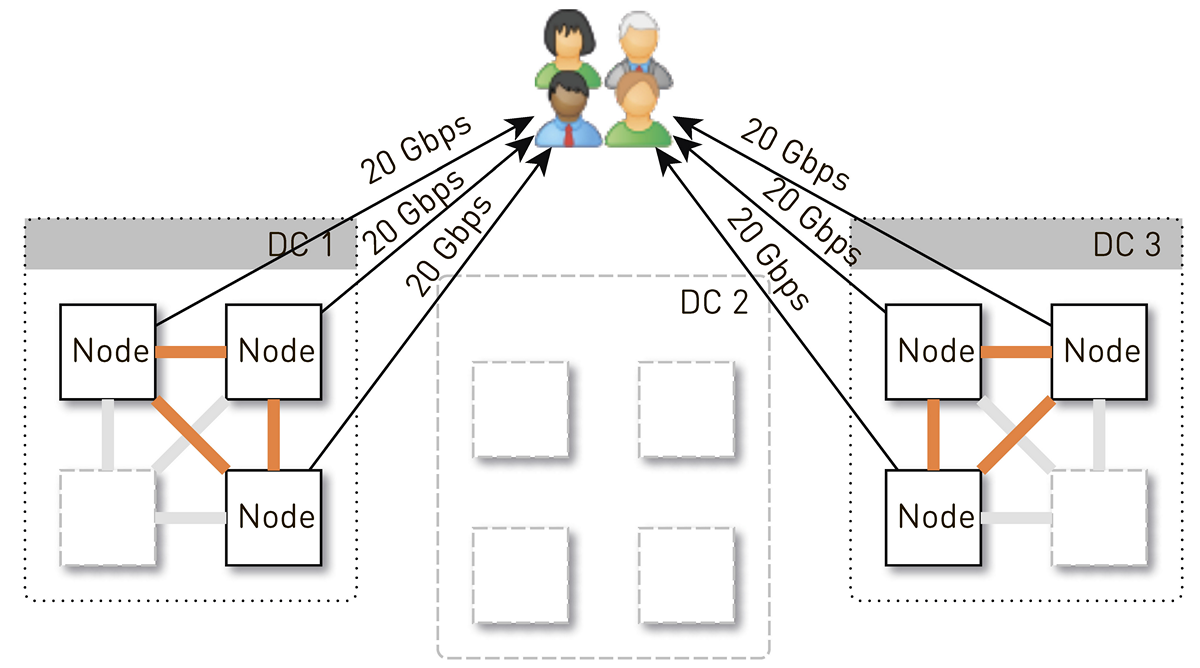
Ainsi, un nœud devrait donner aux utilisateurs 20 Gb / s. Parmi ceux-ci, 10 Gb / s, il tire de ses voisins dans le centre de données. Mais le schéma est symétrique: le nœud donne les mêmes 10 Gb / s aux voisins du centre de données. Il s'avère que 30 Gbit / s sortent du nœud, dont 20 Gbit / s doivent être desservis par lui-même, car il s'agit d'une réplique des données demandées. De plus, les données proviendront soit des disques, soit de la RAM, qui contient environ 50 000 pistes «chaudes». Sur la base de nos statistiques de lecture, cela vous permet de supprimer 60 à 70% de la charge des disques, et restera d'environ 8 Go / s. Ce thread est tout à fait capable de fournir une douzaine de SSD.
Stockage de données sur un nœud
Si vous placez chaque piste dans un fichier séparé, la surcharge de gestion de ces fichiers sera énorme. Même le redémarrage des nœuds et l'analyse des données sur les disques prendront des minutes, voire des dizaines de minutes.
Il existe des limites moins évidentes à ce schéma. Par exemple, vous ne pouvez charger des pistes que depuis le tout début. Et si l'utilisateur a demandé la lecture à partir du milieu et que le cache a été manqué, nous ne pourrons pas envoyer un seul octet tant que nous n'aurons pas chargé les données à l'emplacement souhaité à partir du référentiel de pistes. De plus, nous ne pouvons stocker les morceaux que dans leur ensemble, même si c'est un livre audio géant qu'ils arrêtent d'écouter à la troisième minute. Il continuera à peser lourd sur le disque, à gaspiller de l'espace coûteux et à réduire le nombre de correspondances de cache de ce nœud.
Par conséquent, nous le faisons d'une manière complètement différente: nous divisons les pistes en blocs de 256 Ko, car cela correspond à la taille du bloc dans le SSD, et nous fonctionnons déjà avec ces blocs. Un disque de 1 To contient 4 millions de blocs. Chaque disque d'un nœud est un stockage indépendant et tous les blocs de chaque piste sont répartis sur tous les disques.
Nous ne sommes pas immédiatement arrivés à un tel schéma, au début, tous les blocs d'une piste se trouvaient sur un seul disque. Mais cela a conduit à une forte distorsion de la charge entre les disques, car si une piste populaire atteint l'un des disques, toutes les demandes de données iront à un seul disque. Pour éviter cela, nous avons réparti les blocs de chaque piste sur tous les disques, en équilibrant la charge.
De plus, nous n'oublions pas que nous avons un tas de RAM, mais nous avons décidé de ne pas faire le cache sémantique, car nous avons un merveilleux cache de page sous Linux.
Comment stocker des blocs sur des disques?
Nous avons d'abord décidé d'obtenir un fichier XFS géant de la taille d'un disque et d'y mettre tous les blocs. Puis l'idée est venue de fonctionner directement avec un périphérique bloc. Nous avons implémenté les deux options, les avons comparées et il s'est avéré que lorsque vous travaillez directement avec un périphérique bloc, l'enregistrement est 1,5 fois plus rapide, le temps de réponse est 2-3 fois plus faible, la charge totale du système est 2 fois plus faible.
Index
Mais il ne suffit pas de pouvoir stocker des blocs; vous devez conserver un index des blocs de pistes musicales aux blocs sur le disque.

Il s'est avéré être assez compact, une entrée d'index ne prend que 29 octets. Pour un stockage de 10 To, l'indice est un peu plus de 1 Go.
Il y a un point intéressant ici. Dans chacun de ces enregistrements, vous devez stocker la taille totale de la piste entière. Il s'agit d'un exemple classique de dénormalisation. La raison en est que, selon la spécification de la réponse de plage HTTP, nous devons renvoyer la taille totale de la ressource, ainsi que former un en-tête Content-length. Si ce n'était pas le cas, alors tout serait encore plus compact.
Nous avons formulé un certain nombre d'exigences pour l'index: travailler rapidement (de préférence, stocké dans la RAM), être compact et ne pas prendre de place sur le cache de page. Un autre indice devrait être persistant. Si nous le perdons, nous perdrons des informations sur l'endroit où sur le disque quelle piste est stockée, et cela revient à nettoyer les disques. Et en général, j'aimerais que les anciens blocs, auxquels on n'a pas accédé depuis longtemps, soient en quelque sorte supplantés, laissant la place à des morceaux plus populaires. Nous avons choisi la
politique d'éviction LRU : les blocs sont évincés une fois par minute, 1% des blocs sont libres. Bien sûr, la structure d'index doit être thread-safe, car nous avons 100 000 connexions par nœud. Toutes ces conditions sont idéalement remplies par
SharedMemoryFixedMap de notre bibliothèque open source
one-nio .
On met l'index sur
tmpfs , ça marche vite, mais il y a une nuance. Lorsque la machine redémarre, tout ce qui était sur
tmpfs , y compris l'index, est perdu. De plus, si en raison de la
sun.misc.Unsafe -
sun.misc.Unsafe notre processus s'est écrasé, il n'est pas clair dans quel état l'indice est resté. Par conséquent, nous en faisons une impression une fois par heure. Mais cela ne suffit pas: puisque nous utilisons l'extrusion de blocs, nous devons prendre en charge
WAL , dans lequel nous écrivons des informations sur les blocs extrudés. Les entrées concernant les blocs dans les transtypages et les WAL doivent être triées d'une manière ou d'une autre pendant la récupération. Pour ce faire, nous utilisons le bloc de génération. Il joue le rôle d'un compteur de transactions global et incrémenté à chaque changement d'index. Regardons un exemple de comment cela fonctionne.
Prenez un index avec trois entrées: deux blocs de la piste n ° 1 et un bloc de la piste n ° 2.
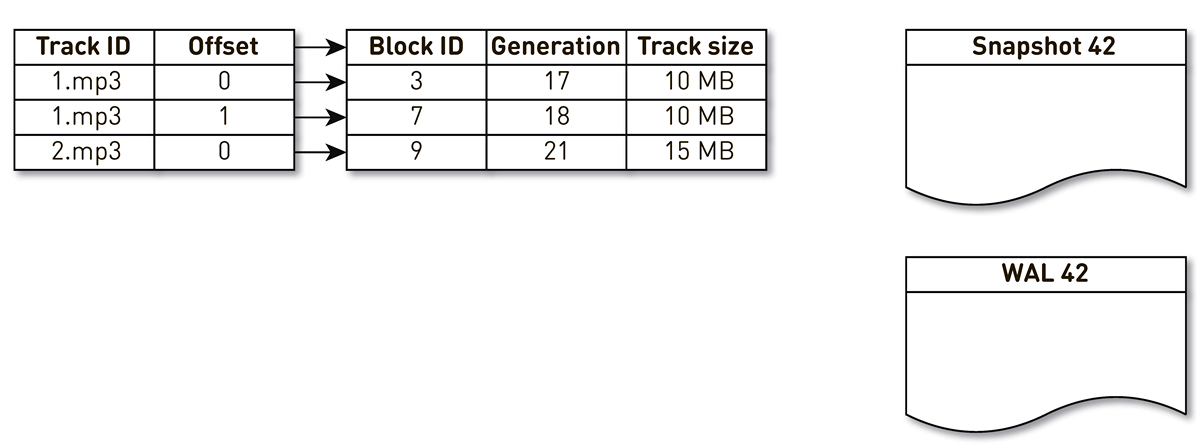
Le flux de création de plâtres est réveillé et itéré par cet index: les premier et second tuples tombent dans le plâtre. Ensuite, le flux d'encombrement se tourne vers l'index, se rend compte que le septième bloc n'a pas été consulté depuis longtemps et décide de l'utiliser pour autre chose. Le processus force le blocage et écrit un enregistrement dans le WAL. Il arrive au bloc 9, voit qu'il n'a pas été contacté depuis longtemps et le marque également comme évincé. Ici, l'utilisateur accède au système et une erreur de cache se produit - une piste est demandée que nous n'avons pas. Nous sauvegardons le bloc de cette piste dans notre référentiel, en écrasant le bloc 9. Dans ce cas, la génération est incrémentée et devient égale à 22. Ensuite, le processus de création d'un moule est activé, qui n'a pas terminé son travail, atteint le dernier enregistrement et l'écrit dans le moule. En conséquence, nous avons deux enregistrements en direct dans l'index, un casting et WAL.
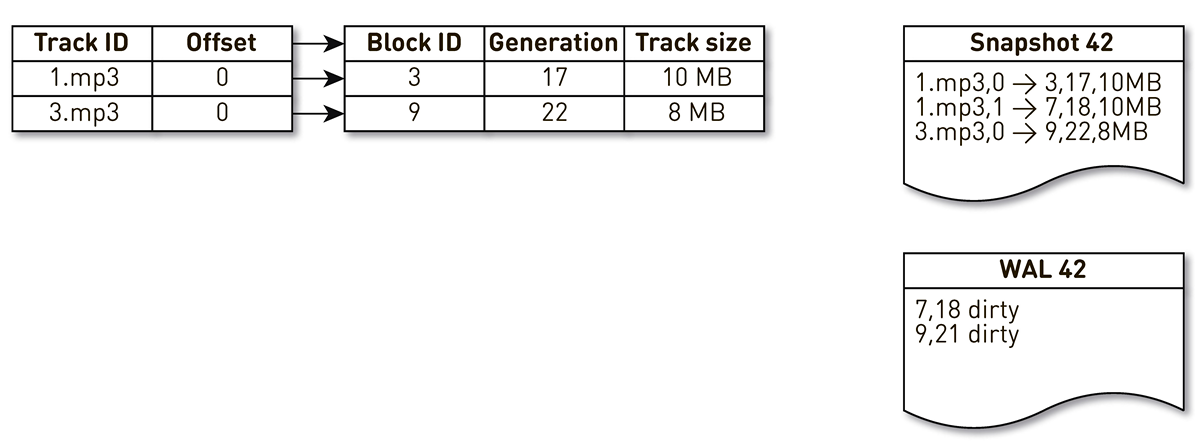
Lorsque le nœud actuel tombe, il restaure l'état initial de l'index comme suit. Tout d'abord, scannez le WAL et créez une carte de bloc sale. La carte stocke le mappage du numéro de bloc à la génération lorsque ce bloc a été remplacé.
Après cela, nous commençons à parcourir le moule en utilisant la carte comme filtre. Nous regardons le premier enregistrement du casting, il concerne le bloc numéro 3. Il n'est pas mentionné parmi les sales, ce qui signifie qu'il est vivant et entre dans l'index. Nous arrivons au bloc numéro 7 avec la dix-huitième génération, mais la carte des blocs sales nous dit que juste à la 18e génération, le bloc était évincé. Par conséquent, il ne tombe pas dans l'index. Nous arrivons au dernier enregistrement, qui décrit le contenu du bloc 9 avec 22 générations. Ce bloc est mentionné dans la carte des blocs sales, mais il a été remplacé plus tôt. Ainsi, il est réutilisé pour de nouvelles données et entre dans l'index. Le but est atteint.
Optimisations
Mais ce n'est pas tout, nous descendons plus profondément.
Commençons par le cache de page. Nous comptions sur lui au départ, mais lorsque nous avons commencé à effectuer des tests de charge de la première version,
il s'est avéré que le taux de réussite du cache de pages n'a pas atteint 20%. Ils ont suggéré que le problème soit lu à l'avance: nous ne stockons pas de fichiers, mais des blocs, tout en servant un tas de connexions, et dans cette configuration, travailler avec le disque est aléatoire de manière efficace. Nous ne lisons presque jamais rien séquentiellement. Heureusement, sous Linux, il existe un appel
posix_fadvise qui vous permet de dire au noyau comment nous allons travailler avec le descripteur de fichier - en particulier, nous pouvons dire que nous n'avons pas besoin de lire à l'avance en passant l'indicateur
POSIX_FADV_RANDOM . Cet appel système est disponible via
one-nio . En fonctionnement, notre hit de cache est de 70 à 80%. Le nombre de lectures physiques à partir des disques a diminué de plus de 2 fois, le délai de réponse HTTP a diminué de 20%.
. heap. TLB- , Huge Pages Java-. (GC Time/Safepoint Total Time 20-30% ), , HTTP latency .
( ) .
. , , , , . , - . , . , , . , Daft Punk №2 sdc, sdd.
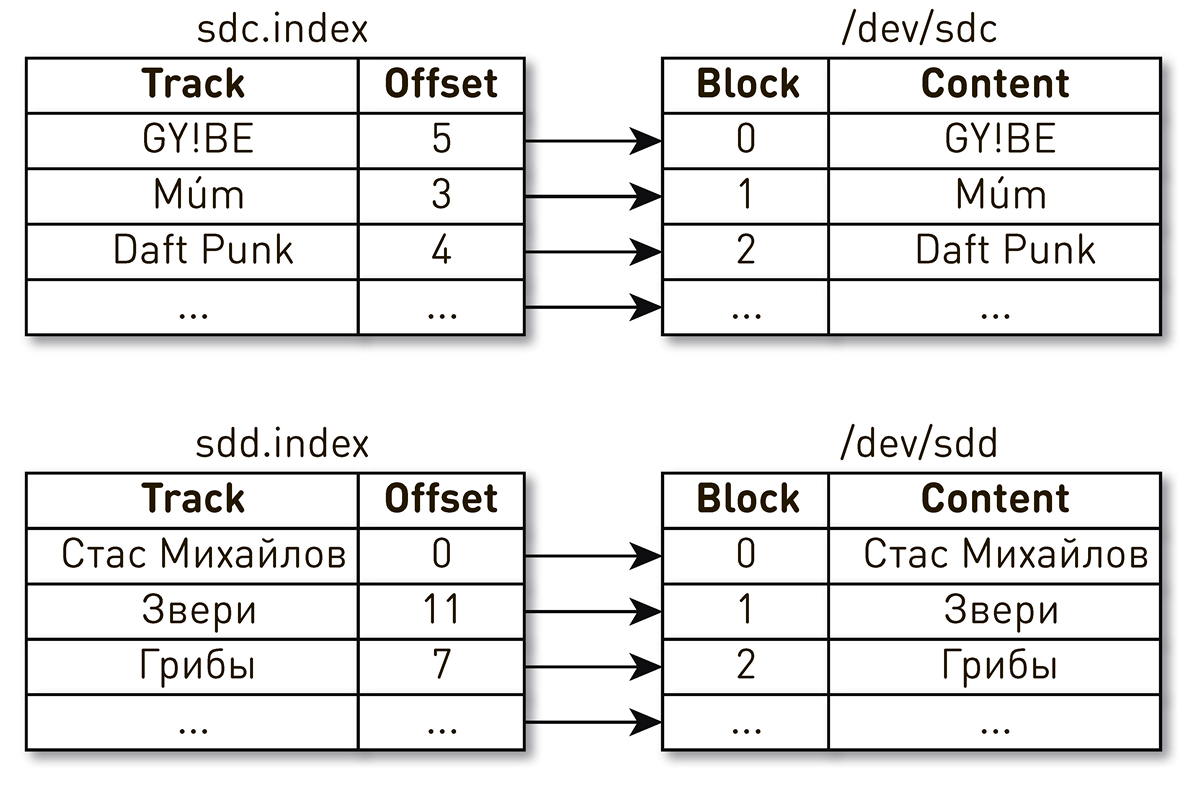
, . Linux
: , .

. ID.
WWN , WAL. , , .
, . CDN , CDN -. . . , , .
.
Open Tracing Zipkin . , . , , HTTP- . , , , , , , .
. , : , , .
ByteBuffer buffer = ByteBuffer.allocate(size); int count = fileChannel.read(buffer, position); if (count <= 0) {
, :
FileChannel.read() kernel space user space;SocketChannel.write() , user space kernel space.
, Linux
sendfile() , , user space. ,
one-nio . ,
sendfile() — 10 /
sendfile() 0.
user-space SSL-
sendfile() , . .
SocketChannel FileChannel ,
Async Profiler ,
sun.nio.ch.IOUtil ,
read() write() . .
ByteBuffer bb = Util.getTemporaryDirectBuffer(dst.remaining()); try { int n = readIntoNativeBuffer(fd, bb, position, nd); bb.flip(); if (n > 0) dst.put(bb); return n; } finally { Util.offerFirstTemporaryDirectBuffer(bb); }
. heap
ByteBuffer , , , heap
ByteBuffer , . .
.
one-nio .
MallocMT — , . SSL , Java heap,
ByteBuffer ,
FileChannel . .
final Allocator allocator = new MallocMT(size, concurrency); int write(Socket socket) { if (socket.getSslContext() != null) { long address = allocator.malloc(size); ByteBuffer buf = DirectMemory.wrap(address, size); int available = channel.read(buf, offset); socket.writeRaw(address, available, flags);
100 000
. . 100 . . ?
, — . , . , . .
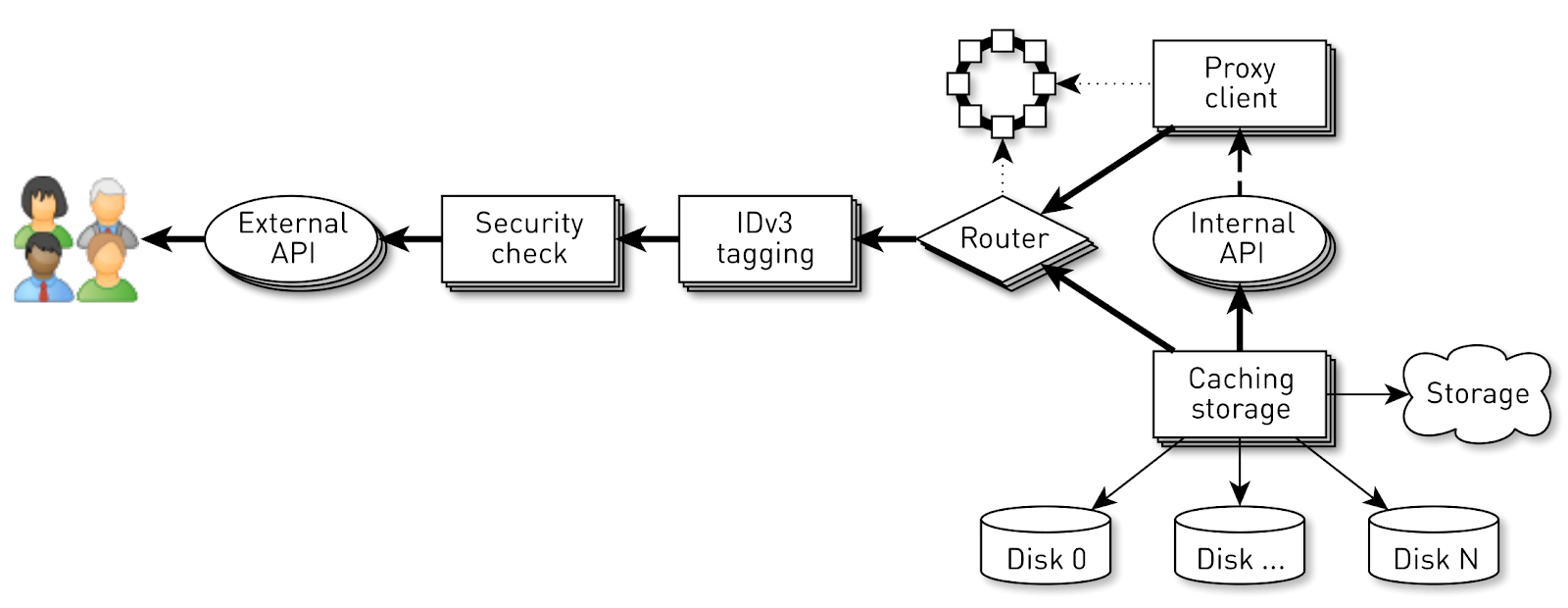
, , . , . . , , . .
. . , , .. . . , , . , . back pressure.
. , subscriber publisher demand. Demand , subscriber demand, . Publisher , demand .
push pull. push subscriber , publisher, publisher demand subscriber, . , subscriber-. pull , publisher , subscriber. publisher , demand . subscriber , , publisher demand.
. publisher subscriber .
.
Publisher Subscriber , :
interface Publisher<T> { void subscribe(Subscriber<? super T> s); } interface Subscriber<T> { void onSubscribe(Subscription s); void onNext(T t); void onError(Throwable t); void onComplete(); } interface Subscription { void request(long n); void cancel(); }
Subscription demand . Nulle part est plus facile.
, , chunk. , heap , . Chunk — ,
ByteBuffer , .
interface Chunk { int read(ByteBuffer dst); int write(Socket socket); void write(FileChannel channel, long offset); }
:
- , cache hit ,
RandomAccessFile . , . , sendfile() . . - cache miss : . , — , , — .
- , - heap.
ByteBuffer .
API, , . Typed Actor Model,
. , , , . .
, .. publisher subscriber , , executor, .
AtomicBoolean happens before .
:
@Override void request(final long n) { enqueue(new Request(n)); } void enqueue(final M message) { mailbox.offer(message); tryScheduleToExecute(); }
tryScheduleToExecute() :
if (on.compareAndSet(false, true)) { try { executor.execute(this); } catch (Exception e) { ... } }
run() :
if (on.get()) try { dequeueAndProcess(); } finally { on.set(false); if (!messages.isEmpty()) { tryScheduleToExecute(); } } }
dequeueAndProcess() :
M message; while ((message = mailbox.poll()) != null) {
. ,
volatile ,
Atomic* , contention . 100 000 200 .
En fin de compte
production 12 , . 10 / . . Java
one-nio .
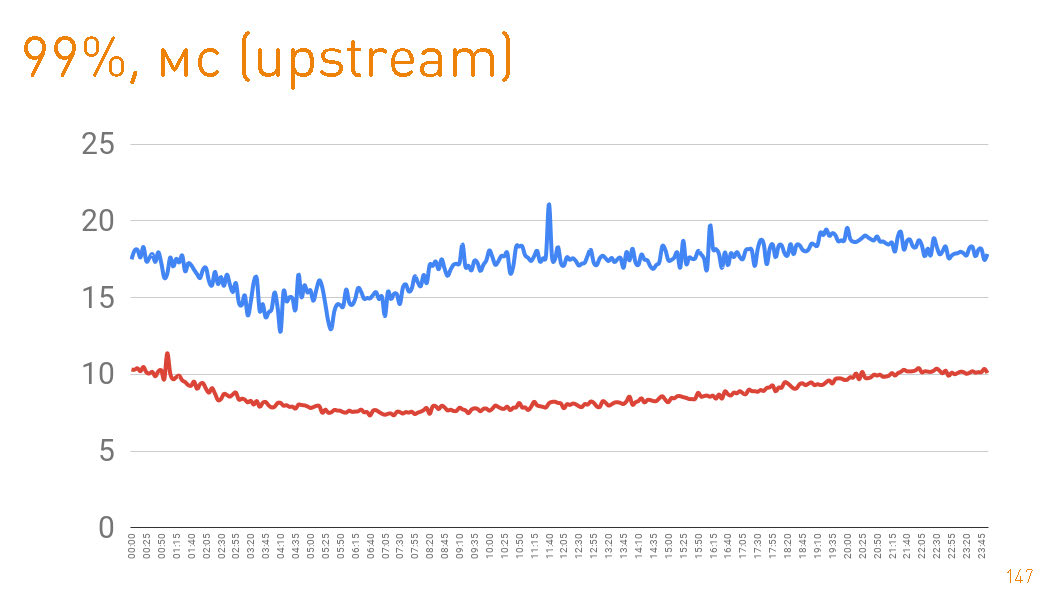
, . 99- 20 . — HTTPS-. —
sendfile() HTTP.
cache hit production 97%, latency , , , .
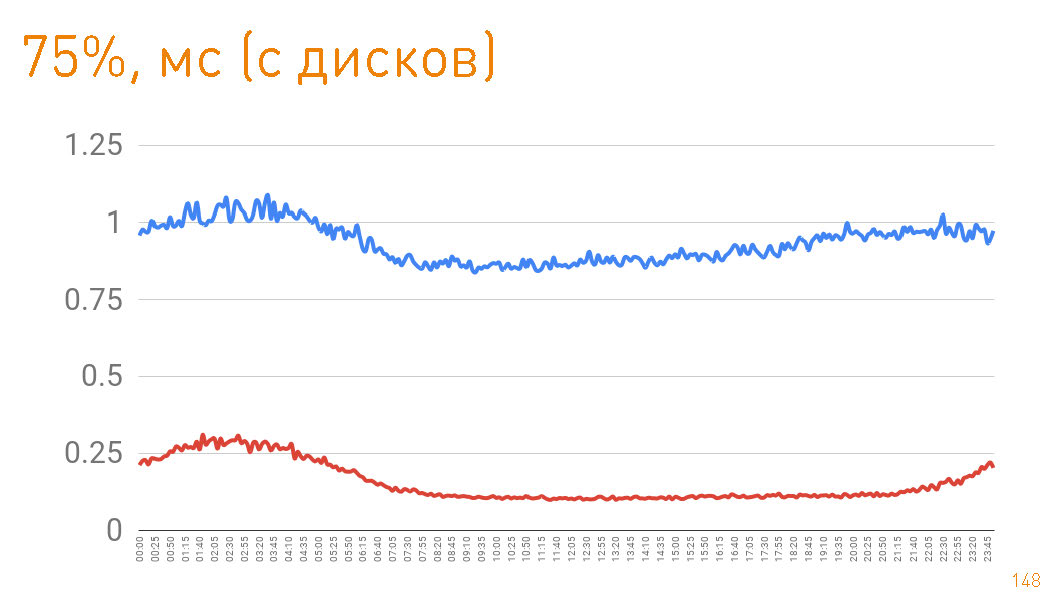
75- , 1 . — 300 . C'est-à-dire 0.7 — .
, , , . , .