Récemment, nous
avons expliqué comment obtenir un stage chez Google. En plus de Google, nos étudiants s'essaient à JetBrains, Yandex, Acronis et à d'autres entreprises.
Dans cet article, je vais partager mon expérience de stage chez
JetBrains Research , parler des tâches qu'ils y résolvent et m'attarder sur la façon dont l'apprentissage automatique peut rechercher des bogues dans le code du programme.

À propos de moi
Je m'appelle Yegor Bogomolov, je suis un étudiant de 4e année du diplôme de premier cycle HSE de Saint-Pétersbourg en mathématiques appliquées et en informatique. Pendant les 3 premières années, comme mes camarades de classe, j'ai étudié à l'Université académique et depuis septembre, nous avons déménagé à l'École supérieure d'économie avec tout le département.
Après la 2e année, j'ai effectué un stage d'été chez Google Zurich. Là, j'ai passé trois mois à travailler dans l'équipe Android Calendar, la plupart du temps à faire du frontend'om et un peu de recherche UX. La partie la plus intéressante de mon travail était la recherche sur l'apparence future des interfaces de calendrier. Il s'est avéré agréable que presque tout le travail que j'ai fait à la fin du stage se soit retrouvé dans la version principale de l'application. Mais le sujet des stages chez Google est très bien traité dans un article précédent, je vais donc parler de ce que j'ai fait cet été.
Qu'est-ce que JB Research?
JetBrains Research est un ensemble de laboratoires travaillant dans divers domaines: langages de programmation, mathématiques appliquées, apprentissage automatique, robotique et autres. Dans chaque domaine, il existe plusieurs groupes scientifiques. Grâce à ma direction, je connais le mieux les activités des groupes dans le domaine de l'apprentissage automatique. Chacun d'eux organise des séminaires hebdomadaires au cours desquels des membres du groupe ou des invités invitent à parler de leur travail ou d'articles intéressants dans leur domaine. De nombreux étudiants du HSE viennent à ces séminaires, car ils traversent la route du bâtiment principal du campus HSE à Saint-Pétersbourg.
Dans notre programme de licence, nous sommes obligatoirement engagés dans des travaux de recherche (R&D) et présentons les résultats de la recherche deux fois par an. Souvent, ce travail se transforme progressivement en stages d'été. C'est ce qui est arrivé avec mon travail de recherche: cet été, j'ai effectué un stage au laboratoire "Méthodes d'Apprentissage Machine en Génie Logiciel" avec mon superviseur Timofey Bryksin. Les tâches en cours dans ce laboratoire comprennent des suggestions de refactorisation automatique, l'analyse du style de code pour les programmeurs, l'achèvement du code et la recherche d'erreurs dans le code du programme.
Mon stage a duré deux mois (juillet et août), et à l'automne j'ai continué à m'engager dans des tâches assignées dans le cadre de la recherche. J'ai travaillé dans plusieurs domaines, le plus intéressant d'entre eux, à mon avis, était la recherche automatique de bugs dans le code, et je veux en parler. Le point de départ était
un article de Michael Pradel .
Recherche automatique de bogues
Comment les bogues sont-ils recherchés maintenant?
Pourquoi chercher des bugs est plus ou moins clair. Voyons comment ils vont maintenant. Les détecteurs de bogues modernes sont principalement basés sur une analyse de code statique. Pour chaque type d'erreur, recherchez les modèles précédemment remarqués par lesquels elle peut être déterminée. Ensuite, pour réduire le nombre de faux positifs, des heuristiques sont inventées, inventées pour chaque cas individuel. Les modèles peuvent être recherchés à la fois dans un arbre de syntaxe abstraite (AST) construit par code et dans les graphiques d'un flux de contrôle ou de données.
int foo() { if ((x < 0) || x > MAX) { return -1; } int ret = bar(x); if (ret != 0) { return -1; } else { return 1; } }
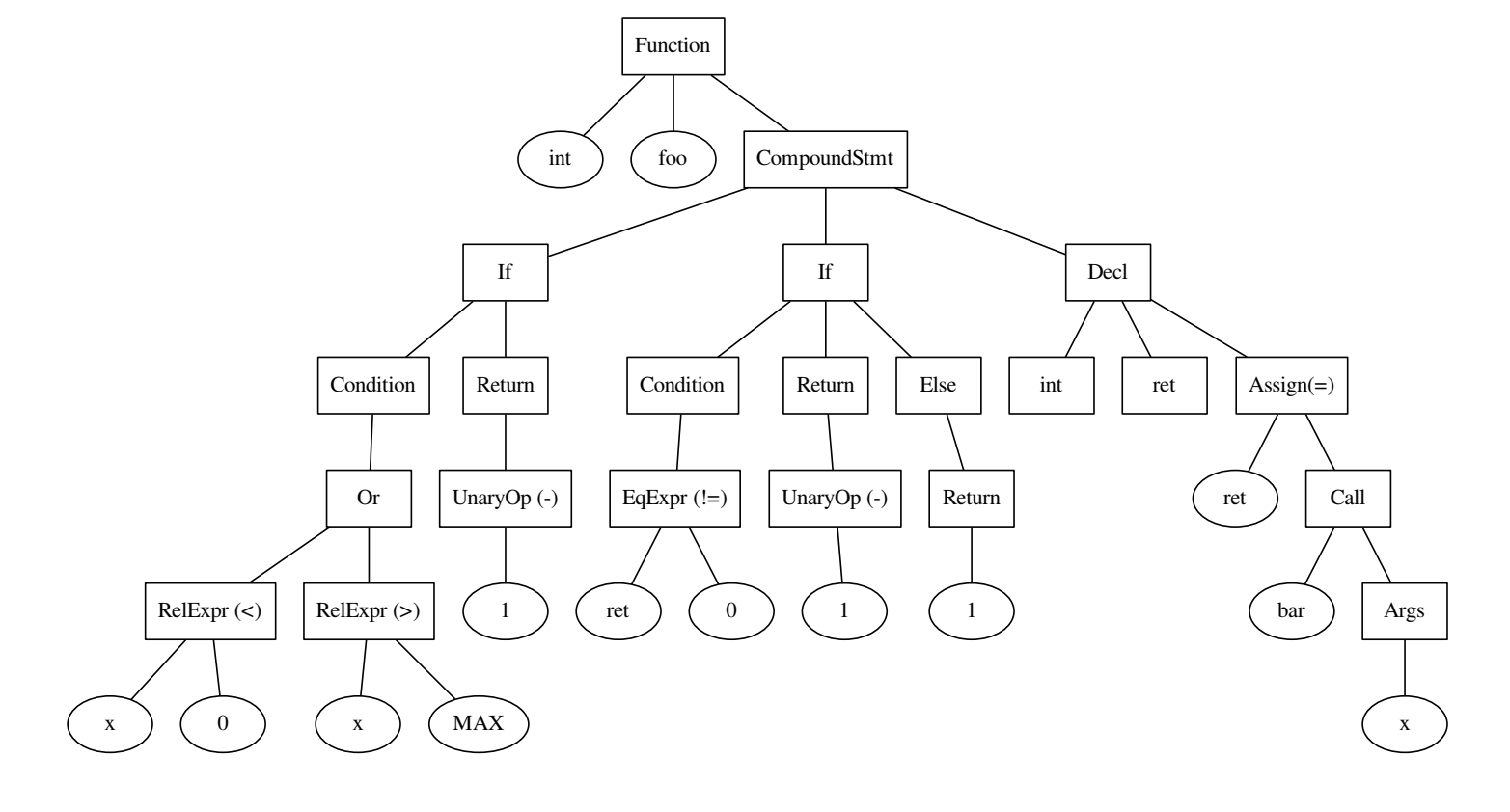
Le code et l'arborescence qui a été construit dessus.
Pour comprendre comment cela fonctionne, considérons un exemple. Le type de bogues peut être l'utilisation de = au lieu de == en C ++. Regardons le morceau de code suivant:
int value = 0; … if (value = 1) { ... } else { … }
Il y avait une erreur dans l'expression conditionnelle, tandis que le premier = dans l'affectation de la valeur à la variable est correct. Le modèle vient d'ici: si l'affectation est utilisée à l'intérieur de la condition dans if, c'est un bug potentiel. En recherchant un tel modèle dans AST, nous pouvons détecter l'erreur et la corriger.
int value = 0; … if (value == 1) { ... } else { … }
Dans un cas plus général, nous ne pourrons pas trouver si facilement un moyen de décrire l'erreur. Supposons que nous voulons déterminer l'ordre correct des opérandes. Encore une fois, regardez les fragments de code:
for (int i = 2; i < n; i++) { a[i] = a[1 - i] + a[i - 2]; }
int bitReverse(int i) { return 1 - i; }
Dans le premier cas, l'utilisation de 1-i était erronée et dans le second, elle était tout à fait correcte, ce qui ressort clairement du contexte. Mais comment le décrire sous la forme d'un motif? Avec la complication du type d'erreurs, nous devons considérer une plus grande section de code et analyser de plus en plus de cas individuels.
Dernier exemple motivant: des informations utiles sont également contenues dans les noms des méthodes et des variables. Il est encore plus difficile à exprimer par certaines conditions spécifiées manuellement.
int getSquare(int xDim, int yDim) { … } int x = 3, y = 4; int s = getSquare(y, x);
Une personne comprend que, très probablement, les arguments de l'appel de fonction sont mélangés, car nous comprenons que x ressemble plus à xDim qu'à yDim. Mais comment signaler cela au détecteur? Vous pouvez ajouter quelques heuristiques de la forme «le nom de la variable est le préfixe du nom de l'argument», mais supposez que x est plus souvent une largeur qu'une hauteur, donc n'exprimez plus.
Conclusion: le problème de l'approche moderne de recherche d'erreurs est que beaucoup de travail doit être fait avec vos mains: pour déterminer les modèles, ajouter des heuristiques, à cause de cela, l'ajout d'un support pour un nouveau type d'erreur dans le détecteur prend du temps. De plus, il est difficile d'utiliser une partie importante des informations que le développeur a laissées dans le code: les noms des variables et des méthodes.
Comment l'apprentissage automatique peut-il aider?
Comme vous l'avez peut-être remarqué, dans de nombreux exemples, les erreurs sont visibles pour les humains, mais elles sont difficiles à décrire formellement. Dans de telles situations, les méthodes d'apprentissage automatique peuvent souvent aider. Arrêtons-nous sur la recherche d'arguments réarrangés dans un appel de fonction et comprenons ce dont nous avons besoin pour les rechercher à l'aide de l'apprentissage automatique:
- Un grand nombre d'exemples de code sans bugs
- Une grande quantité de code avec des erreurs d'un type donné
- Méthode de vectorisation de fragments de code
- Le modèle que nous allons enseigner pour distinguer le code avec et sans erreurs
Nous pouvons espérer que dans la plupart du code présenté dans le domaine public, les arguments dans les appels de fonction sont dans le bon ordre. Par conséquent, pour un exemple de code sans bogues, vous pouvez prendre un ensemble de données volumineux. Dans le cas de l'auteur de l'article original, il s'agissait de JS 150K (150 000 fichiers en Javascript), dans notre cas, un jeu de données similaire pour Python.
Trouver du code avec des bogues est beaucoup plus difficile. Mais nous ne pouvons pas rechercher les erreurs de quelqu'un d'autre, mais faites-les vous-même! Pour le type d'erreurs, vous devez spécifier une fonction qui, selon le bon morceau de code, la rendra corrompue. Dans notre cas, réorganisez les arguments dans l'appel de fonction.
Comment vectoriser le code?
Armés de beaucoup de bons et de mauvais codes, nous sommes presque prêts à enseigner quelque chose. Avant cela, nous devons encore répondre à la question: comment présenter les fragments de code?
Un appel de fonction peut être représenté comme un tuple du nom d'une méthode, du nom de la méthode dont il s'agit, des noms et des types d'arguments passés aux variables. Si nous apprenons à vectoriser des jetons individuels (noms de variables et méthodes, tous les «mots» trouvés dans le code), nous pouvons prendre la concaténation de vecteurs de jetons qui nous intéressent et obtenir le vecteur souhaité pour le fragment.
Pour vectoriser des jetons, regardons comment les mots dans les textes ordinaires vectorisent. L'un des moyens les plus réussis et les plus populaires est le word2vec proposé en 2013.
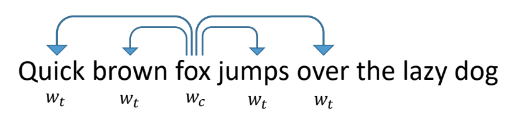
Cela fonctionne comme suit: nous apprenons au réseau à prédire par mot d'autres mots qui apparaissent à côté de lui dans les textes. Dans ce cas, le réseau ressemble à une couche d'entrée de la taille d'un dictionnaire, une couche cachée de la taille de la vectorisation que nous voulons recevoir et une couche de sortie, également de la taille d'un dictionnaire. Pendant la formation, les réseaux sont alimentés par un vecteur d'unité d'entrée avec une unité à la place du mot en question (renard), et en sortie nous voulons obtenir des mots qui apparaissent dans la fenêtre autour de ce mot (rapide, marron, sauts, par dessus). Dans ce cas, le réseau traduit d'abord tous les mots en un vecteur sur une couche cachée, puis fait une prédiction.
Les vecteurs résultants pour des mots individuels ont de bonnes propriétés. Par exemple, les vecteurs de mots ayant une signification similaire sont proches les uns des autres, et la somme et la différence des vecteurs sont l'addition et la différence des «significations» des mots.
Pour effectuer une vectorisation similaire des jetons dans le code, vous devez en quelque sorte définir l'environnement qui sera prédit. Il peut s'agir d'informations issues d'AST: types de sommets autour, jetons rencontrés, position dans un arbre.
Après avoir reçu une vectorisation, vous pouvez voir quels jetons sont similaires les uns aux autres. Pour ce faire, calculez la distance cosinus entre eux. En conséquence, les vecteurs voisins suivants sont obtenus pour Javascript (le nombre est la distance cosinus):
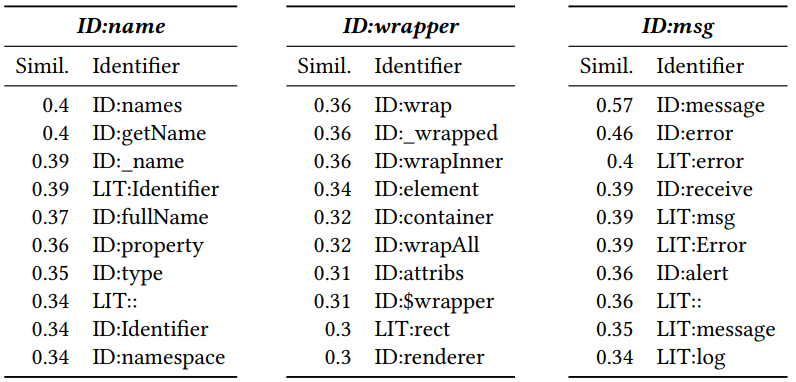
L'ID et le LIT ajoutés au début indiquent si le jeton est un identifiant (nom d'une variable, méthode) ou un littéral (constante). On peut voir que la proximité est significative.
Formation de classificateur
Après avoir reçu une vectorisation pour des jetons individuels, obtenir une vue pour un morceau de code avec une erreur potentielle est assez simple: il s'agit d'une concaténation de vecteurs importants pour la classification des jetons. Un perceptron à deux couches est formé à des morceaux de code avec ReLU comme fonction d'activation et d'abandon pour réduire le sur-ajustement. L'apprentissage converge rapidement, le modèle résultant est petit et peut faire des prédictions pour des centaines d'exemples par seconde. Cela vous permet de l'utiliser en temps réel, ce qui sera discuté plus tard.
Résultats
L'évaluation de la qualité du classificateur résultant a été divisée en deux parties: une évaluation sur un grand nombre d'exemples générés artificiellement et une vérification manuelle sur un petit nombre (50 pour chaque détecteur) d'exemples avec la probabilité prédite la plus élevée. Les résultats pour les trois détecteurs (arguments réarrangés, exactitude de l'opérateur binaire et de l'opérande binaire) étaient les suivants:
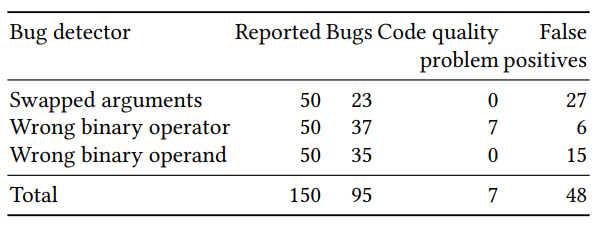
Certaines des erreurs prédites seraient difficiles à trouver avec les méthodes de recherche classiques. Un exemple avec res réarrangé et err dans un appel à p.done:
var p = new Promise (); if ( promises === null || promises . length === 0) { p. done (error , result ) } else { promises [0](error, result).then( function(res, err) { p.done(res, err); }); }
Il y avait aussi des exemples dans lesquels il n'y avait pas d'erreur, mais les variables devaient être renommées afin de ne pas induire en erreur la personne essayant de comprendre le code. Par exemple, ajouter de la largeur et chacun ne semble pas être une bonne idée, même si cela ne s'est pas avéré être un bug:
var cw = cs[i].width + each;
Portage Python
J'ai participé au portage du travail de Michael Pradel de js à python, puis à la création d'un plug-in pour PyCharm qui implémente des inspections basées sur la méthode décrite ci-dessus. Nous avons utilisé l'ensemble de données
Python 150K (150 000 fichiers Python disponibles sur GitHub).
Tout d'abord, il s'est avéré qu'en Python, il y a plus de jetons différents qu'en javascript. Pour js, les 10 000 jetons les plus populaires représentaient plus de 90% de tous les problèmes rencontrés, tandis que pour Python, il fallait en utiliser environ 40 000. Cela a entraîné une augmentation de la taille des jetons dans les vecteurs, ce qui a rendu le portage vers le plugin difficile.
Deuxièmement, après avoir implémenté pour Python une recherche d'arguments incorrects dans les appels de fonction et en regardant les résultats manuellement, j'ai obtenu un taux d'erreur de plus de 90%, ce qui était en désaccord avec les résultats pour js. Après avoir compris les raisons, il s'est avéré qu'en javascript, plus de fonctions étaient déclarées dans le même fichier que leurs appels. Moi, suivant l'exemple de l'auteur de l'article, dans un premier temps, je n'ai pas autorisé la déclaration de fonctions à partir d'autres fichiers, ce qui a conduit à de mauvais résultats.
Vers la fin août, j'ai terminé l'implémentation de Python et écrit la base du plugin. Le plugin continue d'être développé, maintenant l'étudiante Anastasia Tuchina de notre laboratoire est engagée dans ce domaine.
Vous pouvez trouver les étapes pour essayer le fonctionnement du plugin sur le wiki du référentiel.
Liens sur github:
Référentiel avec implémentation pythonRéférentiel avec plugin