Dans cet article, nous simulons et examinons un protocole de validation en deux phases à l'aide de TLA +.
Le protocole de validation en deux phases est pratique et est utilisé aujourd'hui dans de nombreux systèmes distribués. Elle est néanmoins assez courte. Par conséquent, nous pouvons rapidement le modéliser et en apprendre beaucoup. En fait, avec cet exemple, nous allons illustrer quel résultat dans des systèmes distribués est
fondamentalement impossible .
Le problème de commit biphasé
La transaction passe par
les gestionnaires de ressources (RM) . Tous les MR doivent convenir si la transaction sera
terminée ou
abandonnée .
Le gestionnaire de transactions (TM) prend la décision finale:
valider ou
annuler . La condition pour la validation est la volonté de valider tous les RM. Sinon, la transaction doit être annulée.
Quelques notes sur la modélisation
Par souci de simplicité, nous effectuons des simulations dans un modèle de mémoire partagée, pas dans un système de messagerie. Il fournit également une validation rapide du modèle. Mais nous ajouterons la non-atomicité aux actions «lecture depuis le nœud voisin et mise à jour de l'état» afin de capturer un comportement intéressant lors de l'envoi de messages.
RM ne peut lire que l'état TM et lire / mettre à jour son propre état. Il ne peut pas lire l'état d'un autre gestionnaire de ressources. Une MT peut lire l'état de tous les nœuds RM et lire / mettre à jour son propre état.
Définitions

Les lignes 9-10 définissent le
rmState initial pour chaque RM sur
working , et TM sur
init .
Le prédicat
canCommit est
true si tous les RM sont «préparés» (prêts à être validés). Si RM existe à l'état final, le prédicat
canAbort devient
canAbort .

La modélisation TM est simple. Le gestionnaire de transactions vérifie la possibilité d'un commit ou d'une annulation - et met à jour en conséquence
tmState .
Il est possible que TM ne puisse pas rendre
tmState "inaccessible", mais uniquement si la constante
TMMAYFAIL définie sur
true avant la validation du modèle. Dans les étiquettes TLA +, déterminez le degré d'atomicité, c'est-à-dire sa granularité. Par les étiquettes F1 et F2, nous indiquons que les opérateurs correspondants sont exécutés de manière non anatomique (après un certain temps indéfini) par rapport aux opérateurs précédents.
Modèle RM

Le modèle RM est également simple. Étant donné que les états «de travail» et «préparé» ne sont pas définitifs, RM choisit de manière non déterministe parmi les actions jusqu'à ce qu'il atteigne l'état final. Un RM «fonctionnel» peut entrer dans un état «interrompu» ou «préparé». «Prepared» RM attend une validation / annulation de la part de TM - et agit en conséquence. La figure ci-dessous montre les transitions d'état possibles pour un RM. Mais notez que nous avons plusieurs RM, chacun passant par ses états à son propre rythme sans connaître l'état des autres RM.
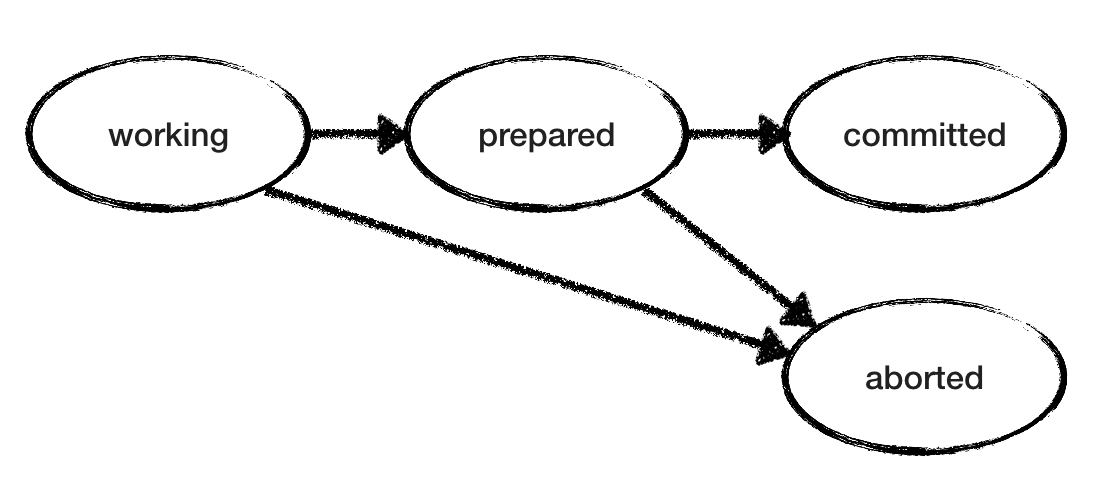
Modèle de validation en deux phases

Nous devons vérifier la cohérence de notre validation en deux phases: afin qu'il n'y ait pas de MR différent, dont l'un dit «commit» et l'autre «avortement».
Le prédicat
Completed vérifie que le protocole ne se bloque pas indéfiniment: à la fin, chaque RM atteint l'état final de
committed ou
aborted .
Nous sommes maintenant prêts à tester le modèle de protocole. Initialement, nous avons défini
TMMAYFAIL=FALSE, RM=1..3 pour démarrer le protocole avec trois RM et une TM, c'est-à-dire dans une configuration fiable. Le test du modèle prend 15 secondes et indique qu'il n'y a pas d'erreur. La
Consistency et l'
Completed satisfaits de toute exécution de protocole possible avec toute alternance d'actions RM et d'actions TM.

Maintenant, définissez
TMMAYFAIL=TRUE et redémarrez la vérification. Le programme produit rapidement le résultat inverse, où RM est resté coincé en attente d'une réponse d'une MT indisponible.

On voit qu'à
State=4 transitions RM2 sont interrompues, à
State=7 transitions RM3 sont interrompues, à
State=8 TM passe à l'état "raccrocher" et tombe à
State=9 . À
State=10 système se bloque car RM1 reste à jamais dans un état préparé, en attente d'une décision d'une MT tombée.
Simulation BTM
Pour éviter les gels de transaction, nous ajoutons une sauvegarde TM (BTM), qui prend rapidement le contrôle si la MT principale n'est pas disponible. BTM utilise la même logique que TM pour prendre des décisions. Et pour simplifier, nous supposons que le BTM ne plante jamais.

Lorsque nous testons le modèle avec le processus BTM ajouté, nous obtenons un nouveau message d'erreur.

BTM ne peut pas accepter un commit car notre condition d'origine,
canCommit stipule que tous les
RMstates doivent être «préparés» et ne prend pas en compte la condition selon laquelle certains RMs ont déjà reçu une décision de commit du TM original avant que le TMB prenne le contrôle. Il est nécessaire de réécrire les conditions de
canCommit en tenant compte d'une telle situation.

Succès! Lorsque nous testons le modèle, nous atteignons à la fois la cohérence et l'exhaustivité, puisque le BTM prend le contrôle et termine la transaction si le TM tombe.
Voici le modèle 2PCwithBTM en TLA + (BTM et la deuxième ligne de canCommit sont initialement non commentés) et le
pdf correspondant .
Et si RM échoue aussi?
Nous avons supposé que RM était fiable. Maintenant, annulez cette condition et voyez comment le protocole se comporte lorsque RM échoue. Ajoutez l'état «inaccessible» au modèle de défaillance. Afin d'étudier le comportement et de simuler une perte de disponibilité intermittente, laissez le RM d'urgence récupérer et continuer à travailler en lisant son état dans le journal. Voici un autre diagramme de transition d'état RM avec l'état «inaccessible» ajouté et les transitions marquées en rouge. Et ci-dessous est le modèle révisé pour RM.
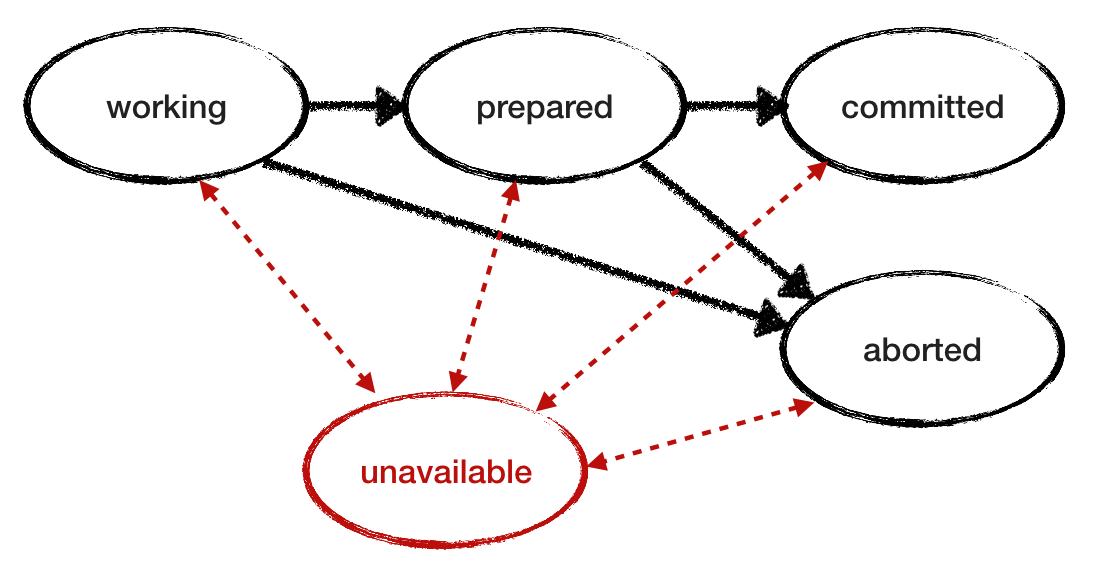

Il est également nécessaire d'affiner
canAbort en tenant compte de l'état d'indisponibilité. TM peut prendre la décision de «raccrocher» si l'un des services est dans un état interrompu ou inaccessible. Si cette condition est omise, un RM tombé et non restauré interrompra la progression de la transaction. Bien sûr, encore une fois, vous devez considérer les RM qui ont appris la décision de finaliser la transaction à partir de la MT source.
Vérification du modèle
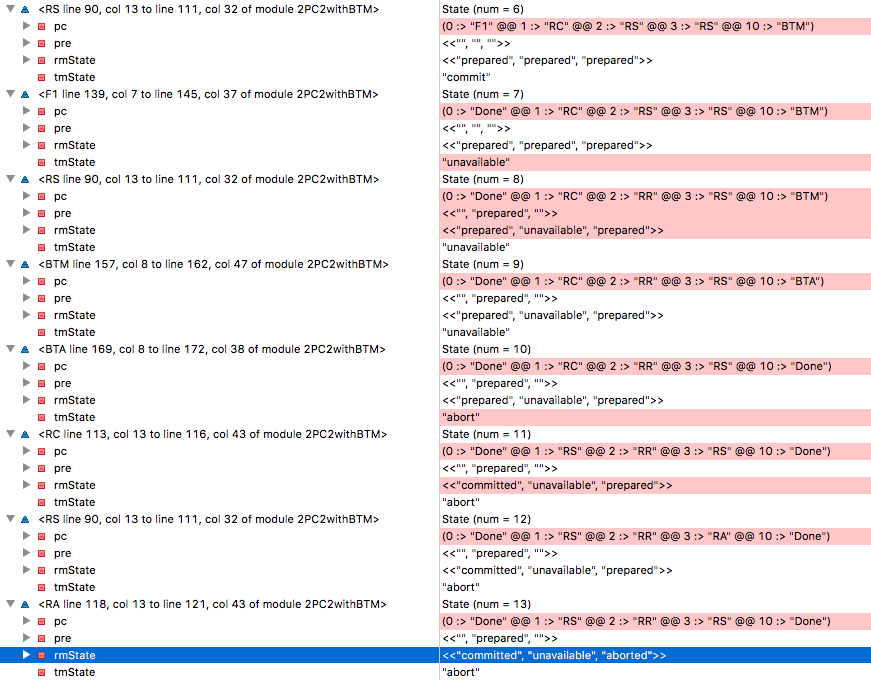
Lorsque nous testons le modèle, il y a un problème d'incohérence! Comment cela a-t-il pu arriver? On trace la trace.
Avec
State=6 tous les RM sont dans un état préparé, TM a pris la décision de finaliser la transaction, RM1 a vu cette décision et est passé à l'étiquette RC, ce qui signifie qu'il est prêt à changer son état en «terminé». (Rappelez-vous RM1, ce pistolet tirera au dernier acte). Malheureusement, le TM tombe à
State=7 , et RM2 devient indisponible à
State=8 . Dans la neuvième étape, le BTM de sauvegarde prend le contrôle et lit le statut des trois RM comme «préparé, inaccessible, préparé» - et décide d'annuler la transaction à la dixième étape. Rappelez-vous RM1? Il décide de finaliser la transaction car il a reçu une telle décision de la part de la MT d'origine et entre dans l'état
committed à l'étape 11. Dans
State=13 RM3 remplit la décision d'annuler la transaction de BTM et entre dans l'état
aborted - et maintenant nous avons rompu la coordination avec RM1.
Dans ce cas, le BTM a pris une décision qui violait la
cohérence . D'un autre côté, si vous faites attendre le BTM que le RM quitte l'état inaccessible, il peut geler pour toujours en cas d'accident au niveau du nœud, et cela violera la condition de
réalisation (progression).
Un fichier de modèle TLA + mis à jour est disponible ici , ainsi que le
pdf correspondant .
Impossibilité FLP
Que s'est-il donc passé? Nous sommes tombés sur le
théorème de Fisher, Lynch, Paterson (FLP) sur l'impossibilité d'un consensus dans un système asynchrone avec échecs.
Dans notre exemple, BTM ne peut pas décider correctement si RM2 est en état d'échec ou non - et décide incorrectement d'annuler la transaction. Si seule la MT d'origine prenait la décision, une telle inexactitude dans la reconnaissance d'un échec ne serait pas un problème. RM obéira à toute décision TM, afin que la cohérence et les progrès soient maintenus.
Le problème est que nous avons deux objets qui prennent des décisions: TM et BTM, ils regardent l'état de RM à différents moments et prennent des décisions différentes. Une telle asymétrie d'information est à l'origine de tout mal dans les systèmes distribués.
Le problème ne disparaît pas même avec l'extension à un commit en trois phases.
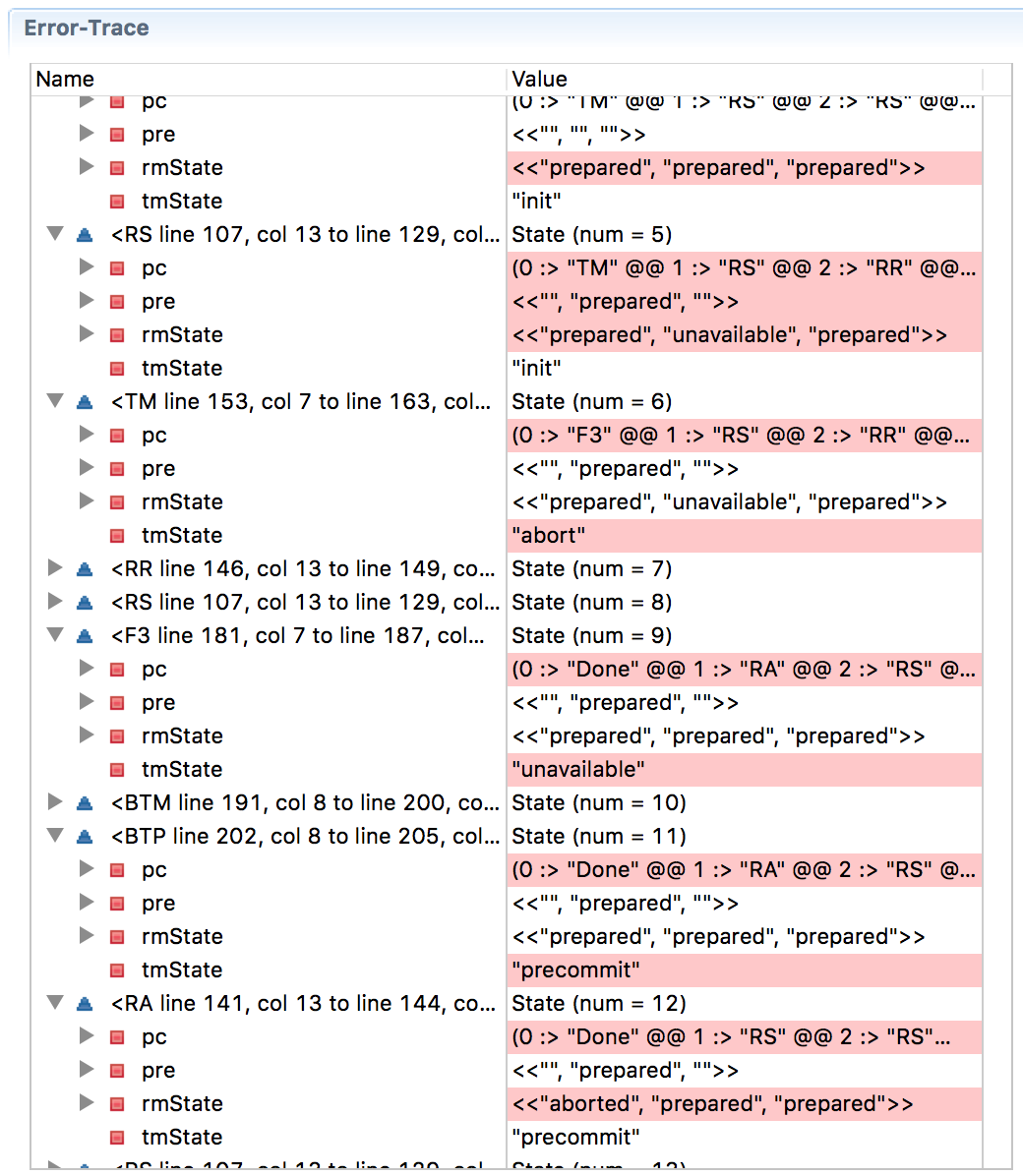
Voici un commit en trois phases modélisé en TLA + (
version pdf ), et ci-dessous est une trace d'erreur qui montre que cette fois la progression a été violée (sur
la page Wikipedia à propos d'un commit en trois phases , une situation est décrite lorsque RM1 se bloque après avoir reçu une décision avant le commit, et RM2 et RM3 commit commit, ce qui viole la cohérence).
Paxos essaie de rendre le monde meilleur.

Mais tout n'est pas perdu, l'espoir n'est pas mort.
Nous avons Paxos . Il agit parfaitement dans le cadre du théorème FLP. L'innovation de Paxos est qu'il est
toujours sûr (même avec des détecteurs inexacts, une exécution asynchrone et des pannes), et
finalise la transaction lorsqu'un consensus devient possible.
Vous pouvez émuler TM sur un cluster avec trois nœuds Paxos, et cela résoudra le problème d'incohérence TM / BTM. Ou, comme Gray et Lampport l'ont montré dans un
article scientifique sur le consensus dans la validation
de transaction , si RM utilise le conteneur Paxos pour stocker leurs décisions simultanément avec la réponse TM, cela élimine une étape supplémentaire dans l'algorithme de protocole standard.