À Rostelecom, comme dans toute grande entreprise, il existe un entrepôt de données d'entreprise (WCD). Notre WCD est en constante croissance et expansion, nous y construisons des vitrines, des rapports et des cubes de données utiles. À un moment donné, nous avons été confrontés au fait que des données de mauvaise qualité interfèrent avec nous lors de la création de fenêtres d'affichage, les unités résultantes ne convergent pas avec les unités des systèmes source et provoquent un manque de compréhension de l'entreprise. Par exemple, les données avec des valeurs Null dans des clés étrangères (clés étrangères) ne sont pas connectées aux données d'autres tables.
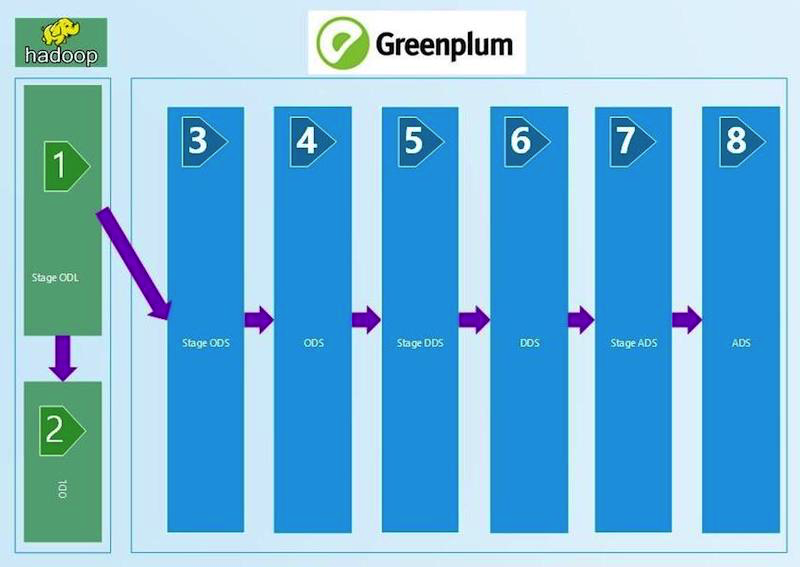
Bref diagramme de WCD:
Nous avons compris que pour garantir la confiance dans la qualité des données, nous avions besoin d'un processus de réconciliation régulier. Bien sûr, automatisé et permettant à chacun des niveaux technologiques d'être sûr de la qualité des données et de leur convergence, à la fois verticalement et horizontalement. En conséquence, nous avons simultanément examiné trois plates-formes prêtes à l'emploi pour gérer les rapprochements de divers fournisseurs et écrit la nôtre. Nous partageons notre expérience dans ce post.
Les inconvénients des plates-formes finies sont connus de tous: prix, flexibilité limitée, manque de possibilité d'ajouter et de corriger des fonctionnalités. Avantages - les pièces mdm (données d'or, etc.), la formation et le support sont également fermés. Ayant apprécié cela, nous avons rapidement oublié l'achat et nous sommes concentrés sur le développement de notre solution.
Le cœur de notre système est écrit en Python, et la base de données de métadonnées pour le stockage, la journalisation et le stockage des résultats est écrite dans Oracle. Il existe de nombreuses bibliothèques pour Python, nous utilisons le minimum nécessaire pour les connexions Hive (pyhive), GreenPlum (pgdb), Oracle (cx_Oracle). La connexion d'un autre type de source ne devrait pas non plus poser de problème.
L'ensemble de données résultant (jeu de résultats) que nous avons mis dans la table Oracle résultante, sur la route évaluant l'état de la réconciliation (SUCCÈS / ERREUR). APEX est configuré sur les tables résultantes dans lesquelles la visualisation des résultats est construite, pratique pour la maintenance et la gestion.
Pour exécuter des vérifications dans le référentiel, l'orchestre Informatica est utilisé, qui télécharge les données. Dès réception d'un statut de téléchargement réussi, ces données commenceront automatiquement à être vérifiées. L'utilisation du paramétrage des requêtes et des métadonnées WCD permet l'utilisation de modèles de réconciliation des requêtes pour les ensembles de tables.
Maintenant sur les rapprochements implémentés sur cette plateforme.
Nous avons commencé par des rapprochements techniques, qui comparent la quantité de données à l'entrée et les couches du WCD avec l'application de certains filtres. Nous prenons le fichier ctl qui est arrivé à l'entrée WCD, lisons le nombre d'enregistrements et le comparons avec le tableau sur Stage ODL et / ou Stage ODS (1, 2, 3 dans le diagramme). Le critère de vérification est défini dans l'égalité du nombre d'enregistrements (nombre). Si la quantité converge, le résultat est SUCCÈS, non - ERREUR et analyse manuelle de l'erreur.
Cette chaîne de rapprochements techniques, par rapport au nombre d'enregistrements, s'étend à la couche ADS (8 sur le schéma). Les filtres sont changés entre les couches, qui dépendent du type de chargement - DIM (livre de référence), HDIM (livre de référence historique), FACT (tables de régularisation réelles), etc. - ainsi que de la version du SCD et de la couche. Le plus proche de la couche d'affichage, les algorithmes de filtrage les plus sophistiqués que nous utilisons.
Une vérification technique a également été effectuée sur l'entrée en Python, qui détecte les doublons dans les champs clés. Dans notre GreenPlum, les champs clés (PK) ne sont pas protégés contre les doublons par les outils du système de base de données. Nous avons donc écrit un script Python qui lit les champs de la table chargée à partir des métadonnées PK et génère un script SQL qui vérifie l'absence de prises sur eux. La flexibilité de l'approche nous permet d'utiliser PK composé d'un ou plusieurs champs, ce qui est extrêmement pratique. Cette réconciliation s'étend à la couche STG ADS.
unique_check import sys import os from datetime import datetime log_tmstmp = datetime.now().strftime("%Y-%m-%d %H:%M:%S") def do_check(args, context): tab = args[0] data = [] fld_str = "" try: sql = """SELECT 't_'||lower(table_id) as tn, lower(column_name) as cn FROM src_column@meta_data WHERE table_id = '%s' and is_primary_key = 'Y'""" % (tab,) for fld in context['ora_get_data'](context['ora_con'], sql): fld_str = fld_str + (fld_str and ",") + fld[1] if fld_str: config = context['script_config'] con_gp = context['pg_open_con'](config['user'], config['pwd'], config['host'], config['port'], config['dbname']) sql = """select %s as pkg_id, 't_%s' as table_name, 'PK fields' as column_name, coalesce(sum(cnt), 0) as NOT_UNIQUE_PK, to_char(current_timestamp, 'YYYY-MM-DD HH24:MI:SS') as sys_creation from (select 1 as cnt from edw_%s.t_%s where %s group by %s having count(*) > 1 ) sq; """ % (context["package"] or '0',tab.lower(), args[1], tab.lower(), (context["package"] and ("package_id = " + context["package"]) or "1=1"), fld_str ) data.extend(context['pg_get_data'](con_gp, sql)) con_gp.close() except Exception as e: raise return data or [[(context["package"] or 0),'t_'+tab.lower(), None, 0, log_tmstmp]] if __name__ == '__main__': sys.exit(do_check([sys.argv[1], sys.argv[2]], {}))
Exemple de code python de réconciliation d'unicité. L'appel, le transfert des paramètres de connexion et la mise des résultats dans la table résultante sont effectués par le module de contrôle en Python.La réconciliation pour l'absence de valeurs NULL est construite de manière similaire à la précédente et également en Python. Nous lisons dans les champs de métadonnées de chargement qui ne peuvent pas avoir de valeurs vides (NULL) et vérifions leur plénitude. La réconciliation est utilisée avant la couche DDS (6 dans le premier diagramme).
A l'entrée du stockage, une analyse de tendance des paquets de données arrivant à l'entrée est également implémentée. La quantité de données reçues à l'arrivée d'un nouveau package est entrée dans le tableau d'historique. Avec un changement significatif dans la quantité de données, la personne responsable de la table et du SI (système source) reçoit une notification par courrier (dans les plans), voit une erreur dans APEX avant que le paquet de données ne pénètre dans l'entrepôt et en trouve la raison avec le SI.
Entre STG (STAGE) _ODS et ODS (couche de données opérationnelles) (3 et 4 dans le diagramme), des champs de suppression technique apparaissent (indicateur de suppression = supprimé_ind), dont nous vérifions également l'exactitude au moyen de requêtes SQL. L'entrée manquante doit être marquée comme supprimée dans ODS.
Le résultat du script de rapprochement ne devrait afficher aucune erreur. Dans l'exemple de réconciliation présenté, les paramètres ~ # PKG_ID # ~ sont transmis via le bloc de contrôle Python, et les paramètres de type ~ P_JOIN_CONDITION ~ et ~ PERIOD_COL ~ sont remplis à partir des métadonnées de la table, le nom de la table elle-même ~ TABLE ~ à partir des paramètres de lancement.
Ce qui suit est une réconciliation paramétrée. Exemple de code de réconciliation SQL entre STG_ODS et ODS pour le type HDIM:
select package_id as pkg_id, 'T_~TABLE~' as table_name, to_char(current_timestamp, 'YYYY-MM-DD HH24:MI:SS'), coalesce(empty_in_ods, 0) as empty_in_ods, coalesce(not_equal_md5, 0) as not_equal_md5, coalesce(deleted_in_ods, 0) as deleted_in_ods, coalesce(not_deleted_in_ods, 0) as not_deleted_in_ods, max_load_dttm from (select max (src.package_id) as package_id, sum (case when tgt.md5 is null then 1 else 0 end) as empty_in_ods, sum (case when src.md5<>tgt.md5 and tgt.~PK~ is not null and tgt.deleted_ind = 0 then 1 else 0 end) as not_equal_md5, sum (case when tgt.deleted_ind = 1 and src.md5=tgt.md5 then 1 else 0 end) as deleted_in_ods from EDW_STG_ODS.T_~TABLE~ src left join EDW_ODS.T_~TABLE~ tgt on ~P_JOIN_CONDITION~ and tgt.active_ind ='Y' where ~
Un exemple de code de réconciliation SQL entre STG_ODS et ODS pour un type HDIM avec des paramètres substitués:
À partir d'ODS, l'historique est conservé dans les répertoires, il faut donc vérifier l'absence d'intersections et de lacunes. Cela se fait en comptant le nombre de valeurs incorrectes dans l'historique et en écrivant le nombre d'erreurs résultant dans la table résultante. S'il y a des erreurs d'historique dans le tableau, elles devront être recherchées manuellement. La réconciliation dépend du type de téléchargement - HDIM (guide de référence historique) en premier lieu. Nous effectuons des rapprochements de l'exactitude de l'historique des répertoires jusqu'à la couche ADS.
Sur la couche DDS (6 dans le premier diagramme), différents SI (systèmes source) sont combinés en une seule table; des tables HUB pour générer des clés de substitution pour relier les données de différents systèmes source apparaissent. Nous vérifions leur unicité avec une vérification en python similaire à la couche stage.
Sur la couche DDS, il est nécessaire de vérifier qu'après combinaison avec la table HUB, les valeurs des types 0, -1, -2 n'apparaissent pas dans les champs clés, ce qui signifie une jointure incorrecte de la table, un manque de données. Ils pourraient apparaître en l'absence des données nécessaires dans la table HUB. Et c'est une erreur pour l'analyse manuelle.
Les rapprochements les plus complexes pour les données de la couche vitrine ADS (8 dans le premier diagramme). Pour une confiance totale dans la convergence du résultat obtenu, une vérification avec un système source d'agrégation du montant des charges est déployée ici. D'une part, il existe une classe d'indicateurs qui incluent les charges à payer agrégées. Nous les récupérons pendant un mois aux fenêtres du WCD. D'un autre côté, nous prenons des agrégats des mêmes charges du système source. Un écart ne dépassant pas 1% ou une valeur absolue certaine et convenue est autorisé. Les ensembles de résultats obtenus par rapprochement sont placés dans des ensembles de données spécialement créés qui reçoivent des tables Oracle. La comparaison des données se fait dans la vue Oracle. Visualisation des résultats dans APEX. La présence de tout un ensemble de données (jeu de résultats) nous permet, s'il y a des erreurs, d'approfondir et d'analyser les données détaillées du résultat, de trouver un article spécifique sur lequel la divergence s'est produite et de rechercher ses raisons.
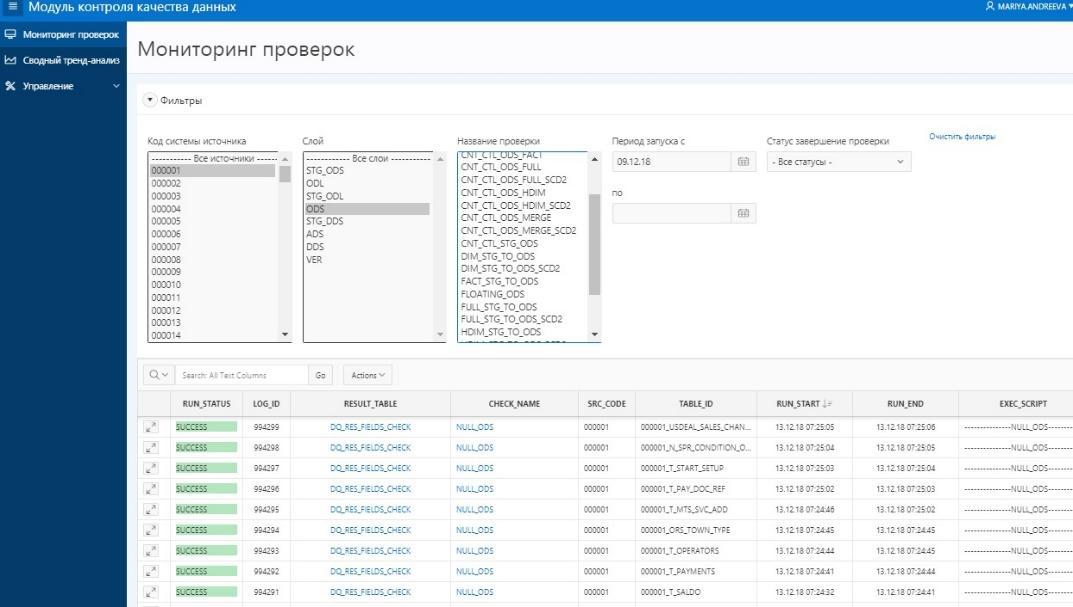 Présentation des résultats de rapprochement aux utilisateurs dans APEX
Présentation des résultats de rapprochement aux utilisateurs dans APEXÀ l'heure actuelle, nous avons obtenu une application utilisable et activement utilisée pour la réconciliation des données. Bien entendu, nous prévoyons de développer davantage à la fois la quantité et la qualité des rapprochements, ainsi que le développement de la plateforme elle-même. Notre propre développement nous permet de changer et de modifier la fonctionnalité assez rapidement.
Cet article a été préparé par l'équipe de gestion des données de Rostelecom