Au début de décembre, Montréal a accueilli la 32e conférence annuelle
des systèmes de traitement de l'information neuronale sur l'apprentissage automatique. Selon un tableau de classement non officiel, cette conférence est le premier événement de ce format au monde. Tous les billets de conférence de cette année ont été vendus en un temps record de 13 minutes. Nous avons une grande équipe de scientifiques des données MTS, mais une seule d'entre elles - Marina Yaroslavtseva (
magoli ) - a eu la chance de se rendre à Montréal. Avec Danila Savenkov (
danila_savenkov ), restée sans visa et qui a suivi la conférence de Moscou, nous parlerons des travaux qui nous ont paru les plus intéressants. Cet échantillon est très subjectif, mais j'espère qu'il vous intéressera.
 Réseaux neuronaux récurrents relationnelsRésuméCode
Réseaux neuronaux récurrents relationnelsRésuméCodeLorsque vous travaillez avec des séquences, il est souvent très important de savoir comment les éléments de la séquence sont liés les uns aux autres. L'architecture standard des réseaux de récurrence (GRU, LSTM) peut difficilement modéliser la relation entre deux éléments assez éloignés l'un de l'autre. Dans une certaine mesure, l'attention aide à y faire face (
https://youtu.be/SysgYptB198 ,
https://youtu.be/quoGRI-1l0A ), mais ce n'est toujours pas tout à fait raison. L'attention vous permet de déterminer le poids avec lequel l'état caché de chacune des étapes de la séquence affectera l'état caché final et, par conséquent, la prédiction. Nous nous intéressons à la relation des éléments de la séquence.
L'année dernière, toujours sur NIPS, Google a suggéré d'abandonner complètement la récidive et d'utiliser l'
auto-attention . L'approche s'est avérée très bonne, mais principalement sur les tâches seq2seq (l'article fournit des résultats sur la traduction automatique).
L'article de cette année utilise l'idée de l'attention personnelle dans le cadre du LSTM. Il n'y a pas beaucoup de changements:
- Nous changeons le vecteur d'état cellulaire en matrice «mémoire» M. Dans une certaine mesure, la matrice mémoire est constituée de nombreux vecteurs d'état cellulaire (de nombreuses cellules mémoire). En obtenant un nouvel élément de la séquence, nous déterminons combien cet élément doit mettre à jour chacune des cellules de mémoire.
- Pour chaque élément de la séquence, nous mettrons à jour cette matrice en utilisant l'attention du produit scalaire à plusieurs têtes (MHDPA, vous pouvez en savoir plus sur cette méthode dans l'article mentionné de Google). Le résultat MHPDA pour l'élément courant de la séquence et de la matrice M est exécuté à travers un maillage entièrement connecté, le sigmoïde puis la matrice M est mis à jour de la même manière que l'état de cellule dans LSTM
On fait valoir que c'est par le biais de MHDPA que le maillage peut prendre en compte l'interconnexion des éléments de séquence même lorsqu'ils sont retirés les uns des autres.
En tant que problème de jouet, le modèle est demandé dans la séquence de vecteurs pour trouver le Nème vecteur par distance du Mème en termes de distance euclidienne. Par exemple, il y a une séquence de 10 vecteurs et nous vous demandons d'en trouver un qui est à la troisième place à proximité du cinquième. Il est clair que pour répondre à cette question du modèle, il faut en quelque sorte évaluer les distances de tous les vecteurs au cinquième et les trier. Ici, le modèle proposé par les auteurs bat en toute confiance le LSTM et le
DNC . De plus, les auteurs comparent leur modèle avec d'autres architectures sur Learning to Execute (nous obtenons quelques lignes de code à saisir, donnons le résultat), Mini-Pacman, Language Modeling et partout rapportent les meilleurs résultats.
Imputation de séries chronologiques multivariées avec des réseaux contradictoires génératifsRésuméCode (bien qu'ils ne soient pas liés ici dans l'article)
Dans les séries chronologiques multidimensionnelles, en règle générale, il y a un grand nombre d'omissions, ce qui empêche l'utilisation de méthodes statistiques avancées. Les solutions standard - remplir avec une moyenne / zéro, supprimer des cas incomplets, restaurer des données basées sur des expansions matricielles dans cette situation, ne fonctionnent souvent pas, car elles ne peuvent pas reproduire les dépendances temporelles et la distribution complexe de séries chronologiques multidimensionnelles.
La capacité des réseaux contradictoires génératifs (GAN) à imiter toute distribution de données, en particulier dans les tâches de «dessin» de visages et de génération de phrases, est largement connue. Mais, en règle générale, ces modèles nécessitent soit une formation initiale sur un ensemble complet de données sans lacunes, soit ne tiennent pas compte de la nature cohérente des données.
Les auteurs proposent de compléter le GAN avec un nouvel élément - le Gated Recurrent Unit for Imputation (GRUI). La principale différence avec le GRU habituel est que le GRUI peut apprendre des données à des intervalles de différentes longueurs entre les observations et ajuster l'effet des observations en fonction de leur distance dans le temps du point actuel. Un paramètre d'atténuation spécial β est calculé, dont la valeur varie de 0 à 1 et plus elle est petite, plus le décalage temporel entre l'observation en cours et la précédente non vide est grand.


Le discriminateur et le générateur GAN sont tous deux constitués d'une couche GRUI et d'une couche entièrement connectée. Comme d'habitude dans les GAN, le générateur apprend à simuler les données source (dans ce cas, il suffit de combler les lacunes dans les lignes), et le discriminateur apprend à distinguer les lignes remplies avec le générateur des vraies.
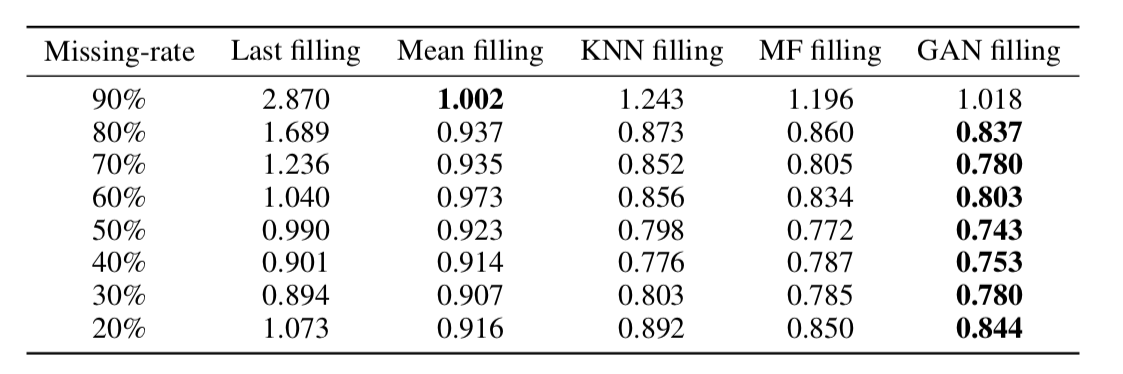
Il s'est avéré que cette approche restitue de manière très adéquate les données même dans les séries chronologiques avec une très grande part d'omissions (dans le tableau ci-dessous - Récupération des données MSE dans l'ensemble de données KDD en fonction du pourcentage d'omissions et de la méthode de récupération. Dans la plupart des cas, la méthode basée sur GAN donne la plus grande précision récupération).
 Sur la dimensionnalité des intégrations de motsRésuméCode
Sur la dimensionnalité des intégrations de motsRésuméCodeL'incorporation de mots / représentation vectorielle de mots est une approche largement utilisée pour diverses applications de PNL: des systèmes de recommandation à l'analyse de la coloration émotionnelle des textes et de la traduction automatique.
De plus, la question de savoir comment régler de manière optimale un hyperparamètre aussi important que la dimension des vecteurs reste ouverte. En pratique, il est le plus souvent sélectionné par recherche empirique exhaustive ou fixé par défaut, par exemple au niveau de 300. Dans le même temps, une dimension trop petite ne permet pas de refléter toutes les relations significatives entre les mots, et trop grande peut conduire à une reconversion.
Les auteurs de l'étude proposent leur solution à ce problème en minimisant le paramètre de perte PIP, une nouvelle mesure de la différence entre les deux options d'intégration.
Le calcul est basé sur des matrices PIP qui contiennent les produits scalaires de toutes les paires de représentations vectorielles de mots dans le corpus. La perte PIP est calculée comme la norme Frobenius entre les matrices PIP de deux plongements: entraînée sur les données (entraînée par l'intégration E_hat) et idéale, entraînée sur les données bruyantes (incorporée par l'oracle E).
Cela semblerait simple: vous devez choisir une dimension qui minimise la perte de PIP, le seul moment incompréhensible est où obtenir l'intégration d'Oracle. En 2015-2017, un certain nombre d'ouvrages ont été publiés dans lesquels il a été montré que différentes méthodes de construction des plongements (word2vec, GloVe, LSA) factorisent implicitement (abaissent la dimension) la matrice de signal de l'affaire. Dans le cas de word2vec (skip-gram), la matrice de signal est
PMI , dans le cas de GloVe, c'est la matrice de log-count. Il est proposé de prendre un dictionnaire de taille pas très grande, de construire une matrice de signaux et d'utiliser SVD pour obtenir l'intégration d'Oracle. Ainsi, la dimension d'intégration d'oracle est égale au rang de la matrice du signal (en pratique, pour un dictionnaire de 10k mots, la dimension sera de l'ordre de 2k). Cependant, notre matrice de signaux empiriques est toujours bruyante et nous devons recourir à des schémas délicats pour obtenir l'intégration d'Oracle et estimer la perte de PIP par une matrice bruyante.
Les auteurs soutiennent que pour sélectionner la dimension d'intégration optimale, il suffit d'utiliser un dictionnaire de 10 000 mots, ce qui n'est pas beaucoup et vous permet d'exécuter cette procédure dans un délai raisonnable.
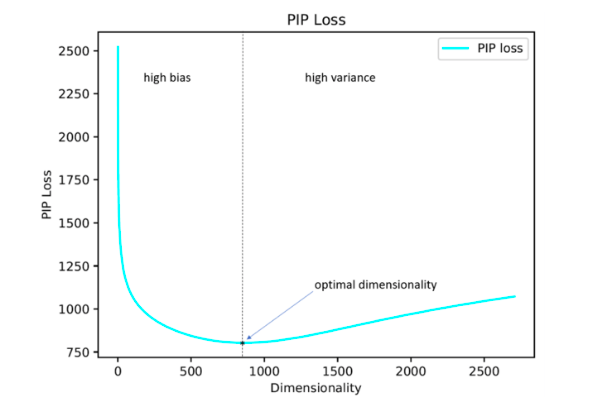
Il s'est avéré que la dimension d'intégration calculée de cette manière dans la plupart des cas avec une erreur allant jusqu'à 5% coïncide avec la dimension optimale déterminée sur la base d'estimations d'experts. Il s'est avéré (attendu) que Word2Vec et GloVe ne se sont pratiquement pas recyclés (la perte de PIP ne chute pas à de très grandes dimensions), mais LSA est recyclé assez fortement.
En utilisant le code affiché sur le github par les auteurs, on peut rechercher la dimension optimale de Word2Vec (skip-gram), GloVe, LSA.
FRAGE: Représentation des mots agnostiques en fréquenceRésuméCodeLes auteurs expliquent comment les intégrations fonctionnent différemment pour les mots rares et populaires. Par populaire, je veux dire non pas des mots (nous ne les considérons pas du tout), mais des mots informatifs qui ne sont pas très rares.
Les observations sont les suivantes:
Si nous parlons de mots populaires, leur proximité en mesure de cosinus se reflète très bien
- leur affinité sémantique. Pour les mots rares, ce n'est pas le cas (ce qui est attendu), et (ce qui est moins attendu) les n premiers des mots cosinus les plus proches d'un mot rare sont également rares et en même temps sémantiquement sans rapport. Autrement dit, les mots rares et fréquents dans l'espace des plongements vivent dans des endroits différents (dans des cônes différents, si nous parlons de cosinus)
- Pendant la formation, les vecteurs de mots populaires sont mis à jour beaucoup plus souvent et, en moyenne, sont deux fois plus loin de l'initialisation que les vecteurs de mots rares. Cela conduit au fait que l'incorporation de mots rares est en moyenne plus proche de l'origine. Pour être honnête, j'ai toujours cru que, au contraire, les incorporations de mots rares sont en moyenne plus longues et je ne sais pas comment me rapporter à la déclaration des auteurs =)
Quelle que soit la relation entre les normes L2 des plongements, la séparabilité des mots populaires et rares n'est pas un très bon phénomène. Nous voulons que les plongements reflètent la sémantique d'un mot, pas sa fréquence.
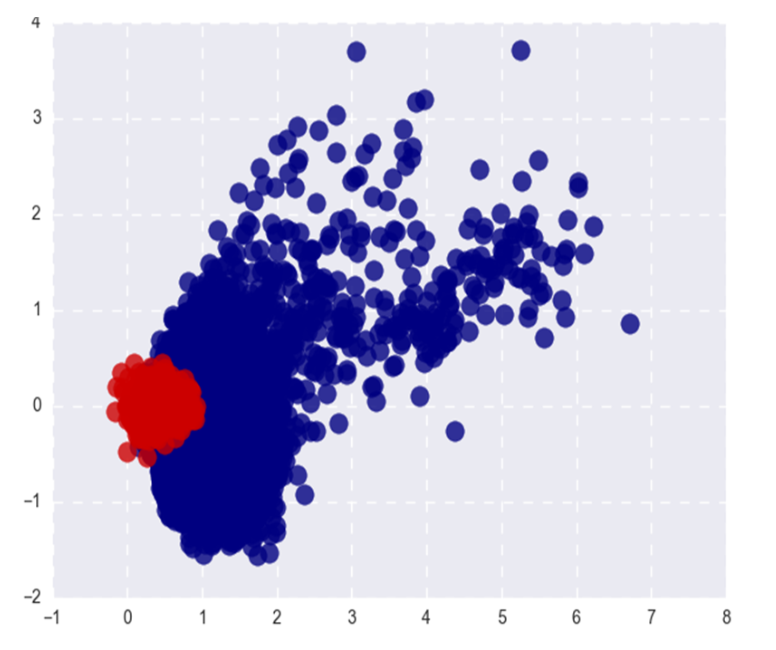
L'image montre les mots Word2Vec populaires (rouges) et rares (bleus) après SVD. Populaire ici fait référence aux 20% de mots les plus fréquents.
Si le problème ne concernait que les normes L2 des plongements, nous pourrions les normaliser et vivre heureux, mais, comme je l'ai dit dans le premier paragraphe, les mots rares sont également séparés des mots populaires par la proximité cosinus (en coordonnées polaires).
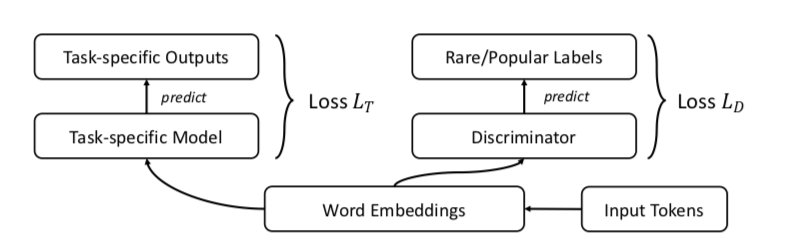
Les auteurs suggèrent, bien sûr, le GAN. Faisons la même chose qu'avant, mais ajoutons un discriminateur qui essaiera de faire la distinction entre les mots populaires et les mots rares (encore une fois, nous considérons que les n-premiers% des mots en fréquence sont populaires).
Cela ressemble à ceci:
Les auteurs testent l'approche sur les tâches de similitude de mots, de traduction automatique, de classification de texte et de modélisation de langage et partout où elles fonctionnent mieux que la ligne de base. Dans la similitude des mots, il est indiqué que la qualité augmente particulièrement sur les mots rares.
Un exemple: la citoyenneté. Problèmes de saut de gramme: bonheur, pakistans, rejet, renforcement. Problèmes FRAGE: population, städtischen, dignité, bürger. Les mots citoyen et citoyens dans FRAGE sont respectivement en 79e et 7e places (à proximité de la citoyenneté), en saut de gramme ils ne sont pas dans le top 10000.
Pour une raison quelconque, les auteurs ont publié le code uniquement pour la traduction automatique et la modélisation de la langue, la similitude des mots et les tâches de classification de texte dans le référentiel, malheureusement, ne sont pas représentés.
Alignement intermodal non supervisé des espaces d'intégration de la parole et du texteRésuméCode: pas de code, mais j'aimerais
Des études récentes ont montré que deux espaces vectoriels formés à l'aide d'algorithmes d'intégration (par exemple, word2vec) sur des corps de texte dans deux langues différentes peuvent être mis en correspondance sans marquage ni correspondance de contenu entre les deux bâtiments. En particulier, cette approche est utilisée pour la traduction automatique sur Facebook. L'une des propriétés clés de l'intégration des espaces est utilisée: à l'intérieur, des mots similaires doivent être géométriquement proches et des mots différents, au contraire, doivent être éloignés les uns des autres. On suppose que, en général, la structure de l'espace vectoriel est préservée quelle que soit la langue dans laquelle le corpus était destiné à l'enseignement.
Les auteurs de l'article sont allés plus loin et ont appliqué une approche similaire dans le domaine de la reconnaissance et de la traduction automatiques de la parole. Il est proposé de former l'espace vectoriel séparément pour le corpus de texte dans la langue d'intérêt (par exemple, Wikipedia), séparément pour le corpus de la parole enregistrée (au format audio), éventuellement dans une autre langue, préalablement décomposée en mots, puis de comparer ces deux espaces de la même manière qu'avec deux cas de texte.
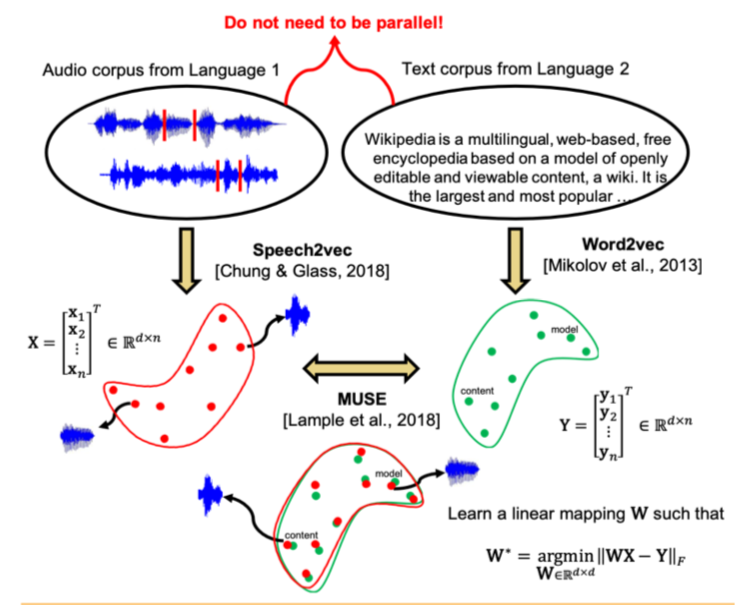
Pour le corpus de texte, word2vec est utilisé, et pour la parole, une approche similaire, appelée par Speech2vec, est basée sur LSTM et les méthodologies utilisées pour word2vec (CBOW / skip-gram), il est donc supposé qu'il combine les mots précisément par des caractéristiques contextuelles et sémantiques, et ne sonne pas.
Une fois que les deux espaces vectoriels ont été formés et qu'il y a deux ensembles de plongements - S (sur le corps du discours), composé de n incorporations de dimension d1 et T (sur le corps du texte), composé de m incorporations de dimension d2, vous devez les comparer. Idéalement, nous avons un dictionnaire qui détermine quel vecteur de S correspond à quel vecteur de T. Ensuite, deux matrices sont formées pour comparaison: k plongements sont sélectionnés parmi S, qui forment une matrice X de taille d1 xk; à partir de T, k plongements correspondants (selon le dictionnaire) précédemment sélectionnés à partir de S sont également sélectionnés, et une matrice Y de taille d2 x k est obtenue. Ensuite, vous devez trouver un mappage linéaire W tel que:
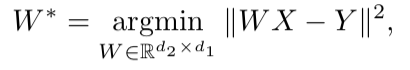
Mais comme l'article considère l'approche non supervisée, il n'y a initialement pas de dictionnaire, par conséquent, une procédure pour générer un dictionnaire synthétique, composé de deux parties, est proposée. Premièrement, nous obtenons la première approximation de W en utilisant l'entraînement par domaine (un modèle compétitif comme GAN, mais au lieu du générateur - une cartographie linéaire de W, avec laquelle nous essayons de rendre S et T indiscernables les uns des autres, et le discriminateur essaie de déterminer l'origine réelle de l'intégration). Ensuite, sur la base des mots dont les plongements ont montré la meilleure correspondance entre eux et se trouvent le plus souvent dans les deux bâtiments, un dictionnaire est formé. Après cela, le raffinement de W conformément à la formule ci-dessus se produit.
Cette approche donne des résultats comparables à l'apprentissage sur des données étiquetées, ce qui peut être très utile dans la tâche de reconnaissance et de traduction de la parole de langues rares pour lesquelles il y a trop peu de cas de parole / texte parallèles, ou ils sont absents.
Détection d'anomalies profondes à l'aide de transformations géométriquesRésuméCodeUne approche assez inhabituelle dans la détection des anomalies, qui, selon les auteurs, défait grandement les autres approches.
L'idée est la suivante: imaginons K différentes transformations géométriques (combinaison de décalages, rotation à 90 degrés et réflexion) et appliquons-les à chaque image de l'ensemble de données d'origine. L'image obtenue à la suite de la i-ème transformation appartiendra désormais à la classe i, c'est-à-dire qu'il y aura K classes au total, chacune d'entre elles sera représentée par le nombre d'images qui étaient à l'origine dans l'ensemble de données. Nous allons maintenant enseigner une classification multiclasse sur un tel balisage (les auteurs ont choisi un large resnet).
Nous pouvons maintenant obtenir K vecteurs y (Ti (x)) de dimension K pour une nouvelle image, où Ti est la i-ème transformation, x est l'image, y est la sortie du modèle. La définition de base de la «normalité» est la suivante:
Ici, pour l'image x, nous avons ajouté les probabilités prédites des classes correctes pour toutes les transformations. Plus la «normalité» est élevée, plus il est probable que l'image soit tirée de la même distribution que l'échantillon d'apprentissage. Les auteurs affirment que cela fonctionne déjà très bien, mais offrent néanmoins un moyen plus complexe qui fonctionne encore un peu mieux. Nous supposerons que le vecteur y (Ti (x)) pour chaque transformation de Ti est distribué par
Dirichlet et nous prendrons le logarithme de vraisemblance comme mesure de la «normalité» de l'image. Les paramètres de distribution de Dirichlet sont estimés sur un ensemble d'apprentissage.
Les auteurs rapportent l'incroyable augmentation des performances par rapport à d'autres approches.
Un cadre unifié simple pour détecter les échantillons hors distribution et les attaques contradictoiresRésuméCodeL'identification dans l'échantillon pour l'application du modèle de cas significativement différent de la distribution de l'échantillon de formation est l'une des principales exigences pour obtenir des résultats de classification fiables. Dans le même temps, les réseaux de neurones sont connus pour leur fonctionnalité avec un haut degré de confiance (et de manière incorrecte) pour classer les objets qui n'ont pas été rencontrés lors de l'entraînement ou intentionnellement corrompus (exemples contradictoires).
Les auteurs de l'article proposent une nouvelle méthode pour identifier à la fois ces cas et d'autres «mauvais» cas. L'approche est mise en œuvre comme suit: d'abord, un réseau de neurones avec la sortie softmax habituelle est formé, puis la sortie de son avant-dernière couche est prise, et le classificateur génératif est formé sur elle. Soit x - qui est appliqué à l'entrée du modèle pour un objet de classification particulier, y - l'étiquette de classe correspondante, puis supposons que nous avons un classificateur softmax pré-formé de la forme:
Où wc et bc sont les poids et constantes de la couche softmax pour la classe c, et f (.) Est la sortie de l'avant-dernier soya DNN.
De plus, sans aucune modification du classificateur pré-formé, une transition est effectuée vers le classificateur génératif, à savoir l'analyse discriminante. On suppose que les entités issues de l'avant-dernière couche du classificateur softmax ont une distribution normale multidimensionnelle, dont chaque composante correspond à une classe. Ensuite, la distribution conditionnelle peut être spécifiée à travers le vecteur de moyennes de la distribution multidimensionnelle et sa matrice de covariance:
Pour évaluer les paramètres du classificateur génératif, des moyennes empiriques sont calculées pour chaque classe, ainsi que la covariance des cas de l'échantillon d'apprentissage {(x1, y1), ..., (xN, yN)}:
où N est le nombre de cas de la classe correspondante dans l'ensemble d'apprentissage. Ensuite, une mesure de fiabilité est calculée sur l'échantillon de test - la distance de Mahalanobis entre le cas de test et la distribution de classe normale la plus proche de ce cas.
Il s'est avéré qu'une telle métrique fonctionnait de manière beaucoup plus fiable sur des objets atypiques ou endommagés, sans donner d'estimations élevées, comme la couche softmax. Dans la plupart des comparaisons sur différentes données, la méthode proposée a montré des résultats qui dépassaient l'état actuel de la technique pour trouver les deux cas qui n'étaient pas dans la formation et intentionnellement gâtés.
De plus, les auteurs envisagent une autre application intéressante de leur méthodologie: utiliser le classificateur génératif pour mettre en évidence de nouvelles classes qui n'étaient pas en formation sur le test, puis mettre à jour les paramètres du classificateur lui-même afin qu'il puisse déterminer cette nouvelle classe à l'avenir.
Exemples contradictoires qui trompent à la fois la vision par ordinateur et les humains limités dans le tempsRésumé:
https://arxiv.org/abs/1802.08195Les auteurs examinent quels sont les exemples contradictoires en termes de perception humaine. Aujourd'hui, il n'est étonnant pour personne que vous ne puissiez presque jamais changer l'image pour que le réseau fasse des erreurs dessus. Cependant, il n'est pas très clair à quel point l'image originale diffère de l'exemple contradictoire pour une personne et si elle diffère du tout. Il est clair qu'aucune personne n'appellera l'image de droite une autruche, mais peut-être que l'image de droite pour une personne n'est pas complètement identique à l'image de gauche et, si tel est le cas, une personne peut également faire l'objet d'attaques accusatoires. Les auteurs tentent d'évaluer dans quelle mesure une personne sera capable de classer des exemples contradictoires. Pour obtenir des exemples contradictoires, on utilise une technique qui n'a pas accès à l'architecture du réseau source (la logique des auteurs est qu'ils n'auront de toute façon pas accès à l'architecture du cerveau humain).Ainsi, une personne se voit montrer un exemple contradictoire, comme dans l'image ci-dessus, et est invitée à le classer. Il est clair que dans des conditions normales, le résultat serait prévisible, mais ici, une image est montrée à une personne dans les 63 millisecondes, après quoi elle doit choisir l'une des deux classes. Dans de telles conditions, la précision des images source était 10% plus élevée que celle de la confrontation. En principe, cela pourrait s'expliquer par le fait que l'image contradictoire est simplement bruyante et donc, dans des conditions de pression temporelle, les gens la classent incorrectement, mais cela réfute l'expérience suivante. Si avant d'ajouter une perturbation à l'image, nous reflétons cette perturbation verticalement, alors la précision ne changera guère par rapport à l'image d'origine.
Les auteurs tentent d'évaluer dans quelle mesure une personne sera capable de classer des exemples contradictoires. Pour obtenir des exemples contradictoires, on utilise une technique qui n'a pas accès à l'architecture du réseau source (la logique des auteurs est qu'ils n'auront de toute façon pas accès à l'architecture du cerveau humain).Ainsi, une personne se voit montrer un exemple contradictoire, comme dans l'image ci-dessus, et est invitée à le classer. Il est clair que dans des conditions normales, le résultat serait prévisible, mais ici, une image est montrée à une personne dans les 63 millisecondes, après quoi elle doit choisir l'une des deux classes. Dans de telles conditions, la précision des images source était 10% plus élevée que celle de la confrontation. En principe, cela pourrait s'expliquer par le fait que l'image contradictoire est simplement bruyante et donc, dans des conditions de pression temporelle, les gens la classent incorrectement, mais cela réfute l'expérience suivante. Si avant d'ajouter une perturbation à l'image, nous reflétons cette perturbation verticalement, alors la précision ne changera guère par rapport à l'image d'origine.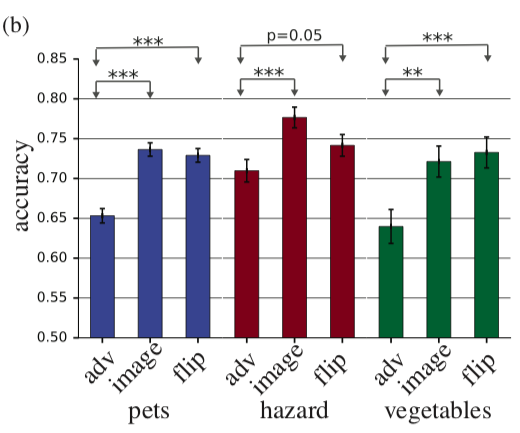 Sur l'histogramme, adv est un exemple contradictoire, l'image est l'image originale, flip est l'image originale + perturbation contradictoire, réfléchie verticalement.Contrôles de santé mentale pour les cartes de saillanceL'interprétation du modèle abstrait est l'un des sujets les plus discutés aujourd'hui. En ce qui concerne l'apprentissage en profondeur, ils parlent généralement de cartes de saillance. Les cartes de saillance tentent de répondre à la question de savoir comment la valeur change à l'une des sorties de la grille lorsque les valeurs d'entrée changent. Cela peut ressembler à une carte de saillance, qui montre quels pixels ont influencé le fait que l'image a été classée comme un «chien».
Sur l'histogramme, adv est un exemple contradictoire, l'image est l'image originale, flip est l'image originale + perturbation contradictoire, réfléchie verticalement.Contrôles de santé mentale pour les cartes de saillanceL'interprétation du modèle abstrait est l'un des sujets les plus discutés aujourd'hui. En ce qui concerne l'apprentissage en profondeur, ils parlent généralement de cartes de saillance. Les cartes de saillance tentent de répondre à la question de savoir comment la valeur change à l'une des sorties de la grille lorsque les valeurs d'entrée changent. Cela peut ressembler à une carte de saillance, qui montre quels pixels ont influencé le fait que l'image a été classée comme un «chien». Les auteurs posent une question très raisonnable: "Comment validerions-nous les méthodes de construction des cartes de saillance?" Deux points évidents sont avancés et proposés à vérifier:
Les auteurs posent une question très raisonnable: "Comment validerions-nous les méthodes de construction des cartes de saillance?" Deux points évidents sont avancés et proposés à vérifier:- La carte de saillance devrait dépendre des poids de la grille
- Saliency map ,
Nous vérifierons la première thèse en remplaçant les poids dans la grille formée par un aléatoire: randomisation en cascade (randomiser les couches à partir de la dernière et voir comment la carte de saillance change) et randomisation indépendante (randomiser une couche spécifique). Nous allons vérifier la deuxième thèse comme ceci: mélanger au hasard toutes les étiquettes sur le train, équiper le train et regarder les cartes de saillance.Si la méthode de construction d'une carte de saillance est vraiment bonne et vous permet de comprendre comment fonctionne le modèle, de telles randomisations devraient changer considérablement les cartes de saillance. Cependant: «À notre grande surprise, certaines méthodes de saillance largement déployées sont indépendantes à la fois des données sur lesquelles le modèle a été formé et des paramètres du modèle», déclarent les auteurs. Ici, par exemple, ressemble à des cartes de saillance obtenues à l'aide de divers algorithmes après randomisation en cascade: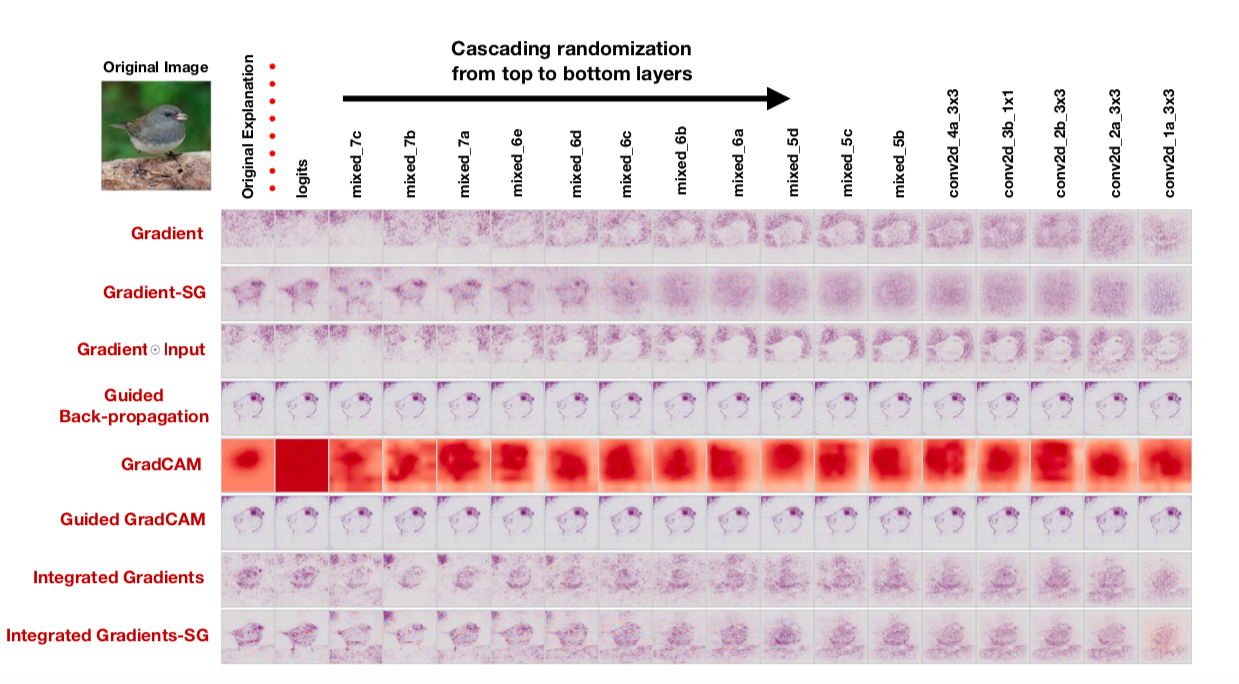 Notez le fait amusant que la dernière colonne correspond à une grille avec des poids aléatoires dans toutes les couches. Autrement dit, la grille prédit au hasard, mais certaines cartes de saillance dessinent toujours un oiseau.Les auteurs disent à juste titre que - une évaluation des cartes de saillance par leur compréhensibilité et leur logique et une attention insuffisante à la manière dont le résultat est généralement lié au fonctionnement du modèle conduit à un biais de confirmation. Apparemment, y compris pour cette raison, il s'avère que les approches communes à l'interprétation des modèles ne les interprètent pas du tout.Une défaillance intrigante des réseaux de neurones convolutifs et de la solution CoordConvRésumé: https://arxiv.org/abs/1807.03247Code: il existe déjà de nombreuses implémentations et en général l'idée est si belle et simple qu'elle est écrite littéralement en 10 lignes.Facile à mettre en œuvre et idée prometteuse d'Uber. Les réseaux convolutifs ont été initialement affinés pour l'invariance de cisaillement, de sorte que les tâches associées à la détermination des coordonnées d'un objet sont très difficiles pour de tels réseaux. Les réseaux convolutionnels conventionnels ne sont même pas capables de résoudre des problèmes de jouets tels que la détermination des coordonnées d'un point dans une image ou le dessin d'un point par des coordonnées:
Notez le fait amusant que la dernière colonne correspond à une grille avec des poids aléatoires dans toutes les couches. Autrement dit, la grille prédit au hasard, mais certaines cartes de saillance dessinent toujours un oiseau.Les auteurs disent à juste titre que - une évaluation des cartes de saillance par leur compréhensibilité et leur logique et une attention insuffisante à la manière dont le résultat est généralement lié au fonctionnement du modèle conduit à un biais de confirmation. Apparemment, y compris pour cette raison, il s'avère que les approches communes à l'interprétation des modèles ne les interprètent pas du tout.Une défaillance intrigante des réseaux de neurones convolutifs et de la solution CoordConvRésumé: https://arxiv.org/abs/1807.03247Code: il existe déjà de nombreuses implémentations et en général l'idée est si belle et simple qu'elle est écrite littéralement en 10 lignes.Facile à mettre en œuvre et idée prometteuse d'Uber. Les réseaux convolutifs ont été initialement affinés pour l'invariance de cisaillement, de sorte que les tâches associées à la détermination des coordonnées d'un objet sont très difficiles pour de tels réseaux. Les réseaux convolutionnels conventionnels ne sont même pas capables de résoudre des problèmes de jouets tels que la détermination des coordonnées d'un point dans une image ou le dessin d'un point par des coordonnées: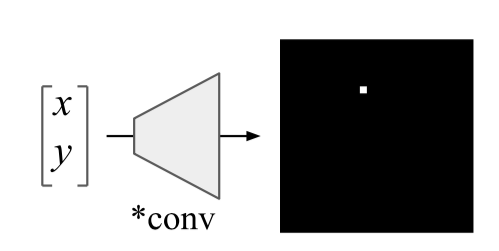 Un hack très élégant est proposé: ajoutez deux matrices i et j à l'image (en général, à l'entrée de la couche CoodrConv), dans laquelle contient les coordonnées verticales et horizontales des pixels correspondants:
Un hack très élégant est proposé: ajoutez deux matrices i et j à l'image (en général, à l'entrée de la couche CoodrConv), dans laquelle contient les coordonnées verticales et horizontales des pixels correspondants: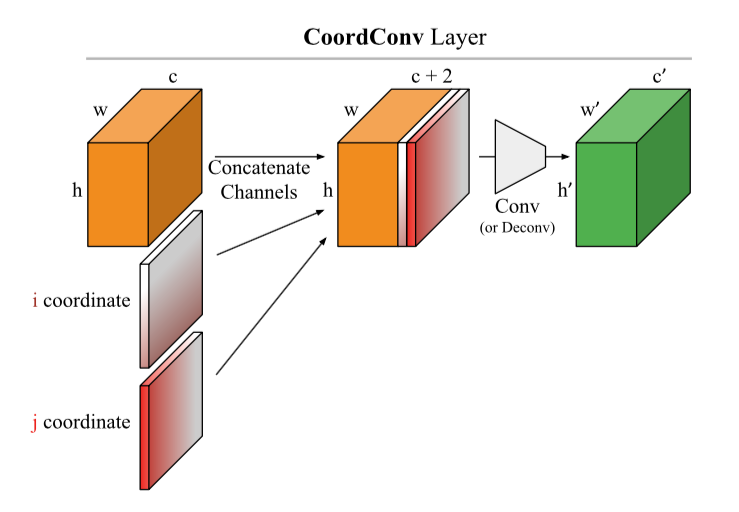 On prétend que:
On prétend que:- ImageNet'. , , , ,
- CoordConv object detection. MNIST, Faster R-CNN, IoU 21%
- CoordConv GAN .
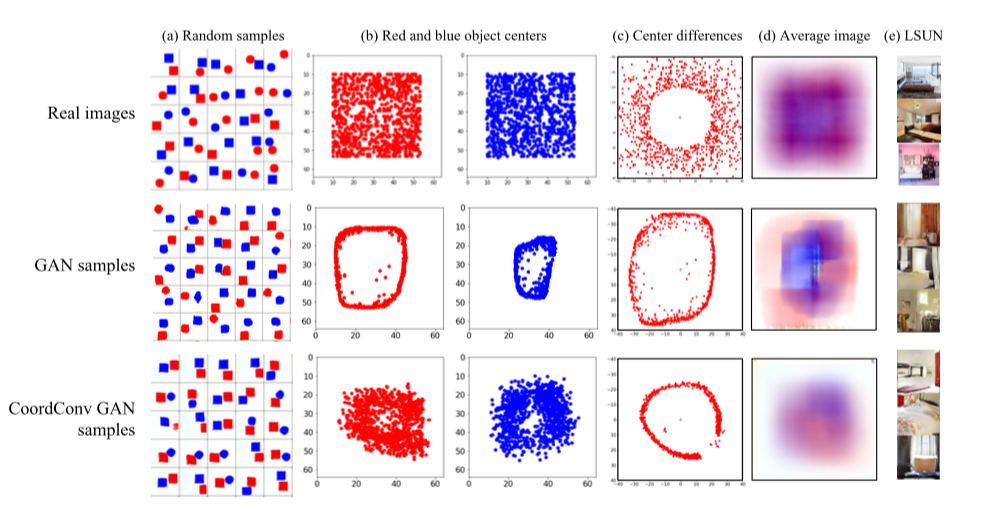
GAN' : LSUN. , — c. , GAN' , , . CoordConv , . LSUN d , , CoordConv GAN,
- 4. L'utilisation de CoordConv dans A2C donne une augmentation dans certains jeux (pas tous).
Personnellement, je suis le plus intéressé par ce deuxième point, j'aimerais voir les résultats sur de vrais ensembles de données, mais rien n'est googlé tout de suite. Pendant ce temps, CoordConv est déjà très activement intégré dans le réseau Internet : https://arxiv.org/abs/1812.01429, https://www.kaggle.com/c/tgs-salt-identification-challenge/discussion/69274 , https: //github.com/mjDelta/Kaggle-RSNA-Pneumonia-Detection-Challenge .Il y a une bonne vidéo plus détaillée de l'auteur .Régularisation par la variance du codeabstrait d' échantillon-variances des activationsLes auteurs offrent une alternative amusante à la normalisation par lots. Nous affinerons la grille pour la variabilité de la dispersion des activations sur une couche. En pratique, ils l'implémentent comme ceci: prenez deux sous-ensembles disjoints S1 et S2 du lot et calculez une telle chose:où σ2 sont des variances d'échantillon dans S1 et S2, respectivement, β est le coefficient positif entraîné. Les auteurs appellent cette chose la perte de constance de la variance (VCL) et l'ajoutent à la perte totale.
Dans la section sur les expériences, les auteurs se plaignent de la façon dont les résultats des articles d'autres personnes ne sont pas reproduits et s'engagent à mettre en place un code reproductible (présenté). Tout d'abord, ils ont expérimenté avec un petit maillage à 11 couches sur l'ensemble de données de petites images (CIFAR-10 et CIFAR-100). Nous avons obtenu que VCL prouve, si vous utilisez Leaky ReLU ou ELU comme activations, mais la normalisation par lots fonctionne mieux avec ReLU. Ensuite, ils augmentent le nombre de couches de 2 fois et passent à Tiny Imagenet - une version simplifiée d'Imagenet avec 200 classes et une résolution de 64x64. En validation, VCL surpasse la normalisation par lots sur la grille avec ELU, ainsi que ResNet-110 et DenseNet-40, mais surpasse Wide-ResNet-32. Un point intéressant est que les meilleurs résultats sont obtenus lorsque les sous-ensembles S1 et S2 sont constitués de deux échantillons.
De plus, les auteurs testent la VCL dans les réseaux à action directe et la VCL gagne un peu plus souvent qu'un réseau avec normalisation par lots ou sans régularisation.
DropMax: Softmax variationnel adaptatifRésuméCodeIl est proposé dans le problème de classification multiclasse à chaque itération de la descente de gradient pour chaque échantillon de supprimer aléatoirement un certain nombre de classes incorrectes. De plus, la probabilité avec laquelle nous abandonnons l'une ou l'autre classe pour tel ou tel objet est également en cours d'apprentissage. En conséquence, il s'avère que le réseau «se concentre» sur la distinction entre les classes les plus difficiles à séparer.
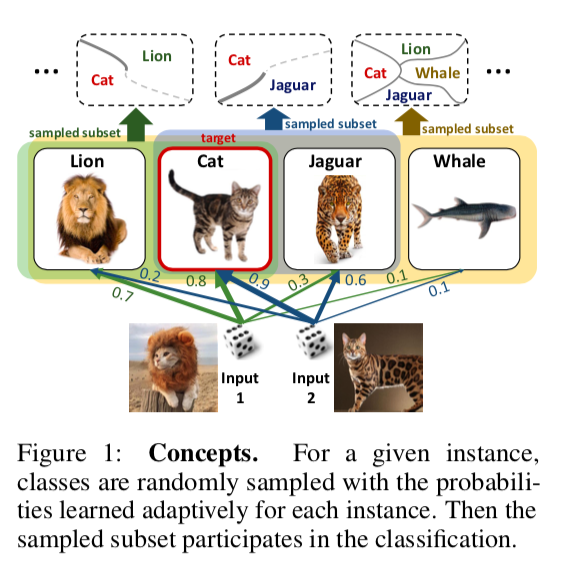
Des expériences sur les sous-ensembles MNIST, CIFAR et Imagenet montrent que DropMax fonctionne mieux que SoftMax standard et certaines de ses modifications.
Modèles intelligibles précis avec interactions par paires(Les amis ne laissent pas les amis déployer des modèles de boîte noire: l'importance de l'intelligibilité dans l'apprentissage automatique)
Résumé:
http://www.cs.cornell.edu/~yinlou/papers/lou-kdd13.pdfCode: il n'est pas là. Je suis très intéressé par la façon dont les auteurs imprègnent un nom aussi impératif avec un manque de code. Académiciens, monsieur =)
Vous pouvez consulter ce package, par exemple:
https://github.com/dswah/pyGAM . Des interactions de fonctionnalités y ont été ajoutées il n'y a pas si longtemps (ce qui distingue en fait GAM de GA2M).
Cet article a été présenté dans le cadre de l'atelier «Interprétabilité et robustesse de l'audio, de la parole et du langage», bien qu'il soit consacré à l'interprétabilité des modèles en général, et non au domaine de l'analyse du son et de la parole. Probablement, tout le monde a été confronté dans une certaine mesure au dilemme de choisir entre l'interprétabilité et sa précision. Si nous utilisons la régression linéaire habituelle, nous pouvons comprendre par les coefficients comment chaque variable indépendante affecte la personne à charge. Si nous utilisons des modèles à boîte noire, par exemple, l'augmentation du gradient sans restrictions sur la complexité ou les réseaux de neurones profonds, un modèle correctement réglé sur des données appropriées sera très précis, mais le suivi et l'explication de tous les modèles que le modèle trouvé dans les données sera problématique. Par conséquent, il sera difficile d'expliquer le modèle au client et de savoir s'il a appris quelque chose que nous n'aimerions pas. Le tableau ci-dessous fournit des estimations de l'interprétabilité et de la précision relatives de divers types de modèles.

Un exemple de situation où une mauvaise interprétabilité du modèle est associée à de grands risques: sur l'un des ensembles de données médicales, le problème de prédire la probabilité du patient de mourir d'une pneumonie a été résolu. Le schéma intéressant suivant a été trouvé dans les données: si une personne souffre d'asthme bronchique, la probabilité de mourir d'une pneumonie est plus faible que chez les personnes sans cette maladie. Lorsque les chercheurs se sont tournés vers les médecins praticiens, il s'est avéré qu'un tel schéma existe vraiment, car les personnes souffrant d'asthme dans le cas de la pneumonie reçoivent l'aide la plus rapide et des médicaments puissants. Si nous avions formé xgboost sur cet ensemble de données, il aurait probablement détecté ce schéma, et notre modèle classerait les patients asthmatiques comme un groupe à faible risque et, en conséquence, leur recommanderait une priorité et une intensité de traitement inférieures.
Les auteurs de l'article proposent une alternative à la fois interprétable et précise - il s'agit du GA2M, une sous-espèce de modèles additifs généralisés.
Le GAM classique peut être considéré comme une généralisation supplémentaire du GLM: un modèle est une somme dont chaque terme reflète l'influence d'une seule variable indépendante sur la personne à charge, mais l'influence n'est pas exprimée par un coefficient de pondération, comme dans le GLM, mais par une fonction non paramétrique lisse (en règle générale, définie par morceaux fonctions - cannelures ou arbres de faible profondeur, y compris les "souches"). Grâce à cette fonctionnalité, les GAM peuvent modéliser des relations plus complexes qu'un simple modèle linéaire. D'un autre côté, les dépendances (fonctions) apprises peuvent être visualisées et interprétées.
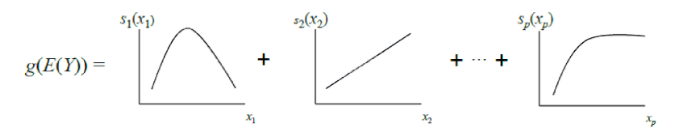
Cependant, les GAM standard n'atteignent toujours pas la précision des algorithmes de boîte noire. Pour y remédier, les auteurs de l'article proposent un compromis - ajouter à l'équation du modèle, en plus des fonctions d'une variable, un petit nombre de fonctions de deux variables - des couples soigneusement sélectionnés dont l'interaction est significative pour prédire la variable dépendante. Ainsi, GA2M est obtenu.
Tout d'abord, un GAM standard est construit (sans tenir compte de l'interaction des variables), puis des paires de variables sont ajoutées étape par étape (le GAM restant est utilisé comme variable cible). Dans le cas où il y a beaucoup de variables et la mise à jour du modèle après chaque étape est difficile à calculer, un algorithme de classement FAST est proposé, avec lequel vous pouvez présélectionner des paires potentiellement utiles et éviter une énumération complète.
Cette approche nous permet d'atteindre une qualité proche de modèles d'une complexité illimitée. Le tableau montre le taux d'erreur des modèles additifs généralisés par rapport à une forêt aléatoire pour résoudre le problème de classification sur différents ensembles de données, et dans la plupart des cas, la qualité de la prévision pour GA2M avec FAST et pour les forêts aléatoires n'est pas significativement différente.
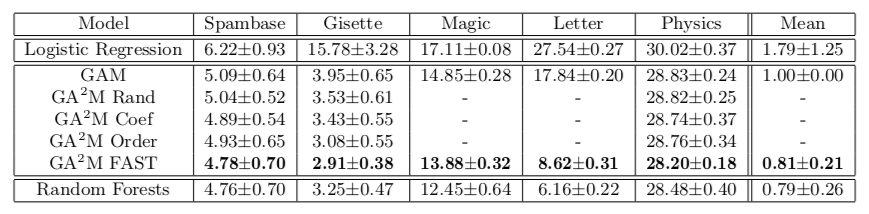
Je voudrais attirer l'attention sur les caractéristiques du travail des universitaires qui proposent d'envoyer ces boostings et lerings profonds au four. Veuillez noter que les jeux de données sur lesquels les résultats sont présentés ne contiennent pas plus de 20 000 objets (tous les jeux de données du référentiel UCI). Une question naturelle se pose: n'y a-t-il vraiment pas de jeu de données ouvert de taille normale pour de telles expériences en 2018? Vous pouvez aller plus loin et comparer sur un ensemble de données de 50 objets - il est possible que le modèle constant ne diffère pas de manière significative d'une forêt aléatoire.
Le point suivant est la régularisation. Sur un grand nombre de signes, il est très facile de se recycler même sans interactions. Les auteurs peuvent croire que ce problème n'existe pas, et le seul problème est le modèle de boîte noire. Au moins dans l'article, la régularisation n'est évoquée nulle part, bien qu'elle soit évidemment nécessaire.
Et le dernier, sur l'interprétabilité. Même les modèles linéaires ne sont pas interprétables si nous avons beaucoup de fonctionnalités. Lorsque vous avez 10 000 poids normalement distribués (dans le cas de l'utilisation de la régularisation L2, ce sera quelque chose comme ça), il est impossible de dire exactement quels signes sont responsables du fait que predite_proba donne 0,86. Pour l'interprétabilité, nous voulons non seulement un modèle linéaire, mais un modèle linéaire avec des poids clairsemés. Il semblerait que cela puisse être réalisé par la régularisation L1, mais ici aussi, ce n'est pas si simple. À partir d'un ensemble de caractéristiques fortement corrélées, la régularisation L1 en choisira une presque par accident. Le reste aura un poids de 0, bien que si l'une de ces fonctionnalités a une capacité prédictive, les autres ne sont clairement pas uniquement du bruit. En termes d'interprétation du modèle, cela peut être OK, en termes de compréhension de la relation entre les caractéristiques et la variable cible, c'est très mauvais. Autrement dit, même avec des modèles linéaires, tout n'est pas si simple, plus de détails sur les modèles interprétables et crédibles peuvent être trouvés
ici .
Visualisation pour l'apprentissage automatique: UMAPAbsractCodeLe jour des tutoriels, l'un des premiers à être exécuté était "Visualisation pour Machine Learning" par Google Brain. Dans le cadre du didacticiel, nous avons été informés de l'histoire des visualisations, à partir du créateur des premiers graphiques, ainsi que des différentes caractéristiques du cerveau humain et de la perception et des techniques qui peuvent être utilisées pour attirer l'attention sur la chose la plus importante de l'image, contenant même de nombreux petits détails - par exemple, la mise en évidence forme, couleur, cadre, etc., comme dans l'image ci-dessous. Je vais sauter cette partie, mais il y a une
bonne critique .

Personnellement, j'étais le plus intéressé par le sujet de la visualisation d'ensembles de données multidimensionnels, en particulier, l'approche Uniform Manifold Approximation and Projection (UMAP) - une nouvelle méthode non linéaire de réduction de dimension. Il a été proposé en février de cette année, donc peu de gens l'utilisent encore, mais il semble prometteur tant en termes de temps de travail qu'en termes de qualité de séparation des classes dans les visualisations bidimensionnelles. Ainsi, sur différents ensembles de données, l'UMAP est 2 à 10 fois plus rapide que le t-SNE et les autres méthodes en termes de vitesse, et plus la dimension des données est grande, plus l'écart de performances est important:
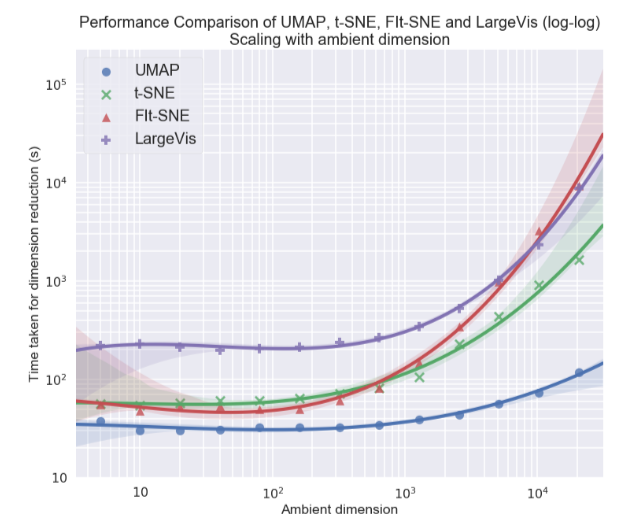
De plus, contrairement au t-SNE, le temps de fonctionnement UMAP est presque indépendant de la dimension du nouvel espace dans lequel nous allons intégrer notre jeu de données (voir la figure ci-dessous), ce qui en fait un outil approprié pour d'autres tâches (en plus de la visualisation) - en particulier, réduire la dimension avant d'entraîner le modèle.
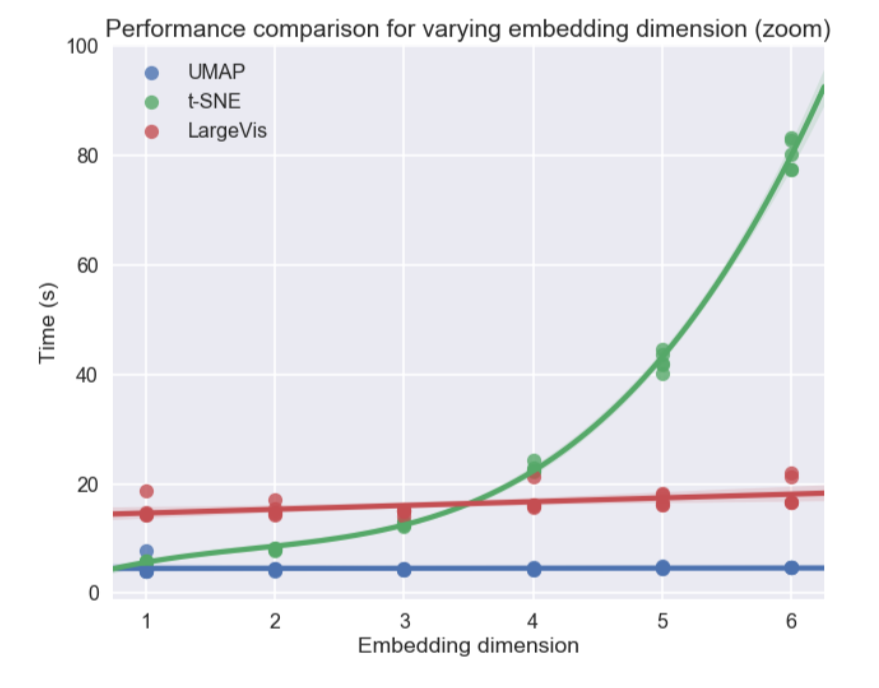
Dans le même temps, les tests sur différents ensembles de données ont montré que l'UMAP ne fonctionnait pas moins bien pour la visualisation, et t-SNE est meilleur par endroits: par exemple, sur les ensembles de données MNIST et Fashion MNIST, les classes sont mieux séparées dans la version avec UMAP:
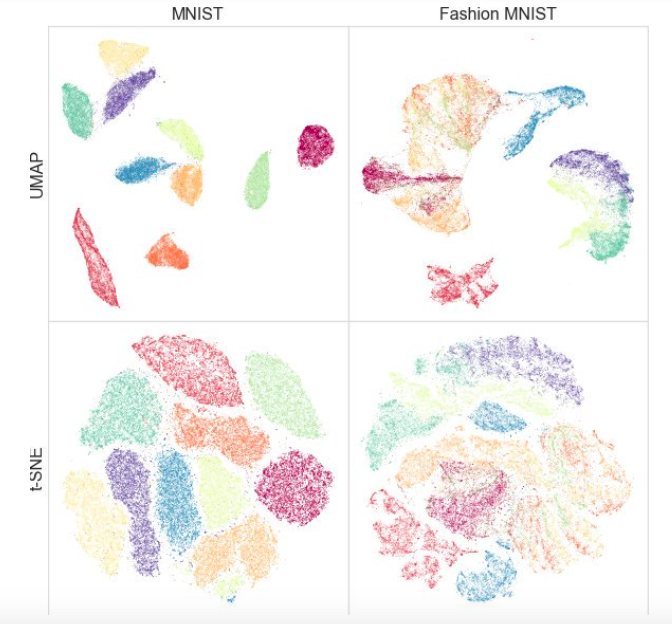
Un avantage supplémentaire est une implémentation pratique: la classe UMAP hérite des classes sklearn, vous pouvez donc l'utiliser comme un transformateur normal dans le pipeline sklearn. En outre, il est avancé que l'UMAP est plus interprétable que le t-SNE, car maintient mieux une structure de données globale.
À l'avenir, les auteurs prévoient d'ajouter un support pour la formation semi-supervisée - c'est-à-dire que si nous avons des balises pour au moins certains des objets, nous pouvons construire UMAP sur la base de ces informations.
Quels articles avez-vous aimé? Écrivez des commentaires, posez des questions, nous y répondrons.