Nous continuons d'expérimenter avec les formats des mitaps. Récemment, dans un ring de boxe, nous sommes
entrés en collision avec un bus de données centralisé et un maillage de service. Cette fois, nous avons décidé d'essayer quelque chose de plus paisible - StandUp, c'est-à-dire un microphone ouvert. Le sujet a été choisi dans la base de données en mémoire.

Dans quels cas dois-je passer en mémoire? Comment et pourquoi évoluer? Et à quoi vaut-il attention? Les réponses se trouvent dans les discours des orateurs, que nous couvrirons dans cet article.
Mais d'abord, imaginez les haut-parleurs:
- Andrey Trushkin, directeur du Centre pour l'innovation et les technologies avancées de Promsvyazbank
- Vladislav Shpileva, développeur Tarantool
- Artyom Shitov, architecte de la solution GridGain
Passer en mémoire
Les tendances actuelles du marché financier imposent des exigences beaucoup plus strictes sur le temps de réponse et le fonctionnement de l'automatisation des processus en général. De plus, presque toutes les plus grandes institutions financières cherchent aujourd'hui à construire leurs propres écosystèmes.
À cet égard, nous voyons par nous-mêmes deux applications principales des solutions en mémoire. Le premier est la mise en cache des données d'intégration. Selon le scénario classique, dans les grandes entreprises, il existe plusieurs systèmes automatisés qui fournissent des données à la demande de l'utilisateur. Ou un système externe - mais dans ce cas, l'initiateur dans la plupart des cas est l'utilisateur. Traditionnellement, ces systèmes stockaient des données structurées d'une certaine manière dans la base de données, y accédant à la demande.
Aujourd'hui, de tels systèmes ne répondent plus aux exigences en termes de charge. Ici, nous ne devons pas oublier les appels à distance de ces systèmes par des systèmes grand public. Cela implique la nécessité de revoir les approches de stockage et de présentation des données - aux utilisateurs, aux systèmes automatisés ou aux services individuels. Sortie logique - stockage des données pertinentes utilisées par les services au niveau de la couche en mémoire; il existe de nombreux cas similaires réussis sur le marché.
Ce fut le premier cas. La seconde est efficace, d'un point de vue technique, la gestion des processus métiers. Les systèmes BPM traditionnels automatisent l'exécution de certaines opérations conformément à un algorithme prédéfini. Et dans de nombreux cas, des questions se posent: pourquoi ces systèmes ne sont-ils pas assez efficaces et assez rapides?
En règle générale, ces systèmes écrivent chaque étape (ou un petit ensemble d'étapes, conçu comme une transaction commerciale) dans la base de données. Ils sont donc liés au temps de réponse et à l'interaction avec ces systèmes. Désormais, le nombre d'instances de processus métier s'exécutant simultanément en temps réel représente des ordres de grandeur il y a plus de 10 ans. Les systèmes modernes de gestion des processus métier devraient donc avoir des performances nettement supérieures et garantir l'exécution des applications décentralisées. De plus, aujourd'hui, toutes les entreprises s'orientent vers la formation d'un large environnement de microservices. Le défi est que différentes instances de processus métier peuvent partager et utiliser efficacement les données opérationnelles. Dans le cadre de l'orchestration, il est logique de les stocker dans une solution en mémoire.
Problème de réconciliation
Supposons que nous ayons un grand nombre de nœuds et de services, qu'un certain nombre de processus métier soient exécutés, dont les actions sont mises en œuvre sous forme de microservices. Pour améliorer les performances, chacun d'eux commence à écrire son état dans une instance de mémoire locale. Nous obtenons un grand nombre d'instances locales. Comment garantir la pertinence et la cohérence pour tous?
Nous utilisons le zonage des zones en mémoire. Par exemple, selon le domaine d'activité. Lorsque nous coupons un domaine métier, nous déterminons que certains microservices / processus métier ne fonctionnent que dans le cadre de la zone responsable du domaine correspondant. De cette façon, nous pouvons accélérer la mise à jour du cache et l'ensemble de la solution en mémoire.
Dans le même temps, le cache responsable du domaine fonctionne en mode de réplication complète - le nombre limité de nœuds en raison de la distribution entre les domaines garantit la vitesse et l'exactitude de la solution dans ce mode. Le zonage et la fragmentation maximale aident à résoudre les problèmes de synchronisation, de fonctionnement du cluster, etc. sur un grand nombre total de nœuds.
Naturellement, des questions se posent souvent sur la fiabilité des solutions en mémoire. Oui, tout ne peut pas y être mis. Afin d'assurer la fiabilité, nous avons toujours des bases de données à côté de la mémoire. Par exemple, pour les problèmes importants de reporting qui doivent être regroupés, ce qui peut être difficile sur un grand nombre de nœuds. Alors quelle est notre vision aujourd'hui: la
synergie des deux approches .
Il convient également de noter que ces deux approches ne sont pas non plus entièrement correctes uniquement pour le contraste. Et en même temps, concentrez-vous sur eux. Les fabricants et contributeurs de systèmes de virtualisation conteneurisés avancés, tels que Kubernetes, nous offrent déjà des options de stockage fiable à long terme. De bons cas industriels pour la mise en œuvre de solutions sont déjà apparus, dans lesquels le stockage est effectué dans un tel format virtualisé.
L'un des plus grands journaux américains offre à ses lecteurs la possibilité de recevoir en ligne tout numéro publié depuis le début de la publication de ce journal au XIXe siècle. On peut imaginer le niveau de charge. Le stockage est mis en œuvre par eux via la plateforme Apache Kafka, déployée sur Kubernetes. Voici une autre option pour stocker des informations et leur donner accès sous une charge importante à un grand nombre de clients. Lors de la conception de nouvelles solutions, cette option mérite également une attention particulière.
Mise à l'échelle des bases de données en mémoire avec Tarantool
Supposons que nous ayons un serveur. Il accepte les demandes, stocke les données. Soudain, il y a plus de demandes et de données, le serveur cesse de faire face à la charge. Vous pouvez télécharger plus de matériel sur le serveur et il acceptera plus de demandes. Mais c'est une impasse pour trois raisons à la fois: coût élevé, capacités techniques limitées et problèmes de tolérance aux pannes. Au lieu de cela, il y a une mise à l'échelle horizontale: des «amis» viennent sur le serveur pour l'aider à accomplir ses tâches. La réplication et le partitionnement sont les deux principaux types de mise à l'échelle horizontale.
La réplication, c'est quand il y a beaucoup de serveurs, ils stockent tous les mêmes données et les demandes des clients sont dispersées sur tous ces serveurs. C'est ainsi que l'informatique, et non les données, évolue. Cela fonctionne lorsque les données sont placées sur un nœud, mais il y a tellement de demandes de clients qu'un serveur ne peut pas les gérer. De plus, la tolérance aux pannes est considérablement améliorée ici.
Le partage est utilisé pour mettre à l'échelle les données: de nombreux serveurs sont créés et stockent des données différentes. Vous mettez donc à l'échelle les calculs et les données. Mais la tolérance aux pannes dans ce cas est faible. Si un serveur tombe en panne, une partie des données sera perdue.
Il existe une troisième approche: les combiner. Nous divisons le cluster en sous-clusters, appelons-les ensembles de répliques. Chacun d'entre eux stocke les mêmes données et les données ne se croisent pas entre les jeux de réplicas. Le résultat est la mise à l'échelle des données, du calcul et de la tolérance aux pannes.
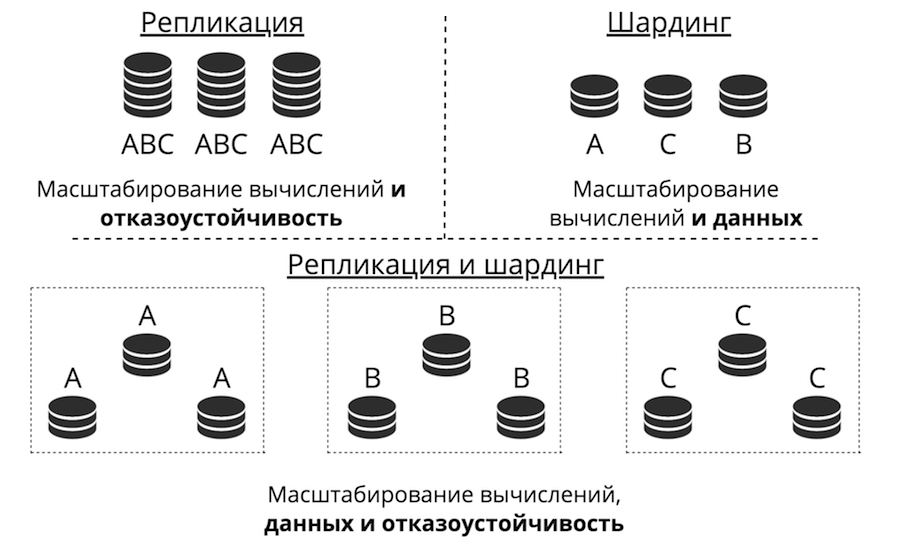
Réplication
La réplication peut être de deux types: asynchrone et synchrone. Asynchrone, c'est lorsque les demandes des clients n'attendent pas que les données soient dispersées sur les répliques: l'écriture sur une réplique suffit. Dès que les données sont arrivées sur disque, dans le journal, la transaction réussit et un jour en arrière-plan ces données sont répliquées. Synchrone - lorsqu'une transaction est divisée en 2 phases: préparation et validation. Commit ne renverra pas le succès tant que les données ne seront pas répliquées vers un quorum de réplicas.
La réplication asynchrone est évidemment plus rapide car rien ne repose sur le réseau. Les données seront envoyées au réseau en arrière-plan et la transaction elle-même, telle qu'elle est enregistrée dans le journal, est terminée. Mais il y a un problème: les répliques peuvent être en retard l'une par rapport à l'autre, désynchronisées.
La réplication synchrone est plus fiable, mais beaucoup plus lente et plus difficile à implémenter. Il existe des protocoles complexes. Dans Tarantool, vous pouvez choisir l'un de ces types de réplications, selon la tâche.

Le décalage des répliques entraîne non seulement la désynchronisation, mais aussi le problème d'ignorance du maître: il ne sait pas comment transmettre ses modifications à la réplique. Les modifications sont généralement apportées de manière incrémentielle - elles sont appliquées et, sous la même forme, elles s'envolent vers la réplique. Mais que faire avec eux si la réplique n'est pas disponible? Par exemple, tout peut être configuré dans Tarantool, et l'assistant devient très flexible.
Autre défi: comment rendre la topologie complexe? Mail.ru, par exemple, a une topologie avec des centaines de Tarantool. Il possède un noyau tarantool auquel les répliques de tarentules pour les sauvegardes sont liées en cercle. Dans Tarantool, vous pouvez créer des topologies complètement arbitraires, la réplication avec cela vit parfaitement.
Partage
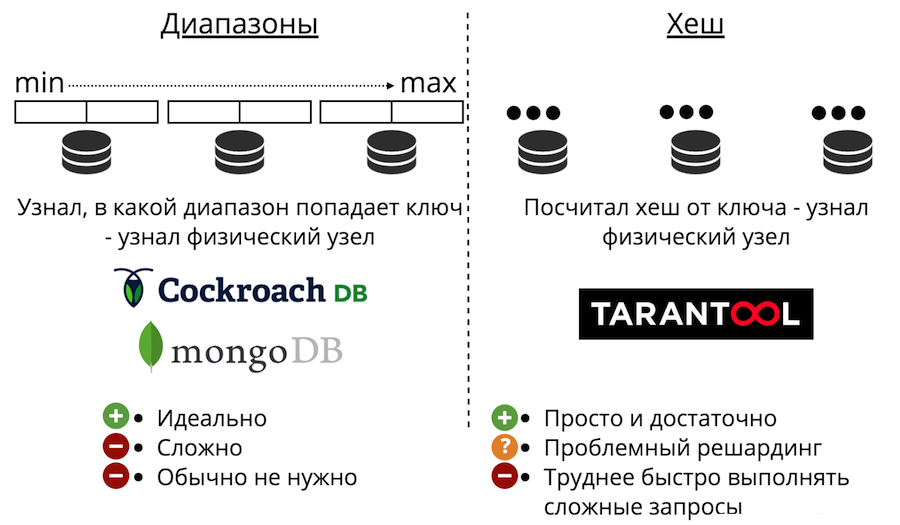
Passons maintenant à la mise à l'échelle des données: le sharding. Il peut être de deux types: plages et hachages. Le partage de plage est lorsque toutes les données sont triées par une clé de partage, et cette grande séquence est divisée en plages de sorte que chaque plage a approximativement la même quantité de données. Et chaque plage est entièrement stockée sur un seul nœud physique. Mais généralement, un tel découpage n'est pas nécessaire. De plus, c'est toujours très compliqué.
Il y a aussi des fragments avec des hachages. Il vient d'être présenté dans Tarantool. Il est beaucoup plus facile à implémenter, à utiliser et presque toujours adapté au lieu de plages de partage. Cela fonctionne comme ceci: nous considérons la fonction de hachage de l'enregistrement et elle renvoie le numéro du nœud physique dans lequel stocker. Il y a des problèmes: premièrement, il est difficile de terminer rapidement une requête complexe.
Deuxièmement, il y a le problème du resharding. Il existe une sorte de fonction de fragment qui renvoie le numéro du fragment physique dans lequel la clé doit être enregistrée. Et lorsque le nombre de nœuds change, la fonction de partition change également. Cela signifie que pour toutes les données qui sont dans le cluster, elles devront être recalculées et vérifiées à nouveau. De plus, dans le partage classique, certaines données ne seront pas transférées vers un nouveau nœud, mais simplement mélangées entre les anciens nœuds. Les transferts inutiles ne peuvent pas être réduits à zéro dans le partage classique.
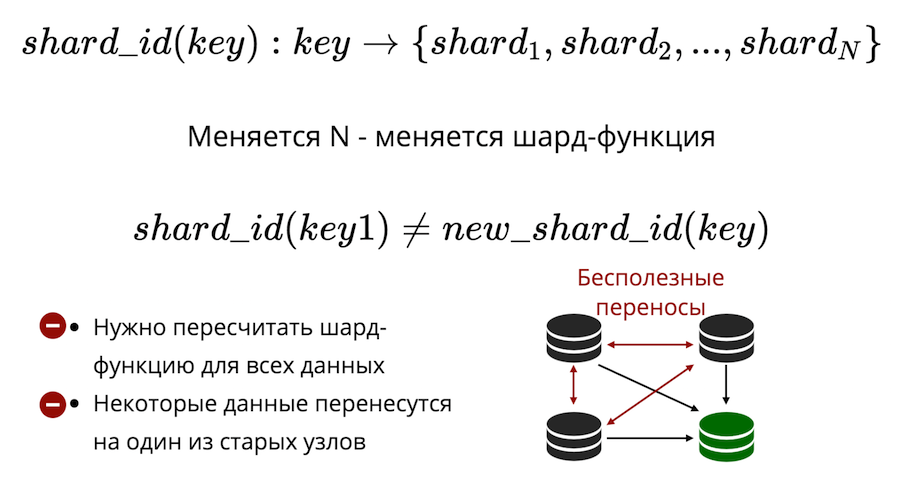
Tarantool utilise le partage virtuel: les données sont distribuées non pas sur des nœuds physiques, mais sur des nœuds virtuels. Compartiment virtuel dans un cluster virtuel. Et les histoires virtuelles sont présentées sur des histoires physiques. Et déjà là, il est garanti que chaque étage virtuel se trouve entièrement sur un étage physique.
Comment cela résout-il le problème du resoldage? Le fait est que le nombre de compartiments est fixe et dépasse sérieusement le nombre de nœuds physiques. Ainsi, quelle que soit la taille physique de votre cluster, le bucket sera toujours suffisant pour stocker les données et les répartir uniformément. Et du fait que la fonction de partition n'est pas modifiée, vous n'aurez pas à la recalculer lorsque la composition du cluster change.
En conséquence, nous obtenons
trois types de partage: les plages, les hachages et les compartiments virtuels . Dans le cas des plages et des compartiments, il existe un problème de recherche physique.
Comment le résoudre? La première façon: interdire simplement le resharding. Ensuite, pour le resharding, vous devrez créer un nouveau cluster et y transférer tout. La deuxième façon: toujours aller à tous les nœuds. Mais cela n'a pas de sens, car vous devez évoluer, et les calculs ne évoluent pas comme ça. Troisième option: un module proxy, qui fait office de routeur pour les buckets. Vous le démarrez, vous y envoyez une demande, en indiquant le numéro du compartiment, et il envoie votre demande en tant que proxy au nœud physique souhaité.
Mémoire avancée avec l'exemple de plate-forme GridGain
L'entreprise a des exigences de base de données supplémentaires. Il veut que tout cela soit tolérant aux fautes et catastrophique. Il veut une haute disponibilité: pour que rien ne soit jamais perdu, pour que vous puissiez récupérer rapidement. Une évolutivité facile et bon marché, un support simple, une confiance dans la plate-forme et des mécanismes d'accès efficaces sont également nécessaires.
Toutes ces idées ne sont pas nouvelles. Beaucoup de ces choses sont, à un degré ou à un autre, implémentées dans des SGBD classiques, en particulier, la réplication entre les centres de données.
In-Memory n'est plus une technologie de startup, ce sont des produits matures qui sont utilisés dans les plus grandes entreprises du monde (Barclays, Citi Group, Microsoft, etc.). On suppose que toutes ces exigences sont remplies.
Donc, si une catastrophe se produisait soudainement, il devrait y avoir une possibilité de récupérer de la sauvegarde. Et si nous parlons d'une organisation financière, il est important que cette sauvegarde soit cohérente, et pas seulement une copie de tous les disques. Pour qu'il n'y ait aucune situation où, sur certaines parties des nœuds, les données ont été restaurées au moment X, et sur l'autre partie au moment Y. Il est très important d'avoir une récupération ponctuelle, de sorte que même en cas de corruption de données ou d'accident particulièrement grave, minimisez la quantité de perte.
Il est important de pouvoir envoyer des données sur disque. Pour que le cluster ne tombe pas en surcharge et continue de fonctionner encore plus lentement. Et pour sortir rapidement du disque, puis déjà pompé les données en mémoire.
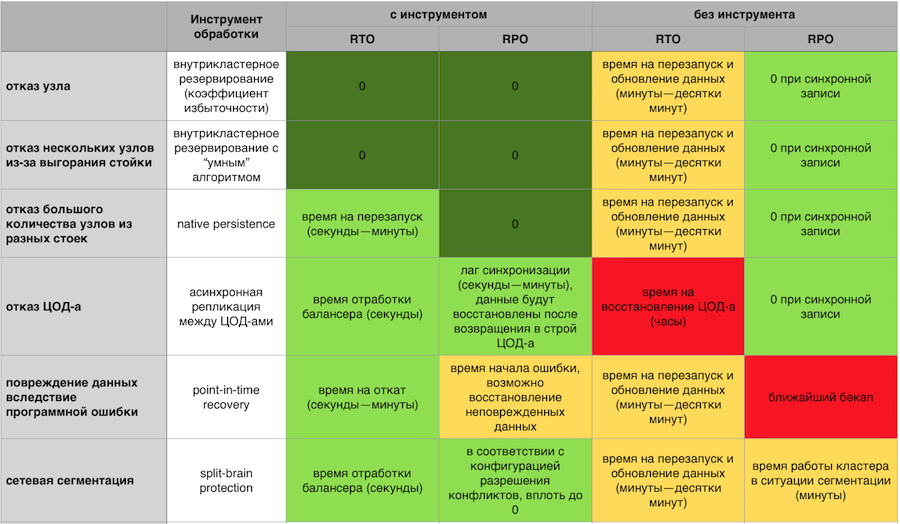 Réponse en mémoire aux plantages avec et sans composants de tolérance aux pannes GridGain
Réponse en mémoire aux plantages avec et sans composants de tolérance aux pannes GridGainUn cluster de basculement doit évoluer facilement horizontalement et verticalement. Je n'ai pas envie de payer pour mon serveur et de regarder comment la moitié des ressources sont inactives. Je ne veux pas avoir l'enfer sur des centaines de processus qui doivent être gérés. Je veux un système simple du point de vue du support, avec une entrée-sortie facile des nœuds du cluster et un système de surveillance développé et mature.
Considérez MongoDB dans cette perspective. Tous ceux qui ont travaillé avec MongoDB connaissent un grand nombre de processus. Si nous avons un MongoDB ombré de 5 fragments, alors chaque fragment aura un jeu de répliques de trois processus (avec un taux de redondance de 3). Et il s'agit de 15 processus uniquement sur les données elles-mêmes. Le stockage de configuration de cluster est un autre plus 3 processus, au total, il en obtient 18, et cela n'inclut pas les routeurs. Si vous voulez 20 fragments, bienvenue en enfer sur 63+ (par exemple, 8 autres, 71 au total) processus.
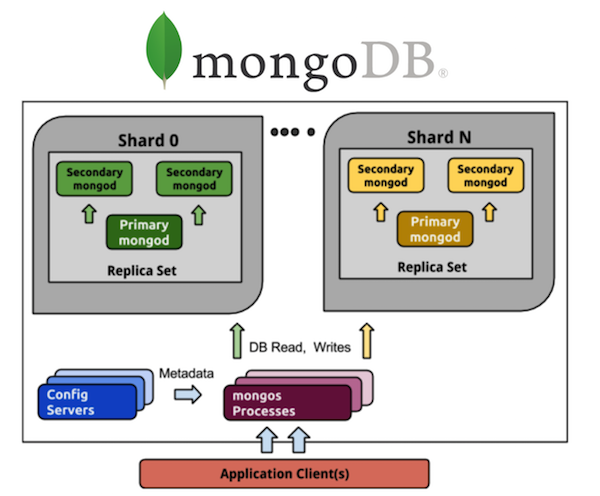
Comparez avec Cassandra. Nous prenons tous les mêmes 5 fragments - ce sont 5 processus et 5 nœuds avec le même taux de redondance de 3, ce qui est beaucoup plus simple en termes de contrôle. Je veux 20 fragments - ce sont 20 processus. Je peux adapter mon cluster à n'importe quel nombre de nœuds, pas nécessairement à un multiple de 3 (ou à une autre valeur du coefficient de redondance). Beaucoup plus facile et moins cher à mettre en œuvre et à entretenir que les jeux de répliques.

De plus, vous devez faire confiance au système pour comprendre ce que les gens soutiennent chaque produit individuel. Idéalement, la licence devrait être open source ou open core. Pour qu'en cas de décès du vendeur, quelque chose puisse être fait. Il est également bon que le code source soit géré par une communauté indépendante - nous nous souvenons tous de la façon dont MongoDB et Redis ont changé de licence à la demande de la société de gestion. Comment Aerospike a introduit des restrictions sur l'édition communautaire «open source» au début de l'année.
Besoin d'un accès efficace aux données. Presque tous ont un langage de requête structuré sous une forme ou une autre. Le plus souvent ils utilisent SQL, il faut que l'adaptation avec ce langage soit aussi simple que possible. Cela aidera à l'exécution des requêtes distribuées, lorsque vous n'avez pas besoin d'envoyer une demande séparément à chaque nœud, mais vous pouvez communiquer avec le cluster comme avec une «fenêtre unique». Sans penser du point de vue de l'API, il s'agit d'un ensemble de nœuds (rappelez-vous à quel point il est difficile de travailler avec Memcache sur de gros volumes même au niveau put / get le plus simple, sans requêtes SQL potentiellement complexes), DDL distribué et garanties ACID.
Et enfin, le soutien. Si quelque chose ne fonctionne pas soudainement, l'entreprise perd tout simplement de l'argent. Pour certains domaines, ce n'est pas critique, mais il est souvent important que quelqu'un assume la responsabilité du produit et de son travail. Qu'il était possible à tout moment de faire une réclamation, et cela a été rapidement résolu.
Avec ce billet, nous terminons l'année de Promsvyazbank sur Habré. Nous avons recueilli les vœux du Nouvel An pour les habitants de Khabrovsk dans une courte vidéo: