Salut les collègues!

Dans la dernière publication de l'année sortante, nous voulions mentionner l'apprentissage par renforcement - un sujet dans lequel nous traduisons déjà un
livre .
Jugez par vous-même: il y avait un article élémentaire avec Medium, qui décrivait le contexte du problème, décrivait l'algorithme le plus simple avec une implémentation en Python. L'article a plusieurs gifs. Et la motivation, la récompense et le choix de la bonne stratégie sur la voie du succès sont des choses qui seront extrêmement utiles à chacun de nous au cours de l'année à venir.
Bonne lecture!
L'apprentissage renforcé est une forme d'apprentissage automatique dans laquelle l'agent apprend à agir dans l'environnement, à effectuer des actions et à développer ainsi l'intuition, après quoi il observe les résultats de ses actions. Dans cet article, je vais vous expliquer comment comprendre et formuler le problème de l'apprentissage par renforcement, puis le résoudre en Python.
Récemment, nous nous sommes habitués au fait que les ordinateurs jouent à des jeux contre les humains - soit comme des bots dans des jeux multijoueurs, soit comme des rivaux dans des jeux en un contre un: disons, dans Dota2, PUB-G, Mario. La société de recherche
Deepmind a fait toute une
histoire à propos de cette nouvelle lorsque son programme AlphaGo 2016 a battu le champion sud-coréen en 2016. Si vous êtes un joueur passionné, vous pourriez entendre parler des cinq matchs de Dota 2 OpenAI Five, où des voitures ont combattu contre des gens et battu les meilleurs joueurs de Dota2 en plusieurs matchs. (Si vous êtes intéressé par les détails, l'algorithme est analysé en détail
ici et il est examiné comment les machines ont joué).

La dernière version d'OpenAI Five
prend Roshan .
Commençons donc par la question centrale. Pourquoi avons-nous besoin d'une formation renforcée? Est-il utilisé uniquement dans les jeux ou est-il applicable dans des scénarios réalistes pour résoudre des problèmes appliqués? Si c'est la première fois que vous lisez une formation de renforcement, vous ne pouvez tout simplement pas imaginer la réponse à ces questions. En effet, l'apprentissage renforcé est l'une des technologies les plus utilisées et en développement rapide dans le domaine de l'intelligence artificielle.
Voici un certain nombre de domaines dans lesquels les systèmes d'apprentissage par renforcement sont particulièrement demandés:
- Véhicules sans pilote
- Industrie du jeu
- Robotique
- Systèmes de recommandation
- Publicité et marketing
Aperçu et contexte de l'apprentissage par renforcementAlors, comment le phénomène d'apprentissage avec renforcement a-t-il pris forme alors que nous avons tant de machines et de méthodes d'apprentissage en profondeur à notre disposition? "Il a été inventé par Rich Sutton et Andrew Barto, directeur de recherche de Rich, qui l'ont aidé à préparer son doctorat." Le paradigme a d'abord pris forme dans les années 80, puis était archaïque. Par la suite, Rich a cru qu'elle avait un grand avenir et qu'elle finirait par être reconnue.
L'apprentissage renforcé prend en charge l'automatisation dans l'environnement où il est déployé. La machine et l'apprentissage en profondeur fonctionnent à peu près de la même manière - ils sont stratégiquement disposés différemment, mais les deux paradigmes prennent en charge l'automatisation. Alors, pourquoi la formation de renforcement est-elle apparue?
Cela rappelle beaucoup le processus d'apprentissage naturel, dans lequel le processus / modèle agit et reçoit des commentaires sur la façon dont elle parvient à faire face à la tâche: bonne et non.
La machine et l'apprentissage en profondeur sont également des options de formation, mais ils sont plus adaptés pour identifier les modèles dans les données disponibles. En revanche, dans l'apprentissage par renforcement, cette expérience s'acquiert par essais et erreurs; le système trouve progressivement les bonnes options ou l'optimum global. Un avantage supplémentaire sérieux de l'apprentissage renforcé est que dans ce cas, il n'est pas nécessaire de fournir un ensemble complet de données de formation, comme dans l'enseignement avec un enseignant. Quelques petits fragments suffiront.
Le concept d'apprentissage par renforcementImaginez apprendre à vos chats de nouveaux trucs; mais, malheureusement, les chats ne comprennent pas le langage humain, vous ne pouvez donc pas prendre et leur dire ce que vous allez jouer avec eux. Par conséquent, vous agirez différemment: imitez la situation et le chat essaiera de répondre d'une manière ou d'une autre en réponse. Si le chat a réagi comme vous le vouliez, vous y versez du lait. Comprenez-vous ce qui va se passer ensuite? Encore une fois, dans une situation similaire, le chat effectuera à nouveau l'action souhaitée, et avec encore plus d'enthousiasme, en espérant qu'il sera encore mieux nourri. C'est ainsi que l'apprentissage se déroule sur un exemple positif; mais, si vous essayez «d'éduquer» un chat avec des incitations négatives, par exemple, regardez-le strictement et froncez les sourcils, il n'apprend généralement pas dans de telles situations.
L'apprentissage renforcé fonctionne de manière similaire. Nous indiquons à la machine certaines entrées et actions, puis récompensons la machine en fonction de la sortie. Notre objectif ultime est de maximiser les récompenses. Voyons maintenant comment reformuler le problème ci-dessus en termes d'apprentissage par renforcement.
- Le chat agit comme un «agent» exposé à «l'environnement».
- L'environnement est une maison ou une aire de jeux, selon ce que vous enseignez au chat.
- Les situations résultant de la formation sont appelées «états». Dans le cas d'un chat, des exemples de conditions sont lorsque le chat «court» ou «rampe sous le lit».
- Les agents réagissent en effectuant des actions et en passant d'un «état» à un autre.
- Après le changement d'état, l'agent reçoit une «récompense» ou une «amende» selon l'action qu'il a entreprise.
- La «stratégie» est une méthodologie pour choisir une action pour obtenir les meilleurs résultats.
Maintenant que nous avons compris ce qu'est l'apprentissage par renforcement, parlons en détail des origines et de l'évolution de l'apprentissage par renforcement et de l'apprentissage par renforcement profond, discutons de la façon dont ce paradigme nous permet de résoudre des problèmes impossibles à apprendre avec ou sans enseignant, et notons également ce qui suit fait curieux: à l'heure actuelle, le moteur de recherche de Google est optimisé à l'aide d'algorithmes d'apprentissage par renforcement.
Comprendre la terminologie de l'apprentissage par renforcementL'agent et l'environnement jouent des rôles clés dans l'algorithme d'apprentissage par renforcement. L'environnement est le monde dans lequel l'agent doit survivre. De plus, l'agent reçoit des signaux de renforcement de l'environnement (récompense): il s'agit d'un nombre qui caractérise à quel point l'état actuel du monde peut être bon ou mauvais. Le but de l'agent est de maximiser la récompense totale, ce que l'on appelle le «gain». Avant d'écrire nos premiers algorithmes d'apprentissage par renforcement, vous devez comprendre la terminologie suivante.

- États : Un État est une description complète d'un monde dans lequel aucun fragment des informations caractérisant ce monde ne manque. Il peut s'agir d'une position, fixe ou dynamique. En règle générale, ces états sont écrits sous la forme de tableaux, de matrices ou de tenseurs d'ordre supérieur.
- Action : l'action dépend généralement des conditions environnementales et, dans différents environnements, l'agent entreprendra différentes actions. De nombreuses actions d'agent valides sont enregistrées dans un espace appelé «espace d'action». En règle générale, le nombre d'actions dans l'espace est fini.
- Environnement : Il s'agit de l'endroit où l'agent existe et avec lequel il interagit. Différents types de récompenses, stratégies, etc. sont utilisés pour différents environnements.
- Récompenses et gains : vous devez surveiller en permanence la fonction de récompense R lorsque vous vous entraînez avec des renforts. Il est essentiel lors de la configuration d'un algorithme, de son optimisation et également lorsque vous arrêtez d'apprendre. Cela dépend de l'état actuel du monde, des mesures qui viennent d'être prises et du prochain état du monde.
- Stratégies : une stratégie est une règle selon laquelle un agent choisit l'action suivante. L'ensemble des stratégies est également appelé «cerveau» de l'agent.
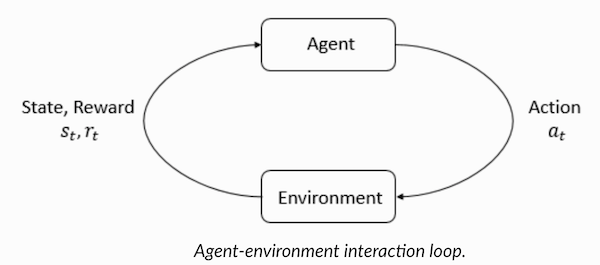
Maintenant que nous nous sommes familiarisés avec la terminologie de l'apprentissage par renforcement, résolvons le problème en utilisant les algorithmes appropriés. Avant cela, vous devez comprendre comment formuler un tel problème et, pour résoudre ce problème, vous fier à la terminologie de la formation avec renforcement.
Solution de taxiNous passons donc à la résolution du problème avec l'utilisation d'algorithmes de renforcement.
Supposons que nous ayons une zone d'entraînement pour un taxi sans pilote, que nous formons pour livrer les passagers au parking à quatre points différents (
R,G,Y,B ). Avant cela, vous devez comprendre et définir l'environnement dans lequel nous commençons la programmation en Python. Si vous commencez tout juste à apprendre Python, je vous recommande
cet article .
L'environnement pour résoudre un problème de taxi peut être configuré à l'aide d'OpenAI's
Gym - c'est l'une des bibliothèques les plus populaires pour résoudre les problèmes avec la formation de renforcement. Eh bien, avant d'utiliser gym, vous devez l'installer sur votre machine, et un gestionnaire de packages Python appelé pip est pratique pour cela. Voici la commande d'installation.
pip install gymVoyons ensuite comment notre environnement sera affiché. Tous les modèles et l'interface pour cette tâche sont déjà configurés dans le gymnase et nommés sous
Taxi-V2 . L'extrait de code ci-dessous est utilisé pour afficher cet environnement.
«Nous avons 4 emplacements (indiqués par des lettres différentes); notre tâche consiste à prendre un passager à un moment donné et à le déposer à un autre. Nous obtenons +20 points pour un atterrissage réussi et perdons 1 point pour chaque étape dépensée. Il y a également une pénalité de 10 points pour chaque embarquement et débarquement involontaire d'un passager. » (Source:
gym.openai.com/envs/Taxi-v2 )
Voici la sortie que nous verrons dans notre console:

Taxi V2 ENV
Génial,
env est le cœur d'OpenAi Gym, c'est une interface d'environnement unifiée. Voici les méthodes env que nous trouvons utiles:
env.reset : réinitialise l'environnement et renvoie un état initial aléatoire.
env.step(action) : fait progresser
env.step(action) développement de l'environnement une étape dans le temps.
env.step(action) : retourne les variables suivantes
observation : Observation de l'environnement.reward : reward si votre action a été bénéfique.done : indique si nous avons réussi à ramasser et à déposer correctement le passager, également appelé «un épisode».info : informations supplémentaires telles que les performances et la latence nécessaires à des fins de débogage.env.render : affiche une image de l'environnement (utile pour le rendu)
Donc, après avoir examiné l'environnement, essayons de mieux comprendre le problème. Les taxis sont la seule voiture sur ce parking. Le stationnement peut être divisé en une grille
5x5 , où nous obtenons 25 emplacements de taxi possibles. Ces 25 valeurs sont l'un des éléments de notre espace d'état. Remarque: pour le moment, notre taxi est situé au point avec les coordonnées (3, 1).
Il y a 4 points dans l'environnement où les passagers sont autorisés à monter à bord: ce sont les coordonnées
R, G, Y, B ou
[(0,0), (0,4), (4,0), (4,3)] en coordonnées ( horizontalement; verticalement), s'il était possible d'interpréter l'environnement ci-dessus en coordonnées cartésiennes. Si vous prenez également en compte un (1) autre état du passager: à l'intérieur du taxi, vous pouvez prendre toutes les combinaisons d'emplacements de passagers et de leurs destinations afin de calculer le nombre total d'états dans notre environnement pour la formation en taxi: nous avons quatre (4) destinations et cinq (4+) 1) emplacements des passagers.
Donc, dans notre environnement pour un taxi, il y a 5 × 5 × 5 × 4 = 500 états possibles. Un agent traite l'une des 500 conditions et prend des mesures. Dans notre cas, les options sont les suivantes: se déplacer dans un sens ou dans l'autre, ou la décision de prendre / déposer le passager. En d'autres termes, nous avons à notre disposition six actions possibles:
ramasser, déposer, nord, est, sud, ouest (les quatre dernières valeurs sont les directions dans lesquelles un taxi peut se déplacer.)
Il s'agit de l'
action space : l'ensemble de toutes les actions que notre agent peut entreprendre dans un état donné.
Comme le montre l'illustration ci-dessus, un taxi ne peut pas effectuer certaines actions dans certaines situations (les murs interfèrent). Dans le code décrivant l'environnement, nous attribuons simplement une pénalité de -1 pour chaque coup dans le mur, et un taxi entrant en collision avec le mur. Ainsi, de telles amendes s'accumuleront, de sorte que le taxi essaiera de ne pas heurter les murs.
Tableau des récompenses: lors de la création d'un environnement de taxi, il est également possible de créer un tableau de récompenses principal appelé P. Vous pouvez le considérer comme une matrice, où le nombre d'états correspond au nombre de lignes et le nombre d'actions au nombre de colonnes. Autrement dit, nous parlons de la matrice
states × actions .
Étant donné que toutes les conditions sont enregistrées dans cette matrice, vous pouvez afficher les valeurs de récompense par défaut affectées à l'état que nous avons choisi d'illustrer:
>>> import gym >>> env = gym.make("Taxi-v2").env >>> env.P[328] {0: [(1.0, 433, -1, False)], 1: [(1.0, 233, -1, False)], 2: [(1.0, 353, -1, False)], 3: [(1.0, 333, -1, False)], 4: [(1.0, 333, -10, False)], 5: [(1.0, 333, -10, False)] }
La structure de ce dictionnaire est la suivante:
{action: [(probability, nextstate, reward, done)]} .
- Les valeurs 0 à 5 correspondent aux actions (sud, nord, est, ouest, prise en charge, dépose) qu'un taxi peut effectuer dans l'état actuel indiqué sur l'illustration.
- done vous permet de juger du moment où nous avons réussi à déposer le passager au point souhaité.
Pour résoudre ce problème sans aucune formation avec renforcement, vous pouvez définir l'état cible, faire une sélection d'espaces, puis, si vous pouvez atteindre l'état cible pendant un certain nombre d'itérations, supposer que ce moment correspond à la récompense maximale. Dans d'autres États, la valeur de la récompense s'approche du maximum si le programme agit correctement (s'approche de l'objectif) ou accumule des amendes en cas d'erreur. De plus, la valeur de l'amende peut atteindre au moins -10.
Écrivons du code pour résoudre ce problème sans formation de renforcement.
Étant donné que nous avons une table P avec des valeurs de récompense par défaut pour chaque état, nous pouvons essayer d'organiser la navigation de notre taxi en fonction de cette table.
Nous créons une boucle sans fin, défilant jusqu'à ce que le passager atteigne la destination (un épisode), ou, en d'autres termes, jusqu'à ce que le taux de récompense atteigne 20. La méthode
env.action_space.sample() sélectionne automatiquement une action aléatoire dans l'ensemble de toutes les actions disponibles . Considérez ce qui se passe:
import gym from time import sleep
Conclusion:
crédits: OpenAI
Le problème est résolu, mais pas optimisé, ou cet algorithme ne fonctionnera pas dans tous les cas. Nous avons besoin d'un agent d'interaction approprié pour que le nombre d'itérations passées par la machine / l'algorithme pour résoudre le problème reste minime. Ici, l'algorithme Q-learning nous aidera, dont la mise en œuvre sera examinée dans la section suivante.
Présentation de Q-LearningVous trouverez ci-dessous les algorithmes d'apprentissage par renforcement les plus populaires et les plus simples. L'environnement récompense l'agent pour une formation progressive et pour le fait que dans un état particulier, il fait le pas le plus optimal. Dans la mise en œuvre discutée ci-dessus, nous avions une table de récompense «P», selon laquelle notre agent apprendra. En fonction du tableau des récompenses, il choisit l'action suivante en fonction de son utilité, puis met à jour une autre valeur, appelée valeur Q. En conséquence, une nouvelle table est créée, appelée Q-table, affichée sur la combinaison (Statut, Action). Si les valeurs Q sont meilleures, alors nous obtenons des récompenses plus optimisées.
Par exemple, si un taxi se trouve dans un état où le passager se trouve au même point que le taxi, il est extrêmement probable que la valeur Q pour l'action «ramasser» soit plus élevée que pour d'autres actions, par exemple, «déposer le passager» ou «aller vers le nord». ".
Les valeurs Q sont initialisées avec des valeurs aléatoires et, lorsque l'agent interagit avec l'environnement et reçoit diverses récompenses en effectuant certaines actions, les valeurs Q sont mises à jour conformément à l'équation suivante:

Cela soulève la question: comment initialiser les valeurs Q et comment les calculer. Au fur et à mesure des actions, les valeurs Q sont exécutées dans cette équation.
Ici, Alpha et Gamma sont les paramètres de l'algorithme Q-learning. Alpha est le rythme d'apprentissage, et gamma est le facteur d'actualisation. Les deux valeurs peuvent aller de 0 à 1 et sont parfois égales à un. Le gamma peut être égal à zéro, mais pas l'alpha, car la valeur des pertes lors de la mise à jour doit être compensée (le taux d'apprentissage est positif). La valeur alpha ici est la même que lorsque vous enseignez avec un professeur. Gamma détermine l'importance que nous voulons donner aux récompenses qui nous attendent à l'avenir.
Cet algorithme est résumé ci-dessous:
- Étape 1: initialisez la table Q, remplissez-la de zéros et pour les valeurs Q, nous définissons des constantes arbitraires.
- Étape 2: Maintenant, laissez l'agent répondre à l'environnement et essayez différentes actions. Pour chaque changement d'état, nous sélectionnons une de toutes les actions possibles dans cet état (S).
- Étape 3: Passez à l'état suivant (S ') en fonction des résultats de l'action précédente (a).
- Étape 4: Pour toutes les actions possibles de l'état (S '), sélectionnez-en une avec la valeur Q la plus élevée.
- Étape 5: Mettez à jour les valeurs de la table Q conformément à l'équation ci-dessus.
- Étape 6: Transformez l'état suivant en l'état actuel.
- Étape 7: Si l'état cible est atteint, nous terminons le processus, puis répétons.
Q-learning en Python import gym import numpy as np import random from IPython.display import clear_output
Génial, maintenant toutes vos valeurs seront stockées dans la variable
q_table .
Ainsi, votre modèle est formé aux conditions environnementales et sait désormais sélectionner plus précisément les passagers. Et vous vous êtes familiarisé avec le phénomène de l'apprentissage par renforcement, et vous pouvez programmer l'algorithme pour résoudre un nouveau problème.
Autres techniques d'apprentissage par renforcement:
- Processus décisionnels de Markov (MDP) et équations de Bellman
- Programmation dynamique: RL basé sur un modèle, itération de stratégie et itération de valeur
- Deep Q-Training
- Méthodes de descente de gradient de stratégie
- Sarsa
Le code de cet exercice se trouve à:
vihar / python-reinforcement-learning