Une brève classe de maître sur le développement de code d'infrastructure

En octobre de cette année, j'ai fait une présentation à la conférence HashiConf 2018, où j'ai parlé de 5 leçons clés que mes collègues Gruntwork et moi avons apprises dans le processus de création et de maintenance d'une bibliothèque de plus de 300000 lignes de code d'infrastructure utilisées par des centaines d'entreprises dans les systèmes de production. Dans cette publication, je partagerai des vidéos et des diapositives de la présentation, ainsi qu'une version texte abrégée de la description des 5 leçons principales.
Vidéos et diapositives
Intro: DevOps maintenant à l'âge de pierre
Malgré le fait que l'industrie regorge de mots progressistes à la mode: Kubernetes, microservices, grilles de services, infrastructure immuable, big data, lacs de données, etc., la réalité est que lorsque vous êtes plongé dans la création d'une infrastructure, vous ne vous sentez pas tellement à la mode et progressive.
Personnellement, DevOps me le rappelle davantage:




La création d'une infrastructure au niveau de la production est difficile. C'est un vrai stress. Et mange beaucoup de temps. Beaucoup de temps.
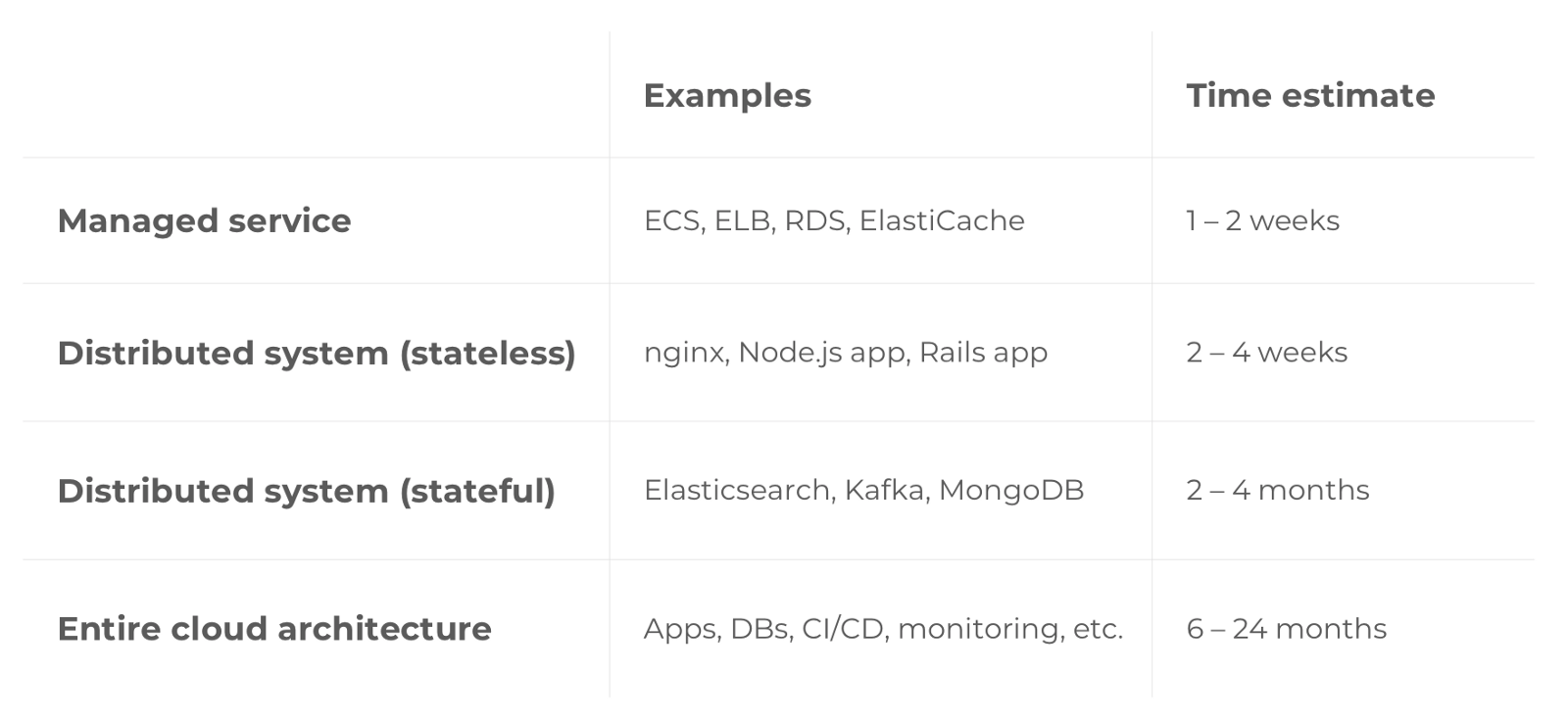
Il montre combien de temps il faudra pour mettre en œuvre le prochain projet d'infrastructure. Nous nous sommes appuyés sur des données empiriques que nous avons collectées au cours de travaux avec des centaines d'entreprises différentes:
Leçon 1. Liste de contrôle pour l'infrastructure de fabrication
Les projets DevOps prennent toujours plus de temps que prévu. Toujours. Pourquoi
La première raison est une coupe de cheveux en yak . Ci-dessous est une illustration vivante de ce phénomène, (ceci est un extrait de la série "Malcolm in the Spotlight")
La deuxième raison est que le processus de création d'une infrastructure au niveau de la production (par exemple, l'infrastructure sur laquelle vous mettriez votre entreprise) se compose de milliers de petites pièces. La grande majorité des développeurs ne connaissent pas ces détails.Par conséquent, lors de l'évaluation d'un projet, vous oubliez généralement de nombreuses tâches critiques (et chronophages).
Pour éviter cela, chaque fois que vous commencez à travailler sur une nouvelle section de l'infrastructure, utilisez la liste de contrôle suivante:
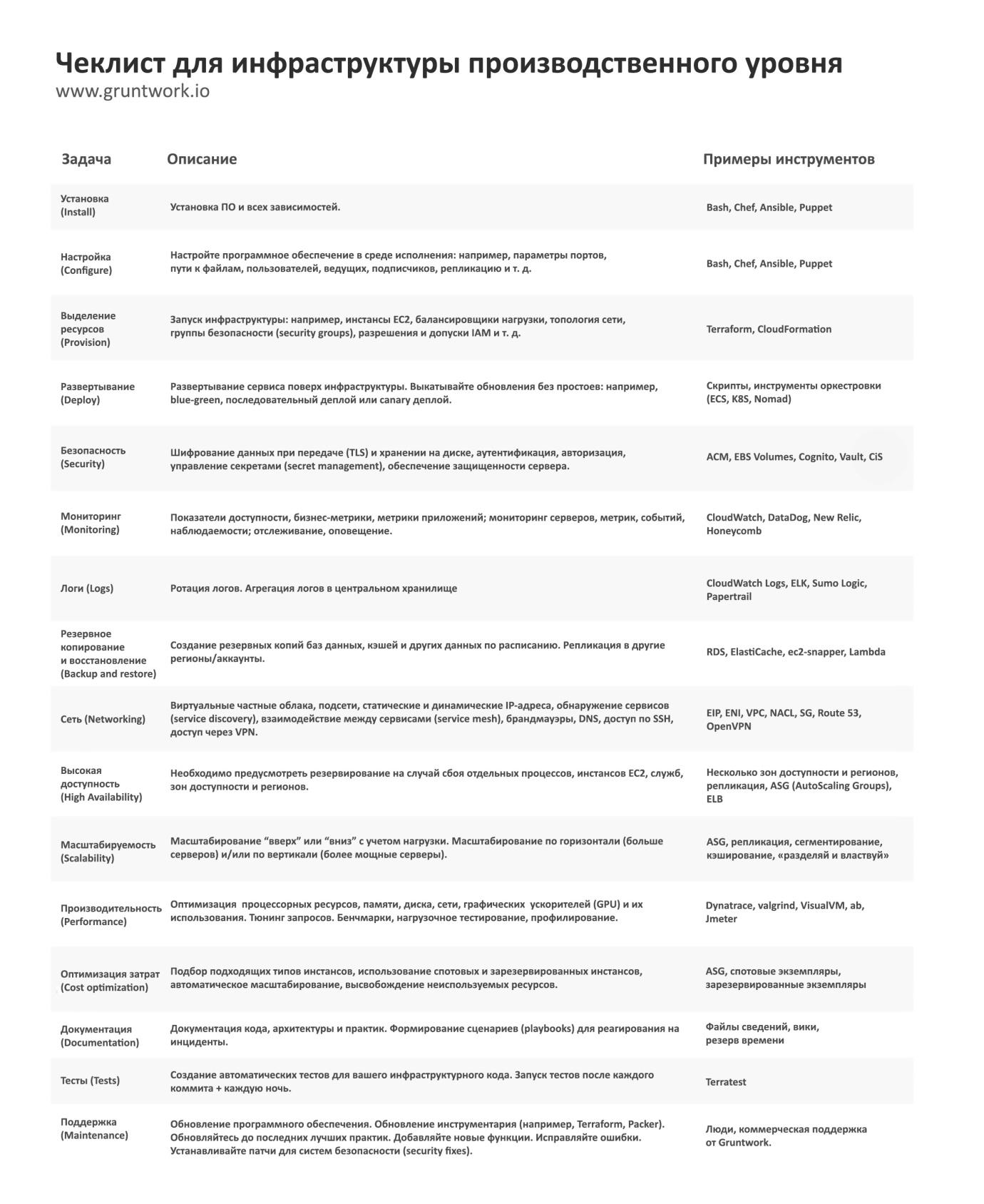
Tous les éléments de la liste ne seront pas nécessaires pour chaque élément individuel de l'infrastructure, mais vous devez documenter consciemment et explicitement les éléments que vous avez mis en œuvre, ceux que vous avez décidé d'ignorer et pourquoi.
Leçon 2. Boîte à outils
Nous listons les principaux outils que nous utilisons chez Gruntwork pour créer et gérer l'infrastructure (à partir de 2018):
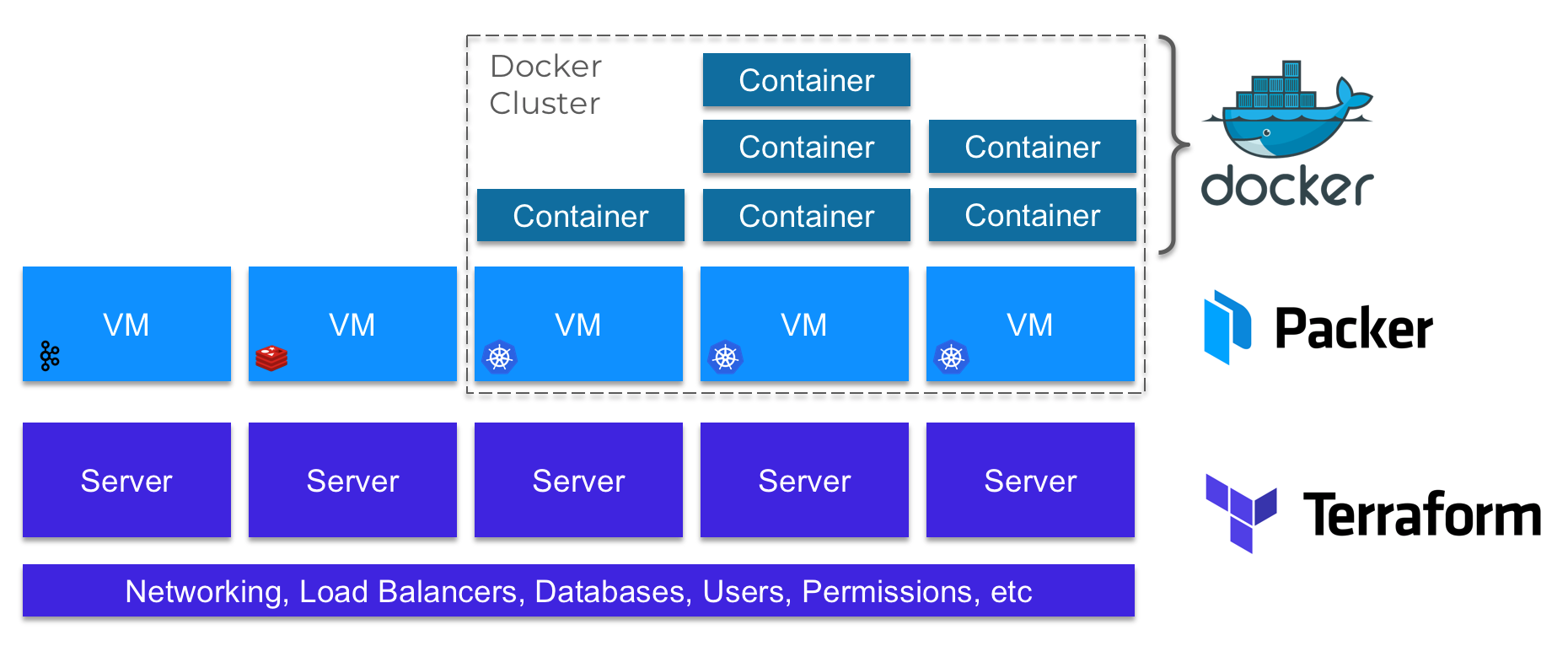
- Terraform . Nous utilisons Terraform pour déployer l'ensemble de l'infrastructure sous-jacente, y compris le réseau, les sous-systèmes d'équilibrage de charge, les bases de données, les outils de gestion des utilisateurs et des autorisations, et tous nos serveurs.
- Packer . Nous utilisons Packer pour configurer et créer des images de machines virtuelles que nous exécutons sur nos serveurs.
- Docker . Certains de nos serveurs forment des clusters dans lesquels nous exécutons des applications en tant que conteneurs Docker. Pour les clusters Docker, nous utilisons principalement les outils suivants: Kubernetes , ECS et Fargate .
Tous ces outils sont utiles, mais ce n'est pas le but. Vous devez comprendre que certains outils ne suffisent pas. Vous devez également modifier le comportement de l'équipe.
En particulier, même les meilleurs outils du monde n’aideront pas votre équipe s’ils ne veulent pas les utiliser ou n’ont pas assez de temps pour apprendre à les utiliser. Ainsi, la principale conclusion est que l'utilisation de "l'infrastructure comme code" est un investissement, c'est-à-dire que certains coûts initiaux vous seront demandés. Si vous investissez judicieusement, vous recevrez des dividendes importants à long terme.
Leçon 3. Les grands modules sont mauvais
Les nouveaux venus dans l'application de «l'infrastructure en tant que code» définissent souvent l'intégralité de leur infrastructure pour tous leurs environnements (environnement de développement, environnement intermédiaire, environnement de production, etc.) dans un fichier ou un ensemble de fichiers qui sont déployés dans leur ensemble. En vain.
Voici quelques-uns des inconvénients de cette approche:
- Basse vitesse Si toute l'infrastructure est définie en un seul endroit, l'exécution de toute commande prendra beaucoup de temps. Nous avons été confrontés à des situations dans les entreprises lorsque l'équipe du
terraform plan a pris 5-6 minutes pour terminer! - Faible sécurité . Si vous gérez l'ensemble de l'infrastructure ensemble, pour changer quelque chose, vous avez besoin d'autorisations pour accéder à tout. Autrement dit, presque tous les utilisateurs doivent être administrateurs, ce qui est également très gênant.
- Risques élevés . Si vous mettez tous vos œufs dans le même panier, créez une situation où une erreur locale peut perturber le fonctionnement de l'ensemble de l'infrastructure. Par exemple, lorsque vous apportez des modifications mineures à une application externe dans l'environnement de développement, une seule faute de frappe ou une commande incorrecte peut entraîner la suppression de la base de données de production.
- C'est difficile à comprendre . Plus le code est placé au même endroit, plus il est difficile pour une personne de comprendre tout cela. Et quand tout cela est connecté, des parties incompréhensibles joueront une cruelle plaisanterie avec vous.
- Difficile à tester . Le test du code d'infrastructure est difficile; tester de grandes quantités de code d'infrastructure est presque impossible. Nous y reviendrons plus tard.
- C'est difficile à analyser . La sortie de commandes telles que le plan terraform devient inutile, car personne ne se soucie de voir des milliers de lignes. De plus, l'analyse de code devient inutile.
En bref, vous devez créer votre code à partir de petits modules composites autonomes et réutilisables. Ce n'est ni une nouvelle ni une découverte. Vous l'avez entendu mille fois, bien que dans des situations légèrement différentes:
«Faites une chose et faites-la bien» - philosophie Unix.
«La première règle des fonctions est qu'elles doivent être petites. La deuxième règle stipule que les fonctions doivent être encore plus petites. " - «Code propre»
Leçon 4. Le code d'infrastructure sans tests automatiques est défectueux
Si votre code d'infrastructure n'a pas de tests automatisés, il ne fonctionne pas correctement. Vous ne le savez tout simplement pas encore. Mais tester le code d'infrastructure est difficile. Vous ne disposez pas d'un "hôte local" (par exemple, vous ne pouvez pas déployer le cloud privé virtuel AWS VPC sur votre ordinateur portable), ni de véritables "tests unitaires" (par exemple, vous ne pouvez pas isoler le code Terraform du monde "extérieur", car c'est comme fois et est conçu pour communiquer avec le monde extérieur).
Par conséquent, afin de tester correctement le code d'infrastructure, vous devez généralement le déployer dans un environnement réel, exécuter une infrastructure réelle, vérifier que le code fonctionne, puis le casser (pour une description de ce style de test: voir Terratest, il s'agit d'une bibliothèque open source qui comprend des outils pour tester le code Terraform , Packer et Docker, travaillant avec les API AWS, GCP et Kubernetes, exécutant des commandes shell localement et sur des serveurs distants via SSH, ainsi que de nombreuses autres fonctionnalités). Ainsi, lors du test de l'infrastructure, vous devez redéfinir légèrement les conditions:
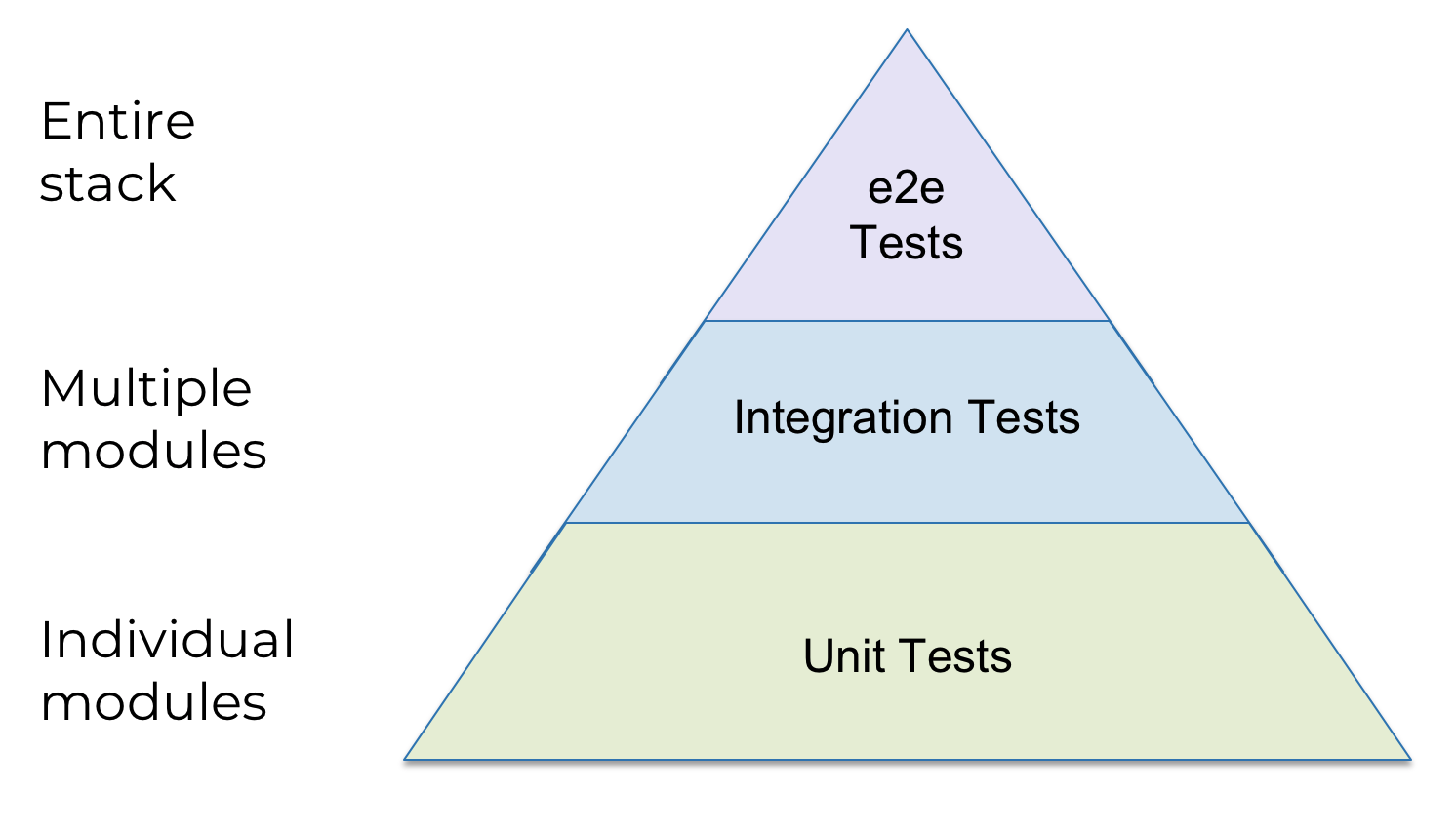
Les tests unitaires déploient et testent un ou plusieurs modules d'infrastructure étroitement liés du même type (par exemple, des modules pour une seule base de données).
Les tests d'intégration déploient et testent plusieurs modules d'infrastructure de différents types pour vérifier qu'ils fonctionnent ensemble (par exemple, les modules de base de données et les modules de service Web).
Les tests de bout en bout (e2e) déploient et testent toute l'architecture.
Veuillez noter que le diagramme est une pyramide: nous avons de nombreux tests unitaires, moins de tests d'intégration et très peu de tests e2e. Pourquoi? Cela dépend de la durée de chaque type de test:
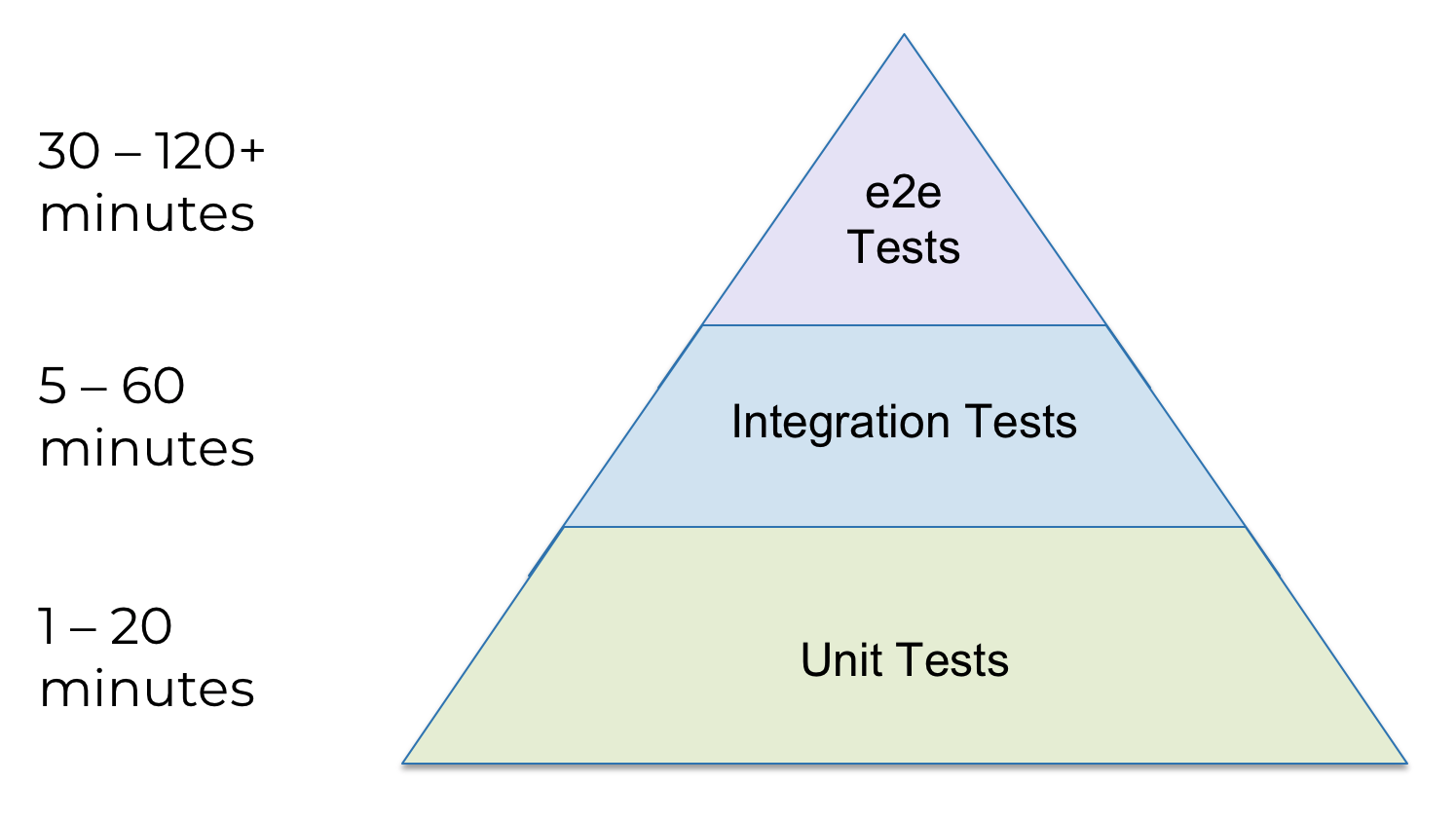
Les tests d'infrastructure prennent beaucoup de temps, en particulier aux niveaux supérieurs de la pyramide, et, bien sûr, vous voudrez trouver et corriger autant d'erreurs que possible tout en bas. Pour ce faire, vous avez besoin de:
- Créez des modules autonomes petits et simples (voir la leçon 3) et écrivez beaucoup de tests unitaires pour eux - assurez-vous qu'ils fonctionnent correctement.
- Combinez ces petits blocs simples et éprouvés pour créer une infrastructure plus sophistiquée que vous testez avec moins d'intégration et de tests E2E.
Leçon 5. Processus de publication
Pour résumer tout ce qui précède. Voici comment vous allez maintenant créer et gérer votre infrastructure:
- Vérifiez la liste de contrôle pour les infrastructures de production et assurez-vous que vous travaillez dans la bonne direction.
- Définissez votre «infrastructure en tant que code» avec des outils tels que Terraform, Packer et Docker. Assurez-vous que votre équipe a suffisamment de temps pour apprendre ces outils (voir Ressources DevOps ).
- Créez du code à partir de petits modules composites autonomes (ou utilisez des modules standard de l'infrastructure en tant que bibliothèque de codes ).
- Préparez des tests automatisés pour vos modules avec Terratest .
- Complétez la demande pour inclure vos modifications afin de réviser votre code.
- Libérez la nouvelle version du code.
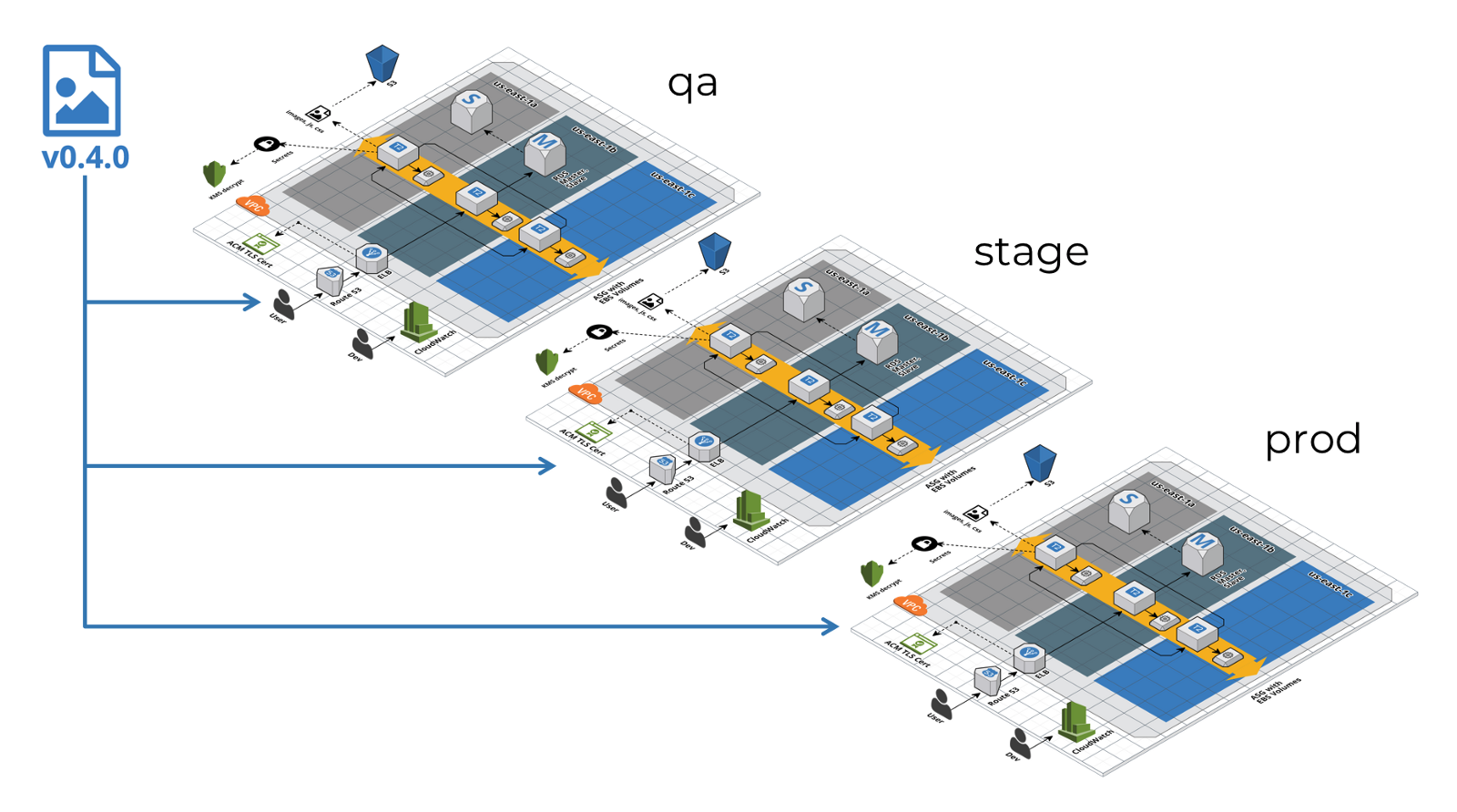
- Copiez la nouvelle version du code d'un environnement à un autre.